https://arxiv.org/abs/2310.01732
Nugget: Neural Agglomerative Embeddings of Text
Embedding text sequences is a widespread requirement in modern language understanding. Existing approaches focus largely on constant-size representations. This is problematic, as the amount of information contained in text often varies with the length of t
arxiv.org
고정 길이 임베딩은 문장 길이와 정보량이 달라도 동일한 크기로 압축해야 해서 긴 텍스트에서 정보 손실 커질 수 있음!
토큰을 전부 저장하는 ColBERT류는 정보는 풍부하지만 메모리나 인덱싱 비용이 매우 큼
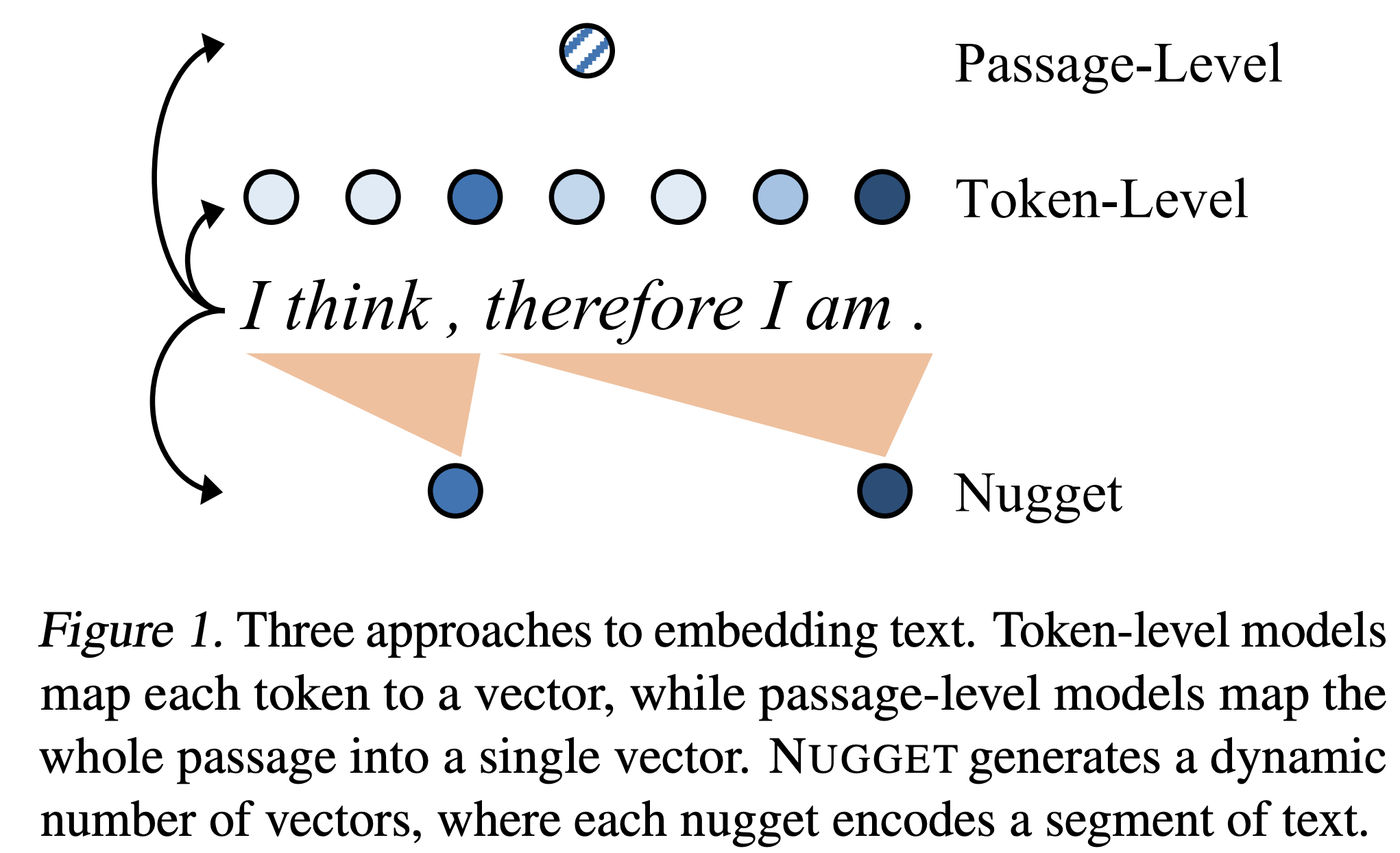
=> 의미적으로 유용한 적정 granularity를 찾아야 함. 텍스트 길이에 따라 동적으로 늘어야 함
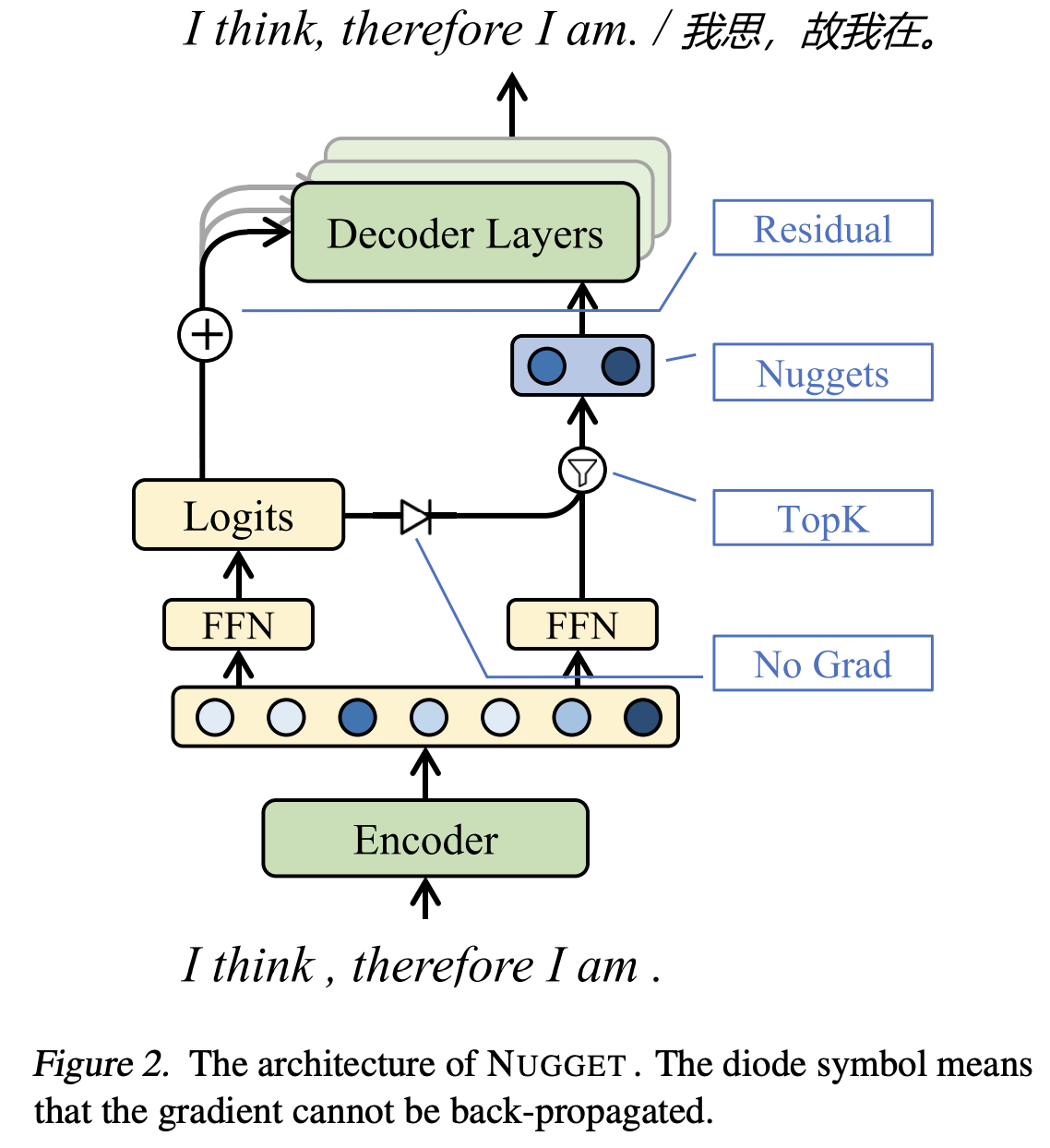
중요도 점수를 통해 top-k 토큰만 선택해 nugget을 구성하고, 여기서 k는 압축비로 정해져 문서가 길어지면 nuggets수도 늘어남
여기서 top-k는 미분 불가하여 selector가 학습 신호를 받지 못하는 문제가 있음 => 여기서 residual을 통해 gradient가 흐르도록 만듬

Nugget이 자주 선택하는 토큰은 구두점, 접속사, 선치사, eos 등 절/구 셩계 성격의 delimiter로 나타남 => 앞 구간을 요약하는 summary token처럼 작동한다고 해석
성능 복구에 큰 문제가 없고, ColBART대비 훨씬 적은 벡터로 비슷한 성능을 낼 수 있음
| 한 줄 핵심 | 텍스트 정보량은 길이/구조에 따라 달라지므로, 고정 크기(1벡터) 와 토큰 전부 저장(다수 벡터) 사이의 절충으로, 입력 길이에 비례해 동적으로 선택된 일부 토큰만을 다중 벡터(nuggets)로 표현하는 방법(NUGGET)을 제안. |
| 문제의식 | (1) 1개/상수개 벡터 표현은 긴 텍스트에서 정보 손실 위험, (2) 토큰 수준 저장은 비용 과다 → “의미적으로 유용한 granularity”가 필요. |
| 제안 방법 개요 | 입력 토큰 임베딩 (X)에서 토큰별 점수 (s) 를 계산하고, Top-k 토큰만 선택해 nuggets (Z)를 구성하는 가변 길이 multi-vector embedding. |
| k(벡터 개수) 설정 | 고정 k가 아니라 압축비 rr로 k=⌈n⋅r⌉ → 입력이 길수록 nugget 수가 증가(가변 표현). |
| 핵심 난점 & 해결 | TopK 선택은 비미분이라 selector가 학습 신호를 못 받음 → 디코더 cross-attention logit에 (s)를 residual로 더해 gradient가 selector로 흐르게 함(식(5)). |
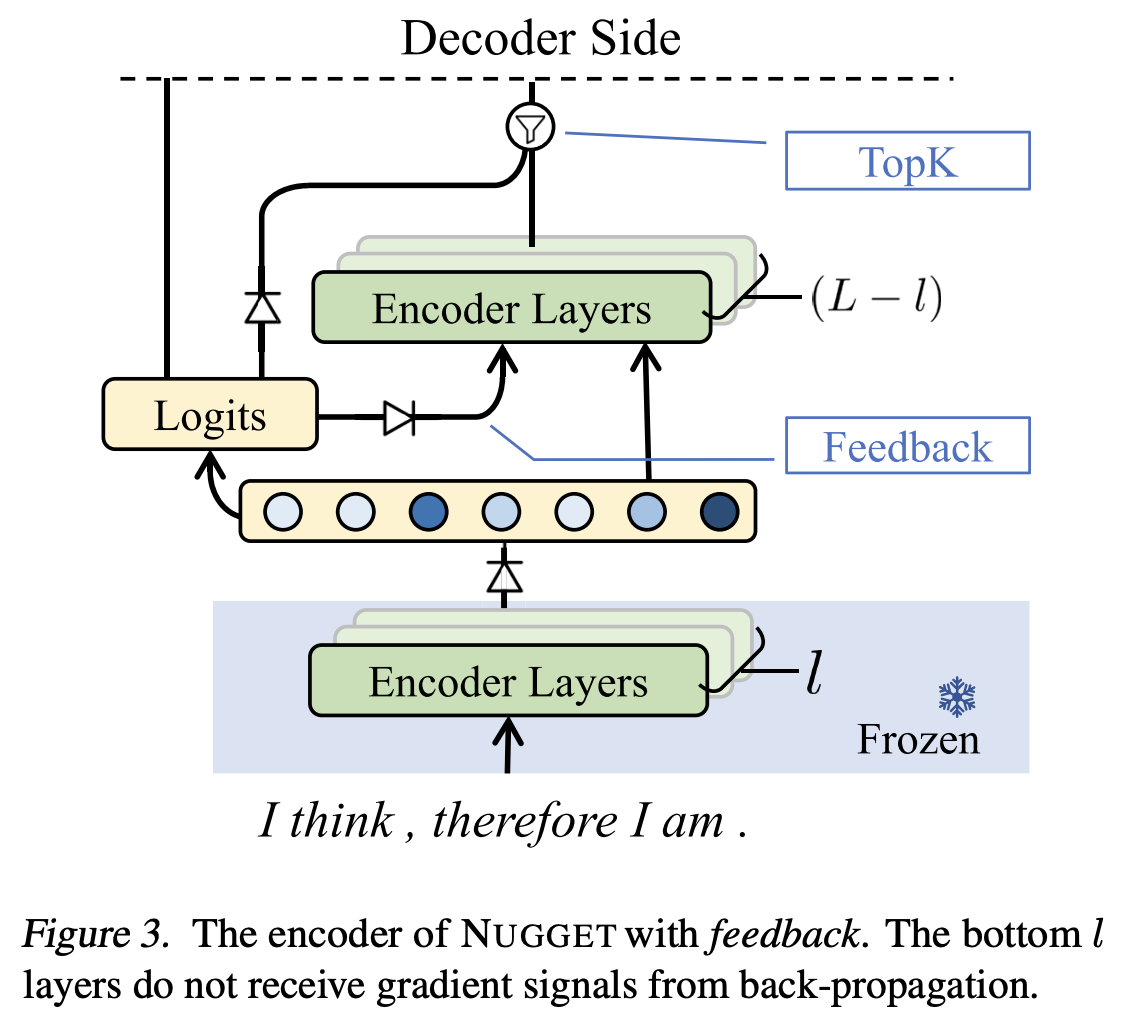
| Informed Nugget Encoding | nugget 선택이 encoder 표현에도 반영되도록, encoder l번째 레이어에서 (s)를 미리 계산하고 nugget/비-nugget에 type embedding을 더해 다음 레이어로 전달(식(7)(8)); 학습 안정화를 위해 하위 l개 레이어 freeze. |
| 학습 목표 | 데이터셋에 따라 Auto-Encoding(AE) 혹은 Machine Translation(MT) 로 end-to-end 학습(문서 수준으로 문장 연결). |
| 내재 평가 | 압축비 (r)에 따른 BLEU로 “semantic completeness” 평가: r=0.1에서 성능 포화, AE의 경우 r≥0.1이면 BLEU>0.99(거의 verbatim, almost lossless). |
| nugget이 선택하는 토큰 | 균등 선택이 아니라 구두점/접속사/전치사 등 delimiter를 선호하며, 이를 segment summary token처럼 해석. |
| nugget이 담는 정보 | 특정 nugget만 노출해 decoding 시 확률 증가(“probability gain”)을 측정 → 각 nugget이 주로 자기 이전 연속 구간 복원에 도움 → delimiter 기반 divide-and-conquer 분절 인코딩 가설을 제시. |
| 외재 평가 1: 문서 유사도 | 문서-수준 paraphrase identification(ParaBank 기반): 1개 정답 + BM25로 19개 hard negative(총 20개) 중 정답 선택. |
| 외재 평가 2: passage reranking | WikiText-103에서 lead section을 query로, 같은 문서의 다른 section을 positive로 두고 BM25로 19개 negative를 구성해 20개 중 랭킹. |
| 유사도 성능 | Table 2(MRR×100): NUGGET(MT, r=0.25) PI 97.38 / RR 56.51, ColBART PI 94.83 / RR 52.44, TSDAE(AE) PI 95.59 / RR 50.48. |
| 비용-성능 주장 | PI(RR)에서 NUGGET이 ColBART급 성능을 내면서도, ColBART는 텍스트 인코딩에 훨씬 많은 벡터(PI 20x, RR 6.7x) 를 사용한다고 서술. |
| 장문 컨텍스트 LM 확장 | 과거 토큰을 nugget으로 압축하고, 최근 s토큰은 self-attn, 과거 nuggets는 cross-attn으로 읽는 형태로 LM을 구성 |
| LM 성능 | Table 3(PPL): 예) r=0.05, h=8에서 28.14 vs full-attn baseline(h=0) 31.46. 또한 “NUGGET-assisted 모델이 full-attn baseline보다 낮은 PPL”이라고 결론. |
| Ablation | 피드백 제거/selector 대체 등 분석: 기본 설정(l=3, r=0.1)이 강하며, l=0(임베딩층)로 selector를 두면 PI/RR 급락 |
| 결론/의의 | (i) 동적 multi-vector 표현을 통해 고정 벡터 vs 토큰 전부 저장의 간극을 메움, (ii) delimiter 기반 자연 분절, (iii) 문서 유사도/장문 LM에서 유효, (iv) 향후 contrastive learning 등 추가 학습을 제안. |
https://arxiv.org/abs/2404.11912
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support. However, key-value (KV) cache, which is stored to avoid re-computation, has emerged
arxiv.org
colm 2024에 붙은 논문이네요
기존 llm추론에서 kv cache 병목을 말하네요
시퀀스 길이마다 선형 증가하고, gpu 메모리에 올리기 등 다양하게 리소스를 소모
=> 출력 분포를 정확히 보존하며 긴 입력에서 토큰당 지연 시간을 줄이자!
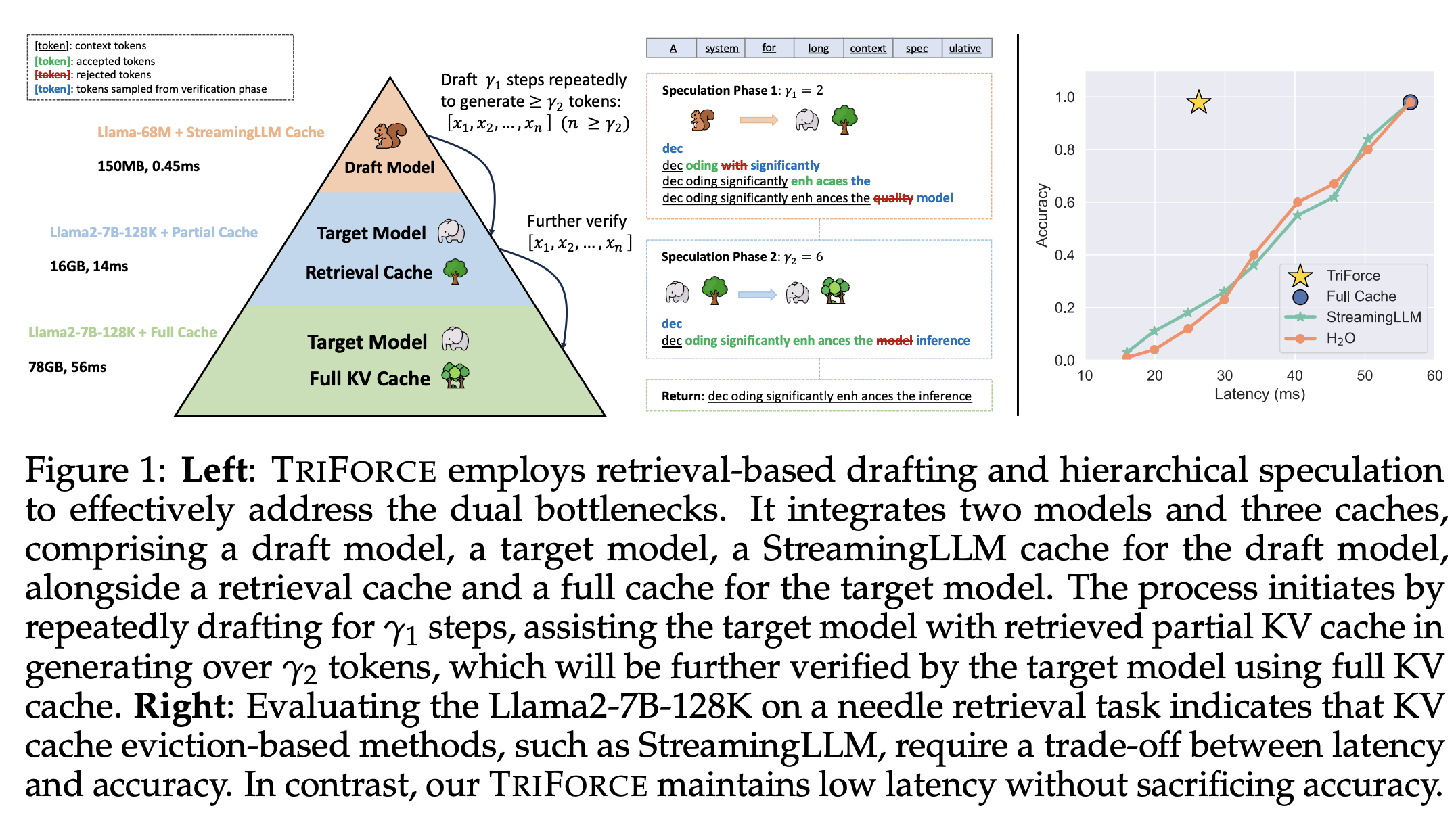
hierarhical speculative decoding 시스템을 통해 model weight, kv cache 이 두 병목을 해결하려고 함
Draft model - llama 68M + streaming LLM cache
Retrieval chach - full kv에서 중요한 청크만 뽑아 만든 partial KV cache
Target model - long context llm, full kv cache
뭐 이렇게 나눠서 캐시를 구성하고, 검색기로 kv가 높은 청크를 가져와서 넣어주고 하는데.... 일단 여긴 너무 제가 하는 거랑은 다른 느낌이라 이정도만....
| 논문/핵심 주장 | TRIFORCE는 계층적(hierarchical) speculative decoding으로, 출력 분포를 보존(lossless) 하면서 롱컨텍스트 생성 속도를 크게 올리는 시스템을 제안한다. |
| 해결하려는 문제 | 롱컨텍스트 추론에서는 토큰마다 모델 weight + 거대 KV cache를 반복 로드해야 해서 지연이 커진다. 기존 KV eviction/압축은 KV를 되돌릴 수 없어 정확도 저하가 발생한다. |
| 핵심 관찰 | (1) Dual bottleneck: KV cache가 weight 못지않은 병목 (2) Attention sparsity: 일부 KV만으로도 attention score 대부분을 회복 가능 (3) Contextual locality: 연속 토큰들이 비슷한 long-context를 참조해 retrieval cache를 재사용 가능 |
| 방법 | Target 큰 모델 (M_p)+full KV (C_p), retrieval cache (C_r)(full KV에서 top chunk만 뽑은 partial KV), Draft 작은 모델 (M_q)+StreamingLLM cache (C_q)를 사용. |
| 방법 | ① (M_q)가 빠르게 draft 생성 → ② (M_p)+(C_r)로 1차 검증/수정(=KV 병목 완화) → ③ (M_p)+(C_p)로 최종 검증(=lossless 보장). acceptance가 떨어지면 (C_r) 재구성. |
| Retrieval cache 구성 | full KV를 chunk로 나누고, 현재 query와 각 chunk의 평균 key 간 attention으로 점수화해 상위 chunk를 budget(예: 4K) 내로 선택하여 (C_r)를 만든다. |
| 주요 결과 | A100에서 122K 프롬프트 + 256 생성 조건에 최대 2.31× 가속(acceptance ~0.92). |
| 주요 결과 | 2×RTX4090에서 128K 컨텍스트: Llama2-7B 7.78×, Llama2-13B 7.94× 토큰 지연 개선. 1×4090에서도 ZeRO-Inference 대비 4.86×. |
| 확장/추가 실험 | 더 긴 입력(256K/512K)에서도 큰 speedup을 보고(예: 11.81×, 12.10×). |
| 의의 | 롱컨텍스트 서빙의 두 병목(Weight/KV)을 계층적 speculation으로 분해해 해결하며, 정확도 손실 없이(lossless) 실용적인 대규모 가속을 달성한다. |
https://arxiv.org/abs/2405.17951
Efficient Time Series Processing for Transformers and State-Space Models through Token Merging
Despite recent advances in subquadratic attention mechanisms or state-space models, processing long token sequences still imposes significant computational requirements. Token merging has emerged as a solution to increase computational efficiency in comput
arxiv.org
4번의 시도 끝에 icml 2025에 붙었네요
여기서도 동일하게 시계열 데이터는 토큰 길이가 길어질수록 리소스가 제곱으로 커지는 것을 말합니다.
비전에서는 token merging이 효율 개선에 효과적이었음 - 시계열 도메인, SSM, Decoder로의 확장이 제대로 이루어지지 않음!
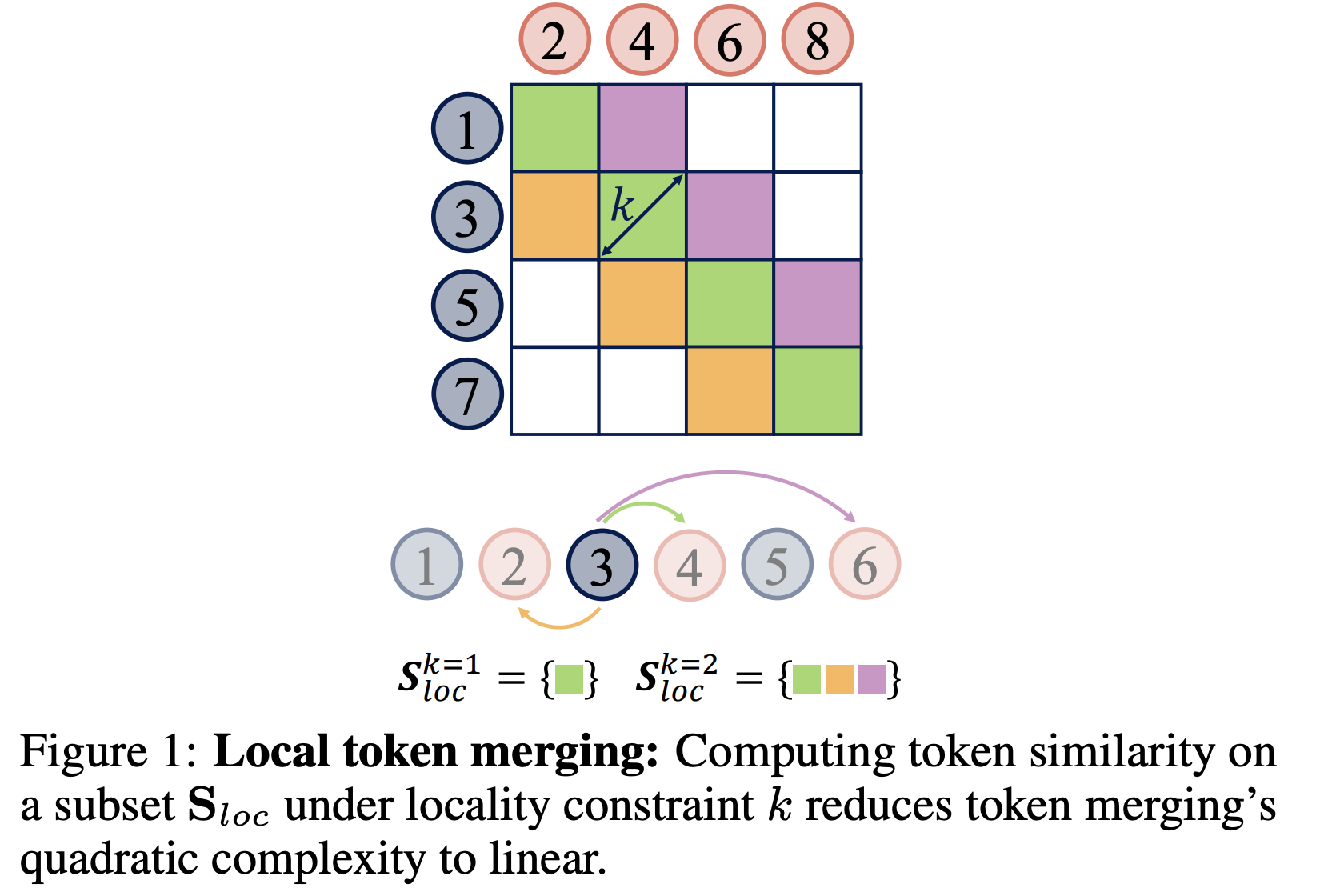
Token Merging을 시계열에 맞게 재설계해야 함
매 레이어에서 토큰을 두 집합으로 나눈뒤 코사인 유사도 행렬을 통해 가장 유사한 쌍들을 골라 평균으로 병합. = 이 것도 계산이 제곱이라 긴 시계열 입력엔 비효율적 !
그래서 유사도 계산을 전체가 아닌 로컬(이웃) 범위에서만 수행하도록 제안! (k가 커지면 범위가 넓어져 제곱에 가까워지고, k가 작아질 수록 로컬로 작아져 선형에 가까워짐)
디코딩 때 차원을 맞춰줘야 하기 때문에 마지막에 unmerge 단계를 둔다.
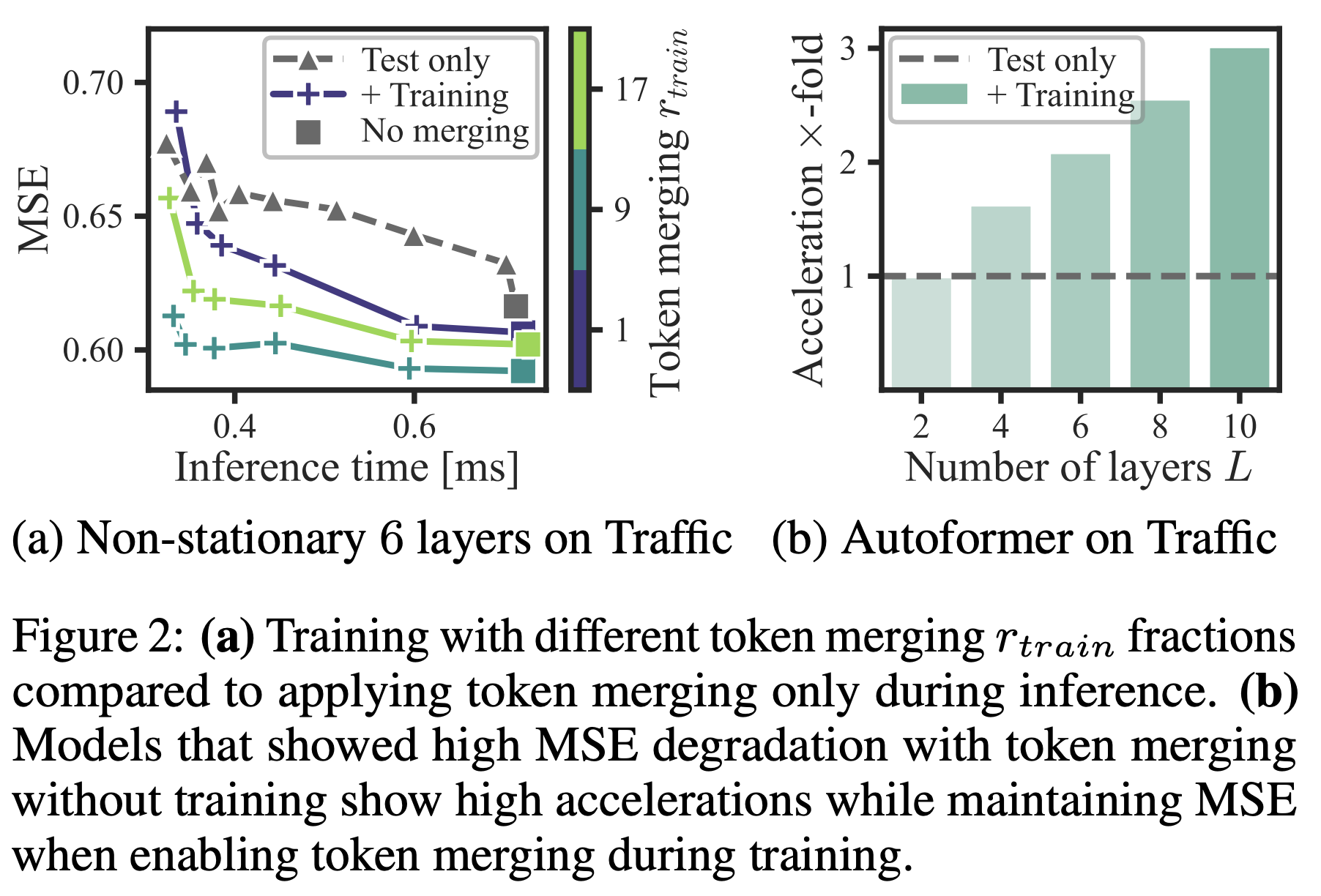
pre-trained transformer를 추가학습 없이 가속할 수 있었음
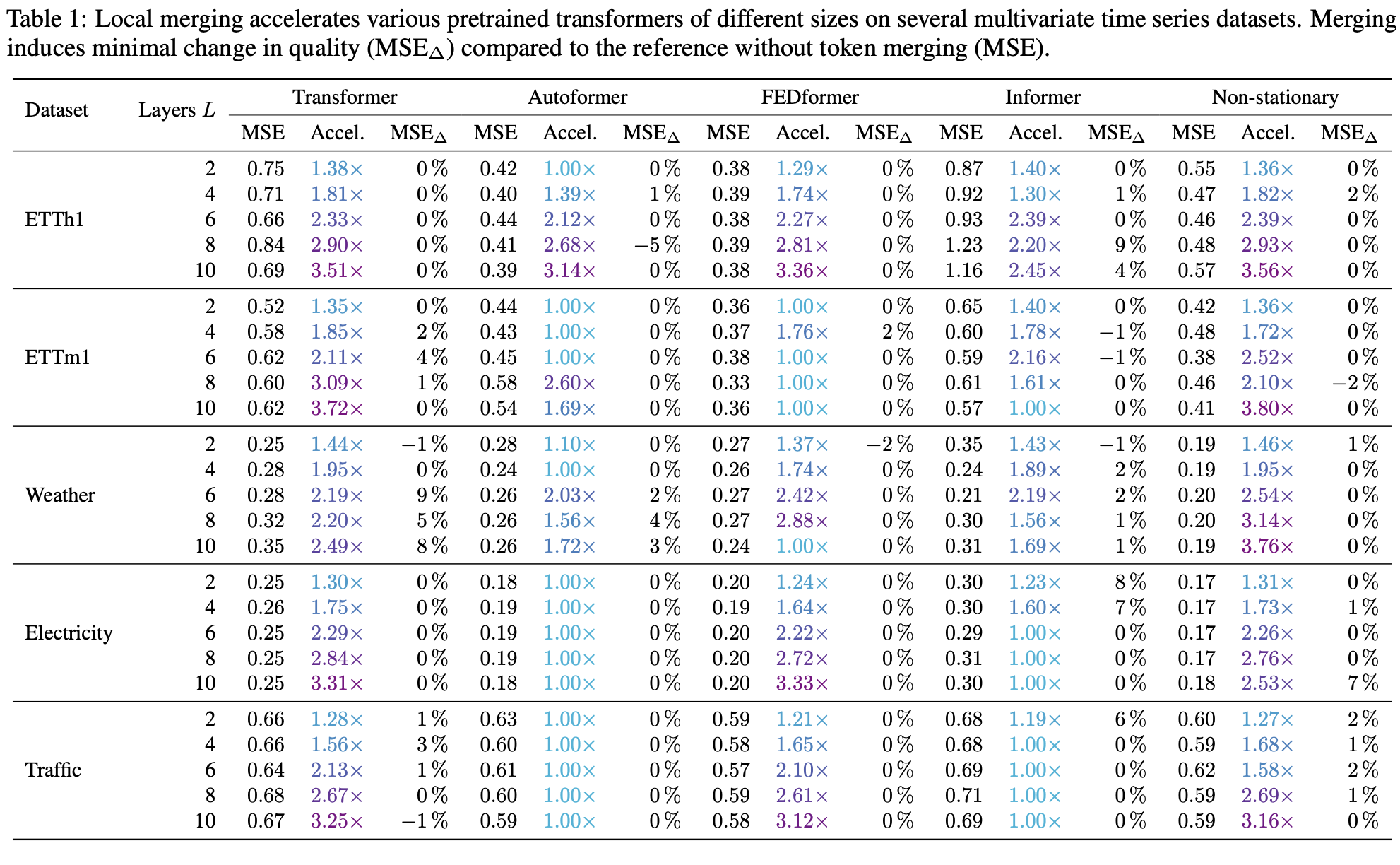
| 문제의식 | 긴 시계열 입력에서 Transformer는 self-attention 때문에 O(t²)로 비용이 급증하고, SSM도 매우 긴 시퀀스에서는 여전히 부담이 큼. 비전에서의 token merging은 잘 알려졌지만, 시계열/SSM/decoder(인과적 생성)로의 일반화가 부족함. |
| 핵심 주장 | Token Merging을 시계열 특성(시간적 국소성)과 인과성에 맞게 재설계하면, 추가 학습 없이도(또는 최소로) 속도를 크게 올리면서 성능 저하를 작게 만들 수 있고, 경우에 따라 성능 향상도 가능. |
| 기본 병합 | 토큰을 두 집합(A,B)으로 나누고, A–B 간 코사인 유사도로 유사한 쌍을 골라 평균(Convex/average)으로 병합해 토큰 수를 줄임. |
| 기존(Global) 한계 | 전역 유사도 행렬 계산이 필요해 O(t²) 오버헤드가 발생 → 긴 시계열에 비효율. |
| Local Token Merging | 유사도 비교를 시간적으로 가까운 토큰 쌍(‖i−j‖<k)으로 제한해 계산을 줄임. k로 효율–정확도 트레이드오프를 연속적으로 제어(k가 작을수록 더 선형에 가까움). |
| Causal Token Merging (Decoder 적용) | 일반 merging은 미래 정보 혼합으로 비인과성 문제가 있어 decoder에 어렵지만, k=1(인접 토큰만 병합)을 쓰면 인과성을 유지하며 적용 가능하다고 주장. 출력 정합을 위해 마지막에 unmerge(복원) 단계(병합 토큰을 인접 동일 토큰으로 복제) 추가. |
| Dynamic Token Merging (적응형 병합) | 레이어/배치마다 병합 가능성이 다르므로 유사도 임계값 기반으로 병합 개수(r)를 동적으로 결정(특히 작은 배치/온디바이스 환경에서 유리하다고 제안). |
| 적용 위치(구현 관점) | Transformer에서는 대체로 self-attention 이후(MLP 전)에 merging을 넣는 구성이 유리하다고 보고. |
| 실험 범위(모델/데이터) | 시계열 forecasting(ETT/Weather/Electricity/Traffic 등)에서 여러 time-series transformer로 평가, 시계열 foundation model Chronos에서 zero-shot 평가, SSM 계열(HyenaDNA, Mamba)에서도 비교/검증. |
| 주요 결과 1: Pretrained TS Transformer 가속 | 다양한 아키텍처/데이터셋에서 throughput을 크게 올리면서 MSE 변화는 작게 유지(깊은 모델일수록 이득이 커지는 경향 관찰). |
| 주요 결과 2: 학습 시 병합으로 안정화 | inference 때만 merging을 넣을 때 성능이 흔들리는 경우에, training에도 merging을 적용하면 정확도 손실 없이 가속(학습도 최대 2.27× 가속 보고). |
| 주요 결과 3: Chronos에서 큰 가속(+성능 향상 사례) | Chronos에서 local merging이 Pareto-optimal 지점을 만들고, 일부 데이터셋에서 정확도와 속도를 동시에 개선. 최대 54.76× 속도 향상, 최대 9% MSE 개선 보고. |
| 주요 결과 4: SSM에도 유효(특히 local) | 16k 길이에서 local(k=1)이 global 대비 더 좋은 정확도–속도 트레이드오프를 보였다고 주장. global은 유사도 계산 오버헤드가 커질 수 있음을 수치로 강조. |
| 왜 성능이 좋아질 수 있나 | token merging을 선택적 스무딩(적응적 저역통과 필터)로 해석: 노이즈 감소로 예측이 좋아질 수 있으며, 실제로 low-pass filtering과 유사한 경향 및 스펙트럼 지표(예: spectral entropy/THD)와의 상관을 보고. |
| 결론/의의 | 시계열 Transformer + SSM + decoder까지 포괄적으로 token merging을 확장해, 긴 시퀀스에서 효율을 실질적으로 끌어올리는 범용 모듈로 제시. |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Sequential Efficient LLM 논문 -3 (0) | 2026.03.03 |
|---|---|
| Sequential Efficient LLM 논문 -1 (0) | 2026.03.03 |
| Latent Reasoning, Soft Thinking 논문 정리 3 (2) | 2026.02.21 |
| Multi-turn, Long-context Benchmark 논문 5 (0) | 2026.02.20 |
| Latent Reasoning, Soft Thinking 논문 정리 2 (0) | 2026.02.20 |