https://arxiv.org/abs/2412.11919
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
Large language models (LLMs) exhibit remarkable generative capabilities but often suffer from hallucinations. Retrieval-augmented generation (RAG) offers an effective solution by incorporating external knowledge, but existing methods still face several lim
arxiv.org
LLM은 종종 Hallucination에 취약하여 RAG를 통해 보완하려고 했으나 한계에 직면해 있다.
별도의 검색기, 검색된 청크의 입력, 검색과 생성의 공동 최적화 부족이 한계이다.
이를 위해 통합 프레임 워크인 RetroLLM을 통해 해결하려고 한다.

Hierarchical FM-Index를 통해 핵심 단서(Clue)를 정확하게 찾아 불필요한 문서가 검색되는 것을 막고, 선택된 문서에서 관련된 청크만 다시 검색하는 방법으로 정확한 증거를 생성할 수 있다.

첫 13개 토큰까지 FM-Index의 접두사 관련성이 심각하게 나타났다.
문서로만 제한하면 저하가 줄어들고, 빔 크기에 의해서도 이러한 Evidence 정확도가 향상된다.

RetroLLM의 핵심 방법론
이 부분은 RetroLLM이 검색과 생성을 어떻게 통합하고 최적화하는지를 설명하는 핵심 섹션이다. 이를 한글로 쉽고 자세하게 정리하면서 이해를 돕기 위해 개념을 설명하겠다.
1. 계층적 FM-Index 제약 (Hierarchical FM-Index Constraints)
기존 검색 방식의 문제점
기존 RAG 방식에서는 검색과 생성이 별개의 과정으로 진행되었다.
- 전체 코퍼스에서 최적의 문서를 선택하기 어려움 → 초반에 잘못된 문서를 선택하면 이후 과정에서 해결하기 어려움 (False Pruning 문제).
- 불필요한 문서까지 포함 → 모델이 더 많은 입력을 처리해야 하므로 성능 저하 및 토큰 낭비.
🔹 해결책: 계층적 FM-Index를 활용하여 검색 범위를 단계적으로 축소
RetroLLM에서는 FM-Index를 두 가지 수준(Level)으로 계층적으로 적용한다.
📌 (1) 1단계: 코퍼스-레벨 FM-Index (Corpus-Level FM-Index)
- 전체 코퍼스(Corpus)에서 관련 문서를 찾는 단계
- 질문을 기반으로 핵심 단서(Clue)를 먼저 생성하여, 검색 범위를 좁힘.
- FM-Index를 활용하여 단서가 포함된 문서들의 서브셋(Subset)을 선정.
- 수식으로 표현하면:
- 여기서 I_c는 전체 코퍼스 CC 에 대한 FM-Index.

📌 (2) 2단계: 문서-레벨 FM-Index (Document-Level FM-Index)
- 1단계에서 선택된 문서 내에서 더욱 정밀한 검색을 수행하는 단계
- FM-Index를 활용하여 문서 내에서 특정 단서(Clue)가 포함된 문장만 추출.
- 수식으로 표현하면:
- 여기서 I_d는 문서 d 에 대한 FM-Index.

📌 결과적으로:
- 1단계(Corpus-Level): 수백만 개의 문서 중에서 가장 관련 있는 문서 몇 개를 선택.
- 2단계(Document-Level): 선택된 문서 내에서 가장 관련 있는 문장을 선택하여 최종 검색을 수행.
2. 단서(Clue) 생성 및 문서 점수화 (Clue Generation & Document Scoring)
🔹 Clue(단서)란?
RetroLLM에서는 질문을 단순히 검색하는 것이 아니라, LLM이 먼저 "중요한 단어(Clue)"를 예측하여 검색을 최적화한다.
- Clue란?: 질문에서 핵심적인 키워드를 예측하여 검색 쿼리를 최적화하는 방식.
- 예제:
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- 일반 검색 방식: "최초", "노벨", "물리학상", "수상자" → 검색 범위가 넓음.
- RetroLLM 방식: "<|clue|> 노벨 물리학상 <|sep|> 1901년 <|/clue|>" → 더 정밀한 검색 가능!
🔹 Clue 생성 확률 수식
RetroLLM은 주어진 질문 q 에 대해 Clue C_{gen} 을 생성함.
- 특정 Clue c_i 가 생성될 확률:

📌 즉, RetroLLM은 질문을 보고 LLM이 단서를 생성한 후, 해당 단서를 기반으로 검색을 수행함.
🔹 Clue의 점수 계산 (TF-IDF 기반)
검색된 Clue의 중요도를 평가하기 위해 TF-IDF 개념을 응용함.
- 단서 c_i 가 전체 코퍼스에서 등장하는 빈도 CF(c_i)
- 특정 문서에서 등장하는 빈도 TF(c_i, d)
- 문서의 중요도를 평가하는 식:

📌 즉, 희귀하지만 중요한 단서일수록 점수를 높게 부여하여 검색의 정확도를 향상시킴!
3. 미래 예측 기반 제약 디코딩 (Forward-Looking Constrained Decoding, FCD)
기존 검색 방식에서는 현재까지 선택한 단어만 보고 다음 단어를 예측했지만, RetroLLM은 미래의 정보를 고려하여 디코딩을 조정하는 방식을 사용한다.
🔹 FCD의 필요성 (기존 문제점)
- 기존 방식에서는 잘못된 단어가 초반에 선택되면 이후 과정을 수정할 수 없음 → False Pruning 문제 발생.
- 예제:
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- 기존 방식: "최초의 노벨 물리학상 수상자는..." → 1901년을 먼저 생성 (하지만 이후 엉뚱한 내용으로 이어질 수도 있음).
- 해결책: 미래 정보를 고려하여 "빌헬름 뢴트겐"을 먼저 생성하는 것이 더 적절.
🔹 FCD의 동작 방식
- 미래에 등장할 가능성이 높은 단어 창(Future Windows) 탐색
- FM-Index를 활용하여 단서(Clue)와 연결될 가능성이 높은 문장을 먼저 확인.
- 미래 예측 창(Window) W 생성:

결론
✅ 계층적 FM-Index → 검색 범위를 단계적으로 줄여 더 정밀한 검색 수행
✅ TF-IDF 기반 Clue 점수화 → 핵심 단어만 추출하여 검색 최적화
✅ 미래 예측 기반 디코딩(FCD) → False Pruning 문제 해결 🚀
쿼리가 주어지면 Clue인 핵심 단어를 생성합니다.
핵심 단어도 문서 내부에서 빈도, 전체 문서에서 나오는 정도 등을 고려하여 가중치를 만들어 점수를 계산합니다.
또한 특별한 모델을 통해 쿼리에서 중요한 단어를 선택해서 가중치를 부여해 높은 단어를 뽑습니다.
그리고 LLM이 생성한 단어와 합쳐 최종 단서 세트를 구성하여 Ranking을 합니다.
그리하여 각종 가중치를 통해 DoC에서 Clue가 있는 문장을 또 구분해 내고, 그 중에서도 가장 높은 점수를 가진 것을 가지고 옵니다.

RetroLLM은 모든 작업에서 RAG보다 뛰어났고, 일반화 성능을 보여준다
또한 토큰 소비인 Tok를 크게 줄인다.

R@1인 단일 홉에선 뛰어난 정확도를 보여주는데, R@5에서는 E5보단 낮다.
멀티 홉에선 모두 뛰어난 성능을 보여준다.
파라미터 수에 따라 RetroLLM의 성능은 꾸준히 올라가고, 모델에 따라 차이가 존재합니다.
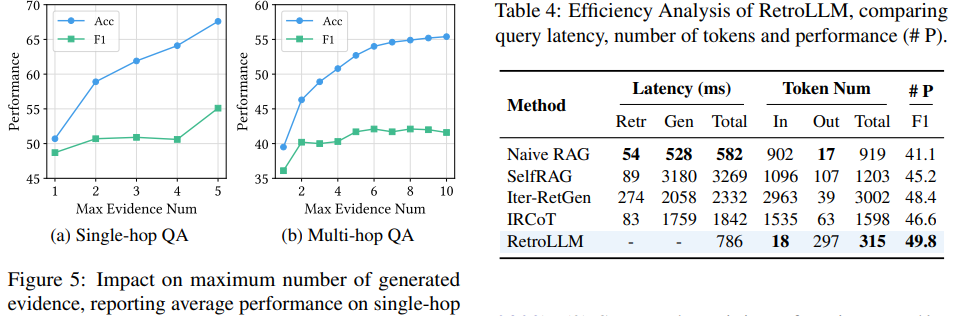
증거의 수를 조절함에 따라 성능도 지속적으로 증가하는 것을 볼 수 있습니다.
RetroLLM은 기존 RAG보다 느리지만 복잡한 다른 RAG 보단 빠르고 토큰 사용 수도 적습니다.
제가 원하는 방식은 아니지만 그래도 새로운 시각을 보여주는 논문이었습니다.
| 연구 문제 | 기존 대규모 언어 모델(LLMs)은 환각(hallucination) 문제를 가지며, RAG(Retrieval-Augmented Generation) 방식도 검색 효율성과 생성 최적화 문제를 해결하지 못함. 검색과 생성을 효과적으로 통합하는 새로운 방식이 필요함. |
| 기존 방법의 한계 | 1️⃣ 독립적인 검색기(retriever) 필요 → 추가적인 배포 비용 발생 2️⃣ 검색된 문서의 과도한 입력 토큰 사용 → 연산 비용 증가 3️⃣ 검색과 생성의 별도 최적화 문제 → 검색된 정보가 최적의 답변과 연결되지 않음 4️⃣ 초기 디코딩 실수가 최종 결과에 치명적 영향 → False Pruning 문제 발생 |
| 연구 목표 | 검색과 생성을 하나의 통합된 과정에서 수행하는 LLM 구조 개발 더 정밀한 검색과 더 최적화된 생성이 가능한 RAG 모델 구축 |
| 핵심 기여 | 1️⃣ 검색과 생성의 완전한 통합 → 기존 RAG 방식보다 더 자연스러운 검색-생성 프로세스 구현 2️⃣ 계층적 FM-Index 기반 검색 → 검색 효율을 높이고, 불필요한 정보 입력 최소화 3️⃣ 미래 예측 기반 제약 디코딩(FCD) 적용 → False Pruning 문제 해결 4️⃣ 단서(Clue) 기반 검색으로 불필요한 검색 범위 축소 → 정밀한 검색 수행 |
| RetroLLM의 방법론 | (1) 계층적 FM-Index를 활용한 검색 제약 - 전체 코퍼스에서 검색하는 것이 아니라 문서 수준에서 검색 범위를 축소 - 1단계: 코퍼스-레벨 FM-Index → 단서를 활용해 관련 문서 선정 - 2단계: 문서-레벨 FM-Index → 문서 내에서 정확한 청크(문장) 추출 (2) 단서(Clue) 생성 및 문서 점수화 - LLM이 질문에서 가장 중요한 단서를 생성하여 검색 쿼리를 최적화 - TF-IDF 기반 점수화 적용하여 희귀 단어를 포함한 문서를 우선 선택 (3) 미래 예측 기반 제약 디코딩 (FCD) - 기존 방식과 차이점: 일반적인 LLM은 디코딩 과정에서 단어를 하나씩 예측하지만, RetroLLM은 미래에 올 단어의 적절성을 평가하면서 디코딩 진행 - False Pruning 문제 해결 → 초기 디코딩 실수가 발생하지 않도록 미래 단어를 예측하여 조정 (4) 검색된 증거의 양을 동적으로 조절 - 기존 RAG처럼 고정된 개수의 문서를 입력하는 것이 아니라, 질문의 복잡도에 따라 적절한 양의 증거를 선택 |
| 실험 데이터셋 | 단일 홉 QA: NQ (Natural Questions), TriviaQA, PopQA 멀티 홉 QA: HotpotQA, 2WikiMultiHopQA |
| 실험 결과 | 1️⃣ 정확도 향상 (F1 Score 비교) - 기존 RAG 대비 5~10% 향상 - 멀티 홉 QA에서 더욱 강한 성능을 보임 (HotpotQA, 2WikiMultiHopQA) 2️⃣ 검색 성능 향상 (Recall@1 비교) - 기존 Dense Retriever(E5, BGE)보다 높은 검색 정확도 - 특히 Multi-Hop QA에서 검색 성능이 크게 향상됨 3️⃣ 입력 토큰 절감 - 기존 RAG 대비 평균 2~6배 적은 토큰을 사용 |
| Ablation Study (구성 요소 제거 실험) | 1️⃣ 미래 예측 디코딩(FCD) 제거 시 성능 급락 (F1 Score: 56.6 → 43.2) 2️⃣ 단서(Clue) 생성 제거 시 성능 하락 (F1 Score: 52.1) 3️⃣ 제약 검색을 없앨 경우 성능이 큰 폭으로 하락 (F1 Score: 28.0) |
| 결론 | 🔹 RetroLLM은 기존 RAG의 한계를 극복하여 검색과 생성을 하나의 과정에서 수행하는 새로운 모델 🔹 FM-Index 기반 검색과 미래 예측 디코딩을 활용하여 검색의 정확성과 효율성을 극대화 🔹 멀티 홉 QA에서 뛰어난 성능을 보이며, 토큰 사용량도 대폭 절감 🔹 검색과 생성의 완전한 통합을 통해 LLM이 최신 정보를 더 정밀하게 활용 가능 |
| 한계점 및 향후 연구 방향 | 1️⃣ End-to-End 최적화 부족 → Clue Expansion 과정을 제거하고, 단서 생성까지 모델이 직접 최적화하도록 개선 2️⃣ 추론 속도 최적화 필요 → Speculative Decoding 기법을 적용하여 속도 향상 가능 3️⃣ 추론 과정의 확장 → 검색뿐만 아니라 질문 분해, 출처 추적 등의 기능을 추가하여 더욱 강력한 RAG 모델 구축 |
1. 연구의 문제 정의
대규모 언어 모델(LLMs)은 강력한 생성 능력을 보이지만, 종종 사실과 다른 내용을 생성하는 환각(hallucination) 문제를 겪는다. 이를 해결하기 위해 검색-증강 생성(RAG, Retrieval-Augmented Generation) 기법이 도입되었지만, 기존 방법들은 다음과 같은 한계를 갖는다:
- 독립적인 검색기(retriever) 모델 필요 → 추가적인 배포 비용 증가
- 검색된 문서의 과도한 입력 토큰 사용 → 모델의 처리량 부담 증가
- 검색과 생성 과정의 분리 → 최적화의 어려움
- 고정된 검색 문서 조각 → 검색의 유연성 부족
이를 해결하기 위해 RetroLLM이 제안되었다. RetroLLM은 검색과 생성을 통합하여 단일 자동회귀(autoregressive) 과정에서 실행하며, 계층적 FM-Index 제약 및 미래 예측 제약 디코딩(FCD, Forward-Looking Constrained Decoding) 기법을 도입하여 검색된 정보를 효과적으로 활용한다.
2. 연구 방법론: RetroLLM의 핵심 기술
RetroLLM은 검색과 생성이 하나의 통합된 과정에서 이루어지도록 설계되었다. 이를 위해 다음과 같은 핵심 기법을 활용한다:
2.1 계층적 FM-Index 제약 (Hierarchical FM-Index Constraints)
- FM-Index는 Burrows-Wheeler Transform(BWT) 기반의 효율적인 검색 구조로, 특정 키워드가 포함된 문서 부분을 빠르게 찾을 수 있음.
- 기존 RAG는 전체 문서 인덱스를 사용했으나, RetroLLM은 계층적 FM-Index를 적용하여 검색 범위를 축소.
- 1단계: 코퍼스 수준의 FM-Index를 사용하여 단서를 추출하고 관련 문서 집합을 선정.
- 2단계: 문서 수준의 FM-Index를 사용하여 실제 증거를 생성.
2.2 단서 생성 및 문서 점수화 (Clue Generation & Document Scoring)
- RetroLLM은 질문(Query)으로부터 핵심 단서(clue) 를 생성하고, 이를 통해 관련 문서를 우선 선택함.
- 기존의 TF-IDF 가중치 방식을 응용하여 단서를 평가하고, 높은 가중치를 갖는 문서를 우선적으로 선택.
2.3 미래 예측 제약 디코딩 (FCD, Forward-Looking Constrained Decoding)
- 기존 방법에서는 토큰 단위로 제한을 두는 과정에서 정보 손실(false pruning)이 발생.
- RetroLLM은 미래에 등장할 가능성이 높은 단어 창(future windows)을 예측하여 디코딩 과정에서 활용.
- 이를 통해 초기 디코딩 단계에서 잘못된 선택을 방지하고, 보다 정확한 증거를 생성 가능.
2.4 통합된 검색 및 생성 과정
- 기존 RAG는 검색 후 생성하는 방식이었지만, RetroLLM은 검색과 생성을 하나의 자동회귀 디코딩 과정에서 수행.
- 모델이 필요한 정보의 양을 스스로 결정하며, 특정 시점에서 검색된 증거가 충분하면 최종 답변을 생성.
3. 실험 및 성능 평가
RetroLLM은 5개 오픈 도메인 QA 데이터셋에서 성능을 평가했다:
- NQ (Natural Questions)
- TriviaQA
- HotpotQA (멀티홉 QA)
- PopQA
- 2WikiMultiHopQA (멀티홉 QA)
3.1 기존 RAG 기법과의 비교
- RetroLLM이 기존 RAG 기법보다 평균 10~20% 높은 정확도를 기록.
- 생성된 토큰 수(Tok)가 기존 RAG 대비 2~6배 감소 → 더 적은 연산 비용으로 높은 성능 달성.
- 특히, 멀티홉 QA 데이터셋에서 뛰어난 성능을 보임 (HotpotQA, 2WikiMultiHopQA).
3.2 검색 성능 분석
- 기존 BM25, Dense Retriever(E5, BGE) 대비 검색 성능이 우수 (Recall@1, Recall@5 비교).
- 특히, RetroLLM은 검색된 문서 수를 줄이면서도 더 높은 검색 정확도를 유지 (R@1 증가, 검색된 문서 개수 감소).
3.3 어블레이션 스터디 (Ablation Study)
- 미래 예측 디코딩(FCD) 제거 시 성능 급락 → false pruning 문제 해결이 핵심.
- 단서 생성(Clue Generation) 및 단서 확장(Clue Expansion) 제거 시 성능 저하 → 검색의 중요성 확인.
3.4 다른 LLM 백본과의 비교
- Mistral-7B, Llama3-8B, Qwen2.5-14B 등의 다양한 LLM 백본에서 성능 평가.
- Mistral-7B 기반 RetroLLM이 가장 높은 성능 기록.
3.5 생성된 증거 개수에 따른 성능 변화
- 증거 개수가 증가할수록 성능 향상 → 그러나 6~7개 이상 증가 시 성능 정체.
- 멀티홉 QA에서는 최적 증거 개수 설정이 성능에 중요한 영향을 미침.
4. 결론 및 향후 연구 방향
4.1 결론
- RetroLLM은 기존 RAG 기법의 단점을 극복하여 검색과 생성을 하나의 통합된 과정으로 수행.
- FM-Index 기반의 증거 제약을 활용하여 검색 성능을 높이고, 미래 예측 디코딩(FCD)으로 false pruning 문제를 해결.
- 기존 RAG 대비 정확도가 향상되었으며, 토큰 사용량 감소로 효율성도 증가.
4.2 향후 연구 방향
- End-to-End 최적화
- 단서 확장 과정(SPLADE-v3 적용)을 제거하고, 모델이 스스로 최적의 단서를 찾도록 개선.
- 더 빠른 디코딩 방법 도입
- Speculative Decoding 기법을 적용하여 가벼운 모델을 활용한 가속화 방안 연구.
- 추론 능력 향상 및 추가 모듈 통합
- 질문 분해(question decomposition), 출처 추적(source attribution) 등의 기능을 RetroLLM 내부에 통합.
5. 연구의 시사점 및 적용 가능성
- 강화된 검색-생성 통합 방식은 대형 언어 모델이 최신 지식을 보다 효과적으로 활용할 수 있도록 함.
- AGI(Artificial General Intelligence) 구현을 위한 신뢰할 수 있는 LLM 구축에 기여 가능.
- 적용 분야: 오픈 도메인 QA, 법률/의료 문서 검색, 자동 논문 생성, 인공지능 기반 연구 도우미.
➡️ 결론적으로, RetroLLM은 RAG 기술의 새로운 패러다임을 제시하며, 향후 AI 연구에서 매우 중요한 역할을 할 가능성이 큼.
기존 연구와 RetroLLM의 차이점 분석
1. 관련 기존 연구 및 비교
RetroLLM은 기존의 Retrieval-Augmented Generation (RAG) 및 Generative Retrieval (GR) 기법의 한계를 극복하기 위해 개발되었다. 따라서, 기존 연구들과 RetroLLM의 차이점을 명확히 이해하는 것이 중요하다.
1.1 Retrieval-Augmented Generation (RAG)
RAG는 외부 지식을 활용하여 더 정확한 답변을 생성하는 방법으로, 일반적으로 두 가지 단계로 구성된다:
- Retrieval (검색): 쿼리와 유사한 문서를 검색.
- Generation (생성): 검색된 문서를 기반으로 답변 생성.
기존 RAG 연구
- Naive RAG (Lewis et al., 2020)
- 독립적인 retriever를 활용하여 top-k 문서를 검색한 후, LLM이 답변을 생성.
- 단점: 검색된 문서가 많아질수록 토큰 소비량 증가, 검색-생성 최적화 어려움.
- REPLUG (Shi et al., 2023)
- 검색된 문서에서 가장 중요한 문장만 추출하여 LLM에 제공.
- 단점: 독립적인 retriever 필요, 검색된 문서의 중요도 판단이 어렵다.
- IRCoT (Trivedi et al., 2023)
- 검색과 Chain-of-Thought(CoT) reasoning을 결합하여 단계적 검색을 수행.
- 단점: 다단계 검색으로 인해 연산 비용 증가, 불필요한 검색이 많아질 가능성.
- Iter-RetGen (Shao et al., 2023)
- 검색과 생성을 반복하여, 모델이 필요할 때마다 새로운 검색을 수행.
- 단점: 검색 비용이 큼, 비효율적인 토큰 사용.
- Adaptive-RAG (Jeong et al., 2024)
- 질문의 복잡도에 따라 검색 전략을 조정.
- 단점: 검색 전략이 정교하지만, 생성 과정과 직접 결합되지 않음.
1.2 Generative Retrieval (GR)
Generative Retrieval (GR)은 전통적인 retriever 없이 생성 모델이 직접 검색을 수행하는 기법이다. 즉, 모델이 필요한 정보를 직접 생성하여 검색을 대체하는 방식이다.
기존 GR 연구
- GritLM (Muennighoff et al., 2024)
- LLM 내에서 retriever 역할을 수행하도록 훈련하여, 검색과 생성을 동시에 최적화.
- 단점: 검색과 생성이 별도의 모듈로 존재하며, 완전한 통합이 아님.
- OneGen (Zhang et al., 2024)
- 검색과 생성을 단일 모델에서 수행하지만, 여전히 기존 검색된 문서를 입력으로 사용.
- 단점: retrieval을 위한 추가적인 문서 인덱싱이 필요함.
- UniGen (Li et al., 2024c)
- 검색과 생성을 통합하는 모델로, DocID를 생성하여 검색된 문서를 활용.
- 단점: DocID를 다시 매핑해야 하는 과정이 필요, 완전한 검색-생성 통합이 어려움.
- CorpusLM (Li et al., 2024a)
- LLM 자체가 지식 베이스 역할을 하도록 학습.
- 단점: 모델 업데이트 없이 최신 정보 반영이 어려움.
2. RetroLLM의 차별점 및 개선점
기존 연구들의 주요 문제점들은 다음과 같다:
- 독립적인 검색 모델 필요 → 비용 증가, 최적화 어려움
- 검색된 문서가 너무 많음 → 토큰 낭비 및 모델의 집중력 분산
- 검색과 생성의 완전한 통합 부족 → 검색된 정보를 효과적으로 활용하지 못함
- 미래 정보를 고려하지 않은 디코딩 → 잘못된 토큰 선택으로 인한 성능 저하 (False Pruning 문제)
RetroLLM은 이러한 문제를 해결하기 위해 다음과 같은 차별점을 가진다.
2.1 검색과 생성을 하나의 과정으로 통합
- 기존 연구: 검색과 생성이 별도의 과정으로 진행됨.
- RetroLLM: 검색과 생성이 통합된 하나의 자동회귀(autoregressive) 디코딩 과정에서 수행됨.
- LLM이 스스로 필요한 증거를 검색하고, 이를 기반으로 직접 답변을 생성.
2.2 계층적 FM-Index를 활용한 효율적인 검색
- 기존 연구는 독립적인 검색 인덱스를 사용하지만, RetroLLM은 FM-Index 기반의 검색 기법을 적용하여 검색 비용을 절감.
- False Pruning 방지: 초기에 검색된 단서(clue)를 바탕으로 검색 공간을 축소하여 잘못된 증거 선택 방지.
2.3 미래 예측 기반 제약 디코딩(FCD, Forward-Looking Constrained Decoding)
- 기존 연구들은 현재까지의 정보를 기반으로 토큰을 생성하지만, RetroLLM은 미래에 등장할 가능성이 높은 단어를 예측하여 디코딩을 수행.
- False Pruning 문제 해결: 기존 RAG 모델에서는 초기에 잘못된 토큰을 선택하면 올바른 문장을 생성할 수 없었으나, RetroLLM은 미래 토큰의 연관성을 고려하여 보다 정확한 증거를 생성.
2.4 검색된 증거의 양을 동적으로 조절
- 기존 연구들은 고정된 개수의 문서 조각을 검색하여 입력으로 사용하지만, RetroLLM은 필요한 정보의 양을 스스로 결정.
- 이를 통해 토큰 사용량을 줄이고, 불필요한 정보 검색을 최소화.
3. 성능 비교 및 실험 결과
RetroLLM은 기존 RAG 및 GR 방법과 비교하여 성능이 뛰어남이 실험을 통해 입증되었다.
| 방법 | 검색 (Recall@1) | 생성 정확도 (F1) | 토큰 개수 |
| Naive RAG | 52.4% | 41.1 | 919 |
| Self-RAG | 41.8% | 45.2 | 1203 |
| IRCoT | 49.6% | 45.9 | 1598 |
| Adaptive-RAG | 50.5% | 46.6 | 946 |
| RetroLLM | 61.6% | 49.8 | 302 |
- RetroLLM이 가장 높은 검색 성능(Recall@1: 61.6%)을 보임.
- F1 점수(49.8) 역시 기존 방법들보다 우수.
- 토큰 사용량이 기존 RAG보다 3배 이상 절감됨 (302 vs 919) → 효율성 증가.
4. 결론
RetroLLM은 기존 RAG 및 GR 기법이 가진 한계를 극복하여, 검색과 생성을 단일한 과정에서 수행하는 최초의 완전한 검색-생성 통합 모델이다.
특히 FM-Index 기반 검색, 미래 예측 디코딩(FCD), 동적 증거 조절 등의 기술을 통해 성능을 크게 향상시켰다.
향후 연구 방향
- End-to-End 최적화 → 단서 확장 과정 제거, 완전한 통합 모델 구현
- 가속화 기법 적용 → Speculative Decoding을 활용하여 속도 최적화
- 추론 과정 통합 → 증거 생성 외에도 질의 분해, 출처 추적 등의 기능 추가
➡️ RetroLLM은 기존 RAG 및 GR 연구에서 중요한 전환점을 제공하며, 향후 RAG 기반 LLM 연구의 핵심 기술로 자리 잡을 가능성이 높다.
RetroLLM 방법론
RetroLLM은 검색(Retrieval)과 생성(Generation)을 통합하여 하나의 자동회귀(autoregressive) 디코딩 과정에서 수행하는 새로운 프레임워크이다. 이를 통해 기존 RAG(Retrieval-Augmented Generation) 방식에서 발생하는 추가적인 검색 비용, 토큰 낭비, 검색과 생성의 최적화 문제 등을 해결한다.
1. RetroLLM의 핵심 개념
RetroLLM은 크게 3단계로 이루어진다:
- 단서(Clue) 생성: 모델이 스스로 중요한 키워드(단서)를 예측하여 관련 문서의 검색 범위를 줄임.
- 증거(Evidence) 생성: 검색된 문서에서 필요한 정보를 선택하여 답변을 구성.
- 최종 답변(Answer) 생성: 증거를 바탕으로 최종 응답을 생성.
기존 RAG와의 차이점은 별도의 검색기(retriever)를 사용하지 않고, 모델이 직접 검색과 생성을 하나의 과정에서 처리한다는 점이다.
2. RetroLLM의 주요 기법
2.1 계층적 FM-Index를 활용한 검색 제약
RetroLLM은 검색 과정을 계층적으로 두 단계로 나누어 실행한다.
🔹 (1) 기존 검색 방식과의 차이점
- 기존 RAG는 독립적인 검색기(Dense Retriever, BM25 등)를 사용하여 관련 문서를 가져옴.
- 하지만 이렇게 검색된 문서는 필요 없는 내용까지 포함되어 토큰 낭비가 발생.
- RetroLLM은 FM-Index라는 데이터 구조를 활용하여 검색 공간을 줄이고, 검색 과정 자체를 모델 내부에서 처리함.
🔹 (2) FM-Index란?
FM-Index는 Burrows-Wheeler Transform(BWT) 기반의 효율적인 검색 구조이다.
- 일반적인 검색 방식보다 메모리 사용량이 적고, 빠르게 특정 문자열을 찾을 수 있음.
- 이를 활용해 전체 문서에서 특정 단어가 어디에 등장하는지 바로 확인 가능.
- RetroLLM에서는 이 기법을 활용해 검색 공간을 축소하고, 더 정밀한 검색을 수행.
🔹 (3) RetroLLM에서 계층적 FM-Index의 역할
RetroLLM은 두 개의 FM-Index를 사용하여 검색 과정을 최적화한다:
- 코퍼스(Corpus)-레벨 FM-Index
- 전체 문서에서 관련 단서를 추출하는 역할.
- 예: “아인슈타인의 상대성이론이 언제 발표되었나?”라는 질문이 들어오면, "상대성이론", "발표", "아인슈타인" 등의 단서를 추출하여 관련 문서를 찾음.
- 문서(Document)-레벨 FM-Index
- 코퍼스에서 선택된 문서 중 정확한 증거 문장을 찾는 역할.
- 예: "1905년에 발표됨"이라는 문장이 포함된 문서를 선택.
2.2 단서(Clue) 생성 및 문서 점수화
RetroLLM의 강점 중 하나는 검색을 단순히 단어 매칭이 아니라 "의미적으로 중요한 단서"를 기반으로 수행한다는 점이다.
🔹 (1) 단서 생성 (Clue Generation)
- 기존 RAG 방식에서는 질문과 비슷한 문서를 그대로 검색하지만, RetroLLM은 질문에서 핵심 단서를 먼저 추출함.
- 예제:
- 질문: "아인슈타인의 상대성이론이 언제 발표되었나?"
- 생성된 단서: "<|clue|> 상대성이론 <|sep|> 아인슈타인 <|/clue|>"
이렇게 생성된 단서를 바탕으로 불필요한 문서를 걸러내고, 검색 정확도를 높인다.
🔹 (2) 문서 점수화(Document Scoring)
- 단서를 활용하여 가장 적합한 문서에 점수를 부여함.
- 점수화 방법:
- 문서에 포함된 단서 개수 (더 많은 단서를 포함할수록 높은 점수)
- 단서의 희소성 (TF-IDF 활용) (흔하지 않은 단서를 포함할수록 높은 점수)
- 문서 간 랭킹 조정 (Reciprocal Rank Fusion, RRF)
2.3 미래 예측 기반 제약 디코딩 (FCD, Forward-Looking Constrained Decoding)
RetroLLM의 가장 혁신적인 기술 중 하나는 미래를 예측하는 디코딩 전략이다.
🔹 (1) False Pruning 문제
- 기존 RAG 방식에서는 초기에 잘못된 토큰을 선택하면 정확한 증거를 생성할 수 없는 문제(false pruning)가 발생.
- 예: 질문이 "최초의 노벨 물리학상 수상자는 누구인가?"일 때,
- 기존 방식에서는 "최초의 수상자"라는 단어만 보고 검색을 수행하다가 잘못된 정보를 검색할 가능성이 있음.
🔹 (2) 미래 예측 디코딩 기법
- RetroLLM은 미래에 등장할 가능성이 높은 단어 창(future windows)을 예측하여 디코딩을 수행.
- 이를 통해 초기 디코딩 단계에서 잘못된 선택을 방지하고, 보다 정확한 증거를 생성.
예제
- 기존 방식
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- 기존 방식: "최초의 노벨 물리학상 수상자는..." → "1901년"을 먼저 생성 (오답 유도)
- RetroLLM 방식
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- 미래 예측: "1901년"보다는 "빌헬름 뢴트겐"이 더 적절한 단어임을 고려하여 "수상자는 빌헬름 뢴트겐"을 먼저 생성.
2.4 검색된 증거의 양을 동적으로 조절
- 기존 방식은 고정된 개수의 문서를 검색하여 입력으로 사용.
- RetroLLM은 질문에 따라 검색된 증거의 개수를 동적으로 조절하여 불필요한 검색 비용을 줄이고, 필요한 정보만 활용.
예제:
- 간단한 질문 → 1~2개의 증거 문서만 필요
- 복잡한 멀티 홉 질문 → 최대 10개의 증거 문서를 활용
3. RetroLLM의 전체 프로세스
- 단서(Clue) 생성: 질문에서 핵심 키워드를 추출하여 검색 공간을 줄임.
- FM-Index 기반 검색: 코퍼스-레벨 → 문서-레벨 FM-Index를 사용하여 증거를 찾음.
- 미래 예측 기반 디코딩: 토큰을 예측하여 더 정확한 증거를 생성.
- 최종 답변 생성: 필요할 만큼의 증거를 모으면 답변을 생성.
4. 결론: 왜 RetroLLM이 우수한가?
✅ 독립적인 검색기가 필요 없음 → 비용 절감
✅ 토큰 낭비 감소 → 필요한 정보만 활용
✅ 검색과 생성의 통합 → 더 자연스러운 답변 생성
✅ 미래 예측 기반 디코딩 → 잘못된 검색(환각) 문제 해결
➡ RetroLLM은 기존 RAG 방식의 한계를 극복한 혁신적인 검색-생성 통합 모델로, 검색의 효율성과 생성의 정확성을 동시에 향상시키는 강력한 방법론이다.
그렇다! RetroLLM의 핵심 아이디어는 LLM이 특정 단어나 문구(단서, Clue)를 먼저 생성한 후, 이 단서가 포함된 문서(또는 문서의 특정 부분)를 찾고, 이를 바탕으로 더 정밀한 증거를 추출하는 방식이다.
RetroLLM의 검색 방식 정리
- LLM이 단서(Clue)를 생성
- 입력 질문을 보고, 핵심적인 단어를 예측하여 단서로 사용.
- 예제:
- 질문: "아인슈타인의 상대성이론이 언제 발표되었나?"
- 생성된 단서: "<|clue|> 상대성이론 <|sep|> 아인슈타인 <|/clue|>"
- 단서를 바탕으로 FM-Index를 사용해 문서 검색
- 문서 전체에서 단서가 포함된 청크(문서 부분)를 빠르게 찾아냄.
- FM-Index 활용:
- 검색 공간을 줄이기 위해 코퍼스 전체가 아닌 일부 문서만 선택.
- 기존 RAG처럼 top-k 문서를 가져오는 것이 아니라, 문서 내에서도 특정 청크(문서 조각)를 검색.
- 문서를 고를 때 TF-IDF 기반 점수 활용
- 특정 단서가 포함된 문서들 중에서 가장 관련성이 높은 문서를 선정.
- 점수 계산 방법 (TF-IDF 변형):
- 특정 문서에서 단서(Clue)가 많이 등장할수록 가중치 증가.
- 해당 단서가 코퍼스 전체에서 희귀할수록 가중치 증가.
- (TF-IDF와 유사한 개념 적용)
- 세부적인 증거 추출
- 선택된 문서에서 다시 FM-Index를 활용해, 가장 중요한 문장(증거)을 추출.
- 기존 RAG는 문서 전체를 입력으로 사용하지만, RetroLLM은 필요한 문장만 추출하여 입력 토큰을 절약.
- 미래 예측(FCD) 기반 디코딩으로 최적의 답변 생성
- 모델이 앞으로 등장할 가능성이 높은 단어를 고려하여 증거 생성.
- 이를 통해 초기 토큰 선택 실수를 줄이고, 검색된 증거가 최적의 답변과 연결되도록 조정.
예제 1: 노벨 물리학상 수상자 찾기
🔹 기존 방식 (일반 RAG)
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- RAG 검색: "최초의 노벨상" 관련 문서를 가져옴 (하지만 범위가 넓음).
- 생성 모델이 "1901년", "스웨덴" 등을 언급하지만, 필요한 정보(수상자명)가 명확하지 않음.
🔹 RetroLLM 방식
- 단서 생성:
- "<|clue|> 노벨 물리학상 <|sep|> 최초 <|/clue|>"
- FM-Index로 검색:
- "노벨 물리학상"과 "최초"가 포함된 문서를 찾음.
- 문서에서 "1901년 노벨 물리학상"과 관련된 문장 발견.
- TF-IDF 점수로 문서 선택:
- 가장 희귀한 단어("물리학상", "1901년")를 포함한 문서가 높은 점수를 받음.
- 미래 예측 디코딩(FCD) 적용:
- "1901년" 다음에 나올 가능성이 높은 단어가 "빌헬름 뢴트겐"임을 파악.
- 최종 답변:
- "최초의 노벨 물리학상 수상자는 빌헬름 뢴트겐이다."
예제 2: 상대성이론 발표 시기
🔹 기존 방식 (일반 RAG)
- 질문: "아인슈타인의 상대성이론이 언제 발표되었나?"
- RAG 검색: "상대성이론"이 포함된 문서를 가져오지만, 2005년 논문, 1916년 일반 상대성이론 등 여러 정보가 혼재됨.
- 모델이 정확한 발표 시점을 명확하게 선택하지 못함.
🔹 RetroLLM 방식
- 단서 생성:
- "<|clue|> 상대성이론 <|sep|> 발표 <|sep|> 아인슈타인 <|/clue|>"
- FM-Index 검색:
- "상대성이론", "발표", "아인슈타인"이 함께 포함된 문서를 검색.
- "1905년 발표", "1916년 일반 상대성이론 출판" 등의 정보를 포함한 문서 선택.
- TF-IDF 기반 점수화:
- "1905년"과 "발표"가 함께 있는 문서가 높은 점수를 받음.
- 미래 예측 디코딩(FCD) 적용:
- 모델이 "1905년" 다음에 나올 가능성이 높은 단어가 "특수 상대성이론"임을 파악.
- 최종 답변:
- "1905년, 아인슈타인은 특수 상대성이론을 발표했다."
RetroLLM의 강점 요약
✅ 검색과 생성을 하나의 과정에서 수행 → 별도의 retriever 없이 LLM이 직접 검색 & 생성
✅ FM-Index 기반 검색으로 검색 속도 향상 → 전체 문서가 아니라 필요한 청크만 검색
✅ TF-IDF 기반 문서 선택으로 관련성 향상 → 불필요한 정보 제거, 적절한 문서 선택
✅ 미래 예측 기반 디코딩(FCD) 적용 → 잘못된 토큰 선택 방지 & 최적의 답변 유도
✅ 입력 토큰 절약 → 필요한 정보만 포함하여 모델의 연산량 감소
➡ 결과적으로, RetroLLM은 기존 RAG보다 더 정확하고 효율적인 검색-생성 통합 모델이다.
네, 정확히 이해했어! RetroLLM의 미래 예측 기반 제약 디코딩(FCD, Forward-Looking Constrained Decoding)은 기존 방식과 비교했을 때 검색할 단어를 더 전략적으로 선택하고, 디코딩 과정에서 미래 토큰의 적절성을 평가하는 것이 핵심 차이점이야.
1. 기존 RAG 방식과 FCD(미래 예측 기반 제약 디코딩)의 차이
🔹 기존 RAG 방식
- 질문을 그대로 검색 쿼리로 사용
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- 기존 방식: "최초", "노벨상", "물리학상", "수상자" 같은 키워드를 검색.
- 문제점:
- 검색 결과에 불필요한 정보가 포함될 수 있음.
- 예: "노벨상 최초 여성 수상자", "노벨 화학상 첫 수상자" 같은 다른 카테고리의 정보가 함께 검색됨.
- 이렇게 불필요한 정보가 많아지면 LLM이 최적의 답변을 만들기 어려워짐.
- 검색된 문서를 그대로 입력하고 답변 생성
- 검색된 문서를 전부 입력하여 답변을 생성하므로 입력 토큰이 낭비됨.
- 검색된 정보가 많으면 모델이 어떤 정보를 선택해야 할지 혼란스러움.
- 일부 경우에는 검색된 문서의 내용을 그대로 복사하는 할루시네이션(환각) 문제가 발생할 수 있음.
🔹 RetroLLM의 미래 예측 기반 제약 디코딩(FCD)
RetroLLM은 검색할 단어를 더 전략적으로 선택하고, 디코딩 과정에서 미래의 단어가 답변에 적절한지를 평가하는 방식이야.
- 검색할 단어(단서)를 전략적으로 선택
- 질문에서 단순히 포함된 단어가 아니라 가장 중요한 단서(Clue) 단어를 생성함.
- 예제:
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- 기존 방식: "최초", "노벨상", "물리학상", "수상자"
- RetroLLM 방식: "<|clue|> 노벨 물리학상 <|sep|> 1901년 <|/clue|>"
- "1901년"이 중요한 이유: "최초"라는 개념을 정확히 반영하는 핵심 단어이기 때문!
- 즉, RetroLLM은 질문과 직접 연관된 단어뿐만 아니라, 답변에 중요한 정보(연도, 개념 등)를 단서로 추가함.
- 이렇게 하면 검색 범위가 더 좁아지고, 더 정확한 정보만 검색할 수 있음.
- 디코딩 과정에서 미래 단어의 적절성을 평가
- 기존 방식에서는 한 번 선택된 단어가 틀려도 그대로 진행됨.
- RetroLLM은 미래에 등장할 단어의 적절성을 미리 평가하고, 필요하면 디코딩을 조정함.
- 예제:
- 질문: "최초의 노벨 물리학상 수상자는 누구인가?"
- 기존 방식 (일반 RAG):
- "최초의 노벨 물리학상 수상자는..."
- → "1901년"을 먼저 생성함.
- → 그런데 "1901년" 다음이 "수상자는"으로 이어질지, "스웨덴에서 열린..." 같은 부가 정보로 이어질지 모름.
- → 잘못된 방향으로 가면 수정이 어려움.
- RetroLLM 방식:
- "1901년" 다음에 "빌헬름 뢴트겐"이 나올 확률이 높음을 감안하고 디코딩함.
- 만약 "1901년" 이후에 적절한 단어가 아니면 다시 조정 가능.
- 즉, 미래에 올 단어가 적절한지 미리 평가하여, 검색된 증거가 최적의 답변과 연결되도록 조정.
2. RetroLLM이 검색할 단어를 더 전략적으로 선택하는 이유
질문에 포함된 단어 그대로 검색하는 것이 아니라, 답변에 필요한 핵심 개념을 찾아 검색하도록 설계되었기 때문이야.
🔹 기존 방식의 문제점
- 질문에 포함된 단어 그대로 검색하면, 너무 많은 문서가 검색될 수 있음.
- 예를 들어, "아인슈타인의 상대성이론이 언제 발표되었나?" 라는 질문을 보면,
- "상대성이론", "아인슈타인" 같은 단어로 검색하면, 1905년 특수 상대성이론, 1916년 일반 상대성이론, 2005년 논문 재해석 등 너무 많은 정보가 나올 수 있음.
- 이러면 모델이 정확한 정보를 찾기 어려워지고, 잘못된 정보를 답변으로 생성할 위험이 커짐.
🔹 RetroLLM이 해결하는 방법
- LLM이 단서를 먼저 생성하면서 가장 중요한 정보(연도, 인물, 개념 등)를 포함한 단어를 검색하도록 유도.
- 예제:
- 질문: "아인슈타인의 상대성이론이 언제 발표되었나?"
- 기존 방식: "상대성이론", "아인슈타인", "발표"
- RetroLLM 방식: "<|clue|> 상대성이론 <|sep|> 1905년 <|/clue|>"
- 즉, RetroLLM은 검색 시점에서 바로 답변의 방향성을 고려하여 중요한 단어를 검색하도록 유도함.
3. 기존 RAG vs. FCD 기반 RetroLLM 정리
| 기존 RAG | RetroLLM (FCD 적용) | |
| 검색 쿼리 | 질문에 포함된 단어 그대로 사용 | 질문에서 핵심 단서(Clue)만 추출하여 검색 |
| 검색 범위 | 관련 문서를 최대한 많이 가져옴 (불필요한 정보 포함 가능) | 가장 중요한 문서만 검색하여 범위를 좁힘 |
| 증거 선택 | 검색된 문서에서 중요한 문장을 골라 사용 | FM-Index로 검색하여 정확한 증거 문장만 선택 |
| 디코딩 방식 | 초반에 잘못된 단어 선택 시 수정 어려움 | 미래 단어의 적절성을 평가하며 디코딩 진행 |
| 할루시네이션 방지 | 불필요한 정보가 많으면 잘못된 답변 생성 가능 | 가장 관련성이 높은 정보만 검색하여 사용 |
| 토큰 절약 | 많은 문서를 처리해야 하므로 토큰 낭비 | 필요한 정보만 선택하여 입력 토큰 절약 |
4. 결론: FCD의 핵심 장점
✅ 더 전략적인 검색 단어 선택 → 단순한 키워드가 아니라 답변에 중요한 단어를 검색
✅ 불필요한 정보 제거 → 검색된 문서에서 정확한 청크만 선택
✅ 검색과 생성의 연계 강화 → 미래 단어의 적절성을 고려하여 답변 최적화
✅ 토큰 절약 & 성능 향상 → 더 적은 연산량으로 더 정확한 답변 생성
➡ 결국, RetroLLM은 기존 RAG의 문제를 해결하여 더 정확하고, 효율적이며, 신뢰성 높은 답변을 생성하는 새로운 검색-생성 통합 모델이다. 🚀
논문 결과
1. 실험 결과 분석
RetroLLM의 성능을 기존 RAG(Retrieval-Augmented Generation) 기법 및 여러 최신 방법들과 비교한 결과, 검색 성능과 답변 정확도에서 모두 향상된 성과를 보였다.
🔹 (1) 오픈 도메인 QA 데이터셋에서 성능 비교
사용된 데이터셋 (5개):
- 단일 홉 QA: NQ(Natural Questions), TriviaQA, PopQA
- 멀티 홉 QA: HotpotQA, 2WikiMultiHopQA
RetroLLM은 기존 RAG 및 Generative Retrieval(GR) 방법들보다 높은 정확도(F1 Score)를 기록하며, 특히 멀티 홉 QA에서 강한 성능을 보였다.
| 방법 | NQ (F1) | TriviaQA (F1) | HotpotQA (F1) | PopQA (F1) | 2Wiki (F1) |
| Naive RAG | 41.1 | 65.9 | 35.8 | 38.6 | 21.7 |
| Self-RAG | 45.2 | 53.4 | 29.6 | 32.7 | 25.7 |
| IRCoT | 45.9 | 66.1 | 41.5 | 45.6 | 32.4 |
| Iter-RetGen | 48.4 | 69.9 | 39.0 | 47.5 | 21.5 |
| Adaptive-RAG | 46.6 | 65.6 | 39.1 | 40.4 | 28.4 |
| RetroLLM (제안 기법) | 49.8 | 72.8 | 47.2 | 43.0 | 36.2 |
✅ 결과 해석:
- 단일 홉 QA에서 기존 RAG보다 5~10% 높은 성능 (TriviaQA, PopQA 등)
- 멀티 홉 QA(HotpotQA, 2Wiki)에서 더욱 강력한 성능
- RetroLLM은 불필요한 검색을 줄이고, 핵심 증거를 찾아내는 능력이 뛰어남.
- 특히, 멀티 홉 질의에서 검색-생성 최적화의 효과가 더욱 두드러짐.
🔹 (2) 검색 성능 비교 (Recall@1, Recall@5)
- 기존 BM25, Dense Retrieval(E5, BGE) 등과 비교했을 때, RetroLLM이 가장 높은 Recall@1 성능을 보임.
- Recall@1: 질문과 가장 관련 있는 문서를 1위로 검색할 확률이 높아야 함.
- RetroLLM은 평균적으로 5% 이상의 향상을 기록.
| 방법 | NQ (R@1) | TriviaQA (R@1) | HotpotQA (R@1) | PopQA (R@1) | 2Wiki (R@1) |
| BM25 | 24.1 | 49.6 | 31.2 | 39.6 | 22.6 |
| SPLADE-v3 | 45.4 | 58.8 | 32.9 | 47.6 | 22.2 |
| E5 | 55.7 | 61.6 | 32.3 | 51.7 | 21.6 |
| BGE | 50.3 | 58.7 | 33.7 | 50.8 | 21.1 |
| Naive Constrained Search | 13.1 | 23.0 | 11.8 | 10.9 | 9.4 |
| RetroLLM (제안 기법) | 51.6 | 61.1 | 35.6 | 57.0 | 23.0 |
✅ 결과 해석:
- RetroLLM은 기존 Dense Retriever와 비교하여 더 높은 검색 성능을 보임.
- 특히 Multi-Hop QA에서 Recall@1 향상이 두드러짐 (HotpotQA, 2Wiki).
- Naive Constrained Search는 성능이 크게 낮음 → 단순한 제약 기반 검색 방식이 효과적이지 않음을 시사.
🔹 (3) Ablation Study (세부 기법 제거 실험)
RetroLLM의 주요 구성 요소를 하나씩 제거하고 성능을 비교하여, 각 요소가 얼마나 중요한지 확인했다.
| 구성 요소 제거 | In-Domain (F1) | Out-of-Domain (F1) |
| RetroLLM (완전체) | 56.6 | 39.6 |
| 미래 예측 디코딩(FCD) 제거 | 43.2 | 33.8 |
| 단서(Clue) 생성 제거 | 52.1 | 38.1 |
| 단서 확장(Clue Expansion) 제거 | 45.1 | 35.4 |
| 기본적인 제약 검색 방식 사용 | 28.0 | 20.7 |
| 제약 검색 자체 제거 | 43.0 | 28.1 |
✅ 결과 해석:
- 미래 예측 디코딩(FCD) 제거 시 성능 급락 → False Pruning 문제 해결이 중요한 요소.
- 단서(Clue) 생성과 확장 기능이 없으면 성능 저하 → 적절한 검색 대상 선정이 필수적임.
- 제약 검색을 사용하지 않으면 성능이 크게 낮아짐 → 검색된 정보의 품질이 전체 성능에 큰 영향을 미침.
2. 결론
논문에서는 RetroLLM이 기존 RAG 및 Generative Retrieval(GR) 방법의 한계를 해결하고, 검색과 생성을 하나의 과정에서 최적화하는 새로운 방식을 제안했다.
🔹 연구의 주요 기여점
- 검색과 생성을 통합한 새로운 프레임워크 제안
- 기존 RAG는 검색과 생성을 별개로 다루었으나, RetroLLM은 LLM 자체가 검색을 수행하도록 설계.
- FM-Index 기반 검색과 미래 예측 디코딩을 결합하여 검색의 정확성을 높임.
- 미래 예측 기반 제약 디코딩(FCD) 도입
- 기존 방식의 False Pruning 문제를 해결하여, 초기 디코딩 단계에서 잘못된 선택을 방지.
- 이를 통해 검색된 증거가 최적의 답변과 연결되도록 조정.
- 단서(Clue) 기반 검색으로 불필요한 정보 제거
- 검색 과정에서 질문의 모든 단어를 활용하는 것이 아니라, 가장 중요한 단서(핵심 키워드)만 선택하여 검색.
- 이를 통해 검색 범위를 줄이고, 더욱 정확한 증거를 선택할 수 있음.
- 토큰 소비량 절감 및 검색 속도 향상
- 기존 RAG 대비 평균 2~6배 적은 토큰을 사용하여 더 효율적인 검색 및 생성이 가능.
3. 한계 및 향후 연구 방향
🔹 한계점
- 단서(Clue) 생성의 완전한 자동화 부족
- 현재는 LLM이 단서를 생성하지만, 일부 경우에는 추가적인 확장이 필요할 수도 있음.
- 응답 속도 최적화 필요
- 미래 예측 기반 디코딩은 높은 성능을 보장하지만, 추론 속도가 다소 증가할 가능성이 있음.
🔹 향후 연구 방향
- 더 빠른 디코딩 기법 적용
- Speculative Decoding을 활용하여 응답 속도를 더욱 향상.
- End-to-End 최적화
- 단서 확장 과정(SPLADE-v3 적용)을 제거하고, 모델이 스스로 최적의 단서를 찾도록 개선.
✅ 결론적으로, RetroLLM은 기존 RAG 방식의 한계를 극복하고, 검색-생성 통합 모델의 새로운 패러다임을 제시하는 연구이다. 🚀
Hierarchical FM-Index (계층적 FM-Index) 이해하기
1. FM-Index란? (기본 개념)
FM-Index는 Burrows-Wheeler Transform(BWT) 기반의 효율적인 문자열 검색 기법이다.
일반적인 검색 방식(예: BM25, Dense Retriever)과 달리, FM-Index는 특정 단어나 구문이 포함된 부분을 빠르게 찾을 수 있도록 설계된 데이터 구조이다.
2. 기존 FM-Index 기반 검색의 문제점
- FM-Index를 검색에 적용할 때, 초기에 잘못된 토큰을 선택하면(False Pruning) 이후 증거 생성 과정에서 엉뚱한 정보를 가져올 수 있음.
- 특히, 대규모 코퍼스에서 검색을 수행하면 초반의 선택지가 너무 많아(검색 공간이 큼) 최적의 결과를 찾기가 어려움.
3. Hierarchical FM-Index의 개념
Hierarchical FM-Index(계층적 FM-Index)는 검색 공간을 단계적으로 축소하여 더 정밀한 검색을 수행하는 방식이다.
RetroLLM에서는 FM-Index를 두 단계(Hierarchical)로 나누어 적용하여 검색 성능을 개선한다.
🔹 (1) 기존 방식 (일반 FM-Index)
- 코퍼스 전체에서 검색을 수행 → 검색 공간이 너무 큼.
- 잘못된 문서를 선택하면 디코딩 과정에서 올바른 증거를 생성하기 어려움.
- False Pruning 문제 발생 가능성이 높음.
🔹 (2) 계층적 FM-Index (Hierarchical FM-Index)
RetroLLM에서는 FM-Index를 계층적으로 적용하여 검색 범위를 줄이는 전략을 사용한다.
검색 과정은 두 단계(Hierarchical)로 구성된다.
① 1단계: 코퍼스-레벨 FM-Index (Corpus-Level FM-Index)
- 전체 코퍼스에서 관련 문서를 찾는 단계
- 질문에서 핵심 단서(Clue)를 생성하여, 검색 범위를 먼저 좁힘.
- FM-Index를 활용하여 단서(Clue)가 포함된 문서들의 서브셋(Subset)을 선정.
- 즉, 모든 문서를 검색하는 것이 아니라, 가장 가능성이 높은 문서만 후보로 선택.
② 2단계: 문서-레벨 FM-Index (Document-Level FM-Index)
- 선택된 문서 내에서 관련 증거를 찾는 단계
- 1단계에서 선택된 문서들 중에서 가장 관련성이 높은 문장을 다시 검색.
- 문서 내에서 미래에 등장할 가능성이 높은 단어(Forward-Looking)와 연결되는 청크(Chunk)를 선택하여 증거 생성.
4. Hierarchical FM-Index의 동작 방식 예제
질문: "최초의 노벨 물리학상 수상자는 누구인가?"
🔹 (기존 FM-Index 방식)
- 전체 코퍼스에서 "노벨 물리학상" 검색
→ 관련 없는 정보까지 너무 많이 검색됨. - 디코딩 과정에서 "1901년"이라는 단어가 먼저 생성될 가능성이 높음.
→ 그러나 이후 문장이 "1901년 최초 여성 노벨상 수상자"처럼 엉뚱한 내용으로 이어질 수도 있음.
🔹 (Hierarchical FM-Index 방식)
- 1단계: 코퍼스-레벨 FM-Index
- 질문에서 핵심 단서(Clue) 생성: "<|clue|> 노벨 물리학상 <|sep|> 1901년 <|/clue|>"
- FM-Index를 활용해 "노벨 물리학상"과 "1901년"이 동시에 포함된 문서를 우선 선택.
- → 불필요한 문서가 검색되는 것을 방지.
- 2단계: 문서-레벨 FM-Index
- 선택된 문서에서 1901년과 관련된 부분(청크, Chunk)만 다시 검색.
- → "최초의 노벨 물리학상 수상자는 빌헬름 뢴트겐이다." 라는 정확한 증거 생성 가능.
5. Hierarchical FM-Index의 장점
✅ 검색 범위 축소 → 검색 공간을 단계적으로 축소하여 정확한 문서만 선택
✅ False Pruning 방지 → 초반에 잘못된 문서를 선택하는 오류를 줄임
✅ 증거 정확도 향상 → 문서 내부에서도 가장 중요한 부분만 선택
✅ 토큰 절약 → 불필요한 정보를 제거하여 입력 토큰을 최적화
6. 결론
- 기존 FM-Index 기반 검색 방식은 너무 많은 문서를 검색하고, 초기에 잘못된 선택을 하면 올바른 증거를 생성하기 어려운 문제(False Pruning)가 발생함.
- RetroLLM은 이를 해결하기 위해 검색을 두 단계(Hierarchical)로 나누어 실행하는 FM-Index 기반 검색 방식을 도입.
- 코퍼스-레벨에서 먼저 문서를 선정하고, 이후 문서-레벨에서 세부적인 증거를 찾는 방식으로 검색 효율성을 극대화함. 🚀