728x90
728x90
with open('Korean_movie_reviews_2016.txt/Korean_movie_reviews_2016.txt', encoding='utf-8') as f:
docs = [doc.strip().split('\t') for doc in f]
docs = [(doc[0], int(doc[1])) for doc in docs if len(doc) == 2]
texts, labels = zip(*docs)
words_list = [doc.strip().split() for doc in texts]
print(words_list[:2])[['부산', '행', '때문', '너무', '기대하고', '봤'], ['한국', '좀비', '영화', '어색하지', '않게', '만들어졌', '놀랍']]
파일 열어서 문장별로 단어들 토큰화하기
total_words = []
for words in words_list:
total_words.extend(words)
from collections import Counter
c = Counter(total_words)
max_features = 10000
common_words = [ word for word, count in c.most_common(max_features)]
# 빈도를 기준으로 상위 10000개의 단어들만 선택
# 각 단어에 대해서 index 생성하기
words_dic ={}
for index, word in enumerate(common_words):
words_dic[word]=index+1
# 각 문서를 상위 10000개 단어들에 대해서 index 번호로 표현하기
filtered_indexed_words = []
for review in words_list:
indexed_words=[]
for word in review:
try:
indexed_words.append(words_dic[word])
except:
pass
filtered_indexed_words.append(indexed_words)토큰들 일정 비율 이상들만 써서 인덱스화 하기
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.utils import to_categorical
# X input padding
max_len = 40
X = sequence.pad_sequences(filtered_indexed_words, maxlen=max_len)
# y to one-hot category labeling
y_one_hot = to_categorical(labels)패딩처리 진행해주고, classification진행할거니까 카테고리컬로 라벨 나눠주기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_one_hot, test_size=0.2)
print(len(X_train))
print(len(X_test))test, train데이터 나눠주기!
from tensorflow.keras import layers
from tensorflow.keras import models
model = models.Sequential()
model.add(layers.Embedding(max_features+1, 64, input_shape=(max_len,))) # 토큰들 64차원으로 임베딩 하기
model.add(layers.Bidirectional(layers.LSTM(32), merge_mode='concat')) # 양방향을 각각 진행하겠다.
model.add(layers.Dense(2, activation = 'softmax')) # 이진분류
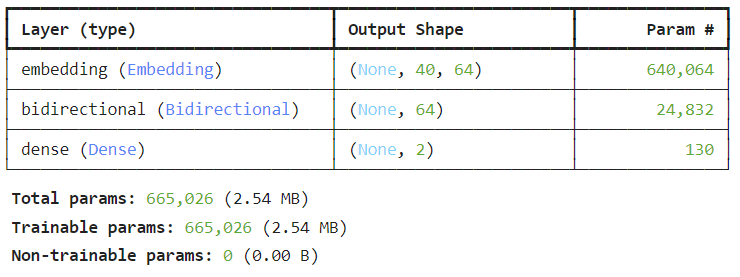
model.summary()model 만들기
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.optimizers import RMSprop
# early stopping 적용
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=5)
# local에 저장하고 싶을 경우 이용
#checkpoint_filepath = './temp/checkpoint_bi_lstm_kr'
#mc = ModelCheckpoint(checkpoint_filepath, monitor='val_loss', mode='min', save_weights_only=True, save_best_only=True)
# optimizer에 필요한 옵션 적용
# loss와 평가 metric 적용
model.compile(optimizer=RMSprop(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])모델에 각종 파라미터, optimizer, lossfunction 등 입력해주기
history = model.fit(X_train, y_train, epochs=5, batch_size=128, validation_split=0.1, callbacks=[es])학습한다!
# Training history plot
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()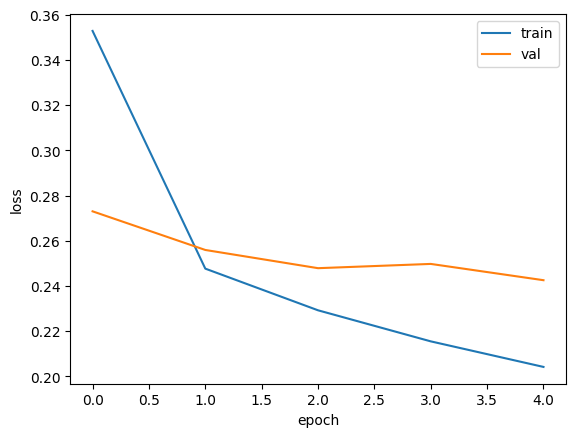
학습 그래프
test_loss, test_acc = model.evaluate(X_test, y_test) # CNN보다 성능이 훨씬 좋다.
print("Loss:", test_loss)
print("Accuracy:", test_acc)test 결과!

728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 한->영 번역기 만들기 python 실습 - seq2seq, LSTM, GRU, BLEU score (0) | 2024.05.05 |
|---|---|
| seq2seq 번역 모델 만들기 (0) | 2024.05.03 |
| 자연어 처리 python 실습 - 한to영 기계 번역 모델 학습 및 평가 (1) | 2024.04.26 |
| 자연어 처리 python 실습 - 한국어 기계 번역 데이터 수집 및 전처리 (0) | 2024.04.26 |
| 자연어 처리 기계 번역 - 딥러닝 기반 기계 번역 연구 동향, 발전 방향 (0) | 2024.04.26 |