728x90
728x90
목표 - 다양한 분야에서 범용적으로 사용되는 Transformer의 작동 원리를 이해할 수 있다.



초기셀의 정보가 사라지는 것은 아직도 해결 X


이전셀의 계산이 끝나지 않으면 계속 기다려야 한다.

효율적인 모델 구조- 대규모 데이터에 대해 효율적으로 학습 가능해졌다.




CNN은 거리를 뭉게기 때문에 어렵다.




순차적으로 들어오지 않기 때문에 순서 정보를 넣어주는 것이 필요하다.

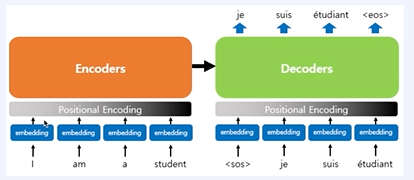


위치마다 값이 다르다 -> 삼각함수


짝수 - sin
홀수 - cos

논문에서 d_model = 512 차원이다.








차원을 줄인다.

모든 단어에 대해 진행할 수 있다.

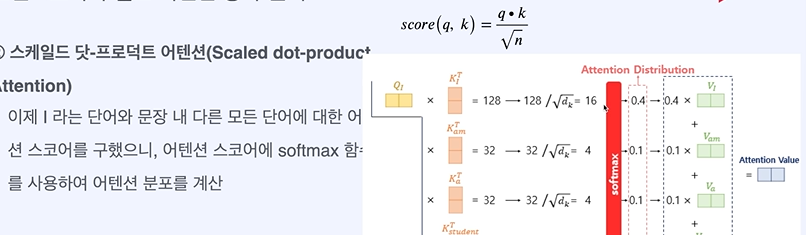

RNN이 가진 병목을 가지는 것 처럼 보인다.
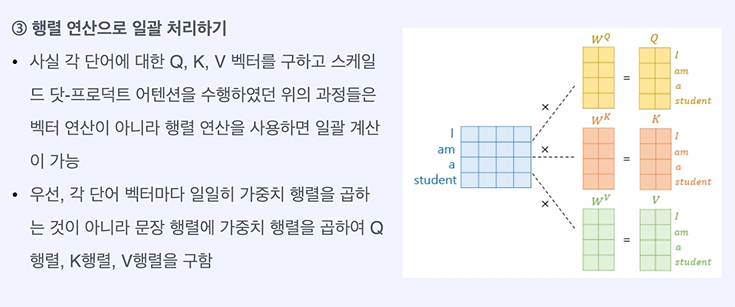
행렬을 통해 일괄로 처리한다.


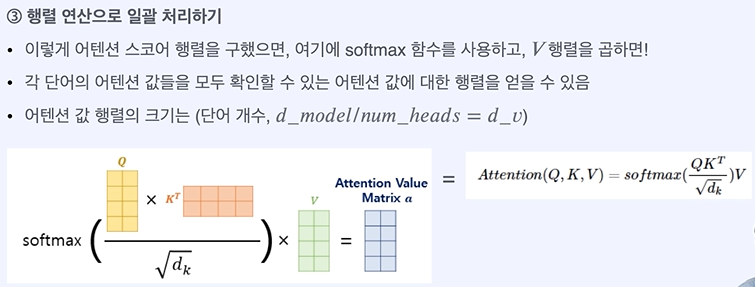










역전파나 계속 진행되도 activation에 의해 0으로 줄어드는 것을 막아준다.







728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 문장 embedding 만들기 - BERT (0) | 2024.03.28 |
|---|---|
| 자연어 처리 문장 embedding 만들기 - GPT (0) | 2024.03.27 |
| 자연어 처리 문장 embedding만들기 - ELMo (0) | 2024.03.24 |
| 자연어 처리 문장 임베딩 만들기 - Seq2Seq (1) | 2024.03.24 |
| 자연어 처리 문장 임베딩 만들기 - 자연어 처리를 위한 모델 구조 (0) | 2024.03.24 |