정책 - 주어신 상황에서 행동을 정한다.
목표에서 보상함수를 만든다.
에이전트는 행동을 선택하고 그 행동에 대해 상태가 변한다. 환경은 보상을 준다.
훈련을 통해 더 많은 보상을 받도록 변한다.
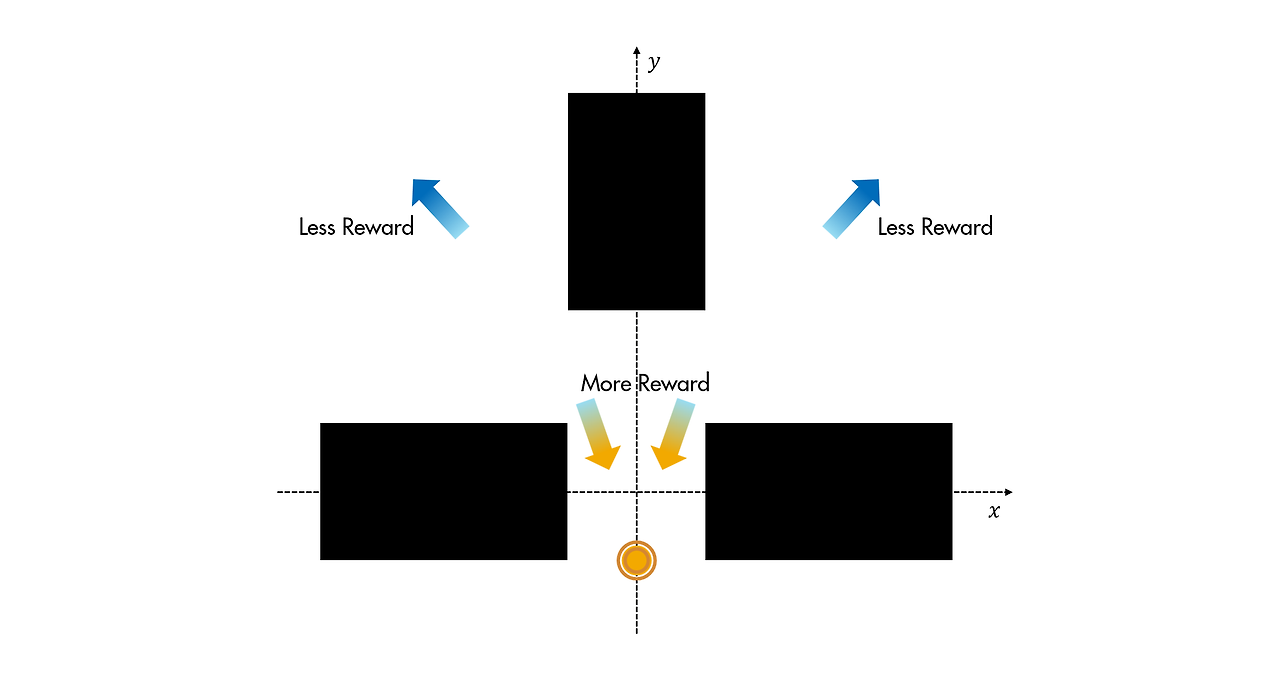
창고 로봇에 대한 보상 설계하기
보상 함수는 로봇이 선반 사이의 공간 쪽( (x,y)=(0,0))으로 이동한 다음 틈새를 통해 아래쪽( y<0)으로 이동하도록 장려해야 합니다.
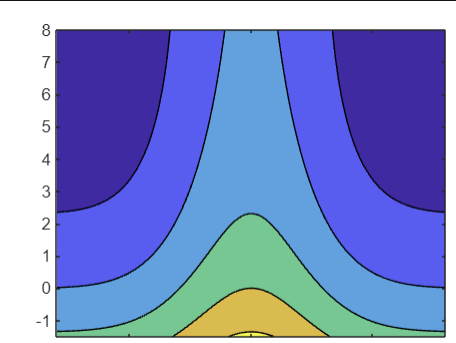
아래에 그래프로 표시된 함수는 각 차원에서 독립적으로 이 목표를 달성합니다. 이 활동에서는 이러한 사항에 기반하여 보상 함수를 설계합니다.

초기화 코드는 meshgrid 함수를 사용하여, (x,y) 점 그리드를 표현하는 행렬을 만듭니다. 또한 행렬 x와 y는 값이 범위 [-1,1] 내에 있도록 10배만큼 축소되었습니다.

힌트
exp 함수와 표준 MATLAB 산술 연산을 사용하여 계산을 수행해 보세요. 결과를 r에 할당해 보세요.
r = exp(-8*x.^2) + exp(-3 * y)
contourf 함수는 채워진 등고선 플롯을 생성하며, 이 등고선 플롯은 두 변수의 함수를 시각화합니다.
contourf(x,y,z)
작업
contourf 함수를 사용하여 위치 (x,y)의 함수인 보상 r에 대한 채워진 등고선 플롯을 만드세요. 원래 좌표값으로 보상 등고선을 플로팅하도록 xvec와 yvec를 (x,y) 좌표로 사용하세요.
contourf(xvec,yvec,r)
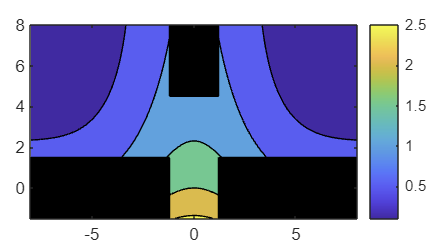
에이전트를 훈련시킬 때, 서로 다른 에피소드에서 획득한 보상이 너무 크게 차이 나지 않도록 보상에 제한을 두는 것이 유용할 수 있습니다. 등고선 플롯에 보상 함수의 형태는 표시되지만 값은 표시되지 않습니다.
작업
colorbar 함수를 사용하여, 보상 함수 값을 표시하는 컬러바를 추가하세요.
창고 로봇에 대한 보상 계산하기
RL Agent 블록에는 환경이 제공하는 3가지 정보, 즉 관측값, 보상, 에피소드의 종료 상태 도달 여부에 대한 정보가 필요합니다. 이러한 정보는 종종 서로 연관되어 있습니다. 창고 로봇의 경우, 로봇이 목표에 도달하거나 선반에 부딪히는 경우 에피소드가 종료됩니다. 두 경우 모두 로봇의 관측 가능한 상태로부터 확인됩니다. 보상은 종료 조건 중 하나에 도달했는지 여부뿐만 아니라 상태에 따라서도 달라집니다.

robot corners 블록은 로봇의 물리적 이동 범위를 확인하고, 그 범위를 기준으로 충돌의 발생 여부도 확인합니다. 이 정보가 reward function 블록에 전달되면, 이 블록은 관측된 상태를 사용하여 로봇의 목표 도달 여부를 확인합니다. 관측된 상태와 두 가지 종료 조건에 대한 정보가 MATLAB 함수 rewardfun에 전부 전달됩니다. 이 활동에서는 이 함수를 작성하여 보상을 계산해 보겠습니다.


function r = rewardfun(state,madeit,collided)
r = 0.05 *exp(-8*(state(1)/10)^2) + 0.06 * exp(-3*state(2)/10) - 0.14;
end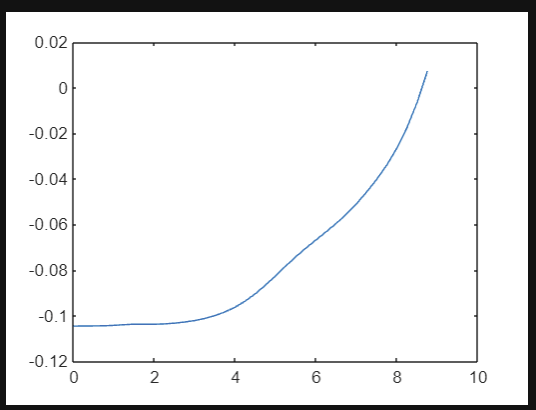
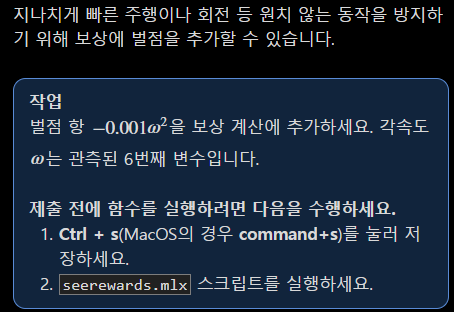
function r = rewardfun(state,madeit,collided)
r = 0.05 *exp(-8*(state(1)/10)^2) + 0.06 * exp(-3*state(2)/10) - 0.14 -0.001*state(6)^2;
end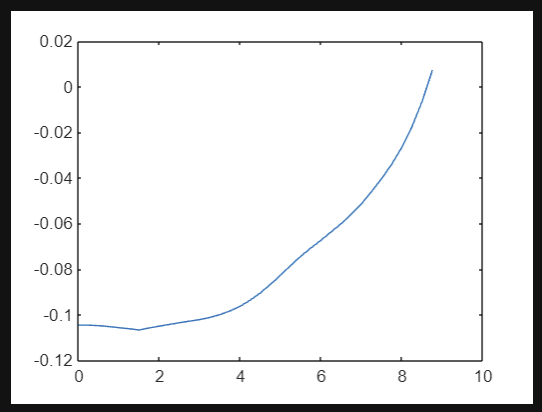
일반적으로, 목표를 성취하거나 제약 조건을 위반하는 경우 이산적인 보상 또는 벌점을 추가합니다. 이러한 이벤트로 인해 에피소드가 종료될 때의 보상은 에피소드가 종료되지 않았을 때 획득할 수 있는 잠재적 최소 보상 또는 최대 보상을 상쇄할 만큼 충분히 커야 합니다.
예를 들어 창고 로봇은 각 시간 스텝에서 작은 음의 보상을 받습니다. 선반에 부딪히는 경우에 대한 벌점이 없으면 에이전트는 에피소드를 종료하기 위해 가능한 한 빨리 선반으로 돌진하도록 학습할 수도 있습니다.
작업
논리형 변수 madeit 및 collided를 사용하여, 목표를 달성할 경우에 대해 5점 보상(+5)을 더하고 선반과 부딪힐 경우에 대해 2점 벌점(-2)을 더하세요. 논리형 변수는 false(0) 또는 true(1) 값만 가지며, 종료의 발생 여부를 나타냅니다.
제출 전에 함수를 실행하려면 다음을 수행하세요.
Ctrl + s(MacOS의 경우 command+s)를 눌러 저장하세요.
seerewards.mlx 스크립트를 실행하세요.
function r = rewardfun(state,madeit,collided)
r = 0.05 *exp(-8*(state(1)/10)^2) + 0.06 * exp(-3*state(2)/10) - 0.14 -0.001* state(6)^2 + madeit * 5 + collided * (-2);
end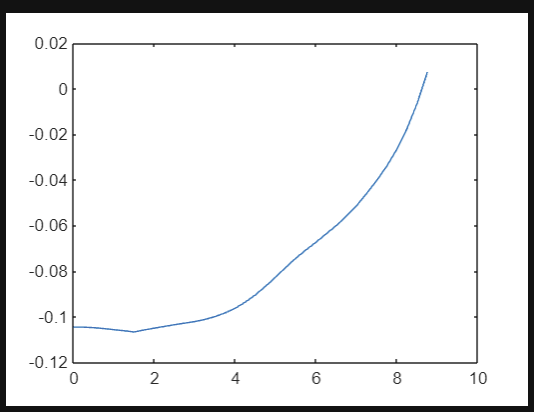
'인공지능 > 강화학습' 카테고리의 다른 글
| matlab 강화학습 onramp 5 - 에이전트 정의하기 ,Q 테이블 시각화하기 (0) | 2024.05.09 |
|---|---|
| matlab 강화학습 onramp 4 - 보상에 행동 포함하기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 2 - 강화 학습 모델의 구성 요소 (0) | 2024.05.09 |
| matlab 강화학습 onramp 1 - 강화 학습 개요 (0) | 2024.05.08 |
| matlab 강화학습 - 다중 에이전트 강화 학습 (0) | 2024.05.08 |