https://ieeexplore.ieee.org/document/10681073
KDPII: A New Korean Dialogic Dataset for the Deidentification of Personally Identifiable Information
The rapid growth of social media in the era of big data and artificial intelligence has raised significant safety concerns related to the communication of sensitive personal information. In modern society, awareness of the importance of preserving privacy
ieeexplore.ieee.org
한국어 환경에서의 개인정보 비식별화 연구가 체계적으로 뒤쳐져 있다!
기존 연구와 데이터셋은 한국어의 언어적 특성(교착어, 맥락 의존성, 사회 문화적 표현)을 충분히 반영하지 못하며 실제 서비스 환경과 가까운 대화 맥락에서 PII(개인정보) 식별은 거의 다뤄지지 않음
1. 한국어 특성을 반영한 PII 분류 체계 정립
2. 실제 대화 기반의 대규모 한국어 PII 데이터 셋 구축
3. 한국어 언어모델의 PII 식별 능력을 체계적으로 진단

기존 NER 태그를 그대로 쓰지 않고 한국 개인 정보 보호법 + TTA 개체명 체계를 재해석하여 8개의 1차 카테고리, 33개의 2차 세부 PII 태그를 정의함


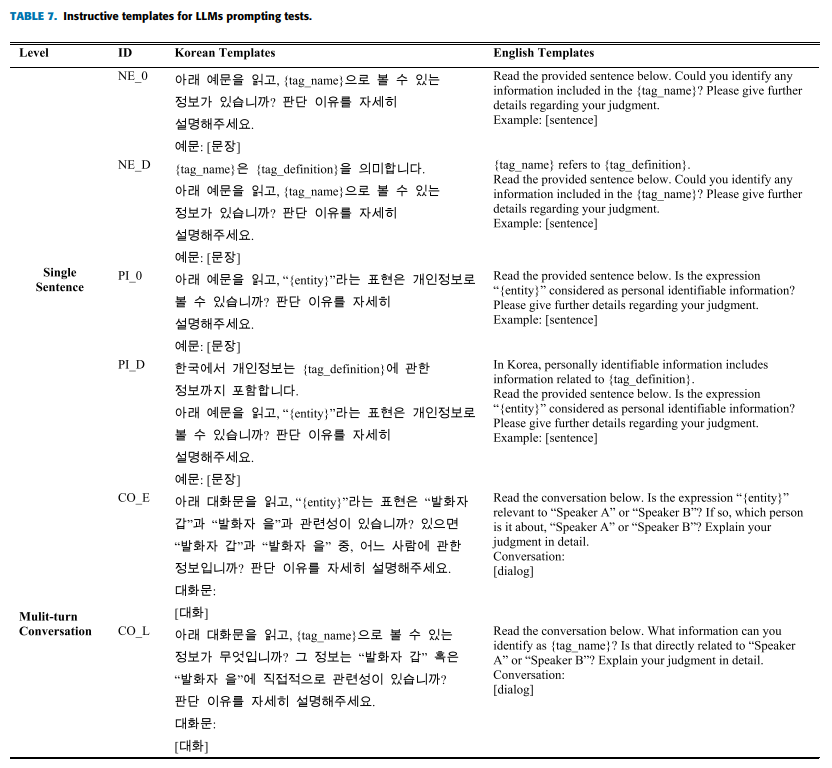
한국어 대화형 PII 데이터 셋을 제작
4581개 대화 세트로 약 5만개의 문장이 존재하고, 3만 2천개의 PII 어노테이션, 2인 대화의 3 ~ 6턴으로 이루어져 실제 상담/메신저 환경을 반영하였다.
구조화된 주민번호나 전화번호 같은 PII는 매우 잘 처리하지만 비구조적, 맥락, 의존 PII 성능은 급감함 (이름, 별명, 직장, 장소 등)
모델 크기와 성능의 scaling law는 유지됨
https://zenodo.org/records/16759166
KDPII DATASET REVISED
KDPII: A New Korean Dialogic Dataset for the Deidentification of Personally Identifiable Information The rapid growth of social media in the era of big data and artificial intelligence has raised significant safety concerns related to the communication of
zenodo.org
데이터는 여기 있습니다.
| 연구 배경 | 대규모 언어모델의 확산으로 개인정보(PII) 유출 위험이 증가했으나, 한국어는 언어적·문화적 특성으로 인해 기존 영어 중심 PII 분류·데이터·평가 체계를 그대로 적용하기 어렵다는 한계가 존재한다. |
| 문제의식 | 기존 한국어 데이터셋은 NER 중심이거나 구조적 PII 위주로 구성되어 있어, 실제 대화 환경에서 등장하는 맥락 의존적·한국어 특화 PII를 충분히 다루지 못한다. |
| 연구 목적 | 한국어 대화 환경에서 개인정보 비식별화를 정밀하게 수행하기 위해, 한국어 특성을 반영한 PII 분류 체계를 정의하고 이를 기반으로 한 대화형 데이터셋을 구축하며, 한국어 LMs와 LLMs의 PII 처리 한계를 체계적으로 분석한다. |
| 핵심 기여 | (1) 한국어 언어·문화 특성을 반영한 33개 세부 PII 태그를 포함한 최초의 한국어 PII 분류 체계 제안, (2) 실제 대화 맥락을 반영한 대규모 한국어 대화형 PII 데이터셋(KDPII) 구축, (3) 한국어 LMs와 LLMs를 아우르는 종합적인 PII 식별 성능 평가 수행 |
| PII 분류 체계 | 개인정보를 8개 1차 범주(개인·위치·식별번호·일반식별·직업·학력·온라인·군 관련 정보)로 나누고, 총 33개 세부 PII 태그로 세분화하여 한국어 특유의 표현(군부대, 직위, 동아리, 별명 등)을 명시적으로 포함한다. |
| 데이터 구성 | 4,581개 2인 대화 세트, 약 50,011문장으로 구성되며, 실제 메신저·상담 상황을 모사한 3–6턴 대화 구조를 갖는다. 총 31,954개의 PII가 어노테이션되었다. |
| 어노테이션 품질 | 언어학 및 NLP 전공자 10명이 참여한 이중 검증 절차를 거쳤으며, 최종 인터어노테이터 합의도(IAA)는 92.5%로 높은 신뢰성을 확보하였다. |
| LM 평가 방법 | Transformer 기반 한국어 언어모델 14종에 대해 BIO 태깅 기반 시퀀스 라벨링 방식으로 fine-tuning을 수행하고, F1 score를 통해 PII 식별 성능을 평가하였다. |
| LLM 평가 방법 | ChatGPT, Gemini, Mistral, Clova, KULLM, KOLLAMA2 등 6개 LLM을 대상으로 PII 중심 프롬프트를 설계하여 질의응답 실험을 수행하고, 문법성·사실성·논리성 기준으로 전문가 수작업 평가를 진행하였다. |
| 주요 실험 결과 | 구조화된 PII(전화번호, 주민번호 등)는 높은 정확도로 식별되었으나, 이름·별명·직장·동아리·직위·군부대 등 비구조적·맥락 의존 PII는 전반적으로 낮은 성능을 보였다. 평균 F1은 약 0.83 수준이다. |
| 주요 실험 결과 | 대부분의 LLM은 한국어 문법성은 우수하나, PII 범주 판단의 사실성·논리성이 낮았으며, 특히 한국어 특화 PII에서 오류가 빈번했다. 한국어 대규모 학습을 거친 Clova가 상대적으로 가장 안정적인 성능을 보였다. |
| 핵심 분석 | 개인정보 식별 성능의 주요 병목은 보편적(universal) PII가 아니라, 언어·문화 맥락에 강하게 의존하는 한국어 특화(language-specific) PII에 있음을 실증적으로 확인하였다. |
| 결론 | 한국어 PII 비식별화는 단순 NER 문제가 아니며, 언어적 감각과 문화적 지식을 요구하는 문제로, 향후 한국어 특화 데이터 확장과 모델 학습 전략 개선이 필수적이다. |
| 활용 및 확장 | KDPII는 한국어 프라이버시 보호 LLM 연구, 의료·법률·상담 도메인 평가, 언어별 PII 비교 연구 및 프라이버시 강화 학습 기법 검증을 위한 표준 벤치마크로 활용 가능하다. |
https://www.sciencedirect.com/org/science/article/pii/S1546221825009907


| 연구 목적 | 한국어 텍스트 데이터에서 언어적 특성만으로도 개인 재식별이 가능한지를 실증적으로 분석하고, 기존 비식별·가명처리 기준의 한계를 규명 |
| 연구 배경 | PII(이름·전화번호 등) 제거 후에도 작성 습관·형태소·높임말 등 언어적 특징으로 개인 식별 가능성 존재, 국내 LLM 학습 확산으로 위험성 증가 |
| 핵심 문제의식 | 현재 비식별화는 토큰 단위 PII 제거에 치중되어 있으며, **언어적 준식별자(quasi-identifier)**에 대한 고려가 부족 |
| 데이터셋 | X(구 Twitter) 한국어 텍스트, 50명 저자 × 1,000문장 (총 50,000문장) |
| 전처리 요소 | 형태소 분석, 불용어 제거, 텍스트 수치화(Tokenization) |
| 형태소 분석기 비교 | OKT, Kkma, Komoran, Hannanum → OKT가 가장 안정적·고성능 |
| 불용어 처리 비교 | 일반 제거, 빈도 기반, TF-IDF, Word2Vec, GloVe, 미적용 → 저자 수 증가 시 빈도 기반 제거가 가장 안정적 |
| 텍스트 표현 방식 | Tokenizer(단어 순서 유지) vs BoW → Tokenizer가 압도적으로 우수 |
| 분류 모델 | LSTM, Random Forest, XGBoost, SVM, Logistic Regression |
| 최적 기본 모델 | LSTM + OKT + Tokenizer + 불용어 제거 + 하이퍼파라미터 튜닝 |
| BERT 비교 | KLUE-BERT와 정확도 유사, 학습 시간은 LSTM이 훨씬 짧음 |
| 분석한 한국어 속성 | 형태소, 결속어, 높임말, 음절 수, 음소 수 |
| 가장 중요한 속성 | 형태소 기반 어휘 빈도 (가장 높은 F1-score) |
| 최대 저자 식별 성능 | 정확도 90.51% (2명 저자 기준) |
| 재식별 위험 분석 | 형태소 기반 고빈도 단어 제거 전 27.31% → 제거 후 19.53% |
| 핵심 실험 결론 | 한국어에서는 형태소·어휘 사용 습관이 강력한 재식별 단서로 작용 |
| 주요 기여 | 한국어 텍스트에서 언어적 특성을 재식별 위험 요소로 정량 입증 |
| 정책·실무 시사점 | 비식별 처리 시 언어 습관·형태소 분포까지 고려한 기준 필요 |
| 한계 | 저자 수 증가 시 정확도 감소, 대규모 적용 시 계산 비용 증가 |
| 향후 연구 | 효율적인 재식별 저감 기법, 대규모·실시간 텍스트 적용 방안 |
https://arxiv.org/abs/2506.15266
Thunder-DeID: Accurate and Efficient De-identification Framework for Korean Court Judgments
To ensure a balance between open access to justice and personal data protection, the South Korean judiciary mandates the de-identification of court judgments before they can be publicly disclosed. However, the current de-identification process is inadequat
arxiv.org
2025 emnlp findings에 붙은 논문입니다.
한국 법원 판결문은 공개 원칙과 개인 정보 보호를 동시에 만족해야 하므로 공개 전 비식별화가 원칙이다.
그러나 기존 시스템은 수작업에 의존하고, 자동화는 8 ~ 15% 수준에 불과함. LLM 기반 접근은 문장 구조와 사실을 변형하여 법적 정밀성 훼손 및 보안 정책 위반 가능성이 존재함
=> 법적 요구사항을 충족하면서도 대규모 판결문에 적용 가능한 고정밀 자동 비식별화 프레임워크가 부재함
토큰 단위 NER 기반 DNN 파이프라인을 통해 정확성, 일관성, 확장성을 동시에 만족하는 판결문 비식별화 프레임워크를 제안함
단순 NER 문제가 아니라 법적 맥락을 반영한 PII 정의 + 후처리까지 포함한 시스템 문제 => LLM 기반 재작성이 아닌 토큰 단위 분류가 본질적으로 더 안전하고 적합하며, 한국어의 형태론적 특성을 반영한 전용 토크나이저 없이는 고정밀 비식별화가 불가능함

기존에 비식별화 된 데이터에 PII 범주로 재라벨링 진행하여 데이터 셋 구축
한국어 특화 토크나이저인 Mecab-ko(형태소 분석) + BPE를 통해 조사 어미 분리로 비식별화 이후에도 문법과 가독성을 유지
동일 판결문에 대해 에폭마다 다른 엔티티를 치환하여 표면형 다양성을 증가하고, 저빈도 라벨은 LLM 보조 생성 + 수작업 검증으로 보완 함
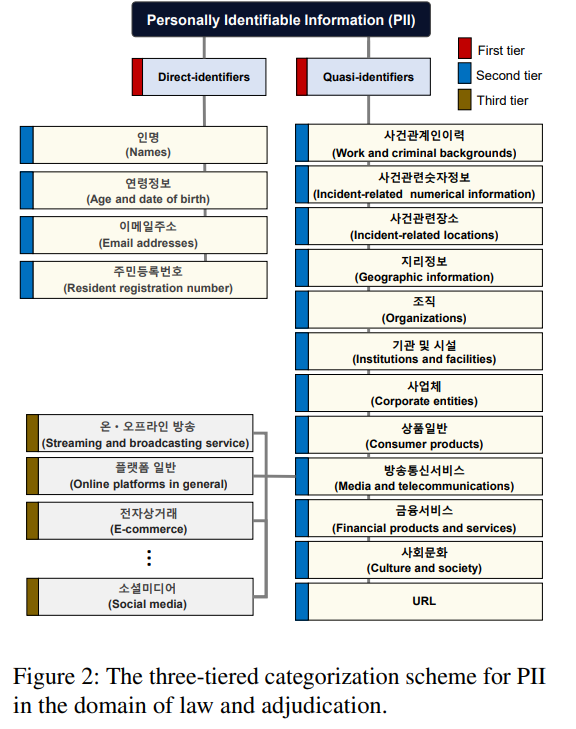
기존 법 규정을 기술적으로 재해석하여 장소, 조직, 숫자, 사건 맥락 정보까지 포함하여 재식별 위험 중심 설계를 진행함

https://github.com/mcrl/SNU_Thunder-DeID
GitHub - mcrl/SNU_Thunder-DeID
Contribute to mcrl/SNU_Thunder-DeID development by creating an account on GitHub.
github.com
데이터도 여기에
| 연구 배경 | 한국 법원 판결문은 공개 전 개인정보 비식별화가 법적으로 의무이나, 기존 수작업 중심 절차는 확장성이 없고 자동화 도구의 정확도는 8–15%로 매우 낮음 |
| 문제의 핵심 | (1) 대규모 판결문 처리 불가, (2) 법률상 개인정보(PII) 정의가 기술적으로 모호, (3) LLM 기반 비식별화는 문장·사실 왜곡 및 보안 정책 위반 위험 |
| 연구 목표 | 한국 법·실무에 정합적인 고정밀·대규모 자동 판결문 비식별화 프레임워크 구축 |
| 핵심 아이디어 | 프롬프트 기반 LLM 재작성 대신 토큰 단위 NER 기반 DNN 비식별화를 사용하여 문맥·사실 왜곡을 원천 차단 |
| 데이터셋 | 민사·형사·행정 판결문 6,700건, 총 48,306개 엔티티 수작업 주석 (한국 최초 판결문 비식별화 전용 데이터셋) |
| 데이터 제약 대응 | 원문 판결문 접근 불가 → 이미 비식별화된 판결문에서 placeholder를 재주석하고 실제 엔티티 치환 리스트를 별도 구축 |
| PII 분류 체계 | 3단계 계층 구조: Direct / Quasi Identifier → 16개 상위 범주 → 80개 세부 범주, 총 729개 라벨 |
| PII 범위 특징 | 이름·번호뿐 아니라 사건 관련 장소, 조직, 숫자, 맥락 정보까지 포함 (재식별 위험 중심 설계) |
| 토크나이저 | Mecab-ko(형태소 분석) + BPE 결합 → 조사/어미 분리로 한국어 문법·가독성 유지 |
| 학습 데이터 생성 | 라벨된 판결문에 대해 실제 엔티티를 치환하여 학습 데이터 생성 |
| 데이터 증강 | Per-Epoch Entity Replacement: 에폭마다 다른 엔티티 치환 → 데이터 다양성 및 일반화 성능 향상 |
| 모델 | DeBERTa-v3 기반 Thunder-DeID (370M / 800M / 1.5B) |
| 비교 모델 | Polyglot-Ko (1.3B), EXAONE-3.5 (2.4B) |
| 평가 지표 | Binary Token-level F1, Token-level Micro F1 (729-class) |
| 핵심 성능 | 최대 Binary F1 ≈ 0.98, Token-level Micro F1 ≈ 0.91 |
| 주요 결과 | 모든 설정에서 기존 한국어 법률 모델 대비 성능 우수, 한국 판결문 비식별화 SOTA 달성 |
| 정성적 장점 | 문장 구조·법적 사실 왜곡 없음, 법원 실무 규칙과 정합적인 후처리 가능 |
| 한계 | 원문 판결문 기반 실환경 평가 불가, 일부 저빈도 라벨 성능 한계 |
| 연구 의의 | 모델이 아닌 데이터·PII 정의·토크나이저·증강·시스템 전체를 포괄한 비식별화 프레임워크 제시 |
| 확장 시사점 | 한국 외 타 국가 판결문 비식별화, 의료·공공 문서 비식별화로 확장 가능 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Privacy AI 관련 조사 12 (0) | 2026.02.02 |
|---|---|
| Multi-turn, Long-context Benchmark 논문 3 (0) | 2026.01.31 |
| ALIENLM: ALIENIZATION OF LANGUAGE FORPRIVACY-PRESERVING API INTERACTION WITHLLMS (0) | 2026.01.28 |
| Privacy AI 관련 조사 11 (0) | 2026.01.27 |
| Privacy AI 관련 조사 10 (0) | 2026.01.26 |