https://arxiv.org/abs/2310.05002
Self-Knowledge Guided Retrieval Augmentation for Large Language Models
Large language models (LLMs) have shown superior performance without task-specific fine-tuning. Despite the success, the knowledge stored in the parameters of LLMs could still be incomplete and difficult to update due to the computational costs. As complem
arxiv.org
LLM의 내부 지식은 완전하지도 않고 업데이트도 얼려워서 외부 지식을 불러오는 Retrieval-Augmentation(RA)는 도움이 될 수 있지만 오히려 성능을 떨어뜨릴 때도 있고, LLM은 스스로 아는 것과 모르는 것도 구분하지 못한다.
Self-Knowledge guided Retrieval(SKR)을 통해 자기가 아는지 모르는지를 판단하게 하여 외부 지식이 필요한 질문에만 Retrieval을 수행하자!

검색된 페세지가 오히려 정답에 악영향을 끼쳤다.

모델이 아는 것과 모르는 것을 추론하여 라벨을 붙인 다음 아는 것과 모르는 것에 대해 학습하여 모르는 것은 retriever를 활용한다!
1. Retrieval 없이 문제를 풀었을 때와 있이 풀었을 때의 결과 비교를 통해 Self-knowledge 측정
2. 위 결과를 토대로 이 질문을 아는지 모르는지에 대해 추론하도록 prompting or In-Context Learning or Classifier 학습 or kNN 진행
3. 위 결과를 통해 Retrieval 사용 결정

KNN 방식

kNN 방식이 제일 효과가 좋은 것을 알 수 있다.
그리고 무작정 Retrieval을 사용하는 것보다 필요할 때만 쓰는 것이 성능이 더 좋았다.
| 📌 문제 상황 | 🔹 LLM의 파라미터 기반 지식은 완전하지 않고 업데이트가 어려움 🔹 Retrieval-Augmented 방식은 외부 지식을 보완하지만 항상 도움이 되지 않으며, 오히려 성능을 떨어뜨릴 수도 있음 🔹 따라서 retrieval을 쓸지 말지를 LLM이 스스로 판단할 수 있는 능력(Self-Knowledge)이 필요함 |
| 🧠 제안 방법 (SKR) | 🔸 질문이 LLM 내부 지식만으로 충분한지(known) 또는 외부 지식이 필요한지(unknown) 판단 🔸 unknown일 때만 retrieval을 수행하는 적응형 구조 제안 🔸 Self-Knowledge를 수집하고, 추론하여, 활용하는 3단계 파이프라인 |
| ⚙️ 방법론 구성 | 1. Self-Knowledge 수집 • 학습 질문에서 retrieval 전후의 정확도 비교 → D⁺(known) / D⁻(unknown) 분류 2. Self-Knowledge 추론 (qₜ에 대해) ① Direct Prompting ② In-Context Learning ③ Classifier (BERT) ④ k-Nearest Neighbors (SimCSE) 3. Retrieval 사용 여부 결정 • known: LLM 단독 답변 • unknown: retrieved passage 추가 입력 후 답변 |
| 📊 주요 결과 | 🔸 5개 QA 데이터셋 (TemporalQA, CommonsenseQA, TabularQA, StrategyQA, TruthfulQA) 실험 🔸 SKR-kNN이 모든 baseline (CoT, IR-CoT 등) 대비 최고 성능 • ChatGPT 기준 최대 +4.2% 향상 • InstructGPT 기준 최대 +4.08% 향상 |
| 🎯 핵심 기여 | ✅ LLM의 self-knowledge 개념을 정의하고 실제 활용 가능하게 설계 ✅ Retrieval을 동적으로 적용하는 SKR 구조 제안 ✅ Prompt-free, 학습 기반, 비지도 기반 등 다양한 self-knowledge 추론 전략 비교 제시 ✅ 불필요한 retrieval 남용 방지 + 성능 향상 동시 달성 |
| ⚠️ 한계점 | ❌ Prompt 기반 self-knowledge 추론 정확도 낮음 (~72%) ❌ 실험 도메인이 일반 QA에 제한됨 (법률, 의료 등 확장 미검증) ❌ 다양한 외부 도구(계산기, 코드 실행기 등) 활용은 고려되지 않음 ❌ kNN 기반 방법은 대규모 환경에선 계산 비용 우려 |
https://arxiv.org/abs/2212.08635
Self-Prompting Large Language Models for Zero-Shot Open-Domain QA
Open-Domain Question Answering (ODQA) aims to answer questions without explicitly providing specific background documents. This task becomes notably challenging in a zero-shot setting where no data is available to train tailored retrieval-reader models. Wh
arxiv.org
Open-Domain Question Answering (ODQA)에서는 질문에 대한 문서를 명시적으로 제공하지 않고도 정답을 생성해야 하나 Zero-shot 설정에서는 학습 데이터나 외부 문서 없이 LLM만으로 답해야 하므로 매우 어렵고, 기존 Direct Prompting 방식은 성능이 낮고 LLM의 잠재력을 충분히 활용하지 못함.
=> Self-Prompting Framework를 통해 LLM 스스로 ICL 해보자!
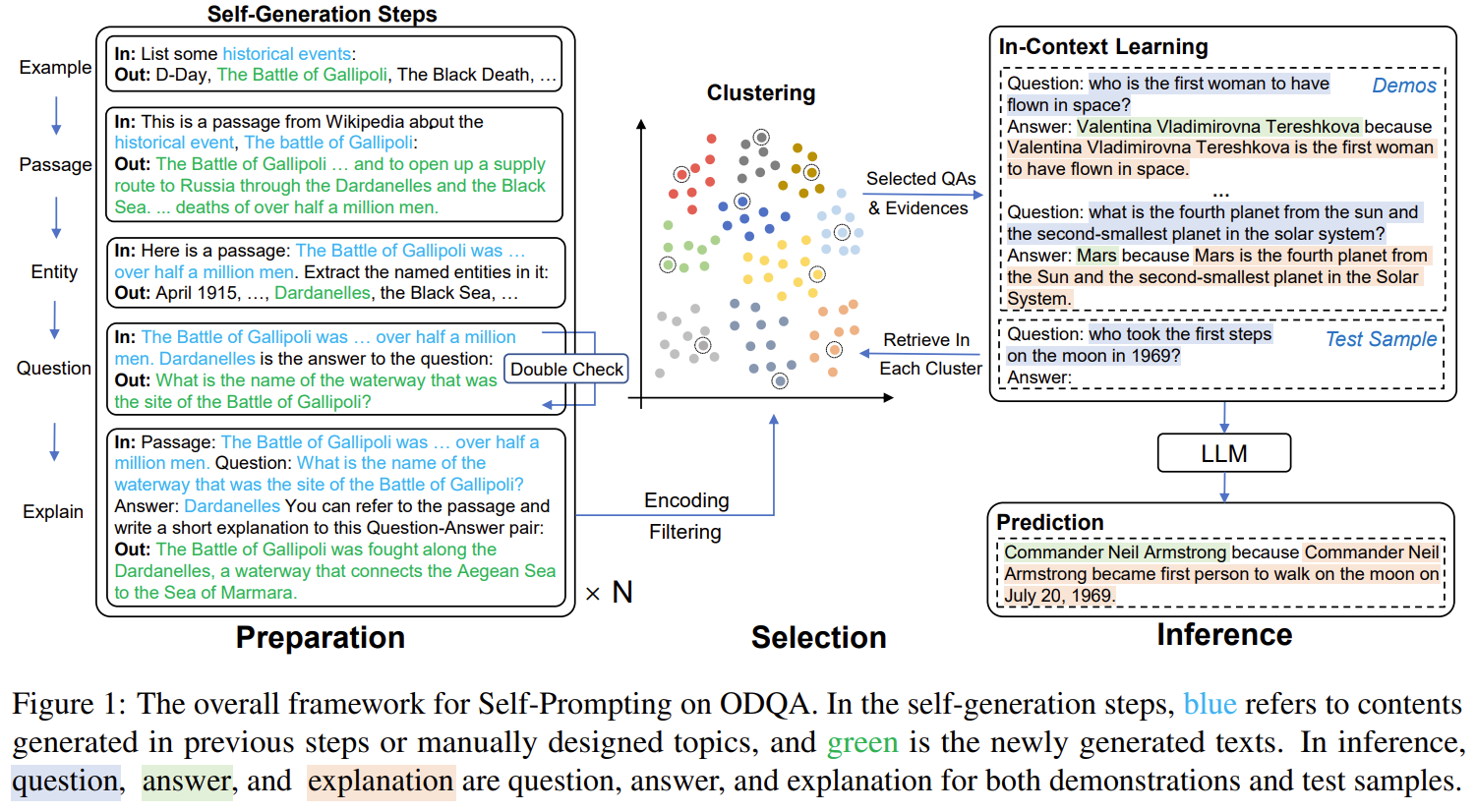
단계가 너무너무 많습니다....
LLM 호출이 너무 너무 많아져요 ㅎㅎ,.,..

Gen Read의 성능이 생각보다 별로네요...?
| 🔍 문제 상황 (Problem) | - Open-Domain QA는 질문에 대해 관련 문서 없이 답변해야 하는 과제 - Zero-shot 환경에서는 학습 데이터도 외부 지식도 없이 오직 LLM의 파라미터 지식만 활용해야 함 - 기존 Direct Prompting 방식은 성능이 낮고, LLM의 잠재력을 충분히 활용하지 못함 |
| 💡 제안 방법 (Method) | Self-Prompting 프레임워크 → LLM이 스스로 QA 데이터를 생성하고 그것을 기반으로 in-context learning 수행 ① Preparation 단계 (LLM 자체 데이터 생성): ‣ Wikipedia-style passage 생성 ‣ Named Entity 추출 → 정답 후보 ‣ 질문 생성 + 정답 확인 ‣ 한 문장 explanation 생성 ② Inference 단계 (추론): ‣ Sentence-BERT + k-means 기반 클러스터링 ‣ 각 클러스터에서 가장 유사한 QA 예시 1개씩 추출 ‣ Q→A→Explanation 포맷으로 in-context 입력 구성 |
| 🧪 주요 결과 (Results) | - Self-Prompting (InstructGPT) → 평균 EM: 46.2 - 기존 Zero-shot SOTA(GENREAD) 대비 +8.8 EM 향상 - 일부 task에서는 fine-tuned 모델(RAG, T5-SSM 11B)와 비슷하거나 더 높은 성능 - 다양한 모델(Codex, GPT-NeoX, Alpaca 등)에서 효과 확인됨 |
| 🌟 주요 기여 (Contributions) | 1. LLM 스스로 QA + 설명을 생성하여 학습 없이 고성능 QA 달성 2. Passage + Q + A + Explanation 생성 → 완전 자동 pseudo QA 데이터 구축 3. 클러스터링 기반 예시 선택으로 유사성 + 다양성 동시 확보 4. Q→A→Explanation 포맷이 가장 효과적임을 실험으로 증명 5. 실제 학습 데이터를 사용한 in-context learning과 유사한 성능 확보 |
| ⚠️ 한계 (Limitations) | - OpenAI API 사용 → 생성 비용 큼 ($120) - prompt 설계는 수작업 trial-and-error 필요 - 일부 QA 데이터에 fact 오류 또는 모호성 존재 - 실시간 예시 생성 방식은 성능 저하 + 비용 증가 발생 |