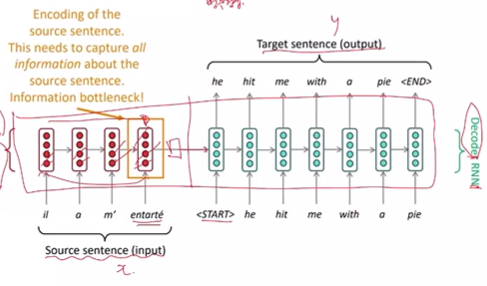
RNN - 인코더와 디코더로 구성되어 있다.
인코더 인풋 - 번역해야될 문장
디코더 출력 - 번역 된 문장
입력이 들어갈 수록 정보가 사라져서 마지막 입력의 영향이 커지게 된다. -> 정보 병목 현상 -> attention 등장
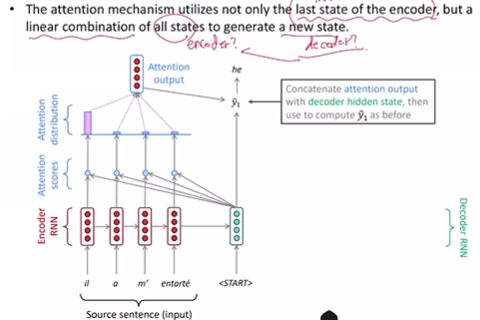
attention - 딥러닝을 비틀어서 효율적으로 학습시킨 경험적 모델
어떤 단어를 집중해야 하는지 나온다.
transformer 계열의 모든 모델에서 attention 개념이 사용된다.
인코더 모델과 디코더 모델의 어텐션을 계산해서 아웃풋을 계산한다.
디코더의 시작값과 인코더 모든 값을 내적하면 인코더 인풋 개수만큼 스칼라 값이 나온다. -> soft max를 취하면 1이 되면 확률 분포가 나온다. = attention distribution을 얻는다. 유사도를 얻게 된다-> 나온 값을 weight와 곱해서 attention hidden state를 얻는다. 디코더 시작 값과 attention hidden state를 concat 하여 결과로 사용한다.

결국 각각 내적하여 스칼라 하나 씩 얻고 그 기반으로 유사도(인코더의 어느 단어에 집중할지)를 얻은 뒤 정보를 집어 넣어 concat한다.?
디코더에서 인코더의 모든 값들을 활용하여 중요한 값을 크게 사용한다.
디코더의 첫 값이 어떻게 되는거지? concat하면 길이가 다르지 않나...?

attention을 본다 - 어떤 encorder를 보는지 알려줘야 한다?
BLEU - 지도학습과 비슷하다. 라벨이 있다.
한계점도 존재한다. - 사람이 평가해놓은 것만 정답이 된다. 정확하게 했어도 사람이 그 표현을 작성해 놓지 않으면 틀리게 된다.


일단 여기선 1gram으로 진행되었다.




'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 python 실습 - 한국어 자연어 추론 Task 실습 (1) | 2024.04.11 |
|---|---|
| 자연어 이해 NLU - Relation Extraction Task 관계 추출 (0) | 2024.04.11 |
| 자연어 처리 과제 2 - CNN text classification 감성 분석 (0) | 2024.04.10 |
| 자연어 이해 - 요약 TASK (0) | 2024.04.04 |
| 자연어 이해 - 자연어 추론 TASK (0) | 2024.04.04 |