https://aclanthology.org/2025.coling-main.504/
DORA: Dynamic Optimization Prompt for Continuous Reflection of LLM-based Agent
Kun Li, Tingzhang Zhao, Wei Zhou, Songlin Hu. Proceedings of the 31st International Conference on Computational Linguistics. 2025.
aclanthology.org
기존 Reflcetion은 성능을 올리긴 했지만 iteration이 증가할 수록 성능 향상이 더뎌졌다.

위 그래프에서 보듯 Early Stop Reflection문제가 발생하였고, DORA(Dynamic and Optimized Reflerction Advice)를 제안한다.
Closed model에서 Gradient Descent를 이용한 학습은 불가능하고, 하더라도 비용이 매우 많이 들기에 비효율 적이므로 Gradient-Free Optimization 방법이 필요하다.

Prompter - Open source Language Model로 Reflection Prompt를 동적으로 만드는 DORA의 KEY이다.
Reflector - history를 분석하고, 새로운 Reflection Suggestion을 만들며, Agent의 Decision을 가이드해준다.
Soft prompt는 Reward를 통해 지속적으로 학습을 진행한다.

DORA가 기존 Reflection이나 CoT 모듈들을 이기는 것을 볼 수 있다.
DORA에서 Prompter는 ~8B 모델들이 사용되었고, Reflector는 GPT 3.5 Turbo가 사용되었다.
여기서 반복 횟수는 모두 40회로 동등하게 진행되었다.
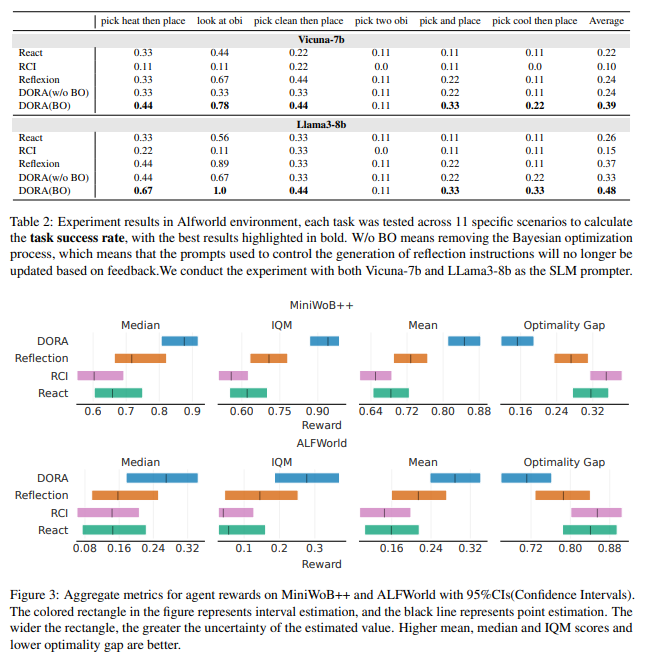
BO의 성능 향상에 일조하는 것을 확인할 수 있고, DORA로 인해 성공률이 특정 작업은 1까지 올라가는 것을 볼 수 있다.
Reward를 비교해봐도 가장 높고, 최적 값과의 차이도 가장 적은 것을 볼 수 있다.

기존 Reflection은 초반 Iteration에서 효과가 있었지만 DORA는 반복이 진행될 수록 성능이 지속적으로 향상된다.
Soft Prompt가 초기에는 랜덤이라 성능이 낮지만 반복 학습을 통해 점차 최적화된다.
학습을 진행할 수록 Reflection과는 다르게 일반적인 지침에서 Task에 맞도록 적합한 조언으로 변화되고, 다양성을 보상 요소로 포함해 동일한 조언이 반복되지 않도록 설계된다.

Soft Prompt의 차원 수에 따라 성공률도 많이 변화하고, 차원이 너무 커지면 학습하는데 시간이 오래 걸려 최적화 속도가 느려지고, 너무 작으면 충분한 정보를 담지 못해 성능이 저하된다.
| 📌 연구 배경 | 기존 LLM 기반 반영(Reflection) 프레임워크는 학습 초기에만 효과적이며, 반복 이후 성능 향상이 멈추는 문제(Early Stop Reflection)가 발생함. 기존 방법은 고정된(static) 반영 프롬프트를 사용하여 개선이 제한됨. |
| 📌 연구 목표 | 반영 프롬프트를 동적으로 최적화하여 지속적인 성능 개선이 가능하게 만드는 새로운 반영 프레임워크(DORA) 제안. |
| 📌 핵심 기여 | ✅ "Early Stop Reflection" 문제 해결 → 동적 프롬프트 최적화를 통해 지속적 학습 가능 ✅ 베이지안 최적화(Bayesian Optimization) 적용 → 최적의 반영 프롬프트를 자동 탐색 ✅ LLM 에이전트의 자기 개선(Self-Improvement) 능력 향상 |
| 📌 기존 연구와의 차이점 | - Reflexion (2023): 정적인 반영 프롬프트 사용 → 학습 정체 문제 발생 - RCI (2023): 개별적인 단계 평가로 인해 전체 행동 궤적 반영 부족 - 기존 프롬프트 최적화 연구(RLPrompt, EvoPrompting 등): 특정 태스크에만 최적화됨 → 범용성이 부족 - DORA는 기존 연구들과 달리, 반영 프롬프트를 동적으로 최적화하여 지속적인 개선이 가능하며, 다양한 태스크에 범용적으로 적용 가능함. |
| 📌 방법론 개요 | 1️⃣ SLM(Small Language Model)을 활용한 동적 반영 프롬프트 생성 → 기존 정적인 프롬프트 대신, Llama3-8B 등 소형 모델을 사용하여 상황에 맞는 반영 프롬프트를 실시간 생성 2️⃣ LLM이 반영 조언 생성 → 생성된 반영 프롬프트를 기반으로 LLM이 새로운 반영 조언 제공 3️⃣ 에이전트 실행 및 피드백 수집 → 반영 조언을 반영한 후, 에이전트 성능(성공률, 조언의 다양성 등)을 평가하여 피드백 수집 4️⃣ 베이지안 최적화를 통해 반영 프롬프트 지속 개선 → 성능이 높은 반영 프롬프트를 점진적으로 학습하여 최적화 |
| 📌 베이지안 최적화 (BO) 적용 방식 | ✅ 가우시안 프로세스(Gaussian Process, GP) 기반 확률 모델을 사용하여 반영 프롬프트와 성능 간 관계 학습 ✅ Expected Improvement (EI) 탐색 전략을 사용하여 가장 높은 성능 개선 가능성이 있는 프롬프트 선택 ✅ 두 가지 보상 함수 적용 - (1) 성능 보상 R_{performance}: 에이전트 성공률 기반 - (2) 다양성 보상 R_{diversity}: 이전 반영 조언과의 차이를 코사인 유사도(Cosine Similarity)로 측정하여 반복성 방지 ✅ 반영 프롬프트를 지속적으로 조정하며 최적의 조합을 찾도록 최적화 수행 |
| 📌 실험 환경 | MiniWoB++ (웹 기반 에이전트 환경) - 클릭, 폴더 탐색, UI 조작 등 다양한 작업 포함 Alfworld (텍스트 기반 에이전트 환경) - 객체 조작, 다중 단계 작업 수행 필요 |
| 📌 실험 결과 | ✅ MiniWoB++ 환경에서 평균 19% 성능 향상 (기존 Reflexion 대비) ✅ Alfworld 환경에서 평균 9~11% 성능 향상 ✅ BO를 적용하지 않은 DORA(w/o BO)와 비교했을 때, BO 적용 시 더욱 균형 잡힌 학습과 지속적인 성능 개선 확인 ✅ 기존 Reflexion이 초기 몇 번만 효과적인 반면, DORA는 일정한 주기로 지속적인 학습 효과 유지 |
| 📌 추가 분석 | 📌 "Early Stop Reflection" 문제 해결 여부 - 기존 Reflexion은 반영이 몇 번 반복되면 개선이 멈췄으나, DORA는 균일한 성공률 분포를 보이며 지속적 학습 가능 📌 복잡한 작업에서도 효과적 - MiniWoB++에서 난이도가 높은 n-screen-n-steps 작업에서 가장 큰 성능 향상 📌 "독성 반영(Toxic Reflection)" 문제 일부 해결 - 잘못된 반영으로 인해 성능이 저하되는 경우를 줄였으나, 완전히 해결되지는 않음 |
| 📌 결론 | ✅ DORA는 기존 반영 프레임워크의 한계를 극복하는 혁신적인 방법론 ✅ 동적 반영 프롬프트 최적화를 통해 지속적인 학습을 가능하게 함 ✅ 베이지안 최적화를 활용하여 최적의 반영 프롬프트를 자동으로 탐색 ✅ 다양한 환경에서도 범용적으로 적용 가능 |
| 📌 향후 연구 방향 | 📌 Toxic Reflection 문제 해결 - 반영 조언이 오히려 성능을 저하시키는 경우를 최소화하는 추가적인 평가 기법 필요 📌 베이지안 최적화 기법의 개선 - 강화학습(RL) 기반 반영 최적화 기법 적용 가능성 탐색 📌 다중 에이전트 시스템 적용 - 현재는 단일 LLM 기반 반영 프레임워크이므로, 다중 에이전트(Multi-Agent) 시스템에서도 동작하는지 연구 필요 |
| 📌 연구의 응용 가능성 | ✔ LLM 기반 자동 연구 에이전트(Auto-Research Agents) 개발 ✔ Mixture of Experts (MoE) 모델에서 반영 최적화 적용 ✔ NLP 및 Reinforcement Learning 모델의 지속적 학습 최적화 ✔ 범용 AI 시스템의 지속적 개선을 위한 메타학습 기법 적용 가능 |
개요
- 기존 LLM 에이전트의 반영(Reflection) 기법에서 발생하는 "Early Stop Reflection" 문제를 해결하려는 연구.
- 정적인 반영 프롬프트를 사용하던 기존 Reflexion 프레임워크와 달리, 동적으로 최적화된 반영 프롬프트를 생성하는 DORA(Dynamic and Optimized Reflection Advice) 제안.
- 작은 언어 모델(SLM)을 활용하여 반영 프롬프트를 생성하고, 베이지안 최적화(Bayesian Optimization, BO)를 적용해 지속적으로 최적화.
- MiniWoB++ 및 Alfworld 환경에서 실험을 수행하여, 기존 Reflexion 대비 반영 성능 19%~11% 향상을 확인.
장점
1️⃣ "Early Stop Reflection" 문제 해결
- 기존 Reflexion 방식은 반복 학습 초기에는 효과적이지만, 이후에는 개선이 정체됨.
- DORA는 반영 프롬프트를 지속적으로 최적화하여 학습이 멈추지 않도록 설계됨.
2️⃣ 베이지안 최적화를 통한 반영 프롬프트 개선
- 미분 불가능한 LLM 최적화 문제에서 Gradient-Free 방식의 최적화 적용.
- Gaussian Process(GP) + Expected Improvement(EI) 탐색 전략을 사용해 효율적인 프롬프트 탐색 수행.
3️⃣ 범용적인 반영 프레임워크
- 특정 태스크에 최적화된 방법이 아니라, 다양한 환경에서 범용적으로 적용 가능한 반영 프레임워크를 설계.
- MiniWoB++(UI 조작, 검색), Alfworld(다단계 액션 수행) 같은 다양한 태스크에서 효과 입증.
4️⃣ 기존 Reflexion 대비 높은 성능 및 지속적 개선 가능
- Reflexion 대비 MiniWoB++에서 19%, Alfworld에서 11% 성능 향상.
- BO 없이 DORA(w/o BO)와 비교했을 때, BO를 적용한 DORA(BO)가 더 높은 성능과 안정적인 학습 유지.
5️⃣ 반영 조언(Reflection Advice)의 다양성 유지
- 단순한 반복 피드백이 아니라, 다양성을 고려한 반영 조언 생성.
- 이전 반영 조언과의 차이를 코사인 유사도(Cosine Similarity) 기반으로 평가하여 중복 방지.
단점
1️⃣ Task Decomposition 및 Scheduling의 한계
- 반영 자체를 최적화하는 데 초점을 맞췄지만, 태스크를 자동으로 분해하는 기법은 부족.
- LLM 기반 에이전트의 복잡한 플래닝(Planning) 작업에는 여전히 취약.
2️⃣ SLM이 실패하면 반영 전체가 실패하는 구조
- SLM(Small Language Model)이 적절한 반영 프롬프트를 생성하지 못하면, 잘못된 프롬프트가 LLM으로 전달되어 지속적인 오류 발생 가능.
- Reflexion 방식과 비교할 때, 오류가 누적될 가능성이 있음.
3️⃣ 온디바이스(On-Device) 환경에서의 실용성 제한
- ‘온디바이스 적용 가능성’을 강조했지만, 실제로는 백본 모델로 7B급 SLM 사용 → 실질적인 온디바이스 활용성은 제한적.
- 진정한 온디바이스 적용을 위해서는 경량화된 모델이 필요함.
4️⃣ Toxic Reflection 문제 해결이 불완전
- 일부 반영 조언이 오히려 성능 저하를 초래하는 Toxic Reflection 현상이 완전히 해결되지 않음.
- Toxic Reflection을 줄이려면 추가적인 평가 기법(예: LLM Self-Evaluation)이 필요.
결론
- DORA는 기존 Reflexion 기반 반영 프레임워크의 한계를 극복하고, 반영 프롬프트를 동적으로 최적화하는 기법을 제안.
- 베이지안 최적화를 통해 반영 프롬프트의 지속적인 개선을 유도, 기존 방식 대비 높은 성능을 보임.
- 그러나 SLM의 성능 한계 및 반영 실패 시 오류 누적 문제가 존재하며, Task Scheduling 및 Decomposition 기법과의 결합이 필요.
- 향후 연구에서는 Toxic Reflection 문제 해결, 경량화 모델 적용, 다중 에이전트(Multi-Agent) 시스템에서의 확장 가능성 탐색이 중요할 것으로 보임. 🚀
1. 연구의 배경 및 문제 정의
대형 언어 모델(LLM) 기반 자율 에이전트는 다양한 분야에서 활용될 수 있지만, 기존의 Reflection 프레임워크에는 심각한 한계가 존재한다.
- 기존 연구들은 반영(reflection)이 에이전트의 성능을 향상시킨다고 밝혔지만, "Early Stop Reflection" 문제를 확인하였다.
- 이는 반영이 주로 초기 반복(iteration)에서만 의미 있는 학습 효과를 보이며, 이후에는 개선되지 않는 현상이다.
- 이러한 문제는 고정된(static) 반영 프롬프트를 사용하기 때문이며, 이로 인해 이후의 반영이 반복적이고 비효율적으로 변한다.
2. DORA: 동적 최적화 반영 프롬프트 방법론
DORA (Dynamic and Optimized Reflection Advice)는 기존의 정적인 프롬프트 대신 작업에 적응하고 동적으로 변화하는 반영 프롬프트를 생성하는 방법을 제안한다.
- 핵심 아이디어:
- 작은 오픈소스 언어 모델(SLM)을 사용하여 동적으로 반영 프롬프트를 생성한다.
- 이 SLM은 비미분(non-gradient) 베이지안 최적화(Bayesian Optimization, BO) 기법을 활용해 지속적으로 프롬프트를 조정한다.
- 반영 LLM의 출력을 단순히 수동 설정된 프롬프트에 의존하지 않고, 실제 에이전트의 성능을 기준으로 동적으로 변화시킨다.
DORA의 반영 과정
- SLM이 동적 프롬프트를 생성 → 에이전트가 수행한 작업과 피드백을 바탕으로 최적의 반영 프롬프트를 만듦.
- LLM이 반영 조언(reflection advice)을 생성 → 반영 프롬프트를 기반으로 에이전트가 다음에 더 나은 결정을 내릴 수 있도록 조언함.
- 반영 조언을 바탕으로 에이전트가 행동 수행 → 조언을 활용해 새로운 작업을 시도.
- 베이지안 최적화를 통한 프롬프트 개선 → 수행된 작업의 성과를 기반으로 반영 프롬프트를 점진적으로 최적화.
3. 실험 및 성능 평가
DORA의 성능을 평가하기 위해 MiniWoB++ 및 Alfworld 환경에서 실험을 수행하였다.
실험 환경
- MiniWoB++: 웹 기반 시뮬레이션 환경으로, 간단한 클릭 작업부터 복잡한 추론이 필요한 작업까지 포함.
- Alfworld: 텍스트 기반 상호작용 환경으로, 여러 단계의 행동이 필요한 복잡한 작업 수행 가능.
비교 모델
- ReAct (Zero-shot CoT 기반 행동 결정)
- RCI (단일 단계 평가 기반 개선)
- Reflexion (기본적인 반영 메커니즘 적용)
- DORA (w/o BO) → 베이지안 최적화 없이 DORA 실행
- DORA (BO) → 베이지안 최적화를 적용한 DORA
실험 결과
- MiniWoB++ 환경에서 평균 성공률 증가
- DORA(BO)는 기존 Reflexion보다 평균 19% 성능 향상.
- 특정 작업에서는 100% 성공률을 기록.
- Alfworld 환경에서 성능 향상
- Reflexion 대비 평균 9~11% 개선.
- 복잡한 작업에서도 지속적인 성능 향상 유지.
- 베이지안 최적화가 성능에 미치는 영향
- BO를 적용하지 않은 DORA(w/o BO)는 일부 작업에서 개선이 제한됨.
- BO 적용 후 더욱 균형 잡힌 학습 및 지속적인 성능 개선 확인.
- 에이전트 보상(Aggregate Metrics) 분석
- MiniWoB++ 및 Alfworld 환경에서 DORA가 다른 방법들보다 더 높은 평균 보상과 낮은 옵티멀리티 갭(optimality gap)을 보임.
- IQM(Interquartile Mean)과 중앙값(Median)이 더 높은 값으로 유지됨.
4. 추가 분석
(1) "Early Stop Reflection" 문제 해결 여부
- 기존 Reflexion 방법은 주로 초기 반복에서만 성능이 향상되었지만, DORA는 일정한 주기로 지속적인 학습 효과를 보임.
- DORA 적용 후 성공적인 반영이 더 균일한 분포를 보임.
(2) 복잡한 작업에서의 성능 향상
- MiniWoB++에서 작업 난이도를 세 가지로 분류 (1-screen-1-step, 1-screen-n-steps, n-screen-n-steps).
- DORA는 모든 난이도에서 향상되었으며, 특히 가장 어려운 n-screen-n-steps 작업에서 가장 큰 개선 효과를 보임.
(3) "독성 반영(Toxic Reflection)" 현상 분석
- 일부 반영이 오히려 성능 저하를 초래하는 경우가 존재 (Toxic Reflection).
- DORA는 실패한 반영을 효과적인 반영으로 전환하는 데 기여했으나, 완전히 해결하지는 못함.
(4) 반영 프롬프트 및 조언의 특징
- 초기에는 일반적인 반영 조언을 제공했으나, 점점 구체적인 해결책을 제시하는 방향으로 진화.
- 최적화 과정에서 다양성을 목표로 설정하여 중복된 반영 감소.
(5) 베이지안 최적화에서 소프트 프롬프트 차원 수의 영향
- 너무 높은 차원은 최적화 어려움을 증가시키고, 너무 낮은 차원은 중요한 정보 손실 발생.
- 적절한 차원을 설정해야 최적의 성능 발휘 가능.
(6) 하이퍼파라미터 영향 분석
- 반영 다양성과 성능 향상 간의 균형을 조정하는 α 값이 0.5일 때 가장 좋은 결과를 보임.
5. 결론 및 향후 연구 방향
결론
- DORA는 기존 Reflexion 방법의 한계를 극복하여 "Early Stop Reflection" 문제를 해결하는 효과적인 방법론을 제시.
- 동적으로 최적화된 프롬프트를 활용하여 지속적인 성능 개선을 가능하게 함.
- MiniWoB++ 및 Alfworld 환경에서 실험적으로 검증되었으며, 모든 난이도에서 성공률 향상.
향후 연구 방향
- 더 다양한 환경에서 테스트 필요 (현재 MiniWoB++ 및 Alfworld에서만 검증됨).
- Toxic Reflection 문제 해결 (일부 반영이 부정적 영향을 미치는 현상).
- 베이지안 최적화 기법의 개선 (불필요한 반영을 최소화하는 방향).
6. 연구 활용 가능성
- AI 에이전트의 지속적 학습 및 적응성 향상
- 자율 연구 에이전트(Auto-Research Agents) 개발 시 반영 기법 적용 가능
- NLP 기반 Fine-tuning 및 Reinforcement Learning 모델에 적용 가능
💡 연구 방향과의 연관성
✔ LLM 기반 자동 연구 시스템에서 자율적 학습 메커니즘 구현 가능
✔ Mixture of Experts (MoE) 모델에서 반영 최적화 적용 가능
✔ AI 모델의 지속적 개선을 위한 메타학습 기법으로 활용 가능
DORA의 최적화 기법을 NLP 및 Multi-Agent 시스템에 적용하는 것도 좋은 연구 주제가 될 수 있을 것! 🚀
DORA 관련 연구 및 기존 연구와의 차이점 분석
DORA가 해결하려는 "Early Stop Reflection" 문제와 관련된 연구는 크게 두 가지 연구 분야에서 논의된다.
- LLM 에이전트의 반영(Reflection) 기법 연구
- 프롬프트 최적화(Prompt Optimization) 연구
이를 기반으로 DORA가 기존 연구에서 어떻게 발전했는지 체계적으로 분석하겠다.
1. LLM 기반 에이전트의 반영(Reflection) 연구
(1) ReAct (Yao et al., 2023a)
- 개념: LLM이 환경과 상호작용하며 Chain-of-Thought(CoT) 기반 추론을 수행하는 방식.
- 한계점:
- 자기 반영(reflection)이 없음 → 반복되는 오류를 수정할 수 없음.
- 환경 변화에 적응하지 못하는 단순한 상호작용 기반 프레임워크.
🔺 DORA와의 차이점:
- ReAct는 단순한 추론 기반 모델이며, 반영 기법이 없음.
- DORA는 과거 수행 결과를 지속적으로 반영하여 자율적 성능 개선 가능.
(2) Reflexion (Shinn et al., 2023)
- 개념: LLM 기반 에이전트가 과거 행동을 기록하고 피드백을 반영하여 자기 개선(Self-improvement)을 수행하는 방식.
- 한계점:
- 고정된(static) 프롬프트를 사용하므로 초기에는 반영이 잘되지만, 이후에는 학습 효과가 둔화됨 (Early Stop Reflection 문제 발생).
- 에이전트가 동일한 유형의 반영을 반복하여 학습이 정체됨.
🔺 DORA와의 차이점:
- Reflexion은 정적인 반영 프롬프트를 사용하지만, DORA는 동적으로 최적화된 프롬프트를 사용하여 지속적인 학습을 가능하게 함.
- Reflexion은 반영이 몇 번 반복되면 성능 개선이 멈추는 경향이 있으나, DORA는 베이지안 최적화를 적용하여 지속적인 성능 향상을 유도.
(3) RCI (Kim et al., 2023)
- 개념: 에이전트가 수행한 작업에 대해 단계별(Sequential) 평가를 수행하는 방식.
- 한계점:
- 매 스텝마다 개별적인 평가를 수행하므로 전체적인 반영 과정이 부족.
- 잘못된 평가가 적용될 경우 성능이 저하됨 (실제로 MiniWoB++ 환경에서 Reflexion보다 낮은 성능 기록).
🔺 DORA와의 차이점:
- RCI는 개별 단계(step)에서 피드백을 주지만, DORA는 전체 행동 궤적(trajectory)을 반영하여 더 효과적인 개선이 가능.
- RCI는 반영 조언이 최적화되지 않음, 반면 DORA는 베이지안 최적화를 적용한 최적 프롬프트를 생성.
2. 프롬프트 최적화(Prompt Optimization) 연구
(1) RLPrompt (Deng et al., 2022)
- 개념: 강화학습(RL)을 이용하여 프롬프트를 최적화하는 방법.
- 한계점:
- LLM이 닫혀 있는 경우(Closed-source) RL 기반 최적화가 어렵다.
- 학습이 불안정하여 일반적인 환경에서 적용하기 힘들다.
🔺 DORA와의 차이점:
- DORA는 비미분 기반 최적화(Non-gradient Bayesian Optimization, BO)를 사용하여 모든 LLM에 적용 가능.
- RLPrompt는 특정 태스크에서만 효과적인 반면, DORA는 일반적인 반영 프레임워크로 사용 가능.
(2) EvoPrompting (Chen et al., 2023a)
- 개념: 진화 알고리즘(Evolutionary Algorithm, EA)을 활용한 프롬프트 최적화.
- 한계점:
- 진화 알고리즘을 이용한 최적화는 연산량이 크고 시간이 오래 걸림.
- 특정 환경에서는 진화가 수렴되지 않을 수 있음.
🔺 DORA와의 차이점:
- EvoPrompting은 랜덤 변이(Random Mutation)를 기반으로 한 탐색을 수행하지만, DORA는 베이지안 최적화를 사용하여 더 효율적인 탐색 가능.
- EvoPrompting은 수렴이 불안정하지만, DORA는 에이전트 성능을 기반으로 프롬프트를 점진적으로 최적화하여 안정적인 개선을 유도.
(3) InstructZero (Chen et al., 2023c)
- 개념: 프롬프트를 직접 생성하여 최적화하는 방법.
- 한계점:
- 프롬프트 최적화가 특정한 태스크(task)에 고정적으로 적용됨.
- 범용적인 반영 프레임워크로 사용하기 어려움.
🔺 DORA와의 차이점:
- InstructZero는 특정 작업에 대해 맞춤형 프롬프트를 최적화하는 반면, DORA는 범용적인 반영 프레임워크로 확장 가능.
- DORA는 베이지안 최적화를 사용하여 다양한 환경에서 반영 프롬프트를 최적화할 수 있음.
3. 기존 연구 대비 DORA의 발전점 요약
| 기존 연구 | 문제점 | DORA의 개선 |
| ReAct (2023) | 반영 없음, 단순 상호작용 기반 | 반영 프레임워크를 추가하여 지속적인 개선 가능 |
| Reflexion (2023) | 정적인 프롬프트 사용 → Early Stop Reflection 문제 발생 | 동적으로 최적화된 반영 프롬프트 사용, 지속적 성능 향상 가능 |
| RCI (2023) | 개별 스텝 평가로 인해 전반적 반영 부족 | 전체 궤적 기반 반영, 더 효과적인 성능 개선 |
| RLPrompt (2022) | RL 기반 프롬프트 최적화, 닫힌 모델에서 적용 어려움 | 베이지안 최적화 사용, 모든 LLM에 적용 가능 |
| EvoPrompting (2023) | 진화 알고리즘의 높은 연산 비용 | 베이지안 최적화로 효율적인 탐색 |
| InstructZero (2023) | 특정 작업(task) 중심 최적화 | 범용적인 반영 프레임워크로 활용 가능 |
4. 결론: DORA의 기여점
- "Early Stop Reflection" 문제를 해결 → 기존 Reflexion 모델의 학습 정체 문제를 개선.
- 동적 최적화된 반영 프롬프트 사용 → 기존 고정된 반영 프롬프트 방식보다 지속적인 성능 개선 가능.
- 베이지안 최적화(Bayesian Optimization) 적용 → 연산량이 많거나 불안정한 기존 최적화 기법보다 효율적.
- 모든 LLM 및 다양한 환경에 적용 가능 → 특정 태스크에 한정되지 않고 범용적인 반영 프레임워크로 활용 가능.
💡 연구 적용 가능성
DORA는 단순한 반영 프레임워크가 아니라, 자동 연구 에이전트(Auto-Research Agents), Mixture of Experts (MoE), NLP 기반 지속적 학습 모델 등 다양한 분야에 응용 가능하다.
특히 LLM의 자율 학습 및 개선을 연구하는 경우, DORA의 동적 반영 기법을 적용하면 큰 도움이 될 것이다! 🚀
DORA: 동적 최적화 반영 프롬프트 방법론
1. 개요: 왜 DORA가 필요한가?
기존 LLM 기반 에이전트의 자기 개선(Self-Improvement) 기법인 Reflection은 특정 문제를 해결할 때 이전 경험을 바탕으로 더 나은 해결책을 찾기 위한 반영(Reflection) 과정을 포함한다. 하지만, 이 방법에는 근본적인 한계가 있다.
"Early Stop Reflection" 문제
- 기존 연구에서는 반영 기법을 적용하면 초기 몇 번의 반복(iteration)에서 성능이 향상되지만, 이후에는 개선이 멈춘다.
- 이는 반영 프롬프트가 고정적(static)이며 반복적인 조언을 생성하기 때문.
- 예를 들어, "파일을 클릭하는 작업"을 수행하는 AI가 있다면:
- 처음에는 "파일을 클릭해야 한다"는 올바른 피드백을 반영하여 성공률이 향상됨.
- 이후 같은 조언을 계속 반복하다 보니, 추가적인 학습이 일어나지 않고 개선이 정체됨.
DORA의 목표
- 반영 프롬프트를 동적으로 최적화하여 지속적인 성능 개선을 가능하게 만듦.
- 기존의 정적인 반영 프롬프트 대신, 작업에 맞춰 변화하는 반영 프롬프트를 생성.
- 이를 위해 오픈소스 작은 언어 모델(SLM)과 베이지안 최적화(BO)를 활용하여 반영 프로세스를 자동으로 조정.
2. DORA 방법론 상세 분석
DORA는 크게 4단계 과정을 통해 기존 반영 프레임워크를 개선한다.
1️⃣ 단계: 동적 반영 프롬프트 생성 (SLM 기반)
- 기존 방법(예: Reflexion)은 고정된 프롬프트를 사용하여 반복적인 반영을 수행했지만, DORA는 반영 프롬프트를 자동으로 조정한다.
- 이를 위해, 작은 오픈소스 언어 모델(SLM, 예: Llama3-8B)을 이용해 반영 프롬프트를 생성.
- 예를 들어, AI가 파일을 찾는 작업을 수행한다고 가정하면:
- 기존 방법: "파일을 찾으세요."
- DORA의 SLM 기반 방법: "이전 작업에서 'Alan' 폴더를 클릭하는 것이 효과적이었으니, 이번에는 그 내부에서 'Agustina' 파일을 찾아보세요."
✔ 핵심 차별점:
- 단순한 조언이 아니라, 이전 수행 결과를 반영하여 적절한 조언을 자동 생성.
2️⃣ 단계: 반영 조언 생성 (LLM 기반)
- SLM이 생성한 새로운 반영 프롬프트를 기반으로, LLM이 반영 조언을 생성.
- 기존 방법은 고정된 프롬프트로 인해 반복적인 조언만 생성하지만, DORA는 매 반복마다 새로운 조언을 제공.
- 예를 들어, "클릭해야 하는 파일을 찾는 AI"가 있다고 하면:
- 기존 Reflexion: "폴더를 클릭하세요."
- DORA: "파일명이 'Report'로 시작하는 파일을 먼저 탐색하고, 없다면 하위 폴더를 확인하세요."
✔ 핵심 차별점:
- 기존 Reflexion은 반복적인 피드백을 제공하지만, DORA는 상황에 맞게 조언을 조정.
3️⃣ 단계: 에이전트 실행 및 피드백 수집
- 반영 조언을 받은 에이전트가 해당 조언을 바탕으로 행동을 수행.
- 이후, 성공률, 작업 성공 여부, 조언의 다양성 등을 평가하여 프롬프트를 조정하는 피드백 데이터를 수집.
✔ 핵심 차별점:
- 기존 방법은 고정된 평가 방식을 사용했지만, DORA는 반영의 효과를 직접 평가하여 다음 프롬프트에 반영.
4️⃣ 단계: 베이지안 최적화를 통한 반영 프롬프트 개선
- 비미분(non-gradient) 최적화 기법인 베이지안 최적화(BO)를 사용하여 반영 프롬프트를 점진적으로 개선.
- 왜 베이지안 최적화인가?
- LLM 기반 반영은 블랙박스 문제(Gradient 계산이 불가능) → 기존 딥러닝 방식으로 최적화 어려움.
- BO는 수집된 데이터(에이전트 성능 및 조언 다양성)를 기반으로 최적 프롬프트를 탐색하여 점진적으로 개선.
✔ 핵심 차별점:
- 기존 Reflexion은 반영 프롬프트를 개선하는 메커니즘이 없었음.
- DORA는 베이지안 최적화를 통해 프롬프트를 지속적으로 개선하여 학습이 멈추지 않도록 함.
3. 예시를 통한 이해: 파일 찾기 작업
기존 Reflexion 방식
초기 학습 단계
- AI: 파일을 찾아야 함.
- Reflexion: "파일을 찾으세요."
- AI: 특정 폴더를 열어봄 → 실패.
중기 학습 단계
- Reflexion: "폴더를 열어야 합니다."
- AI: 다시 폴더를 열어봄 → 실패.
- Reflexion: 계속 같은 조언을 반복 (성능 개선 없음).
DORA 방식
초기 학습 단계
- AI: 파일을 찾아야 함.
- DORA의 SLM: "이전 작업에서 'Alan' 폴더를 열었지만, 그 안에서 'Agustina' 파일을 찾지 못했음. 이번에는 검색 기능을 활용해보세요."
- AI: 검색 기능 사용 → 성공률 증가.
중기 학습 단계
- DORA의 SLM: "이전 작업에서 검색 기능을 활용했지만, 하위 폴더까지는 탐색하지 않았음. 이번에는 특정 키워드('Report')를 추가하여 검색 범위를 넓혀보세요."
- AI: 개선된 전략을 사용하여 성공률 향상.
✔ 핵심 차별점:
- 기존 Reflexion은 반복적인 피드백으로 인해 학습이 멈추지만,
- DORA는 동적으로 프롬프트를 최적화하여 지속적인 학습을 유도.
4. DORA의 주요 기여점 정리
| 기존 방법 | 문제점 | DORA의 개선 |
| Reflexion | 정적인 반영 프롬프트 사용 → 학습 정체 | 동적 최적화 프롬프트 사용 |
| ReAct | 반영 없음, 단순한 행동 기반 AI | 반영 프레임워크 추가 |
| RCI | 개별적인 단계 평가 → 전체 궤적 반영 부족 | 전체 행동 궤적을 반영하여 최적화 |
| 기존 프롬프트 최적화 기법 | 특정 태스크 중심 최적화 | 다양한 환경에서 범용 적용 가능 |
| 진화 알고리즘 기반 최적화 | 연산 비용이 크고 불안정 | 베이지안 최적화를 활용해 효율적 탐색 |
5. 결론 및 향후 연구 방향
DORA는 기존의 Reflection 기반 방법론에서 발생하는 "Early Stop Reflection" 문제를 해결하기 위해 개발되었다.
✔ 동적 반영 프롬프트 최적화를 통해 지속적인 성능 개선이 가능하며,
✔ 베이지안 최적화를 적용하여 효율적인 반영 프롬프트 탐색이 가능하다.
향후 연구 방향
- 베이지안 최적화 외에 다른 최적화 기법(예: 강화학습 기반 프롬프트 최적화) 적용 가능성 탐색.
- 반영 과정에서 발생하는 Toxic Reflection 문제 해결.
🚀 연구 적용 가능성
✔ LLM 기반 자동 연구 에이전트(Auto-Research Agents) 개발
✔ Mixture of Experts (MoE) 모델에서 반영 최적화 적용
✔ NLP 및 Reinforcement Learning 모델의 지속적 학습 최적화
DORA의 최적화 기법을 다양한 AI 시스템에 적용할 수 있을 것이다! 🚀
DORA 연구의 결과
1. 연구 결과 (Experimental Results)
DORA는 기존 Reflexion 기반 반영 프레임워크가 가진 "Early Stop Reflection" 문제를 해결하기 위해 개발되었다. 연구에서는 DORA의 성능을 MiniWoB++ 및 Alfworld 환경에서 실험을 통해 평가했다.
📌 실험 환경
- MiniWoB++: 웹 기반 시뮬레이션 환경으로, 간단한 클릭 작업부터 복잡한 추론이 필요한 작업까지 포함.
- Alfworld: 텍스트 기반 상호작용 환경으로, 여러 단계의 행동이 필요한 복잡한 작업 수행 가능.
📌 비교 모델
- ReAct – Zero-shot CoT 기반 행동 결정.
- RCI – 단일 단계 평가 기반 개선.
- Reflexion – 기본적인 반영 메커니즘 적용.
- DORA(w/o BO) – 베이지안 최적화 없이 DORA 실행.
- DORA(BO) – 베이지안 최적화를 적용한 DORA.
📌 주요 성과
1️⃣ MiniWoB++ 환경에서의 성능 향상
- 기존 Reflexion 대비 평균 19% 성공률 증가.
- 일부 작업에서는 100% 성공률을 기록하며, 기존 방식보다 더 빠르게 최적의 전략을 찾음.
2️⃣ Alfworld 환경에서의 성능 향상
- Reflexion 대비 평균 9~11% 개선.
- 복잡한 작업에서도 DORA가 더 높은 성공률을 유지.
3️⃣ 베이지안 최적화가 성능에 미치는 영향
- BO를 적용하지 않은 DORA(w/o BO)는 일부 작업에서 개선이 제한됨.
- BO 적용 후 더욱 균형 잡힌 학습 및 지속적인 성능 개선 확인.
4️⃣ 에이전트 보상(Aggregate Metrics) 분석
- MiniWoB++ 및 Alfworld 환경에서 DORA가 다른 방법들보다 더 높은 평균 보상과 낮은 옵티멀리티 갭(optimality gap)을 기록.
- IQM(Interquartile Mean)과 중앙값(Median)이 더 높은 값으로 유지됨.
5️⃣ "Early Stop Reflection" 문제 해결 여부
- 기존 Reflexion 방법은 초기 반복에서만 성능이 향상되었지만, DORA는 일정한 주기로 지속적인 학습 효과를 보임.
- DORA 적용 후 성공적인 반영이 더 균일한 분포를 보이며, 학습이 멈추지 않음.
6️⃣ 복잡한 작업에서의 성능 향상
- MiniWoB++에서 작업 난이도를 세 가지로 분류 (1-screen-1-step, 1-screen-n-steps, n-screen-n-steps).
- DORA는 모든 난이도에서 향상되었으며, 특히 가장 어려운 n-screen-n-steps 작업에서 가장 큰 개선 효과를 보임.
7️⃣ "독성 반영(Toxic Reflection)" 현상 분석
- 일부 반영이 오히려 성능 저하를 초래하는 경우가 존재 (Toxic Reflection).
- DORA는 실패한 반영을 효과적인 반영으로 전환하는 데 기여했으나, 완전히 해결하지는 못함.
2. 연구 결론 (Conclusion)
🔹 연구의 핵심 기여
- "Early Stop Reflection" 문제를 해결
- 기존 Reflexion 프레임워크는 초기 몇 번의 반복(iteration) 후 성능이 정체되지만,
- DORA는 동적 반영 프롬프트와 베이지안 최적화(Bayesian Optimization)를 적용하여 지속적인 학습이 가능하도록 함.
- 동적 최적화된 반영 프롬프트 사용
- 기존 정적인 반영 프롬프트 방식보다 작업에 맞춰 변화하는 반영 프롬프트를 생성하여 개선 효과 증가.
- 베이지안 최적화(Bayesian Optimization) 적용
- 기존의 미분 기반 최적화가 불가능한 상황에서 비미분(non-gradient) 최적화 기법을 사용하여 반영 프로세스를 자동으로 조정.
- 모든 LLM 및 다양한 환경에 적용 가능
- 특정 태스크에 한정되지 않고 범용적인 반영 프레임워크로 활용 가능하여 확장성이 뛰어남.
🔹 DORA의 주요 성과 요약
| 기존 방법 | 문제점 | DORA의 개선 |
| Reflexion | 정적인 반영 프롬프트 사용 → 학습 정체 | 동적 최적화 프롬프트 사용 |
| ReAct | 반영 없음, 단순한 행동 기반 AI | 반영 프레임워크 추가 |
| RCI | 개별적인 단계 평가 → 전체 궤적 반영 부족 | 전체 행동 궤적을 반영하여 최적화 |
| 기존 프롬프트 최적화 기법 | 특정 태스크 중심 최적화 | 다양한 환경에서 범용 적용 가능 |
| 진화 알고리즘 기반 최적화 | 연산 비용이 크고 불안정 | 베이지안 최적화를 활용해 효율적 탐색 |
3. 마무리 및 향후 연구 방향
🛠 향후 연구 방향
- 더 다양한 환경에서 테스트 필요
- 현재 MiniWoB++ 및 Alfworld에서만 검증되었음.
- 더 복잡한 실제 환경에서 테스트하여 일반화 가능성을 확인해야 함.
- Toxic Reflection 문제 해결
- 일부 반영이 부정적 영향을 미치는 현상이 여전히 존재함.
- 반영 품질을 평가하는 새로운 메커니즘 도입 필요.
- 베이지안 최적화 기법의 개선
- BO는 탐색 과정에서 랜덤 요소가 포함되므로, 더 정교한 최적화 기법 적용 가능성 탐색 필요.
- 예: 강화학습 기반 반영 최적화(RL-Based Prompt Optimization) 적용 연구.
- 다중 에이전트 시스템에서의 적용 연구
- 현재 연구는 단일 LLM 기반 반영 프레임워크를 대상으로 했음.
- 다중 에이전트(Multi-Agent) 시스템에서도 적용 가능성을 확인해야 함.
🚀 연구 적용 가능성
✔ LLM 기반 자동 연구 에이전트(Auto-Research Agents) 개발
✔ Mixture of Experts (MoE) 모델에서 반영 최적화 적용
✔ NLP 및 Reinforcement Learning 모델의 지속적 학습 최적화
✔ 범용 AI 시스템의 지속적 개선을 위한 메타학습 기법 적용 가능
DORA의 최적화 기법을 다양한 AI 시스템에 적용하면 LLM의 지속적 개선과 자기 학습(Self-Learning)을 최적화하는 데 큰 도움이 될 것이다! 🚀
베이지안 최적화 (Bayesian Optimization, BO) 상세 분석
DORA에서 사용한 베이지안 최적화(Bayesian Optimization, BO)는 반영 프롬프트를 지속적으로 개선하는 핵심 기법이다. BO는 일반적인 최적화 알고리즘과는 다른 방식으로 동작하며, 비미분(non-gradient) 최적화를 수행하는 데 적합하다.
1. 왜 베이지안 최적화를 사용하는가?
일반적인 최적화 문제는 보통 미분을 이용한 방법(예: Gradient Descent)으로 해결된다. 하지만, DORA에서는 다음과 같은 이유로 기존의 미분 기반 최적화가 불가능하다.
📌 LLM 반영 프롬프트 최적화의 문제점
- LLM의 출력이 블랙박스(Black-box)이다.
- LLM은 내부적으로 복잡한 뉴럴 네트워크를 사용하며, 프롬프트가 어떻게 출력을 결정하는지 명확한 수학적 모델을 만들기 어렵다.
- 즉, 프롬프트 최적화를 위해 기울기(Gradient)를 직접 계산할 수 없다.
- 반영 피드백이 연속적인 값이 아니라 불연속적인 값이다.
- 반영 조언이 유효한지 판단하는 기준(예: 에이전트의 성공률, 조언의 다양성 등)은 연속적인 함수가 아니라 이산적인(binary 또는 step-wise) 평가 값을 갖는다.
- 최적의 반영 프롬프트를 직접 찾는 것이 어렵다.
- 어떤 프롬프트가 가장 좋은 반영 조언을 만들어낼지 미리 알기 어렵고, 이를 단순한 탐색(Search)으로 해결하려면 계산 비용이 매우 크다.
📌 베이지안 최적화의 장점
- BO는 블랙박스 함수에서도 효과적으로 최적의 솔루션을 탐색할 수 있다.
- 최적화 과정에서 이전 탐색 결과를 활용하여 더 적은 시도(trial)로 최적의 솔루션에 도달 가능.
- Gradient-Free 방식으로 미분이 불가능한 문제에서도 사용할 수 있음.
2. 베이지안 최적화 개념 및 원리
BO는 확률 모델(Probabilistic Model)과 탐색 전략(Acquisition Function)을 조합하여 최적의 해를 탐색하는 기법이다.
BO의 기본 흐름은 다음과 같다.
📌 베이지안 최적화의 핵심 과정
- 확률 모델(Surrogate Model) 구축
- 현재까지 수집한 데이터(반영 프롬프트와 그에 따른 성능)를 기반으로 확률적 모델(보통 Gaussian Process, GP)을 만든다.
- 이 모델은 우리가 모르는 목적 함수(Objective Function)를 근사하는 역할을 한다.
- 탐색 전략(Acquisition Function) 적용
- 현재까지의 정보를 바탕으로 다음에 어디를 탐색할지 결정한다.
- 일반적으로 Expected Improvement (EI), Upper Confidence Bound (UCB), Probability of Improvement (PI) 같은 기법을 사용한다.
- 새로운 반영 프롬프트 실험 및 업데이트
- 선택된 새로운 반영 프롬프트를 적용하여 LLM이 반영 조언을 생성하고, 그 결과(성공률 등)를 평가한다.
- 이 결과를 확률 모델에 반영하여 다음 탐색을 더욱 정교하게 수행한다.
- 반복 수행 (Convergence 될 때까지)
- 위 과정을 반복하여 최적의 반영 프롬프트를 찾는다.
3. DORA에서 베이지안 최적화 적용 방법
DORA는 베이지안 최적화를 이용해 반영 프롬프트를 지속적으로 개선한다. 이를 위해 4단계로 진행된다.
📌 (1) 확률 모델 (Gaussian Process, GP) 초기화
- 처음에는 랜덤으로 10개의 소프트 프롬프트(Soft Prompt) 벡터를 생성하고, 각 프롬프트에 대한 반영 성능을 측정하여 초기 데이터셋을 만든다.
- 가우시안 프로세스(GP)를 사용하여 현재까지의 데이터를 바탕으로 반영 프롬프트와 성능 간의 관계를 학습한다.
🎯 가우시안 프로세스(GP) 수식
가우시안 프로세스(GP)는 주어진 데이터 포인트들의 분포를 추정하는 모델이다.
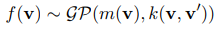
- m(v): 평균 함수 (보통 0으로 설정)
- k(v, v'): 공분산 함수 (Matérn 커널 사용)
GP는 현재까지의 데이터를 기반으로 미래의 프롬프트 성능을 예측하는 역할을 한다.
📌 (2) 탐색 전략 (Acquisition Function) 선택
- Expected Improvement (EI) 방식을 사용하여 새로운 프롬프트 벡터 v_{next}를 선택한다.

- 여기서 f(v^+)는 현재까지의 최상의 성능을 나타낸다.
- 즉, 가장 큰 개선 가능성이 있는 프롬프트를 우선 탐색.
📌 (3) 새로운 반영 프롬프트 평가
- BO가 선택한 새로운 프롬프트 v_{next}를 이용하여 LLM이 반영 조언을 생성.
- 생성된 조언을 적용하여 에이전트가 행동을 수행하고 성공률, 조언 다양성 등을 평가.
✔ DORA는 반영 성능 평가를 위해 두 가지 보상을 활용한다.
- 성능 보상 (R_{performance})
- 반영 조언이 적용된 후, 에이전트의 성공률을 측정하여 보상 값으로 사용.
- 다양성 보상 (R_{diversity})
- 새로운 반영 조언이 이전과 얼마나 다른지 코사인 유사도(Cosine Similarity)를 기반으로 평가.
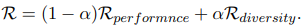
- 여기서 α는 성능과 다양성의 중요도를 조절하는 하이퍼파라미터.
📌 (4) 최적화 반복 및 수렴
- 위 과정을 여러 번 반복하면서 점점 더 최적의 반영 프롬프트를 찾아감.
- 초기에는 랜덤한 탐색을 수행하지만, 점점 성능이 높은 프롬프트를 중심으로 탐색이 집중됨.
- 탐색이 수렴하면 최적의 반영 프롬프트를 획득.
4. 베이지안 최적화가 DORA에 미친 영향
- "Early Stop Reflection" 문제 해결
- 기존 Reflexion 프레임워크는 정적인 프롬프트로 인해 일정 반복 이후 학습이 멈췄지만,
- DORA는 BO를 사용해 지속적으로 최적의 반영 프롬프트를 찾아 학습이 멈추지 않도록 함.
- 불필요한 탐색을 줄이고 효율적으로 최적화
- 랜덤 탐색보다 빠르고 적은 시도로 최적의 반영 프롬프트를 찾음.
- 반영 프롬프트의 다양성 유지
- BO가 탐색 과정에서 다양한 반영 조언을 생성하도록 유도하여, 같은 조언이 반복되는 문제를 방지.
5. 결론: 베이지안 최적화가 DORA에 가져온 혁신
✔ LLM의 반영 성능을 최적화하는 효과적인 방법
✔ 미분을 사용할 수 없는 블랙박스 최적화 문제 해결
✔ 반복적이고 정체되는 반영 문제(Early Stop Reflection) 해결
✔ 다양한 환경에서도 최적의 반영 조언을 자동으로 탐색 가능
DORA는 베이지안 최적화를 통해 LLM 반영 프레임워크의 한계를 극복하고, 더 지속적인 성능 향상을 가능하게 한 혁신적인 접근 방식이다. 🚀
Soft Prompt란?
Soft Prompt는 프롬프트 최적화를 수행하는 기법 중 하나로, 기존의 텍스트 기반 프롬프트와 달리 학습 가능한 벡터(임베딩)로 표현되는 프롬프트를 의미한다.
즉, LLM을 사용할 때 사람이 직접 작성하는 텍스트 프롬프트 대신 뉴럴 네트워크가 학습하여 최적의 프롬프트를 자동으로 생성하는 방식이다.
📌 1. Soft Prompt의 개념
일반적인 LLM 프롬프트 입력 방식과 Soft Prompt의 차이를 정리하면 다음과 같다.
| 구분 | 기존 텍스트 Prompt | Soft Prompt |
| 정의 | 사람이 직접 작성한 텍스트 기반 프롬프트 | 벡터 형태의 학습 가능한 프롬프트 |
| 입력 방식 | "Summarize this text: ..." 같은 문자열 입력 | LLM의 입력 임베딩 공간에 특정 벡터 삽입 |
| 학습 가능 여부 | 사람이 수동으로 작성해야 함 (학습 불가능) | 모델이 자동으로 학습 가능 |
| 적용 방식 | 일반적인 Zero-shot, Few-shot Prompting | Prompt Tuning, Fine-tuning 방식 적용 |
| 최적화 가능 여부 | 불가능 (수정하려면 사람이 직접 조정해야 함) | 가능 (Gradient-based 또는 Non-gradient 방식으로 최적화 가능) |
즉, Soft Prompt는 사람이 직접 수정하는 것이 아니라, 모델이 자동으로 최적화하는 "학습 가능한 프롬프트"라고 이해하면 된다.
📌 2. Soft Prompt가 필요한 이유
기존 LLM 프롬프트 방식(Hard Prompting)에는 몇 가지 한계가 있다.
- 고정된 텍스트 프롬프트의 한계
- 사람이 직접 프롬프트를 작성해야 하므로 프롬프트 엔지니어링이 필요함.
- 프롬프트를 최적화하려면 직접 여러 번 수정해야 하므로 비효율적.
- 최적의 프롬프트를 찾기 어려움
- LLM의 내부 작동 방식이 블랙박스이기 때문에, 어떤 프롬프트가 가장 효과적인지 수작업으로 찾기 어려움.
- Soft Prompt는 LLM이 스스로 최적의 프롬프트를 학습하여 개선할 수 있도록 도와줌.
- Prompt의 표현력을 확장할 수 있음
- Hard Prompt는 텍스트 기반이므로, 복잡한 최적화를 적용하기 어려움.
- Soft Prompt는 벡터 공간에서 최적화 가능하여, 더 유연한 방식으로 LLM의 출력을 제어할 수 있음.
📌 3. DORA에서 Soft Prompt의 역할
DORA는 반영 프롬프트(Reflection Prompt)를 최적화하는 과정에서 Soft Prompt를 사용하여 베이지안 최적화(Bayesian Optimization)를 수행한다.
- Soft Prompt 벡터 초기화
- Soft Prompt를 벡터 공간에서 초기화하며, 일반적인 고정된 텍스트 프롬프트를 사용하지 않음.
- 즉, 초기에는 랜덤한 값으로 설정됨.
- 베이지안 최적화를 통해 최적의 Soft Prompt 탐색
- Soft Prompt 벡터를 조금씩 수정하면서 LLM이 더 좋은 반영 조언을 생성하도록 학습.
- Gaussian Process를 기반으로, 반영 성능이 높은 방향으로 Soft Prompt를 조정.
- Soft Prompt를 LLM 입력에 삽입하여 최적화된 반영 프롬프트 생성
- 최적화된 Soft Prompt를 활용하여 LLM이 더 나은 반영 조언을 생성하도록 유도.
즉, DORA에서는 Soft Prompt가 LLM의 반영 성능을 최적화하는 핵심적인 역할을 담당한다.
📌 4. Soft Prompt의 동작 방식 (수식)
Soft Prompt는 LLM의 입력에 추가적인 "가상 토큰(Virtual Token)"을 삽입하는 방식으로 작동한다.
(1) 기존 Hard Prompt 방식
일반적인 LLM 입력 방식:
Output=LLM(Prompt)
예를 들어:
LLM("Summarize the following text: ...")
이런 방식에서는 프롬프트를 사람이 직접 작성해야 하며, 학습이 불가능함.
(2) Soft Prompt 방식
Soft Prompt는 LLM의 임베딩 공간에 직접 삽입되는 학습 가능한 벡터로 표현됨.
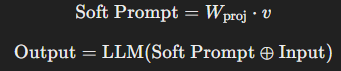
- vv : 학습 가능한 저차원 벡터 (Soft Prompt)
- W_{proj} : 고차원 임베딩 공간으로 변환하는 선형 프로젝션
- ⊕: 입력과 Soft Prompt의 연결(Concatenation)
즉, Soft Prompt는 단순한 문자열이 아니라 뉴럴 네트워크가 학습 가능한 추가적인 "토큰"으로 작용하여 LLM 출력을 제어하는 역할을 한다.
📌 5. Soft Prompt의 활용 예시
🔹 기존 Hard Prompt 방식
"Summarize the following text: ..."
- 사람이 직접 작성해야 하며, 여러 번 수작업으로 조정해야 함.
🔹 Soft Prompt 방식
Soft Prompt가 LLM 입력의 앞부분에 학습 가능한 벡터로 삽입됨.
[Soft Prompt] + "Summarize the following text: ..."
- 사람이 직접 수정할 필요 없이, Soft Prompt 벡터가 자동으로 최적화됨.
- 모델이 "Summarization"에 최적화된 벡터를 학습하여 더 나은 출력을 생성.
📌 6. Soft Prompt vs. Fine-tuning
Soft Prompt는 기존의 Fine-tuning(모델 미세 조정)과 유사하지만, 중요한 차이점이 있다.
| 구분 | Soft Prompting | Fine-tuning |
| 학습 가능 여부 | ✅ 가능 (벡터 학습) | ✅ 가능 (전체 모델 파라미터 학습) |
| 학습 방식 | LLM의 입력 프롬프트를 학습 가능 벡터로 변환 | LLM 전체를 미세 조정(Fine-tuning) |
| 모델 수정 여부 | ❌ 모델 자체는 수정하지 않음 | ✅ 모델 내부 가중치를 수정 |
| 적용 용이성 | ✅ 기존 LLM을 그대로 사용 가능 | ❌ 모델을 다시 학습해야 함 |
| 계산 비용 | ✅ 저비용 (빠른 학습 가능) | ❌ 고비용 (전체 모델 학습 필요) |
즉, Soft Prompting은 Fine-tuning 없이도 특정 태스크에 맞게 LLM 출력을 최적화하는 기법이라고 볼 수 있다.
📌 7. 결론
✅ Soft Prompt란?
- 기존의 텍스트 기반 프롬프트 대신, LLM 입력에 삽입되는 학습 가능한 벡터(임베딩) 형태의 프롬프트.
- 사람이 직접 조정하는 것이 아니라, 모델이 최적의 프롬프트를 자동으로 학습하는 방식.
✅ DORA에서 Soft Prompt의 역할
- 반영 프롬프트를 동적으로 최적화하여 LLM이 더 좋은 반영 조언을 생성하도록 유도.
- 베이지안 최적화와 결합하여 최적의 반영 프롬프트를 탐색하는 데 사용.
✅ Soft Prompt의 장점
✔ Fine-tuning 없이도 모델을 최적화할 수 있음
✔ 베이지안 최적화와 결합하여 LLM 반영 성능을 지속적으로 개선 가능
✔ LLM 내부를 수정하지 않고도 특정 태스크에 맞게 적응 가능
결론적으로, DORA의 Soft Prompt 기법은 LLM의 반영 최적화를 보다 효율적이고 자동화된 방식으로 수행할 수 있도록 설계된 핵심 요소라고 할 수 있다! 🚀
✅ Soft Prompt는 Closed Model에서도 사용 가능할까?
정답: "부분적으로 가능하지만, 제한적이다."
Soft Prompt 기법이 Closed Model(예: OpenAI의 GPT-4, Claude, Gemini 등)에서 완전히 적용되는 것은 어렵지만, 특정 방식으로는 사용할 수 있다.
1. Closed Model vs. Open Model에서 Soft Prompt 사용 가능 여부
| 구분 | Open Model | Closed Model |
| Soft Prompt 적용 가능 여부 | ✅ 가능 (모델 내부에 Soft Prompt 벡터 직접 삽입 가능) | ❌ 직접 삽입 불가능 (API 기반 접근) |
| 프롬프트 학습 가능 여부 | ✅ 가능 (모델 내부에서 Soft Prompt 벡터를 최적화할 수 있음) | ❌ 불가능 (API를 통해 텍스트 입력만 가능) |
| Soft Prompt 최적화 가능 여부 | ✅ 가능 (Gradient-based 또는 Bayesian Optimization 사용 가능) | ⭕ 제한적 (RLHF처럼 간접적인 최적화 가능) |
| Fine-tuning과 비교 | ✅ Soft Prompt로 대체 가능 | ❌ Soft Prompt 대신 Prompt Engineering 필요 |
즉, Soft Prompt는 모델 내부적으로 벡터를 삽입해야 하는 기법이므로, Closed Model에서는 직접적인 적용이 불가능하다.
하지만, 대체 방법이 존재한다.
2. Closed Model에서 Soft Prompt를 대체할 수 있는 방법
Soft Prompt를 사용할 수 없는 경우, Closed Model에서는 다음과 같은 대체 방법을 사용할 수 있다.
(1) Prefix Prompting (프리픽스 프롬프트)
- Soft Prompt와 가장 유사한 방식으로, 프롬프트 앞부분에 "가이드 텍스트"를 추가하여 모델의 출력을 유도하는 방식.
- 예를 들어, Soft Prompt를 사용할 수 없는 경우, 아래와 같은 방법으로 가상의 Soft Prompt를 만드는 것이 가능함.
📌 Soft Prompt (Open Model에서 사용 가능)
[Soft Prompt Embedding] + "Summarize the following text: ..."
📌 Prefix Prompt (Closed Model에서 사용 가능)
"Think step by step before answering. When solving problems, reflect on previous mistakes and improve: Summarize the following text: ..."
- Closed Model에서는 Soft Prompt처럼 모델 내부 벡터를 수정할 수 없으므로, 텍스트 기반 프리픽스(Prefix)를 활용하여 유사한 효과를 내는 방법을 사용함.
- 즉, Soft Prompt를 텍스트 기반 프롬프트 엔지니어링 방식으로 변환하여 적용 가능.
(2) Prompt Tuning API 활용
일부 Closed Model은 Soft Prompt와 유사한 기능을 제공하는 API를 제공하기도 한다.
예를 들어, OpenAI의 API에서 제공하는 custom instructions나 system prompt를 활용하면 Soft Prompt와 비슷한 효과를 얻을 수 있다.
✅ 예시: OpenAI의 System Prompt 활용
SYSTEM: "당신은 반영(Reflection) 기반 AI입니다. 매번 반영 조언을 개선하세요."
USER: "Summarize the following text: ..."
- 시스템 프롬프트를 활용하면 Soft Prompt처럼 지속적인 최적화는 어렵지만, 기본적인 지시를 포함할 수 있음.
(3) Reinforcement Learning with Human Feedback (RLHF) 방식 적용
Soft Prompt가 Gradient-based로 최적화되는 것처럼, RLHF를 활용하면 Closed Model에서도 반영 최적화가 가능하다.
- OpenAI의 GPT-4도 RLHF(인간 피드백을 이용한 강화학습)를 통해 최적화됨.
- RLHF를 적용하면 Soft Prompt처럼 Closed Model에서도 지속적인 최적화를 수행할 수 있음.
📌 Closed Model에서 RLHF를 활용한 대체 방법
- 반영 조언을 다양하게 생성한 후, 최적의 반영 프롬프트를 선택.
- 사용자 피드백(RLHF)을 활용하여 반영 프롬프트를 개선.
- 최적화된 프롬프트를 API 호출 시 지속적으로 반영.
✅ 결과:
Soft Prompt처럼 자동 최적화는 어렵지만, 사용자 피드백을 이용하여 Closed Model에서도 반영 조언을 최적화할 수 있음.
3. 결론: Closed Model에서 Soft Prompt를 어떻게 활용할 수 있을까?
✅ Soft Prompt 자체는 Closed Model에서 직접 사용할 수 없음.
✅ 하지만 Prefix Prompting, System Prompting, RLHF 등을 활용하면 유사한 효과를 얻을 수 있음.
✅ Closed Model에서도 Soft Prompt를 간접적으로 적용하는 방법은 존재하지만, Open Model만큼 자유롭게 최적화할 수는 없음.
💡 최종 요약
| 환경 | Soft Prompt 사용 가능 여부 | 대체 방법 |
| Open Model (예: LLaMA, Mistral) | ✅ 가능 | Soft Prompt 최적화 가능 |
| Closed Model (예: GPT-4, Claude, Gemini) | ❌ 불가능 | Prefix Prompting, System Prompting, RLHF 활용 |
즉, Soft Prompt는 Closed Model에서는 직접 사용할 수 없지만, 대체 기법을 활용하면 유사한 효과를 얻을 수 있다! 🚀
논문의 해당 부분 분석 및 설명
논문의 해당 부분에서는 대형 LLM(특히 Closed-source LLM)에서 Gradient-based 최적화가 어려운 이유와 이를 해결하기 위한 Gradient-Free Prompt Optimization 기법에 대해 설명하고 있다.
📌 1. Closed-source 또는 대형 LLM에서 Gradient Descent 사용이 어려운 이유
논문에서는 Gradient Descent(기울기 기반 최적화)가 대형 또는 Closed-source LLM에서 비효율적이며, 이를 대체하는 Gradient-Free 방법이 필요함을 강조한다.
🔹 Closed LLM에서 Gradient Descent가 어려운 이유
- 모델 내부 파라미터 접근 불가능
- OpenAI GPT-4, Claude, Gemini와 같은 Closed LLM은 내부 파라미터를 제공하지 않으므로 Gradient 계산이 불가능.
- 즉, 모델을 미세 조정(Fine-tuning)할 수 없으며, 외부에서 프롬프트 최적화만 가능함.
- Gradient Descent 적용 불가능
- 일반적인 Fine-tuning 방식(Gradient Descent 기반)은 모델의 가중치를 조정하여 최적화하지만, Closed Model은 이런 방식으로 학습할 수 없음.
- 계산 비용 문제
- GPT-4, LLaMA 65B와 같은 대형 모델에서는 Gradient Descent를 이용한 Fine-tuning이 매우 비싸고 비효율적.
- 즉, 미분 기반 최적화(Gradient-based Optimization) 대신 비미분 최적화(Gradient-Free Optimization) 방법이 필요.
📌 2. Gradient-Free Prompt Optimization 기법
Gradient Descent를 사용할 수 없는 상황에서는 비미분 최적화(Gradient-Free Optimization) 기법을 사용하여 최적의 프롬프트를 찾는다.
논문에서는 이를 해결하기 위해 다음과 같은 방법들을 소개하고 있다.
| 방법론 | 설명 | 참고 연구 |
| 1️⃣ Evolutionary Algorithms (진화 알고리즘) | 여러 세대에 걸쳐 프롬프트를 점진적으로 진화시키는 방식 | Xu et al., 2022; Guo et al., 2023; Chen et al., 2023a; Fernando et al., 2023; Yang & Li, 2023 |
| 2️⃣ Text Editing Search (텍스트 편집 탐색 기법) | 기존 프롬프트를 조금씩 수정하면서 최적의 프롬프트를 찾는 방식 | Prasad et al., 2023 |
| 3️⃣ Reinforcement Learning (강화학습 기반 최적화) | LLM과 상호작용하며 피드백을 기반으로 최적의 프롬프트를 학습하는 방식 | Deng et al., 2022 |
| 4️⃣ LLM 자체를 활용한 프롬프트 최적화 | LLM이 직접 프롬프트를 생성하고 이를 최적화하는 방식 | Pryzant et al., 2023; Wang et al., 2023b; Yang et al., 2023 |
각 방법에 대해 좀 더 자세히 설명해 보겠다.
🔹 1️⃣ Evolutionary Algorithms (진화 알고리즘)
개념:
- 자연에서 유전적 진화가 반복되면서 더 나은 개체가 선택되는 방식처럼, 최적의 프롬프트를 찾아가는 방식.
- 즉, 여러 개의 프롬프트를 랜덤하게 생성한 뒤, 성능이 좋은 프롬프트를 선택하고 변형(Mutation)하면서 점진적으로 최적화.
과정:
- 초기 프롬프트 집합을 무작위로 생성.
- LLM을 실행하여 성능을 평가.
- 성능이 좋은 프롬프트를 선택하여 변형(돌연변이, Crossover) 수행.
- 새로운 프롬프트를 평가하고, 최적의 프롬프트를 점진적으로 학습.
장점:
✅ Gradient 없이 최적의 프롬프트를 찾아갈 수 있음.
✅ Closed Model에서도 사용 가능.
단점:
❌ 계산 비용이 크고, 탐색 과정이 오래 걸릴 수 있음.
❌ 최적해를 찾는 과정에서 랜덤성이 강함.
🔹 2️⃣ Text Editing Search (텍스트 편집 탐색)
개념:
- 기존 프롬프트에서 조금씩 텍스트를 수정하면서 최적의 프롬프트를 찾는 방식.
- 예를 들어, "Solve the math problem step by step"이라는 프롬프트를 다음과 같이 변형하면서 최적의 결과를 찾음.
- "Solve the math problem carefully."
- "First, break down the problem into steps."
- "Think step by step before answering."
과정:
- 기존 프롬프트에서 작은 변형을 적용하여 새로운 후보 프롬프트를 생성.
- 각 프롬프트를 실행하고 성능을 평가.
- 최고 성능을 보이는 프롬프트를 선택하여 최적화 진행.
장점:
✅ 기존 프롬프트를 크게 변경하지 않고 최적화 가능.
✅ 탐색 과정이 상대적으로 단순함.
단점:
❌ 아주 큰 변화를 줄 수 없으므로 최적해를 찾기 어려울 수도 있음.
🔹 3️⃣ Reinforcement Learning (강화학습 기반 최적화)
개념:
- 프롬프트를 입력하고 모델의 출력을 보며 학습.
- 예를 들어, LLM이 생성한 반영 조언을 평가하고, 보상을 부여하여 점진적으로 더 나은 프롬프트를 학습.
과정:
- 초기 프롬프트를 설정하고 LLM을 실행.
- 출력 결과를 평가하여 보상 함수 적용.
- 보상을 기반으로 프롬프트를 업데이트하여 점진적으로 개선.
장점:
✅ Closed Model에서도 활용 가능.
✅ 피드백을 기반으로 최적화되므로 점진적으로 개선 가능.
단점:
❌ 학습 속도가 느릴 수 있음.
❌ 보상 함수 설계가 어려울 수 있음.
🔹 4️⃣ LLM 자체를 활용한 프롬프트 최적화
개념:
- LLM이 스스로 프롬프트를 생성하고, 이를 반복적으로 수정하면서 최적의 프롬프트를 찾아감.
- 예를 들어, GPT-4에게 "더 나은 프롬프트를 생성해줘"라고 요청하고 이를 반복하면 점진적으로 최적화할 수 있음.
과정:
- 초기 프롬프트를 LLM에 입력.
- LLM이 스스로 새로운 프롬프트를 생성.
- 각 프롬프트를 평가하고 최적의 프롬프트를 선택.
장점:
✅ 자동화가 가능하고 인간 개입이 적음.
✅ LLM이 스스로 최적화할 수 있음.
단점:
❌ LLM이 생성하는 프롬프트가 항상 최적인 것은 아님.
❌ 평가 기준이 명확하지 않을 경우 학습이 어려울 수 있음.
📌 3. DORA가 사용하는 방법: Bayesian Optimization (BO)
논문에서는 다양한 Gradient-Free 최적화 기법 중에서 베이지안 최적화(Bayesian Optimization, BO)를 사용하여 Soft Prompt를 최적화하는 방법을 선택함.
✅ 왜 BO를 사용했을까?
- 진화 알고리즘이나 강화학습보다 탐색 과정이 더 효율적.
- 학습 속도가 빠르고, 랜덤성이 적어 안정적으로 최적해를 찾을 수 있음.
- Gaussian Process(GP)를 사용하여 최적의 Soft Prompt를 찾는 방향성을 제시할 수 있음.
📌 4. 결론
- Closed LLM에서는 Gradient-based 최적화가 어렵기 때문에 Gradient-Free 방법이 필요함.
- 진화 알고리즘, 강화학습, LLM 자체를 활용한 최적화 기법 등이 존재하지만, DORA는 베이지안 최적화를 선택함.
- 베이지안 최적화는 탐색을 더 효율적으로 수행하며, Closed Model에서도 프롬프트를 최적화할 수 있는 강력한 방법임. 🚀
DORA에서 Reward 측정 방식과 활용 목적 분석
DORA에서는 반영 프롬프트(Reflection Prompt)를 최적화하는 과정에서, 에이전트의 성능을 평가하는 지표로 Reward를 사용한다.
이 Reward는 베이지안 최적화(Bayesian Optimization, BO)에서 프롬프트를 지속적으로 개선하는 핵심 요소로 활용된다.
📌 1. Reward를 측정하는 이유
DORA는 Gradient-Free 방식(베이지안 최적화)을 사용하여 최적의 반영 프롬프트를 탐색한다.
이때, 일반적인 Gradient Descent에서는 손실 함수(Loss Function)가 학습 방향을 결정하지만,
Gradient-Free 방식에서는 Reward 값을 최적화 목표(Objective Function)로 사용하여 프롬프트를 개선한다.
✔ 즉, DORA에서 Reward는 손실 함수(Loss)와 같은 역할을 하며, 최적의 반영 프롬프트를 탐색하는 기준이 됨.
📌 2. Reward의 구성 요소
DORA에서는 Reward를 두 가지 요소(Performance Reward + Diversity Reward)로 나누어 측정한다.
이 두 가지 요소를 결합하여 최종 Reward 값을 계산한다.
🔹 (1) 성능 기반 보상 (Performance Reward)
- R_performance: 에이전트가 주어진 환경에서 얼마나 잘 수행했는지를 평가하는 지표.
- 특정 작업(Task)에서 에이전트의 성공률(Success Rate)을 측정하여 사용.
✔ 왜 필요한가?
- 일반적인 환경에서는 성공(1) / 실패(0) 같은 이진 결과(Binary Outcome)만 존재하기 때문에, 단일 태스크 기준으로는 적절한 평가가 어려움.
- 따라서, 비슷한 유형의 여러 작업에서 에이전트의 성공률을 종합적으로 측정하여 평가.
✔ 수식 표현:

- 여기서 a_i는 에이전트의 행동(Action), o_i는 환경의 관찰(Observation).
- 즉, 현재 작업(Task)에서의 성능을 평가하여 반영 프롬프트가 얼마나 효과적인지를 측정.
🔹 (2) 다양성 기반 보상 (Diversity Reward)
- R_diversity: 반영 조언(Reflection Advice)의 다양성을 평가하는 지표.
- 같은 작업에서도 계속 동일한 반영 조언이 생성되면 학습이 정체될 수 있으므로,
→ 반영 조언이 얼마나 다르게 생성되는지를 측정하여 보상으로 활용.
✔ 왜 필요한가?
- 만약 프롬프트가 계속 같은 유형의 반영 조언을 생성하면, 에이전트가 새로운 전략을 배우지 못함.
- 따라서, 반영 조언이 반복되지 않도록 Cosine Similarity를 활용하여 다름(변화 정도)을 측정.
✔ 수식 표현:

- R_i: 현재 반영 조언 (Iteration i)
- R_{i-1}: 이전 반영 조언 (Iteration i-1)
- Cosine Similarity를 사용하여 두 반영 조언 간의 유사도를 계산.
→ 유사도가 낮을수록(즉, 반영 조언이 많이 다를수록) 높은 보상을 부여.
📌 3. 최종 Reward 계산 방법
DORA는 성능 보상(R_performance)과 다양성 보상(R_diversity)을 결합하여 최종 Reward 값(R)을 생성한다.
이때, α(Alpha)라는 가중치 파라미터를 사용하여 두 보상의 중요도를 조정할 수 있다.
✔ 최종 Reward 수식:

🔹 α(Alpha) 값이 의미하는 것
- α값이 크면 → 다양성을 더 중요하게 반영 (새로운 반영 조언을 적극적으로 탐색).
- α값이 작으면 → 성능을 더 중요하게 반영 (현재 가장 성능이 좋은 반영 프롬프트를 유지).
✔ 왜 α(Alpha) 조정이 필요한가?
- 초기 학습 단계에서는 다양성을 높게 설정하여 여러 가지 반영 조언을 실험.
- 학습이 진행되면 성능을 더 높게 설정하여 안정적인 최적 반영 프롬프트를 찾음.
📌 4. Reward의 활용 목적
Reward는 베이지안 최적화(Bayesian Optimization, BO)의 탐색 대상(목적 함수)으로 사용된다.
📌 (1) 반영 프롬프트 최적화
- 베이지안 최적화는 최적의 Soft Prompt를 찾기 위해 Reward 값을 최적화하는 방식으로 동작한다.
- 즉, Reward가 높을수록 더 나은 반영 프롬프트로 간주하고, 이후 탐색 과정에서 더 집중적으로 평가함.
📌 (2) 탐색 vs. 활용(Exploration vs. Exploitation) 균형 유지
- R_diversity를 활용하여 탐색(Exploration)을 수행 → 새로운 반영 프롬프트를 시도.
- R_performance를 활용하여 활용(Exploitation)을 수행 → 가장 성능이 높은 프롬프트를 선택.
✔ 즉, Reward는 새로운 반영 조언을 탐색하면서도 성능을 유지하도록 균형을 맞추는 역할을 수행.
📌 5. 예제 시나리오 (MiniWoB++ 환경에서 에이전트 실행)
🚀 기존 Reflexion 방식
- 에이전트가 "파일을 찾는 작업"을 수행한다고 가정하면:
- Reflexion 프롬프트: "파일을 클릭하세요."
- 동일한 반영 조언이 반복되면서 학습이 멈춤.
🚀 DORA + Reward 기반 최적화
- 초기 반영 프롬프트:
- "파일을 찾으려면 먼저 'Alan' 폴더를 확인하세요."
- R_performance = 0.6 (60% 성공)
- R_diversity = 0.9 (새로운 반영 조언 생성)
- 최종 Reward: R = 0.3(0.6) + 0.7(0.9) = 0.81
- 개선된 반영 프롬프트:
- "Alan 폴더를 확인한 후, 내부에서 'Agustina' 파일을 찾아보세요."
- R_performance = 0.8 (성공률 증가)
- R_diversity = 0.5 (다양성 감소)
- 최종 Reward: R = 0.3(0.8) + 0.7(0.5) = 0.59
✅ 결과:
→ 다양성이 줄어들었기 때문에, 이전 프롬프트보다 Reward가 낮음.
→ 더 효과적인 반영 프롬프트를 찾기 위해 새로운 탐색을 수행해야 함.
📌 6. 결론
✅ DORA의 Reward는 최적의 반영 프롬프트를 찾기 위한 지표로 사용됨.
✅ 두 가지 보상(성능 + 다양성)을 조합하여 탐색과 활용을 균형 있게 조정.
✅ 베이지안 최적화를 통해 Reward가 높은 방향으로 반영 프롬프트를 점진적으로 최적화.
✅ Closed LLM에서도 Gradient-Free 방식으로 최적화가 가능하도록 설계됨.
👉 즉, DORA에서 Reward는 최적의 반영 조언을 생성하기 위해 지속적으로 학습 방향을 제시하는 핵심 역할을 수행한다! 🚀