액션과 상태가 별로 없으면 테이블이 적당하니 구할 수 있다. 그러나 우리가 할 작업은 액션과 상태가 연속적이라 엄청나다...
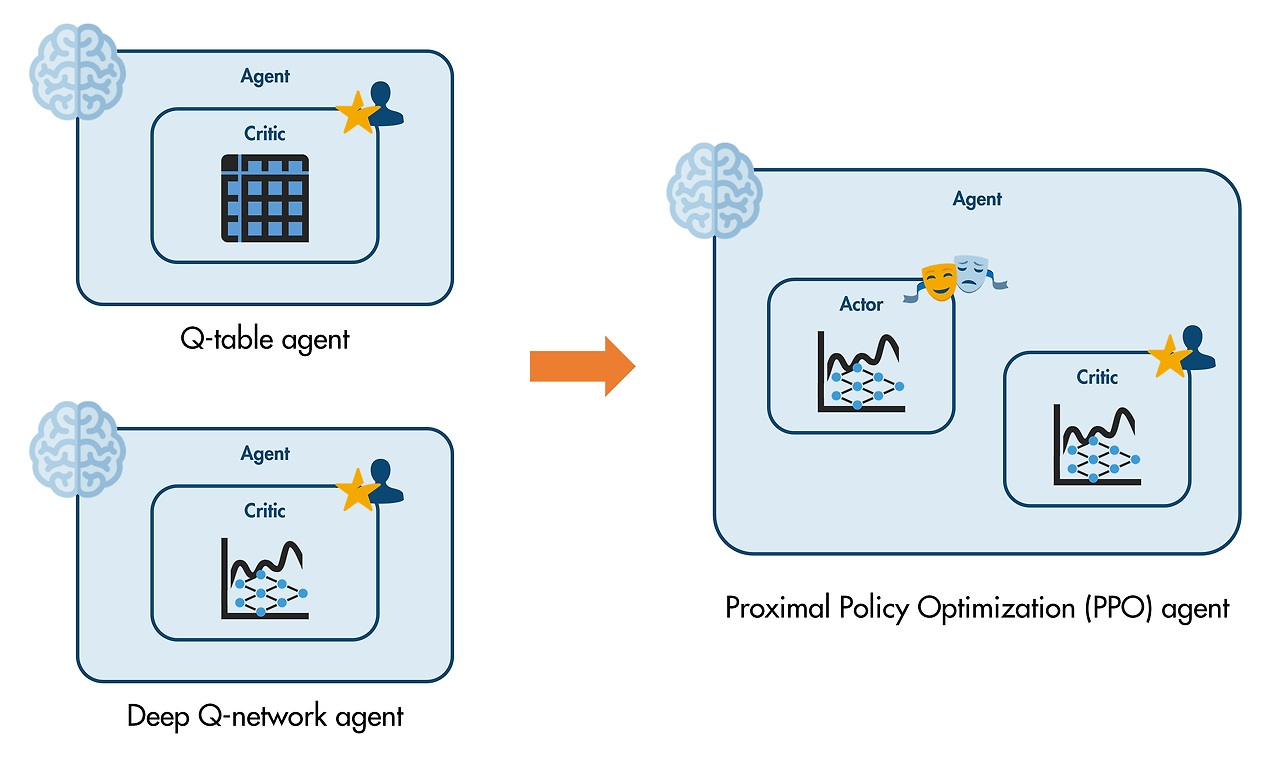
크리틱을 신경망으로 사용하자!
크리틱의 액션은 액터한테서 가져온다.
크리틱의 평가로부터 정책 학습이 가능하다.
액터-크리틱 에이전트
다양한 유형의 액터-크리틱 에이전트가 있으며, 각각은 액터 신경망과 크리틱 신경망에 특정 아키텍처를 사용합니다. 액터와 크리틱에 대한 사용자 지정 신경망을 만들지 않는 한, 여러 다른 유형의 액터 신경망과 크리틱 신경망에 대해 염려할 필요가 없습니다. 일반적으로 관측값과 행동만 지정하여 에이전트를 만들 수 있으며, 이 경우 선택된 디폴트 액터 신경망과 디폴트 크리틱 신경망을 갖는 에이전트가 생성됩니다.
주사위 게임을 위한 액터-크리틱 에이전트
PPO(근위 정책 최적화) 에이전트는 이산 행동에 사용할 수 있는 간단한 액터-크리틱 에이전트입니다.
이런 간단한 문제에는 보다 단순한 크리틱 에이전트(예: Q-러닝 또는 DQN)가 잘 작동할 수 있지만, 어쨌든 이 활동에서는 주사위 게임을 위한 PPO(근위 정책 최적화) 에이전트를 만들어 보겠습니다.
관측값 사양과 행동 사양을 입력값으로 지정하여 적절한 rl*Agent 함수를 호출해 에이전트를 만들 수 있습니다. 이 경우에는 "*" 와일드카드를 PPO로 대체하세요.
agent = rlPPOAgent(obsInfo,actInfo);
그러면 에이전트의 액터와 크리틱을 표현하는 신경망에 대해 미리 결정된 디폴트 아키텍처를 사용하는 PPO(근위 정책 최적화) 에이전트가 생성됩니다.
작업
rlPPOAgent 함수를 사용하여 디폴트 액터 신경망과 디폴트 크리틱 신경망을 갖는 agent라는 에이전트를 만드세요.
agent = rlPPOAgent(obsInfo,actInfo);
PPO 에이전트는 액터-크리틱 에이전트입니다.
getActor 함수와 getCritic 함수는 모두 에이전트를 입력값으로 받고 그 에이전트의 액터 또는 크리틱을 출력값으로 반환합니다.
작업
getActor 함수와 getCritic 함수를 사용하여 agent에서 액터와 크리틱을 추출하세요. actor라는 변수에 액터를 저장하고 critic이라는 변수에 크리틱을 저장하세요.
actor = getActor(agent)
critic = getCritic(agent)
getModel 함수를 사용하여 크리틱에서 신경망을 추출한 다음 점 표기법을 사용하여, 결과로 생성된 신경망 변수의 Layers 속성에 액세스할 수 있다는 점을 기억하세요.
network = getModel(critic)
layers = network.Layers
작업
getModel 함수를 사용하여 critic에서 신경망을 추출한 다음 cnet이라는 변수에 저장하세요. 그런 다음 점 표기법을 사용하여 cnet의 Layers 속성을 추출하고 결과를 clayers라는 변수에 저장하세요.
세미콜론을 생략하면 결과를 직접 확인할 수 있습니다.
cnet = getModel(critic)
clayers = cnet.Layers
getModel 함수는 액터 또는 크리틱을 표현하는 신경망을 반환합니다.
작업
getModel 함수를 사용하여 actor에서 신경망을 추출한 다음 anet이라는 변수에 저장하세요. 그런 다음 점 표기법을 사용하여 신경망 anet의 Layers 속성을 추출하고 결과를 alayers라는 변수에 저장하세요.
세미콜론을 생략하면 결과를 직접 확인할 수 있습니다.
anet = getModel(actor)
alayers = anet.Layers

이산 행동의 경우, PPO 에이전트는 가치 크리틱과 확률적 범주 액터를 사용합니다.
가치 크리틱은 특정 상태에 있을 때의 가치를 평가합니다. 주사위 게임의 경우에 이는 크리틱이 한 스칼라 변수(목표값)에서 또 다른 스칼라 변수(값)로의 단순 함수임을 의미합니다. 로컬 함수 visualizevalue는 크리틱의 가치를 모든 목표값의 함수로 플로팅합니다.
visualizevalue(cnet)
액터는 스칼라 목표값을 입력값으로 받고 각 행동에 대한 확률을 출력합니다. 최종 완전 연결 계층은 5개의 뉴런(각 행동당 하나의 뉴런)을 가지고 있다는 점에 유의하세요. "softmax" 출력 계층은 완전 연결 계층의 원시 숫자형 값을 확률로 정규화합니다. 로컬 함수 visualizepolicy는 액터의 확률을 모든 목표값의 함수로 시각화합니다.
visualizepolicy(anet)
신경망 가중치와 편향은 에이전트가 생성될 때 무작위로 설정됩니다. 즉, 스크립트를 실행할 때마다 다른 가치 함수와 정책이 표시됩니다. MAT 파일 trainedPPO.mat를 사용하여, 훈련된 크리틱과 액터가 어떻게 각 목표값을 평가하는지 확인할 수 있습니다. 새로 만드는 대신 이 파일에서 에이전트를 불러오세요(작업 1에서).
load trainedPPO
주사위 게임의 경우, 크리틱이 제공하는 값은 게임을 끝내기 위해 (평균적으로) 주사위를 굴려야 하는 횟수의 음수 값이어야 합니다.
이번 활동에서는 평가되는 작업이 없습니다. 스크립트를 실행하여 에이전트의 크리틱이 여러 번의 게임(변수 numexp로 설정됨)을 통해 결정되는 실제 결과를 얼마나 잘 예측하는지 평가할 수 있습니다.
DDPG(심층 결정적 정책 경사법) 에이전트는 연속 행동을 가질 수 있는 액터-크리틱 에이전트입니다. 따라서 창고 로봇을 제어하기에 적합합니다.
작업
rlDDPGAgent 함수를 사용하여 디폴트 액터 신경망과 디폴트 크리틱 신경망을 갖는 agent라는 에이전트를 만드세요.
힌트
obsInfo와 actInfo를 rlDDPGAgent 함수에 입력값으로 전달해 보세요. 결과를 agent에 할당해 보세요.
agent = rlDDPGAgent (obsInfo,actInfo)
작업
getActor 함수와 getCritic 함수를 사용하여 agent에서 액터와 크리틱을 추출하세요. actor라는 변수에 액터를 저장하고 critic이라는 변수에 크리틱을 저장하세요.
actor = getActor (agent)
critic= getCritic (agent)
로봇 에이전트에 대한 액터는 6개의 관측값을 받아야 하며 1과 +1 사이의 연속 숫자형 값인 2개의 행동(병진력과 회전력)을 생성해야 합니다.
신경망은 tanh(쌍곡탄젠트 함수) 계층을 사용하여 원시 숫자형 값을 범위 [-1,1]에 매핑할 수 있습니다.
작업
getModel 함수를 사용하여 actor에서 신경망을 추출한 다음 anet이라는 변수에 저장하세요. 그런 다음 점 표기법을 사용하여 신경망 anet의 Layers 속성을 추출하고 결과를 alayers라는 변수에 저장하세요.
세미콜론을 생략하면 결과를 직접 확인할 수 있습니다.
DDPG 에이전트는 Q-값 크리틱을 사용합니다. 이 크리틱은 관측값과 행동 둘 모두를 입력값으로 받고 단일 스칼라 값을 출력값으로 반환합니다.
작업
getModel 함수를 사용하여 critic에서 신경망을 추출한 다음 cnet이라는 변수에 저장하세요. 그런 다음 plot 함수를 사용하여 신경망 cnet의 구조를 시각화하세요.
cnet = getModel(critic)
plot(cnet)

스크립트의 맨 끝에 있는 명령의 주석을 해제하여 DDPG 에이전트로 로봇을 시뮬레이션할 수 있습니다.
당연하게도, 무작위로 지정된 신경망 가중치와 편향을 사용하면 로봇이 제대로 작동하지 않을 것입니다. 새로 만드는 대신 MAT 파일 trainedDDPG.mat를 사용하여, 훈련된 에이전트를 불러올 수 있습니다(작업 1에서).
load trainedDDPG
이 에이전트는 동일한 디폴트 신경망 아키텍처를 사용하지만 원하는 동작을 생성할 수 있도록 훈련을 통해 결정된 가중치와 편향을 가지고 있다는 점에 유의하세요. 로봇이 선반 사이에서 성공적으로 길을 찾아가도록 더 많은 시간을 할애하려면 MaxSteps 옵션을 늘리면 됩니다.
에이전트 유형 요약
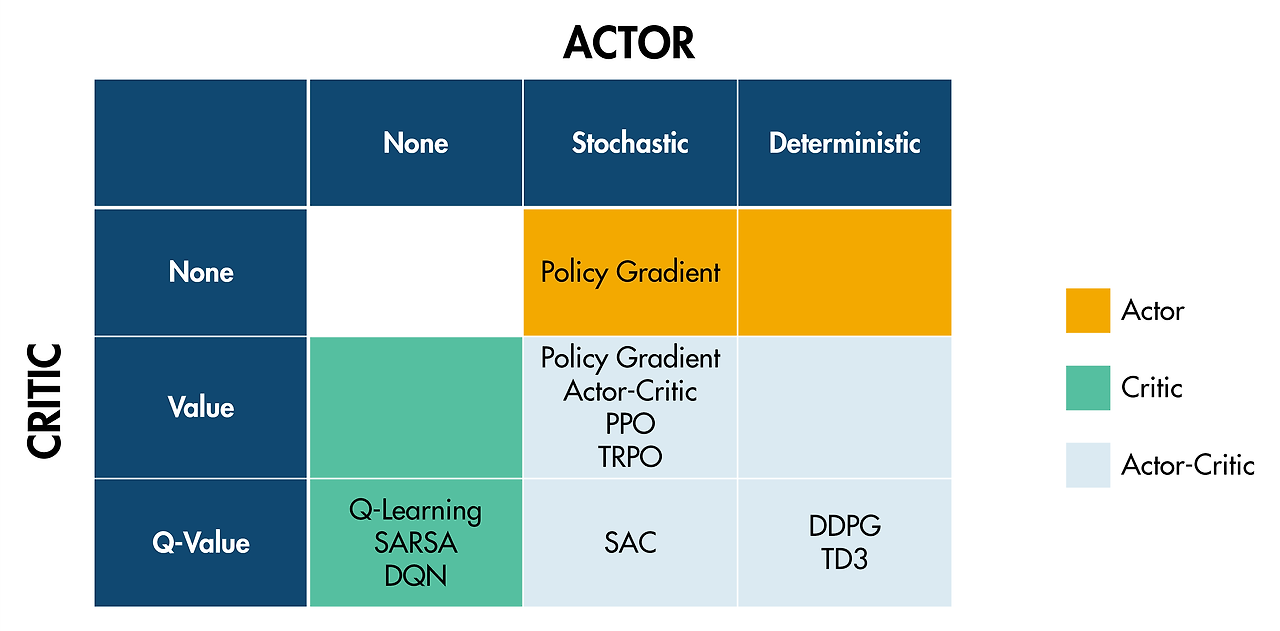
다음 표에는 복잡도가 높은 순서대로 에이전트가 나열되어 있습니다. 일반적으로, 가장 간단한 알고리즘으로 시작하고 에이전트가 제대로 작동하지 않으면 더 복잡한 알고리즘으로 이동해야 합니다. 주황색으로 표시된 에이전트는 가치 기반(크리틱) 에이전트입니다. 파란색으로 표시된 에이전트는 액터-크리틱입니다.
이산 행동연속 행동
|
Q-러닝
rlQAgentSARSA
rlSARSAAgentDQN(심층 Q-신경망)
rlDQNAgentPPO(근위 정책 최적화)
rlPPOAgentTRPO(신뢰 영역 정책 최적화)
rlTRPOAgent |
DDPG(심층 결정적 정책 경사법)
rlDDPGAgentTD3(트윈 지연 심층 결정적 정책 경사법)
rlTD3AgentPPO(근위 정책 최적화)
rlPPOAgentSAC(소프트 액터-크리틱)
rlSACAgentTRPO(신뢰 영역 정책 최적화)
rlTRPOAgent |
'인공지능 > 강화학습' 카테고리의 다른 글
| Matlab 강화학습 - simulink 환경 만들기 및 에이전트 훈련시키기 (0) | 2024.05.10 |
|---|---|
| matlab 강화학습 onramp 8 - 에이전트 훈련시키기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 6 - 에이전트 정의하기 , 신경망으로 크리틱 표현하기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 5 - 에이전트 정의하기 ,Q 테이블 시각화하기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 4 - 보상에 행동 포함하기 (0) | 2024.05.09 |