https://arxiv.org/abs/2006.03236
Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing
With the success of language pretraining, it is highly desirable to develop more efficient architectures of good scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the much-overlooked redundancy
arxiv.org
Transformer가 모든 layer에서 토큰 길이를 끝까지 유도하는 것은 리소스 소모가 과하고, 시퀀스 전체를 하나의 벡터로 요약해 사용하는 다운스트림 테스크에서는 그 표현이 상당히 중복될 수 있다고 말한다.
BERT 학습 이후 성능을 올리려면 더 크고 길게 학습이 필요하지만 메모리 비용이 폭증하기에 기존 증류, 프로닝, 양자화나 블록 재설계도 있지만 Transformer의 비용원인인 full-length 토큰 시퀀스를 유지하는 설계 자체가 낭비라고 봄

여기선 Encoder로 압축, Decoder로 복원을 진행하여 Transformer의 구조 자체는 동일하지만 Encoder Block 사이 사이에 Stride 2, Window 2의 간단한 mean pooling을 활용하여 토큰 길이를 줄인다.
Decoder는 줄어든 길이를 한꺼번에 늘려서 이전에 압축 전에 있던 hidden state를 연결하여 사용
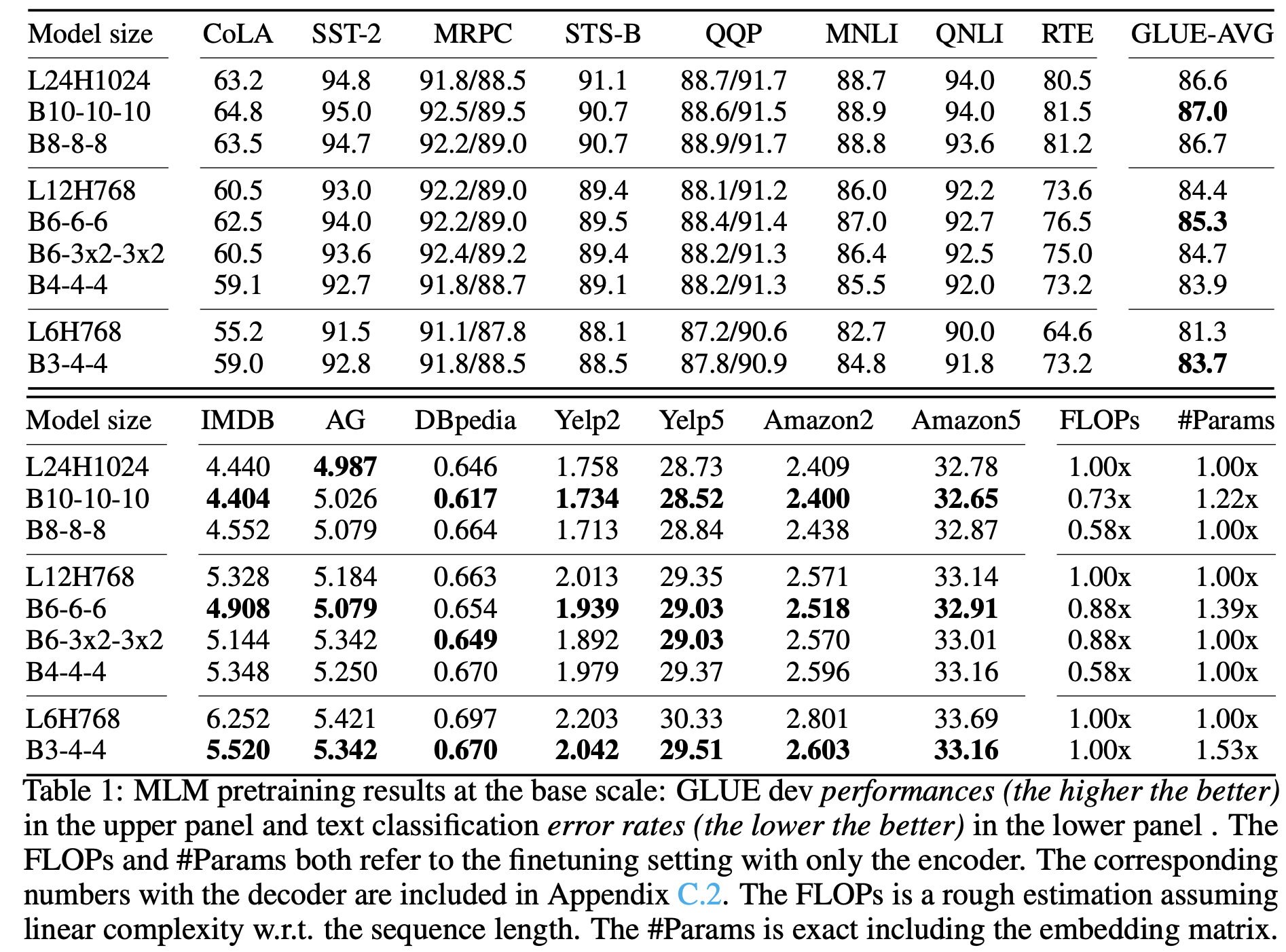
더 적은 FLOPs를 달성했지만 성능을 올린 것을 볼 수 있었음
Squad처럼 토큰 스팬 예측이 중요한 경우에는 표준 트렌스포머가 더 유리한 현상을 보여줌 - 압축이 디테일을 손상함
| 논문 한 줄 요약 | Transformer가 레이어 전반에서 full-length 토큰 시퀀스를 유지하며 발생하는 순차적 중복(redundancy) 을 줄이기 위해, 깊어질수록 시퀀스 길이를 점진적으로 압축(풀링) 하는 encoder를 설계하고, 절약된 FLOPs를 더 깊고/넓은 모델로 재투자하여 같은(혹은 더 적은) 비용으로 성능을 높인다. |
| 해결하려는 문제 | 사전학습 확대로 성능은 오르지만 FLOPs·메모리 비용이 너무 크고 , 특히 분류/랭킹처럼 시퀀스-레벨 단일 벡터([CLS]) 만 쓰는 태스크에서 토큰-level 표현을 끝까지 유지하는 것은 불필요한 중복일 수 있음. |
| 핵심 기여 | (1) Funnel-Transformer(F-TFM): encoder가 블록을 거치며 시퀀스 길이를 단계적으로 감소 (2) 압축으로 절약한 연산을 깊이/폭에 재투자하여 capacity 향상 (3) 토큰-레벨 예측(사전학습/시퀀스 라벨링)을 위해 decoder로 토큰 표현 복원 |
| 방법론 – Encoder 구조 | 여러 블록(block) 의 Transformer layer로 구성. 블록 내에서는 길이 유지, 블록 경계에서 Pooling(h) 으로 길이 축소. |
| 방법론 – 핵심 설계: pool-query-only attention | 풀링된 시퀀스 (h')는 Query(및 residual) 로만 사용하고, 풀링 전 시퀀스 (h)는 Key/Value 로 사용:h←LN(h′+Attn(Q=h′,KV=h)). 이로써 압축이 “단순 풀링”이 아니라 attention 가중합을 포함한 표현력 있는 선형 압축이 됨. |
| 방법론 – 풀링/CLS 처리 | 실험에선 stride=2, window=2 mean pooling만으로도 잘 동작(길이를 절반으로). 또한 [CLS]는 풀링으로 구조가 깨질 수 있어 [CLS]를 분리해 유지하고 나머지에만 풀링 적용. |
| 방법론 – Decoder | encoder 최종 출력(길이 (T/2^{M-1}))을 한 번에 크게 up-sample(반복 복제)하여 길이 T로 복원 → 토큰 디테일 보강을 위해 1블록의 full-length 표현 (h^1) 과 결합(스킵/잔차) 후, decoder에 추가 Transformer layer(논문은 2층) 를 쌓아 토큰-레벨 예측에 사용. |
| 학습/활용 시나리오 | 사전학습/토큰-레벨 태스크는 encoder+decoder, 분류처럼 시퀀스-레벨은 decoder를 버리고 encoder만 finetune. |
| 복잡도/효율 | 표준 Transformer layer 비용: (O(T^2D + TD^2)). 길이를 절반으로 줄이면 super-linear(>1/2) 수준으로 비용 감소가 가능. |
| 대표 설계 예시(깊이-길이 trade-off) | BERTBase(L12H768) 대비, 예: B6-6-6H768(총 18층) 은 분류 finetune 기준 FLOPs가 “full-length 10.5층” 수준으로 줄면서 성능이 더 좋았다고 설명. |
| 실험 결과 – 시퀀스-레벨 | GLUE 등에서 동일/더 적은 FLOPs로 대응 baseline보다 다수 태스크에서 우수. RACE(긴 문장+추론)에서도 유의미한 이득: 긴 문단 압축이 기회가 될 수 있음을 강조. |
| 실험 결과 – 토큰-레벨 | SQuAD에서는 base 그룹에선 강하지만, large 그룹에선 full-length 유지 표준 Transformer가 더 유리한 경우가 있어, 압축이 토큰 디테일에 불리할 수 있음을 인정. |
| Ablation 핵심 결론 | 풀링 종류는 mean/max는 대체로 괜찮지만 Top-Att 기반 선택은 크게 악화.pool-query-only, [CLS] 분리 유지, relative attention 등이 성능에 중요하다고 보고. |
| 결론/의미 | “시퀀스의 순차 해상도(resolution) 를 레이어 깊이에 따라 낮추는” 구조를 통해 Transformer 효율을 개선하고, 절약 FLOPs를 capacity로 재투자해 특히 시퀀스-레벨 태스크에서 비용 대비 성능을 개선하는 방향을 제시. |
https://arxiv.org/abs/2110.13711
Hierarchical Transformers Are More Efficient Language Models
Transformer models yield impressive results on many NLP and sequence modeling tasks. Remarkably, Transformers can handle long sequences which allows them to produce long coherent outputs: full paragraphs produced by GPT-3 or well-structured images produced
arxiv.org
naacl 2022 findings에 뽑혔네요
여기서도 시퀸스 길이에 대해 연산 메모리 비용이 제곱으로 계속 커지는 것을 지적한다. => 대형, 장문 입력에서 병목
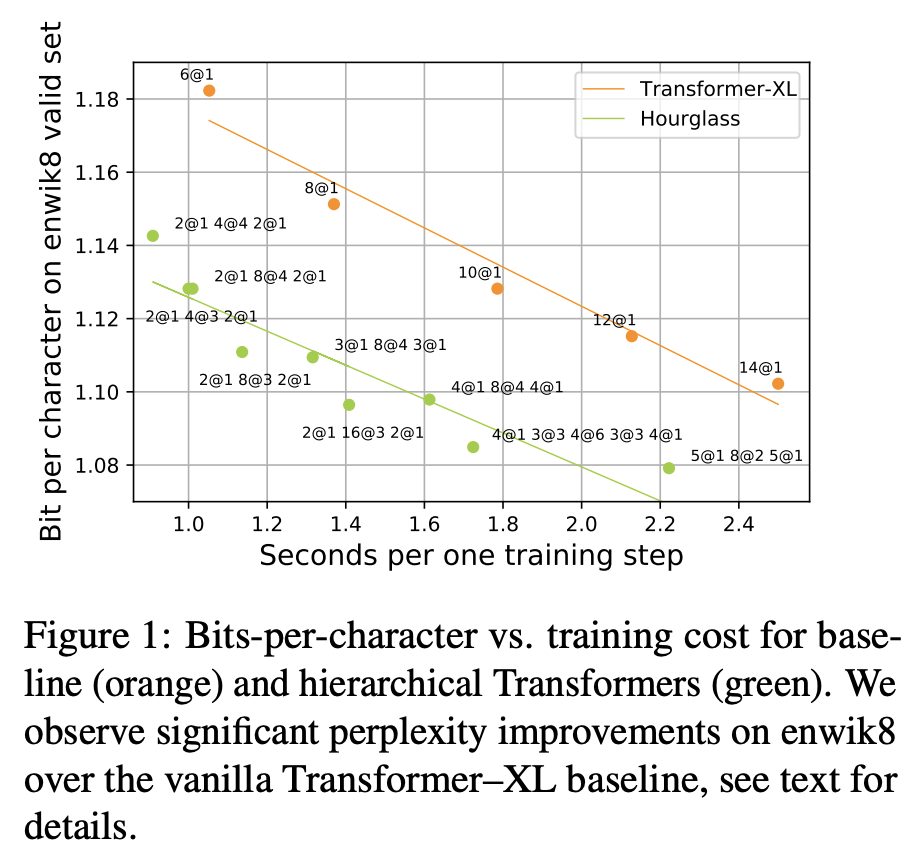
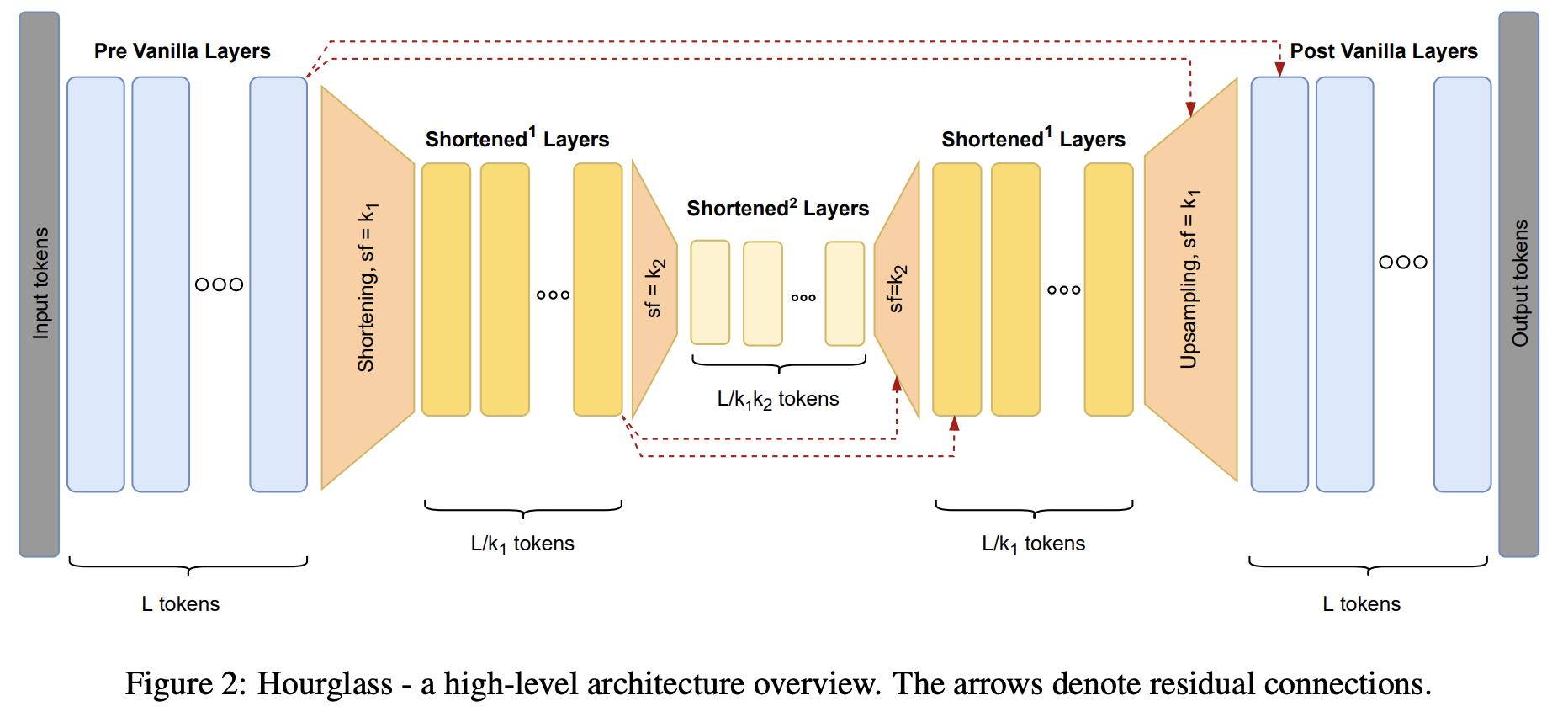
U-Net형 계층적 Autoregressive Transformer형태로 기존 Transformer레이어를 반복하다가 down sampling하는 구간이 있고, 다시 up sampling하면서 줄어든 차원에 이전의 내용을 넣어주며 정보 손실을 줄여줌
| 문제의식 | 표준 Transformer는 시퀀스 길이 (L)에 대해 계산/메모리 비용이 커져(특히 attention) 장문 처리 효율이 낮음. 효율적 attention만으로는 “모든 레이어가 원래 길이 시퀀스를 계속 처리”하는 병목이 남음. |
| 핵심 주장 | 명시적 계층(hierarchy) 을 도입해 레이어 진행 중 시퀀스 길이를 줄였다가(다운샘플) 다시 복원(업샘플) 하면, 같은 비용에서 더 좋은 성능(또는 같은 성능에서 더 적은 비용)을 달성할 수 있음. |
| 제안 모델 | Hourglass(U-Net/Hourglass 형태): (1) 토큰-레벨 pre-vanilla 블록 → (2) shortening → (3) 짧아진 시퀀스에서 블록(재귀적 hourglass 가능) → (4) upsampling(+스킵/잔차 결합) → (5) 토큰-레벨 post-vanilla 블록. |
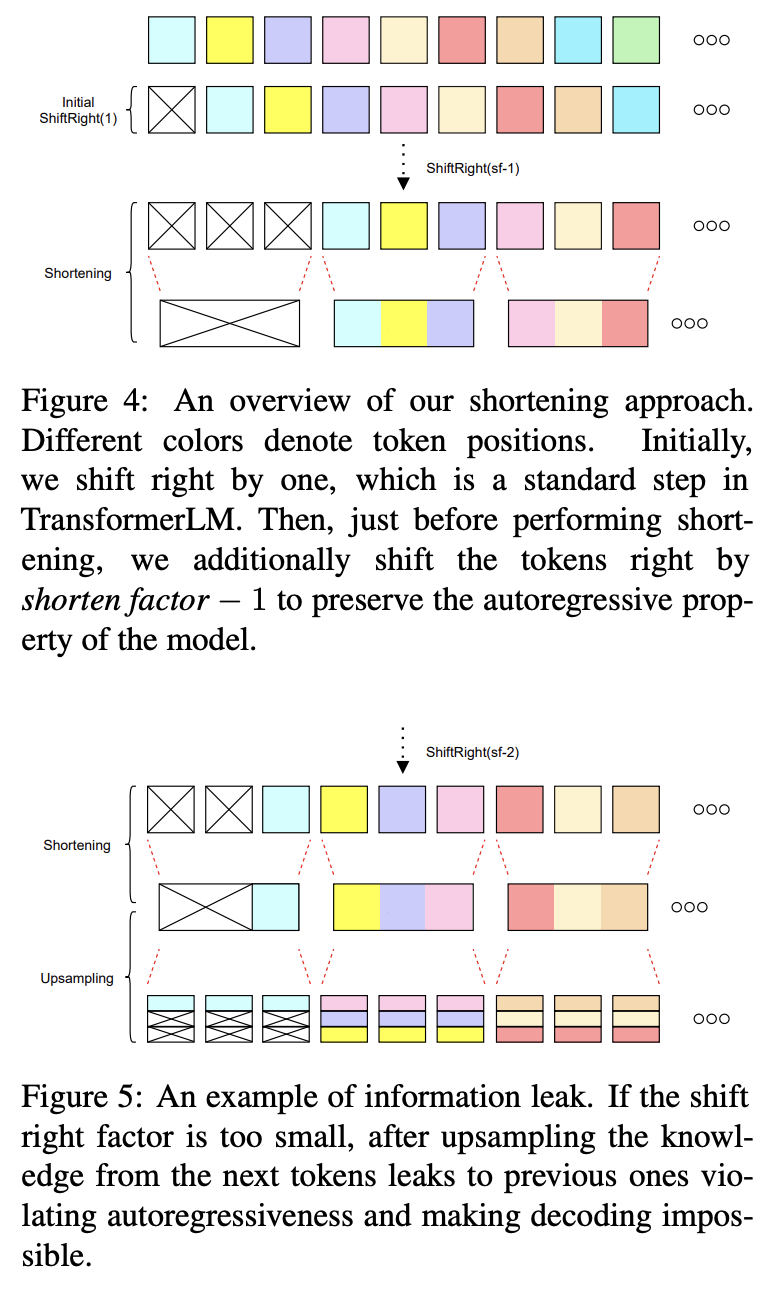
| Causality | Autoregressive에서 다운샘플 시 미래 정보 누출 위험이 있으므로, shortening 직전에 (k-1) shift-right 로 누출을 방지(최소 안전 shift). |
| 표현력 유지 | 너무 이르게(또는 너무 많이) 축소하면 토큰 간 직접 상호작용이 약해져 표현력 저하가 발생하므로, 축소 전/후에 토큰-레벨 vanilla layers 를 유지하는 설계가 중요. |
| Shortening | 길이 (l,d)→(l/k,d). 방식: AvgPool / Linear pooling(reshape→linear) / Attention pooling(Funnel-style). |
| Upsampling | 방식: Repeat / Linear / Attention upsampling(토큰이 축소 표현에서 content-based로 읽어옴). 전반적으로 attention upsampling이 강력하다고 보고. |
| 추가 정규화 | Shorten factor dropout: 훈련 중 shorten factor (k)를 {2,3} 등에서 랜덤 샘플링하여 일반화/성능을 개선. |
| 주요 결과 | enwik8에서 효율-성능 Pareto 개선을 보이며, 예시 구성으로 0.98 BPC 달성을 보고. |
| 주요 결과 | autoregressive 이미지 생성에서도 효과적이며, ImageNet32에서 SOTA(3.741 bpd) 를 주장. |
| 의의 | attention 변형(희소/근사/LSH 등)과 직교적으로 결합 가능한 구조적 효율화 프레임워크(“레이어 내부 시퀀스 길이 자체를 줄이는” 접근). |
https://arxiv.org/abs/2211.09761
Efficient Transformers with Dynamic Token Pooling
Transformers achieve unrivalled performance in modelling language, but remain inefficient in terms of memory and time complexity. A possible remedy is to reduce the sequence length in the intermediate layers by pooling fixed-length segments of tokens. Neve
arxiv.org
이건 2023 acl long에 붙었네요
여기서도 말하는 문제는 동일합니다.
그리고 고정 pooling은 언어의 의미 단위(형태소, 단어, 구)가 가변 길이라는 점과 충돌해 성능 손실이 난다고 말한다.

중간 레이어에서 토큰을 가변 길이 세그먼트로 동적으로 묶어 효율을 얻되, 그 세그먼트 경계를 모델이 예측하도록 하여 효율과 성능 모두를 개선하게 됩니다.

BPC는 낮을 수록 좋고, SF는 높을 수록 좋음
| 문제의식 | Transformer는 시퀀스 길이 (l)에 대해 계산/메모리 비용이 커서 비효율적이며, 중간 레이어에서 고정 길이 토큰 묶음(pooling) 으로 길이를 줄이는 기존 방식은 단어/구 등 의미 단위가 가변 길이라는 언어 특성과 불일치해 성능 손실이 생긴다. |
| 핵심 주장 | 중간 레이어에서 세그먼트 경계를 동적으로 예측해 가변 길이 세그먼트 pooling을 수행하면, 동일/유사한 계산 예산에서 더 빠르고 더 정확한 Transformer를 만들 수 있다. |
| 제안 모델 | Dynamic-Pooling Transformer: (1) 경계 예측으로 세그먼트 생성 → (2) 세그먼트 단위로 pooling하여 중간 시퀀스 단축 → (3) 짧아진 시퀀스에서 연산 → (4) AR 생성 가능하도록 원 길이로 업샘플링(Hourglass 계열의 “줄였다가 복원” 골격 위에 동적 경계를 결합). |
| 경계(boundary) 획득 방법 | 4가지 비교: (i) 확률적 재매개변수화 기반 end-to-end 학습(Gumbel-Sigmoid), (ii) subword tokenizer(Unigram) 분절을 supervision으로 사용, (iii) conditional entropy spike 기반 supervision, (iv) 언어학적 규칙(whitespace 등). |
| 평가 세팅 | Character-level language modeling을 여러 데이터셋/언어에서 수행. |
| 평가 지표 | BPC(bits per character; ↓): 예측 품질(음의 로그확률) SF(shortening factor; ↑): 중간 레이어에서 평균적으로 얼마나 길이를 줄였는지(효율). |
| 주요 결과(정확도/효율 트레이드오프) | 영어 벤치마크(text8, wiki40b, CC-100)에서 whitespace 기반과 Unigram 기반 동적 분절이 가장 낮은 BPC를 기록하며, vanilla 및 고정 pooling 대비 통계적으로 유의미하게 우수하고, 동시에 가장 큰 SF(더 많이 단축) 를 달성한다. |
| 수치 예시(Table 1) | text8에서 Vanilla: BPC 1.143 (SF 1.0x) 대비, Unigram: 1.134⋆ (SF 5.0x), Whitespaces: 1.133⋆ (SF 5.7x) 로 성능(BPC)과 효율(SF)을 함께 개선. |
| 효율 측정(시간/메모리) | 구현 측정에서 SF=2면 메모리/학습시간이 40%+ 감소, SF=4에서도 동적 pooling이 더 좋은 BPC를 유지하며 자원 사용이 50–60% 감소하고 학습이 2.5× 빠름. |
| 결론/의미 | “고정 길이” 대신 “가변 의미 단위에 정렬된 동적 세그먼트 pooling”이라는 inductive bias를 주면, Transformer를 더 잘 스케일시키면서 예측 품질도 개선할 수 있다는 실증을 제시한다(효율–성능 Pareto front 개선). |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Sequential Efficient LLM 논문 -3 (0) | 2026.03.03 |
|---|---|
| Sequential Efficient LLM 논문 -2 (0) | 2026.03.03 |
| Latent Reasoning, Soft Thinking 논문 정리 3 (2) | 2026.02.21 |
| Multi-turn, Long-context Benchmark 논문 5 (0) | 2026.02.20 |
| Latent Reasoning, Soft Thinking 논문 정리 2 (0) | 2026.02.20 |