728x90
728x90
목표 - Transformer의 encorder를 사용하는 언어 모델인 BERT의 작동 원리 이해

encorder를 사용하고 양방향 학습을 한다는 것이 GPT와의 차별성을 가졌다.

문장 단위의 자연어 추론에서 두각을 보였다. -> 전체적으로 분석하여 예측

ELMo - 입력이 들어왔을 때 엘모와 임베딩 모두를 사용하는 것

ELMo, GPT - 단방향
문장단위의 task를 고려할 때 뒤에서 앞으로도 앞에서 뒤로도 봐야하는데 단방향인 GPT는 부족하므로 양방향이 필요하다.

2번 논문 - 구조적으로 사전학습하겠다.
3번 논문 - 통계적으로 뉴럴넷을 학습하겠다.



label이 있는 데이터를 통해 Fine turning을 한다.



문장 - 컨택스트 윈도우로 잠근 문장
문장이 여러개 있는 task는 양방향으로 봐야 잘 볼 수 있다.-> 여러개의 문장을 해결하는데 목적이 있다.
문장이 어디에 시작해서 끝나는지 말해줘야 한다. == input retresentation
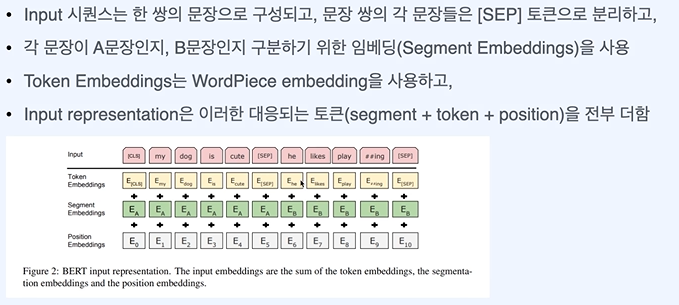
Position == Transformer에서와 똑가탇.


15%를 마스크로 놓고 맞추면 학습이 잘 된다.

MASK로 바꿔야 학습을 진행한다.

두문장의 관계로 학습







728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 모델 학습 - Pre-training이란 (1) | 2024.03.29 |
|---|---|
| 자연어 처리 python 실습 - 간단한 답변 랭킹 모델 만들기 (1) | 2024.03.28 |
| 자연어 처리 문장 embedding 만들기 - GPT (0) | 2024.03.27 |
| 자연어 처리 문장 embedding 만들기 - Transformer (0) | 2024.03.24 |
| 자연어 처리 문장 embedding만들기 - ELMo (0) | 2024.03.24 |