https://aclanthology.org/2024.acl-long.536/
Dodo: Dynamic Contextual Compression for Decoder-only LMs
Guanghui Qin, Corby Rosset, Ethan Chau, Nikhil Rao, Benjamin Van Durme. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024.
aclanthology.org
acl 2024 long에 붙은 논문입니다.
기존 방법들(sparse attention, 커널 등)은 nlp에서 일관적인 효과가 나지 않거나, 대형 llm에 적용이 어려웠음
모든 토큰을 동일 길이의 hidden state로 유지하지 말자!
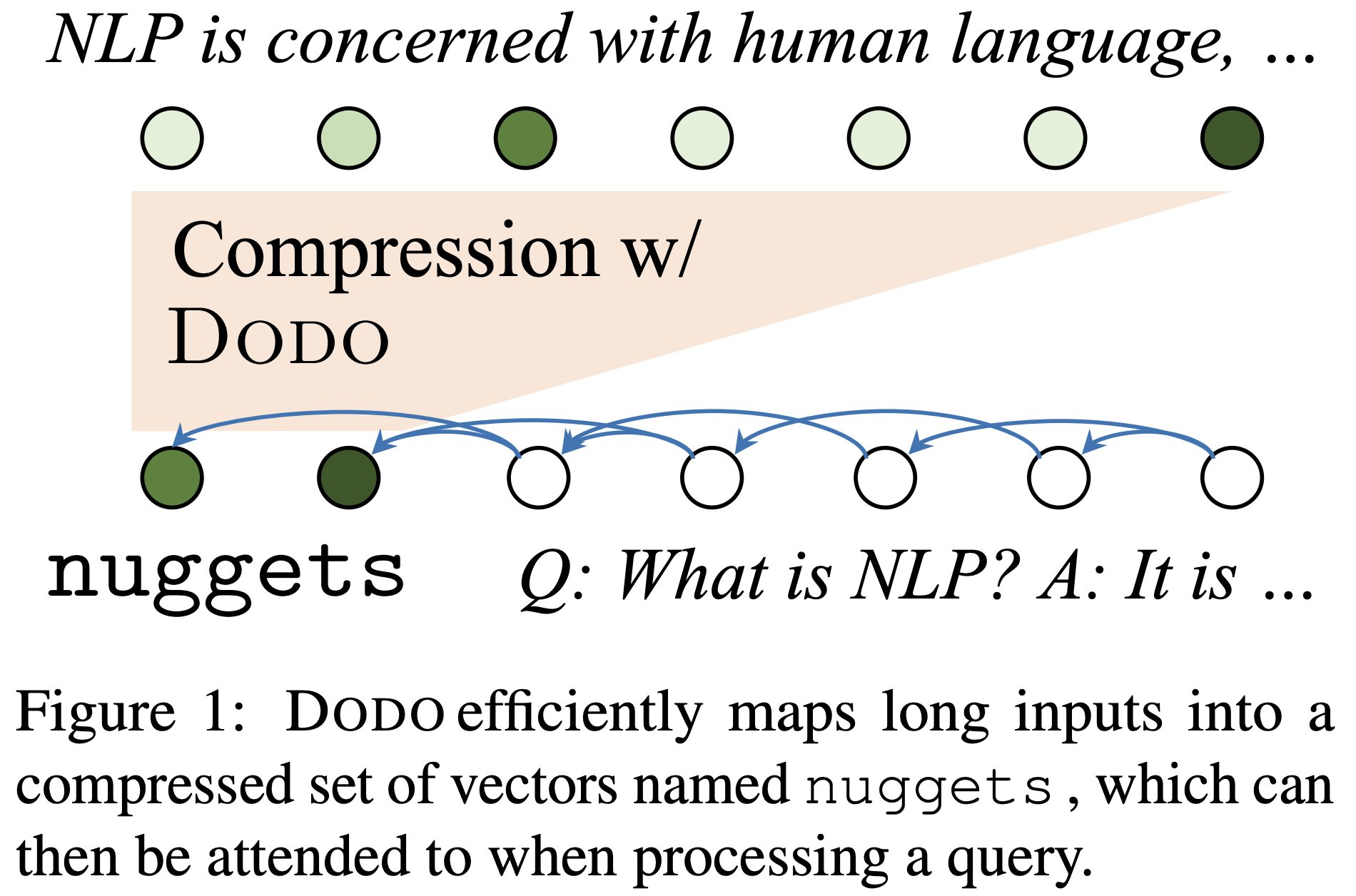
각 레이어에서 중요한 일부 토큰 hidden state만 선택해 더 짧은 시퀀스로 문맥 표현하면 self-attention의 키 벨류 길이가 줄어 디코딩 비용을 크게 절감할 수 있다.
2026.03.03 - [인공지능/논문 리뷰 or 진행] - Sequential Efficient LLM 논문 -2
Sequential Efficient LLM 논문 -2
https://arxiv.org/abs/2310.01732 Nugget: Neural Agglomerative Embeddings of TextEmbedding text sequences is a widespread requirement in modern language understanding. Existing approaches focus largely on constant-size representations. This is problematic,
yoonschallenge.tistory.com
여기서 사용한 nuggets를 또 사용하네요
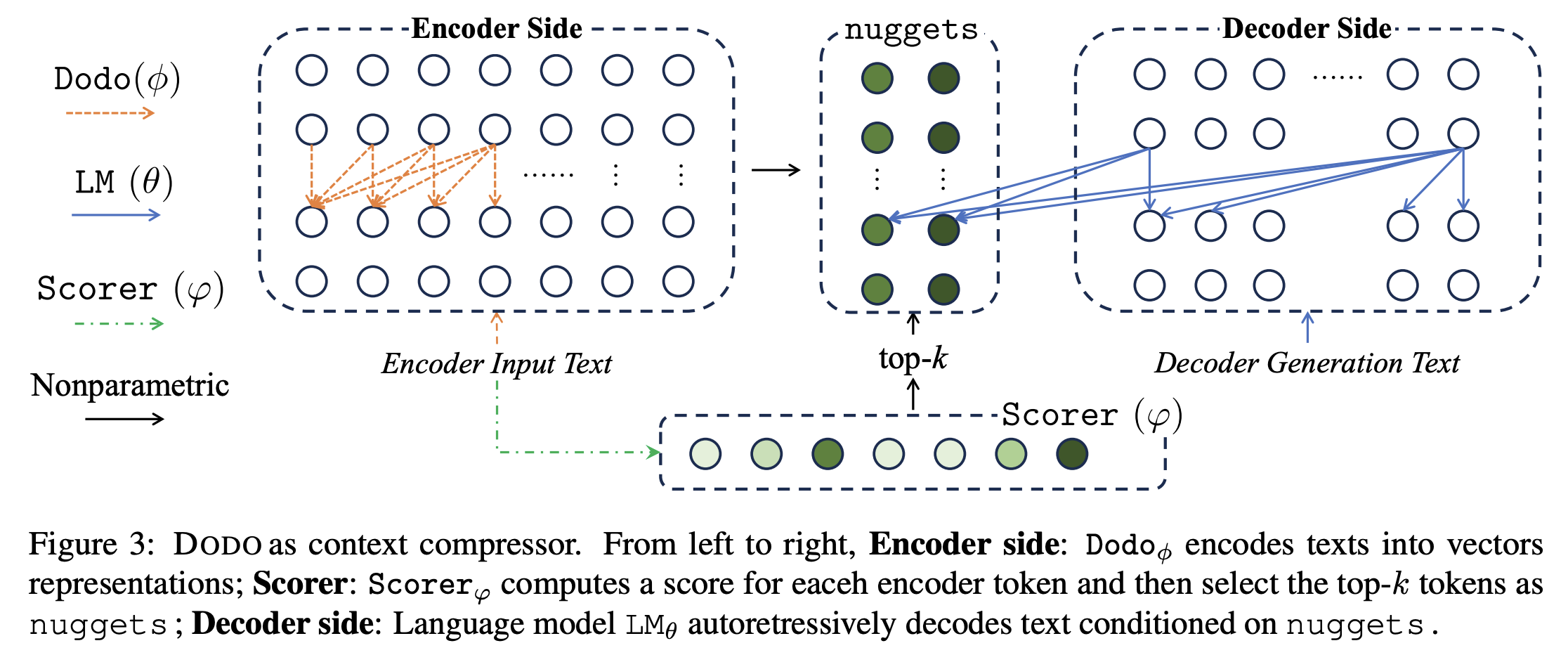
여기서도 t개의 토큰을 k개의 토큰으로 동적으로 표현함 (But 실험에서는 압축비로 제어)
각 토큰에 대해 scorer가 점수를 매기고, 선택된 토큰의 hidden state만 nuggets으로 남김
여기서도 top-k의 미분 불가가 문제였는데 STE를 적용해 end to end로 학습함

질의 응답과 생성 테스트를 진행함
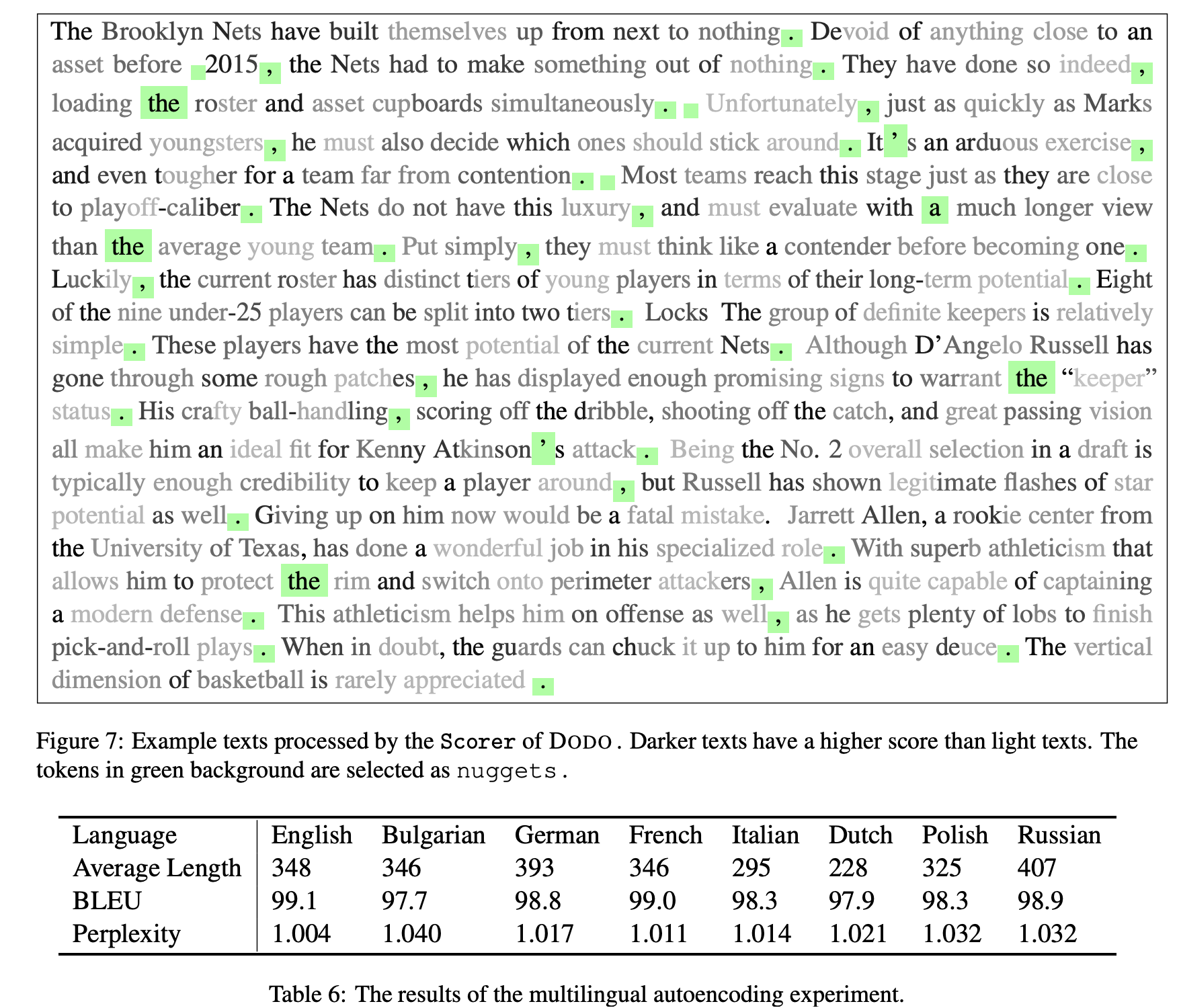
입력을 다시 복원하는 실험에서 20배를 압축해도 98%를 복구하는 모습을 보여줬고, 다른 압축 방법에 비해 긴 입력에 유리하다고 알림
Full text보다 좋은 perplexity를 보이기도 함
| 논문 한 줄 요약 | 디코더-only LLM에서 컨텍스트를 동적으로 압축한 hidden-state 집합(nuggets) 만 유지해 self-attention 비용을 줄이면서도 성능을 유지하는 Dynamic Contextual Compression(DODO) 를 제안 |
| 해결하려는 문제 | 긴 컨텍스트에서 self-attention이 O(n²) 로 증가해 추론 시간/메모리가 급증. 기존 희소/근사 attention은 LLM에서 효과·적용성이 제한적이라는 문제의식 |
| 핵심 아이디어 | 입력 토큰 전체를 그대로 유지하지 않고, 각 레이어에서 중요 토큰의 hidden state만 선택하여 길이 k(≤n)의 nuggets로 컨텍스트를 표현 → K/V 길이 감소로 연산 절감 |
| 표현 | 표준: 토큰 n개 → hidden state n개. DODO: 토큰 n개 → nuggets k개(동적)로 압축된 컨텍스트 표현 |
| 선택 메커니즘 | Scorer(점수 함수)가 토큰별 중요도를 산출하고 Top-k 또는 threshold로 토큰 인덱스를 선택 → 선택된 토큰 hidden state만 nuggets로 유지(레이어 간 선택 인덱스 일관성 유지) |
| 학습 핵심 | 토큰 선택은 이산적이라 미분 불가 → Straight-Through Estimator(STE) 로 end-to-end 학습. attention logit에 (s − stopgrad(s)) 형태로 gradient를 흘려 “미래에서 참조될 토큰” 을 선택하도록 유도 |
| 사용 모드 1: Autoregressive LM | 생성 시 미래를 볼 수 없으므로 causal(온라인) threshold 선택(Λ) 을 사용. 정보 손실 완화 위해 최근 τ 토큰은 미압축(원본 유지), 먼 과거만 nuggets로 압축(mixed resolution) |
| 사용 모드 2: Context Compressor | 문서가 먼저 주어지는 설정(QA/요약 등)에서는 입력 전체를 보고 정확히 k=⌈n/r⌉개 Top-k 선택 → nuggets를 압축 컨텍스트로 만들고 디코더가 이를 조건화해 생성 |
| 주요 실험 1: Autoencoding | nuggets로 입력을 압축 후 복원 시 고압축에서도 거의 무손실 수준의 복원 성능 |
| 주요 실험 2: 제한 메모리 LM | 동일한 “저장 가능한 hidden state 수(64/128/256)” 제약에서 기존 방법(Compressive 등) 대비 perplexity 개선 |
| 주요 실험 3: Downstream(QA/요약) | SQuAD zero-shot 등에서 압축비가 낮을수록 FULL에 근접. CNN/DailyMail 요약에서는 10× 압축에서도 Rouge가 경쟁적(일부 설정에서 FULL fine-tune과 비슷/상회) |
| 분석/해석 | 선택된 토큰이 문장부호·접속사 등 구/절 경계에 자주 위치(“문맥을 구조적으로 대표하는 토큰”을 잡는 경향). 근사 선택이 “거의 최적”에 가깝다는 중첩/갭 분석도 제시 |
| 기여(Contributions) | (1) 디코더-only에서 동적 길이 컨텍스트 압축 표현(nuggets), (2) STE 기반 hard selection 학습 정식화, (3) 생성/압축기 2-모드로 실용 적용, (4) 다양한 설정에서 효율-성능 trade-off 실증 |
| 한계/리스크(해석) | hard selection은 구현·학습 안정성(하이퍼파라미터 Λ, τ, 압축비 r) 의존 가능. 압축이 과도하면 long-range 정보 손실 위험(그래서 mixed resolution을 둠) |
| 결론 메시지 | 디코더-only LLM도 긴 문맥을 소수의 상태 벡터로 충분히 캡슐화할 수 있으며, 이를 통해 추론 비용을 줄이면서 성능을 유지/개선할 수 있다 |
https://arxiv.org/abs/2510.26622
Encoder-Decoder or Decoder-Only? Revisiting Encoder-Decoder Large Language Model
Recent large language model (LLM) research has undergone an architectural shift from encoder-decoder modeling to nowadays the dominant decoder-only modeling. This rapid transition, however, comes without a rigorous comparative analysis especially \textit{f
arxiv.org
이건 en-decoder랑 decoder only랑 정리해놓은 논문이네요

| 문제의식 | 최근 LLM이 encoder-decoder → decoder-only로 이동했지만, 스케일링 관점(파라미터/컴퓨트 효율)에서 encoder-decoder가 과소평가되었을 수 있어 이를 재검증 |
| 비교 대상 | RedLLM(encoder-decoder) vs DecLLM(decoder-only) 를 동일 스케일(≈150M~8B)에서 비교 |
| RedLLM 설계 | RoPE를 encoder/decoder self-attn 및 cross-attn 전체에 적용, continuous position, embedding all-tied, 안정화 위해 attn output에도 추가 norm |
| 학습 목표 | DecLLM은 Causal LM, RedLLM은 Prefix LM 사용 |
| 데이터/학습 설정 | RedPajama V1로 400K steps(≈1.6T tokens) 프리트레인, 이후 FLAN으로 인스트럭션 튜닝(입/출력 max 2048/512) |
| 평가 | PPL 스케일링(in-domain RedPajama / out-of-domain Paloma) + 13개 다운스트림 태스크 zero/few-shot, 프리트레인(PT)과 튜닝 후(FT) 모두 비교 |
| 주요 결과 1 | DecLLM이 더 파라미터 효율적(동일 파라미터에서 RedLLM 대비 일관되게 우수) |
| 주요 결과 2 | RedLLM은 “비슷한 조건”에서 학습에 ≈2배 FLOPs가 필요해 계산 비효율이 있으나, 컴퓨트 기준으로 비교하면 품질 격차가 거의 사라져 스케일링 곡선이 겹침 |
| 주요 결과 3 | PPL-컴퓨트 관점의 compute-optimal frontier는 대체로 DecLLM이 지배(특히 큰 컴퓨트에서) |
| 주요 결과 4 | 프리트레인 동안 RedLLM이 compute-optimal 학습에서 뒤처지고, zero/few-shot에서도 DecLLM 대비 열세 경향 |
| 주요 결과 5 | “+BiAttn”은 DecLLM에서 입력에 bidirectional attention을 허용한 변형이며, 튜닝/태스크 성능 분석에서 중요한 비교축으로 사용 |
| 논문이 말하고자 하는 결론 | encoder-decoder는 “구식”이 아니라, 스케일링 기준을 명확히 잡으면(파라미터 vs 컴퓨트) DecLLM/RedLLM 각각 강점이 드러나며, 아키텍처 선택은 효율-품질 트레이드오프로 재해석해야 함 |
https://arxiv.org/abs/2503.10337
KV-Distill: Nearly Lossless Learnable Context Compression for LLMs
Sequence-to-sequence tasks often benefit from long contexts, but the quadratic complexity of self-attention in standard Transformers renders this non-trivial. During generation, temporary representations -stored in the so-called KV cache-account for a larg
arxiv.org
이 논문도 엄청 연관된 논문은 아니라서...
결국 여기서도 gpu메모리 문제를 말하면서 캐시를 압축하려고 합니다.

원본 모델을 두고, 압축된 캐쉬가 생성 분포가 같아지도록 디스틸함

| 주제 | KV-DISTILL: Nearly Lossless Learnable Context Compression for LLMs — LLM의 KV cache를 학습적으로 압축해 긴 컨텍스트 추론의 메모리 병목을 줄이는 방법 |
| 해결하려는 문제 | 긴 컨텍스트에서 KV cache 메모리가 토큰 길이에 선형 증가 → 추론 시 GPU 메모리 병목. 기존 효율화는 성능 저하/설정 제약이 크며, 긴 컨텍스트를 모델이 충분히 활용 못하는 현상도 존재 |
| 목표/설정 | Question-independent context compression: 질문을 모르는 상태에서 문서를 미리 압축해 두고, 이후 여러 질문에 재사용해도 성능을 유지 |
| 핵심 아이디어 | 원본 KV 조건의 next-token 분포(교사)와 압축 KV 조건 분포(학생)가 같아지도록 distillation 수행 |
| 압축 구성요소 1: 토큰 선택 | 컨텍스트 토큰 hidden state → scorer(FFN)로 중요도 점수 산출 → top-k 토큰 선택(모든 레이어에 동일 선택 적용). top-k 비미분 문제는 학습 시 attention 감쇠로 scorer에 신호 전달 |
| 압축 구성요소 2: 조건부 LoRA | 단순 삭제가 아니라 선택 토큰이 정보까지 “흡수”하도록 conditional computation 적용. 구현은 선택 토큰에 대해 transformer의 W_Q, W_O에 LoRA 라우팅(선택 토큰 인지) |
| 학습 목표(손실) | 원본 분포 (p) vs 압축 분포 (q_θ)에 대해 forward KL + reverse KL 혼합으로 next-token 분포 정렬: λD_{KL}(p∥q)+(1−λ)D_{KL}(q∥p) |
| 학습 데이터/절차 | Self-Instruct, P3, LongAlpaca, Super-Natural Instructions 등으로 (Context, Instruction, Answer) 구성. ①교사 logits 생성 → ②컨텍스트만 압축해 학생 logits 생성 → ③KL 혼합 손실로 정렬 |
| 추론(사용) 방식 | 고정 컨텍스트는 1회 압축해 저장 후 재사용, 이후 자동회귀 디코딩은 추가 오버헤드 없이 압축 KV cache로 진행 |
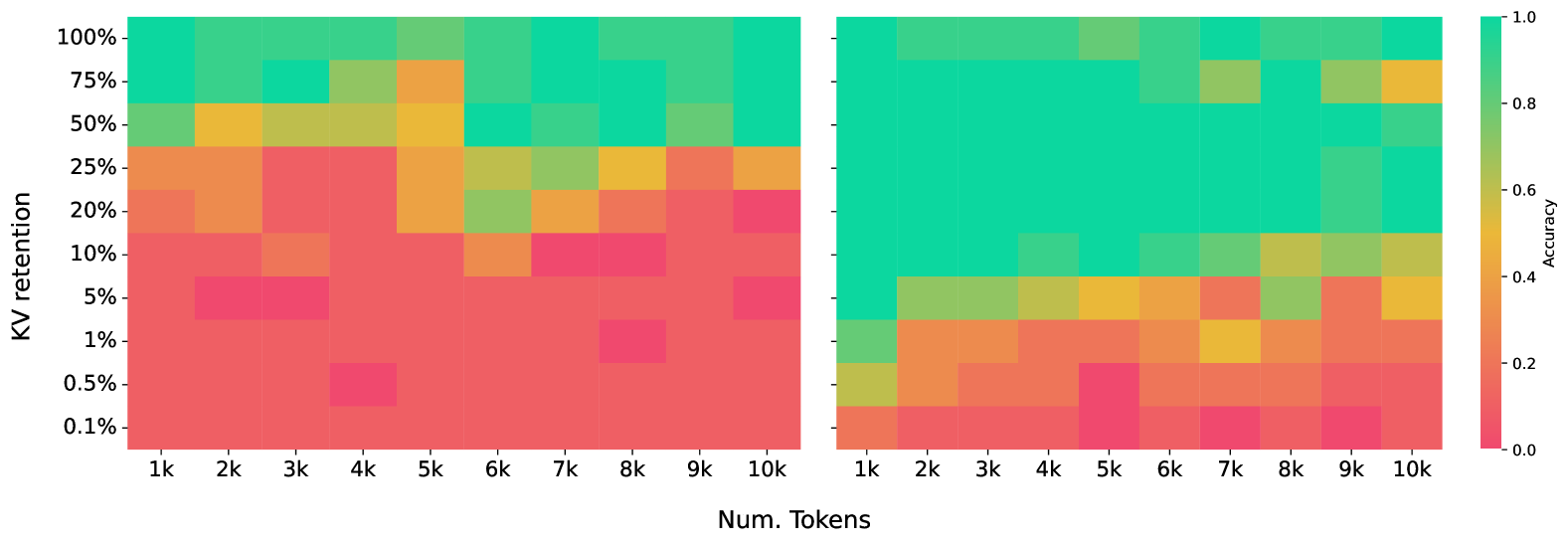
| 주요 결과 요약 | Needle-in-a-Haystack에서 대폭 높은 정확도(예: KV 90% 제거 후에도 매우 강함). SQuAD에서 20–25% KV 유지 시 base에 근접하며, H2I/ICAE/DODO 대비 우수. QuALITY/요약에서도 10x~100x 이상 압축에서 성능 유지 가능성을 제시 |
| 기여(한 줄) | “텍스트를 줄이는” 대신, LLM이 실제로 쓰는 KV cache 자체를 distill하여 질문-독립적이고 거의 무손실에 가까운 컨텍스트 압축을 달성 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Sequential Efficient LLM 논문 -2 (0) | 2026.03.03 |
|---|---|
| Sequential Efficient LLM 논문 -1 (0) | 2026.03.03 |
| Latent Reasoning, Soft Thinking 논문 정리 3 (2) | 2026.02.21 |
| Multi-turn, Long-context Benchmark 논문 5 (0) | 2026.02.20 |
| Latent Reasoning, Soft Thinking 논문 정리 2 (0) | 2026.02.20 |