728x90
728x90
GPT - Transformer의 디코더 부분을 사용

ELMo랑 비슷하다.





RNN 기반 -> 병렬화가 안된다.




확률값이 최대가 되도록 파라미터를 조절한다.

Multi head -> 병렬로 진행하여 각각으로 확인하겠다.
GPT에서는 Multihead Attention은 없고 masked만 있다.
소프트 맥스 후 arguemax하면 가장 높은 확률의 단어를 뽑아낼 수 있다.





유사도 측정할 때 순서도 바꿔서 학습한다.
여러개중에서 고를 때 모두 비교 후 소프트맥스하여 높은 값을 고른다.


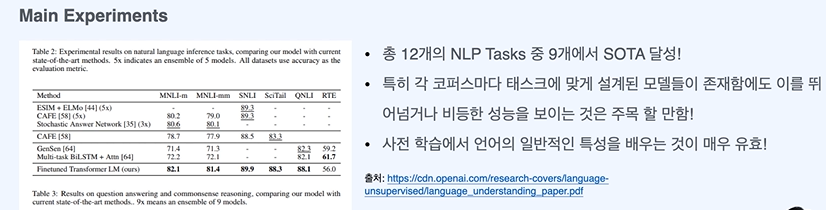


Zero shot 알려주지 않고 테스트 하기
728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 python 실습 - 간단한 답변 랭킹 모델 만들기 (1) | 2024.03.28 |
|---|---|
| 자연어 처리 문장 embedding 만들기 - BERT (0) | 2024.03.28 |
| 자연어 처리 문장 embedding 만들기 - Transformer (0) | 2024.03.24 |
| 자연어 처리 문장 embedding만들기 - ELMo (0) | 2024.03.24 |
| 자연어 처리 문장 임베딩 만들기 - Seq2Seq (1) | 2024.03.24 |