게임을 잘 하려면 여러가지 시도를 통해 학습을 해야한다.
에이전트는 환경과 상호작용하며 게임의 참가자이다.
환경은 관측치를 에이전트에게 넘겨준다.
에이전트는 액션을 통해 환경을 변화할 수 있다.

여기서 환경은 시뮬링크 모델을 통해 시뮬레이션 된다.
모든 값들은 Matlab에서 변수로 표현된다.
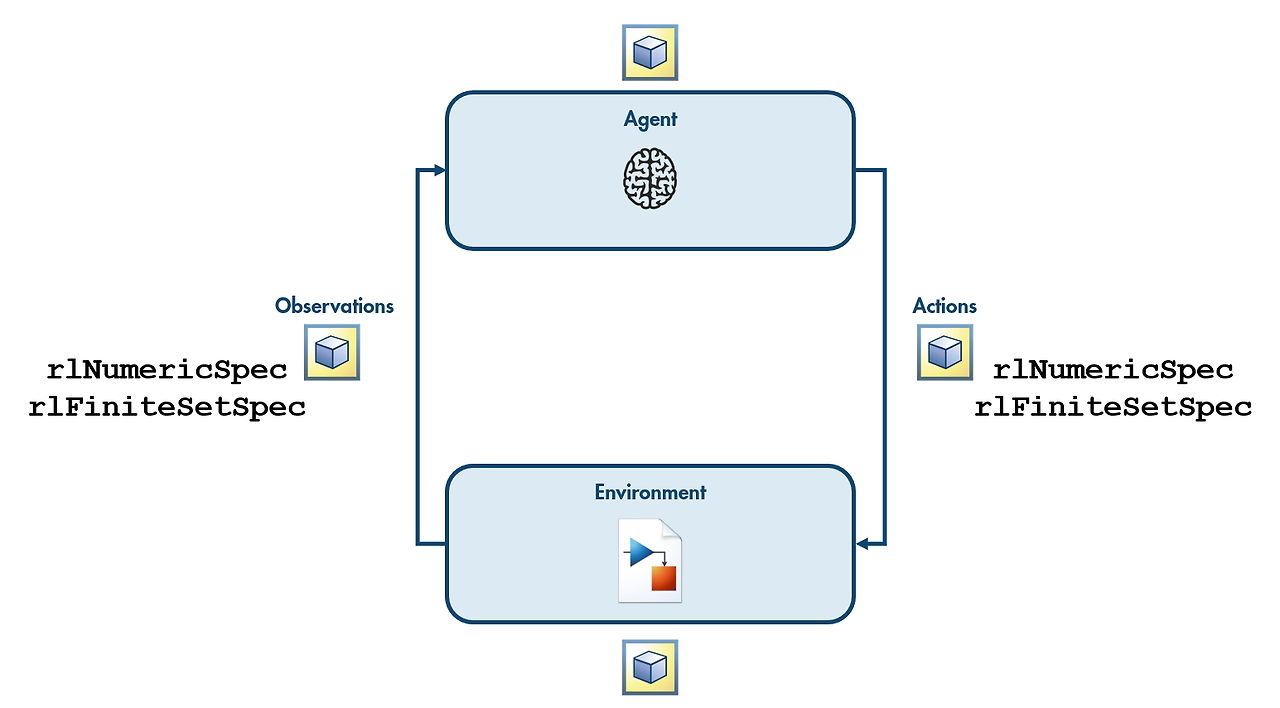
에이전트, 환경, 관측값, 행동은 모두 MATLAB에서 변수로 표현됩니다.관측값과 행동을 정의할 방법을 지정하려면 rlNumericSpec 함수 또는 rlFiniteSetSpec 함수를 사용합니다.
관측 가능 상태 또는 가능한 행동으로 구성된 유한 집합이 있는 경우에는 rlFiniteSetSpec을 사용합니다.
관측값 또는 행동이 유한 집합을 형성하지 않는 숫자형 값으로 지정된 경우에는 rlNumericSpec을 사용합니다.
관측값과 행동은 서로 다른 유형이어도 함께 사용할 수 있습니다.

Simulink 모델에서 환경 변수를 정의하려면 rlSimulinkEnv 함수를 사용합니다. rlSimulinkEnv 함수에 대한 입력값은 Simulink 모델의 이름, 관측값 사양을 정의하는 변수, 행동 사양을 정의하는 변수입니다.
주사위 선택 게임
이 게임은 간단합니다. 색이 서로 다른 주사위 5개가 있고, 주사위마다 서로 다른 숫자가 적혀 있습니다. 1과 20 사이의 임의 초기 목표값이 주어지면 주사위 중 하나를 선택하고 굴리세요. 목표값과 굴려서 나온 값 간의 차이가 새 목표값이 됩니다. 목표는 가능한 한 빨리 목표값을 0으로 만드는 것입니다.
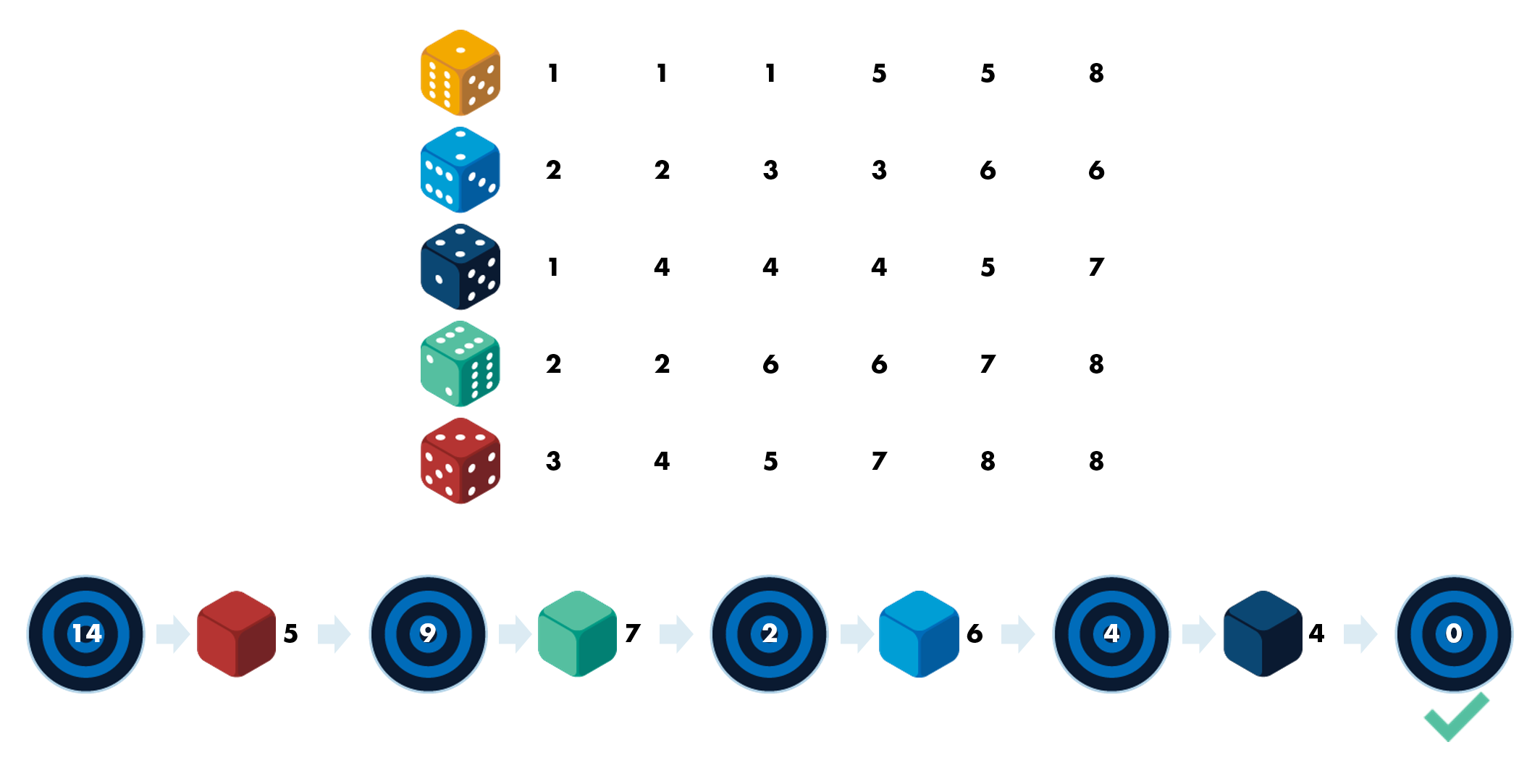
이 게임은 Simulink 모델 targetDice.slx에 구현되어 있습니다. 이 예제를 컴퓨터에서 자세히 살펴보고자 한다면 오른쪽 위 코너에 있는 도움말 메뉴에서 targetDice.slx가 포함되어 있는 교육과정 파일을 다운로드할 수 있습니다.
목표값은 0에서 20까지의 정수 값일 수 있습니다. 목표값은 항상 음이 아닌 값입니다. 0은 게임의 종료 상태를 나타내는 유효한 상태입니다.
작업
콜론 연산자(:)를 사용하여 정수 값 0, 1, ..., 20이 포함된 states라는 벡터를 만드세요.
states = (0:1:20)
이렇게나
states = 0:20으로 하네요...
게임 참가자가 행렬 d의 행으로 표현된 5개 주사위 중에서 하나를 고릅니다.
작업
콜론 연산자를 사용하여 정수 값 1, 2, 3, 4, 5가 포함된 choices라는 벡터를 만드세요.
choices = 1:5
환경 변수를 만들려면 관측값과 행동을 표현하기 위한 변수를 정의해야 합니다.

게임 참가자는 1개의 스칼라 값 즉, 현재 목표값(states의 어떤 값이든 가능)을 관측할 수 있습니다.
rlFiniteSetSpec 함수를 사용하여, 유한한 관측 가능 상태 집합을 표현하기 위한 변수를 만들 수 있습니다.
obs = rlFiniteSetSpec(values)
작업
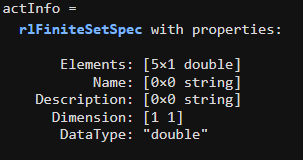
rlFiniteSetSpec 함수를 사용하여, 주사위 게임의 가능한 관측값(벡터 states에 저장되어 있음)을 표현하는 obsInfo라는 변수를 만드세요.
obsInfo = rlFiniteSetSpec(states)

게임 참가자가 5개 주사위 중에서 하나를 고릅니다. 마찬가지로, rlFiniteSetSpec 함수를 사용하여, 유한한 행동 집합을 표현하기 위한 변수를 만들 수 있습니다.
작업
rlFiniteSetSpec 함수를 사용하여, 주사위 게임의 가능한 행동(벡터 choices에 저장되어 있음)을 표현하는 actInfo라는 변수를 만드세요.
actInfo = rlFiniteSetSpec(choices)
게임 모델링하기
Simulink 모델 targetDice.slx가 주사위 게임을 합니다. "RL die chooser" 블록으로 표현되는 RL 에이전트가 굴릴 주사위를 고릅니다. 에이전트가 선택한 주사위로 서브시스템 "roll and recalculate"가 게임의 한 단계를 진행합니다.

Simulink 모델 modelname.slx로 시뮬레이션된 환경을 표현하는 변수를 rlSimulinkEnv 함수를 사용하여 만들 수 있습니다.
env = rlSimulinkEnv("modelname",...
"modelname/RL agent block name",...
obsInfo,actInfo)작업
rlSimulinkEnv 함수를 사용하여, Simulink 모델 targetDice.slx의 환경을 표현하는 slEnv라는 변수를 만드세요. RL 에이전트는 targetDice 모델의 "RL die chooser"라는 블록에 정의되어 있습니다.
slEnv= rlSimulinkEnv("targetDice",...
"targetDice/RL die chooser",...
obsInfo,actInfo)
이후 활동에서는 에이전트를 만들고 훈련시켜 보겠습니다 지금은 우선, 사전 훈련된 에이전트를 사용하여, 환경이 올바르게 설정되었는지 확인할 수 있습니다. MAT 파일 premadeagents.mat에는 2개의 저장된 에이전트가 포함되어 있습니다. 하나는 훈련된 에이전트이고, 다른 하나는 임의로 선택한 정책을 사용하는 에이전트입니다.
교육과정 예제 함수 playdice를 사용하면, 지정된 에이전트의 선택에 따른 행동으로 주사위 게임을 시뮬레이션한 결과가 표시됩니다.
작업
다음 명령을 사용하여,
load premadeagents
agent = trainedagent
[n,win] = playdice(agent,slEnv)
어떤 주사위를 굴릴지 선택하도록 사전 훈련된 에이전트로 주사위 게임을 시뮬레이션하세요.
load premadeagents
agent = trainedagent
[n,win] = playdice(agent,slEnv)
모델 파라미터 설정하기
Simulink 모델 targetDice.slx에서 주사위 굴리기는 난수를 사용해 시뮬레이션됩니다. 하지만 난수 생성기의 시드값은 고정되어 있습니다. 따라서 각 시뮬레이션에서 동일한 결과를 얻게 됩니다.
시드값은 모델 작업 공간의 변수 seed에 저장되어 있습니다. 모델을 실행할 때마다 seed를 새 값으로 설정하면 시뮬레이션이 무작위로 실시됩니다.
이 활동에서는 각 시뮬레이션을 실행하기 전에 초기화 함수를 적용하도록 시뮬레이션 환경을 수정합니다. 이 함수는 각 시뮬레이션에 서로 다른 난수가 사용되도록 seed의 값을 변경합니다.

Simulink 환경 변수에는 ResetFcn이라는 속성이 포함되어 있고, 이 속성에는 각 시뮬레이션 에피소드 전에 호출되는 함수가 들어 있습니다. 이 함수를 사용하여 환경 상태를 설정할 수 있습니다. 이렇게 하는 일반적인 이유는 모델에 임의의 변동을 추가하기 위함입니다.
점 인덱싱을 사용하여 ResetFcn 속성의 값을 설정할 수 있습니다. 함수를 지정하려면 함수 핸들(@)을 사용합니다.
env.ResetFcn = @myfun
작업
환경 slEnv에 대한 재설정 함수를 함수 randomstart로 설정하세요. 이 로컬 함수는 스크립트의 맨 끝에 정의되어 있습니다. 이 함수는 현재 아무런 영향을 미치지 않습니다.
slEnv.ResetFcn = @randomstart
재설정 함수는 한 개의 입력값을 받고 동일한 변수를 출력값으로 반환합니다. 이 변수가 Simulink 시뮬레이션 입력값입니다. Simulink 시뮬레이션 입력 변수를 setVariable 함수에 전달하여 Simulink 모델의 작업 공간 내에 있는 변수의 값을 설정할 수 있습니다.
siminput = setVariable(siminput,...
"varname",value,"Workspace","modelname")
작업
예제 코드를 사용하여 targetDice 모델의 작업 공간에서 seed 변수를 randi(1e5)(임의의 정수 값)로 설정하도록 randomstart 함수를 수정하세요.
function siminput = randomstart(siminput)
% siminput = setVariable(siminput,"varname",value,"Workspace","modelname");
siminput = setVariable(siminput,"seed",randi(1e5),"Workspace","targetDice");
end
이제 게임을 시뮬레이션하면 서로 다른 주사위가 구르게 됩니다.
작업
명령 [n,win] = playdice(agent,slEnv)를 사용하여, 어떤 주사위를 굴릴지 선택하는 사전 훈련된 에이전트 agent로 주사위 게임을 시뮬레이션하세요.
[n,win] = playdice(agent,slEnv)
연속 변수를 사용하여 환경 정의하기
창고 로봇의 환경
이 활동에서는 창고 로봇의 환경을 만듭니다. Simulink 모델 whrobot.slx는 로봇의 동특성을 시뮬레이션합니다. 로봇 에이전트는 6개의 연속 값 x,y,sin(θ),cos(θ),v,ω를 관측합니다. 그리고 두 개의 연속 행동 즉, 적용할 병진력과 회전력을 지정합니다. 이 두 요소는 범위 [-1 1]로 정규화됩니다.

관측값은 연속 숫자형 값입니다. rlNumericSpec 함수를 사용하여 관측값 차원을 입력값으로 받아 숫자형 관측 가능 상태를 표현하는 변수를 만들 수 있습니다.
obs = rlNumericSpec([m n])
작업
rlNumericSpec 함수를 사용하여 창고 로봇의 관측값을 나타내는 obsInfo라는 변수를 만드세요. 로봇은 6×1 숫자형 벡터 형식으로 6개 변수를 관측합니다.
obsInfo = rlNumericSpec([6 1])
행동이나 관측값에 물리적 제한이 있는 경우가 있습니다. 창고 로봇에서 행동은 범위 [-1 1]로 정규화된 힘입니다.
"LowerLimit" 옵션과 "UpperLimit" 옵션을 사용하여 숫자형 변수에 범위를 지정할 수 있습니다.
act = rlNumericSpec(dims,"UpperLimit",maxval)
작업
rlNumericSpec 함수를 사용하여 창고 로봇의 행동을 나타내는 actInfo라는 변수를 범위 [-1 1] 내의 힘으로 구성된 2×1 벡터 형식으로 만드세요.
힌트
차원의 벡터([2 1])를 rlNumericSpec 함수에 입력값으로 전달해 보세요. 두 쌍의 옵션 LowerLimit, -1과 UpperLimit, 1도 전달해 보세요. 결과를 actInfo에 할당해 보세요.
actInfo = rlNumericSpec([2,1],"LowerLimit",-1,"UpperLimit",1)
작업
rlSimulinkEnv 함수를 사용하여 Simulink 모델 whrobot.slx의 로봇 환경을 나타내는 env라는 변수를 만드세요. RL 에이전트는 "controller"(whrobot 모델에 있음)라는 블록에 정의되어 있습니다.
힌트
모델의 이름("whrobot"), RL Agent 블록의 이름("whrobot/controller"), 관측값 변수와 행동 변수(obsInfo와 actInfo)를 rlSimulinkEnv 함수에 입력값으로 전달해 보세요. 결과를 env에 할당해 보세요.
env = rlSimulinkEnv ("whrobot","whrobot/controller",obsInfo,actInfo)
작업
점 표기법을 사용하여 환경 env에 대한 재설정 함수를 함수 randomstart(스크립트의 맨 끝에 정의되어 있음)로 설정하세요.
힌트
randomstart에 대한 함수 핸들을 env.ResetFcn에 할당해 보세요. 함수 핸들은 함수 이름 앞에 @ 기호를 붙여 만들 수 있습니다.
env.ResetFcn = @randomstart
'인공지능 > 강화학습' 카테고리의 다른 글
| matlab 강화학습 onramp 4 - 보상에 행동 포함하기 (0) | 2024.05.09 |
|---|---|
| matlab 강화학습 onramp 3 - 환경 정의하기 (0) | 2024.05.09 |
| matlab 강화학습 onramp 1 - 강화 학습 개요 (0) | 2024.05.08 |
| matlab 강화학습 - 다중 에이전트 강화 학습 (0) | 2024.05.08 |
| Matlab 강화학습 - 실질적인 문제 극복하기 (0) | 2024.05.08 |