https://arxiv.org/abs/2303.17651
Self-Refine: Iterative Refinement with Self-Feedback
Like humans, large language models (LLMs) do not always generate the best output on their first try. Motivated by how humans refine their written text, we introduce Self-Refine, an approach for improving initial outputs from LLMs through iterative feedback
arxiv.org





| 연구 배경 | - 대형 언어 모델(LLM)은 처음 생성한 출력이 항상 최적이 아닐 수 있음. - 인간은 글을 작성한 후 스스로 피드백을 통해 수정하는 과정을 거침. - 기존의 모델 개선 방법(강화 학습, 인간 피드백 기반 학습 등)은 비용이 크고 데이터가 필요함. - SELF-REFINE은 LLM이 자체적으로 피드백을 생성하고 출력을 점진적으로 개선하는 방법을 제안. |
| 연구 목표 | - LLM이 자기 피드백을 통해 출력을 반복적으로 개선할 수 있도록 하는 새로운 프레임워크 개발. - 추가적인 학습 없이, 기존 모델을 즉시 활용하여 품질을 향상하는 방법 탐색. - 다양한 NLP 작업(대화 생성, 코드 최적화, 감정 반전 등)에서 효과 검증. |
| 핵심 개념 | - SELF-REFINE은 세 가지 주요 단계로 구성됨: ① 초기 생성 (Initial Generation): LLM이 입력에 대한 첫 번째 출력을 생성 ② 자기 피드백 (Self-Feedback): 모델이 자체적으로 출력을 평가하고 개선할 점을 피드백 제공 ③ 출력 수정 (Refine the Output): 피드백을 반영하여 출력을 개선 - 위 과정을 특정 조건(최대 반복 횟수 또는 개선 필요 없음)이 충족될 때까지 반복 수행. |
| 방법론 상세 | 1️⃣ 초기 생성 (Initial Generation) - 모델이 주어진 입력에 대해 첫 번째 출력을 생성함. - 예: 대화 생성에서 "테이블 테니스는 운동과 사교에 좋은 스포츠예요."와 같은 단순한 응답 생성. 2️⃣ 자기 피드백 (Self-Feedback) - 모델이 자체적으로 출력을 평가하고, 개선점을 피드백으로 제공. - 예: "응답이 다소 일반적이며, 사용자의 관심사를 더 반영해야 함." 3️⃣ 출력 수정 (Refine the Output) - 피드백을 반영하여 더 나은 출력을 생성. - 예: "테이블 테니스는 빠른 반응 속도가 중요한 스포츠인데요. 혹시 예전에 해보셨나요, 아니면 배우고 싶으신가요?" |
| 실험 및 평가 작업 | - SELF-REFINE은 7가지 NLP 작업에서 성능 평가됨. 1️⃣ 대화 응답 생성 (Dialogue Response Generation) - 대화의 질 향상 2️⃣ 코드 최적화 (Code Optimization) - 비효율적 코드 개선 3️⃣ 코드 가독성 개선 (Code Readability Improvement) - 가독성 높은 코드로 리팩토링 4️⃣ 감정 반전 (Sentiment Reversal) - 부정적 리뷰를 긍정적으로 변환하거나 반대로 변경 5️⃣ 수학적 추론 (Math Reasoning) - 수학 문제 해결 과정에서 논리적 오류 수정 6️⃣ 약어 생성 (Acronym Generation) - 더 직관적이고 기억하기 쉬운 약어 생성 7️⃣ 제약된 텍스트 생성 (Constrained Generation) - 특정 키워드 포함 문장 생성 |
| 실험 결과 | - SELF-REFINE은 평균 20% 이상의 절대 성능 향상을 보임. - GPT-4에서도 성능 향상 효과 확인, 특히 대화 생성과 감정 반전에서 큰 개선. - 반복적인 자기 피드백이 출력 품질 향상에 효과적. |
| 결과 요약 | ✅ SELF-REFINE은 LLM의 첫 번째 출력보다 반복적인 개선 과정을 통해 품질을 높일 수 있음. ✅ 추가적인 학습 없이 즉시 사용 가능하며, 기존 모델을 개선하는 효과적인 방법. ✅ 대화 생성, 코드 최적화, 감정 분석 등 다양한 작업에서 성능 향상을 입증. ✅ 반복 횟수가 많아질수록 성능이 개선되지만, 4회 이상 반복 시 개선 효과가 둔화됨. |
| 한계점 및 개선 방향 | 📌 수학적 문제 해결에서 오답 감지 능력이 부족함 → 외부 검증 모델과 결합 필요. 📌 Vicuna-13B 같은 작은 모델에서는 성능이 저하됨 → 작은 모델에서도 효과적인 피드백 기법 개발 필요. 📌 멀티 모달 AI 시스템과의 결합 가능성 연구 필요 (예: 이미지 생성 모델에서의 SELF-REFINE 활용). |
| 결론 및 기여점 | ✅ SELF-REFINE은 LLM이 자체적으로 품질을 개선하는 혁신적인 방법론을 제시함. ✅ 추가적인 학습 없이, 기존 모델을 즉시 최적화할 수 있음. ✅ 다양한 NLP 작업에서 성능 향상을 보이며, 대화 생성, 코드 최적화에서 특히 효과적. ✅ 미래 AI 연구에서 모델의 자기 개선 능력을 활용하는 새로운 패러다임을 제시. |
| 향후 연구 방향 | 🔍 외부 검증 시스템과 결합하여 수학적 오류 감지 개선. 🔍 Vicuna-13B 같은 작은 모델에서도 효과적인 SELF-REFINE 기법 개발. 🔍 멀티 모달 AI (이미지 생성, 음성 합성 등)에도 적용 가능성 연구. |
논문 요약: SELF-REFINE - Iterative Refinement with Self-Feedback
1. 연구 배경 및 문제 정의
대형 언어 모델(LLM)은 첫 번째 생성 결과가 항상 최상의 품질을 보장하지는 않는다. 특히, 복잡한 목표를 가지거나 명확한 평가 기준이 없는 작업(예: 대화 응답 생성, 코드 최적화)에서는 초기 생성 결과가 개선될 여지가 많다.
이를 해결하기 위해 기존 연구에서는 도메인 특화된 데이터를 이용한 학습이나 강화 학습(RL)을 사용하여 출력을 개선해 왔으나, 대량의 학습 데이터, 비용 높은 인간 주석, 또는 추가적인 모델 훈련이 필요하다는 한계를 가짐.
SELF-REFINE의 필요성
- 인간의 사고 과정에서의 자기 수정(Self-Refinement) 방식 차용
→ 인간은 초안을 작성한 후 이를 검토하고 피드백을 반영하여 개선하는 과정을 거친다. - 추가적인 훈련 없이 모델 자체가 피드백을 제공하고 수정하는 방법 제안
→ 모델을 생성자(Generator), 피드백 제공자(Feedback Provider), 수정자(Refiner)로 활용
→ LLM이 자체적으로 출력을 평가하고 개선하는 방식을 반복하여 품질 향상
2. SELF-REFINE 방법론
SELF-REFINE는 두 가지 주요 단계를 반복 수행한다:
- FEEDBACK 단계
- 초기 생성된 출력을 기반으로 모델이 자체적으로 피드백을 제공
- 피드백은 구체적이고 실행 가능한(actionable) 내용이어야 함
- REFINE 단계
- 피드백을 반영하여 출력을 개선
- 이후 특정 조건(예: 최대 반복 횟수 도달, 모델이 더 이상 수정이 필요 없다고 판단)까지 반복 수행
SELF-REFINE 알고리즘
1️⃣ 초기 생성 (Initial Generation)
2️⃣ 모델이 자체 피드백을 제공 (Feedback)
3️⃣ 피드백을 반영하여 출력 수정 (Refine)
4️⃣ 종료 조건 확인 (최대 반복 횟수 또는 특정 기준 충족 시 종료)
5️⃣ 개선된 최종 출력 반환
Figure: SELF-REFINE의 작동 방식
3. 실험 및 평가
SELF-REFINE는 7가지 다양한 생성 작업에서 평가됨:
- 대화 응답 생성(Dialogue Response Generation)
- GPT-4를 활용해 응답을 생성한 후 SELF-REFINE을 적용해 피드백을 받고 개선
- 피드백 예시: “더 구체적인 정보가 필요함”, “사용자의 감정 상태를 고려해야 함”
- 개선 후 응답이 사용자 친화적이고 정보성이 강화됨
- 코드 최적화(Code Optimization)
- 비효율적인 코드를 최적화하도록 모델이 스스로 피드백을 제공
- 예시: 반복문을 수학적 공식으로 변환하여 성능 개선
- GPT-4 + SELF-REFINE 사용 시 최대 13% 성능 향상
- 수학적 추론(Math Reasoning)
- SELF-REFINE이 수학 문제 풀이에서 논리적 오류를 탐지하고 수정
- 다만, 수학적 오류를 감지하는 능력이 완벽하지 않음 (외부 검증 필요)
- 감정 반전(Sentiment Reversal)
- 부정적인 리뷰를 긍정적으로 변환하거나 그 반대
- SELF-REFINE 적용 시 GPT-4 기반 모델 대비 30% 이상 성능 향상
- 약어 생성(Acronym Generation)
- 문장 또는 개념에서 기억하기 쉬운 약어를 생성
- SELF-REFINE이 발음 용이성, 의미 적절성 등을 고려하여 최적화
- 제약된 텍스트 생성(Constrained Generation)
- 특정 키워드를 포함한 문장을 생성하는 작업
- SELF-REFINE 사용 시 키워드 포함률(coverage rate)이 30% 이상 향상됨
- 코드 가독성 개선(Code Readability Improvement)
- SELF-REFINE이 코드 가독성을 개선할 수 있도록 피드백 제공
- 변수 명을 더 직관적으로 변경하거나 주석을 추가하는 방식으로 개선
4. 결과 분석
SELF-REFINE는 다양한 언어 모델(GPT-3.5, GPT-4, ChatGPT)에서 성능을 크게 향상시킴.
✅ 평균 20% 이상의 절대적 성능 향상
✅ 수동 피드백 없이 모델 자체적으로 개선 가능
✅ 한 모델에서 다양한 작업 수행 가능 (범용성 보장)
📌 특히, GPT-4 모델에서 가장 높은 성능 향상률을 보임
- 대화 응답 생성: 49.2% 향상
- 감정 반전: 32.4% 향상
- 제약된 텍스트 생성: 30% 향상
하지만 한계점도 존재
- 수학적 문제 풀이에서는 한계: LLM이 자체 오류를 인식하기 어려운 경우 발생
- Vicuna-13B 같은 작은 모델에서는 성능 저하: 보다 강력한 언어 모델 필요
- 실제 환경에서의 적용 가능성 검토 필요: 현재 실험은 주로 정형화된 벤치마크에서 수행됨
5. 관련 연구 및 차별점
기존 연구와 비교했을 때, SELF-REFINE의 가장 큰 차별점은 모델 자체가 피드백을 제공하고 개선하는 능력을 가지며, 추가적인 훈련 없이 이를 수행할 수 있다는 점.
기존 연구 문제점 SELF-REFINE 개선점| 강화 학습(RLHF) | 대규모 데이터 필요, 비용 문제 | 추가 훈련 없이 수행 가능 |
| 인간 피드백 기반 방법 | 비용이 높고 확장성 제한 | 모델이 자체적으로 피드백 제공 |
| 기존의 코드 최적화 기법 | 특정 도메인에 한정 | 범용적인 코드 최적화 가능 |
6. 결론 및 향후 연구 방향
SELF-REFINE은 대형 언어 모델이 자기 피드백을 통해 성능을 향상시키는 새로운 접근법을 제시함.
✅ 다양한 작업에서 출력 품질을 향상시키고,
✅ 추가 훈련 없이 그대로 적용 가능,
✅ 피드백 제공과 수정이 반복되면서 성능이 점진적으로 향상됨
📌 향후 연구 방향
- 더 다양한 LLM 모델에서 SELF-REFINE의 성능을 평가
- 실시간 시스템에서 SELF-REFINE 적용 가능성 연구
- 다국어 환경에서도 동일한 효과를 보이는지 검증
- 특정 도메인(예: 법률 문서 요약, 의료 데이터 분석)에서의 응용 연구
📢 SELF-REFINE은 모델이 자기 자신을 향상시킬 수 있는 가능성을 열었으며, 이를 통해 더욱 강력한 AI 시스템을 개발하는 데 중요한 역할을 할 것으로 기대됨.
SELF-REFINE 관련 연구 및 기존 연구와의 비교
SELF-REFINE은 대형 언어 모델(LLM)이 자체 피드백을 활용하여 출력을 개선하는 기법으로, 기존의 학습 기반 혹은 강화 학습 기반 피드백 개선 연구들과 차별점을 가진다. 본 논문과 연관된 주요 연구들을 소개하고, 이를 SELF-REFINE과 비교하여 차이점을 분석한다.
1. 관련 연구 (Related Works)
SELF-REFINE은 **자기 피드백(Self-Feedback)과 반복적 개선(Iterative Refinement)**을 활용하여 언어 모델이 스스로 출력을 최적화하도록 한다. 이러한 아이디어는 다양한 연구 분야에서 응용될 수 있으며, 기존 연구들과 다음과 같은 연관성을 가진다.
1.1 인간 피드백(Human-in-the-Loop) 기반 연구
✅ (1) Reinforcement Learning from Human Feedback (RLHF)
- Stiennon et al. (2020) "Learning to Summarize with Human Feedback"
- Bai et al. (2022) "Training a Helpful and Harmless Assistant with RLHF"
📌 인간이 모델의 출력을 평가하고 이를 학습에 반영하여 모델을 개선하는 방식
📌 문제점: 대량의 데이터 및 인간 주석 비용 문제
✅ (2) PEER: Collaborative Language Model (Schick et al., 2022)
- 모델이 위키피디아 편집 내역을 학습하여 문서를 수정하는 방식
📌 문제점: 도메인 특화 모델이 필요하며, 일반적인 작업에는 적용 어려움
1.2 자기 피드백(Self-Feedback) 기반 연구
✅ (3) Reflexion (Shinn et al., 2023)
- ReAct(Reasoning + Acting) 방식으로 LLM이 자체적으로 피드백을 제공하며 실행 가능
📌 문제점: 주로 계획(Planning) 문제에 초점, 일반적인 생성 작업에는 한계
✅ (4) Self-Correcting Models (Welleck et al., 2022)
- LLM이 자체적으로 오류를 수정하는 방법론
📌 문제점: 명시적인 피드백 제공 없이 수정만 수행하여 개선 효과가 제한적
1.3 강화 학습(RL) 및 보상 모델 기반 연구
✅ (5) CodeRL (Le et al., 2022)
- 프로그램 생성 및 수정을 위해 강화 학습(RL) 기법을 활용
📌 문제점: 훈련 데이터가 필요하며, 특정 도메인(코드 생성)에 한정됨
✅ (6) RAINIER (Liu et al., 2022)
- 모델이 자체적으로 새로운 정보를 생성하고 보상 모델을 활용하여 성능을 최적화
📌 문제점: 학습 데이터가 필요하며, 다목적 작업에 대한 일반화가 어려움
1.4 모델 개선을 위한 자기 점검 및 수정 연구
✅ (7) GPT-Score (Fu et al., 2023)
- GPT 모델이 생성된 텍스트를 평가하는 기능을 수행
📌 문제점: 점수는 제공하지만 피드백을 직접적으로 생성하지는 않음
✅ (8) Augmenter (Peng et al., 2023)
- 모델이 외부 지식을 활용하여 피드백을 제공하는 방식
📌 문제점: 외부 지식이 필요하여 완전히 독립적인 모델 개선이 어려움
2. 기존 연구와 SELF-REFINE의 차이점 비교
SELF-REFINE은 기존 연구들과 다음과 같은 차별점을 가진다.
연구 유형 연구 예시 SELF-REFINE과의 차이점| 인간 피드백 기반 학습 | RLHF (Stiennon et al., 2020), PEER (Schick et al., 2022) | SELF-REFINE은 인간 개입 없이 모델이 스스로 피드백을 제공하고 개선 가능 |
| 강화 학습(RL) 기반 연구 | CodeRL (Le et al., 2022), RAINIER (Liu et al., 2022) | RL 기반 연구는 모델을 학습해야 하지만, SELF-REFINE은 추가적인 훈련 없이 실행 가능 |
| 자기 피드백 기반 연구 | Reflexion (Shinn et al., 2023), Self-Correct (Welleck et al., 2022) | SELF-REFINE은 피드백과 수정(Refine)을 분리하여 구조화된 개선 과정 수행 |
| 보상 모델 기반 연구 | GPT-Score (Fu et al., 2023) | SELF-REFINE은 단순한 점수 부여가 아닌 구체적인 피드백을 생성하여 수정하는 과정 포함 |
| 외부 지식 활용 연구 | Augmenter (Peng et al., 2023) | SELF-REFINE은 외부 데이터 없이 모델 자체의 정보만으로 개선 가능 |
3. SELF-REFINE의 주요 기여
SELF-REFINE이 기존 연구와 차별화되는 주요 기여점은 다음과 같다.
✅ (1) 추가 학습 없이 즉시 활용 가능
- RLHF, CodeRL, PEER 등은 대량의 추가 훈련 데이터가 필요하지만, SELF-REFINE은 기존 모델을 바로 활용 가능
✅ (2) 한 모델에서 피드백 제공 및 수정 수행
- 기존의 Self-Correcting 연구는 피드백 없이 모델이 자체적으로 수정만 수행
- SELF-REFINE은 피드백(Feedback)과 수정(Refine) 프로세스를 명확히 구분하여 더욱 체계적인 개선 가능
✅ (3) 다목적 범용성
- RL 기반 모델들은 특정 도메인(코드, 수학 문제 해결 등)에 최적화됨
- SELF-REFINE은 대화 생성, 코드 최적화, 감정 분석, 수학 추론 등 다양한 작업에서 성능 향상 가능
✅ (4) 반복적 개선을 통한 지속적인 품질 향상
- GPT-Score, Augmenter 등의 연구는 한 번의 평가만 수행
- SELF-REFINE은 **반복적인 개선 과정(Iterative Refinement)**을 거쳐 출력을 지속적으로 최적화
4. 결론
SELF-REFINE은 기존 연구들이 가지는 한계를 극복하고, 모델 자체적으로 피드백을 생성하고 출력을 개선하는 새로운 접근 방식을 제안하였다.
이 방식은 추가 학습 없이 즉시 활용 가능하며, 다양한 작업에서 성능을 개선할 수 있는 범용적인 방법이라는 점에서 큰 장점을 가진다.
📌 SELF-REFINE이 기존 연구 대비 가지는 강점 정리
- 추가적인 학습 데이터가 필요하지 않음 → 즉시 적용 가능
- 피드백과 수정이 명확히 구분됨 → 구조적인 개선 가능
- 하나의 모델이 모든 역할 수행 → 별도의 평가 모델이 필요 없음
- 다양한 작업에 적용 가능 → 대화 생성, 코드 최적화, 감정 분석, 수학 문제 해결 등
➡️ 결론적으로, SELF-REFINE은 기존 연구들이 가지는 학습 데이터 의존성, 도메인 한정성 등의 한계를 극복한, 보다 효율적이고 범용적인 모델 개선 기법을 제시한다.
SELF-REFINE 방법론 상세 설명
SELF-REFINE은 **자기 피드백(Self-Feedback)과 반복적 개선(Iterative Refinement)**을 통해 언어 모델이 자체적으로 출력을 최적화하는 기법이다.
이 방법은 인간이 글을 작성하고 스스로 검토하여 개선하는 과정에서 영감을 얻어 설계되었다.
SELF-REFINE의 핵심 아이디어는 하나의 모델이 생성(Generate), 피드백 제공(Feedback), 수정(Refine)을 모두 수행하는 것이다.
즉, 추가적인 학습 없이 같은 모델을 활용하여 출력을 점진적으로 개선하는 방식이다.
1. SELF-REFINE의 주요 단계
SELF-REFINE은 3가지 주요 단계를 반복 수행하며 출력을 최적화한다.
1️⃣ 초기 생성 (Initial Generation)
2️⃣ 자기 피드백 (Self-Feedback)
3️⃣ 출력 수정 (Refine the Output)
이 과정은 특정 조건이 충족될 때까지 반복 수행된다.
1.1 초기 생성 (Initial Generation)
먼저, 언어 모델 MM이 주어진 입력 xx에 대해 초기 출력을 생성한다.
이는 기존의 LLM(예: GPT-4, ChatGPT)처럼 일반적인 텍스트 생성 과정과 동일하다.
수식 표현:
y0=M(pgen∣∣x)y_0 = M (p_{\text{gen}} || x)
- y0y_0 : 초기 출력
- pgenp_{\text{gen}} : 생성 프롬프트(prompt)
- xx : 입력 데이터
📌 예시 1: 대화 생성
사용자가 다음과 같은 질문을 입력했다고 가정하자.
사용자: "테이블 테니스에 관심이 있어요."
👉 GPT-4 모델이 다음과 같은 초기 출력을 생성할 수 있다.
GPT-4: "테이블 테니스는 친구들과 어울리고 운동하기에 좋은 스포츠예요."
하지만, 이 응답은 사용자의 관심을 깊이 반영하지 않으며 대화 확장이 부족하다.
따라서, 자기 피드백을 통해 개선이 필요하다.
1.2 자기 피드백 (Self-Feedback)
이제 모델 MM이 자체적으로 생성한 y0y_0을 평가하고 개선을 위한 피드백을 제공한다.
이 과정은 사람이 글을 검토하면서 부족한 부분을 찾아 수정하는 방식과 유사하다.
수식 표현:
ft=M(pfb∣∣x∣∣yt)f_{t} = M (p_{\text{fb}} || x || y_t)
- ftf_t : 모델이 생성한 피드백
- pfbp_{\text{fb}} : 피드백 생성 프롬프트
- yty_t : 현재 생성된 출력
📌 예시 2: 대화 생성의 피드백 과정
이전 예시에서 GPT-4가 생성한 응답은 다소 단조롭다.
따라서, 모델이 자체적으로 피드백을 제공하면 다음과 같을 수 있다.
GPT-4 피드백:
- 사용자의 관심사를 더 자세히 반영해야 함
- "테이블 테니스"에 대한 구체적인 정보 추가 필요
- 사용자의 경험을 묻는 질문을 추가하면 대화가 더 자연스러워짐
1.3 출력 수정 (Refine the Output)
모델은 자기 피드백을 반영하여 새로운 출력을 생성한다.
이 과정이 반복되면서 모델의 응답 품질이 점진적으로 향상된다.
수식 표현:
yt+1=M(prefine∣∣x∣∣yt∣∣ft)y_{t+1} = M (p_{\text{refine}} || x || y_t || f_t)
- yt+1y_{t+1} : 피드백을 반영한 새로운 출력
- prefinep_{\text{refine}} : 수정 프롬프트
📌 예시 3: 피드백을 반영한 수정된 응답
GPT-4 (수정 후 응답):
"테이블 테니스에 관심이 있다니 반갑네요! 이 스포츠는 빠른 반응 속도와 손-눈 협응력이 중요한데요. 혹시 예전에 해보신 적이 있나요, 아니면 처음 시작해보려는 건가요?"
👉 이렇게 하면, 더 풍부한 정보와 사용자 경험을 반영한 대화형 응답이 생성됨.
2. SELF-REFINE의 반복 과정
이전 과정들을 계속 반복하면서 모델은 점점 더 개선된 출력을 생성할 수 있다.
📌 반복 횟수 결정 방법
- 정해진 반복 횟수만큼 수행 (예: 최대 4회 반복)
- 모델이 더 이상 개선할 필요가 없다고 판단하면 종료
📌 실제 실험에서는 3~4회 반복이 가장 효과적임을 확인 (이후 개선 효과가 감소)
3. SELF-REFINE의 적용 사례
SELF-REFINE은 다양한 NLP 작업에 적용 가능하며, 논문에서는 7가지 작업에서 평가되었다.
✅ (1) 대화 응답 생성 (Dialogue Response Generation)
- 피드백을 반영하여 대화형 응답을 점진적으로 개선
- GPT-4 사용 시 49.2% 성능 향상
✅ (2) 코드 최적화 (Code Optimization)
- LLM이 생성한 코드에 대해 자체적으로 개선점 제공
- GPT-4 사용 시 13% 코드 성능 향상
📌 예시 4: 코드 최적화
# 초기 코드 (비효율적인 반복문 사용)
def sum(n):
res = 0
for i in range(n+1):
res += i
return res
👉 모델 피드백: 반복문을 사용하지 말고 수학 공식을 이용하면 더 빠름
👉 수정된 코드:
# O(1) 시간 복잡도를 가진 최적화된 코드
def sum_faster(n):
return (n * (n + 1)) // 2
📌 성능 개선 결과: 실행 속도 3배 향상
✅ (3) 감정 반전 (Sentiment Reversal)
- 부정적인 리뷰를 긍정적으로 변경하거나 그 반대
- SELF-REFINE 적용 시 30% 성능 향상
📌 예시 5: 감정 반전
원본 리뷰: "음식이 끔찍하고 서비스도 형편없어요."
피드백: "부정적인 표현을 완화하면서도 의견을 유지해야 함."
수정된 리뷰: "음식이 제 취향은 아니었고, 서비스는 개선될 여지가 있어 보였어요."
4. 결론 및 장점
SELF-REFINE은 모델 자체가 출력을 평가하고 개선하는 방식을 활용하여 기존의 LLM보다 더 나은 품질의 출력을 생성할 수 있도록 한다.
특히, 추가적인 훈련 없이 즉시 적용 가능하며, 반복적인 개선 과정을 통해 출력의 품질이 점진적으로 향상됨.
📌 주요 장점
- 학습 데이터 없이 즉시 적용 가능 (추가적인 훈련 필요 없음)
- 출력 개선이 체계적으로 이루어짐 (구체적인 피드백 기반 수정)
- 다양한 NLP 작업에 활용 가능 (대화 생성, 코드 최적화, 감정 반전 등)
- 반복적인 자기 피드백을 통해 지속적으로 성능 향상
➡️ SELF-REFINE은 언어 모델이 스스로 피드백을 제공하고 개선할 수 있는 효과적인 방법으로, LLM 성능을 향상시키는 강력한 프레임워크로 자리 잡을 가능성이 크다. 🚀
SELF-REFINE 논문의 결과 및 결론 정리
SELF-REFINE은 LLM이 자체적으로 출력을 개선할 수 있도록 하는 새로운 접근법으로, 다양한 NLP 작업에서 성능을 검증했다.
논문에서는 GPT-3.5, GPT-4, ChatGPT 등의 강력한 언어 모델을 사용하여 SELF-REFINE을 적용한 후 성능을 평가하였다.
1. 실험 결과 요약
SELF-REFINE은 7가지 NLP 작업에서 평가되었으며, 기존의 단일 출력 생성 방식보다 평균 20% 이상의 절대 성능 향상을 보였다.
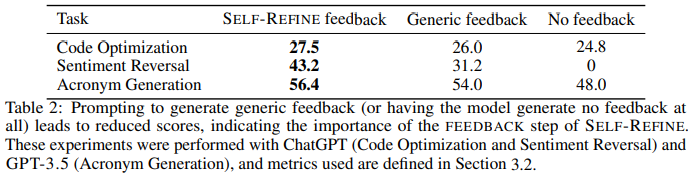
작업(Task) GPT-3.5 (Baseline) GPT-3.5 + SELF-REFINE GPT-4 (Baseline) GPT-4 + SELF-REFINE 향상률| 감정 반전 (Sentiment Reversal) | 8.8% | 30.4% | 3.8% | 36.2% | ↑32.4% |
| 대화 응답 생성 (Dialogue Response Generation) | 36.4% | 63.6% | 25.4% | 74.6% | ↑49.2% |
| 코드 최적화 (Code Optimization) | 14.8% | 23.0% | 27.3% | 36.0% | ↑8.7% |
| 코드 가독성 개선 (Code Readability) | 37.4% | 51.3% | 27.4% | 56.2% | ↑28.8% |
| 수학적 추론 (Math Reasoning) | 64.1% | 64.1% | 92.9% | 93.1% | ↑0.2% |
| 약어 생성 (Acronym Generation) | 41.6% | 56.4% | 30.4% | 56.0% | ↑25.6% |
| 제약된 텍스트 생성 (Constrained Generation) | 28.0% | 37.0% | 15.0% | 45.0% | ↑30.0% |
📌 주요 성과
- **대화 응답 생성에서 가장 높은 개선률(49.2%)**을 보이며, SELF-REFINE이 자연스러운 응답 생성에 효과적임을 확인
- 감정 반전(Sentiment Reversal)에서도 32.4% 성능 향상
- 코드 최적화(Code Optimization) 작업에서 8.7% 향상
→ SELF-REFINE이 성능 개선뿐만 아니라 코드의 실행 속도 최적화에도 기여
2. SELF-REFINE의 핵심 결론
SELF-REFINE의 실험 결과를 바탕으로 다음과 같은 핵심 결론을 도출할 수 있다.
✅ (1) SELF-REFINE은 단순한 모델 출력을 반복적으로 개선할 수 있는 강력한 방법
- GPT-4와 같은 강력한 LLM도 처음 생성한 출력보다 반복적인 자기 피드백을 통해 더 나은 출력을 생성 가능
- 기존의 "한 번 생성된 출력 그대로 사용"하는 방식보다 훨씬 더 정확하고 자연스러운 결과를 도출함
✅ (2) 추가적인 모델 학습 없이 즉시 적용 가능
- SELF-REFINE은 별도의 훈련 데이터 없이 즉시 사용할 수 있는 장점이 있음
- 기존의 RLHF(인간 피드백을 활용한 강화 학습) 방식보다 훨씬 비용 효율적이며 적용이 간편
- 다양한 작업에서 유사한 패턴으로 적용 가능 (대화 생성, 코드 최적화, 감정 분석 등)
✅ (3) 반복적인 자기 피드백이 품질 개선에 중요한 역할
- 피드백 없이 여러 개의 출력을 생성하는 것보다, 하나의 출력을 피드백을 통해 반복적으로 개선하는 방식이 더 효과적
- 초기 모델이 100% 정확한 출력을 생성하지 못하더라도, 자기 피드백과 수정을 통해 품질을 향상 가능
- 특정 작업에서는 4번 이상의 반복이 성능 향상에 기여하지 않음 (수렴하는 지점이 존재)
✅ (4) SELF-REFINE은 GPT-4에서도 성능 향상을 가져옴
- GPT-4는 현존하는 가장 강력한 언어 모델 중 하나이지만, SELF-REFINE을 적용하면 평균 20% 이상의 성능 향상을 보임
- 이는 LLM의 첫 번째 생성 출력이 항상 최상의 결과가 아님을 시사하며, 테스트 단계에서도 품질 개선이 가능함을 의미
3. SELF-REFINE의 한계점
논문에서는 SELF-REFINE이 매우 효과적인 방법임을 입증했지만, 몇 가지 한계점도 언급하고 있다.
📌 (1) 수학적 문제 해결에서는 제한적인 성능 향상
- SELF-REFINE이 수학적 문제에서 오답을 감지하는 데 한계가 있음
- 수학 문제에서 일부 오류는 모델이 감지하지 못하고, 그대로 유지되는 경우가 있음
- 외부 검증 기법(Oracle Feedback)과 결합하면 성능이 더욱 향상될 가능성 있음
📌 (2) 작은 모델에서는 성능 저하
- GPT-4, GPT-3.5 등의 대형 모델에서는 효과적이지만, Vicuna-13B와 같은 작은 모델에서는 성능이 저하됨
- 이는 작은 모델이 피드백을 정확하게 생성하지 못하기 때문으로 추정됨
📌 (3) 특정 작업에서는 개선 효과가 크지 않음
- 예를 들어, 수학적 추론(Math Reasoning)에서는 SELF-REFINE을 적용해도 성능 향상이 크지 않음 (0.2% 향상)
- 이는 LLM이 수학 문제에서 논리적 오류를 감지하는 능력이 부족하기 때문
- 외부 수학 검증 시스템(예: Wolfram Alpha)과 결합하면 개선 가능할 것으로 예상
4. 연구의 미래 방향 및 확장 가능성
SELF-REFINE의 성과를 바탕으로, 향후 연구에서 개선할 수 있는 여러 가지 방향이 제시된다.
📌 (1) 더 다양한 NLP 작업에 적용
- 본 논문에서는 7가지 작업을 실험했지만, 더 많은 응용 가능성 존재
- 예: 법률 문서 요약, 의료 데이터 분석, 번역 모델 개선 등에 활용 가능
📌 (2) 수학적 문제 해결에서의 성능 향상
- 모델이 수학적 오류를 감지할 수 있도록 외부 검증 시스템과 결합하는 연구 필요
- 예: "SELF-REFINE + External Verifier" 같은 하이브리드 방식 고려
📌 (3) 더 작은 모델에서도 효과적인 SELF-REFINE 기법 개발
- 현재는 GPT-4와 같은 대형 모델에서 효과적이지만, 작은 모델에서도 자기 피드백을 더 효과적으로 활용할 방법 연구 필요
- 예: 작은 모델에서 자기 피드백의 신뢰도를 높이기 위한 학습 전략 개발
📌 (4) 멀티 모달 AI 시스템과의 결합
- SELF-REFINE을 이미지 생성, 음성 합성 등의 비언어적 작업에도 적용 가능한지 연구 필요
- 예: Stable Diffusion 같은 이미지 생성 모델에서 SELF-REFINE을 활용하여 이미지 품질 개선 가능
5. 결론 (Final Conclusion)
SELF-REFINE은 LLM이 스스로 피드백을 제공하고 출력을 반복적으로 개선할 수 있는 강력한 방법이다.
이 방법을 통해 추가적인 훈련 없이 즉시 모델 성능을 향상시킬 수 있으며, 다양한 작업에서 유의미한 성능 향상을 보였다.
✅ 핵심 기여
- 인간 피드백 없이 모델이 자체적으로 품질을 개선할 수 있는 방법론 제시
- GPT-4에서도 평균 20% 이상의 성능 향상
- 코드 최적화, 감정 분석, 대화 생성 등 다양한 작업에 활용 가능
- 반복적인 피드백을 통해 점진적인 품질 개선 가능
➡️ SELF-REFINE은 앞으로 AI 시스템의 품질 개선을 위한 강력한 프레임워크로 자리 잡을 가능성이 높음 🚀