https://arxiv.org/abs/2309.08963
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
Despite the remarkable capabilities of Large Language Models (LLMs) like GPT-4, producing complex, structured tabular data remains challenging. Our study assesses LLMs' proficiency in structuring tables and introduces a novel fine-tuning method, cognizant
arxiv.org
Naacl 2024 short에 붙은 논문입니다.
LLM은 구조화된 테이블을 잘 못 만든다는 문제에서 출발해 강화시킵니다.

단순히 TEXT 만으로 정확한 형식에 맞처 생성하기 어렵기에 포맷을 추가하여 학습시키는 모습이다.

GPT 모델보다 학습을 진행한 모델이 좀 더 잘하는 것을 볼 수 있다.
| 📌 문제 상황 | - LLM(GPT-4 포함)은 자유 텍스트 생성은 잘하지만, 복잡한 구조화된 테이블 (LaTeX, HTML 등) 생성에는 어려움이 있음 - 기존 평가는 단순 단어 유사도(BLEU, ROUGE)에 치중되어 구조적 정확성을 반영하지 못함 |
| 🧪 방법론 | ① FORMATCOT (Self-Instruct 방식) → GPT-3.5로 포맷 정보를 생성하여 데이터 구성 ② Instruction Tuning → {텍스트 + 포맷 설명} → 테이블 구조 출력으로 LLaMA-7B 파인튜닝 ③ 평가 지표 개발 - P-Score (GPT-3.5로 CoT 평가) - H-Score (Levenshtein + difflib 기반 휴리스틱 평가) |
| 🧾 벤치마크 | - STRUC-BENCH: 구조 생성 전용 벤치마크 제안 - 3가지 형식: Raw Text Table / HTML / LaTeX - RotoWire 및 The Stack 데이터셋 기반 |
| 🎯 결과 요약 | - Fine-tuned LLaMA-7B(Ours-7B)가 GPT-3.5 / GPT-4보다 전반적인 구조 정확성 우수 - 콘텐츠 및 포맷 점수(P/H-score) 모두 최고 성능 - FORMATCOT이 없는 경우 성능 급락 (Ablation 실험) |
| 🌟 기여 | ✅ STRUC-BENCH: 테이블 구조 생성 특화 벤치마크 구축 ✅ FORMATCOT: 포맷 인식 학습용 instruction 생성 기법 ✅ P/H-score: 구조화 출력 평가를 위한 새로운 지표 제안 ✅ 소형 모델도 대형 모델을 특정 작업에서 능가 가능성 입증 |
| ⚠️ 한계 | - 📐 테이블 포맷 다양성(정답 구조가 여러 개 존재 가능)에 대한 정규화 미고려 - 🧬 도메인 특화 구조 평가 미흡 (예: 의학, 금융) - ➕ 수치 계산 능력 부족 (e.g. 합계, 평균 등) - 🎨 멀티모달 구조 출력(표+이미지 등) 확장 필요 |
https://arxiv.org/abs/2403.19318
TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
We introduce TableLLM, a robust large language model (LLM) with 8 billion parameters, purpose-built for proficiently handling tabular data manipulation tasks, whether they are embedded within documents or spreadsheets, catering to real-world office scenari
arxiv.org
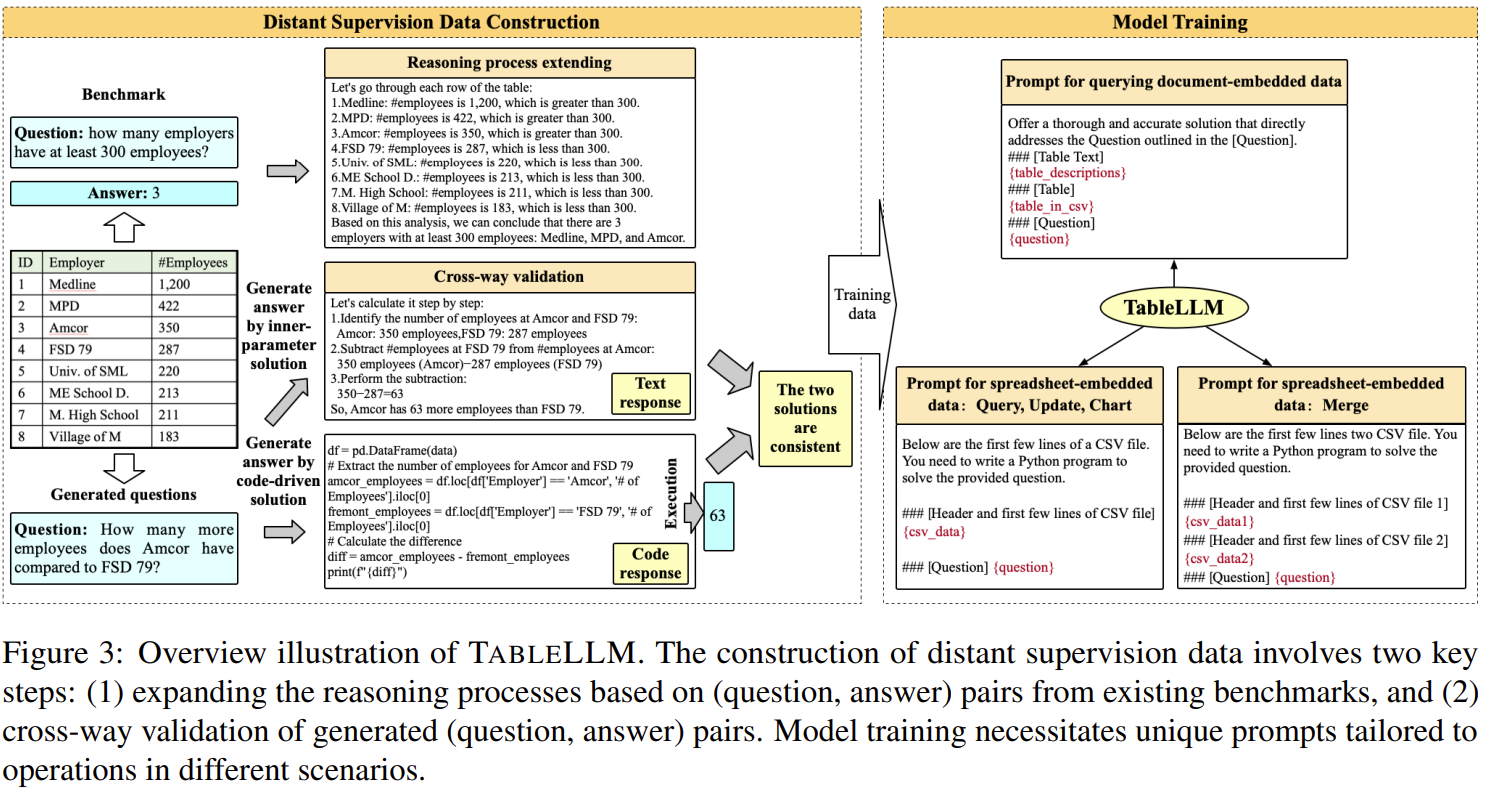
Reasoning Path를 추가하고, Cross-way validation을 통해 정답을 생성하는데 text와 code 모두 답이 일치해야 신뢰할 수 있는 샘플로 간주된다.
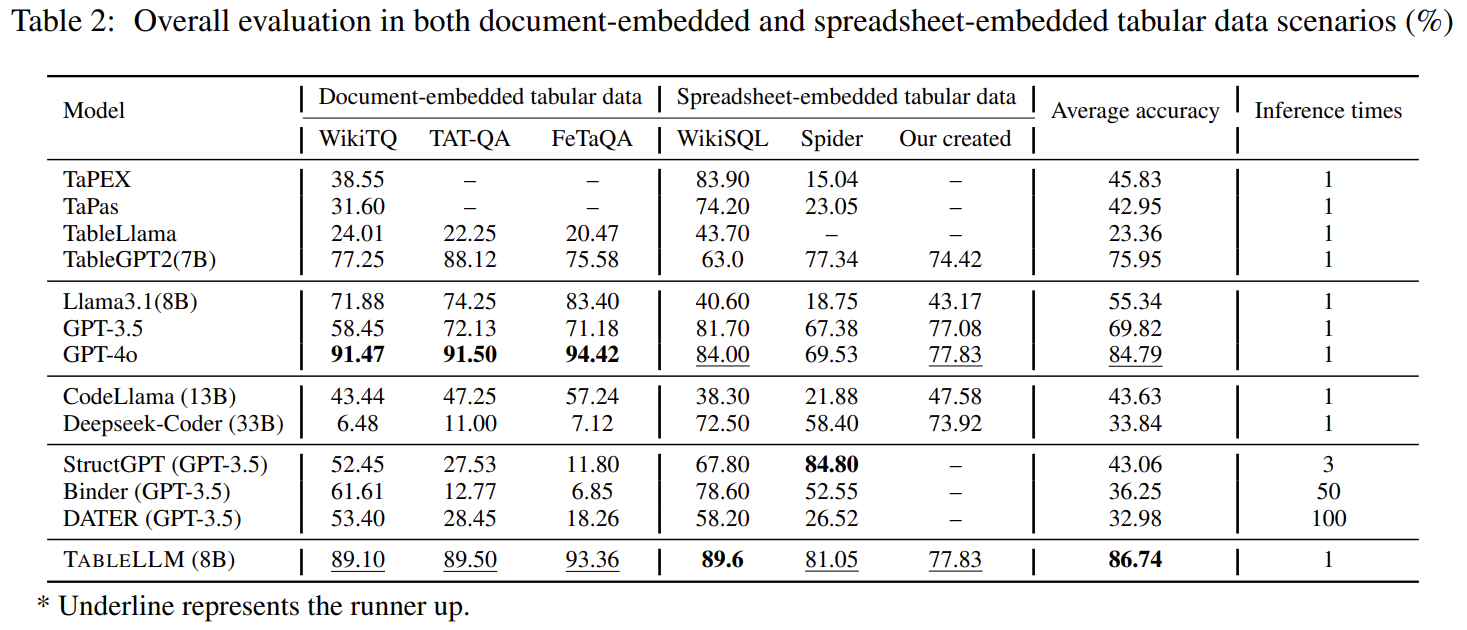
inference times도 적고, 성능도 4o와 가장 유사하면서 높은 모델이 되었다.
| 문제 상황 (Motivation) | - 실제 오피스 환경(Word, PDF, Excel, CSV 등)에서 테이블 작업은 복잡하고 다양하지만, 기존 LLM은 TableQA에만 국한되고 조작(Update, Merge, Chart 등)은 미흡함. - 특히 스프레드시트의 긴 테이블, 문서의 텍스트+표 혼합 쿼리 등은 기존 방식으로 처리 어려움. |
| 목표 (Goal) | - 문서와 스프레드시트 양쪽에서 다양한 테이블 작업을 처리할 수 있는 범용 LLM(TableLLM) 개발 - 단일 모델로 쿼리, 수정, 병합, 차트까지 모두 대응 가능한 실제 사무 작업 자동화 |
| 방법론 (Methodology) | ✅ Distant Supervision 기반 학습 데이터 구성 • 기존 QA 벤치마크(WikiTQ, TAT-QA 등)에서 reasoning-rich 데이터 생성 • GLM-4-Plus로 reasoning 과정 확장 (CoT 스타일) • 코드 기반 reasoning은 Pandas 코드로 생성 ✅ Cross-way Validation • 동일 질문에 대해 자연어 답변과 코드 실행 결과를 비교 • 두 결과가 일치할 때만 학습에 사용 (신뢰도 향상) ✅ 시나리오별 Prompt 학습 • 문서 기반: Text + Table + Question • 스프레드시트 기반: CSV 일부 + Question (Merge는 2개의 CSV) ✅ LLaMA3.1(8B) fine-tuning: 총 73K 학습 샘플, 1:1 비율로 문서/스프레드시트 데이터 혼합 |
| 실험 결과 (Results) | 📌 Table 2 기준 • 전체 평균 정확도: 86.74% (모델 중 최고) • 문서 기반 성능: GPT-4o와 유사한 수준 (WikiTQ: 89.1%, TAT-QA: 89.5%) • 스프레드시트 기반 성능: GPT-4o 초과 (WikiSQL: 89.6%) • 자체 생성된 unseen benchmark에서도 77.83% 성능 • 추론 횟수: 1회만으로도 고성능 (Binder: 50회, DATER: 100회) |
| 기여 (Contributions) | 1️⃣ 실제 오피스 환경 기반의 다양한 테이블 조작 시나리오 대응 모델 2️⃣ reasoning 확장 + code reasoning + cross-way validation 기반 고품질 학습 데이터 자동 생성 방법 제안 3️⃣ 문서/스프레드시트를 모두 처리 가능한 범용 단일 모델 구조 제안 4️⃣ 모델, 학습 데이터셋, 웹 애플리케이션 전부 공개 |
| 한계 (Limitations) | ⚠️ 자동 생성 질문의 다양성 부족 ⚠️ 기존 벤치마크 중심이라 현실적 복잡도/구조 다양성이 충분히 반영되지 않을 수 있음 ⚠️ 표+텍스트 조합의 고난도 추론에서 일부 오류 (Error 분석: Question 이해 실패 多) |
https://arxiv.org/abs/2406.10922
Generating Tables from the Parametric Knowledge of Language Models
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating struct
arxiv.org
LLM의 테이블 생성 가능성을 평가하려고 하네요
전반적으로 낮은 성능을 기록하고, 3가지 테이블 생성 방식을 제안하였음
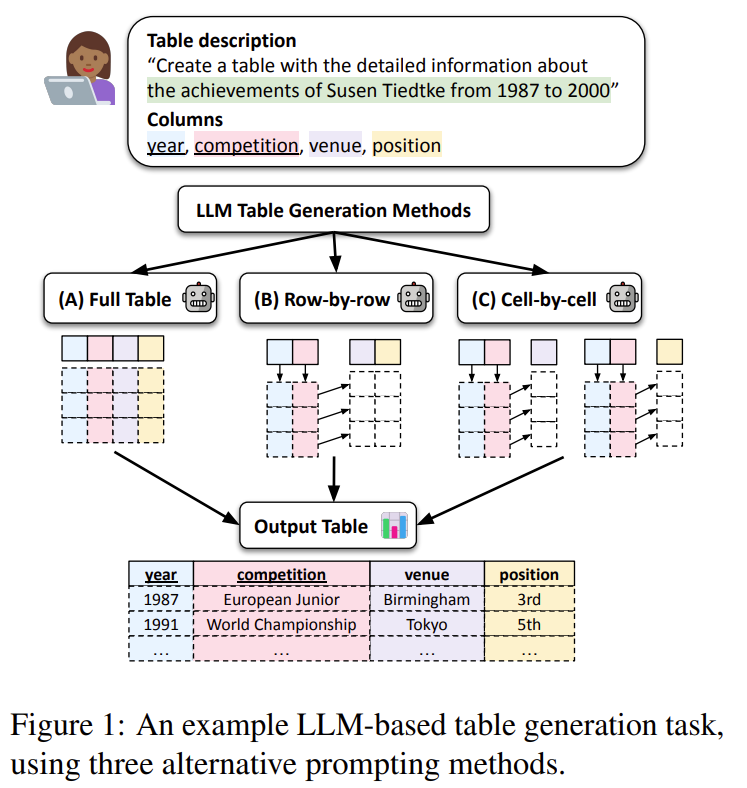
1. Full table : 전체 테이블 다 생성하기 BUT 누락 확률 증가
2. Row by Row : 주요 키 컬럼의 리스트 먼저 생성 후 각 키에 대한 행을 생성하도록 해서 그나마 안정적이고 정확도가 높으나 호출 회수가 많아져 토큰 비용이 높음
3. Cell by Cell : key리스트 먼저 생성 후 각 키마다 각 컬럼별로 셀 값을 개별적으로 생성하여 세밀하게 제어 가능하지만 프롬프트 수가 행 * 열이 되어 비용 큼


성능이 낮은 것을 볼 수 있다....
| 문제 상황 (Problem) |
- LLM은 다양한 텍스트 기반 지식은 잘 생성하지만 → 구조화된 테이블 형식의 지식 생성 능력은 미지수 - 특히, 내부 파라미터에 저장된 지식만으로 얼마나 정확한 테이블을 생성할 수 있는지 평가 |
| 목표 (Goal) |
- 자연어 설명과 컬럼 정보를 입력으로 받아 → 사실적으로 정확한 테이블 생성 - 외부 검색이나 문서 없이, 모델 자체의 지식만 사용 |
| 방법론 (Methodology) |
🔹 3가지 프롬프트 전략 ① Full-table: 한 번에 전체 테이블 생성 ② Row-by-row: 키 생성 후 각 행 생성 ③ Cell-by-cell: 키 생성 후 각 셀 개별 생성 🔹 평가 벤치마크: WIKITABGEN - 100개 Wikipedia 테이블 + 정답 포함 - 크기, 숫자비율, 인기도 등 다양성 반영 |
| 실험 모델 (Models) |
- GPT-3.5, GPT-4 - LLaMA2-13B, LLaMA2-70B |
| 주요 결과 (Results) |
🔸 GPT-4 + Row-by-row 방식 최고 성능 (F1 = 19.6%) 🔸 키 컬럼은 비교적 정확 (F1 ≈ 53.7%) 🔸 Non-key 셀은 정확도 낮음 (F1 ≈ 12~19%) 🔸 예시 행 제공 또는 키를 미리 주면 성능 향상 🔸 테이블 크기↑, 숫자 비율↑, 인기도↓ → 성능 하락 |
| 기여 (Contributions) |
✅ LLM을 활용한 테이블 생성 문제 최초 제시 ✅ 세분화된 프롬프트 방식 (3가지) 설계 및 실험 ✅ WIKITABGEN 벤치마크 구축 및 공개 ✅ 성능에 영향을 미치는 구조적 요인 분석 ✅ 정량 평가 체계 (Precision / Recall / F1) 도입 |
| 한계 (Limitations) |
⚠️ 소규모 벤치마크 (100개 테이블) ⚠️ Wikipedia 기반 정보에만 한정됨 ⚠️ 엄격한 정답 기준 → 포맷 오류도 불일치 처리 ⚠️ Row/Cell 방식은 비용이 매우 큼 (프롬프트 수 많음) |
| 결론 (Conclusion) |
- LLM이 구조적 데이터(테이블)를 생성하는 능력은 아직 제한적 - 하지만 프롬프트 분해 전략(Row-by-row)으로 정확도 개선 가능 - 향후 대규모/다양한 테이블, 외부 지식 결합 방식, 비용 절감 방안 등의 연구 필요 |
| Generating Tables from the Parametric Knowledge of Language Models | Are LLMs Really Good at Generating Complex Structured Data? | |
| 문제 정의 | LLM의 내부 파라미터에 저장된 지식만으로 사실적인 테이블 생성이 가능한가? | LLM이 복잡한 포맷(LaTeX, HTML 등)을 갖는 구조적 테이블을 정확히 생성할 수 있는가? |
| 입력 형태 | ✔️ 자연어 설명 + 컬럼 리스트 ❌ 외부 문서 없음 |
✔️ 자연어 설명 + 포맷 설명(FormatCoT) ✔️ 복잡한 포맷 구조를 포함한 텍스트 |
| 출력 목표 | ✔️ JSON 형태의 표준 테이블 → 단순 구조 (Wikipedia 기반) |
✔️ Raw text, LaTeX, HTML 등 다양한 복잡한 테이블 포맷 |
| 방법론 | ① Full-table ② Row-by-row ③ Cell-by-cell → 세분화된 프롬프트 전략 |
FORMATCOT: GPT-3.5를 활용한 포맷 중심 self-instruct 학습 + LLaMA-7B 파인튜닝 |
| 평가 벤치마크 | 📘 WIKITABGEN (Wikipedia 기반, 100개) → 자연어 설명과 정답 테이블 쌍 제공 |
📘 STRUC-BENCH (RotoWire, HTML, LaTeX 등 다양) → 다양한 포맷 구조를 포함 |
| 평가 방식 | - 키/비키 구분 후 F1 계산 - 정밀하게 매칭 (포맷 오류도 오답 처리) |
- P-score (LLM 기반 체인-오브-생각 평가) - H-score (휴리스틱 포맷-컨텐츠 정합성 평가) |
| 결과 요약 | - GPT-4 최고 성능: F1 19.6% (row-by-row) - 테이블 크기, 숫자 비율, 인기 등 구조적 요소가 성능에 영향 |
- GPT-4도 복잡한 포맷에서 정확도 낮음 → FormatCoT + LLaMA-7B fine-tune 모델이 모든 지표에서 GPT-4보다 우수 |
| 기여 | - LLM의 내부 지식 기반 테이블 생성 문제 정의 - 3가지 프롬프트 방식 비교 - WIKITABGEN 공개 |
- 복잡한 포맷을 포함한 테이블 생성 평가 - FORMATCOT + LLaMA-7B 방식 제안 - 새로운 평가 지표 (P/H-score) 도입 |
| 한계 | - Wikipedia에만 기반 - 소규모 (100개) - 비용 문제로 더 큰 실험 어려움 |
- 포맷 선택 최적화에 대한 연구 부족 - 도메인 특화 벤치마크 미포함 - 수치 추론 능력 한계 있음 |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| DoGe 관련 논문 조사 5 - LayoutLLM, DocLLM (6) | 2025.07.08 |
|---|---|
| DoGe 관련 논문 조사 4 - LongRefiner, PDFTriage (4) | 2025.07.08 |
| Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts When Knowledge Conflicts? (2) | 2025.07.07 |
| DoGe 관련 논문 조사 2 - SKR, Self-Prompting (0) | 2025.07.06 |
| DoGe 관련 논문 조사 1 - Don't Do RAG, In-context, internal knowledge (1) | 2025.07.06 |