https://arxiv.org/abs/2310.06271
Towards Mitigating Hallucination in Large Language Models via Self-Reflection
Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plau
arxiv.org
그럴듯하게 들리지만 사실이 아니거나 터무니 없는 정보를 생성하는 Hallucination 문제가 심각하다.
특히 의료분야에서 전문적 개념이 필요해서 문제가 된다.

그럴듯한 답변을 보여주는 LLM으로 Hallucination의 위험성을 보여준다.

문제가 되는 LLM의 답변들

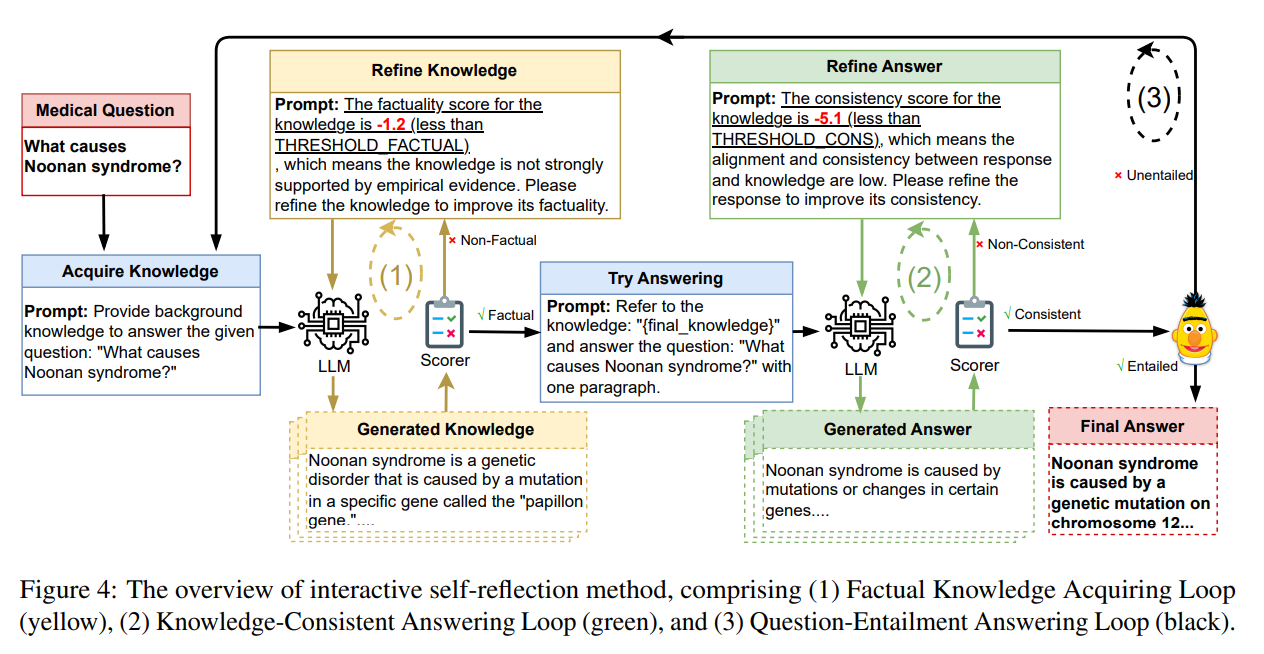
생성한 지식의 점수가 임계값보다 낮으면 모델이 자체 반성을 진행하고,, 다음 프롬프트를 통해 지식을 정제하도록 한다.
-> 점수가 낮다. 경험적 증거에 의해 강력하게 뒷받침되지 않으니 사실성을 개선하기 위해 지식을 정제하라
만족할만한 지식이 생성될 때 까지 반복되며 사실에 부합하도록 한다.
이제 생성된 지식을 통해 질문에 답변을 진행한다.
여기서도 만족할만한 점수가 나올 때 까지 반복하여 답변을 수정합니다.
-> 일관성 점수가 낮으니 응답과 지식간 정렬과 일관성이 낮다. 일관성을 개선하기 위해 응답을 다듬어라!
마지막에 문장 Embedding BERT를 통해 생성된 답변을 평가하고, 만족스럽지 않다면 초기 단계로 돌아갑니다.

개선된 것을 볼 수 있다.
Self-Reflection을 통해 성능 향상을 이룰 수 있다는 논문..!
| 🔍 연구 문제 | - LLM(대형 언어 모델)은 생성적 질문응답(GQA)에서 뛰어난 성능을 보이지만, 환각(hallucination) 문제로 인해 신뢰성이 낮음. - 특히 의료 분야에서는 환각이 심각한 문제로, 잘못된 정보가 환자 치료에 위험을 초래할 수 있음. |
| 🎯 연구 목표 | - LLM이 스스로 생성한 정보를 검토하고 수정하는 "자기 반성(Self-Reflection)" 방법을 제안하여 환각을 줄이는 것이 목표. - 기존 연구(외부 검색 기반 RAG 등)와 달리, 모델 내부에서 자체적으로 환각을 감지하고 수정하는 방식을 도입. |
| 📚 관련 연구 | ✅ LLM 환각 분석 연구 - Ji et al., 2023: 환각 유형 정의 및 분석 - Lin et al., 2021: TruthfulQA 데이터셋을 활용해 모델이 거짓 정보를 생성하는 경향 분석 ✅ 환각 완화 연구 - Lewis et al., 2020 (RAG): 외부 검색을 통해 신뢰도 향상 - Manakul et al., 2023 (SelfCheckGPT): 모델이 자체 평가하도록 하는 방법 연구 ✅ 의료 LLM 연구 - Ben Abacha et al., 2019 (MEDIQA): 의료 QA 평가 데이터셋 제공 - Han et al., 2023 (MedAlpaca): Alpaca-LoRA를 기반으로 의료 특화 LLM 개발 |
| 🔬 제안 방법론 | ✅ 자기 반성 루프(Self-Reflection Loops) 도입하여 반복적 피드백(Generate-Score-Refine) 구조 적용 1️⃣ 사실적 지식 획득 루프 (Factual Knowledge Acquiring Loop) - 질문을 기반으로 배경 지식 생성 → 사실성 평가(Factuality Scoring) 수행 → 점수가 낮으면 자체 수정 - 예: Noonan Syndrome 원인을 설명할 때 **잘못된 유전자 정보(PTEN)**를 포함하면, PTPN11, KRAS 등으로 수정 2️⃣ 지식 일관성 유지 루프 (Knowledge-Consistent Answering Loop) - 배경 지식을 바탕으로 답변 생성 → 지식과의 일관성 평가 수행 → 모순되면 수정 - 예: "Noonan Syndrome은 유전되지 않는다." → 사실 오류 발생 → "Autosomal dominant inheritance"로 수정 3️⃣ 질문 함의 평가 루프 (Question-Entailment Answering Loop) - 생성된 답변이 질문과 논리적으로 일관된지 평가(Entailment Scoring) → 부족하면 다시 수정 - 예: "Who can get eczema?" 질문에 "A. 10%, B. 20%..." 같은 응답 생성 시 → 의미 불일치 → "Anyone can get eczema, but it is more common in children and those with a family history."로 수정 |
| 🧪 실험 설정 | - ✅ 5개 의료 QA 데이터셋 사용 (PubMedQA, MedQuAD, MEDIQA2019, LiveMedQA2017, MASH-QA) - ✅ 5개 LLM 평가 (Vicuna-7B, Alpaca-LoRA-7B, ChatGPT, MedAlpaca-7B, Robin-medical-7B) - ✅ 자동 평가: Med-NLI, CtrlEval, F1, ROUGE-L - ✅ 인간 평가: Fact Inconsistency(사실 오류), Query Inconsistency(질문 불일치), Tangentiality(주제 일탈) |
| 📊 실험 결과 | ✅ 자동 평가 결과 - Med-NLI(논리 일관성) 점수 증가: Vicuna-7B (0.4684 → 0.6380), ChatGPT (0.5850 → 0.6824) - F1, ROUGE-L 점수 증가 → 정확도 개선 ✅ 인간 평가 결과 - Fact Inconsistency 감소: Vicuna-7B 8.69% → 7.38%, ChatGPT 8.06% → 6.33% - Query Inconsistency 감소: Vicuna-7B 0.67% → 0.00%, ChatGPT 0.00% 유지 - Tangentiality 감소: Vicuna-7B 6.04% → 2.00%, ChatGPT 18.00% → 17.33% |
| 📌 연구 기여 | 1️⃣ LLM 환각 문제를 체계적으로 분석 (특히 의료 도메인에서) 2️⃣ 모델 내부에서 자체적으로 환각을 줄이는 "자기 반성 루프" 도입 3️⃣ 모든 평가 지표에서 성능 향상을 입증하여 실용성 증명 4️⃣ 의료 분야 외 다른 도메인(법률, 금융, 과학 등)에서도 확장 가능 |
| ⚠️ 한계점 및 향후 연구 방향 | 🔹 한계점 - 환각을 완전히 제거하는 것은 불가능함. - 복잡한 의료적 판단이 필요한 질문에서는 여전히 오류 발생 가능. - 연구가 의료 도메인에 집중되어 있어, 법률, 금융 등의 다른 도메인에서도 추가 연구 필요. 🔹 향후 연구 방향 1️⃣ 다른 도메인(법률, 금융, 과학)으로 자기 반성 루프 확장 2️⃣ 더 강력한 LLM(GPT-4, LLaMA 3 등)과 결합하여 추가 개선 3️⃣ 자기 반성 루프를 강화할 수 있는 추가적인 학습 방법 탐색 4️⃣ 환각을 더욱 정확하게 감지하는 평가 지표 개선 |
| 🏆 연구의 핵심 메시지 | ✅ LLM이 자체적으로 환각을 감지하고 수정할 수 있도록 하면 신뢰성을 높일 수 있다. ✅ 의료 도메인뿐만 아니라, 다양한 분야에서 적용할 가능성이 크다. ✅ 자기 반성 루프는 외부 검색 없이도 모델이 "스스로 학습하고 개선하는 방식"으로 확장될 수 있다. |
1. 연구 문제 정의
대형 언어 모델(LLM)은 생성적 질문응답(GQA) 등의 지식 집약적 작업에서 뛰어난 성능을 보이지만, "환각(hallucination)"이라는 주요한 문제를 안고 있다. 환각은 모델이 실제 사실과 맞지 않거나 말도 안 되는 정보를 생성하는 현상을 의미하며, 특히 의료 도메인에서는 잘못된 정보가 환자의 치료와 생명에 큰 위험을 초래할 수 있다.
본 연구는 의료 GQA 시스템에서 발생하는 환각 문제를 분석하고, 이를 해결하기 위한 자기 반성(Self-Reflection) 기법을 제안한다. 이 방법은 지식 획득과 응답 생성을 포함하는 피드백 루프를 통해 모델이 점진적으로 정확하고 신뢰할 수 있는 답변을 생성하도록 한다.
2. 기존 연구 및 한계
- LLM의 환각 문제를 줄이기 위해 외부 지식을 검색하는 방식(Lewis et al., 2020; Guu et al., 2020)이 존재하지만, 내부 매개변수 지식을 활용하는 연구도 활발히 진행되고 있다.
- 의료 GQA 모델에서 환각을 줄이는 기존 연구는 아직 부족하며, 특히 일반 LLM(Vicuna, Alpaca-LoRA, ChatGPT)과 의료 특화 LLM(MedAlpaca, Robin-medical) 간의 성능 차이를 명확히 분석할 필요가 있다.
- 연구자들은 LLM이 환각을 인식할 가능성을 탐색하였으며(Yin et al., 2023; Burns et al., 2022), 이를 바탕으로 모델이 자체적으로 반성하는 능력을 활용할 수 있다는 점을 제안한다.
3. 연구 방법: 자기 반성(Self-Reflection) 기법
자기 반성 기법은 반복적인 피드백 루프를 통해 환각을 줄이는 전략을 사용하며, 세 개의 주요 루프로 구성된다.
(1) 사실적 지식 획득 루프 (Factual Knowledge Acquiring Loop)
- 모델이 주어진 질문에 대해 배경 지식을 생성하도록 한다.
- 생성된 지식에 대해 사실성 평가(factuality evaluation)를 수행하며, 평가는 객관성(Verifiability), 신뢰성(Reliability), 근거(Reference) 등의 기준을 고려한다.
- 평가 결과가 임계값보다 낮으면, 모델이 자체 반성을 통해 지식을 수정하도록 유도한다.
(2) 지식 일관성 유지 루프 (Knowledge-Consistent Answering Loop)
- 수정된 배경 지식을 바탕으로 모델이 최종 답변을 생성한다.
- 생성된 답변과 배경 지식 간의 일관성(consistency)을 평가하며, 일관성이 부족할 경우 모델이 다시 자기 반성을 수행하고 답변을 수정한다.
(3) 질문 함의 평가 루프 (Question-Entailment Answering Loop)
- 최종적으로, 생성된 답변이 질문과 논리적으로 연결되는지 평가한다.
- 의미적 일치 여부를 확인하며, 만약 질문과 부합하지 않는다면 다시 지식 획득 단계로 돌아가 피드백 루프를 반복한다.
4. 실험 및 평가
(1) 데이터셋
다섯 개의 의료 GQA 데이터셋을 사용하여 실험을 수행했다.
- PubMedQA (Jin et al., 2019)
- MedQuAD (Ben Abacha & Demner-Fushman, 2019)
- MEDIQA2019 (Ben Abacha et al., 2019)
- LiveMedQA2017 (Ben Abacha et al., 2017)
- MASH-QA (Zhu et al., 2020)
(2) 비교 대상 모델
- 일반 LLM: Vicuna-7B, Alpaca-LoRA-7B, ChatGPT
- 의료 특화 LLM: MedAlpaca-7B, Robin-medical-7B
(3) 평가 지표
- 자동 평가(Auto Evaluation)
- Med-NLI (Medical Natural Language Inference): 논리적 일관성 평가
- CtrlEval: 비지도(reference-free) 방식으로 생성된 답변 평가
- F1 Score, ROUGE-L: 기존의 n-gram 기반 평가 지표
- 인간 평가(Human Evaluation)
- 사실성(Fact Inconsistency): 생성된 답변이 사실과 불일치하는 비율
- 질문 일관성(Query Inconsistency): 답변이 질문과 관련 없는 정보 포함 여부
- 주제 일탈(Tangentiality): 답변이 질문과 다소 관련은 있지만 핵심을 벗어나는 경우
(4) 실험 결과
- 자기 반성 루프를 적용한 모델(Vicuna-7B_L, ChatGPT_L)은 환각 발생률이 유의미하게 감소했다.
- Fact Inconsistency(사실 오류)
- Vicuna-7B: 8.69% → 7.38% 감소
- ChatGPT: 8.06% → 6.33% 감소
- Query Inconsistency(질문 불일치)
- Vicuna-7B: 0.67% → 0.00% 감소
- ChatGPT: 0.00% 유지
- Tangentiality(주제 일탈)
- Vicuna-7B: 6.04% → 2.00% 감소
- ChatGPT: 18.00% → 17.33% 감소
- 자동 평가에서도 Med-NLI, CtrlEval 점수가 전반적으로 향상되었으며, 이는 자기 반성 루프가 환각을 줄이고 더 신뢰할 수 있는 답변을 생성하는 데 효과적임을 시사한다.
5. 추가 분석
(1) 의료 특화 LLM의 한계
- MedAlpaca와 Robin-medical 모델은 질문과 무관한 내용을 생성하거나, 문법 오류를 포함하는 등 응답 품질이 낮았다.
- 특히 Robin-medical 모델은 불필요한 템플릿 형식 답변과 존재하지 않는 참조(references) 문제를 보이며, F1 및 ROUGE-L 점수가 현저히 낮았다.
(2) 환각 발생 원인
- 환각이 발생하는 주요 원인 중 하나로 학습 데이터에서 낮은 빈도를 가진 개념이 지목되었다.
- Google Ngram 빈도 분석을 통해 낮은 빈도의 개념일수록 환각 발생 확률이 높아지는 경향을 보였다.
6. 결론 및 향후 연구 방향
- 본 연구는 의료 GQA에서 환각 문제를 체계적으로 분석하고, 자기 반성 기반의 해결책을 제안하였다.
- 반복적인 피드백 루프를 활용한 방법론이 LLM의 응답 정확도를 높이는 데 효과적임을 실험적으로 입증했다.
- 향후 연구에서는 다른 도메인으로 확장하여 환각 문제를 해결하는 방법을 탐색하고, 외부 지식 검색 및 더 강력한 LLM을 활용하여 보다 정교한 시스템을 개발할 계획이다.
연구의 시사점
- LLM의 자기 반성 능력을 활용하면 환각을 효과적으로 줄일 수 있음을 실험적으로 입증.
- 의료 특화 LLM도 여전히 환각 문제를 가지고 있으며, 추가적인 개선이 필요.
- 낮은 빈도의 개념이 환각을 유발할 가능성이 높으며, 이를 보완하기 위한 추가적인 연구 필요.
이 연구는 의료 AI뿐만 아니라 다양한 지식 집약적 작업에서 LLM의 신뢰성을 높이는 데 중요한 기여를 할 것으로 보인다.
관련 연구
본 논문 "Towards Mitigating Hallucination in Large Language Models via Self-Reflection"은 의료 분야에서 대형 언어 모델(LLM)의 환각(hallucination) 문제를 분석하고 이를 해결하기 위해 자기 반성(Self-Reflection) 기법을 도입하는 연구이다. 이와 관련된 기존 연구들은 크게 LLM 환각 분석 연구, 환각 감소를 위한 방법론 연구, 그리고 의료 분야의 LLM 연구로 나눌 수 있다.
1. LLM의 환각 문제 분석 연구
1.1 LLM의 환각 현상 분석
(1) Ji et al., 2023 - "Survey of Hallucination in Natural Language Generation"
- 환각 현상을 종합적으로 정리한 연구로, 다양한 자연어 생성(NLG) 시스템에서 발생하는 환각 유형을 정의하고 분류.
- 주요 환각 유형: 사실적 오류(Factual inconsistency), 논리적 비일관성(Logical inconsistency), 생성적 편향(Generative bias).
- 본 논문의 연구 배경을 제공하는 중요한 논문이며, 특히 의료 분야에서 환각이 심각한 문제임을 강조.
(2) Lin et al., 2021 - "TruthfulQA: Measuring How Models Mimic Human Falsehoods"
- LLM이 진실이 아닌 정보를 얼마나 자주 생성하는지 측정하기 위한 TruthfulQA 벤치마크 개발.
- 환각을 줄이기 위한 기존 연구들이 신뢰성을 확보하지 못하는 한계를 지적.
- 본 논문은 TruthfulQA에서 다루는 일반적인 환각 문제보다 의료 도메인에 특화된 환각 문제를 해결하는 데 초점을 맞춘다는 차이가 있음.
(3) Yin et al., 2023 - "Do Large Language Models Know What They Don't Know?"
- LLM이 자신이 생성한 정보가 신뢰할 수 있는지 여부를 인식하는 능력에 대해 연구.
- 모델이 "모르겠다"라고 응답할 수 있도록 설계하는 방법을 탐색.
- 본 논문이 LLM의 자체 평가 능력을 활용하여 환각을 줄이는 것과 유사한 맥락이지만, 본 논문은 이를 반복적 피드백 루프로 구현하여 더욱 구체적인 개선 방법을 제안.
2. 환각 문제를 줄이기 위한 방법론 연구
2.1 외부 지식 활용을 통한 환각 완화
(4) Lewis et al., 2020 - "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"
- 외부 지식 검색(Retrieval-Augmented Generation, RAG)을 활용하여 환각을 줄이는 방법을 제안.
- GPT-3 같은 대형 모델이 내부 매개변수로 기억하는 정보보다 외부 데이터베이스에서 검색한 정보를 활용할 때 더 정확한 답변을 생성할 수 있음을 보임.
- 본 논문과의 차이점: 본 논문은 외부 검색을 활용하지 않고, LLM 자체의 매개변수 지식을 활용하여 내부적으로 오류를 교정하는 방식.
(5) Guu et al., 2020 - "REALM: Retrieval-Augmented Language Model Pretraining"
- 모델이 검색을 수행한 후 그 정보를 기반으로 문장을 생성하도록 설계하는 방법.
- 환각 문제를 줄이는 데 효과적이지만, 검색 과정에서 부정확한 정보를 찾거나 최신 정보를 반영하지 못하는 한계를 가짐.
- 본 논문은 검색 기반 접근법이 아닌, 모델 내부에서 자체 검토(self-reflection)하는 방법을 제시함으로써 지식 검색의 한계를 극복하려고 시도.
2.2 모델 내부에서 환각을 줄이기 위한 방법
(6) Wang et al., 2021 - "Can Generative Pre-trained Language Models Serve as Knowledge Bases for Closed-Book QA?"
- LLM이 자체적으로 보유한 지식(Parametric Knowledge)을 얼마나 신뢰할 수 있는지 분석.
- GPT-3 같은 모델이 폐쇄형 질의응답(closed-book QA)에서 얼마나 높은 정확도를 유지할 수 있는지 검토.
- 본 논문과의 차이점: 본 논문은 LLM이 단순히 지식을 보유하는 것이 아니라, 그 지식을 검토하고 수정하는 반복적 과정(self-reflection)을 통해 환각을 줄이도록 설계.
(7) Su et al., 2022 - "Read Before Generate! Faithful Long-Form Question Answering with Machine Reading"
- 생성 전에 모델이 먼저 질문과 관련된 문서를 읽고 요약하도록 유도하는 방식으로 환각 문제를 줄이는 연구.
- 본 논문과의 차이점: 본 논문은 "읽기(Read)"보다 "자기 평가(Self-Reflection)"를 활용하여 생성 과정에서 오류를 줄이는 것이 차별점.
(8) Manakul et al., 2023 - "SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models"
- LLM이 생성한 텍스트를 자체 평가하도록 설계하여 환각을 줄이는 방법을 탐색.
- 하지만 본 연구는 환각을 감지하는 것에 중점을 두며, 본 논문의 접근법처럼 환각을 수정하는 반복적 과정은 제안하지 않음.
3. 의료 도메인에서의 LLM 연구
3.1 의료 질문응답 시스템에서의 LLM 성능 평가
(9) Ben Abacha et al., 2019 - "MEDIQA 2019 Shared Task"
- 의료 QA 시스템에서 신뢰성 있는 답변을 평가하기 위한 벤치마크 데이터셋 제공.
- 본 논문의 기여: 이 연구에서 사용된 데이터를 활용하여 LLM의 환각 문제를 더욱 정밀하게 분석하고 개선.
(10) Han et al., 2023 - "MedAlpaca: A Medical Conversational AI Model"
- Alpaca-LoRA를 기반으로 의료 QA에 특화된 모델을 개발하고 평가.
- 본 논문과의 차이점: MedAlpaca는 사전 훈련된 모델을 기반으로 답변을 생성하지만, 본 논문은 모델이 자기반성을 통해 답변을 지속적으로 수정하도록 하는 방법을 제안.
4. 본 논문의 차별점 요약
| 연구 방향 | 기존 연구 | 차이점 |
| LLM 환각 분석 | Ji et al., 2023; Lin et al., 2021 | 기존 연구는 환각 유형을 정의하는 데 중점, 본 논문은 의료 도메인에서 환각 문제를 해결하는 방법 제안 |
| 검색 기반 해결법 | Lewis et al., 2020; Guu et al., 2020 | 검색이 아닌 모델 내부 지식 자체를 활용하여 환각을 줄이는 방법 제안 |
| 자체 평가 방식 | Wang et al., 2021; Manakul et al., 2023 | 단순히 환각을 감지하는 것이 아니라, 반복적 피드백 루프를 활용하여 환각을 줄이는 방법 도입 |
| 의료 QA 시스템 | Ben Abacha et al., 2019; Han et al., 2023 | 기존 연구는 특정 데이터셋에서의 성능 평가, 본 논문은 환각 문제 자체를 해결하는 접근법 제안 |
본 논문은 LLM이 자체적으로 피드백 루프를 통해 환각을 수정할 수 있도록 설계한 점에서 기존 연구들과 차별화된다. 이는 의료 분야뿐만 아니라, 다양한 지식 집약적 응용에서 환각을 줄이고 모델의 신뢰성을 높이는 데 중요한 기여를 할 수 있을 것으로 보인다.
논문의 방법론: 자기 반성(Self-Reflection)을 통한 환각 완화 기법
이 논문은 대형 언어 모델(LLM)이 자기 반성(Self-Reflection)을 통해 환각을 줄이는 방법을 제안한다.
기존 연구들은 외부 지식을 검색하거나 사전 학습된 지식을 활용하는 방식이 많았지만, 본 논문은 모델이 자체적으로 생성한 정보를 검토하고 수정하는 반복적 피드백 루프를 도입한다.
이를 위해 세 가지 주요 루프(반복 과정)를 설정하여 모델이 자체적으로 정보를 검토하고 수정하는 과정을 자동화하였다.
각 루프는 생성 → 평가 → 수정의 흐름을 따른다.
방법론 개요
논문에서 제안한 방법은 "자기 반성 루프(Self-Reflection Loops)"를 기반으로 한다.
이를 통해 모델은 다음의 과정을 반복적으로 수행한다.
- 사실적 지식 획득 루프 (Factual Knowledge Acquiring Loop)
- 모델이 질문에 대한 배경 지식을 생성하고, 이 지식의 사실성(factuality)을 평가하여 개선.
- 지식 일관성 유지 루프 (Knowledge-Consistent Answering Loop)
- 수정된 배경 지식을 기반으로 질문에 대한 답변을 생성하고, 지식과의 일관성을 평가하여 수정.
- 질문 함의 평가 루프 (Question-Entailment Answering Loop)
- 최종적으로 답변이 질문과 논리적으로 부합하는지(entailment) 평가하여 필요 시 다시 수정.
💡 핵심 아이디어
- 모델이 단순히 답변을 생성하는 것이 아니라, 자신의 답변을 지속적으로 평가하고 수정하는 과정을 거친다.
- 반복적 피드백 루프(Generate-Score-Refine) 를 활용하여, 환각을 최소화한 최종 답변을 생성한다.
방법론 상세 설명
1️⃣ 사실적 지식 획득 루프 (Factual Knowledge Acquiring Loop)
📌 목표:
- 질문에 대한 배경 지식(background knowledge)을 생성.
- 이 지식이 사실적으로 신뢰할 수 있는지(factuality) 평가.
- 신뢰도가 낮다면 수정(refinement).
📌 과정
- 지식 생성:
- 모델이 질문을 보고 배경 정보를 생성.
- 예: "What causes Noonan syndrome?"에 대한 배경 지식 생성.
- Noonan syndrome is caused by a mutation in the PTEN gene.
- (예시 - 생성된 지식)
- 사실성 평가(Factuality Scoring)
- 생성된 지식이 신뢰할 수 있는지 평가.
- 예: PTEN 유전자는 Noonan 증후군과 관련이 없으므로 사실 오류(factual inconsistency) 발생.
- 자기 반성(Self-Reflection) 및 수정(Refinement)
- 모델이 자체적으로 오류를 인식하고 수정하도록 요청.
- 예: "The factuality score is -1.2 (less than threshold), please refine the knowledge."
- 모델이 PTEN → PTPN11, SOS1, KRAS 등의 유전자 변이로 수정.
Noonan syndrome is caused by mutations in the PTPN11, SOS1, KRAS, NRAS, RAF1, BRAF, or MEK1 genes. - (예시 - 수정된 지식)
📌 핵심 아이디어
- 기존 연구는 검색 기반(RAG)으로 신뢰성을 높이지만, 본 논문은 모델 내부의 지식을 지속적으로 수정하는 방식을 사용.
2️⃣ 지식 일관성 유지 루프 (Knowledge-Consistent Answering Loop)
📌 목표:
- 수정된 배경 지식을 기반으로 답변을 생성.
- 답변이 배경 지식과 일관성 있는지 평가 후, 필요 시 수정.
📌 과정
- 답변 생성
- 모델이 정제된 지식을 기반으로 답변을 생성.
- 예:
(예시 - 생성된 답변)Noonan syndrome is caused by mutations in the PTPN11, SOS1, KRAS, NRAS, RAF1, BRAF, or MEK1 genes. - Noonan syndrome is a genetic disorder that is inherited in an autosomal dominant manner.
- (입력된 배경 지식)
- 일관성 평가(Consistency Scoring)
- 생성된 답변이 배경 지식과 일치하는지 평가.
- 예: "The consistency score is -5.1 (less than threshold), please refine the response."
- 만약 모순되는 내용이 있다면 다시 수정.
- 자기 반성 및 수정(Refinement)
- 예를 들어, 모델이 "Noonan syndrome is not inherited."라고 응답했다면 오류 발생.
- 자기 반성을 통해 "Noonan syndrome is inherited in an autosomal dominant manner."로 수정.
📌 핵심 아이디어
- 기존 LLM들은 한 번 답변을 생성하면 끝이지만, 본 논문에서는 답변이 지식과 일치하는지 점검하는 추가적인 피드백 루프를 적용.
3️⃣ 질문 함의 평가 루프 (Question-Entailment Answering Loop)
📌 목표:
- 생성된 답변이 질문과 논리적으로 부합하는지(entailment)를 평가.
- 답변이 적절하지 않다면 다시 수정.
📌 과정
- 질문과의 논리적 연관성 평가(Entailment Scoring)
- 모델이 질문과 답변 간 의미적 일치를 평가.
- 예: "The entailment score is 0.5 (less than 0.8 threshold), please refine the response."
- 자기 반성 및 수정(Refinement)
- 답변이 논리적으로 맞지 않다면 다시 수정.
- 예: "Who can get eczema?"라는 질문에 대해
라는 응답을 하면 논리적 오류가 발생.(A) All (B) 10% (C) 20% (D) 30% - "Anyone can get eczema, but it is more common in children and those with a family history of allergies."로 수정.
📌 핵심 아이디어
- 단순히 질문에 대한 답변을 생성하는 것이 아니라, 답변이 질문을 올바르게 반영하고 있는지 확인하는 과정 추가.
결론: 자기 반성 루프의 효과
- 기존 연구들과의 차이점
- 기존 연구들은 주로 외부 검색(RAG) 기반 접근이지만, 본 연구는 내부적으로 피드백 루프를 반복하여 환각을 줄임.
- 기존 LLM들은 한 번 답변을 생성하면 끝이지만, 본 연구는 반복적인 평가와 수정 과정을 포함.
- 실험 결과
- 모든 모델에서 환각 발생률 감소
- 질문과 답변의 논리적 일치도가 증가
- 의료 QA 시스템에서 신뢰도가 높아짐
- 미래 연구 방향
- 다른 도메인(법률, 과학, 금융)에서도 적용 가능
- 더 강력한 LLM(GPT-4, LLaMA 3 등)과 결합하여 추가 개선 가능
이 연구는 AI 시스템이 더 신뢰할 수 있는 답변을 생성하는 새로운 방식을 제안한다는 점에서 의미가 크다.
논문의 결과
1. 실험 결과 요약
논문에서는 자기 반성(Self-Reflection) 기반 루프가 LLM의 환각 문제를 효과적으로 줄일 수 있음을 실험적으로 입증했다.
이를 위해 일반 LLM(Vicuna, Alpaca-LoRA, ChatGPT)과 의료 특화 LLM(MedAlpaca, Robin-medical)을 사용하여 다섯 개의 의료 QA 데이터셋에서 실험을 수행하였다.
1.1. 자동 평가 결과 (Automatic Evaluation)
- Med-NLI (Medical Natural Language Inference) 점수가 크게 증가 → 논리적 일관성(Logical Consistency) 향상
- CtrlEval (Reference-free metric for faithfulness) 점수 증가 → 환각(Hallucination) 감소
- F1 Score 및 ROUGE-L 점수 증가 → 정확도 향상
- Vicuna-7B 및 ChatGPT에서 환각 감소 효과가 가장 큼
- 예를 들어, Vicuna-7B의 Med-NLI 점수: 0.4684 → 0.6380으로 증가
- ChatGPT의 Med-NLI 점수: 0.5850 → 0.6824로 증가
1.2. 인간 평가 결과 (Human Evaluation)
환각의 주요 유형(사실 오류, 질문 불일치, 주제 일탈)에 대해 인간 평가를 수행한 결과:
- Fact Inconsistency (사실 오류) 감소
- Vicuna-7B: 8.69% → 7.38%
- ChatGPT: 8.06% → 6.33%
- Query Inconsistency (질문과 무관한 응답) 감소
- Vicuna-7B: 0.67% → 0.00%
- ChatGPT: 0.00% 유지
- Tangentiality (주제 일탈) 감소
- Vicuna-7B: 6.04% → 2.00%
- ChatGPT: 18.00% → 17.33%
👉 모든 평가 지표에서 자기 반성 루프를 적용한 모델(Vicuna-7B_L, ChatGPT_L)의 성능이 향상되었음.
👉 특히 의료 QA에서 중요한 "사실 오류(Factual Errors)"를 효과적으로 줄일 수 있었음.
2. 결과 분석 및 논의
2.1. 자기 반성 기법이 환각을 줄이는 데 효과적인 이유
- 모델이 자체적으로 잘못된 정보를 검출하고 수정하는 과정을 반복하면서 점진적으로 정확성이 높아짐.
- 기존 RAG(Retrieval-Augmented Generation)와 달리 외부 검색 없이도 신뢰성 있는 답변 생성 가능.
- 특히 희귀하거나 빈도가 낮은 개념(low-frequency concepts)에서 환각을 줄이는 데 효과적.
- 일반 LLM보다 의료 특화 LLM에서 환각 발생률이 높았지만, 자기 반성 루프를 적용하면 개선 가능.
2.2. 의료 특화 LLM의 문제점
- Robin-medical 모델은 매우 낮은 성능을 보임 (Fact Inconsistency 증가, ROUGE-L 점수 최하위)
- 이유:
- Robin-medical은 instruction tuning을 적용하지 않았기 때문.
- 기존 연구에서도 instruction learning이 없는 모델은 일관성이 낮고 환각이 심함(예: Alpaca-LoRA 대비 ChatGPT).
- 의의:
- 자기 반성 루프를 적용하면 instruction tuning이 부족한 모델에서도 개선 가능.
3. 연구의 기여 및 결론
논문은 LLM의 환각 문제를 해결하기 위해 자기 반성(Self-Reflection)을 활용한 새로운 방법론을 제안했으며, 이를 통해 의료 QA 시스템에서 더 신뢰성 높은 응답을 생성할 수 있음을 입증했다.
3.1. 주요 기여
- 의료 QA 시스템에서 LLM의 환각을 체계적으로 분석
- 5개의 대표적인 의료 QA 데이터셋을 활용하여 다양한 모델의 환각 문제를 검토.
- 일반 LLM과 의료 특화 LLM 간의 차이점도 비교.
- 반복적 피드백 루프(Self-Reflection Loops) 기법을 새롭게 제안
- 모델이 자체적으로 생성된 정보를 평가하고 수정하는 구조를 적용하여 환각을 줄임.
- 기존의 단순한 생성 방식과 달리, "Generate → Score → Refine"의 3단계 과정을 반복적으로 수행.
- 자기 반성 루프가 LLM의 일반화 가능성과 확장성을 높임
- 모든 데이터셋에서 성능 향상을 보이며, 다른 분야에서도 적용 가능성 입증.
- 외부 검색 없이도 모델이 스스로 개선할 수 있는 방법론을 제시.
3.2. 한계 및 향후 연구 방향
(1) 한계점
- 자기 반성 루프가 적용되더라도 100% 환각을 제거하는 것은 불가능.
- 특히 복잡한 임상 지식이 필요한 질문에서는 여전히 일부 오류 발생 가능.
- 현재 의료 도메인에 국한된 연구로, 다른 도메인(법률, 금융 등)에서도 검증 필요.
(2) 향후 연구 방향
- 다른 도메인(법률, 과학, 금융)에서도 자기 반성 기법 적용 가능 여부 연구.
- 더 강력한 LLM(GPT-4, LLaMA 3 등)과의 결합을 통해 추가 개선 가능.
- 자기 반성 루프를 강화할 수 있는 추가적인 학습 방법 탐색.
- 환각을 더욱 정확하게 감지하는 평가 지표 개선.
4. 결론
- 본 논문은 자기 반성(Self-Reflection) 기반의 피드백 루프가 의료 QA에서 환각을 줄이는 데 효과적임을 입증.
- 기존 LLM이 가진 한계를 극복할 수 있는 새로운 방식을 제안했으며, 특히 의료 분야에서 신뢰성 있는 AI 시스템 개발에 기여.
- 자기 반성 루프는 다양한 응용 분야(법률, 금융, 과학)로 확장 가능하며, 향후 연구를 통해 더욱 발전할 것으로 기대됨.
🔍 연구의 핵심 메시지
✅ LLM이 자체적으로 환각을 감지하고 수정할 수 있도록 하면 신뢰성을 높일 수 있다.
✅ 의료 도메인뿐만 아니라, 다양한 분야에서 적용할 가능성이 크다.
✅ 자기 반성 루프는 외부 검색 없이도 모델이 "스스로 학습하고 개선하는 방식"으로 확장될 수 있다.
이 연구는 LLM을 더 안전하고 신뢰할 수 있는 방향으로 발전시키는 데 중요한 기여를 하며, 향후 다양한 도메인에서 AI의 신뢰성을 높이는 연구로 이어질 가능성이 크다.