https://link.springer.com/article/10.1007/s13369-021-06343-7
이 논문은 토큰 임베딩 관련 논문이었습니다.
우르두라는 형태론적으로 복잡한 언어에서 문구를 정확히 분할하기도 어렵고, 임베딩이 다의어와 문맥 의존적인 내용을 잘 못 담아 냈습니다.
그래서 기존 비문맥적 워드투백터에서 문맥적인 임베딩을 읽을 수 있는 ELMo를 통해 문맥을 훨씬 더 파악할 수 있게 되었고, 청킹 과정 또한 개선해 냈습니다.
| 연구 문제 | - 우르두와 같은 형태론적으로 복잡한 언어에서 문구(chunk)를 정확히 분할하기 어려움. - 기존 비문맥적 임베딩(Word2Vec)은 다의어와 문맥 의존성을 반영하지 못함. |
| 연구 목적 | - 문맥 기반 임베딩(ELMo)을 활용하여 우르두 언어의 문구 청킹 성능을 개선. - IOB 태그 코퍼스 구축 및 BiLSTM 기반 모델 개발. |
| 데이터 및 방법론 | 1. 코퍼스 구축: - 10만 단어 규모의 우르두 코퍼스 주석화. - 명사구(NP), 동사구(VP), 후치사구(PP), 전치사구(PRP) 주석. - 95% 이상의 inter-annotator agreement 달성. 2. 모델 구조: - BiLSTM(최대 3개 층) 기반 신경망 모델. - Word2Vec 및 ELMo 임베딩으로 전이 학습. 3. 전이 학습 데이터: - 비주석 데이터 3,500만 단어에서 Word2Vec 및 ELMo 학습. |
| 핵심 결과 | 1. 성능 비교: - Word2Vec 사용 시: F1 = 93.9. - ELMo 사용 시: F1 = 94.9 (최고 성능). 2. 문구별 성능: - 후치사구(PP): F1 = 98.9 (최고 정확도). - 동사구(VP): F1 = 96.4. - 명사구(NP): F1 = 91.7. |
| ELMo의 강점 | - 문맥 의존적 의미 학습으로 다의어 처리 가능. - 문자 기반 학습으로 형태소 정보 반영. - 데이터 부족 환경에서도 우수한 성능 제공. |
| 결론 및 의의 | - 문맥 기반 임베딩(ELMo)은 형태론적으로 복잡한 언어에서 비문맥적 임베딩(Word2Vec)보다 더 우수. - 저자원 언어 처리에서 전이 학습의 가능성을 입증. - 구축된 코퍼스와 모델은 우르두 NLP 연구에 기여. |
| 향후 연구 방향 | - 최신 문맥 기반 모델(BERT, GPT 등) 성능 비교. - 더 큰 데이터셋 및 다국어 확장. - 다양한 언어 특성을 반영한 새로운 코퍼스 구축. |
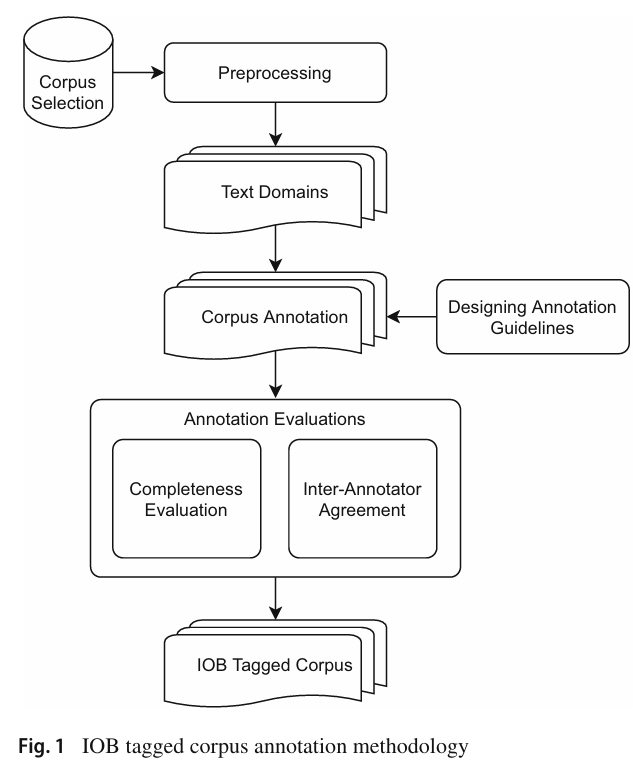
Figure 설명: IOB 태깅 코퍼스 주석화 방법론
이 그림은 IOB 태그 형식으로 코퍼스를 주석화(Annotation)하는 과정을 단계적으로 설명한 흐름도입니다. 각 단계는 데이터 준비부터 최종적으로 주석화된 코퍼스 생성까지의 과정을 체계적으로 나타냅니다.
1. Corpus Selection (코퍼스 선택)
- 주석화 작업을 위한 원시 텍스트 데이터를 선택하는 단계입니다.
- 도메인별로 텍스트를 수집하며, 여기에는 다양한 문서 유형(예: 뉴스 기사, 소설 등)이 포함됩니다.
- 선택된 데이터는 모델 학습 및 평가의 기초가 됩니다.
2. Preprocessing (전처리)
- 선택된 텍스트 데이터를 정제하고 표준화하는 단계입니다.
- 여기에는 불필요한 기호 제거, 문장 분할, 토큰화 등이 포함됩니다.
- 데이터 품질을 높이고 주석화 작업을 효율적으로 수행하기 위해 필수적인 단계입니다.
3. Text Domains (텍스트 도메인 구성)
- 텍스트 데이터를 여러 도메인으로 분류합니다.
- 예를 들어, 뉴스, 대화, 학술 텍스트 등 다양한 도메인별로 데이터를 분리하여 주석화 작업의 일관성을 높이고 각 도메인의 특성을 반영합니다.
4. Designing Annotation Guidelines (주석 지침 설계)
- 주석 작업의 일관성을 보장하기 위해 명확한 지침을 설계합니다.
- 예: 명사구(NP), 동사구(VP), 후치사구(PP)와 같은 문구의 경계 정의.
- 각 태그의 적용 조건과 사례를 포함하여 작업자 간의 혼란을 방지.
5. Corpus Annotation (코퍼스 주석화)
- 설계된 지침에 따라 텍스트 데이터를 주석화하는 단계입니다.
- 여기서 각 단어에 IOB 태그(B-XX, I-XX, O)가 부여됩니다.
- 예: "그가 행복하다" → "그가(B-NP) 행복하다(B-VP)".
- 이 작업은 주로 언어학 전문가들이 수행합니다.
6. Annotation Evaluations (주석 평가)
- 주석의 품질을 평가하여 최종 코퍼스의 신뢰성을 보장합니다.
- Completeness Evaluation (완전성 평가):
- 데이터가 완전하게 주석화되었는지 확인.
- Inter-Annotator Agreement (주석자 간 일치도):
- 여러 주석자가 동일 데이터에 대해 주석을 수행한 후 결과의 일치도를 측정하여 신뢰성 평가.
- Completeness Evaluation (완전성 평가):
7. IOB Tagged Corpus (IOB 태그 코퍼스 생성)
- 평가를 거친 주석 데이터를 기반으로 최종 IOB 형식의 태깅된 코퍼스를 생성합니다.
- 이 코퍼스는 문구 청킹 모델 학습 및 평가에 사용됩니다.
결론
이 그림은 우르두와 같은 언어를 위한 고품질 코퍼스를 체계적으로 생성하는 과정을 단계적으로 설명합니다. 데이터 수집부터 전처리, 주석 작업, 품질 평가를 거쳐 최종적으로 모델 학습에 적합한 IOB 태그 형식의 코퍼스를 완성합니다. 이 체계적인 접근은 데이터의 일관성과 신뢰성을 높이며, 고성능 NLP 모델을 구축하는 데 중요한 기초를 제공합니다.
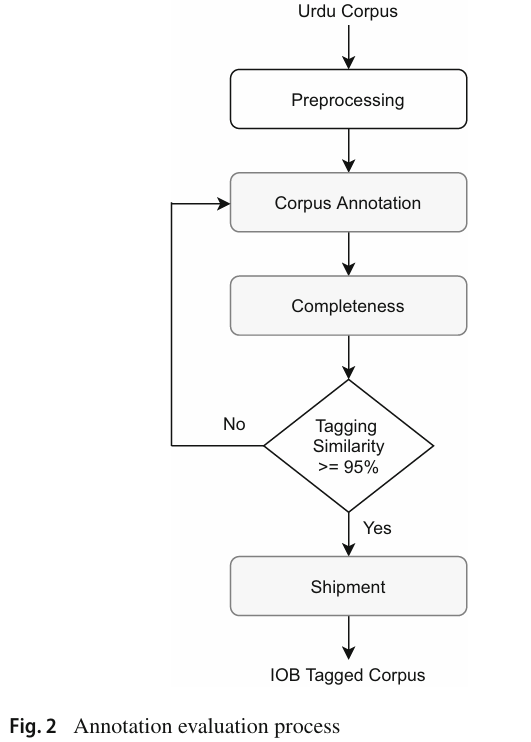
Figure 설명: Annotation Evaluation Process
이 그림은 우르두 코퍼스 주석화의 평가 과정을 단계별로 나타내며, 데이터 품질을 보장하기 위해 반복적으로 검증하고 수정하는 절차를 강조합니다. 각 단계의 역할과 연결 관계를 아래에 설명합니다.
1. Urdu Corpus (우르두 코퍼스)
- 주석화 작업의 기초가 되는 원시 데이터입니다.
- 다양한 텍스트 도메인에서 수집된 우르두 코퍼스를 의미합니다.
2. Preprocessing (전처리)
- 원시 데이터를 주석화 가능한 상태로 만드는 과정입니다.
- 이 단계에서 수행되는 주요 작업:
- 텍스트 정제: 특수문자 제거, 정규화.
- 토큰화: 문장을 단어 단위로 분리.
- 구문 구조 정리: 문장 경계 및 정렬 작업.
3. Corpus Annotation (코퍼스 주석화)
- 전처리된 데이터를 기반으로 단어마다 IOB 태그를 부여합니다.
- 주석화의 대상은 문구(phrase) 단위로, 명사구(NP), 동사구(VP), 후치사구(PP) 등이 포함됩니다.
- 이 작업은 주석 지침(Annotation Guidelines)을 참고하여 전문가에 의해 수행됩니다.
4. Completeness (완전성 평가)
- 완전성 평가는 모든 데이터가 누락 없이 주석화되었는지를 확인하는 단계입니다.
- 예를 들어, 일부 문장이 주석화되지 않았거나 IOB 태그가 적용되지 않은 경우 이를 탐지하고 재주석화를 요청합니다.
5. Tagging Similarity >= 95% (태깅 유사도 검증)
- 여러 주석자가 동일 데이터에 대해 작업한 결과를 비교하여 일관성을 평가합니다.
- 태깅 유사도:
- 두 주석자가 동일한 문구를 같은 IOB 태그로 표시했는지 확인.
- 유사도가 95% 이상인 경우, 주석 결과를 최종 승인.
- 유사도가 95% 미만인 경우:
- 이전 단계(전처리 또는 주석화)로 돌아가 수정 작업을 반복.
6. Shipment (최종 승인 및 저장)
- 주석화와 검증 작업이 완료된 코퍼스는 최종적으로 저장 및 배포됩니다.
- IOB 태그 형식의 코퍼스는 이후 NLP 모델 학습 및 평가에 활용됩니다.
결론
이 프로세스는 코퍼스의 품질을 보장하기 위한 주석화-검증-수정의 반복적 워크플로우를 보여줍니다. 특히, 태깅 유사도 ≥ 95%라는 기준을 설정함으로써 주석 결과의 신뢰성과 일관성을 극대화합니다. 이와 같은 체계적인 검증 과정은 신뢰할 수 있는 NLP 데이터 구축에 필수적입니다.

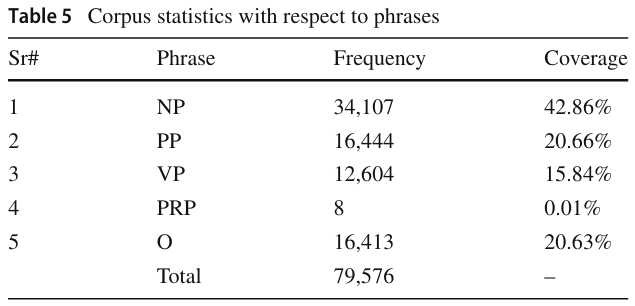
Table 4: Inter-annotator Agreement
이 테이블은 주석자 간의 일치도(inter-annotator agreement)를 평가한 결과를 나타내며, 데이터의 신뢰성과 주석 품질을 검증하는 데 중요한 지표를 제공합니다. 각 Batch별로 다양한 평가 지표가 제시됩니다.
주요 지표
- Label Agreement (%)
- 두 명 이상의 주석자가 동일한 데이터를 주석화했을 때, 태그가 일치하는 비율.
- Batch별 결과:
- Batch-1: 95.3%
- Batch-2: 96.0%
- Batch-3: 96.1%
- 전체 평균: 95.8% → 높은 일치도로 데이터 신뢰성이 검증됨.
- Phrase Agreement (F-score)
- 문구(phrase) 단위로 주석이 얼마나 정확히 이루어졌는지를 측정한 F1 점수.
- Batch별 결과:
- Batch-1: 94.48
- Batch-2: 94.59
- Batch-3: 94.54
- 전체 평균: 94.53 → 주석의 일관성과 품질이 우수함을 보여줌.
- Kappa Coefficient (κ)
- 주석자 간의 일치도를 측정하는 통계 지표로, 랜덤으로 태그가 일치했을 가능성을 제거하고 평가.
- Batch별 결과:
- Batch-1: 0.9412
- Batch-2: 0.9499
- Batch-3: 0.9508
- 전체 평균: 0.9478 → 매우 높은 수준의 일관성.
- No. of Sentences (문장 수)
- 각 Batch에 포함된 문장의 수:
- Batch-1: 137
- Batch-2: 171
- Batch-3: 212
- 전체: 520 문장.
- 각 Batch에 포함된 문장의 수:
- No. of Tokens (토큰 수)
- 각 Batch에서 처리된 단어(토큰)의 총합:
- Batch-1: 3,240
- Batch-2: 4,046
- Batch-3: 4,090
- 전체: 11,376 토큰.
- 각 Batch에서 처리된 단어(토큰)의 총합:
Table 5: Corpus Statistics with Respect to Phrases
이 테이블은 우르두 코퍼스에서 문구(phrase)별 통계를 나타내며, 각 문구 유형의 빈도와 전체 코퍼스에서의 비율을 제공합니다.
주요 문구 통계
- NP (Noun Phrase, 명사구)
- 총 빈도: 34,107
- 전체 코퍼스에서 차지하는 비율: 42.86% → 명사구가 가장 높은 비중을 차지.
- PP (Postpositional Phrase, 후치사구)
- 총 빈도: 16,444
- 전체 비율: 20.66%.
- VP (Verb Phrase, 동사구)
- 총 빈도: 12,604
- 전체 비율: 15.84%.
- PRP (Prepositional Phrase, 전치사구)
- 총 빈도: 8
- 전체 비율: 0.01% → 거의 등장하지 않는 문구.
- O (Outside, 문구 외부)
- 총 빈도: 16,413
- 전체 비율: 20.63%.
- Total
- 전체 빈도 합계: 79,576.
테이블 분석 요약
- Table 4: 주석 품질 평가
- 95% 이상의 주석 일치도와 높은 Kappa 계수(0.9478)는 주석 데이터의 신뢰성과 품질을 보장.
- 문구 단위 주석의 F1 점수도 94.53으로 우수한 성능을 나타냄.
- Table 5: 문구 분포
- 코퍼스에서 명사구(NP)가 가장 많이 등장(42.86%)하며, 이는 우르두 문장에서 명사구가 중요한 구조임을 보여줌.
- 동사구(VP)와 후치사구(PP)는 각각 15.84%, 20.66%의 비중을 차지.
- 전치사구(PRP)는 극히 적게 나타나, 문장 구조에서 덜 중요한 역할을 수행함을 시사.
이 두 테이블은 주석 코퍼스가 높은 품질을 가지며, 우르두 문장의 구조적 특성을 잘 반영하고 있음을 증명합니다.
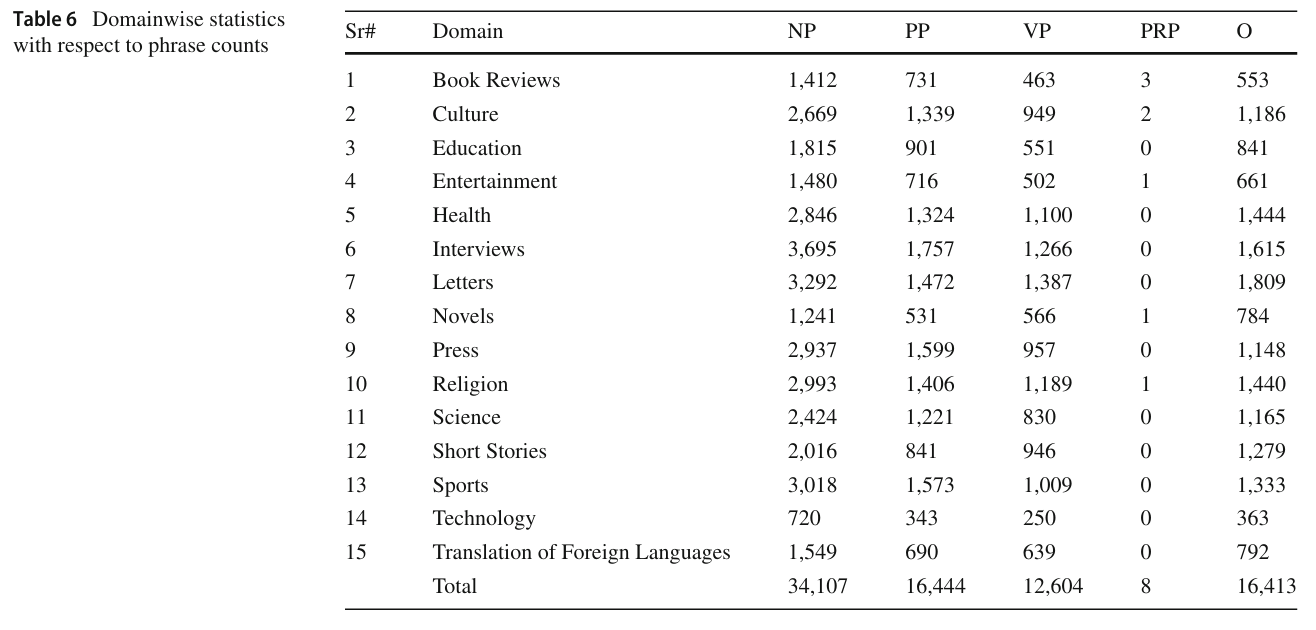
Table 6: Domainwise Statistics with Respect to Phrase Counts
이 테이블은 다양한 도메인별로 문구(phrase) 수를 통계적으로 정리하여, 각 도메인에서 명사구(NP), 동사구(VP), 후치사구(PP), 전치사구(PRP), 문구 외부(O)의 빈도를 나타냅니다. 이를 통해 각 도메인의 텍스트 구조적 특성을 분석할 수 있습니다.
테이블 구조 설명
- Sr#: 도메인 번호.
- Domain: 텍스트 도메인(예: Book Reviews, Culture 등).
- NP, PP, VP, PRP, O: 각 문구 유형의 빈도.
- Total: 모든 도메인의 빈도 합계.
주요 분석
- NP (Noun Phrase, 명사구)
- 명사구는 대부분의 도메인에서 가장 높은 빈도를 차지하며, 전체 합계는 34,107입니다.
- 명사구가 가장 많이 나타난 도메인:
- Interviews: 3,695
- Letters: 3,292
- Sports: 3,018
- 이는 인터뷰와 편지 형식의 텍스트에서 명사구가 자주 사용됨을 보여줍니다.
- PP (Postpositional Phrase, 후치사구)
- 후치사구는 전체 합계 16,444로 명사구 다음으로 높은 빈도를 기록합니다.
- 후치사구가 가장 많이 등장한 도메인:
- Interviews: 1,757
- Letters: 1,472
- Press: 1,599
- 이는 후치사가 우르두 문법에서 중요한 역할을 한다는 점을 반영합니다.
- VP (Verb Phrase, 동사구)
- 동사구는 총 12,604회 등장하며, 도메인 간 분포가 상대적으로 균등합니다.
- 동사구가 가장 많이 나타난 도메인:
- Interviews: 1,266
- Letters: 1,387
- Health: 1,100
- 특히 인터뷰와 건강 관련 텍스트에서 동사가 빈번히 사용됩니다.
- PRP (Prepositional Phrase, 전치사구)
- 전치사구는 전체적으로 빈도가 매우 낮으며, 총 8회만 나타났습니다.
- 이는 우르두 문법에서 전치사가 덜 중요함을 나타냅니다.
- O (Outside, 문구 외부)
- 문구 외부 태그는 총 16,413회 나타나며, 후치사구와 유사한 빈도를 보입니다.
- 문구 외부 태그는 구조적 역할보다는 문장 맥락에 의존하지 않는 단어에 사용됩니다.
도메인별 주요 경향
- Interviews (인터뷰):
- 모든 문구 유형(NP, PP, VP)에서 가장 높은 빈도를 기록, 텍스트가 복잡한 문장 구조를 가짐.
- Letters (편지):
- 명사구와 동사구가 다수 등장하며, 개인적이고 서술적인 문장이 많음을 시사.
- Sports (스포츠):
- 명사구가 높은 빈도를 보이며, 스포츠 주제 특유의 기술적 서술이 반영됨.
결론
이 테이블은 각 도메인의 텍스트 특성과 문구 구조를 이해하는 데 중요한 정보를 제공합니다. 명사구(NP)와 후치사구(PP)가 대부분의 도메인에서 높은 빈도를 차지하며, 이는 우르두 문법의 구조적 특성과 도메인별 텍스트 특성을 반영합니다. 도메인 간의 이러한 차이는 모델 학습 시 다양한 텍스트 구조를 이해하고 처리하는 데 중요한 역할을 할 것입니다.

Table 8: Division of the Corpus into Train, Test, and Development Sets
이 테이블은 우르두 코퍼스를 학습(train), 테스트(test), 개발(dev) 세트로 나눈 분포를 나타냅니다. 이는 모델의 학습, 평가, 및 튜닝을 위해 데이터를 체계적으로 분할한 결과를 보여줍니다.
주요 정보
- No. of Sentences (문장 수)
- 데이터셋에 포함된 문장의 수:
- Train: 4,536문장
- Test: 626문장
- Dev: 626문장
- Total: 5,788문장
- 데이터셋에 포함된 문장의 수:
- No. of Tokens (토큰 수)
- 각 세트에서 단어(토큰)의 총합:
- Train: 88,426토큰
- Test: 11,745토큰
- Dev: 11,862토큰
- Total: 112,033토큰
- 각 세트에서 단어(토큰)의 총합:
- Phrase Counts (문구 수)
- Noun Phrases (명사구)
- Train: 26,937
- Test: 3,618
- Dev: 3,552
- Total: 34,107
- Post-Positional Phrases (후치사구)
- Train: 13,005
- Test: 1,725
- Dev: 1,714
- Total: 16,444
- Verb Phrases (동사구)
- Train: 9,896
- Test: 1,347
- Dev: 1,361
- Total: 12,604
- Prepositional Phrases (전치사구)
- Train: 8
- Test: 0
- Dev: 0
- Total: 8 (아주 적음).
- Outside of Phrase (문구 외부)
- Train: 12,910
- Test: 1,736
- Dev: 1,767
- Total: 16,413
- Noun Phrases (명사구)
테이블 분석
- 학습 세트가 전체 데이터의 대부분을 차지하며, 테스트 및 개발 세트는 각각 전체 데이터의 약 10%로 균형 있게 분할.
- 명사구(NP)가 가장 많은 빈도를 보이며, 후치사구(PP)와 동사구(VP)가 그 뒤를 이음.
- 전치사구(PRP)는 전체에서 매우 낮은 빈도를 차지.
Figure 3: Bi-directional Long-Short-Term Memory (BiLSTM) Model for Sequence Labeling
이 그림은 문구 청킹(sequence labeling)을 위해 사용된 BiLSTM 모델의 구조를 설명합니다. BiLSTM은 양방향으로 정보를 처리하여, 문맥(Context)을 보다 효과적으로 학습할 수 있습니다.
모델 구조
- 입력 토큰 (x1,x2,...,xnx)
- 문장을 구성하는 단어들이 입력으로 주어집니다.
- 각 단어는 Word2Vec 또는 ELMo와 같은 임베딩 벡터로 변환됩니다.
- LSTM 레이어
- 각 단어의 문맥을 학습하기 위해 양방향 LSTM이 사용됩니다:
- Forward LSTM (→): 문장의 시작부터 끝까지 정보를 학습.
- Backward LSTM (←): 문장의 끝에서 시작으로 정보를 학습.
- 두 방향의 결과를 결합하여 단어의 전체 문맥 정보를 얻습니다.
- 각 단어의 문맥을 학습하기 위해 양방향 LSTM이 사용됩니다:
- 출력 벡터 (h1,h2,...,hn)
- 각 단어의 문맥 정보를 포함하는 은닉 상태 벡터가 출력됩니다.
- 이 벡터는 다음 단계에서 Softmax를 통해 IOB 태그(예: B-NP, I-NP, O 등)로 변환됩니다.
BiLSTM의 특징과 장점
- 양방향 처리
- 단어의 앞뒤 문맥을 모두 학습하여 문장의 구조적 정보를 더 잘 이해.
- 예: "책을 읽는다"에서 "책을"과 "읽는다"의 관계를 양방향으로 학습.
- 시퀀스 태깅에 최적화
- BiLSTM은 문장 내 단어의 순서와 문맥을 고려하여 각 단어의 역할(태그)을 정확히 예측.
결론
- Table 8: 코퍼스를 Train, Test, Dev 세트로 체계적으로 분리하여 데이터 분포의 균형을 유지.
- Figure 3: BiLSTM 모델은 양방향 문맥 학습을 통해 문구 청킹과 같은 시퀀스 태깅 작업에서 높은 성능을 보이는 구조. 이는 형태론적으로 복잡한 우르두 언어에 특히 적합한 모델입니다.

Figure 4: BiLSTM-based Model for IOB Tagging
이 그림은 BiLSTM 모델을 사용하여 IOB 태그를 예측하는 과정을 상세히 설명하고 있습니다. 우르두 문장에서 각 단어에 대해 IOB 태그를 할당하는 작업을 수행하기 위한 모델의 전체 구조를 나타냅니다.
모델 구조 설명
- Train Samples (훈련 샘플)
- 입력 데이터는 각 단어(w_i)에 대해 다음 정보를 포함합니다:
- 단어(w_i): 문장의 각 단어.
- 품사 태그(POS): 단어의 품사 정보.
- IOB 태그: 각 단어에 할당된 실제 IOB 태그 (B-NP, I-NP, O 등).
- 이 데이터는 모델 학습을 위한 주요 입력입니다.
- 입력 데이터는 각 단어(w_i)에 대해 다음 정보를 포함합니다:
- Input Layer (입력 레이어)
- 각 단어는 벡터로 변환되어 모델에 입력됩니다.
- 입력 정보:
- Word Embeddings: 사전 학습된 임베딩(Word2Vec 또는 ELMo)을 사용하여 단어를 벡터로 표현.
- POS Representations: 품사 태그를 추가하여 단어의 구문적 정보를 보강.
- 결과적으로, 각 단어는 단어 임베딩 + 품사 태그가 결합된 고차원 벡터로 표현됩니다.
- Hidden Layers (은닉층)
- BiLSTM 레이어:
- 양방향 LSTM(200 유닛)을 사용하여 문맥 정보를 학습.
- Forward LSTM: 단어의 이전 문맥을 학습.
- Backward LSTM: 단어의 이후 문맥을 학습.
- 두 방향의 출력을 결합하여 각 단어의 문맥적 표현(contextual representation)을 생성.
- BiLSTM 레이어:
- Dense Layer (완전 연결층)
- BiLSTM의 출력 벡터를 Softmax 활성화 함수를 사용하는 밀집층(Dense Layer)으로 전달.
- 각 단어의 IOB 태그에 대한 확률 분포를 계산합니다.
- Predicted Labels (예측 태그)
- Softmax 층에서 각 단어에 대해 가장 높은 확률을 가진 IOB 태그를 최종 출력으로 예측.
- 예:
- 입력: "책을 읽는다"
- 출력: "책을(B-NP) 읽는다(B-VP)"
작동 방식 요약
- 입력으로 단어와 품사 정보, 사전 학습된 임베딩을 결합하여 벡터화.
- BiLSTM 레이어를 통해 단어의 양방향 문맥 정보를 학습.
- Dense 층과 Softmax를 통해 각 단어의 IOB 태그를 확률적으로 예측.
BiLSTM 기반 모델의 특징
- 문맥 학습
- BiLSTM은 단어의 이전과 이후 문맥을 모두 활용하여 정확한 태그를 예측.
- 예: "책"이 명사구인지, 동사구와 연결되는지 문맥적으로 판단.
- POS 정보 활용
- 품사 태그(POS)를 추가하여 단어의 구문적 역할을 더 정확히 파악.
- 전이 학습
- Word2Vec 또는 ELMo와 같은 사전 학습된 임베딩을 활용해, 데이터 부족 문제를 해결하고 더 나은 표현력을 제공.
결론
이 모델은 양방향 문맥 정보 학습(BiLSTM)과 품사 정보 결합을 통해 IOB 태그를 정확히 예측하도록 설계되었습니다. 특히 우르두와 같은 형태론적으로 복잡한 언어에서 높은 성능을 보이는 구조입니다. 이 접근 방식은 문구 청킹(phrase chunking) 문제를 해결하기 위한 효과적인 방법임을 보여줍니다.
문제 정의
우르두(Urdu)와 같은 형태론적으로 복잡한 언어에서 문장 구조를 분할(phrase chunking)하는 작업은 자연어 처리(NLP)에서 중요한 과제입니다. 이 언어는 어휘 형태와 문장 구조가 복잡하고 자원이 부족하여 기존의 방법론으로는 높은 정확도를 달성하기 어렵습니다. 따라서, 이 논문은 우르두 언어를 위한 문구 청킹 모델을 제안하며, 이에 필요한 주석 코퍼스를 생성하고 BiLSTM 기반 신경망 모델을 통해 문구 청킹을 구현합니다.
연구 방법론
- 데이터 주석 및 코퍼스 구축
- CLE Urdu Digest POS 코퍼스를 기반으로 10만 단어 규모의 IOB(In-Out-Begin) 형식 주석 코퍼스 개발.
- 4가지 문구(NP: 명사구, VP: 동사구, PP: 후치사구, PRP: 전치사구)를 주석화하며, 명확한 주석 지침을 개발.
- 주석의 일관성과 정확성을 위해 다단계 검증 수행 및 inter-annotator agreement 계산.
- 신경망 기반 문구 청킹 모델
- BiLSTM 모델: 문장 시퀀스의 문맥 정보를 학습하여 IOB 태그를 예측.
- 전이 학습(Transfer Learning): 부족한 주석 데이터를 보완하기 위해 비구문적(corpus-wide) 단어 임베딩(Word2Vec) 및 문맥화된 단어 임베딩(ELMo) 학습.
- 모델 구성: BiLSTM 레이어(최대 3개)와 Softmax 분류기를 결합하여 각 단어의 문구 태그를 예측.
결과 및 논의
- 모델 성능
- Word2Vec 기반 전이 학습 모델: F1 점수 93.9.
- ELMo 기반 전이 학습 모델: F1 점수 94.9로 최고 성능 기록.
- ELMo는 문맥 정보 및 형태소 수준의 정보를 효과적으로 학습하며, Word2Vec보다 우수한 성능을 보임.
- 문구별 성능
- 동사구(VP): F1 = 96.4
- 후치사구(PP): F1 = 98.9
- 명사구(NP): F1 = 91.7 (다양한 구문적 복잡성으로 인해 상대적으로 낮은 점수).
- 분석 결과
- ELMo 임베딩은 단어의 다의성을 구별하고 문맥에 따라 적절히 분포를 학습, 비문맥적 임베딩 대비 높은 유사도를 달성.
- POS 태그를 추가하여 BiLSTM 성능을 약 4% 향상.
결론
- 제안된 BiLSTM 기반 문구 청킹 모델은 우르두와 같은 형태론적으로 복잡한 언어에서도 높은 성능(F1 = 94.9)을 달성.
- ELMo 임베딩은 문맥 의존적 정보 학습에서 탁월한 성과를 보였으며, 특히 데이터가 부족한 언어에서 전이 학습의 가능성을 확인.
- 본 연구는 우르두 언어의 NLP 자원 부족 문제를 해결하고, 향후 명명 엔터티 인식, 정보 추출 등 다양한 응용으로의 확장이 기대됨.
연구의 의의
이 연구는 형태론적으로 복잡한 언어에서 전이 학습과 신경망 모델을 활용한 문구 청킹의 가능성을 제시하며, 저자원이지만 구문적으로 복잡한 언어를 처리하는 새로운 방법론의 기틀을 마련합니다. 추가 연구에서는 더 큰 데이터셋과 언어 확장을 통해 모델 성능을 더욱 개선할 여지가 있습니다.
방법론
1. 데이터 주석 및 코퍼스 구축
우르두 언어를 처리하기 위해 먼저 문장을 구성하는 명사구(NP), 동사구(VP), 후치사구(PP), 전치사구(PRP)를 식별하고 주석화해야 했습니다. 이를 위해 다음 단계를 거쳤습니다.
- IOB 태그 형식 사용
- IOB 형식은 B(문구 시작), I(문구 내부), O(문구 외부)로 단어를 태그합니다.
- 예시: 문장 "그가 행복하다"에서
- "그가"는 명사구(NP) → B-NP
- "행복하다"는 동사구(VP) → B-VP
- 나머지 단어는 해당 문구 외부 → O.
- 주석 지침 개발
- 주석 작업의 일관성을 위해 명확한 규칙을 설정. 예를 들어:
- 명사구(NP)는 명사와 이를 수식하는 형용사, 관사를 포함합니다.
- 동사구(VP)는 주동사와 조동사, 부정어를 포함합니다.
- 사례: "좋은 책을 읽는다"
- "좋은 책" → B-NP, I-NP
- "읽는다" → B-VP.
- 주석 작업의 일관성을 위해 명확한 규칙을 설정. 예를 들어:
- 주석 품질 관리
- 두 명의 언어학자가 각각 주석 작업을 수행하고, 10%의 데이터에서 주석 일치를 비교해 95% 이상의 정확도를 유지.
2. 신경망 기반 문구 청킹 모델
우르두 문장에서 단어들이 어떤 문구에 속하는지 학습하기 위해 BiLSTM 모델을 사용했습니다.
- BiLSTM이란?
- BiLSTM(양방향 장단기 메모리 네트워크)은 문맥을 고려하여 데이터를 처리합니다.
- 예를 들어 문장에서 "그는 학교에 간다"라는 문장이 있을 때:
- "그는"이 명사구인지, "학교에"가 후치사구인지 결정하려면 이전/이후 단어의 정보가 필요합니다.
- BiLSTM은 "간다"라는 동사가 "학교에"와 연결된다는 문맥을 이해합니다.
- 모델 구조
- 입력: 단어 임베딩(Word2Vec 또는 ELMo)과 품사(POS) 정보를 결합한 벡터.
- 예: "책" → [단어 임베딩] + [POS 임베딩]
- 은닉층: BiLSTM 층(최대 3개).
- 단어의 이전과 이후 문맥 정보를 학습.
- 출력층: Softmax 분류기로 각 단어에 대해 IOB 태그 예측.
- 입력: 단어 임베딩(Word2Vec 또는 ELMo)과 품사(POS) 정보를 결합한 벡터.
- 전이 학습 활용
- 데이터 부족 문제를 해결하기 위해 3,500만 개 단어로 구성된 우르두 텍스트에서 사전 학습된 단어 임베딩을 사용.
- 두 가지 임베딩:
- Word2Vec: 단어의 전역적 의미 학습 (예: "책"의 기본 의미).
- ELMo: 문맥적 의미 학습 (예: "가벼운 책"과 "책을 쓰다"에서 "책"의 다른 의미를 학습).
3. 전이 학습 적용 예시
Word2Vec와 ELMo의 차이점 이해
예제 문장:
- "뱀이 쥐의 굴로 들어갔다."
- "전기와 가스 요금은 매달 나온다."
위 문장에서 우르두 단어 "굴"은 두 가지 의미를 가집니다:
- "쥐의 굴(burrow)"
- "요금서(bill)"
Word2Vec
- "굴"이라는 단어를 하나의 고정된 벡터로 표현합니다.
- 따라서, 문맥에 따라 의미가 달라지지 않습니다.
ELMo
- 문맥을 학습하여 "굴"이 "쥐의 굴"과 관련된 경우 쥐와 가까운 의미를, "요금서"와 관련된 경우 전기/가스와 가까운 의미를 학습합니다.
결과
- Word2Vec: "굴"은 고정된 하나의 의미로 처리.
- ELMo: "굴"이 문맥에 따라 쥐 또는 전기와 더 관련성이 높은 벡터로 학습.
4. 모델 성능 측정
- 평가지표: 정확도, 재현율(Recall), F1 점수로 평가.
- 결과:
- Word2Vec 사용: F1 = 93.9
- ELMo 사용: F1 = 94.9 (문맥 정보 활용으로 성능 개선).
학생을 위한 쉬운 요약
- 우르두 문장은 복잡한 구조를 가집니다.
- 예를 들어, 동사 뒤에 보조 동사, 부정어 등이 붙어 복잡한 문장 구조를 만듭니다.
- BiLSTM은 문맥 정보를 양방향으로 학습하여 이런 복잡한 문장을 처리할 수 있습니다.
- ELMo는 단어의 문맥적 의미를 학습합니다.
- "굴"이라는 단어가 "쥐의 굴"인지, "요금서"인지 문맥에 따라 올바르게 판단.
- 결과적으로, 이 모델은 95%에 가까운 정확도로 문구를 분리합니다.
- NLP에서 우르두와 같은 복잡한 언어도 신경망 모델로 효율적으로 처리할 수 있음을 보여줍니다.
그럼 이 논문은 ELMo와 같이 문맥 기반 임베딩 모델의 우수성을 보여주는 논문이야?
맞습니다! 이 논문은 문맥 기반 임베딩 모델(ELMo)의 우수성을 실험적으로 입증하는 중요한 사례를 제공합니다. 구체적으로 살펴보면, 이 논문은 다음과 같은 점에서 ELMo의 강점을 강조하고 있습니다.
1. 문맥 기반 임베딩의 필요성
- 우르두와 같은 형태론적으로 복잡한 언어에서는 단어의 의미가 문맥에 따라 크게 달라질 수 있습니다.
- 예시: 우르두 단어 "굴(bil)"
- 문맥 1: "뱀이 쥐의 굴로 들어갔다" → 굴(burrow).
- 문맥 2: "전기와 가스 요금은 매달 나온다" → 요금서(bill).
- Word2Vec와 같은 문맥 비의존적 임베딩은 단어당 하나의 고정된 벡터만 생성하여 두 의미를 구별하지 못합니다.
- ELMo는 문장의 문맥을 학습하여 "굴"의 의미를 문맥에 따라 다르게 벡터화합니다.
2. ELMo와 Word2Vec 성능 비교
논문은 BiLSTM 기반 문구 청킹 모델에서 Word2Vec과 ELMo를 활용한 실험을 진행하며, 두 모델의 성능을 비교했습니다.
- Word2Vec 사용 시 성능:
- F1 점수: 93.9.
- 단어의 기본 의미를 학습하는 데는 효과적이지만, 문맥적 의미를 구별하지 못해 일부 문구 태그를 정확히 예측하지 못함.
- ELMo 사용 시 성능:
- F1 점수: 94.9.
- 단어가 문맥에 따라 다르게 해석되도록 학습하며, 복잡한 문구 구조를 더 정확히 태깅.
결론: 문맥 기반 임베딩(ELMo)을 적용했을 때 성능이 약 1%p 향상되었으며, 이는 신경망 모델에서 중요한 개선입니다. 특히 우르두와 같이 형태론적 변형이 많고 데이터 자원이 부족한 언어에서 효과적임을 입증했습니다.
3. ELMo의 추가적 강점
- 형태소 수준 학습: ELMo는 문자를 기반으로 단어를 표현하므로, 우르두와 같은 형태론적으로 복잡한 언어의 변형(예: 접사, 굴절)을 더 잘 처리합니다.
- 예시: "학교에 갔다"와 "학교에서 갔다"는 후치사에 따라 문장의 의미가 달라지는데, ELMo는 이를 잘 반영합니다.
- OOV 문제 해결: 데이터에 없는 단어(out-of-vocabulary)를 처리할 때도 ELMo는 단어 내부 구조를 활용하여 적절한 벡터를 생성합니다.
4. 논문의 기여
- 이 논문은 문맥 기반 임베딩(ELMo)의 실질적 효과를 우르두 언어 처리에 적용하여 입증했습니다.
- 특히, 데이터가 제한적이고 형태소적 변형이 많은 언어에서도 ELMo와 같은 문맥 의존적 접근법이 우수한 성능을 제공할 수 있음을 보여줍니다.
요약
따라서, 이 논문은 ELMo가 Word2Vec와 같은 고정된 임베딩보다 더 우수한 결과를 제공한다는 사실을 뒷받침하는 실험적 증거를 제공합니다. 또한, 형태론적으로 복잡한 언어를 위한 NLP 모델에서 문맥 기반 임베딩의 중요성을 강조하는 데 기여합니다.
논문의 결과와 결론
1. 연구 결과
이 논문은 BiLSTM 기반의 문구 청킹 모델에 대해 문맥 기반 임베딩(ELMo)과 비문맥적 임베딩(Word2Vec)의 성능을 비교 실험하였고, 다음과 같은 주요 결과를 제시했습니다.
- 성능 비교
- Word2Vec을 사용한 모델:
- F1 점수: 93.9.
- 단어의 전역적 의미를 학습했지만, 문맥 정보를 반영하지 못함.
- ELMo를 사용한 모델:
- F1 점수: 94.9 (최고 성능).
- 문맥 정보를 효과적으로 학습해 복잡한 문장 구조와 다의어를 정확히 처리.
- Word2Vec을 사용한 모델:
- 문구별 성능
- 후치사구(Post-Positional Phrase, PP): F1 = 98.9 (최고 정확도).
- 동사구(Verb Phrase, VP): F1 = 96.4.
- 명사구(Noun Phrase, NP): F1 = 91.7 (상대적으로 낮은 성능, 문법적 다양성 때문).
- ELMo의 효과
- ELMo는 단어의 문맥적 의미를 학습하며, 특히 형태소 정보와 다의성을 효과적으로 반영.
- 예: 우르두 단어 "bil"이 "굴(burrow)" 또는 "요금서(bill)"로 문맥에 따라 다르게 해석됨.
2. 연구 결론
- ELMo의 강점
- ELMo는 문맥 의존적 단어 표현을 학습하여, 형태론적으로 복잡하고 자원이 부족한 언어(예: 우르두)에서 우수한 성능을 발휘.
- 문맥적 의미 학습을 통해 다의어 문제를 효과적으로 해결.
- 전이 학습의 중요성
- 사전 학습된 대규모 임베딩(Word2Vec 및 ELMo)은 데이터가 부족한 환경에서 모델 성능을 크게 향상시킴.
- 비문맥적 모델(Word2Vec)도 성능을 높였지만, 문맥 기반 모델(ELMo)이 더 나은 결과를 보임.
- 형태소 정보 활용
- ELMo는 문자 기반 임베딩 방식을 사용하여, 형태소 변형이 많은 언어에서도 강력한 표현력을 제공.
- 데이터 부족 문제 해결
- 대규모 비주석 데이터로 학습한 단어 임베딩을 활용하여 데이터 부족 문제를 완화하고, 우르두와 같은 저자원 언어를 효과적으로 처리.
3. 논문의 마무리
- 학문적 기여
- 본 연구는 우르두와 같은 형태론적으로 복잡한 언어에서 문구 청킹을 위한 신뢰성 있는 코퍼스와 모델을 제공.
- NLP 연구에서 문맥 기반 임베딩의 효과를 실질적으로 증명.
- 실무적 의의
- 우르두뿐만 아니라 다른 저자원 언어에도 적용 가능한 문구 청킹 방법론을 제안.
- 명명 엔터티 인식(NER), 정보 추출 등 다양한 NLP 응용 분야에 확장 가능.
- 향후 연구
- ELMo 외에도 BERT, GPT 등 최신 문맥 기반 모델의 성능 비교 연구.
- 더 큰 데이터셋과 다국어 지원 모델 개발.
- 다양한 언어적 특성을 고려한 새로운 코퍼스 구축.
최종 요약
이 논문은 ELMo와 같은 문맥 기반 임베딩이 우르두와 같은 복잡한 언어에서 비문맥적 임베딩(Word2Vec)보다 우수한 성능을 제공함을 입증했습니다. 이를 통해 문맥 기반 모델의 중요성을 확인했으며, 데이터 부족 문제를 해결하기 위한 전이 학습의 효과를 제시했습니다. 이 연구는 저자원 언어의 NLP 발전에 중요한 기여를 했습니다.
사용자가 정리한 내용을 기반으로 부족하거나 개선이 필요한 점을 보완한 수정된 내용을 아래에 제시합니다.
수정 및 보완된 내용
이 논문은 토큰 임베딩과 문구 청킹(phrase chunking) 문제를 다룹니다.
- 연구 문제
- 우르두는 형태론적으로 복잡한 언어로, 단어가 문맥과 형태소 구조에 따라 의미가 크게 달라집니다.
- 기존의 비문맥적 임베딩 방법(Word2Vec)은 단어를 고정된 벡터로 표현하기 때문에, 다의어 처리와 문맥 의존성 학습에 한계가 있었습니다.
- 이로 인해 우르두와 같은 언어에서 문구 청킹의 정확도가 떨어지는 문제가 있었습니다.
- 연구 기여
- ELMo를 사용하여 단어의 문맥적 의미(contextual meaning)를 반영한 임베딩을 생성했습니다.
- ELMo는 이전과 이후 문맥을 모두 고려하여 동적으로 임베딩을 생성하므로, 다의어 처리와 문맥 학습에서 Word2Vec보다 훨씬 우수한 성능을 보였습니다.
- BiLSTM 모델과 결합하여 문장 내 단어의 IOB 태그를 더 정확히 예측할 수 있었습니다.
- 결과
- 문맥적 임베딩(ELMo)을 도입함으로써 문구 청킹 성능이 개선되었습니다.
- F1 점수에서 Word2Vec(93.9) 대비 ELMo(94.9)가 더 높은 결과를 보여줬으며, 특히 후치사구(PP)와 동사구(VP)에서 뛰어난 성능을 기록했습니다.
- 결론
- 이 논문은 ELMo와 같은 문맥 기반 임베딩 모델이 우르두와 같은 형태론적으로 복잡한 언어에서 비문맥적 모델보다 더 나은 성능을 제공한다는 것을 실증적으로 보여줍니다.
- 이를 통해 다의어 처리, 문맥 학습, 문구 청킹 정확도 향상 등 다양한 문제를 해결했습니다.
보완 이유
- '토큰 임베딩 논문'으로만 정의하기에는 문구 청킹 문제와 IOB 태그 예측이라는 명확한 응용 목표가 드러나야 합니다.
- 다의어 처리와 문맥 학습의 구체적 한계 및 개선 방안(Word2Vec vs. ELMo)을 명확히 제시하여 독자의 이해를 돕도록 보완했습니다.
- 결과(F1 점수)와 성능 개선 사례를 포함하여, 실험 결과와 논문의 기여를 더 구체적으로 전달했습니다.
수정된 내용을 바탕으로 다시 검토해보시면 좋겠습니다! 😊