시뮬링크를 활용한 선반 사이를 지나가는 로봇을 만든다.

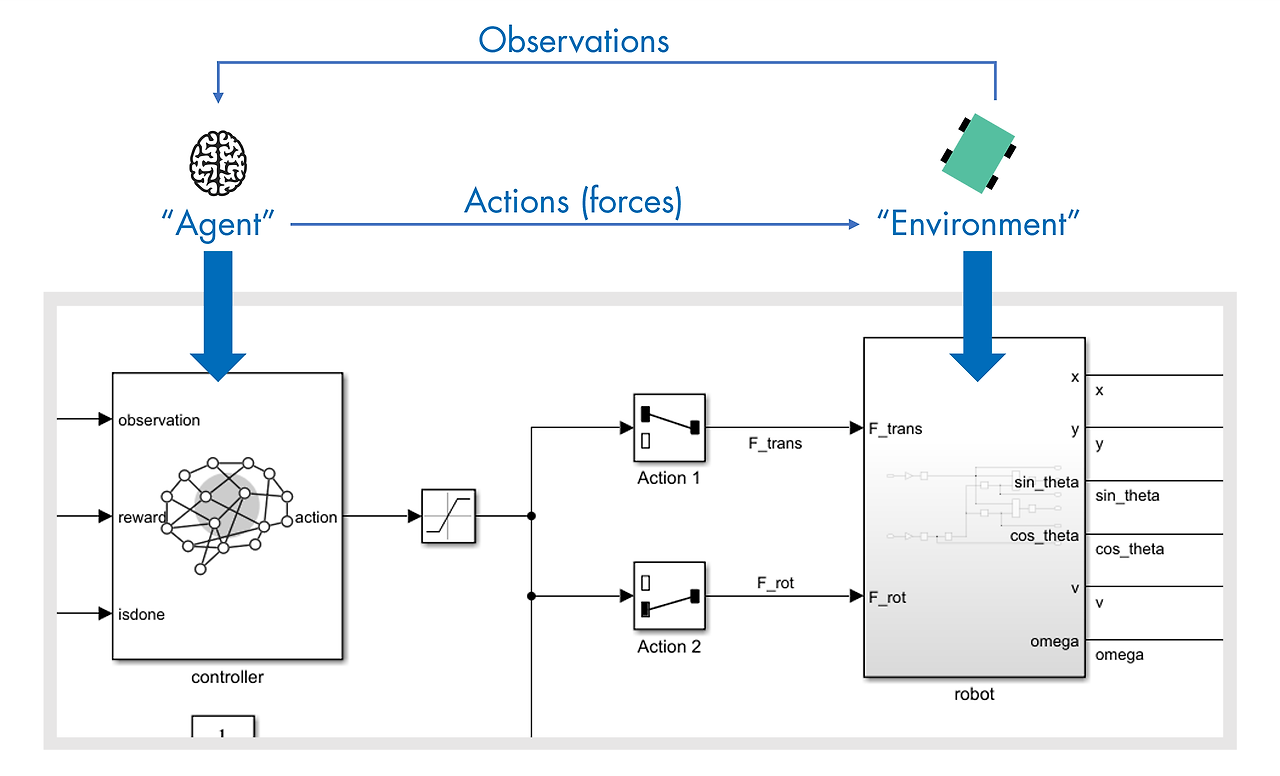
에이전트를 훈련시켰으면 에이전트가 어떻게 동작하는지 확인할 수 있습니다. sim 함수를 사용하여 시뮬레이션을 실행할 수 있습니다.
out = sim(agent,environment)
MAT 파일 robotmodel.mat에는 변수 agent와 env가 포함되어 있으며, 이 두 변수는 각각 사전 훈련된 RL 에이전트와 모델 whrobot.slx를 사용하는 시뮬레이션 환경을 나타냅니다.
작업
sim 함수에서 RL 에이전트 agent를 제어기로 사용하여 env에 저장된 로봇 모델의 시뮬레이션을 실행하세요. 시뮬레이션 결과를 simout이라는 변수에 저장하세요.
출력 패널에서 코드 실행 중에 시뮬레이션이 어떻게 애니메이션되는지 살펴보세요.
simout = sim(agent,env)
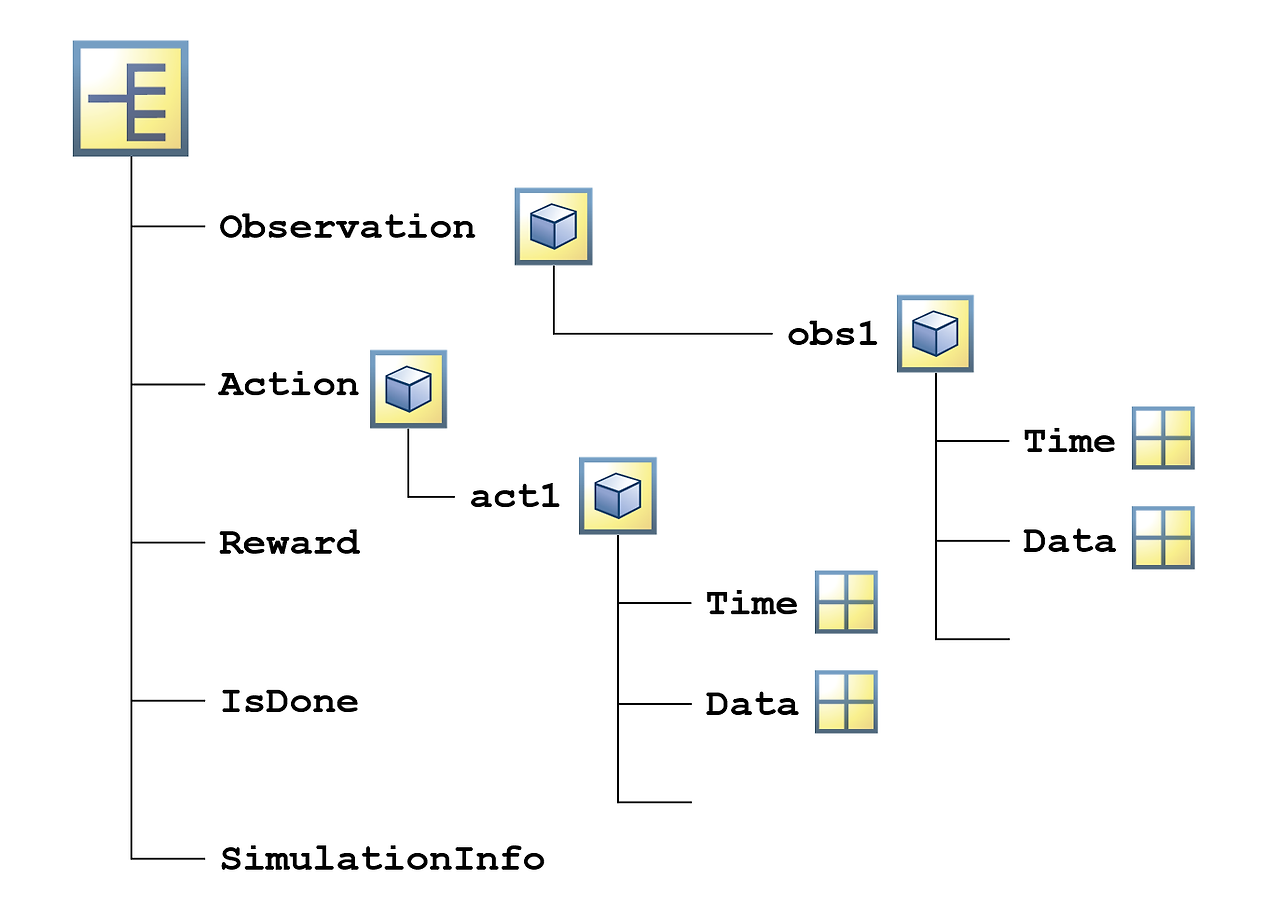
시뮬레이션의 출력값은 구조체에 패키징됩니다.
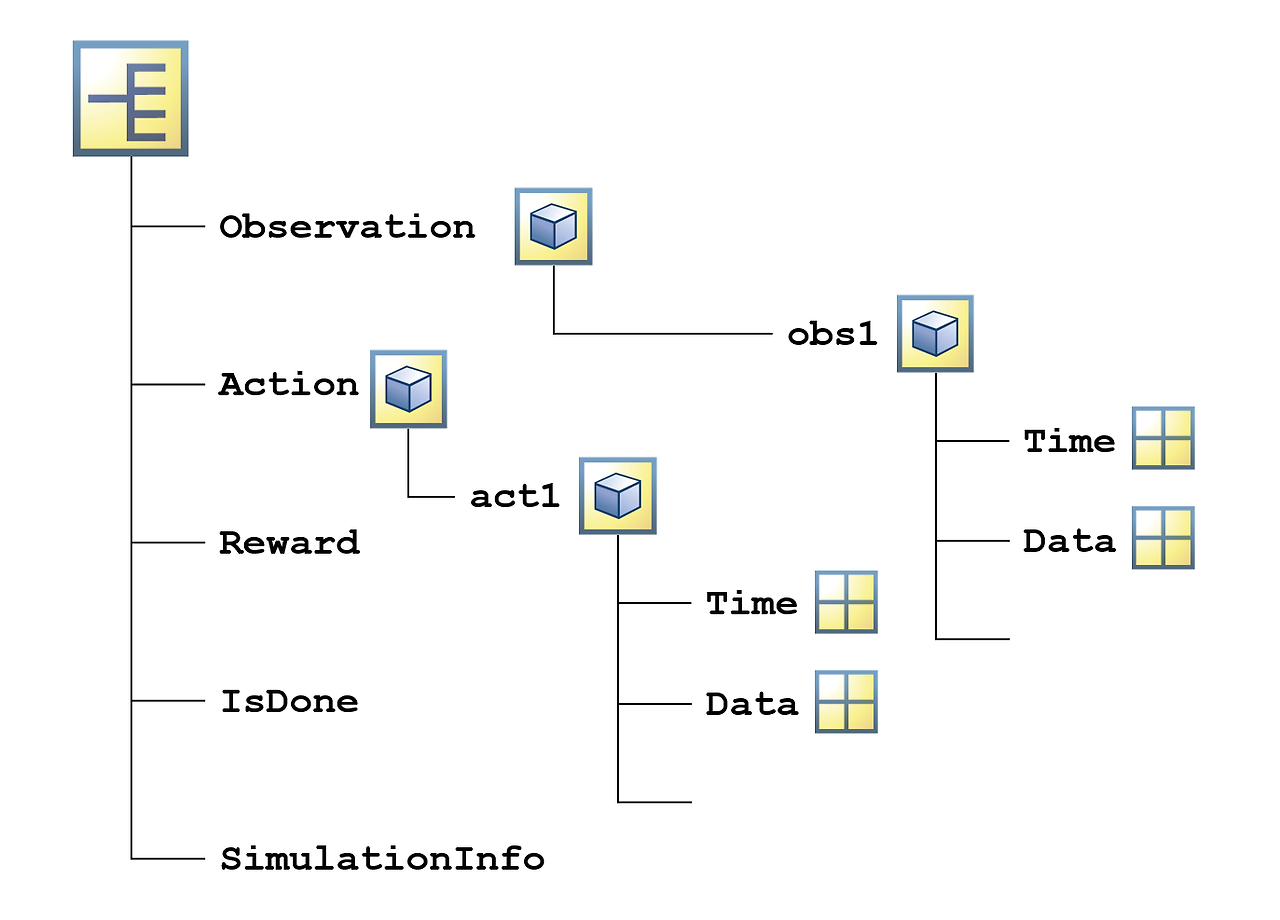
점 인덱싱을 사용하여 특정 정보를 추출할 수 있습니다. 예를 들어 다음 명령은 각 시간 스텝에서 에이전트가 취한 행동을 추출합니다.
actions = out.Action.act1.Data
작업
점 인덱싱을 사용하여 simout의 관측값(observation) 데이터를 obs라는 변수로 추출하세요.
obs= simout.Observation.obs1.Data
창고 로봇이 확인하는 요소
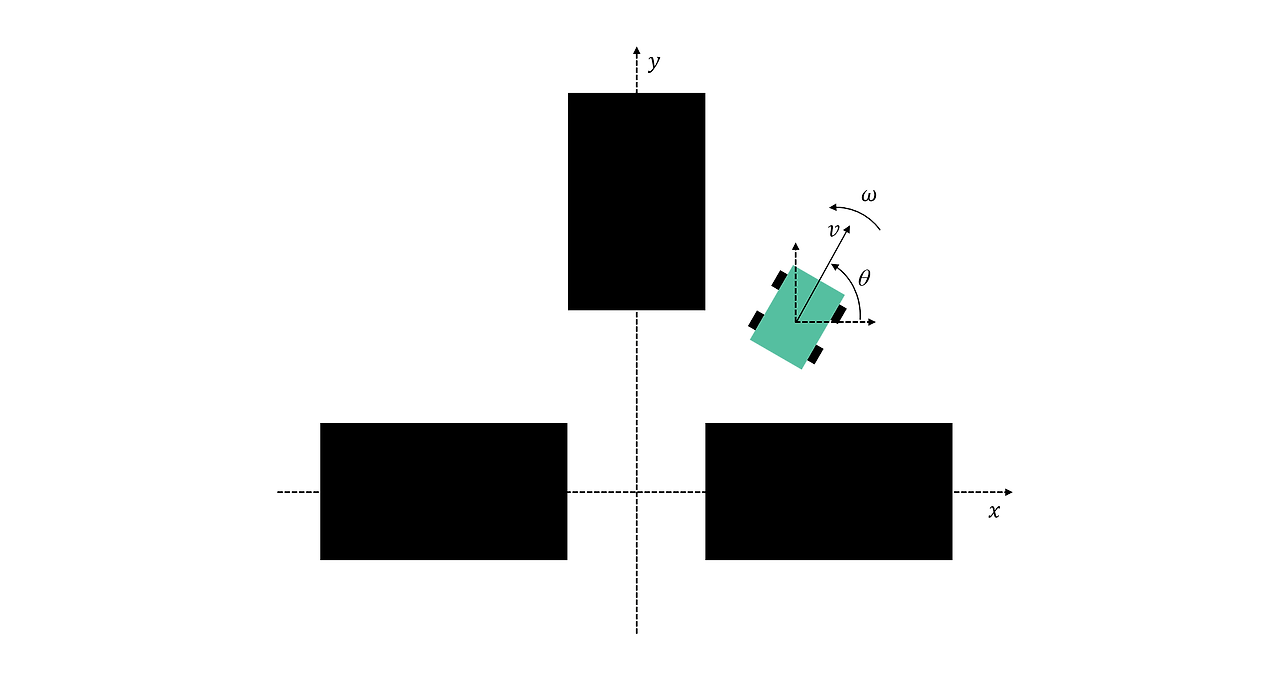
로봇은 자신의 위치(x,y), 방향(θ), 움직임(병진 속도 v와 회전 속도 ω=θ)을 관측할 수 있습니다.
위치는 선반에 맞춰 정렬된 좌표로 지정되므로 원점이 세 선반 사이에 위치합니다. 로봇은 방향에 대해 단순히 θ가 아니라, sin(θ)와 cos(θ)를 사용합니다. 즉, 값은 범위 [-1,1] 이내이며 급격하게 변하지 않습니다(예: 359°에서 0°로 변동되지 않음).
따라서 로봇의 상태는 다음과 같은 총 6개의 관측값으로 주어집니다. x,y,sin(θ),cos(θ),v,ω.
시뮬레이션 출력값은 시뮬레이션의 각 시간 스텝에서의 관측값, 행동 및 보상을 포함합니다. 각 시간 스텝에서의 관측값이 행렬일 수 있기 때문에, 전체 관측값 집합은 시간 스텝에 대응되는 세 번째 차원과 함께 3차원 배열로 저장됩니다. 하지만 이 경우에는 각 시간 스텝에서의 관측값이 6×1 열 벡터입니다.
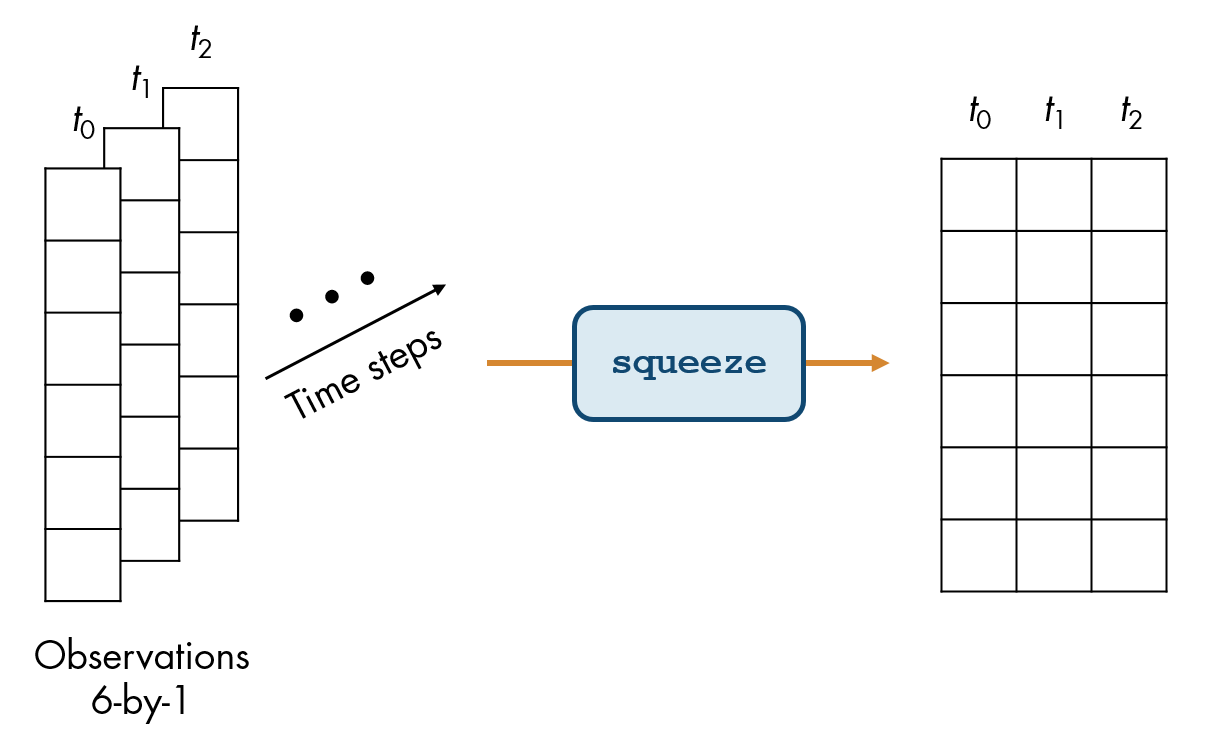
squeeze 함수를 사용하여 배열에서 길이가 1인 차원을 제거할 수 있습니다.
smaller = squeeze(fulldata)
작업
squeeze 함수를 사용하여 obs를 6×1×nsteps 배열에서 6×nsteps 행렬로 축소하세요. 결과를 obsmat라는 행렬에 저장하세요.
obsmat = squeeze(obs)
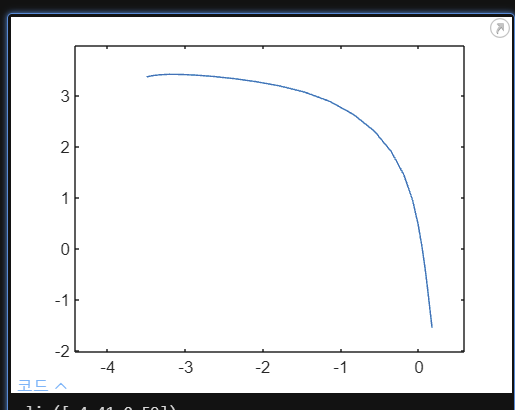
이제 관측값이 행렬로 저장되기 때문에 플로팅하고 분석하기가 더 쉽습니다. 관측값으로 구성된 행렬의 각 행은 시간 경과에 따라 관측된 단일 변수를 나타냅니다. 관측된 처음 2개의 변수는 로봇의 x, y 위치입니다.
작업
obsmat의 첫 번째 행을 x라는 벡터로 추출하고 두 번째 행을 y라는 벡터로 추출하세요. x에 대해 y를 플로팅하세요.
x= obsmat(1,:)
y = obsmat(2,:)
plot(x,y)
시간 경과에 따른 관측값과 행동을 종종 시각화해야 할 수 있습니다. 관측값은 Data 속성에 저장되어 있습니다. 해당 시간은 Time 속성에 저장되어 있습니다.
작업
simout에서 관측값 시간을 t라는 벡터로 추출하세요. 회전 속도(obsmat의 6번째 행)를 t의 함수로 플로팅하세요.
t = simout.Observation.obs1.Time
plot(t,obsmat(6,:))

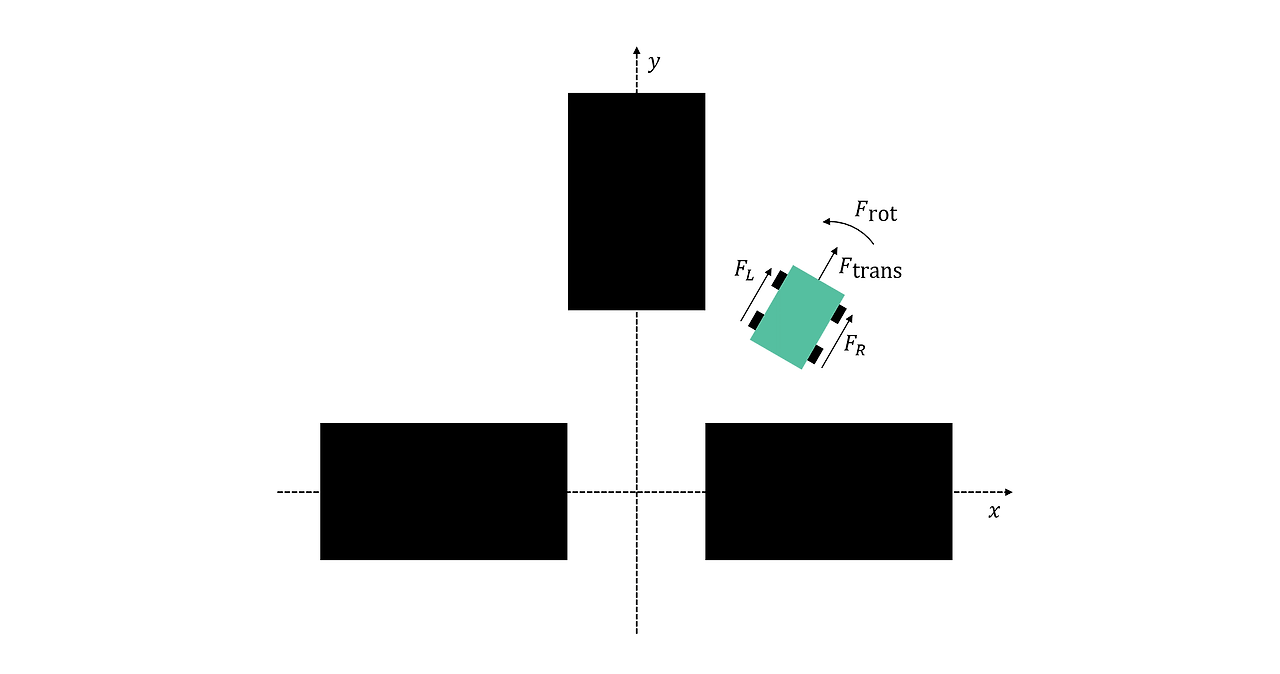
로봇이 취한 행동을 조사할 때 동일한 접근 방식을 이용할 수 있습니다. 로봇은 차동 구동을 사용합니다. 즉, 로봇의 왼쪽( FL) 바퀴와 오른쪽( FR) 바퀴에 개별적으로 힘을 가할 수 있습니다. 수학적으로, 이는 병진력과 회전력을 적용하는 것, 즉 Ftrans = 1/2 (FR + FL )과 Frot = 1/2 (FR – FL)을 적용하는 것과 동일합니다.
모델은 병진력과 회전력을 행동으로 사용합니다. 힘은 범위 [-1,1] 내로 정규화됩니다. 병진력이 +1 또는 -1이면 모든 바퀴가 각각 전속력으로 앞으로 움직이거나 또는 뒤로 움직입니다. 회전력이 -1(시계 방향) 또는 +1(반시계 방향)이면 모든 바퀴가 전속력으로 움직입니다. 방향은 서로 반대입니다.
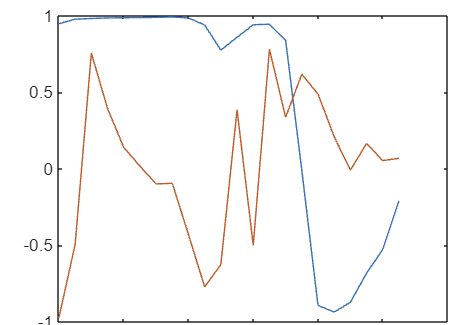
다음 코드를 사용하여 병진력과 회전력을 플로팅할 수 있습니다.
act = squeeze(simout.Action.act1.Data);
t = simout.Action.act1.Time;
Ftrans = act(1,:);
Frot = act(2,:);
plot(t,Ftrans,t,Frot)MATLAB 툴스트립에서 실행 또는 섹션 실행 버튼을 클릭하여 스크립트를 실행할 수 있다는 점을 기억하세요.
실습을 마쳤으면 다음 섹션으로 진행할 수 있습니다.
시뮬레이션의 특성(예: 필요한 최대 시간 스텝 수)을 제어해야 할 수 있습니다. 이전 활동에서는 디폴트 설정으로 시뮬레이션했습니다. 디폴트 설정을 보려면, rlSimulationOptions 함수를 사용하여 디폴트 시뮬레이션 설정을 포함하는 변수를 만들면 됩니다.
opts = rlSimulationOptions
작업
rlSimulationOptions 함수를 사용하여 디폴트 시뮬레이션 설정을 포함하는 opts라는 변수를 만드세요. 라인 끝에 있는 세미콜론을 제거하여 출력값을 확인할 수 있도록 하세요.
opts = rlSimulationOptions
불완전한 환경에서 창고 로봇 테스트하기
선반 사이로 창고 로봇을 조종하는 에이전트는 이전 시스템에서 제어권을 받아 로봇을 선반 사이의 틈 가까이로 이동시킵니다. 하지만 이 이전 제어 시스템은 항상 로봇을 완벽히 일관된 상태로 두지는 않습니다. 시뮬레이션에서 이를 나타내기 위해 로봇은 파란색으로 음영 처리된 영역(아래에 표시) 내의 임의 위치에서 임의로 초기 움직임을 시작합니다.
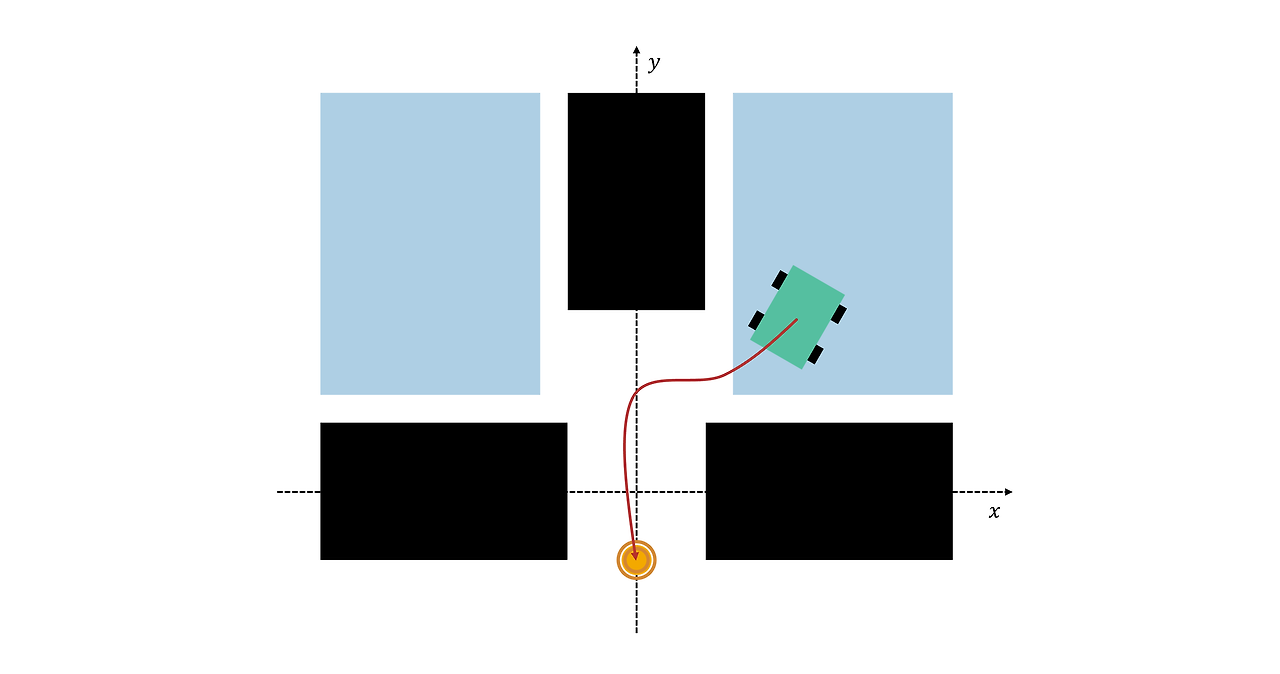
우수한 제어기는 다양한 상황에서도 제대로 작동할 수 있습니다. 에이전트의 성능을 테스트하기 위해 서로 다른 초기 상태로 여러 개의 시뮬레이션을 실행해야 할 수 있습니다. 실행할 시뮬레이션 수는 설정할 수 있는 옵션 중 하나입니다.
설정할 수 있는 또 다른 옵션은 시뮬레이션 시간 스텝의 최대 수입니다. whrobot.slx 모델은 로봇이 목표에 도달하거나 선반에 부딪히면 시뮬레이션을 종료합니다. 그렇지 않으면 로봇은 모델에 설정된 시뮬레이션 중지 시간까지 실행됩니다. 적절한 시간 내에 로봇이 목표에 도달하기를 바란다는 점에서 시뮬레이션 시간에 상한을 설정할 수 있습니다.
옵션 이름과 값을 쌍으로 지정하여 옵션을 설정할 수 있습니다.
opts = rlSimulationOptions("Option1",value1,...
"Option2",value2)옵션은 순서에 상관없이 원하는 개수만큼 설정할 수 있습니다.
whrobot 모델에서 로봇 제어기는 0.25초마다 작동합니다. 시뮬레이션 스텝의 최대 수를 100으로 설정하면 로봇이 출구를 찾지 못하거나 출구를 찾기 전에 선반에 부딪히는 경우 25초 후에 각 시뮬레이션이 종료됩니다. (참고로, 시뮬레이션은 실제 시간보다 훨씬 더 빨리 실행됩니다. 따라서 시뮬레이션 시간 25초를 실행하는 데는 불과 몇 초밖에 걸리지 않습니다.)
작업
rlSimulationOptions 함수를 사용하여 "MaxSteps" 옵션은 100으로, "NumSimulations" 옵션은 5로 설정된 시뮬레이션 설정을 포함하는 opts라는 변수를 만드세요.
opts = rlSimulationOptions("MaxSteps",100,...
"NumSimulations",5)
시뮬레이션 옵션을 sim 함수에 추가 입력값으로 전달할 수 있습니다.
opts = rlSimulationOptions(...);
out = sim(agent,environment,opts)작업
sim 함수에서, opts에 있는 시뮬레이션 옵션을 사용하여 로봇 모델의 여러 시뮬레이션을 실행하세요. 환경과 RL 에이전트는 각각 변수 env와 agent에 저장되어 있습니다. 시뮬레이션의 결과를 simout이라는 변수에 저장하세요.
simout = sim(agent,env,opts)
옵션을 변경하여 시뮬레이션을 추가로 수행해 봅니다. (초기화 코드에서) 난수 시드값을 변경하여 다른 임의 초기 시작 조건으로 시뮬레이션할 수도 있습니다.
최대 시뮬레이션 시간을 변경하면 결과가 달라질까요? 에이전트가 목표에 도달하기 전에 시간이 다 지나가나요?
이전 활동에서 단일 구조체에 저장된 단일 시뮬레이션에서 출력값을 추출하는 방법을 살펴보았습니다. 여러 시뮬레이션의 출력값은 구조체형 배열로 저장됩니다. 다음 활동에서는 이러한 결과를 조사해 보겠습니다.
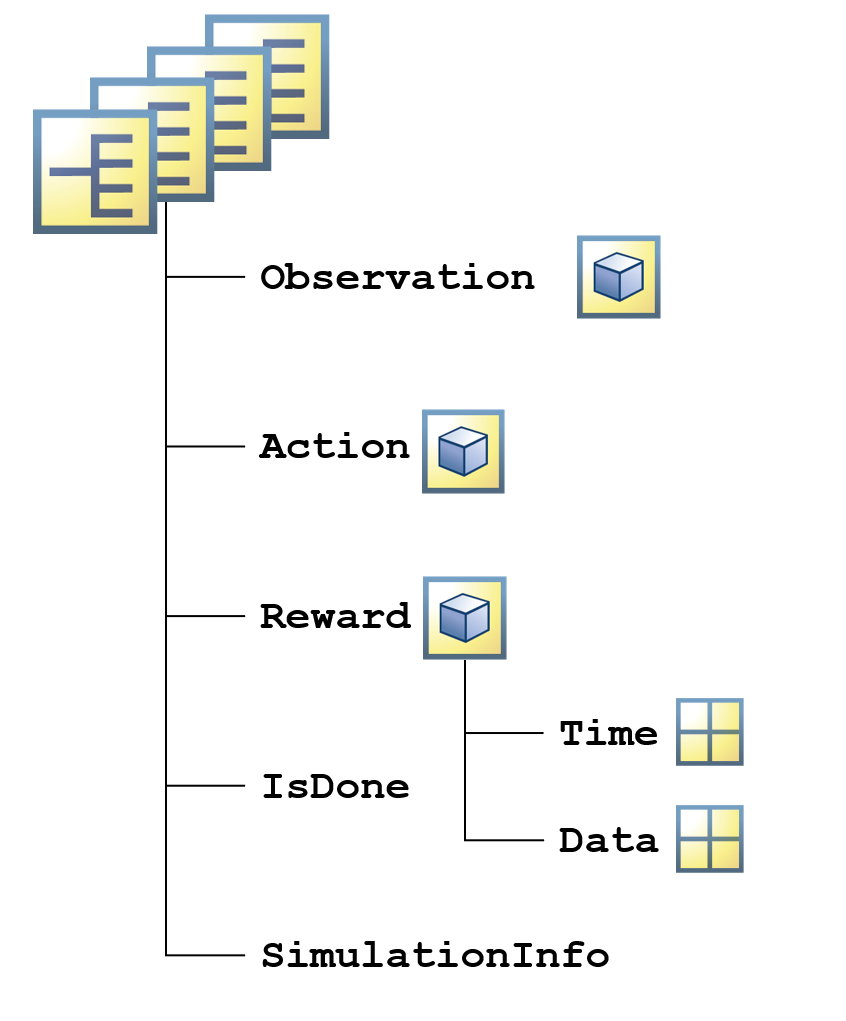
여러 시뮬레이션에 대한 출력값은 구조체형 배열에 저장되고, 구조체형 배열의 각 요소에 단일 시뮬레이션의 결과가 포함되어 있습니다. 표준 배열 인덱싱을 사용하여 단일 시뮬레이션을 추출할 수 있습니다.
onesim = simout(k)
작업
첫 번째 시뮬레이션의 결과(simout의 첫 번째 요소)를 s라는 변수로 추출하세요.
s = simout(1)
에이전트는 환경으로부터 받는 보상의 크기를 최대화하도록 훈련됩니다. 보상은 에이전트가 목표를 향해 얼마나 잘 진행하고 있는지 평가하는 함수입니다. 시간 경과에 따른 보상을 시각화하면 에이전트 성능을 파악할 수 있습니다.
창고 로봇 에이전트는 보상으로 훈련되었습니다. 보상은 목표 위치에 근접할수록 증가하고 목표에 도달하면 큰 보너스를 주지만 선반에 부딪히면 큰 벌점을 부과합니다.
작업
점 인덱싱을 사용하여 s의 시간 값과 보상 값을 각각 t와 r이라는 변수로 추출하세요.
t = s.Reward.Time
r = s.Reward.Data
작업
보상 r을 시간 t의 함수로 플로팅하세요.
plot(t,r)
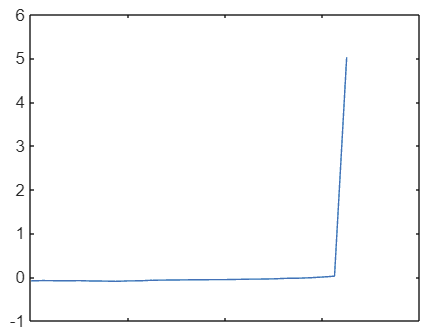
시뮬레이션 출력값의 요소를 순환하며 실행하여, 개별 시뮬레이션을 모두 분석할 수 있습니다.
figure
hold on
for k = 1:numsim
% analyze kth simulation
end
hold off시뮬레이션마다 시간 스텝 수가 다를 수 있기 때문에, 벡터화된 연산을 사용하기보다 루프를 사용하는 것이 가장 간단할 수 있습니다.
작업
위에 주어진 프레임워크 코드를 사용하여 10개 시뮬레이션 모두에 대해 작업 1~3을 반복하고 동일한 좌표축에 모든 보상을 플로팅하세요. 그리고 루프의 각 반복 시 k번째 시뮬레이션의 데이터를 추출하도록 작업 1의 코드를 반드시 수정하세요. 또한 hold on 명령에 이전 작업의 플롯이 포함되지 않도록, 프레임워크 코드에서 figure 명령을 반드시 포함시키세요.
figure
hold on
for k = 1:10
s = simout(k)
plot(s.Reward.Time,s.Reward.Data)
end
hold off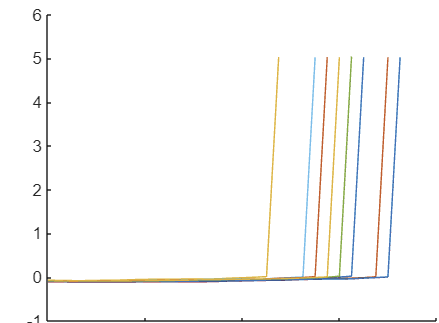
로봇은 목표에 도달하면 상당히 큰 긍정적인 보상(양의 보상)을 받고, 선반에 부딪히면 벌점(음의 보상)을 받습니다. 이 같은 큰 값을 사용할 경우 최종 상태에 이르기 전까지의 보상의 변동을 파악하기가 어려울 수 있습니다. 대화형 방식 플롯 툴 또는 ylim([ymin ymax])를 사용하여 y축 제한을 변경해 보세요.
각 시뮬레이션에서 획득한 총 보상을 통해 에이전트의 전반적인 성능을 평가할 수 있습니다. sum(r)을 계산하고 결과를 벡터의 k번째 요소에 저장해 보세요. 총계로 구성된 벡터에 대한 히스토그램을 만드세요.
이 예제를 컴퓨터에서 자세히 살펴보고자 한다면 오른쪽 위 코너에 있는 도움말 메뉴에서 Simulink 모델과 MAT 파일이 포함되어 있는 교육과정 파일을 다운로드할 수 있습니다.
'인공지능 > 강화학습' 카테고리의 다른 글
| matlab 강화학습 onramp 3 - 환경 정의하기 (0) | 2024.05.09 |
|---|---|
| matlab 강화학습 onramp 2 - 강화 학습 모델의 구성 요소 (0) | 2024.05.09 |
| matlab 강화학습 - 다중 에이전트 강화 학습 (0) | 2024.05.08 |
| Matlab 강화학습 - 실질적인 문제 극복하기 (0) | 2024.05.08 |
| 딥러닝 강화학습을 통해 워킹 로봇 작동하기 matlab (0) | 2024.05.08 |