728x90
728x90
https://arxiv.org/abs/2511.06411
SofT-GRPO: Surpassing Discrete-Token LLM Reinforcement Learning via Gumbel-Reparameterized Soft-Thinking Policy Optimization
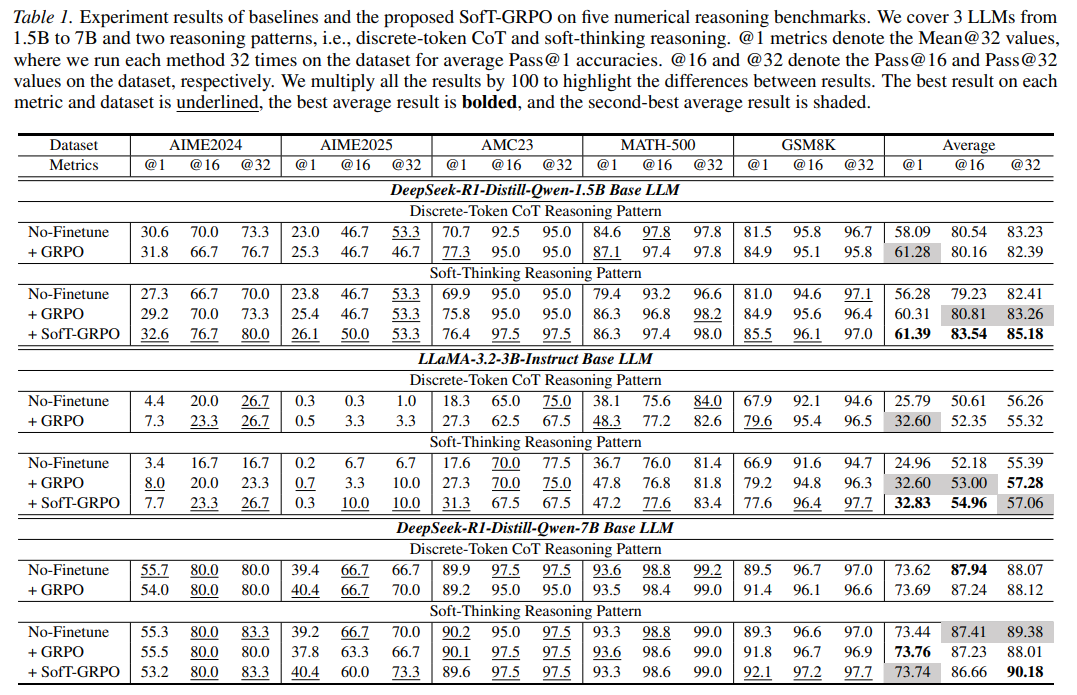
The soft-thinking paradigm for Large Language Model (LLM) reasoning can outperform the conventional discrete-token Chain-of-Thought (CoT) reasoning in some scenarios, underscoring its research and application value. However, while the discrete-token CoT re
arxiv.org
딱 제가 하려고 했던 아이디어 인데.....
일단 나와있으니 논문을 한번 읽어보겠습니다

Soft-Thinking은 토큰을 추상적 개념으로 전달할 수 있어




728x90
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Multi-turn, Long-context Benchmark 논문 5 (0) | 2026.02.20 |
|---|---|
| Latent Reasoning, Soft Thinking 논문 정리 2 (0) | 2026.02.20 |
| Latent Reasoning, Soft Thinking 논문 정리 1 (1) | 2026.02.19 |
| Multi-turn, Long-context Benchmark 논문 4 (0) | 2026.02.04 |
| Privacy AI 관련 조사 13 (0) | 2026.02.03 |