https://arxiv.org/abs/2412.15605
Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
Retrieval-augmented generation (RAG) has gained traction as a powerful approach for enhancing language models by integrating external knowledge sources. However, RAG introduces challenges such as retrieval latency, potential errors in document selection, a
arxiv.org
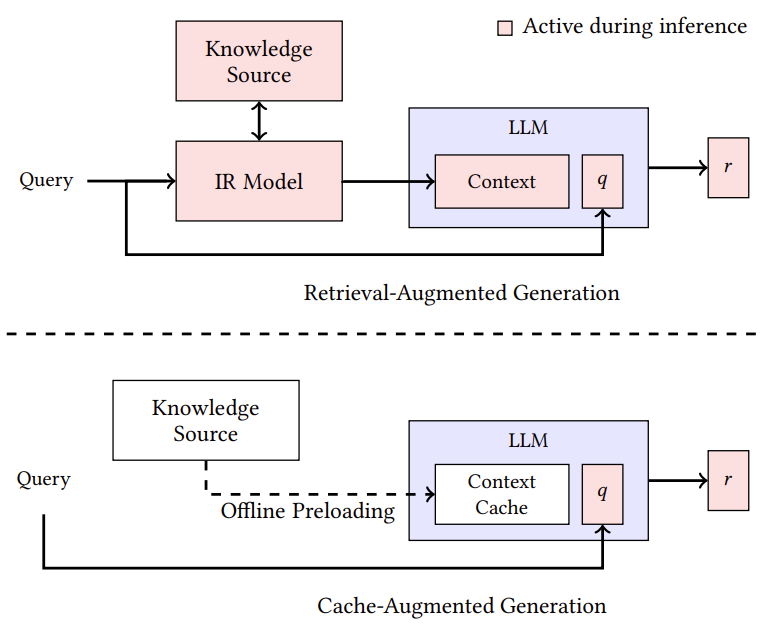


이 논문은 요즘 LLM의 Context length가 기니 굳이 검색하고, In-context로 넣지 말고, 문서를 통째로 넣어 KV cahce를 만들어서 Query 함께 넣어주는 방식으로 Latency 문제를 해결하자는 논문 입니다.
문서 전체가 들어와야 하니 Context length에 제한적인 방법이라 저는 유용한 논문인진 잘 모르겠네요 ㅎㅎ
| 문제 상황 | - 기존 RAG는 외부 문서를 실시간 검색하여 LLM 입력에 포함 - 지연(latency), 검색 오류, 시스템 복잡도 증가가 문제 - Long-context LLM(Llama 3.1 등)의 발전으로 retrieval 없는 QA 가능성 대두 |
| 제안 방법 (CAG) | 🔹 Cache-Augmented Generation (CAG) 제안 1. 문서를 미리 LLM에 입력해 KV-Cache 생성 (오프라인) 2. 추론 시 질의만 입력하고 KV-Cache를 활용하여 응답 생성 3. 질의 후 토큰을 제거하여 KV-Cache 재사용 가능 ✅ retrieval 없음, context 통합, 구조 단순화 |
| 실험 및 결과 | - 데이터셋: SQuAD 1.0, HotPotQA (단일/멀티 문서 QA) - 비교 대상: BM25 RAG, Dense RAG (OpenAI), In-Context Learning - BERTScore 기준 성능: CAG가 대부분의 설정에서 최고 점수 - 속도 측면: Dense RAG > CAG > Sparse RAG (retrieval 포함 시) → CAG는 빠르고 일관된 응답 생성 가능 |
| 기여 | ✅ Retrieval-free QA 가능성 입증 (RAG 대체) ✅ KV-Cache 활용으로 빠른 추론 실현 ✅ 간단한 시스템 구조로 개발 및 유지 용이 ✅ 실제 적용 가능한 프레임워크 및 오픈소스 공개 |
| 한계점 | ⚠ 문서 전체가 context window 내에 들어와야 함 (ex. Llama 3.1 → 128K) ⚠ 지식량이 많은 도메인엔 부적합 ⚠ 문서가 자주 변경될 경우 KV-Cache 재생성 필요 |
| 활용 가능 분야 | - FAQ 시스템, 사내 위키봇, 고객 지원 QA, 의료/법률 도메인 등 - 도메인 제한적이며 지식량이 manageable한 시나리오에 적합 |
https://arxiv.org/abs/2502.20245
From Retrieval to Generation: Comparing Different Approaches
Knowledge-intensive tasks, particularly open-domain question answering (ODQA), document reranking, and retrieval-augmented language modeling, require a balance between retrieval accuracy and generative flexibility. Traditional retrieval models such as BM25
arxiv.org
이 논문은 기존에 존재하는 RAG의 다양한 방식 실험을 진행하였습니다.
| 🧩 문제 상황 | - ODQA, IR, LM 같은 지식 집중형 작업에서 retriever는 정확하지만 문맥 이해 부족 generator는 문맥 표현은 우수하지만 hallucination 발생 ⇒ 각 접근법의 trade-off 존재 |
| 🧪 방법론 | 세 가지 접근 비교: ① Retriever: BM25, DPR, Contriever, MSS 등 ② Generator: GenRead (질문 기반 문서 생성) ③ Hybrid: R+G, G+R 조합 + reranking (UPR, RankGPT) 실험 task: - Open-domain QA: NQ, TriviaQA, WebQ - 정보 검색: TREC, BEIR - 언어 모델링: WikiText-103 (perplexity 기준) |
| 📊 실험 결과 | ✅ ODQA: · MSS-DPR (Top-1 on NQ: 50.17%) · GenRead (Top-1 on TriviaQA: 69.41%) ✅ Re-ranking: · RankGPT 사용 시 Top-100 정확도 극대화 (91.16%) ✅ IR (BEIR): · BM25+Gen+RankGPT → nDCG@10 = 52.59 (vs BM25 43.42) ✅ Language Modeling: · BM25 + GPT-2 → Perplexity 29.56 (생성 기반보다 낮음) |
| 🧠 기여 (Contribution) | - 새로운 방법 제안은 ❌ 없지만, ✅ 다양한 접근법을 동일 조건에서 대규모 비교 실험 ✅ Hybrid 조합 + reranking 구조에 대한 성능 영향 체계적 분석 ✅ Retrieval → Generation 순서(R+G)가 G+R보다 일관되게 우수함을 실증 |
| ⚠ 한계 (Limitations) | - Novel architecture 없음 (기존 방식 조합) - Hybrid 방식은 계산 비용과 확장성 문제 존재 - Generator와 Retriever의 alignment 불일치 시 성능 저하 가능 - 의료·법률 등 도메인 특화 QA 미포함 - Benchmark 중심으로, 실제 응용 다양성은 제한적 |
| 💡 요약 한줄 | “기존 retrieval/generation/hybrid 방식을 대규모 실험을 통해 체계적으로 비교한 논문으로, retrieval의 중요성과 hybrid 전략의 강점을 실증적으로 보여줌.” |
https://arxiv.org/abs/2405.19010
Evaluating the External and Parametric Knowledge Fusion of Large Language Models
Integrating external knowledge into large language models (LLMs) presents a promising solution to overcome the limitations imposed by their antiquated and static parametric memory. Prior studies, however, have tended to over-reliance on external knowledge,
arxiv.org
모델 내부 지식(Kp)은 시간이 지나면 구식이 되고, 외부 지식(Ke)은 노이즈나 불완전할 수 있다!
-> 두 지식을 효과적으로 융합하여 답변을 생성하는 능력이 중요한데 체계적 분석이 부족
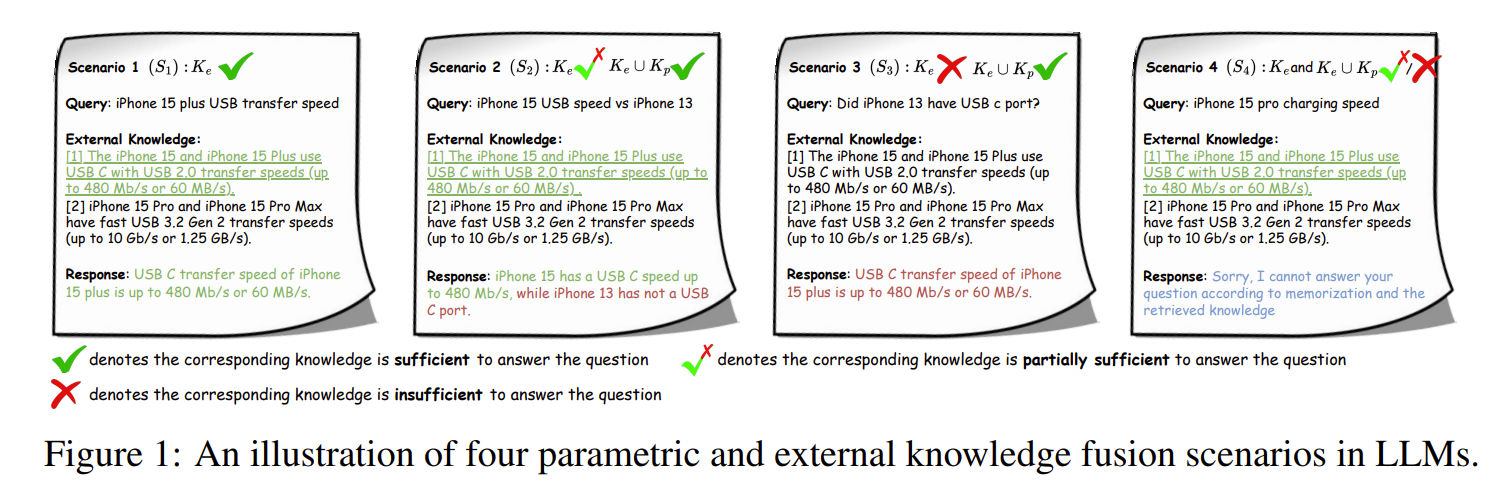
4가지 시나리오로 진행된다.
- S1: Ke만으로 충분한 경우
- S2: Ke는 불완전하고 Kp가 보완해야 하는 경우
- S3: Ke는 무의미하고, Kp만 필요한 경우
- S4: Ke도 Kp도 무용지물로, LLM이 답변을 거절해야 하는 경우

데이터셋 구축 파이프라인이다.
최근 데이터들은 학습되지 않았기에 Ke로 두고, 과거 제품들은 학습되었을 확률이 있기에 Kp로 두고 나중에 또 학습도 진행한다.

그래도 확실히 CT(문서 그대로를 학습 like Pre training)가 효과가 있습니다.

| 시나리오 | 조건 | 주요 결과 |
| S1 (Ke만 충분) | 외부 지식만으로 정답 가능 | 🔹 GPT-4가 가장 우수 (81.7%) 🔹 SFT가 효과적이지만 CT는 불필요하거나 오히려 성능 저하 가능 🔹 노이즈 삽입 시 성능 하락 명확 (Ke 활용 능력 저조) |
| S2 (Ke + Kp 필요) | 외부 지식은 부분적, 나머지는 내부 지식 필요 | 🔹 CT가 필수, 단 CT만으로는 완전한 정답 생성에는 한계 🔹 CT+SFT 조합이 가장 우수 (최대 72.1%) 🔹 파라메트릭 지식 호출 능력은 약 60% 수준 |
| S3 (Kp만 필요) | 외부 지식은 무관, 내부 지식만으로 정답 생성 | 🔹 CT 이후 성능 크게 상승 🔹 ChatGLM: CT+SFT 시 35%까지 향상 🔹 그러나 여전히 Easy 모드(ground-truth 제공)에 비해 43.3%p 낮음 |
| S4 (답변 불가능) | Ke도 Kp도 부족 | 🔹 모든 모델이 거절에 실패하고 틀린 답을 생성 (hallucination) 🔹 CT+SFT는 약간의 개선 효과가 있지만 본질적 문제는 남음 |
| 🧩 문제 상황 (Problem Setting) | - LLM의 파라메트릭 지식(Kp)은 구식이며, 외부 지식(Ke)은 불완전/노이즈 포함 가능 - 많은 연구가 외부 지식에만 의존, 내부 지식 활용은 미흡 - LLM이 Ke와 Kp를 효율적으로 융합하는 능력은 체계적으로 분석된 적이 없음 |
| 🎯 연구 목표 | - 외부 지식(Ke)과 파라메트릭 지식(Kp)의 융합 능력을 4가지 시나리오(S1~S4)로 분해하고 분석 - LLM이 외부 지식이 불완전하거나 무관한 상황에서 Kp를 보완적으로 사용할 수 있는가?를 정량 실험 |
| 🧠 방법론 (Methodology) | - 전자제품 도메인의 최신/구식 데이터를 수집 → Ke / Kp로 분할 - GPT-4로 시나리오별 QA 생성 (S1~S4) • S1: Ke만 • S2: Ke+Kp • S3: Kp만 • S4: 둘 다 없음 - Kp는 CT (Continued Training)으로 모델에 주입 - QA 데이터로 SFT (Supervised Fine-Tuning) 수행 - 다양한 LLM(ChatGLM, Qwen, GPT-4)에 대해 정량 실험 |
| 🧪 결과 (Results) | - S1 (Ke만): SFT가 가장 효과적, CT는 성능 저하 가능 - S2 (Ke+Kp): CT+SFT 조합이 가장 좋음 (Ke와 Kp를 융합함) - S3 (Kp만): CT 없이는 거의 불가능, CT+SFT로 성능 향상 - S4 (답변 불가능): 대부분 LLM이 거절 실패, overconfidence 문제 심각 - 전체적으로: CT로 Kp를 주입해도 지식 호출이 불완전, 노이즈에 매우 취약 |
| 🌟 기여 (Contributions) | - Ke & Kp 융합 상황을 4가지 시나리오로 체계화 - 도메인 기반 QA 데이터셋 구축 (Ke/Kp 명확 분리, 노이즈 포함) - 다양한 오픈소스 및 상용 LLM을 대상으로 융합 능력 정량 비교 - 융합 실패 원인을 실험적으로 분석하여 향후 연구 방향 제시 |
| ⚠️ 한계 및 과제 (Limitations & Challenges) | - CT로 학습한 Kp도 부분적으로만 기억됨 - Ke와 Kp를 함께 줘도 효율적으로 융합하는 능력 부족 - LLM은 "자신이 모르는 걸 모른다"는 인식 결여 (거절 응답 실패) - 노이즈에 매우 민감, 외부 지식에 과신하여 잘못된 답 생성 가능 - 향후 과제: ⬇ • Kp 주입 최적화 • 노이즈 필터링 전략 • 지식 경계 인식과 거절 판단 강화 • 파라메트릭 vs 외부 지식의 동적 결합 전략 |