기존에 진행했던 튜토리얼들이 너무 길어서 짧게 줄여봤습니다.
최대한 설명도 적으면서 저도 나중에 기억할 수 있게 적어볼게요
import os
from setproctitle import setproctitle
setproctitle("")
os.environ["CUDA_VISIBLE_DEVICES"] = "0"항상하는 이름이랑 gpu번호 적기!
import torch
from tqdm import tqdm
import plotly.express as px
import pandas as pd
# Imports for displaying vis in Colab / notebook
torch.set_grad_enabled(False)
# For the most part I'll try to import functions and classes near where they are used
# to make it clear where they come from.
if torch.backends.mps.is_available():
device = "mps"
else:
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Device: {device}")디바이스도 정의해줄게요
이제 사전 학습된 sae랑 모델을 불러줍니다.
from sae_lens.toolkit.pretrained_saes_directory import get_pretrained_saes_directory
from sae_lens import SAE, HookedSAETransformer
model = HookedSAETransformer.from_pretrained("gpt2-small", device = device)
#`cfg` 딕셔너리는 SAE와 함께 반환되며, 이는 SAE를 분석하는 데 유용한 정보를 포함할 수 있기 때문입니다 (예: 활성화 저장소 인스턴스화).
#이는 SAE의 구성 딕셔너리와 동일하지 않으며, HF(Hugging Face) 저장소에 있던 내용을 의미하며, 여기서 SAE 구성 딕셔너리를 추출할 수 있습니다.
# 또한 편의상 HF에 저장된 특징 희소성도 반환됩니다.
sae, cfg_dict, sparsity = SAE.from_pretrained(
release = "gpt2-small-res-jb", # <- Release name
sae_id = "blocks.7.hook_resid_pre", # <- SAE id (not always a hook point!)
device = device
)LLama도 하고 싶고 다른 모델도 해보고 싶은데 영...
print(sae.cfg.__dict__){'architecture': 'standard', 'd_in': 768, 'd_sae': 24576, 'activation_fn_str': 'relu', 'apply_b_dec_to_input': True, 'finetuning_scaling_factor': False, 'context_size': 128, 'model_name': 'gpt2-small', 'hook_name': 'blocks.7.hook_resid_pre', 'hook_layer': 7, 'hook_head_index': None, 'prepend_bos': True, 'dataset_path': 'Skylion007/openwebtext', 'dataset_trust_remote_code': True, 'normalize_activations': 'none', 'dtype': 'torch.float32', 'device': 'cuda', 'sae_lens_training_version': None, 'activation_fn_kwargs': {}, 'neuronpedia_id': 'gpt2-small/7-res-jb', 'model_from_pretrained_kwargs': {'center_writing_weights': True}}
SAE 정보입니다.
768 임베딩 차원을 24576까지 늘렸네요
이제 랜덤한 뉴런 하나 뽑아서 그 뉴런이 활성화 되는 토큰이랑, sparsity 확인해보겠습니다.
from IPython.display import IFrame
feature_idx = torch.randint(0, sae.cfg.d_sae, (1,)).item() # 랜덤 피쳐 뽑기
html_template = "https://neuronpedia.org/{}/{}/{}?embed=true&embedexplanation=true&embedplots=true&embedtest=true&height=300"
def get_dashboard_html(sae_release = "gpt2-small", sae_id="7-res-jb", feature_idx=0):
return html_template.format(sae_release, sae_id, feature_idx)
html = get_dashboard_html(sae_release = "gpt2-small", sae_id="7-res-jb", feature_idx=feature_idx)
IFrame(html, width=1200, height=600)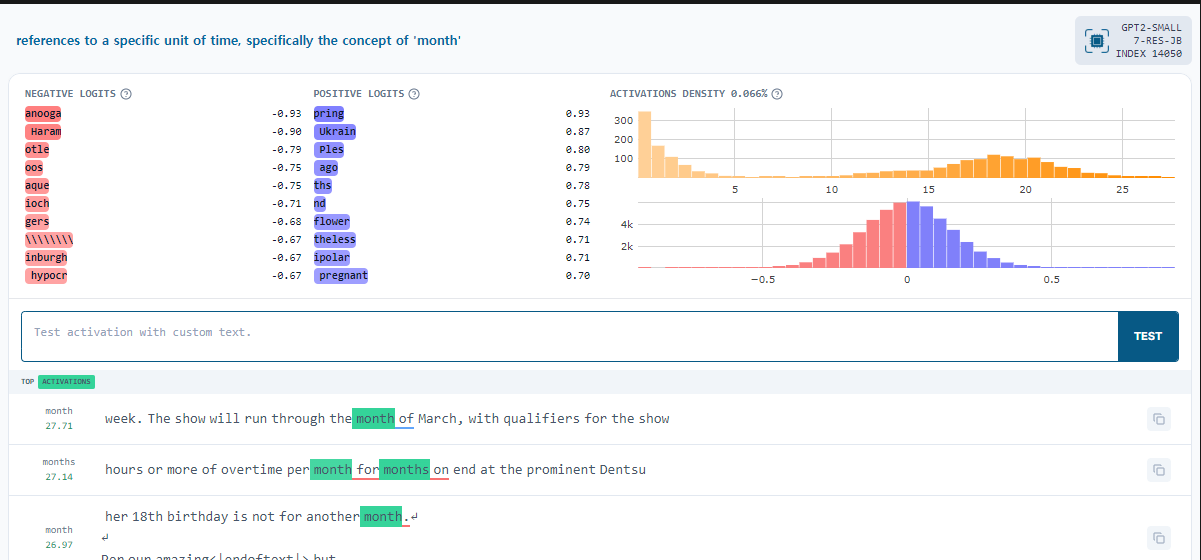
이 특정한 뉴런은 'month'와 밀접한 관련이 있습니다. - 이 상단 문장은 클로드나 gpt가 생성합니다.
단어마다 양수, 음수가 나뉘어져 있고, 얼마나 활성화 되어있는지도 볼 수 있습니다.
아래 문장들은 각각 input으로 들어가서 각각의 token층에서 얼마나 활성화 되어있는지, 활성화가 크게 되어있다면 색이 추가 되고 있습니다.
이 부분은 웹페이지에 등록 되어야 할 수 있는 기능입니다...
이 아래 부분은 특정 주제와 관련 있는 노드를 찾는 방법입니다.
여기도 웹페이지에 등록되어 있으며, 이 기능까지 추가해 놔야 사용할 수 있는 방법입니다.
import requests
url = "https://www.neuronpedia.org/api/explanation/export?modelId=gpt2-small&saeId=7-res-jb"
headers = {"Content-Type": "application/json"}
response = requests.get(url, headers=headers)
# convert to pandas
data = response.json()
explanations_df = pd.DataFrame(data)
# rename index to "feature"
explanations_df.rename(columns={"index": "feature"}, inplace=True)
# explanations_df["feature"] = explanations_df["feature"].astype(int)
explanations_df["description"] = explanations_df["description"].apply(lambda x: x.lower())
explanations_df
음청 많습니다.
bible_features = explanations_df.loc[explanations_df.description.str.contains(" bible")]
bible_features
# Let's get the dashboard for this feature.
html = get_dashboard_html(sae_release = "gpt2-small", sae_id="7-res-jb", feature_idx=bible_features.feature.values[0])
IFrame(html, width=1200, height=600)
여기 성경과 관련있는 뉴런을 찾아서 방금 전과 동일하게 표시한 것입니다.
이제 SAE를 사용해서 저렇게 말고 입력을 통해 feature를 찾아보겠습니다.
from transformer_lens.utils import test_prompt
prompt = "In the beginning, God created the heavens and the"
answer = "earth"
# Show that the model can confidently predict the next token.
test_prompt(prompt, answer, model)
이 것은 모델이 earth를 출력할 확률과, 각각의 가장 높은 확률을 가지는 토큰들입니다.
이제 저 프롬포트를 가지고 모델을 돌려서 sae에서는 어떻게 되는지 확인해 보도록 하겠습니다.
# hooked SAE Transformer will enable us to get the feature activations from the SAE
_, cache = model.run_with_cache_with_saes(prompt, saes=[sae])
print([(k, v.shape) for k,v in cache.items() if "sae" in k])
# note there were 11 tokens in our prompt, the residual stream dimension is 768, and the number of SAE features is 768[('blocks.7.hook_resid_pre.hook_sae_input', torch.Size([1, 11, 768])), ('blocks.7.hook_resid_pre.hook_sae_acts_pre', torch.Size([1, 11, 24576])), ('blocks.7.hook_resid_pre.hook_sae_acts_post', torch.Size([1, 11, 24576])), ('blocks.7.hook_resid_pre.hook_sae_recons', torch.Size([1, 11, 768])), ('blocks.7.hook_resid_pre.hook_sae_output', torch.Size([1, 11, 768]))]
sae의 구조입니다. 바로 다음 코드에서 사용됩니다.
# 이제 레이어 8에서 마지막 토큰 위치에서 어떤 기능들이 활성화되었는지 살펴보겠습니다.
# 선 위에 마우스를 올리면 기능 ID를 확인할 수 있습니다.
px.line(
cache['blocks.7.hook_resid_pre.hook_sae_acts_post'][0, -1, :].cpu().numpy(),
title="Feature activations at the final token position",
labels={"index": "Feature", "value": "Activation"},
).show()
# let's print the top 5 features and how much they fired
vals, inds = torch.topk(cache['blocks.7.hook_resid_pre.hook_sae_acts_post'][0, -1, :], 2)
for val, ind in zip(vals, inds):
print(f"Feature {ind} fired {val:.2f}")
html = get_dashboard_html(sae_release = "gpt2-small", sae_id="7-res-jb", feature_idx=ind)
display(IFrame(html, width=1200, height=300))
특정 feature(뉴런)에서 강하게 활성화 되는 것을 볼 수 있습니다.
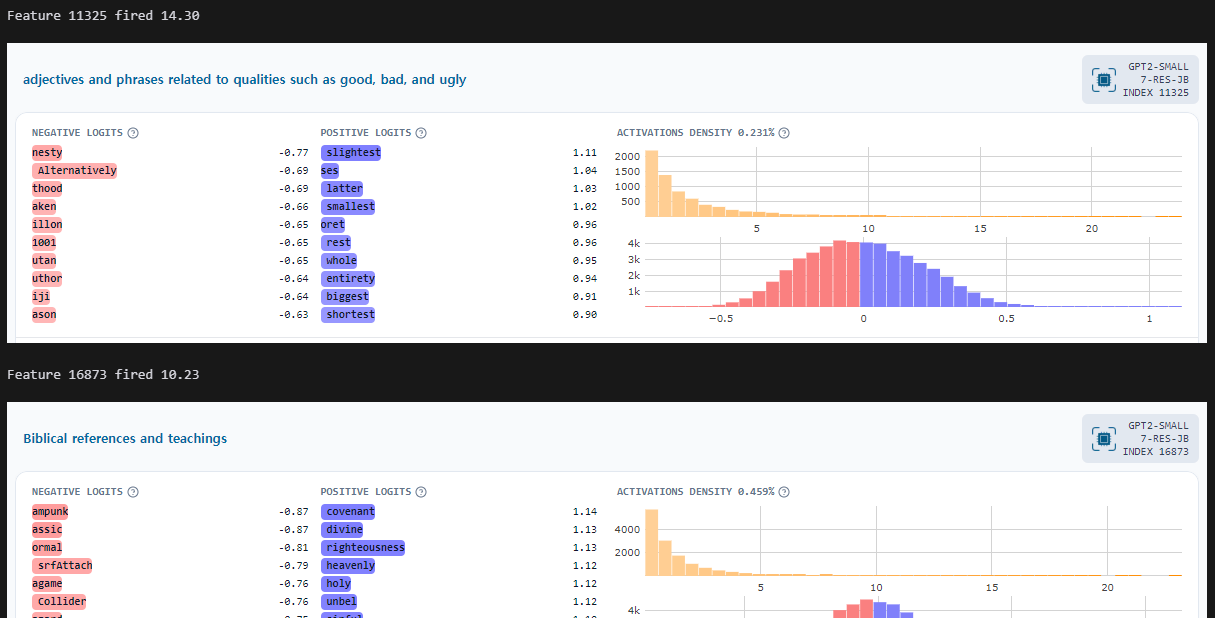
두개의 특징만 뽑아서 보면 이렇습니다.
성경에 대한 특징이 강하게 살아나는 것을 볼 수 있습니다.
이제 두 프롬포트를 넣고, 차이를 확인해 보겠습니다.
prompt = ["In the beginning, God created the heavens and the", "In the beginning, God created the cat and the"]
_, cache = model.run_with_cache_with_saes(prompt, saes=[sae])
print([(k, v.shape) for k,v in cache.items() if "sae" in k])
feature_activation_df = pd.DataFrame(cache['blocks.7.hook_resid_pre.hook_sae_acts_post'][0, -1, :].cpu().numpy(),
index = [f"feature_{i}" for i in range(sae.cfg.d_sae)],
)
feature_activation_df.columns = ["heavens_and_the"]
feature_activation_df["cat_and_the"] = cache['blocks.7.hook_resid_pre.hook_sae_acts_post'][1, -1, :].cpu().numpy()
feature_activation_df["diff"]= feature_activation_df["heavens_and_the"] - feature_activation_df["cat_and_the"]
fig = px.line(
feature_activation_df,
title="Feature activations for the prompt",
labels={"index": "Feature", "value": "Activation"},
)
# hide the x-ticks
fig.update_xaxes(showticklabels=False)
fig.show()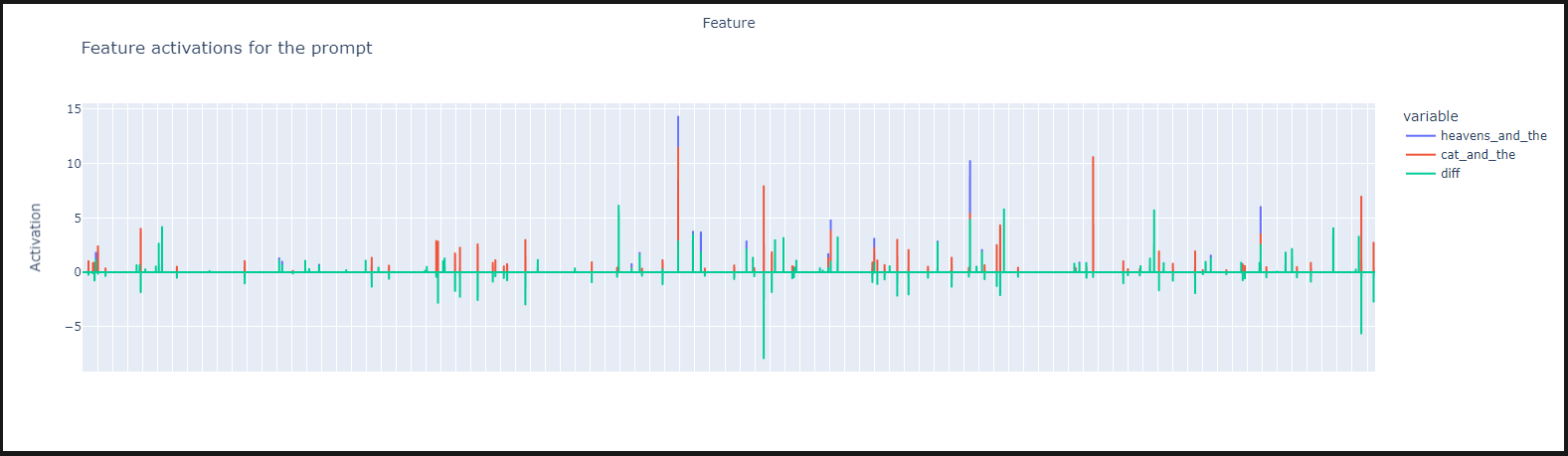
천국이 나오는 것과, 고양이가 나오는 것은 확실히 다른 것을 볼 수 있습니다.
# let's look at the biggest features in terms of absolute difference
diff = cache['blocks.7.hook_resid_pre.hook_sae_acts_post'][1, -1, :].cpu() - cache['blocks.7.hook_resid_pre.hook_sae_acts_post'][0, -1, :].cpu()
vals, inds = torch.topk(torch.abs(diff), 2)
for val, ind in zip(vals, inds):
print(f"Feature {ind} had a difference of {val:.2f}")
html = get_dashboard_html(sae_release = "gpt2-small", sae_id="7-res-jb", feature_idx=ind)
display(IFrame(html, width=1200, height=300))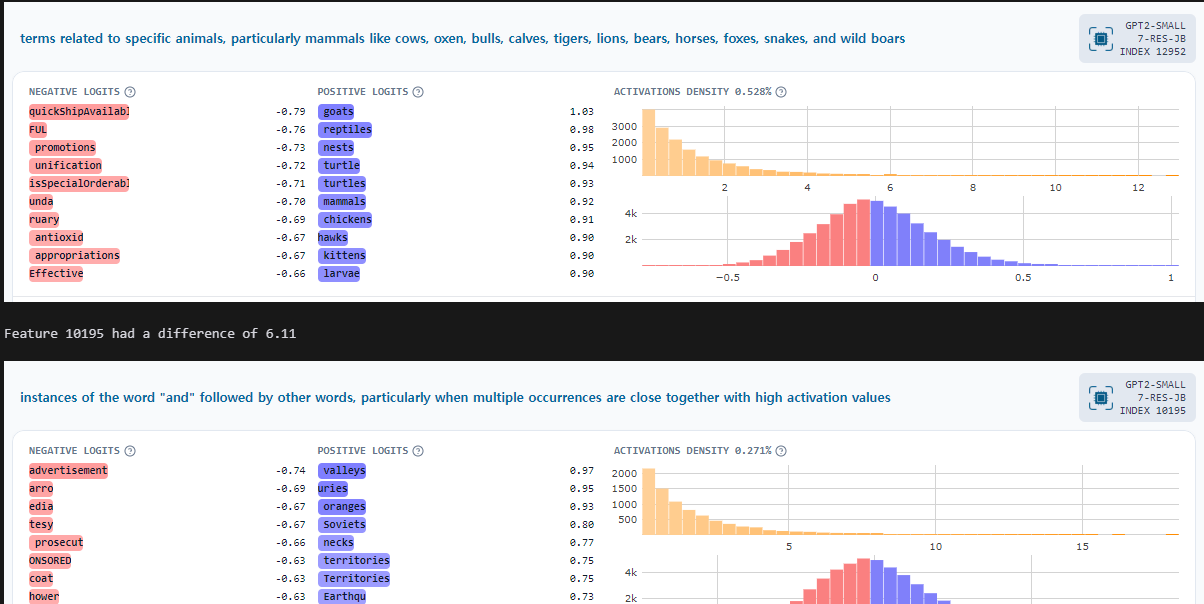
차이가 가장 큰 부분이 동물과 관련된 곳이라는 것을 확인할 수 있습니다.
이제 이렇게 프롬포트로 찾는 것 말고, 특정 뉴런을 지정한 뒤 어떤 token에 강하게 발현되는지 확인해 보겠습니다.
from sae_lens import ActivationsStore
# a convenient way to instantiate an activation store is to use the from_sae method
activation_store = ActivationsStore.from_sae(
model=model,
sae=sae,
streaming=True,
# fairly conservative parameters here so can use same for larger
# models without running out of memory.
store_batch_size_prompts=8,
train_batch_size_tokens=4096,
n_batches_in_buffer=32,
device=device,
)
def list_flatten(nested_list):
return [x for y in nested_list for x in y]
# A very handy function Neel wrote to get context around a feature activation
def make_token_df(tokens, len_prefix=5, len_suffix=3, model = model):
str_tokens = [model.to_str_tokens(t) for t in tokens]
unique_token = [[f"{s}/{i}" for i, s in enumerate(str_tok)] for str_tok in str_tokens]
context = []
prompt = []
pos = []
label = []
for b in range(tokens.shape[0]):
for p in range(tokens.shape[1]):
prefix = "".join(str_tokens[b][max(0, p-len_prefix):p])
if p==tokens.shape[1]-1:
suffix = ""
else:
suffix = "".join(str_tokens[b][p+1:min(tokens.shape[1]-1, p+1+len_suffix)])
current = str_tokens[b][p]
context.append(f"{prefix}|{current}|{suffix}")
prompt.append(b)
pos.append(p)
label.append(f"{b}/{p}")
# print(len(batch), len(pos), len(context), len(label))
return pd.DataFrame(dict(
str_tokens=list_flatten(str_tokens),
unique_token=list_flatten(unique_token),
context=context,
prompt=prompt,
pos=pos,
label=label,
))
# finding max activating examples is a bit harder. To do this we need to calculate feature activations for a large number of tokens
#feature_list = torch.randint(0, sae.cfg.d_sae, (100,))
feature_list = torch.tensor([1])
examples_found = 0
all_fired_tokens = []
all_feature_acts = []
all_reconstructions = []
all_token_dfs = []
total_batches = 300
batch_size_prompts = activation_store.store_batch_size_prompts
batch_size_tokens = activation_store.context_size * batch_size_prompts
pbar = tqdm(range(total_batches))
for i in pbar:
tokens = activation_store.get_batch_tokens()
tokens_df = make_token_df(tokens)
tokens_df["batch"] = i
flat_tokens = tokens.flatten()
_, cache = model.run_with_cache(tokens, stop_at_layer = sae.cfg.hook_layer + 1, names_filter = [sae.cfg.hook_name])
sae_in = cache[sae.cfg.hook_name]
feature_acts = sae.encode(sae_in).squeeze()
feature_acts = feature_acts.flatten(0,1)
fired_mask = (feature_acts[:, feature_list]).sum(dim=-1) > 0
fired_tokens = model.to_str_tokens(flat_tokens[fired_mask])
reconstruction = feature_acts[fired_mask][:, feature_list] @ sae.W_dec[feature_list]
token_df = tokens_df.iloc[fired_mask.cpu().nonzero().flatten().numpy()]
all_token_dfs.append(token_df)
all_feature_acts.append(feature_acts[fired_mask][:, feature_list])
all_fired_tokens.append(fired_tokens)
all_reconstructions.append(reconstruction)
examples_found += len(fired_tokens)
# print(f"Examples found: {examples_found}")
# update description
pbar.set_description(f"Examples found: {examples_found}")
# flatten the list of lists
all_token_dfs = pd.concat(all_token_dfs)
all_fired_tokens = list_flatten(all_fired_tokens)
all_reconstructions = torch.cat(all_reconstructions)
all_feature_acts = torch.cat(all_feature_acts)300 배치를 활용하여 가장 활성화 되는 토큰들을 찾습니다.
저는 1번 뉴런을 확인했습니다.
feature_acts_df = pd.DataFrame(all_feature_acts.detach().cpu().numpy(), columns = [f"feature_{i}" for i in feature_list])
feature_acts_df.shape
feature_idx = 0
# get non-zero activations
all_positive_acts = all_feature_acts[all_feature_acts[:, feature_idx] > 0][:, feature_idx].detach()
prop_positive_activations = 100*len(all_positive_acts) / (total_batches*batch_size_tokens)
px.histogram(
all_positive_acts.cpu(),
nbins=50,
title=f"Histogram of positive activations - {prop_positive_activations:.3f}% of activations were positive",
labels={"value": "Activation"},
width=800,)
특정 부분이 강하게 활성화되고 나머지는 0 주변에 몰려있는 것을 확인할 수 있습니다.
top_10_activations = feature_acts_df.sort_values(f"feature_{feature_list[0]}", ascending=False).head(80)
all_token_dfs.iloc[top_10_activations.index] # TODO: double check this is working correctly
확인해보면 법과 관련된 토큰들이 강하게 활성화 된것을 볼 수 있습니다.
위치랑 배치, 문맥까지 주기 때문에 좀 더 확실한 것 같네요
print(f"Shape of the decoder weights {sae.W_dec.shape})")
print(f"Shape of the model unembed {model.W_U.shape}")
projection_matrix = sae.W_dec @ model.W_U
print(f"Shape of the projection matrix {projection_matrix.shape}")
# then we take the top_k tokens per feature and decode them
top_k = 10
# let's do this for 100 random features
_, top_k_tokens = torch.topk(projection_matrix[feature_list], top_k, dim=1)
feature_df = pd.DataFrame(top_k_tokens.cpu().numpy(), index = [f"feature_{i}" for i in feature_list]).T
feature_df.index = [f"token_{i}" for i in range(top_k)]
feature_df.applymap(lambda x: model.tokenizer.decode(x))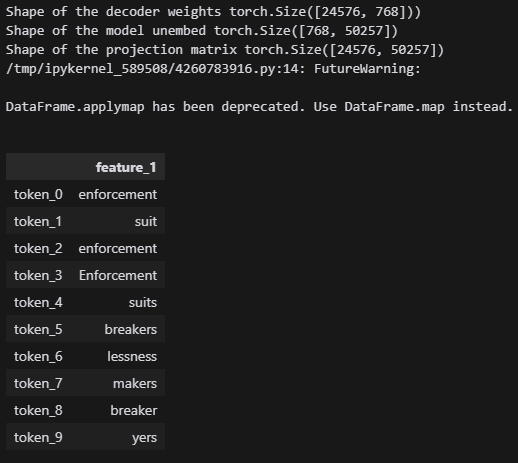
여기도 law는 없지만 법률과 같은 주제가 동일하게 있는 것을 확인할 수 있습니다.
이제 이 아래 부분은 확인한 뉴런을 강하게, 혹은 지워서 출력을 확인하는 부분입니다.
from tqdm import tqdm
from functools import partial
def find_max_activation(model, sae, activation_store, feature_idx, num_batches=100):
'''
Find the maximum activation for a given feature index. This is useful for
calibrating the right amount of the feature to add.
'''
max_activation = 0.0
pbar = tqdm(range(num_batches))
for _ in pbar:
tokens = activation_store.get_batch_tokens()
_, cache = model.run_with_cache(
tokens,
stop_at_layer=sae.cfg.hook_layer + 1,
names_filter=[sae.cfg.hook_name]
)
sae_in = cache[sae.cfg.hook_name]
feature_acts = sae.encode(sae_in).squeeze()
feature_acts = feature_acts.flatten(0, 1)
batch_max_activation = feature_acts[:, feature_idx].max().item()
max_activation = max(max_activation, batch_max_activation)
pbar.set_description(f"Max activation: {max_activation:.4f}")
return max_activation
def steering(activations, hook, steering_strength=1.0, steering_vector=None, max_act=1.0):
# Note if the feature fires anyway, we'd be adding to that here.
return activations + max_act * steering_strength * steering_vector
def generate_with_steering(model, sae, prompt, steering_feature, max_act, steering_strength=1.0, max_new_tokens=95):
input_ids = model.to_tokens(prompt, prepend_bos=sae.cfg.prepend_bos)
steering_vector = sae.W_dec[steering_feature].to(model.cfg.device)
steering_hook = partial(
steering,
steering_vector=steering_vector,
steering_strength=steering_strength,
max_act=max_act
)
# standard transformerlens syntax for a hook context for generation
with model.hooks(fwd_hooks=[(sae.cfg.hook_name, steering_hook)]):
output = model.generate(
input_ids,
max_new_tokens=max_new_tokens,
temperature=0.7,
top_p=0.9,
stop_at_eos = False if device == "mps" else True,
prepend_bos = sae.cfg.prepend_bos,
)
return model.tokenizer.decode(output[0])
# Choose a feature to steer
steering_feature = steering_feature = 20115 # Choose a feature to steer towards
# 철학적인 출력을 자주 출력한다.
# Find the maximum activation for this feature
max_act = find_max_activation(model, sae, activation_store, steering_feature)
print(f"Maximum activation for feature {steering_feature}: {max_act:.4f}")
# note we could also get the max activation from Neuronpedia (https://www.neuronpedia.org/api-doc#tag/lookup/GET/api/feature/{modelId}/{layer}/{index})
# Generate text without steering for comparison
prompt = "Once upon a time"
normal_text = model.generate(
prompt,
max_new_tokens=95,
stop_at_eos = False if device == "mps" else True,
prepend_bos = sae.cfg.prepend_bos,
)
print("\nNormal text (without steering):")
print(normal_text)Once upon a time, square footage was considered the "rich encyclopedic knowledge of the nation." Seward Labbir was much excited about exposing problems with postal paper applications, but the 18th-century author in question, Samuel Gregg, did his very best to show early technological systems as ancient as they existed — block printers, un-rollable "alphonochranes" sophisticated enough to handle 15 to 20 sheets of paper. Counterfeit ineffective type transit stickers, patent
기존의 출력입니다.
# Generate text with steering
steered_text = generate_with_steering(model, sae, prompt, steering_feature, max_act, steering_strength=2.0)
print("Steered text:")
print(steered_text)<|endoftext|>Once upon a time, the creator of the world's most powerful weapon, the mighty Asmodeus, used the power of the universe's many creatures to make his own. One day, he set about destroying the world, and to do so he must have the power to be true to his own.
In the pages of his works, Asmodeus does not need to make a living, but rather that he can live in the world he created. Asmodeus is born of
문장 느낌이 많이 바뀐것을 확인할 수 있습니다.
사이트에 올라간 모델은 이렇게도 활용이 가능합니다.
import requests
import numpy as np
url = "https://www.neuronpedia.org/api/steer"
payload = {
# "prompt": "A knight in shining",
# "prompt": "He had to fight back in self-",
"prompt": "In the middle of the universe is the galactic",
# "prompt": "Oh no. We're running on empty. Its time to fill up the car with",
# "prompt": "Sure, I'm happy to pay. I don't have any cash on me but let me write you a",
"modelId": "gpt2-small",
"features": [
{
"modelId": "gpt2-small",
"layer": "7-res-jb",
"index": 6770,
"strength": 8
}
],
"temperature": 0.2,
"n_tokens": 2,
"freq_penalty": 1,
"seed": np.random.randint(100),
"strength_multiplier": 4
}
headers = {"Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print(response.json()){'STEERED': 'In the middle of the universe is the galactic centre of', 'DEFAULT': 'In the middle of the universe is the galactic center of', 'id': '_', 'shareUrl': 'https://www.neuronpedia.org/steer/clyrdsvvc000dxoy7qirsc2yr', 'limit': '59'}
특정 feature 제거하기
from transformer_lens.utils import test_prompt
from functools import partial
def test_prompt_with_ablation(model, sae, prompt, answer, ablation_features):
def ablate_feature_hook(feature_activations, hook, feature_ids, position = None):
if position is None:
feature_activations[:,:,feature_ids] = 0
else:
feature_activations[:,position,feature_ids] = 0
return feature_activations
ablation_hook = partial(ablate_feature_hook, feature_ids = ablation_features)
model.add_sae(sae)
hook_point = sae.cfg.hook_name + '.hook_sae_acts_post'
model.add_hook(hook_point, ablation_hook, "fwd")
test_prompt(prompt, answer, model)
model.reset_hooks()
model.reset_saes()
# Example usage in a notebook:
# Assume model and sae are already defined
# Choose a feature to ablate
model.reset_hooks(including_permanent=True)
prompt = "In the beginning, God created the heavens and the"
answer = "earth"
test_prompt(prompt, answer, model)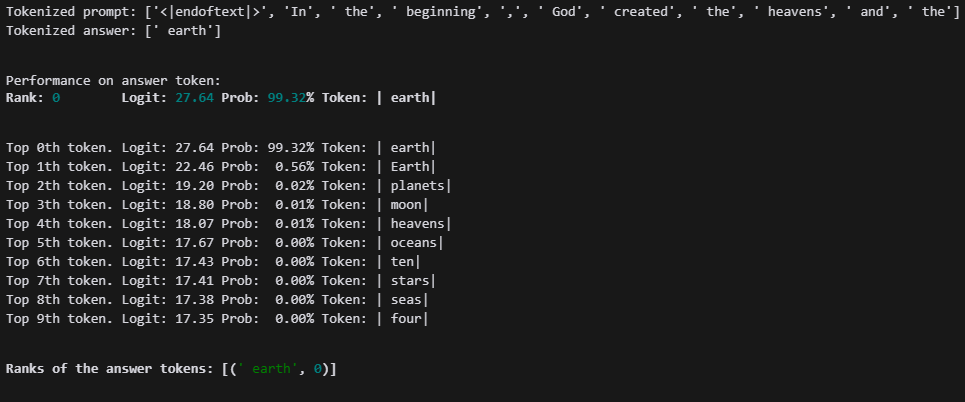
여긴 기본 출력 부분이다.
# Generate text with feature ablation
print("Test Prompt with feature ablation and no error term")
ablation_feature = 16873 # Replace with any feature index you're interested in. We use the religion feature
sae.use_error_term = False
test_prompt_with_ablation(model, sae, prompt, answer, ablation_feature)
print("Test Prompt with feature ablation and error term")
ablation_feature = 16873 # Replace with any feature index you're interested in. We use the religion feature
sae.use_error_term = True
test_prompt_with_ablation(model, sae, prompt, answer, ablation_feature)
첫번째는 16873번 뉴런을 지우면서, 에러에 대한 보정을 하지 않은 것이고,
두 번째는 뉴런을 지우고, 그 공간에 대한 보정을 진행한 것이다.
from dataclasses import dataclass
from functools import partial
from typing import Any, Literal, NamedTuple, Callable
import torch
from sae_lens import SAE
from transformer_lens import HookedTransformer
from transformer_lens.hook_points import HookPoint
class SaeReconstructionCache(NamedTuple):
sae_in: torch.Tensor
feature_acts: torch.Tensor
sae_out: torch.Tensor
sae_error: torch.Tensor
def track_grad(tensor: torch.Tensor) -> None:
"""wrapper around requires_grad and retain_grad"""
tensor.requires_grad_(True)
tensor.retain_grad()
@dataclass
class ApplySaesAndRunOutput:
model_output: torch.Tensor
model_activations: dict[str, torch.Tensor]
sae_activations: dict[str, SaeReconstructionCache]
def zero_grad(self) -> None:
"""Helper to zero grad all tensors in this object."""
self.model_output.grad = None
for act in self.model_activations.values():
act.grad = None
for cache in self.sae_activations.values():
cache.sae_in.grad = None
cache.feature_acts.grad = None
cache.sae_out.grad = None
cache.sae_error.grad = None
def apply_saes_and_run(
model: HookedTransformer,
saes: dict[str, SAE],
input: Any,
include_error_term: bool = True,
track_model_hooks: list[str] | None = None,
return_type: Literal["logits", "loss"] = "logits",
track_grads: bool = False,
) -> ApplySaesAndRunOutput:
"""
Apply the SAEs to the model at the specific hook points, and run the model.
By default, this will include a SAE error term which guarantees that the SAE
will not affect model output. This function is designed to work correctly with
backprop as well, so it can be used for gradient-based feature attribution.
Args:
model: the model to run
saes: the SAEs to apply
input: the input to the model
include_error_term: whether to include the SAE error term to ensure the SAE doesn't affect model output. Default True
track_model_hooks: a list of hook points to record the activations and gradients. Default None
return_type: this is passed to the model.run_with_hooks function. Default "logits"
track_grads: whether to track gradients. Default False
"""
fwd_hooks = []
bwd_hooks = []
sae_activations: dict[str, SaeReconstructionCache] = {}
model_activations: dict[str, torch.Tensor] = {}
# this hook just track the SAE input, output, features, and error. If `track_grads=True`, it also ensures
# that requires_grad is set to True and retain_grad is called for intermediate values.
def reconstruction_hook(sae_in: torch.Tensor, hook: HookPoint, hook_point: str): # noqa: ARG001
sae = saes[hook_point]
feature_acts = sae.encode(sae_in)
sae_out = sae.decode(feature_acts)
sae_error = (sae_in - sae_out).detach().clone()
if track_grads:
track_grad(sae_error)
track_grad(sae_out)
track_grad(feature_acts)
track_grad(sae_in)
sae_activations[hook_point] = SaeReconstructionCache(
sae_in=sae_in,
feature_acts=feature_acts,
sae_out=sae_out,
sae_error=sae_error,
)
if include_error_term:
return sae_out + sae_error
return sae_out
def sae_bwd_hook(output_grads: torch.Tensor, hook: HookPoint): # noqa: ARG001
# this just passes the output grads to the input, so the SAE gets the same grads despite the error term hackery
return (output_grads,)
# this hook just records model activations, and ensures that intermediate activations have gradient tracking turned on if needed
def tracking_hook(hook_input: torch.Tensor, hook: HookPoint, hook_point: str): # noqa: ARG001
model_activations[hook_point] = hook_input
if track_grads:
track_grad(hook_input)
return hook_input
for hook_point in saes.keys():
fwd_hooks.append(
(hook_point, partial(reconstruction_hook, hook_point=hook_point))
)
bwd_hooks.append((hook_point, sae_bwd_hook))
for hook_point in track_model_hooks or []:
fwd_hooks.append((hook_point, partial(tracking_hook, hook_point=hook_point)))
# now, just run the model while applying the hooks
with model.hooks(fwd_hooks=fwd_hooks, bwd_hooks=bwd_hooks):
model_output = model(input, return_type=return_type)
return ApplySaesAndRunOutput(
model_output=model_output,
model_activations=model_activations,
sae_activations=sae_activations,
)이쪽이 제일 어렵습니다....
잘 모르겠기도 하고,.....
GPT의 설명으로 가게씃ㅂ니다...
이 코드에서는 SAE(Sparse Autoencoder)를 Transformer 모델에 적용한 후, 모델의 출력과 그 과정에서의 중간 활성화(activations) 및 SAE 결과를 추적하는 과정을 수행합니다. 이 함수는 특히 SAE(희소 오토인코더)를 사용하여 모델의 특정 부분을 분석하거나 수정하고, 그 과정에서 에러 항(term)을 사용해 모델의 출력을 보정하는 데 중점을 두고 있습니다. 주요 작업을 설명하면 다음과 같습니다.
1. SAE 적용 및 실행 함수: apply_saes_and_run
이 함수는 입력 데이터를 받아서 Transformer 모델에 적용하고, 주어진 SAEs(Sparse Autoencoders)를 특정 모델의 hook 포인트에 적용한 후 모델을 실행합니다. 함수는 모델 출력뿐만 아니라, 중간 활성화값, 그리고 SAE의 입력, 출력, 특징(활성화), 에러를 기록하여 나중에 분석할 수 있도록 해줍니다.
2. 핵심 개념
- SAE(Sparse Autoencoder): 특정 레이어나 기능(feature)을 학습하여 모델의 활성화값을 인코딩하고 디코딩하는 역할을 합니다. 이 과정에서 인코딩된 특징과 원래 값의 차이를 에러로 계산하고, 이를 통해 모델에 영향을 미치지 않도록 조정합니다.
- HookedTransformer: Transformer 모델의 특정 레이어 또는 포인트에 hook을 걸어, 중간 활성화 값 또는 입력/출력을 추적하거나 수정할 수 있게 해줍니다.
3. 구체적인 과정 설명
- SAE 및 모델의 활성화 추적 (Reconstruction Hook):
- 각 SAE를 Transformer 모델의 특정 hook 포인트에 적용합니다.
- SAE는 입력값(sae_in)을 인코딩하여 특징값(feature_acts)을 추출하고, 이를 다시 디코딩하여 출력값(sae_out)을 만듭니다.
- 또한, 디코딩된 출력과 원래 입력값의 차이를 에러 값(sae_error)으로 계산합니다. 이 에러 값은 SAE가 모델의 출력을 수정하지 않도록 하는 데 사용됩니다.
- track_grads가 활성화된 경우, 중간값에 대해 gradient tracking을 설정합니다.
- 에러 항 사용 (include_error_term):
- 이 옵션이 True일 때, SAE 출력에 에러 값(sae_error)을 더하여, SAE가 모델 출력에 영향을 미치지 않도록 보정합니다.
- False일 때는 SAE 출력만 반환하며, 모델 출력이 SAE의 영향을 받을 수 있습니다.
- 모델 활성화 기록 (Tracking Hook):
- 모델의 중간 활성화를 기록하는 역할을 합니다. 이를 통해 모델이 입력 데이터를 처리하는 중간 과정에서 어떤 활성화값이 발생하는지를 추적할 수 있습니다.
- 이 또한 track_grads가 True일 경우, 중간 활성화에 대한 gradient를 추적합니다.
- 모델 실행:
- with model.hooks(fwd_hooks=fwd_hooks, bwd_hooks=bwd_hooks) 블록을 사용하여, 모델을 실행할 때 각 hook 포인트에 설정된 함수들이 실행되도록 합니다.
- 모델이 실행되고, 결과적으로 SAE와 모델의 중간 활성화값, 그리고 최종 출력이 기록됩니다.
4. 결과 반환:
- 함수는 ApplySaesAndRunOutput 객체를 반환하며, 여기에는 모델 출력, 모델의 중간 활성화값, SAE의 활성화값이 저장됩니다.
- 이 결과를 통해 사용자는 SAE가 적용된 모델의 동작을 분석할 수 있습니다.
5. 코드 목적 요약:
- 이 코드는 Transformer 모델의 특정 레이어에 SAE(희소 오토인코더)를 적용하여 모델의 중간 활성화값을 분석하거나 수정하는 작업을 수행합니다.
- 에러 항 사용 여부에 따라 모델 출력에 영향을 미치지 않도록 하거나, SAE가 모델의 출력에 영향을 줄 수 있도록 설정할 수 있습니다.
- 또한, gradient 추적을 통해 중간 활성화 값들의 변화나 학습 과정에서의 기여도를 추적할 수 있는 기능을 포함하고 있습니다.
이러한 과정을 통해, 모델이 데이터를 처리하는 도중에 발생하는 중요한 정보를 더 정교하게 분석하거나, 특정 기능(feature)을 조정하여 모델의 동작을 실험할 수 있습니다.
from dataclasses import dataclass
from transformer_lens.hook_points import HookPoint
from dataclasses import dataclass
from functools import partial
from typing import Any, Literal, NamedTuple
import torch
from sae_lens import SAE
from transformer_lens import HookedTransformer
from transformer_lens.hook_points import HookPoint
EPS = 1e-8
torch.set_grad_enabled(True)
@dataclass
class AttributionGrads:
metric: torch.Tensor
model_output: torch.Tensor
model_activations: dict[str, torch.Tensor]
sae_activations: dict[str, SaeReconstructionCache]
@dataclass
class Attribution:
model_attributions: dict[str, torch.Tensor]
model_activations: dict[str, torch.Tensor]
model_grads: dict[str, torch.Tensor]
sae_feature_attributions: dict[str, torch.Tensor]
sae_feature_activations: dict[str, torch.Tensor]
sae_feature_grads: dict[str, torch.Tensor]
sae_errors_attribution_proportion: dict[str, float]
def calculate_attribution_grads(
model: HookedSAETransformer,
prompt: str,
metric_fn: Callable[[torch.Tensor], torch.Tensor],
track_hook_points: list[str] | None = None,
include_saes: dict[str, SAE] | None = None,
return_logits: bool = True,
include_error_term: bool = True,
) -> AttributionGrads:
"""
Wrapper around apply_saes_and_run that calculates gradients wrt to the metric_fn.
Tracks grads for both SAE feature and model neurons, and returns them in a structured format.
"""
output = apply_saes_and_run(
model,
saes=include_saes or {},
input=prompt,
return_type="logits" if return_logits else "loss",
track_model_hooks=track_hook_points,
include_error_term=include_error_term,
track_grads=True,
)
metric = metric_fn(output.model_output)
output.zero_grad()
metric.backward()
return AttributionGrads(
metric=metric,
model_output=output.model_output,
model_activations=output.model_activations,
sae_activations=output.sae_activations,
)
def calculate_feature_attribution(
model: HookedSAETransformer,
input: Any,
metric_fn: Callable[[torch.Tensor], torch.Tensor],
track_hook_points: list[str] | None = None,
include_saes: dict[str, SAE] | None = None,
return_logits: bool = True,
include_error_term: bool = True,
) -> Attribution:
"""
Calculate feature attribution for SAE features and model neurons following
the procedure in https://transformer-circuits.pub/2024/march-update/index.html#feature-heads.
This include the SAE error term by default, so inserting the SAE into the calculation is
guaranteed to not affect the model output. This can be disabled by setting `include_error_term=False`.
Args:
model: The model to calculate feature attribution for.
input: The input to the model.
metric_fn: A function that takes the model output and returns a scalar metric.
track_hook_points: A list of model hook points to track activations for, if desired
include_saes: A dictionary of SAEs to include in the calculation. The key is the hook point to apply the SAE to.
return_logits: Whether to return the model logits or loss. This is passed to TLens, so should match whatever the metric_fn expects (probably logits)
include_error_term: Whether to include the SAE error term in the calculation. This is recommended, as it ensures that the SAE will not affecting the model output.
"""
# first, calculate gradients wrt to the metric_fn.
# these will be multiplied with the activation values to get the attributions
outputs_with_grads = calculate_attribution_grads(
model,
input,
metric_fn,
track_hook_points,
include_saes=include_saes,
return_logits=return_logits,
include_error_term=include_error_term,
)
model_attributions = {}
model_activations = {}
model_grads = {}
sae_feature_attributions = {}
sae_feature_activations = {}
sae_feature_grads = {}
sae_error_proportions = {}
# this code is long, but all it's doing is multiplying the grads by the activations
# and recording grads, acts, and attributions in dictionaries to return to the user
with torch.no_grad():
for name, act in outputs_with_grads.model_activations.items():
assert act.grad is not None
raw_activation = act.detach().clone()
model_attributions[name] = (act.grad * raw_activation).detach().clone()
model_activations[name] = raw_activation
model_grads[name] = act.grad.detach().clone()
for name, act in outputs_with_grads.sae_activations.items():
assert act.feature_acts.grad is not None
assert act.sae_out.grad is not None
raw_activation = act.feature_acts.detach().clone()
sae_feature_attributions[name] = (
(act.feature_acts.grad * raw_activation).detach().clone()
)
sae_feature_activations[name] = raw_activation
sae_feature_grads[name] = act.feature_acts.grad.detach().clone()
if include_error_term:
assert act.sae_error.grad is not None
error_grad_norm = act.sae_error.grad.norm().item()
else:
error_grad_norm = 0
sae_out_norm = act.sae_out.grad.norm().item()
sae_error_proportions[name] = error_grad_norm / (
sae_out_norm + error_grad_norm + EPS
)
return Attribution(
model_attributions=model_attributions,
model_activations=model_activations,
model_grads=model_grads,
sae_feature_attributions=sae_feature_attributions,
sae_feature_activations=sae_feature_activations,
sae_feature_grads=sae_feature_grads,
sae_errors_attribution_proportion=sae_error_proportions,
)
# prompt = " Tiger Woods plays the sport of"
# pos_token = model.tokenizer.encode(" golf")[0]
prompt = "In the beginning, God created the heavens and the"
pos_token = model.tokenizer.encode(" earth")
neg_token = model.tokenizer.encode(" sky")
def metric_fn(logits: torch.tensor, pos_token: torch.tensor =pos_token, neg_token: torch.Tensor=neg_token) -> torch.Tensor:
return logits[0,-1,pos_token] - logits[0,-1,neg_token]
feature_attribution_df = calculate_feature_attribution(
input = prompt,
model = model,
metric_fn = metric_fn,
include_saes={sae.cfg.hook_name: sae},
include_error_term=True,
return_logits=True,
)
여기도 잘 모르겠어서....
이 코드에서는*SAE(Sparse Autoencoder)와 Transformer 모델을 활용하여, 특정 프롬프트에 대한 기능(feature) 및 활성화값의 중요도(Attribution)를 계산합니다. 주로 모델의 중간 활성화 값과 그에 대한 그라디언트(gradient)를 기반으로 하여, 모델 및 SAE의 기능들이 주어진 입력(prompt)에 어떤 영향을 미치는지를 분석하는 목적을 가지고 있습니다.
핵심 작업 설명
- Attribution(기능 기여도)와 Gradient(그라디언트)를 계산하여, 모델이 특정 입력에 대해 어떤 기능(또는 뉴런)이 얼마나 중요한 역할을 하는지 파악합니다.
- SAE를 모델의 특정 레이어에 삽입하여, 특정 기능(feature)이 모델의 출력에 어떤 영향을 미치는지 확인합니다.
- 에러 항(term)을 사용하여, SAE가 모델의 결과에 미치는 영향을 보정합니다. 이렇게 하면 SAE가 모델의 성능을 해치지 않으면서 기능 기여도를 계산할 수 있습니다.
주요 함수 및 클래스 설명
- AttributionGrads 클래스:
- metric: 모델 출력에서 사용자가 정의한 메트릭 함수(예: 긍정 토큰과 부정 토큰 간의 차이)를 기반으로 계산된 값입니다.
- model_output: 모델의 최종 출력 (로짓 또는 손실 값).
- model_activations: 모델의 중간 레이어에서 발생하는 활성화값.
- sae_activations: SAE에서 추출된 활성화값(입력, 출력, 에러 등).
- Attribution 클래스:
- 모델과 SAE의 기여도 및 그라디언트를 저장합니다. 이를 통해 각 뉴런이나 기능이 출력에 얼마나 기여했는지 알 수 있습니다.
- model_attributions: 모델 뉴런들이 출력에 얼마나 기여했는지를 기록.
- sae_feature_attributions: SAE 기능들이 출력에 미친 기여도.
- sae_errors_attribution_proportion: SAE의 에러 항이 모델 출력에 미친 비율.
- calculate_attribution_grads 함수:
- 모델과 SAE에서 발생한 활성화값 및 그라디언트를 기반으로 기능 기여도를 계산합니다.
- metric_fn은 모델 출력에 대해 사용자 정의 메트릭(예: 긍정 토큰과 부정 토큰 간의 차이)을 계산하는 함수입니다.
- 이 함수는 apply_saes_and_run 함수를 사용하여 모델과 SAE를 실행한 후, 그라디언트(기울기)를 계산하고 기록합니다.
- calculate_feature_attribution 함수:
- SAE 및 모델 뉴런의 기능 기여도를 계산하는 핵심 함수입니다.
- 그라디언트와 활성화값을 곱하여 기능 기여도를 계산합니다. 이 과정은 각 기능이 출력에 얼마나 중요한지, 그 기능이 주어진 입력에 대해 어떻게 반응하는지를 보여줍니다.
- 에러 항 사용: 기본적으로 SAE의 에러 항을 사용하여 SAE가 모델 출력에 영향을 미치지 않도록 보정합니다. include_error_term=False로 설정하면 SAE가 모델 결과에 영향을 미칠 수 있습니다.
- metric_fn 함수:
- 이 함수는 모델 출력(logits)에서 두 토큰 간의 차이를 계산합니다. 이 예제에서는 "earth"와 "sky" 토큰 간의 차이를 비교하는 메트릭을 정의하여, 출력에서 이 두 단어 중 어느 것이 더 큰 영향을 미치는지 분석합니다.
- 예를 들어, 프롬프트가 "In the beginning, God created the heavens and the"일 때, "earth"과 "sky" 중 어떤 단어가 더 예측 확률이 높은지 확인합니다.
코드 실행 과정 설명:
- 모델과 SAE에 대해 기능 기여도 계산:
- calculate_attribution_grads 함수에서 모델과 SAE의 그라디언트를 계산하고, 이를 바탕으로 각 뉴런과 SAE 기능이 출력에 얼마나 기여하는지를 파악합니다.
- 그라디언트 계산: 모델의 출력에서 메트릭 함수(metric_fn)를 통해 긍정 토큰과 부정 토큰 간의 차이를 구한 후, 이 차이를 기준으로 역전파(backpropagation) 과정을 수행하여 그라디언트를 계산합니다.
- 기능 기여도(Attribution) 계산:
- calculate_feature_attribution 함수는 모델과 SAE에서 발생한 활성화값과 그라디언트를 곱하여, 각 기능이 최종 출력에 얼마나 중요한 역할을 했는지 계산합니다.
- 이 과정에서 SAE의 에러 항을 고려하여, SAE가 출력에 영향을 미치지 않도록 하거나, SAE가 어떻게 기여했는지 분석할 수 있습니다.
- 프롬프트에 대한 메트릭 계산:
- prompt는 "In the beginning, God created the heavens and the"라는 입력을 사용하고, "earth"와 "sky"라는 두 토큰 간의 차이를 계산하는 메트릭 함수를 사용합니다.
- 모델은 이 입력을 통해 "earth"가 "sky"보다 더 적합한지 판단하고, 그 결과를 기여도 분석에 사용합니다.
최종 결과:
- feature_attribution_df에 모델과 SAE의 각 기능이 주어진 프롬프트에 대해 어떻게 반응했는지, 그리고 어느 기능이 더 큰 기여를 했는지에 대한 정보를 저장합니다.
- 이를 통해 모델 내부에서 발생하는 중간 활성화값과 그라디언트를 기반으로 특정 뉴런이나 기능이 어떤 영향을 미치는지를 정밀하게 분석할 수 있습니다.
이 코드는 특히 Transformer 모델 내부의 기능 분석과 희소 오토인코더(SAE)의 기능 분석에 유용하며, **기능 기여도 분석(feature attribution)**을 통해 모델의 해석 가능성을 높이는 데 중점을 둡니다.
tokens = model.to_str_tokens(prompt)
unique_tokens = [f"{i}/{t}" for i, t in enumerate(tokens)]
px.bar(x = unique_tokens,
y = feature_attribution_df.sae_feature_attributions[sae.cfg.hook_name][0].sum(-1).detach().cpu().numpy())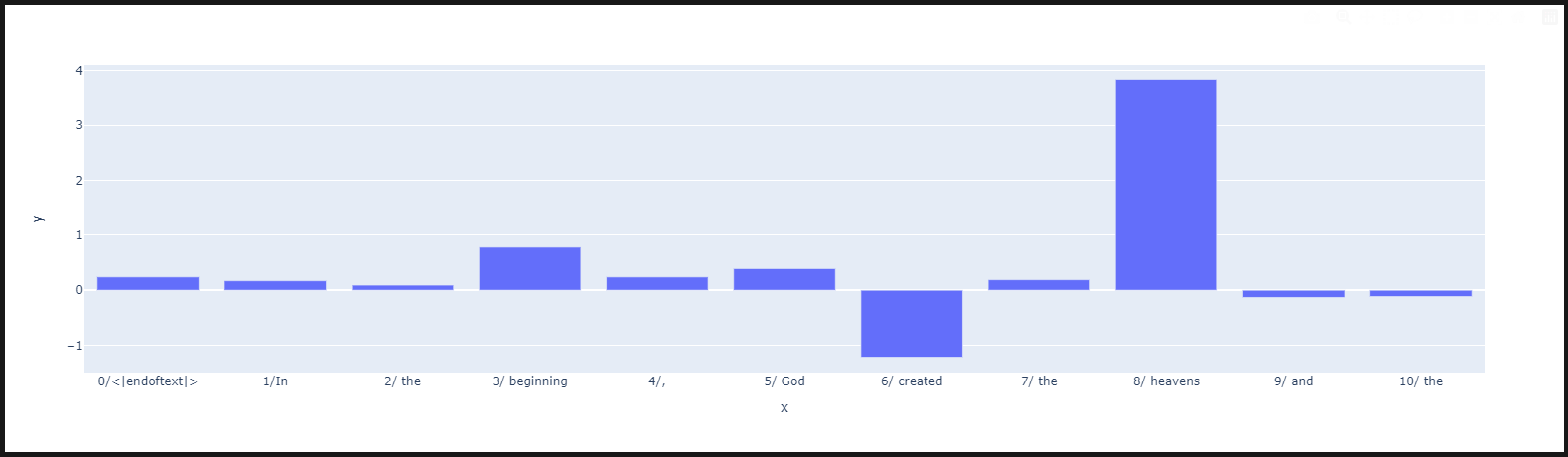
이 그래프는 입력된 프롬프트("In the beginning, God created the heavens and the")에 대해 SAE(Sparse Autoencoder)가 특정 토큰들에 대해 어떻게 기여(Attribution)를 했는지를 시각화한 것입니다. 각 토큰이 모델에 어떤 영향을 미쳤는지를 보여주며, 그래프의 Y축은 특정 토큰에 대해 SAE가 모델의 활성화 값에 미친 영향을 나타냅니다.
세부 해석:
- X축 (토큰들):
- X축은 프롬프트 내의 각 단어 또는 토큰을 나타냅니다. model.to_str_tokens(prompt)를 통해 입력 프롬프트를 토큰화하고, 이를 X축에 표시했습니다.
- 각 토큰은 "토큰 인덱스/토큰" 형식으로 표시되었습니다. 예를 들어, "8/heavens"는 프롬프트 내 8번째 토큰이 "heavens"임을 나타냅니다.
- Y축 (기여도):
- Y축은 각 토큰에 대해 SAE가 모델 활성화에 미친 기여도를 나타냅니다. 양의 값은 해당 토큰이 모델에 긍정적인 기여를 했음을 의미하며, 음의 값은 해당 토큰이 모델에 부정적인 영향을 미쳤음을 나타냅니다.
- SAE를 통해 추출된 특정 특징(feature)이 각 토큰에 대해 어떻게 영향을 미쳤는지를 sae_feature_attributions로 표현하였으며, 기여도의 합계를 그래프로 그린 것입니다.
- 그래프 해석:
- 가장 큰 양의 기여는 "8/heavens" 토큰에서 나타납니다. 이는 SAE가 "heavens"라는 단어에 대해 매우 중요한 기여를 했음을 보여줍니다. 즉, 모델이 이 토큰을 처리할 때 SAE가 특히 큰 영향을 미쳤다는 것을 의미합니다.
- 다른 토큰들은 상대적으로 기여도가 낮거나 음수 값(특히 "created"에서)이 나타났습니다. 이는 해당 토큰들이 모델의 활성화에 덜 중요한 역할을 했거나, 모델이 해당 토큰에 대해 부정적으로 반응했음을 나타냅니다.
- 해석의 의미:
- 이 분석은 특정 단어("heavens")가 주어진 문맥에서 모델 출력에 매우 중요한 영향을 미친다는 것을 보여줍니다. 또한 SAE가 이 단어에 대해 활성화 값을 크게 조정하거나 강조한 것으로 볼 수 있습니다.
- 반면, "created"와 같은 단어는 SAE의 기능 기여도가 음수로 나타나며, 모델의 출력에 덜 긍정적인 영향을 미친 것으로 해석됩니다.
결론:
이 그래프는 주어진 문장에서 "heavens"라는 단어가 모델과 SAE 분석에서 매우 중요한 역할을 한다는 것을 시각적으로 보여줍니다. 반면, 다른 단어들은 상대적으로 덜 중요한 기여도를 가지고 있으며, 특히 "created"라는 단어는 기여도가 음수로 나타나면서 그다지 긍정적인 영향을 미치지 않았습니다.
def convert_sparse_feature_to_long_df(sparse_tensor: torch.Tensor) -> pd.DataFrame:
"""
Convert a sparse tensor to a long format pandas DataFrame.
"""
df = pd.DataFrame(sparse_tensor.detach().cpu().numpy())
df_long = df.melt(ignore_index=False, var_name='column', value_name='value')
df_long.columns = ["feature", "attribution"]
df_long_nonzero = df_long[df_long['attribution'] != 0]
df_long_nonzero = df_long_nonzero.reset_index().rename(columns={'index': 'position'})
return df_long_nonzero
df_long_nonzero = convert_sparse_feature_to_long_df(feature_attribution_df.sae_feature_attributions[sae.cfg.hook_name][0])
df_long_nonzero.sort_values("attribution", ascending=False)
이 코드에서는 희소 텐서(sparse tensor)를 긴 형식의 pandas DataFrame으로 변환하여, 각 토큰의 위치와 그에 따른 기능(feature) 기여도를 확인할 수 있게 합니다. 해당 코드를 통해 추출한 정보는 SAE 기능의 기여도를 분석할 때 매우 유용합니다. 코드의 각 부분을 설명하겠습니다.
코드 설명:
- convert_sparse_feature_to_long_df 함수:
- 이 함수는 희소 텐서를 받아 pandas DataFrame으로 변환합니다. 변환 후, 각 토큰의 특정 위치에서 SAE 기능들이 모델에 얼마나 기여했는지를 데이터 프레임으로 표현합니다.
- 희소 텐서(sparse_tensor)는 주로 모델의 각 위치에서 발생하는 SAE의 기능 기여도를 포함하고 있으며, 이 함수는 그 희소 텐서에서 0이 아닌 기여도만 추출하여 분석할 수 있게 합니다.
- 과정 설명:
- pd.DataFrame(sparse_tensor.detach().cpu().numpy()):
- sparse_tensor는 PyTorch 텐서로, 이를 CPU로 이동시킨 뒤 numpy 배열로 변환하여 pandas DataFrame으로 만듭니다.
- df.melt():
- melt 함수는 DataFrame을 "wide format"에서 "long format"으로 변환합니다. 즉, 각 컬럼(특정 기능(feature))을 행 단위로 변환하여, 각 기능의 기여도를 하나씩 나열합니다.
- 결과적으로 "position"(위치)와 "feature"(기능), "attribution"(기여도)로 나누어진 데이터를 생성합니다.
- df_long_nonzero = df_long[df_long['attribution'] != 0]:
- 기여도가 0이 아닌 값만 필터링하여, 분석에 유의미한 값들만 남깁니다.
- reset_index().rename(columns={'index': 'position'}):
- 인덱스를 초기화하고, 기존 인덱스를 'position'(토큰의 위치)으로 지정합니다. 이렇게 하면 각 위치에서 특정 기능의 기여도를 확인할 수 있습니다.
- pd.DataFrame(sparse_tensor.detach().cpu().numpy()):
- df_long_nonzero.sort_values("attribution", ascending=False):
- 변환된 데이터 프레임에서 **기여도(attribution)**에 따라 내림차순으로 정렬하여, 어떤 기능이 가장 중요한 기여를 했는지 쉽게 확인할 수 있게 합니다.
테이블 해석:
이 테이블은 SAE 기능 기여도와 토큰의 위치에 대한 정보를 담고 있습니다. 각 행은 특정 토큰의 위치에서 특정 기능(feature)이 얼마나 기여했는지를 보여줍니다.
| position | feature | attribution |
| 522 | 8 | 22597 |
| 45 | 8 | 1941 |
| 383 | 10 | 16873 |
| 201 | 8 | 10531 |
| 194 | 10 | 10195 |
컬럼 설명:
- position:
- 프롬프트 내에서의 토큰 위치를 나타냅니다. 예를 들어, 522는 프롬프트의 8번째 토큰(예: "heavens")에 해당하며, 383은 10번째 토큰(예: "the")에 해당합니다.
- feature:
- 각 위치에서 활성화된 **SAE 기능(특정 feature의 ID)**를 나타냅니다. 이는 특정 뉴런이나 기능을 식별하는 고유 ID입니다.
- attribution:
- 각 기능이 모델의 출력에 얼마나 기여했는지를 나타내는 값입니다. 양수 값은 해당 기능이 긍정적인 영향을 미쳤음을 의미하고, 음수 값은 부정적인 영향을 미쳤음을 의미합니다.
예시 해석:
- position 522, feature 22597, attribution 2.092221:
- 프롬프트의 8번째 위치(예: "heavens")에서, 기능 22597이 모델 출력에 매우 큰 기여(2.092221)를 했습니다.
- position 383, feature 16873, attribution 0.657706:
- 10번째 위치(예: "the")에서, 기능 16873이 상대적으로 더 작은 기여(0.657706)를 했습니다.
전체적인 해석:
이 데이터는 프롬프트 내 특정 토큰들이 모델의 출력에 얼마나 중요한 역할을 했는지를 보여줍니다. 특히, 기여도가 높은 기능과 위치를 확인함으로써, SAE가 특정 토큰에서 모델 출력을 어떻게 조정했는지를 이해할 수 있습니다. 예를 들어, "heavens"라는 단어에서 특정 기능(22597)이 매우 중요한 기여를 했다는 것을 알 수 있습니다.
이 정보를 바탕으로, 모델이 특정 단어에 대해 어떻게 반응하는지에 대한 분석을 깊이 있게 진행할 수 있습니다.
SAE의 파라미터 분석! - 통계적인 해석을 사용합니다.
import numpy as np
import torch
import plotly_express as px
from transformer_lens import HookedTransformer
# Model Loading
from sae_lens import SAE
from sae_lens.analysis.neuronpedia_integration import get_neuronpedia_quick_list
# Virtual Weight / Feature Statistics Functions
from sae_lens.analysis.feature_statistics import (
get_all_stats_dfs,
get_W_U_W_dec_stats_df,
)
# Enrichment Analysis Functions
from sae_lens.analysis.tsea import (
get_enrichment_df,
manhattan_plot_enrichment_scores,
plot_top_k_feature_projections_by_token_and_category,
)
from sae_lens.analysis.tsea import (
get_baby_name_sets,
get_letter_gene_sets,
generate_pos_sets,
get_test_gene_sets,
get_gene_set_from_regex,
)각종 라이브러리 불러오기
GPT2-small과 SAE 불러오기
model = HookedTransformer.from_pretrained("gpt2-small")
# this is an outdated way to load the SAE. We need to have feature spartisity loadable through the new interface to remove it.
gpt2_small_sparse_autoencoders = {}
gpt2_small_sae_sparsities = {}
for layer in range(12):
sae, original_cfg_dict, sparsity = SAE.from_pretrained(
release="gpt2-small-res-jb",
sae_id="blocks.0.hook_resid_pre",
device="cpu",
)
gpt2_small_sparse_autoencoders[f"blocks.{layer}.hook_resid_pre"] = sae
gpt2_small_sae_sparsities[f"blocks.{layer}.hook_resid_pre"] = sparsity레이어별로 다 가지고 오느라 반복문이 사용됩니다.
8레이어의 통계적 특성
# In the post, I focus on layer 8
layer = 8
# get the corresponding SAE and feature sparsities.
sparse_autoencoder = gpt2_small_sparse_autoencoders[f"blocks.{layer}.hook_resid_pre"]
log_feature_sparsity = gpt2_small_sae_sparsities[f"blocks.{layer}.hook_resid_pre"].cpu()
W_dec = sparse_autoencoder.W_dec.detach().cpu()
# calculate the statistics of the logit weight distributions
W_U_stats_df_dec, dec_projection_onto_W_U = get_W_U_W_dec_stats_df(
W_dec, model, cosine_sim=False
)
W_U_stats_df_dec["sparsity"] = (
log_feature_sparsity # add feature sparsity since it is often interesting.
)
display(W_U_stats_df_dec)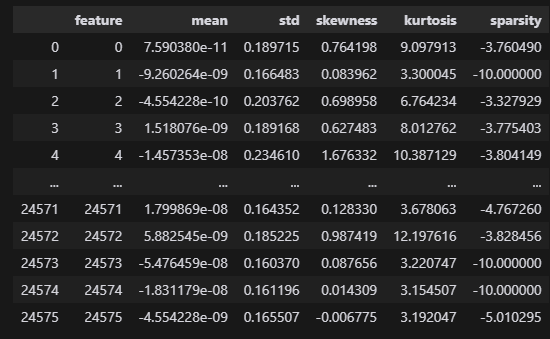
fig = px.scatter(
W_U_stats_df_dec,
x="skewness",
y="kurtosis",
color="std",
color_continuous_scale="Portland",
hover_name="feature",
width=800,
height=500,
log_y=True, # Kurtosis has larger outliers so logging creates a nicer scale.
labels={"x": "Skewness", "y": "Kurtosis", "color": "Standard Deviation"},
title=f"Layer {8}: Skewness vs Kurtosis of the Logit Weight Distributions",
)
# decrease point size
fig.update_traces(marker=dict(size=3))
fig.show()
# then you can query accross combinations of the statistics to find features of interest and open them in neuronpedia.
tmp_df = W_U_stats_df_dec[["feature", "skewness", "kurtosis", "std"]]
# tmp_df = tmp_df[(tmp_df["std"] > 0.04)]
# tmp_df = tmp_df[(tmp_df["skewness"] > 0.65)]
tmp_df = tmp_df[(tmp_df["skewness"] > 3)]
tmp_df = tmp_df.sort_values("skewness", ascending=False).head(10)
display(tmp_df)
# if desired, open the features in neuronpedia
get_neuronpedia_quick_list(sparse_autoencoder, list(tmp_df.feature))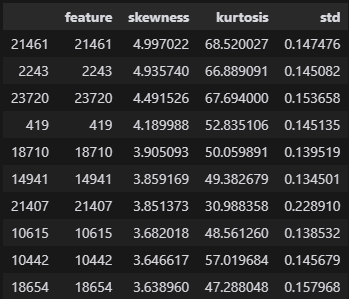
높은 skewness를 가지는 부분만 뽑아낼 수 있습니다.
nltk를 활용하여 특정 데이터에 따른 값 비교
import nltk
nltk.download("averaged_perceptron_tagger")
# get the vocab we need to filter to formulate token sets.
vocab = model.tokenizer.get_vocab() # type: ignore
# make a regex dictionary to specify more sets.
regex_dict = {
"starts_with_space": r"Ġ.*",
"starts_with_capital": r"^Ġ*[A-Z].*",
"starts_with_lower": r"^Ġ*[a-z].*",
"all_digits": r"^Ġ*\d+$",
"is_punctuation": r"^[^\w\s]+$",
"contains_close_bracket": r".*\).*",
"contains_open_bracket": r".*\(.*",
"all_caps": r"Ġ*[A-Z]+$",
"1 digit": r"Ġ*\d{1}$",
"2 digits": r"Ġ*\d{2}$",
"3 digits": r"Ġ*\d{3}$",
"4 digits": r"Ġ*\d{4}$",
"length_1": r"^Ġ*\w{1}$",
"length_2": r"^Ġ*\w{2}$",
"length_3": r"^Ġ*\w{3}$",
"length_4": r"^Ġ*\w{4}$",
"length_5": r"^Ġ*\w{5}$",
}
# print size of gene sets
all_token_sets = get_letter_gene_sets(vocab)
for key, value in regex_dict.items():
gene_set = get_gene_set_from_regex(vocab, value)
all_token_sets[key] = gene_set
# some other sets that can be interesting
baby_name_sets = get_baby_name_sets(vocab)
pos_sets = generate_pos_sets(vocab)
arbitrary_sets = get_test_gene_sets(model)
all_token_sets = {**all_token_sets, **pos_sets}
all_token_sets = {**all_token_sets, **arbitrary_sets}
all_token_sets = {**all_token_sets, **baby_name_sets}
# for each gene set, convert to string and print the first 5 tokens
for token_set_name, gene_set in sorted(
all_token_sets.items(), key=lambda x: len(x[1]), reverse=True
):
tokens = [model.to_string(id) for id in list(gene_set)][:10] # type: ignore
print(f"{token_set_name}, has {len(gene_set)} genes")
print(tokens)
print("----")데이터 나누기
features_ordered_by_skew = (
W_U_stats_df_dec["skewness"].sort_values(ascending=False).head(5000).index.to_list()
)
token_sets_index = ["boys_names", "girls_names"]
token_set_selected = {
k: set(v) for k, v in all_token_sets.items() if k in token_sets_index
}
df_enrichment_scores = get_enrichment_df(
dec_projection_onto_W_U, features_ordered_by_skew, token_set_selected
)
manhattan_plot_enrichment_scores(df_enrichment_scores).show()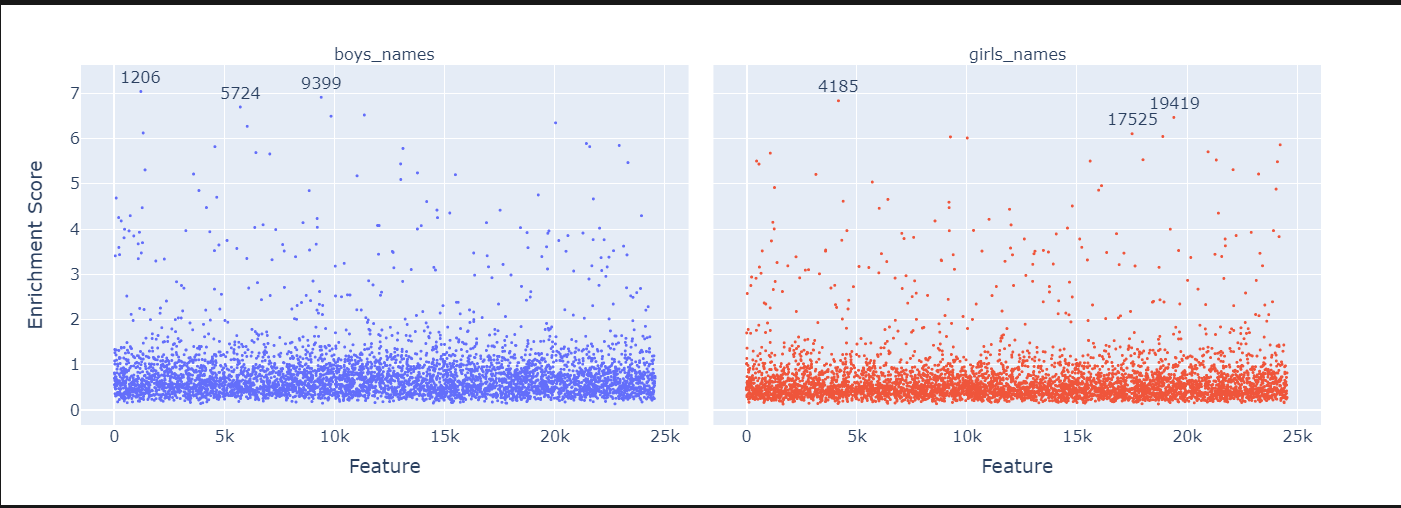
tmp_df = df_enrichment_scores.apply(lambda x: -1 * np.log(1 - x)).T
color = (
W_U_stats_df_dec.sort_values("skewness", ascending=False)
.head(5000)["skewness"]
.values
)
fig = px.scatter(
tmp_df.reset_index().rename(columns={"index": "feature"}),
x="boys_names",
y="girls_names",
marginal_x="histogram",
marginal_y="histogram",
# color = color,
labels={
"boys_names": "Enrichment Score (Boys Names)",
"girls_names": "Enrichment Score (Girls Names)",
},
height=600,
width=800,
hover_name="feature",
)
# reduce point size on the scatter only
fig.update_traces(marker=dict(size=3), selector=dict(mode="markers"))
# annotate any features where the absolute distance between boys names and girls names > 3
for feature in df_enrichment_scores.columns:
if abs(tmp_df["boys_names"][feature] - tmp_df["girls_names"][feature]) > 2.9:
fig.add_annotation(
x=tmp_df["boys_names"][feature] - 0.4,
y=tmp_df["girls_names"][feature] + 0.1,
text=f"{feature}",
showarrow=False,
)
fig.show()
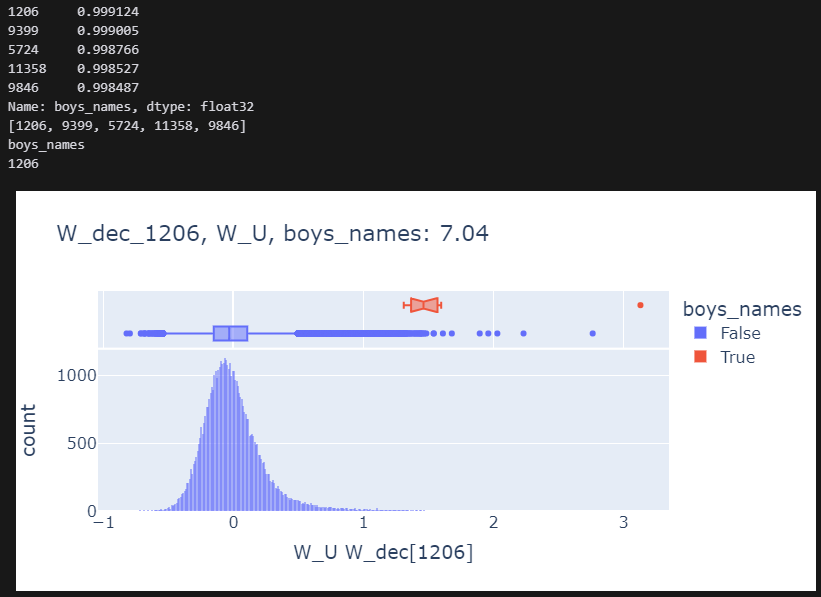
for category in ["boys_names"]:
plot_top_k_feature_projections_by_token_and_category(
token_set_selected,
df_enrichment_scores,
category=category,
dec_projection_onto_W_U=dec_projection_onto_W_U,
model=model,
log_y=False,
histnorm=None,
)
W_U_stats_df_dec_all_layers = get_all_stats_dfs(
gpt2_small_sparse_autoencoders, gpt2_small_sae_sparsities, model, cosine_sim=True
)
display(W_U_stats_df_dec_all_layers.shape)
display(W_U_stats_df_dec_all_layers.head())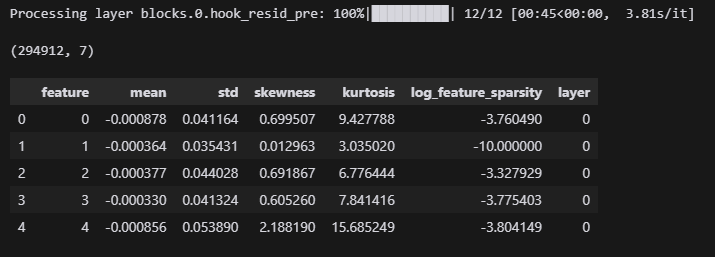
'인공지능 > XAI' 카테고리의 다른 글
| Sae 학습에 따른 dead_features (2) | 2024.10.04 |
|---|---|
| LLama3 학습 데이터 변환하여 LLama3.2 Sparse Autoencoder 학습하기 (3) | 2024.09.27 |
| SAE 통해 특정 feature를 강화시켜 LLM 출력 변형하기 - 미스트랄 mistral 7b (2) | 2024.09.26 |
| Sparse Autoencoder 시작 (1) | 2024.09.19 |
| LLM interpretability1 : Toy Models of Superposition (1) | 2024.09.12 |