https://arxiv.org/abs/2404.05225v1
LayoutLLM: Layout Instruction Tuning with Large Language Models for Document Understanding
Recently, leveraging large language models (LLMs) or multimodal large language models (MLLMs) for document understanding has been proven very promising. However, previous works that employ LLMs/MLLMs for document understanding have not fully explored and u
arxiv.org
이 논문도 제가 하려는 것과는 살짝 거리가 있어서....
대충 보고 넘어가겠습니다.
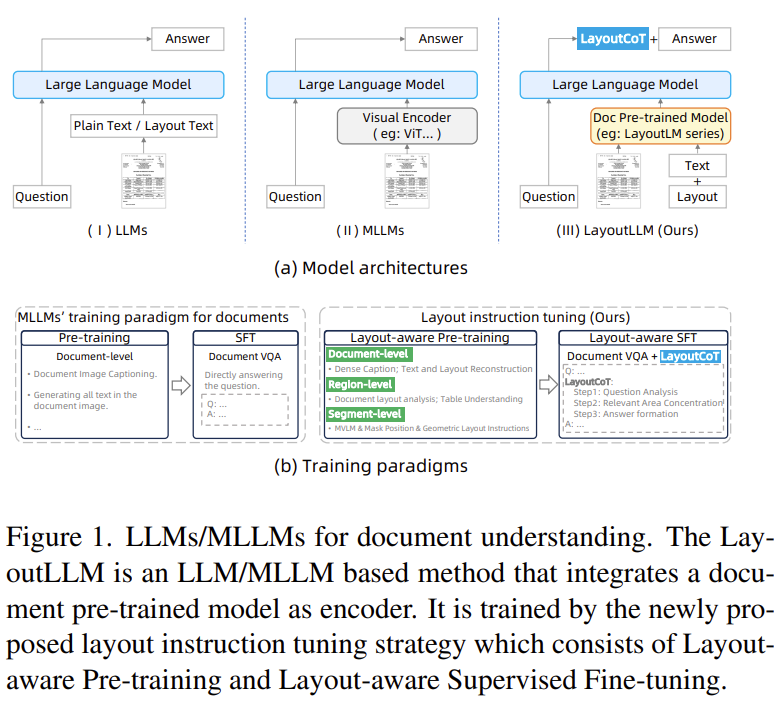
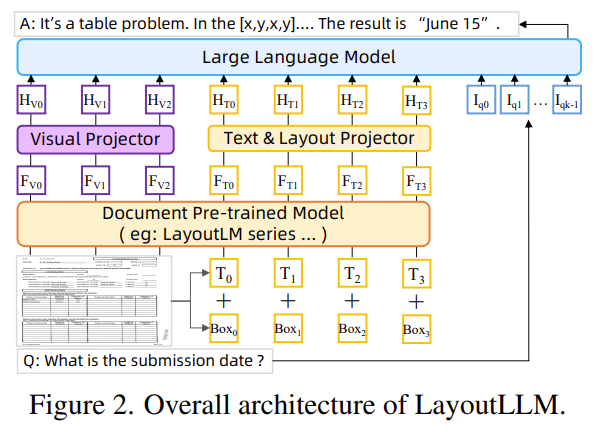


| 문제 상황 | 기존 LLM/MLLM 기반 문서 이해 모델들이 문서의 레이아웃 정보를 충분히 활용하지 못해 정확한 문서 이해에 한계가 있음. 특히 zero-shot 상황에서 성능이 낮고 해석 가능성이 떨어짐. |
| 주요 기여 | ① 문서 구조(레이아웃)를 효과적으로 학습할 수 있는 Layout Instruction Tuning 전략 제안 ② CoT에 레이아웃 정보를 포함한 LayoutCoT 생성 전략 도입 ③ Zero-shot 설정에서도 강력한 성능과 해석 가능성 제공 |
| 방법론 | 1. 모델 아키텍처 - LayoutLMv3를 encoder로 사용 - 시각/텍스트/레이아웃 정보를 LLM 입력으로 투영하기 위한 projector 2개 도입 2. Layout Instruction Tuning 전략 ① Layout-aware Pre-training - 문서 전체(Doc-level): 상세 설명 생성(DDD), 텍스트+레이아웃 복원(TLR) - 특정 영역(Region-level): 레이아웃 분석(DLA), 테이블 이해(TU) - 세그먼트(Segment-level): MVLM, Mask Position, Geometric Layout ② Layout-aware Supervised Fine-tuning - LayoutCoT: 문제 해결 과정을 세 단계로 분해 ① 질문 분석 → ② 관련 영역 집중 → ③ 정답 생성 |
| 실험 설정 | - Zero-shot 평가 - 문서 VQA (DocVQA, VisualMRC), 정보 추출 (FUNSD, CORD, SROIE) - LLM: Vicuna-7B-v1.5 / LLaMA2-7B-chat - SFT 및 Pre-training은 공개 문서 및 GPT-3.5로 생성한 레이아웃 QA 사용 |
| 결과 | - 기존 SOTA LLM/MLLM 대비 모든 태스크에서 10% 이상 우수한 성능 - DocVQA: 기존 MLLM보다 +10%, LLM보다 +7% 이상 성능 향상 - Layout-aware Pretrain만으로도 기본 성능 상승, LayoutCoT 포함 시 추가 향상 |
| 정성적 예시 | - 질문 유형 분류 → 문서 내 관련 영역 지정 → 테이블/단락 등 특성 기반 정답 생성 - 잘못된 영역을 사람이 수정해주면 답도 수정 가능: Human-in-the-loop 가능 |
| 한계점 | - “답이 없음”을 추론하거나 거절하는 기능이 부족 - 지역 간 관계 이해 부족: 레이아웃 간 논리적 추론 개선 필요 |
| 결론 | LayoutLLM은 LLM/MLLM 기반 문서 이해에서 레이아웃 정보를 효과적으로 통합하여 Zero-shot 상황에서도 우수한 성능과 해석 가능성을 동시에 달성한 모델임 |
https://arxiv.org/abs/2401.00908v1
DocLLM: A layout-aware generative language model for multimodal document understanding
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in
arxiv.org
이 논문도 Doc를 어떻게 읽어 들이냐 는 논문이라 사실 큰 연관 분야가 아니라서...
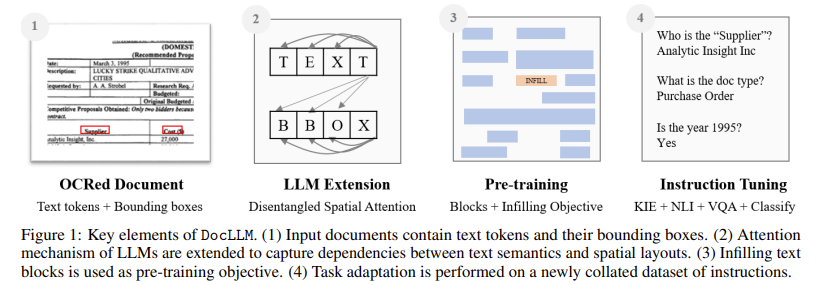
| 문제 상황 (Problem) | - 기존 LLM은 문서 레이아웃 정보 (spatial layout)를 다루지 못함 - 기존 멀티모달 모델은 복잡하고 무거운 vision encoder에 의존함 - 문서에는 비정형적이고 시각적으로 복잡한 정보가 많아 기존 모델로는 정확한 문서 이해 어려움 |
| 제안 방식 (Method) | DocLLM: LLM 기반의 경량 모델로 시각 정보 없이 텍스트 + bounding box 정보만으로 문서 레이아웃 이해 수행 |
| 세부 기법 (Architecture) | - Disentangled Spatial Attention: Text ↔ Layout 관계를 4개의 attention으로 분리 (T2T, T2S, S2T, S2S) - Block-level infilling: 자연스러운 문맥 이해를 위한 블록 단위 마스킹 복원 학습 - Causal decoder 구조 유지, 기존 LLM과 호환 가능 |
| 사전 학습 (Pretraining) | - 3.8B tokens 규모의 CDIP + DocBank 문서 데이터로 self-supervised 학습 - 문서 내 text block 단위 infilling 학습 |
| Instruction Tuning | - VQA, KIE, NLI, CLS 4개 Task에 대해 16개 데이터셋으로 fine-tuning - 다양한 template 구성으로 제로샷 generalization 능력 향상 |
| 데이터셋 (Pretrain & Fine-tune) | - Pretrain: CDIP(5M docs), DocBank(500K docs) - Instruction-tuning: 총 63만 개 train sample + 9만 개 test sample |
| 성능 결과 (Performance) | - SDDS (동일 데이터셋, 다른 split): GPT-4 제외 14/16개 데이터셋에서 SoTA - STDD (동일 task, 다른 데이터셋): 4/5개 unseen 데이터셋에서 우수한 generalization |
| 기여 (Contributions) | ① Vision encoder 없이 문서 이해 가능한 경량 구조 ② Text/Layout 분리 attention 도입 ③ 문서 문맥에 맞춘 block infilling pretraining ④ Instruction 데이터셋 구축 및 공개 ⑤ 다양한 DocAI task에서 높은 성능 달성 |
| 한계 (Limitations) | - 현재는 classification task에 약한 성능 - OCR 품질에 따라 block 구성의 품질 좌우됨 - Vision encoder를 완전히 배제한 한계도 존재 |
| 향후 연구 방향 | - 경량 Vision 모듈 추가 고려 - 다양한 OCR 및 layout parser 활용하여 block 품질 개선 예정 |
https://aclanthology.org/2024.emnlp-main.902/
Free your mouse! Command Large Language Models to Generate Code to Format Word Documents
Shihao Rao, Liang Li, Jiapeng Liu, Guan Weixin, Xiyan Gao, Bing Lim, Can Ma. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024.
aclanthology.org
emnlp 2024 main 논문이네요
이 것도 딱히...
Perplexity 서치 왜 이래 ...

| 문제 상황 (Motivation) | - MS Word 문서 포맷 작업은 반복적이며 시간 소모가 큼 - 기존 자동화 도구는 템플릿 기반으로 유연성과 범용성이 낮음 - 사용자 맞춤 포맷을 자동으로 처리할 수 있는 지능형 시스템 부재 |
| 연구 목표 | - 자연어 지시만으로 MS Word 문서를 자동 포맷팅하는 코드 생성 시스템 구축 - 다양한 포맷 지시를 처리할 수 있는 범용 LLM 기반 방법 제안 |
| 방법론 (TEXT-TO-FORMAT) | LLM 기반 자동 포맷 시스템으로, 4단계 구성: ① API 지식 검색 (RAG): Word API 문서에서 관련 정보 검색 ② 코드 생성: 지식 + 예시 + 지시문을 조합해 포맷 코드 생성 ③ 코드 실행: Word Add-in 환경에서 실행 및 결과 확인 ④ Self-Refinement: 실행 실패 시 LLM이 오류 분석 후 코드 수정 반복 |
| 데이터셋 (DOCFORMEVAL) | - 125개 원자 포맷 작업 기반, 최대 12개 조합 - GPT-4 Turbo로 자연어 다양화 + 수작업 검증 - 총 1,911개의 고품질 (지시문, 코드) 페어로 구성 |
| 실험 결과 | - 단순 Prompting: 성능 낮음 (GPT-4 Turbo: 34.41%) - Few-shot + Doc Prompting + Self-Refinement: → GPT-4 Turbo: 91.43%, DeepSeek: 91.54% - 포맷 속성 개수와 복잡도 증가 시 성능 하락 - 토큰 소모 많은 전략은 비용 이슈 있음 |
| 주요 기여 (Contributions) | ① LLM 기반 Word 포맷 코드 생성이라는 새로운 응용 분야 개척 ② 평가 전용 데이터셋 DOCFORMEVAL 구축 및 공개 ③ 다양한 프롬프트 전략, 자기수정(Self-Refine) 성능 체계적 비교 ④ 오프라인 적용 가능성을 고려한 설계 (보안/사생활 보호 강조) |
| 한계 (Limitations) | - 학습용 데이터셋 없음 (평가셋만 제공) - 이미지, 표, 레이아웃 등은 포맷 대상 아님 (텍스트 전용) - LLM들은 Word 포맷 작업에 대한 사전 지식이 부족함 - 최고의 전략은 평균 3700+ 토큰 소모로 상용화에 비용 부담 |
https://arxiv.org/abs/2401.06945
Knowledge-Centric Templatic Views of Documents
Authors seeking to communicate with broader audiences often share their ideas in various document formats, such as slide decks, newsletters, reports, and posters. Prior work on document generation has generally tackled the creation of each separate format
arxiv.org
이 논문도 별로...
| 문제 상황 | - 동일한 지식을 기반으로 하지만 문서 형식이 다른 슬라이드, 블로그, 포스터 등을 생성하는 작업이 각각 별도 과제로 다뤄짐 - 이로 인해 모델 및 평가 지표의 단편화, 중복 개발, 확장성 부족 문제가 발생 |
| 연구 목표 | - 다양한 문서 형식을 하나의 지식 기반에서 파생된 템플릿 뷰(Templatic Views)로 통합하여 생성 - 통합적인 생성 및 평가 프레임워크 개발 |
| 방법론 | 1. 중간 표현(Intermediate Representation): 입력 문서에서 핵심 정보를 추출해 JSON 구조로 구성 2. 스타일 파라미터 기반 생성: JSON + 스타일 설명(prompt) → LLM이 템플릿 문서 생성 3. 평가 프레임워크 (TAE): 품질(Q), 순서(순서 패널티), 길이(길이 패널티)를 반영한 정밀도-재현율 기반 통합 평가 시스템 |
| 실험 설정 | - 데이터셋: DOC2PPT (슬라이드), LongSumm (블로그), Paper-Poster (포스터) - 모델: GPT-3.5, GPT-4, Mixtral, Mistral-7B 등 비교 실험 - 다양한 설정 (중간 표현 있음/없음, 스타일 파라미터 적용 여부 등)으로 비교 |
| 주요 결과 | - JSON 중간 표현 사용 + 스타일 파라미터 적용이 가장 우수한 성능 - 특히 작은 모델(Mistral-7B)에서 성능 향상 효과가 큼 - 인간 평가자 82%가 중간 표현을 사용한 결과를 선호함 - 제안한 TAE 평가 방식이 인간 평가와 더 높은 상관관계를 가짐 |
| 기여 | ✅ 문서 생성의 단일화된 접근 방식 제안 (중간 표현 + 스타일 파라미터) ✅ 다양한 문서 형식 간 통합 평가가 가능한 프레임워크(TAE) 설계 ✅ 작은 모델에서도 성능을 크게 향상시킬 수 있는 실용적 전략 ✅ 인간 평가와 정합성 높은 평가 지표 설계 |
| 한계 | - 실험이 과학 문서 도메인에 한정됨 → 일반 문서로 확장 필요 - 멀티모달 콘텐츠(이미지, 그래프 등)는 고려하지 않음 - 중간 표현 구조(JSON)의 다양성 실험 부족 - 평가에 사용된 일부 문서가 LLM 학습 데이터에 포함되었을 가능성 |
https://arxiv.org/abs/2306.00526
Layout and Task Aware Instruction Prompt for Zero-shot Document Image Question Answering
Layout-aware pre-trained models has achieved significant progress on document image question answering. They introduce extra learnable modules into existing language models to capture layout information within document images from text bounding box coordin
arxiv.org
이 논문도 결국 다른 분야기에...



| 문제 상황 | - 문서 이미지 질문응답(Document Image QA)에서는 텍스트+레이아웃+시각 정보를 함께 이해해야 함 - 기존 모델(LayoutLM 등)은 OCR 좌표 기반의 레이아웃 인식 모듈을 추가해야 하며, 대규모 문서 이미지 데이터로 사전학습 필요 - 최근 떠오른 instruction-tuned LLMs(Claude, ChatGPT 등)는 zero-shot에서 강력하지만, 이들은 좌표 기반의 레이아웃 정보 처리 불가하고 재학습 불가능 (특히 상용 모델) |
| 핵심 아이디어 | - Claude, ChatGPT는 공백(Space)과 줄바꿈(Line break) 만으로도 문서의 레이아웃을 인식할 수 있음 - 따라서 좌표 없이도 layout-aware QA 가능 |
| 제안 기법 | 🔷 LATIN-Prompt → OCR 결과를 공백/줄바꿈으로 재배열하여 layout-aware 문서 생성 + Task에 맞는 명확한 Instruction 삽입 🔷 LATIN-Tuning → 소형 모델(Alpaca)이 layout 인식이 어려움 → Pandas+Claude를 이용해 레이아웃 반영된 튜닝 데이터 생성 → Alpaca 파인튜닝 |
| 방법론 요약 | LATIN-Prompt: ① OCR 텍스트 + 좌표 → 위에서 아래, 왼쪽에서 오른쪽 정렬 ② 공백 수 = 박스 간 거리 / 문자폭 ③ 행은 줄바꿈으로 연결 ④ Task-aware prompt 템플릿에 삽입하여 추론 수행 LATIN-Tuning: ① CSV 테이블 → 문서 형식 문자열 생성 (공백 + 줄바꿈 포함) ② Claude를 사용해 질문/정답 생성 ③ Instruction Prompt Template에 삽입하여 튜닝 데이터 생성 ④ Alpaca를 해당 데이터로 파인튜닝 |
| 실험 결과 | ✅ DocVQA (ANLS 기준) ‣ Claude + LATIN-Prompt: 0.2298 → 0.8336 (+60.4%) ‣ ChatGPT-3.5 + LATIN-Prompt: 0.6866 → 0.8255 (+13.9%) ‣ Alpaca + LATIN-Tuning: 0.3567 → 0.6697 (+87.7%) ✅ InfographicVQA: Claude, GPT-3.5의 zero-shot 성능이 fine-tuned 모델 대부분을 능가 ✅ MP-DocVQA: Claude + LATIN-Prompt가 Longformer, BigBird 등 fine-tuned 모델보다 우수 |
| 기여 | - 📍 최초로 공백/줄바꿈 기반의 간단한 layout 표현 방법을 통해 instruction-tuned 모델의 zero-shot QA 성능 극대화 - 📍 사전학습 없이도 SOTA 수준 도달 가능 - 📍 작은 모델의 layout 인식 능력 향상을 위한 효율적 튜닝 데이터 생성 방법 제안 - 📍 다양한 문서 QA 벤치마크에서 정량적/정성적 우수성 검증 |
| 한계 및 미래 방향 | - GPT-4와 같은 시각 정보 기반 모델과 공정한 비교 어려움 - Claude, ChatGPT 등 상용 모델 의존 - 복잡한 시각 요소가 많은 문서 (예: Infographics)에서는 여전히 시각 정보의 도움이 필요 - GPT-4 + LATIN-Prompt 실험은 API 제약으로 미실시 (향후 연구 과제) |
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| TriviaQA 논문 확인 및 평가 코드 작성 (6) | 2025.07.08 |
|---|---|
| DoGe 관련 논문 조사 6 - Synthetic QA Data, SELF-ROUTE (0) | 2025.07.08 |
| DoGe 관련 논문 조사 4 - LongRefiner, PDFTriage (4) | 2025.07.08 |
| DoGe 관련 논문 조사 3 - STRUC-BENCH, TABLELLM, LLM table Gen task Evaluation (2) | 2025.07.07 |
| Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts When Knowledge Conflicts? (2) | 2025.07.07 |