액터는 여러 에피소드를 거치면서 정책을 개선한다.
어떻게 정책을 개선할까?
크리틱은 얼마나 적합한가 판단한다. 가치를 어떻게 판단하냐?
반복하며 추정을 할 수 있게 된다. 탐색이 요구되는 것이다.
입실론 그리디를 통해 랜덤 한 값을 탐험하기도 한다.
Q테이블을 만들어보자!
Q 테이블에는 관측 가능한 각 상태에 대한 행과 허용되는 각 행동에 대한 열이 있습니다. rlTable 함수를 사용하여 Q-러닝 RL 에이전트에 대한 Q 테이블을 만들 수 있습니다.
T = rlTable(states,actions)
여기서 states와 actions는 rlFiniteSetSpec으로 만든 환경 인터페이스입니다.
작업
rlTable 함수를 사용하여 주사위 게임에 대한 T라는 Q 테이블을 만드세요. 관측 가능한 상태는 변수 obsInfo에 저장되어 있습니다. 행동 선택은 변수 actInfo에 저장되어 있습니다.
T = rlTable(obsInfo,actInfo)

Q 값은 Q 테이블의 Table 속성에 저장되어 있습니다.
작업
점 표기법을 사용하여 T의 Table 속성을 Qvals라는 행렬로 추출하세요.
Qvals = T.Table
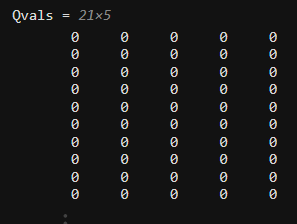
훈련 전에 Q 값은 기본적으로 모두 0으로 설정되어 있습니다. 이러한 값은 훈련 중에 업데이트됩니다.
작업
rand 함수를 사용하여 무작위 Q 값으로 구성된 21 ×5 행렬을 만드세요. 이 행렬을 randQvals라는 변수에 저장하세요.
randQvals = rand(21,5)
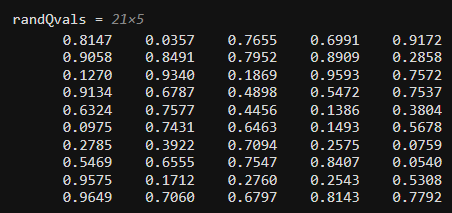
Q 값은 일반적으로 훈련 중에 결정됩니다. 하지만 Q 테이블의 Table 속성을 직접 수정하여 Q 값을 수동으로 설정할 수 있습니다.
작업
점 표기법을 사용하여 T의 Table 속성을 행렬 randQvals와 같게 설정하세요.
T.Table = randQvals
이게 맞네....?
Q 테이블 T를 사용해 Q-러닝 에이전트에 대한 크리틱을 만들 수 있습니다. (당연히 임의로 선택한 Q 값을 사용하면 이 크리틱은 실제로 아무 소용이 없을 수도 있습니다.)
rlQValueFunction 함수를 사용하여 Q 테이블에서 Q-값 크리틱을 만들 수 있습니다.
Qcritic = rlQValueFunction(QTable,...
states,actions)여기서 states와 actions는 rlFiniteSetSpec으로 만든 환경 인터페이스입니다.
작업
rlQValueFunction을 사용하여 테이블 T에서 critic이라는 Q-값 크리틱을 만드세요.
관측 가능한 상태는 변수 obsInfo에 저장되어 있습니다. 행동 선택은 변수 actInfo에 저장되어 있습니다.
critic = rlQValueFunction(T,obsInfo,actInfo)
이제 크리틱을 만들었으므로 rlQAgent 함수를 사용하여 크리틱에서 Q-러닝 에이전트를 만들 수 있습니다.
agent = rlQAgent(QValCritic)
작업
rlQAgent 함수를 사용하여 critic에서 agent라는 Q-러닝 에이전트를 만드세요.
agent = rlQAgent(critic)
명령 [n,win] = playdice(agent, slEnv)를 사용하여, 방금 만든 에이전트로 주사위 게임을 시뮬레이션하세요.
[n,win] = playdice(agent,slEnv)

방금 만든 에이전트는 무작위 Q 값을 갖습니다. 이는 에이전트가 따르는 정책이 임의로 결정된다는 의미입니다. 시뮬레이션된 게임을 검토하여 에이전트가 관측된 목푯값을 행동에 어떻게 매핑하는지 확인해 보세요.
스크립트를 다시 실행해 다른 에이전트를 만들어 보세요. 이 에이전트는 어떤 정책을 사용하나요? 그 정책은 이전 정책과 비교해서 어떤가요? playdice의 첫 번째 출력값은 각 게임에서 주사위를 굴린 횟수입니다. 두 번째 출력값은 주사위 굴리기 제한 횟수 20번 이내에 에이전트가 목표를 달성했는지 여부를 나타냅니다.
Q테이블 시각화하기!
Q 테이블의 의미
Q 테이블에는 상태 값과 행동 값의 각 쌍이 표시됩니다. 이 활동에서는 주사위 게임에 훈련된 에이전트의 Q 테이블을 시각화합니다. 또한 Q 값과 에이전트의 정책 사이의 관계를 시각화합니다.
Q 값은 테이블 표현의 Table 속성에 저장되어 있습니다.
주사위 게임에 대한 Q 테이블의 첫 번째 행은 종료 상태(목푯값 = 0)에 해당합니다.
작업
T의 Table 속성에서 첫 번째 행을 제외한 모든 행을 추출하세요. 결과를 Qvals라는 행렬에 저장하세요.
힌트
Q 값으로 구성된 행렬은 T.Table에 저장되어 있습니다. 행렬 인덱싱을 사용하여 결과에서 행 2:end를 추출해 보세요. 이를 Qvals에 할당해 보세요.
Qvals = T.Table(2:end,:)
작업
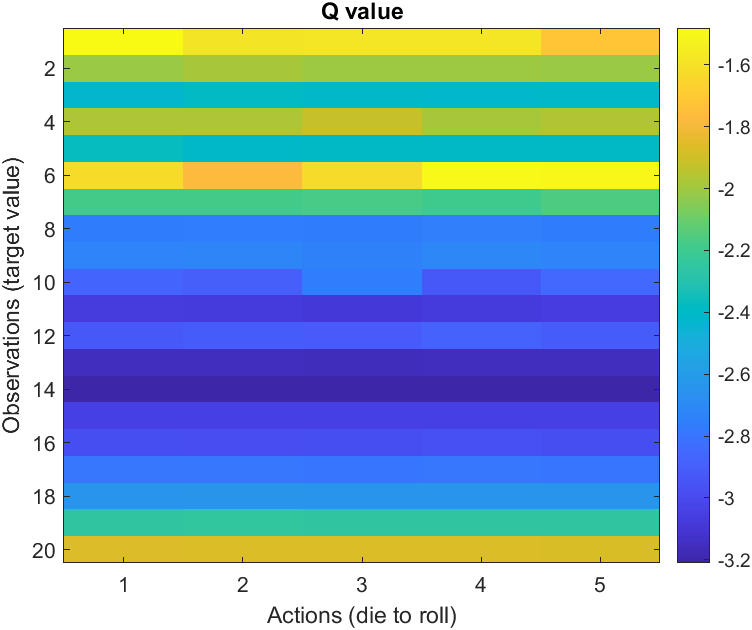
imagesc 함수를 사용하여 Qvals의 값을 시각화하세요. colorbar 함수를 사용하여 값과 색 간의 매핑을 표시하세요.
imagesc(Qvals)
colorbar

각 상태에 대한 최적의 행동은 Q 테이블의 각 행의 최댓값에 의해 결정됩니다.
max 함수에 차원 입력값(선택적 인수)을 사용하면 행별 최댓값을 구할 수 있습니다. max 함수의 두 번째 출력값(선택적 인수)에 최댓값 요소의 열 인덱스가 포함됩니다.
[mx, colidx] = max(X, [],2);
작업
Qvals의 행별 최댓값과 이에 대응되는 열 인덱스를 구하세요. mxQ라는 변수에 값을 저장하고 col이라는 변수에 인덱스를 저장하세요.
힌트
선택적 차원 인수 구문을 사용하여 max 함수를 Qvals에 적용해 보세요. 출력값을 mxQ와 col에 할당해 보세요.
[mxQ, col] = max(Qvals, [],2);
최대 Q 값의 열 인덱스가 에이전트의 정책을 나타냅니다. 즉, col(n)이 상태 n에 대한 최적 행동입니다.
작업
hold on 명령과 hold off 명령을 사용하여 이미지에 플롯을 추가하세요. 가로축에는 열 인덱스를, 세로축에는 상태 1:20을 플로팅 하세요. (선은 그리지 않고) 검은색 마커를 사용하여 데이터 점을 표시하세요.
figure
hold on
plot(col,1:20,"kx")
hold off
낮은 목푯값이 항상 높은 Q 값에 대응하지는 않는다는 점에 유의하세요. 이 예제에서는 0에 도달하기 위해 굴려야 하는 평균 주사위 횟수에 의해 Q 값이 결정됩니다. 주어진 주사위의 값에 대해, 다른 목표값보다 더 어려운 목표값이 있나요?
무작위로 결정되는 에이전트(randomagent에 저장되어 있음)의 정책을 시각화해 보세요.
'인공지능 > 강화학습' 카테고리의 다른 글
| matlab 강화학습 onramp 7 - 액터와 크리틱 (0) | 2024.05.09 |
|---|---|
| matlab 강화학습 onramp 6 - 에이전트 정의하기 , 신경망으로 크리틱 표현하기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 4 - 보상에 행동 포함하기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 3 - 환경 정의하기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 2 - 강화 학습 모델의 구성 요소 (0) | 2024.05.09 |