목표 - 대표적 NLU Task의 요약 작업에 대해 이해할 수 있다.

추상요약 - 새로운 문장을 생성하므로 좀 더 난이도 있는 방식으로 볼 수 있다.

추상 문장으로 요약 -> 정보의 압축이 필요하다

단일 문서를 다중문서에 여러번 쓰게 되면 실패할 확률이 있다!

반면, 특정 내용에 대해 요청하는 query가 들어온 경우에, 해당 query의 요구나 질문에 집중하여 요약문을 생성하는 방법을 query-focused 요약 방법이라 한다.
예를 들어, 사용자가 원하는 정보를 얻기 위해서 문서들을 탐색할 때 문서의 전반적인 내용 보다는 특정반 정보나 문장에 대해서만 혹은 정답을 얻기를 원할 확률이 높다. - 개인화 요약 방식과 직접적으로 연관되어 있다.

이렇듯 정보적 요약의 목적이 문서의 핵심 정보를 추출하는 것인 반면, 지시적 요약은 문서를 분류하거나, 계층화 할 때 사용할 수 있다.
단일 언어, 다중언어의 방식으로 나눌 수 있고, 교차 요약도 사용할 수 있다.
이메일이나 웹기반 요약 방식도 다르다.






제목이 내용을 포함하고 있을 것이다!



통계량 활용 -> 옛날 논문

모든게 자동적으로 수행되지 않는다. - heurisitic한 통계!

데이터가 비정형적 - 통계량을 뽑기 힘들다.

규칙을 얼마나 잘 세우냐에 성능이 좌우된다.

정교한 탬플릿을 만들어 탬플릿 기준으로 요약한다.

경로를 잇기만 하면 요약문이 생성된다.

문법적으로 알맞은지, 자연스러운지 판단하는 파싱 트리도 존재한다.
딥러닝이 나오기 전에 유연하고, 노이즈한 데이터를 처리하였다.


Seq2Seq의 시조격이다.
트리가 Seq2Seq의 인코더이다.

딥러닝이 발전하며 추출, 추상요약 모두 발전!

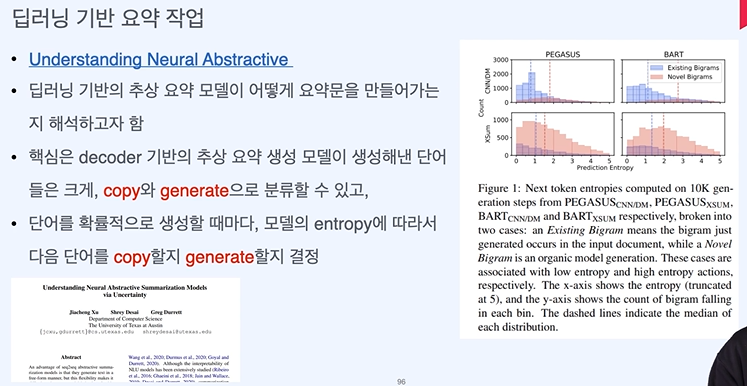
불확실성이 높다 -> copy한다.
불확실성이 낮다 -> 생성한다.


'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 온라인 강의 - Machine Translation with RNN (0) | 2024.04.10 |
|---|---|
| 자연어 처리 과제 2 - CNN text classification 감성 분석 (0) | 2024.04.10 |
| 자연어 이해 - 자연어 추론 TASK (0) | 2024.04.04 |
| 자연어 이해 NLU- 감정 분석 Sentiment Analysis Task (0) | 2024.04.01 |
| 자연어 이해 (NLU) TASK - 개요 (0) | 2024.03.31 |