Introduction
Chapter 8. 기계 번역 (Machine Translation) Task 강의의 한국어 기계 번역 실습 (2) 기계 번역 모델 학습 및 평가 강의입니다.
이번 실습에서는 이전 실습 강의에서 진행했던 한국어-영어 번역 모델을 학습하기 위한 한국어-영어 병렬 코퍼스 수집 및 전처리 과정에 이어서, Seq2Seq Transformer를 기반으로하는 한국어-영어 번역 모델을 직접 학습하고 평가해봅니다.
1. 데이터셋 수집
오늘 학습에서는 AI Hub에서 제공하는 한국어-영어 번역(병렬) 말뭉치의 샘플 데이터를 사용합니다.
(본 데이터 사용에 제한은 없으나, 간단한 신청 절차를 거친 후 사용해야하므로, 본 데이터셋을 모두 학습에 활용해보고 싶은 분은 데이터를 신청하고 사용하실 수 있습니다!)
1.1. 데이터셋 특징
본 데이터셋은 AI 번역 엔진 개발을 위한 뉴스(80만 장), 정부/지자체 홈페이지, 간행물(10만 문장), 행정 규칙, 자치법규(10만 문장), 한국 문화(10만 문장), 구어체(40만 문장), 대화체(10만 문장)의 학습용 문장으로 구축된 한국어-영어 번역 작업을 위한 병렬 데이터셋입니다.
데이터 통계는 다음과 같습니다.
문장이 많아서 이 데이터셋을 모두 활용하면 좋은 결과가 나온다.
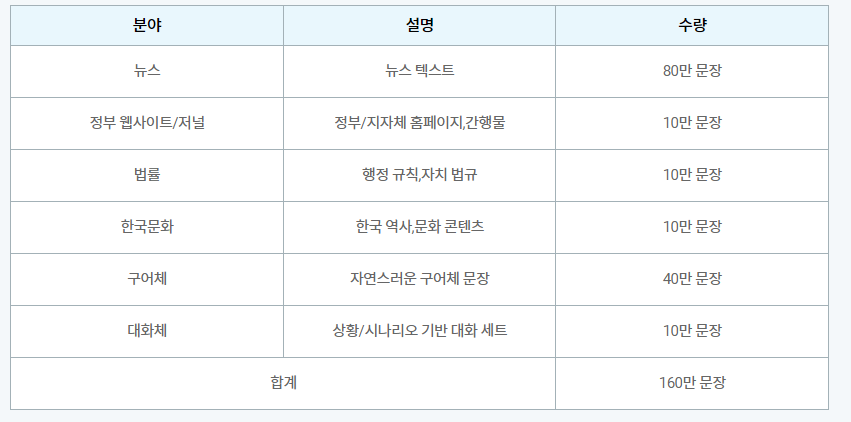
아까 말했듯, 오늘 실습에서는 위 데이터 대신 샘플 데이터 중 대화체에 해당하는 파일으로 학습을 진행할게요.
해당 데이터셋의 본래 파일명은 2_대화체_190920.xlsx이지만, 파일을 읽을 때 부작용이 없도록 2_conversation_200226.xlsx로 변경하여 사용합니다.
영어 형식으로 이름을 변경해준 것이다.
import pandas as pd
from tqdm import tqdm
raw_dataset = pd.read_excel('/content/2_conversation_200226.xlsx')
raw_dataset
한국어랑 영어 데이터만 사용하면 된다.
source_dataset = list(raw_dataset['한국어'])
target_dataset = list(raw_dataset['영어']) # 영어 column에 대해 리스트로 사용한다.
print(f"source_dataset 크기 : {len(source_dataset)}")
print(f"target_dataset 크기 : {len(target_dataset)}")source_dataset 크기 : 11756
target_dataset 크기 : 11756
이번에는 각각 토큰화를 따로 하고, 사전을 따로 만들어준다.
2. 데이터셋 전처리
2.1. 데이터 토큰화
이번 실습에서는 데이터 토큰화를 위해 다음과 같은 토큰 분절 방식을 사용합니다.
- 한국어 : konlpy의 Hannanum 토크나이저
- 영어 : spacy 패키지의 영어 토크나이저
!pip install konlpy
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from konlpy.tag import Hannanum
kor_tokenizer = get_tokenizer(Hannanum().morphs) # 한나눔의 형태소 분석기
eng_tokenizer = get_tokenizer('spacy', language='en')2.2. 원본, 타겟 언어 Vocabulary 만들기
앞선 실습에서처럼 원본, 타겟 언어 각각에 대한 단어 사전을 만들어야 합니다.
def vocab_iterator(strings, tokenizer):
for string_ in tqdm(strings):
yield tokenizer(string_) # 스트링에 대한 토큰 결과를 내보낸다.[UNK]를 기본 인덱스로 설정합니다. 이 인덱스는 토큰을 찾지 못하는 경우에 반환됩니다.
만약 기본 인덱스를 설정하지 않으면 Vocabulary에서 토큰을 찾지 못하는 경우 RuntimeError가 발생합니다.
kor_vocab = build_vocab_from_iterator(vocab_iterator(source_dataset, kor_tokenizer), specials=['<PAD>', '<UNK>', '<SOS>', '<EOS>'], min_freq=5)
# 토큰화된 결과를 저 eos등을 추가하여 보캡으로 만들어준다.
kor_vocab.set_default_index(kor_vocab['<UNK>']) #키가 없는 단어를 어떻게 처리하겠냐100%|██████████| 11756/11756 [00:21<00:00, 540.99it/s]
eng_vocab = build_vocab_from_iterator(vocab_iterator(target_dataset, eng_tokenizer), specials=['<PAD>', '<UNK>', '<SOS>', '<EOS>'], min_freq=5)
eng_vocab.set_default_index(eng_vocab['<UNK>'])100%|██████████| 11756/11756 [00:01<00:00, 9678.75it/s]
2.3. 학습 데이터셋 구축
영어와 한국어 단어 사전(Vocabulary)를 기반으로 학습, 검증, 테스트 데이터셋을 구축합니다.
import torch
def data_process(source_dataset, target_dataset):
data = []
for (raw_kor, raw_eng) in tqdm(zip(source_dataset, target_dataset)):
kor_tensor_ = torch.tensor([kor_vocab[token] for token in kor_tokenizer(raw_kor)], dtype = torch.long)
# 문장 하나하나를 잘라서 토큰화 후 토큰을 인덱스로 치환하여 텐서형으로 바꿔준다.
eng_tensor_ = torch.tensor([eng_vocab[token] for token in eng_tokenizer(raw_eng)], dtype = torch.long)
data.append((kor_tensor_, eng_tensor_))
return data
train_dataset = data_process(source_dataset[:10000], target_dataset[:10000])
valid_dataset = data_process(source_dataset[10000:11000], target_dataset[10000:11000])
test_dataset = data_process(source_dataset[11000:], target_dataset[11000:])10000it [00:25, 396.36it/s]
1000it [00:02, 482.58it/s]
756it [00:01, 455.31it/s]
print(f"train_dataset 개수 : {len(train_dataset)}")
print(f"valid_dataset 개수 : {len(valid_dataset)}")
print(f"test_dataset 개수 : {len(test_dataset)}")train_dataset 개수 : 10000
valid_dataset 개수 : 1000
test_dataset 개수 : 756
데이터셋을 더 받아와서 사용한다고 해도, split을 잘 해야 한다.
사전 데이터만을 학습하고, 뉴스를 번역하면 성능이 떨어진다. 동일한 비율로 넣어줘야 한다.
2.4. Dataloader 선언
pad_sequence 함수를 활용하여 배치 내 가장 긴 길이에 맞춰 padding을 진행합니다.
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader
batch_size = 128
device = torch.device('cuda')
PAD_IDX = kor_vocab['<PAD>'] # kor과 eng의 인덱스가 이것들은 같다.
UNK_IDX = kor_vocab['<UNK>']
SOS_IDX = kor_vocab['<SOS>']
EOS_IDX = kor_vocab['<EOS>']
def generate_batch(dataset):
kor_batch, eng_batch = [], []
for (kor_item, eng_item) in dataset: #배치 구성을 이전에 했던 길이 맞춰주기로 진행
kor_batch.append(torch.cat([torch.tensor([SOS_IDX]), kor_item, torch.tensor([EOS_IDX])], dim=0))
eng_batch.append(torch.cat([torch.tensor([SOS_IDX]), eng_item, torch.tensor([EOS_IDX])], dim=0))
kor_batch = pad_sequence(kor_batch, padding_value=PAD_IDX) # 가장 긴것에 맞게 패딩 넣어준다.
eng_batch = pad_sequence(eng_batch, padding_value=PAD_IDX)
return kor_batch, eng_batch
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=generate_batch)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True, collate_fn=generate_batch)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True, collate_fn=generate_batch)3. 모델 클래스 선언
기계 번역 모델에는 Seq2Seq Transformer를 활용합니다.
인코더와 디코더 모두 있는 transformer이다.
from torch import Tensor
import torch.nn as nn
from torch.nn import Transformer
import math단어 순서 개념(notion)을 토큰 임베딩에 도입하기 위한 위치 인코딩(positional encoding)을 위한 클래스를 선언
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout: float, max_len: int = 5000):
super(PositionalEncoding, self).__init__()
den = torch.exp(- torch.arange(0, emb_size, 2)* math.log(10000) / emb_size)
# 사이즈에 따른 인코딩 값 만들기
pos = torch.arange(0, max_len).reshape(max_len, 1)
pos_embedding = torch.zeros((max_len, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.Dropout(dropout)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
return self.dropout(token_embedding + self.pos_embedding[:token_embedding.size(0), :])입력 인덱스의 텐서를 해당하는 토큰 임베딩의 텐서로 변환하기 위한 클래스를 선언
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)Se2SeqTransformer 모델 클래스를 선언합니다.
class Seq2SeqTransformer(nn.Module):
def __init__(self, # 설정해야할 파라미터들
num_encoder_layers: int,
num_decoder_layers: int,
emb_size: int,
num_head: int,
src_vocab_size: int,
tgt_vocab_size: int,
dim_feedforward: int = 512,
dropout: float = 0.1
): # 타겟과 소스의 임베딩이 다르므로 !
super(Seq2SeqTransformer, self).__init__()
self.transformer = Transformer(
d_model=emb_size,
nhead=num_head,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers,
dim_feedforward=dim_feedforward,
dropout=dropout
)
self.generator = nn.Linear(emb_size, tgt_vocab_size)
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)# 임베딩 사이즈는 동일해야 한다.
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
def forward(self,
src: Tensor,
trg: Tensor,
src_mask: Tensor,
tgt_mask: Tensor,
src_padding_mask: Tensor,
tgt_padding_mask: Tensor,
memory_key_padding_mask: Tensor
):
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
outs = self.transformer(src_emb, tgt_emb, src_mask, tgt_mask, None, src_padding_mask, tgt_padding_mask, memory_key_padding_mask)
return self.generator(outs) # 확률을 뱉어주니 argmax하면 가장 높은 확률 나온다.
def encode(self, src: Tensor, src_mask: Tensor):
return self.transformer.encoder(self.positional_encoding(self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor): # 인코더가 뱉은 애들을 받아서 출력 만들기
return self.transformer.decoder(self.positional_encoding(self.tgt_tok_emb(tgt)), memory, tgt_mask)def generate_square_subsequent_mask(sz):
mask = (torch.triu(torch.ones((sz, sz), device=device)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
src_mask = torch.zeros((src_seq_len, src_seq_len),device=device).type(torch.bool)
src_padding_mask = (src == PAD_IDX).transpose(0, 1) # 패딩인 경우 마스킹하지 않는다.
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask모델 파라미터를 설정합니다.
kor_vocab_size = kor_vocab.__len__()
eng_vocab_size = eng_vocab.__len__()
embedding_dim = 512
hidden_dim = 512
num_heads = 8
batch_size = 128
encoder_layer_num = 3
decoder_layer_num = 3
print(f"kor_vocab_len is {kor_vocab.__len__()}")
print(f"eng_vocab is {eng_vocab.__len__()}")kor_vocab_len is 2374
eng_vocab is 2281
torch.manual_seed(0)
model = Seq2SeqTransformer(encoder_layer_num, decoder_layer_num, embedding_dim, num_heads, kor_vocab_size, eng_vocab_size, hidden_dim)
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p) # 파라미터 초기화 구현!
model = model.to(device) # GPU에 올리기로스 함수와 옵티마이저를 선언합니다.
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX) # 패딩은 무시하도록!
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)4. 모델 학습 및 평가
from timeit import default_timer as timer
def train_epoch(model, optimizer, train_dataloader):
model.train()
losses = 0
for src, tgt in tqdm(train_dataloader):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :] # 입력 형식에 맞춰주기
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)
optimizer.zero_grad()
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
loss.backward()
optimizer.step() # 한스탭 훈련
losses += loss.item()
return losses / len(train_dataloader)def evaluate(model, valid_dataloader):
model.eval()
losses = 0
for src, tgt in valid_dataloader:
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
losses += loss.item()
return losses / len(valid_dataloader)num_epochs = 10
for epoch in range(1, num_epochs+1):
start_time = timer()
train_loss = train_epoch(model, optimizer, train_dataloader)
end_time = timer()
val_loss = evaluate(model, valid_dataloader)
print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Val loss: {val_loss:.3f}, "f"Epoch time = {(end_time - start_time):.3f}s"))100%|██████████| 79/79 [00:13<00:00, 5.83it/s]
Epoch: 1, Train loss: 5.649, Val loss: 4.917, Epoch time = 13.568s
100%|██████████| 79/79 [00:09<00:00, 7.98it/s]
Epoch: 2, Train loss: 4.688, Val loss: 4.314, Epoch time = 9.904s
100%|██████████| 79/79 [00:09<00:00, 7.98it/s]
Epoch: 3, Train loss: 4.228, Val loss: 4.032, Epoch time = 9.908s
100%|██████████| 79/79 [00:10<00:00, 7.90it/s]
Epoch: 4, Train loss: 3.954, Val loss: 3.850, Epoch time = 10.012s
100%|██████████| 79/79 [00:10<00:00, 7.82it/s]
Epoch: 5, Train loss: 3.743, Val loss: 3.687, Epoch time = 10.110s
100%|██████████| 79/79 [00:10<00:00, 7.78it/s]
Epoch: 6, Train loss: 3.565, Val loss: 3.560, Epoch time = 10.160s
100%|██████████| 79/79 [00:10<00:00, 7.75it/s]
Epoch: 7, Train loss: 3.408, Val loss: 3.493, Epoch time = 10.205s
100%|██████████| 79/79 [00:10<00:00, 7.75it/s]
Epoch: 8, Train loss: 3.270, Val loss: 3.388, Epoch time = 10.201s
100%|██████████| 79/79 [00:10<00:00, 7.71it/s]
Epoch: 9, Train loss: 3.145, Val loss: 3.321, Epoch time = 10.251s
100%|██████████| 79/79 [00:10<00:00, 7.66it/s]
Epoch: 10, Train loss: 3.024, Val loss: 3.271, Epoch time = 10.318s
처음 데이터 셋을 GPU에 올리는데 시간이 걸리기 때문에 처음 학습할 때 오래걸린다.
오버피팅이 나지 않아서 에폭을 늘려도 좋다.
7. 모델 추론
학습한 모델을 greedy decoding 방식으로 추론하기 위한 greedy_decode 함수를 작성합니다.
def greedy_decode(model, src, src_mask, max_len, start_symbol):
src = src.to(device)
src_mask = src_mask.to(device)
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(device)
for i in range(max_len-1):
memory = memory.to(device)
tgt_mask = (generate_square_subsequent_mask(ys.size(0)).type(torch.bool)).to(device)
out = model.decode(ys, memory, tgt_mask)
out = out.transpose(0, 1)
prob = model.generator(out[:, -1]) # 확률을 뽑아온다.
_, next_word = torch.max(prob, dim=1) # 가장 높은 확률의 타겟 인덱스 뽑기
next_word = next_word.item()
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
if next_word == EOS_IDX: # EOS 나오면 끝
break
return ysstring 형식의 한국어 문장이 들어왔을 때, 영어 문장으로 번역해주는 translate 함수를 작성합니다.
def translate(model: torch.nn.Module, src_sentence: str):
model.eval() # 학습하면 안된다.
src = torch.tensor([kor_vocab[token] for token in kor_tokenizer(src_sentence)], dtype = torch.long).view(-1, 1)
num_tokens = src.shape[0]
src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=SOS_IDX).flatten()
target_sentence = " ".join([eng_vocab.lookup_token(token) for token in list(tgt_tokens.cpu().numpy())])#인덱스를 다시 토큰으로 바꿔준다.
return target_sentence.replace("<SOS>", "")print(translate(model, "너 몇살이니?"))What 's the <UNK> ? <EOS>
print(translate(model, "안녕"))Hello . I 'm <UNK>
데이터 셋이 적고, 학습을 아직 덜 했다.
print(translate(model, "한국의 날씨는 지금 매우 추워"))The <UNK> is not very <UNK> . <EOS>
'인공지능 > 자연어 처리' 카테고리의 다른 글
| seq2seq 번역 모델 만들기 (0) | 2024.05.03 |
|---|---|
| 자연어 처리 python 양방향(Bidirectional) LSTM 진행하기 (0) | 2024.04.28 |
| 자연어 처리 python 실습 - 한국어 기계 번역 데이터 수집 및 전처리 (0) | 2024.04.26 |
| 자연어 처리 기계 번역 - 딥러닝 기반 기계 번역 연구 동향, 발전 방향 (0) | 2024.04.26 |
| 자연어 처리 기계 번역 - 딥러닝 기반 기계 번역 (1) | 2024.04.26 |