https://arxiv.org/abs/2501.02772
GeAR: Generation Augmented Retrieval
Document retrieval techniques form the foundation for the development of large-scale information systems. The prevailing methodology is to construct a bi-encoder and compute the semantic similarity. However, such scalar similarity is difficult to reflect e
arxiv.org
현재 존재하는 Bi-Encoder를 통한 유사도 계산은 정보를 충분히 반영하기 어렵고, 이해하기도 어렵다. 또한 세부적인 의미 관계도 무시된다.
Generation Augmented Retrieval(GeAR)을 통해 쿼리 문서 퓨전 표련으로 텍스트 생성, 세분화된 정보에 집중하는 방법을 학습

뭔가 세분화된 RAG인 것 같아 보이네요

대조학습을 하는 것은 일반적인 Embedding 모델과 비슷하네요
Doc인코더는 Doc만을 위한 인코더이고, Query 인코더는 Fusion 인코더로도 사용됩니다.
Text Decoder는 Fusion Encoder를 통해 정보를 생성합니다.

여기서도 Loss를 단순히 합쳐서 모델을 업데이트하네요

테스트 결과 높은 성능을 가지는 것을 볼 수 있다.
SBERT와 BGE는 문서와 쿼리간 의미적 유사도를 최저고하하는 데만 초점을 맞추고 세부적인 의미 관계를 무시하기에 최적이 아닌 성능을 보이는 것으로 관찰된다.
GeAR은 End to End 학습 과정을 통해 쿼리와 세부적으로 정렬된 문서를 검색할 수 있고, 세분화된 정보에 효과적으로 대처할 수 있었다.
대조학습만 진행한 모델은 검색성능이 조금 더 높지만 이 부분은 해결해야 할 문제이다 .

시각화를 통해 높은 Weight를 가진ㄴ 토큰을 볼 수 있다.
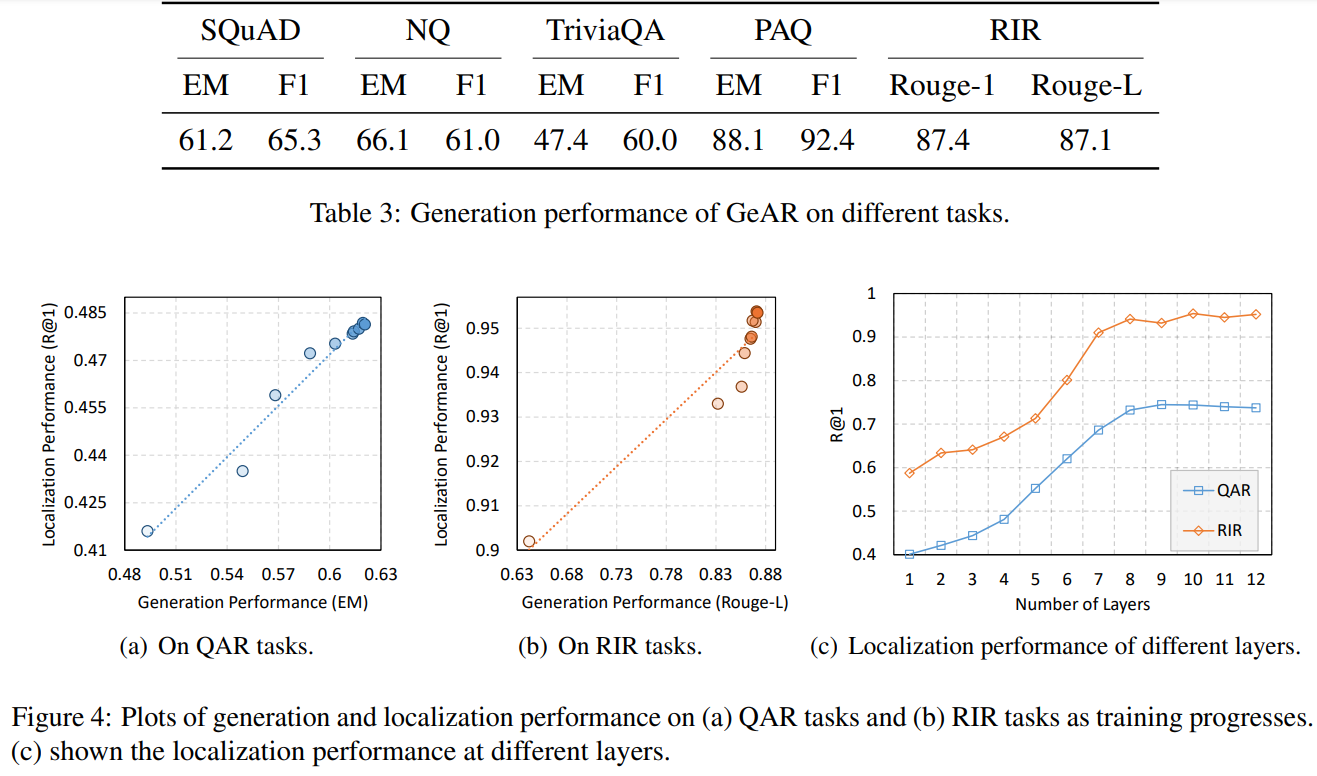
표3을 통한 생성 능력은 PAQ와 RIR과 같은 훈련데이터와 유사한 분포를 가진 테스트 세트에선 강력한 성능을 보여준다.

음 모델이 조금 많이 쓰여서 제가 만들고 싶었던 것이랑은 조금 다르긴 하지만 그래도 이것으로 진행이 된다면 한번 쯤은 고민해볼 만한 논문이네요
| 📖 연구 배경 | - 기존 문서 검색 모델 (bi-encoder 기반)은 문서와 쿼리를 벡터화하여 단순한 스칼라 유사도 비교를 수행. - 하지만 이러한 방식은 문서 내에서 정확한 정보가 어디에 있는지 알 수 없으며, 검색 결과를 해석하기 어려움. - 특히 긴 문서(256~512 토큰 이상)의 경우, 쿼리와 관련된 특정 정보를 찾는 것이 어려운 한계 존재. |
| 🛠️ 연구 목표 | ✅ 검색 성능을 유지하면서도 문서 내에서 쿼리와 가장 관련된 정보를 찾아낼 수 있는 모델 개발. ✅ 검색 결과를 더 해석 가능하도록 하기 위해, 검색된 문서에서 관련 내용을 생성하는 기능 추가. ✅ 기존 bi-encoder 방식의 검색 모델과 비교하여 연산 부담을 증가시키지 않으면서도 성능 향상. |
| 📌 주요 기여 (Contribution) | 1️⃣ 검색 + 정보 생성 결합 → 단순한 검색이 아닌, 검색된 문서에서 가장 중요한 정보를 자동으로 찾아 생성 가능. 2️⃣ 세밀한 정보 검색 능력 향상 → 기존 검색 모델이 문서 전체를 하나의 벡터로 처리하는 것과 달리, 문서 내 특정 문장을 찾아 강조 가능. 3️⃣ 연산 효율성 유지 → 기존 bi-encoder와 동일한 연산 비용으로 작동하면서도 추가적인 정보 제공. |
| 🔍 모델 구성 | GeAR는 3가지 주요 모듈로 구성됨. ✅ Bi-Encoder → 쿼리와 문서를 각각 벡터화하여 검색 수행 (기본 검색 기능). ✅ Fusion Encoder → 문서 내에서 쿼리와 가장 관련된 문장을 찾아 강조 (세밀한 정보 탐색). ✅ Text Decoder → 검색된 문서에서 관련 내용을 요약하거나 직접 생성 (정보 생성). |
| 📊 실험 데이터셋 | ✅ 질문-응답 검색 (QAR) → PAQ(30M), SQuAD, NQ, TriviaQA. ✅ 관련 정보 검색 (RIR) → 위키피디아에서 LLM을 활용해 5.8M 데이터 자동 생성. |
| 🧑🏫 학습 방법 | - Contrastive Learning (대조 학습): Bi-Encoder에서 쿼리와 문서 간 유사도 최적화. - Language Modeling (언어 모델링): Fusion Encoder와 Text Decoder가 문서 내에서 중요한 정보를 학습하고 생성 가능하도록 훈련. - 16개 GPU 사용, AdamW 옵티마이저, Cosine Learning Rate Scheduler 적용. |
| 📌 실험 결과 (1) - 문서 검색 성능 | ✅ GeAR는 기존 검색 모델(SBERT, E5, BGE, GTE) 대비 모든 데이터셋에서 성능 우수. ✅ 특히 PAQ 및 RIR 데이터셋에서 기존 대비 +5~10% 향상 (Recall@5 기준). |
| 📌 실험 결과 (2) - 세밀한 정보 탐색 성능 | ✅ GeAR는 문서 내에서 정확한 문장을 찾아내는 능력이 뛰어남. ✅ 기존 검색 모델이 문서 전체의 유사도만 평가하는 반면, GeAR는 문서 내 특정 문장을 찾아 강조 가능. ✅ NQ 및 PAQ 데이터셋에서 기존 모델 대비 +20% 이상 향상. |
| 📌 실험 결과 (3) - 정보 생성 성능 | ✅ 기존 검색 모델과 달리, GeAR는 검색된 문서에서 관련 내용을 자동으로 생성 가능. ✅ 질문-응답(QA) 데이터셋에서 F1 Score 및 Exact Match(EM) 성능 우수. ✅ 특히 PAQ 및 RIR 데이터셋에서 높은 정확도를 보이며, 검색 결과의 해석 가능성을 극대화. |
| 🎯 결론 (Conclusion) | 🔹 GeAR는 검색과 생성의 결합을 통해 기존 검색 모델의 한계를 극복한 혁신적인 모델. 🔹 기존 검색 모델이 단순히 관련 문서를 반환하는 것과 달리, GeAR는 검색된 문서에서 가장 중요한 정보를 자동으로 찾아내고 생성 가능. 🔹 웹 검색, 법률 문서 분석, 논문 검색 등 다양한 응용 가능성 존재. |
| 🚀 향후 연구 방향 | ✅ 긴 문서 검색 지원 (Long Context Retrieval) → 512 토큰 이상의 문서를 효과적으로 검색할 수 있도록 확장 연구 필요. ✅ 멀티모달 검색 (Multi-Modal Retrieval) → 이미지, 비디오, 음성 데이터까지 확장 가능. ✅ 검색과 생성의 최적화 (Retrieval-Generation Trade-off) → 검색 성능을 유지하면서도 생성된 정보의 품질을 높이는 방향으로 연구 필요. |
📌 마무리 요약
✅ GeAR는 기존 검색 모델이 제공하지 못했던 "문서 내 중요한 정보 식별 및 생성" 기능을 추가한 검색 모델이다.
✅ 기존 bi-encoder 방식의 검색 모델과 동일한 연산 비용을 유지하면서도 더 정교한 검색 결과 제공 가능.
✅ 검색 + 생성 기능을 결합하여 검색 결과의 해석 가능성을 극대화.
✅ 웹 검색, 논문 검색, 법률 문서 분석 등 다양한 분야에서 활용 가능.
✅ 향후 긴 문서 검색, 멀티모달 검색, 검색과 생성 최적화 연구 등이 진행될 예정.
논문 요약: GeAR (Generation Augmented Retrieval)
1. 연구 배경 및 문제 정의
1.1 기존 문서 검색 시스템의 한계
- 대규모 정보 시스템에서는 문서 검색(retrieval) 기술이 필수적이다.
- 현재 대부분의 문서 검색 시스템은 bi-encoder 방식을 사용하여 쿼리(query)와 문서를 각각 벡터로 변환한 후, 벡터 간의 유사도 계산을 통해 검색을 수행한다.
- 하지만 이러한 방식에는 다음과 같은 한계가 있다:
- 스칼라 유사도 점수의 한계: 쿼리와 문서의 복잡한 의미적 관계를 단순한 스칼라 값(유사도 점수)로 표현하는 것은 정보량이 부족하다.
- 세밀한 정보 매칭 부족: 긴 문서(256~512 토큰 이상)의 경우, 쿼리와 가장 관련성이 높은 특정 부분을 식별하는 것이 어렵다.
- 전반적인 의미 중심의 최적화: bi-encoder 모델은 전체 문서와 쿼리 간의 의미적 유사성만을 학습하며, 문서 내 특정 문장이 중요한지를 고려하지 않는다.
1.2 연구 목표
- 기존 검색 모델이 가지는 단점을 보완하고자, GeAR (Generation Augmented Retrieval) 기법을 제안.
- 문서 검색 모델이 단순히 검색 결과를 반환하는 것뿐만 아니라, 세밀한 정보(localized information)를 제공하고 생성(generation)까지 수행할 수 있도록 개선.
2. GeAR (Generation Augmented Retrieval) 방법론
2.1 개요
GeAR는 생성(generation)과 검색(retrieval)을 통합한 모델로, 쿼리-문서-세부정보(query-document-information) 트리플을 학습하여 세밀한 정보 검색 및 생성 능력을 강화한다.
2.2 주요 구성 요소
GeAR는 세 가지 주요 모듈로 구성됨:
- Bi-Encoder:
- 기존의 검색 모델과 동일하게, 쿼리와 문서를 벡터로 변환.
- 대조 학습(contrastive learning)을 사용하여 검색 성능을 최적화.
- Fusion Encoder:
- 쿼리와 문서의 의미적 융합을 수행하는 인코더.
- Cross-Attention을 활용하여 쿼리와 문서 간의 관계를 강화.
- Text Decoder:
- 문서 내에서 쿼리와 관련성이 높은 정보를 생성.
- Unidirectional causal attention을 사용하여 문장 생성을 수행.
3. 데이터 생성 및 학습 방법
3.1 데이터 생성
- GeAR의 학습을 위한 고품질 데이터셋을 생성하기 위해 대형 언어 모델(LLM)을 활용.
- 두 가지 검색 시나리오를 고려:
- 질문-응답 검색(QAR, Question Answer Retrieval):
- 특정 질문을 기반으로, 관련 문서와 답변이 포함된 세부 문장을 검색.
- 관련 정보 검색(RIR, Relevant Information Retrieval):
- 키워드 기반 검색을 수행하고, 가장 관련성이 높은 문서 및 문장 단위를 검색.
- 질문-응답 검색(QAR, Question Answer Retrieval):
- 데이터셋 생성 과정:
- 고품질 위키피디아 문서를 선택.
- 문서 내 특정 문장을 샘플링하여, 대형 언어 모델(LLM)을 활용하여 쿼리로 변환.
- 중복 제거 및 유사도 필터링을 수행하여 최종 5.8M 개의 트리플 데이터를 구축.
3.2 학습 목표
GeAR 모델은 두 가지 목표를 최적화함:
- 대조 학습 손실 (Contrastive Learning Loss, CL)
- 기존 bi-encoder 모델과 동일하게 쿼리와 문서 간의 의미적 유사성을 학습.
- 언어 모델링 손실 (Language Modeling Loss, LM)
- Text Decoder를 활용하여 문서 내 세밀한 정보(fine-grained information)를 생성.
- 문서와 쿼리의 융합 표현을 학습하여, 단순한 검색 결과 반환이 아니라 맥락적으로 관련된 문장까지 생성할 수 있도록 유도.
최종 손실 함수:
LGeAR=LCL+LLML_{\text{GeAR}} = L_{\text{CL}} + L_{\text{LM}}
4. 실험 및 성능 평가
4.1 실험 데이터셋
- QAR (질문-응답 검색): PAQ(30M), SQuAD, NQ, TriviaQA.
- RIR (관련 정보 검색): 5.8M 개의 합성 데이터.
4.2 비교 모델
- 사전 학습된 검색 모델: SBERT, E5, BGE, GTE.
- 재학습된 검색 모델: SBERT (재학습), BGE (재학습).
- GeAR 및 변형 모델: GeAR, GeAR (LLM 없이 학습).
4.3 실험 결과
4.3.1 문서 검색 성능
- GeAR는 기존 검색 모델(SBERT, E5, BGE)보다 우수한 성능을 달성.
- 기존 bi-encoder와 동일한 비용을 유지하면서, 성능 향상을 이룸.
4.3.2 세밀한 정보 탐색(Localization)
- GeAR는 검색된 문서 내에서 가장 관련성이 높은 문장을 잘 찾아냄.
- 기존 검색 모델이 단순한 유사도 비교만 수행하는 반면, GeAR는 cross-attention을 활용하여 더 정확한 정보 추출.
4.3.3 정보 생성(Generation)
- GeAR의 Text Decoder는 관련 문장을 자동 생성하여, 검색된 정보의 해석 가능성을 높임.
- 질의응답(QA) 성능 평가 (EM, F1 Score)에서도 우수한 성능을 보임.
5. 결론 및 향후 연구 방향
5.1 결론
- GeAR는 검색과 생성의 융합을 통해 검색 모델의 한계를 극복.
- 문서 검색뿐만 아니라 검색된 정보의 세밀한 분석 및 생성까지 수행하여, 검색 결과의 해석 가능성을 향상.
- 기존 bi-encoder 방식과 비교하여 추가적인 연산 비용 없이 성능을 향상.
5.2 한계 및 향후 연구 방향
- 현재 GeAR는 512 토큰 이하의 문서에서만 동작하며, 더 긴 문서 검색을 지원하는 연구가 필요.
- 검색 성능과 생성 성능의 균형 조절이 필요함.
- 다중 모달 검색(이미지, 비디오 검색 등)으로 확장 가능성이 있음.
6. 연구 기여
✅ 기존 검색 모델의 한계를 극복한 GeAR 프레임워크 제안
✅ 검색 + 생성 결합을 통해 검색 결과의 해석 가능성을 향상
✅ LLM을 활용한 데이터 생성 파이프라인 구축
✅ 다양한 데이터셋에서 기존 검색 모델 대비 우수한 성능 달성
📝 연구 적용 가능성 및 미래 연구 방향
- Retrieval-Augmented Generation (RAG) 시스템의 개선
- 웹 검색, 법률 문서 분석, 논문 검색 등에서 활용 가능
- 다중 모달 정보 검색(텍스트+이미지, 텍스트+비디오)으로 확장 연구 가능
📌 GeAR는 검색 모델을 한 단계 발전시키는 접근법으로, NLP 및 AI 연구에서 의미 있는 발전을 이룰 것으로 기대됨! 🚀
GeAR 관련 연구 및 기존 연구와의 차이점 분석
1. 관련 연구
GeAR는 기존 문서 검색 및 정보 검색(IR, Information Retrieval) 모델을 발전시킨 연구로, 여러 기존 연구들과 밀접한 관련이 있다. 크게 두 가지 연구 분야와 관련이 있음.
1.1 임베딩 기반 검색 (Embedding-based Retrieval)
임베딩 기반 검색 기법은 쿼리와 문서를 벡터 공간에 매핑하여 유사도를 계산하는 방식이다. 대표적인 연구들은 다음과 같다.
(1) Word Embedding 기법
- Word2Vec (Mikolov et al., 2013): 단어를 벡터 공간에 매핑하여 의미적 유사성을 학습.
- GloVe (Pennington et al., 2014): 통계적 방법을 활용하여 전역적 단어 표현을 학습.
(2) Transformer 기반 검색 모델
- BERT-based Retrieval (Devlin et al., 2019): 문서와 쿼리를 개별적으로 임베딩하여 검색 수행.
- Dense Passage Retrieval (DPR, Karpukhin et al., 2020): 쿼리와 문서를 별도의 인코더를 통해 벡터화하여 유사도 비교.
- ColBERT (Khattab & Zaharia, 2020): 기존 bi-encoder 모델의 한계를 보완하여 문서의 세밀한 부분까지 비교 가능하도록 개선.
(3) 최신 문서 검색 모델
- SBERT (Reimers & Gurevych, 2019): Siamese BERT를 활용한 문장 검색.
- E5 (Wang et al., 2022): 대량의 텍스트 데이터에서 약한 지도학습(weakly-supervised learning)으로 임베딩 학습.
- BGE (Xiao et al., 2024): 최신 임베딩 모델로, 대규모 문서 검색을 위해 최적화됨.
GeAR와의 차이점
- 기존 연구들은 대부분 bi-encoder 방식으로 문서 전체를 하나의 벡터로 변환하여 검색을 수행하지만, 이는 문서 내 세부 정보를 고려하지 못하는 단점이 있음.
- GeAR는 Fusion Encoder와 Text Decoder를 추가하여 문서 내 세밀한 정보까지 활용 가능.
- 기존 모델은 유사도 점수만 반환하는 반면, GeAR는 검색과 함께 세밀한 정보를 생성할 수 있음.
1.2 정보 로컬라이제이션 (Information Localization)
대규모 문서에서 특정 정보를 정확하게 찾아내는 기술은 NLP에서 중요한 연구 분야 중 하나이다.
(1) 전통적인 정보 검색 모델
- BiDAF (Seo et al., 2016): 질문 응답(QA) 모델로, 문서에서 특정 부분을 하이라이트하여 정답을 예측.
- DrQA (Chen et al., 2017): Wikipedia 기반의 Open-domain QA 모델로, 검색된 문서에서 답변을 찾는 방식.
- Hierarchical Attention Networks (Yang et al., 2016): 문서의 계층적 구조를 반영하여 정보 검색 성능을 개선.
(2) 최근 정보 검색 모델
- Needle-in-a-Haystack (Liu et al., 2024b): 문서 내에서 매우 작은 단위의 중요한 정보를 찾아내는 연구.
- Fine-grained Citation (Gao et al., 2023; Zhang et al., 2024): 논문 내 세밀한 문장 단위의 인용 정보를 제공하는 연구.
GeAR와의 차이점
- 기존 연구는 대부분 문서를 세부 단위(문장, 절)로 나누고 각각 유사도를 계산하는 방식을 사용.
- GeAR는 Fusion Encoder와 Text Decoder를 활용하여 문서 내 세부 정보를 더 정밀하게 추출.
- 기존 정보 검색 모델은 특정 정답을 찾는 데 초점을 맞추지만, GeAR는 관련 정보를 생성할 수 있음.
1.3 생성 기반 검색 (Retrieval-Augmented Generation, RAG)
최근에는 단순한 검색을 넘어서, 검색된 정보를 활용하여 새로운 문장을 생성하는 연구도 활발하다.
(1) RAG (Retrieval-Augmented Generation)
- Lewis et al. (2020): 검색된 문서를 기반으로 텍스트를 생성하는 모델 제안.
- Gao et al. (2024): 대형 언어 모델(LLM)을 활용하여 검색된 정보를 기반으로 응답을 생성하는 연구.
(2) 검색을 활용한 세밀한 정보 생성
- LLM-based Context Utilization (An et al., 2024): LLM이 검색된 정보를 효과적으로 활용하는 연구.
- Multi-Modal Retrieval (Chen et al., 2024): 텍스트뿐만 아니라 이미지, 동영상 검색을 결합하는 연구.
GeAR와의 차이점
- RAG 모델은 일반적으로 문서 전체를 참고하여 텍스트를 생성하지만, GeAR는 문서 내 세밀한 단위까지 고려하여 정보를 생성.
- GeAR는 검색 모델 자체를 개선한 것이므로, 추가적인 생성 모델 없이도 검색 결과의 해석 가능성을 높일 수 있음.
2. 기존 연구와 GeAR의 차이점 요약
GeAR의 주요 차별점은 검색과 생성의 융합이다. 이를 표로 정리하면 다음과 같다.
| 연구 분야 | 기존 연구 | GeAR의 차이점 |
| 임베딩 기반 검색 | Bi-Encoder 방식으로 문서 전체의 의미적 유사도 계산 | Fusion Encoder 도입으로 문서 내 세밀한 정보 학습 |
| 정보 로컬라이제이션 | 문장을 개별적으로 나누어 유사도를 비교 | Cross-Attention을 활용하여 문서 내 특정 정보 자동 탐색 |
| 생성 기반 검색 (RAG) | 검색된 문서를 기반으로 생성 모델이 텍스트 생성 | 검색 과정에서 정보 생성을 동시에 수행 가능 |
3. GeAR의 연구 기여
GeAR는 기존 연구와 차별화된 세 가지 주요 기여를 한다.
- 검색과 생성의 융합 (Retrieval + Generation)
- 기존 검색 모델은 단순히 유사한 문서를 찾는 역할을 했지만, GeAR는 검색된 문서에서 중요한 정보까지 생성.
- 이를 통해 검색된 결과를 더욱 해석 가능하고 유용한 정보로 변환.
- 세밀한 정보 검색 강화 (Fine-grained Information Localization)
- 기존 검색 모델은 문서 전체를 하나의 벡터로 변환하는 방식이었으나, GeAR는 Fusion Encoder와 Text Decoder를 추가하여 문서 내 특정 정보를 더 정밀하게 분석.
- 연산 효율성 유지
- GeAR는 bi-encoder 방식과 동일한 비용으로 동작하면서도 추가적인 정보 생성이 가능.
- 기존 대비 검색 성능이 향상되면서도 추가적인 연산 부담이 크지 않음.
4. 결론 및 향후 연구 방향
- GeAR는 기존 검색 모델의 한계를 극복하고, 검색된 정보의 해석 가능성을 높이는 새로운 접근 방식.
- 검색뿐만 아니라 문서 내에서 가장 중요한 정보를 식별하고, 생성까지 수행할 수 있는 능력을 갖춤.
- 향후 연구 방향:
- 멀티모달 검색 확장 (이미지, 비디오 검색 포함)
- 더 긴 문서 검색 지원 (512+ 토큰 확장)
- 검색과 생성의 최적화 (두 가지 목적의 균형 조절)
📌 GeAR는 검색과 생성의 결합을 통해 정보 검색의 새로운 패러다임을 제시하며, 향후 RAG 및 대형 언어 모델과의 결합 가능성이 높음! 🚀
1. 모델 구성 (Model Architecture)
GeAR는 기존의 bi-encoder 기반 검색 모델을 개선하여 검색과 정보 생성 기능을 통합한 모델이다.
이를 위해 세 가지 주요 모듈로 구성된다:
📌 1.1 Bi-Encoder (기본 검색 기능)
- 기존 bi-encoder 방식과 동일하게, 쿼리와 문서를 개별적으로 벡터로 변환.
- 쿼리와 문서를 벡터화한 후 대조 학습(contrastive learning)을 통해 유사도를 최적화.
- 즉, 기본적인 검색 모델 역할을 수행.
📝 예시
- 검색 엔진에서 "자동차 엔진의 원리"라는 쿼리를 입력하면,
- 각 문서(예: "전기차 모터 vs 내연기관", "엔진 연소 과정 설명")를 벡터로 변환하고,
- 가장 유사한 문서를 찾아 반환.
📌 1.2 Fusion Encoder (문서 내 관련 정보 찾기)
- 쿼리와 문서 간의 의미적 결합을 수행하는 인코더.
- 기존 bi-encoder는 문서를 하나의 벡터로 변환하여 문서 전체를 비교했지만,
Fusion Encoder는 문서 내 개별 문장과의 연관성을 학습. - Cross-Attention을 활용하여 문서 내 가장 관련성이 높은 문장을 강조.
📝 예시
- 검색 결과에서 "엔진 연소 과정 설명" 문서가 선택되었을 때,
- Fusion Encoder는 "연료가 연소 챔버에서 폭발하여 동력을 생성하는 과정" 문장을 자동으로 강조하여 출력.
📌 1.3 Text Decoder (관련 정보 생성)
- 검색된 문서에서 쿼리와 관련된 새로운 정보를 생성.
- 기존 검색 시스템은 단순히 문서 리스트를 반환하지만,
GeAR는 문서 내용을 요약하거나 특정 정보(답변)를 직접 생성. - Transformer 기반 Unidirectional Causal Attention을 사용하여 생성.
📝 예시
- 사용자가 "자동차 엔진의 원리는?"을 검색하면,
- 기존 검색 모델 → "이 문서에서 답을 찾을 수 있습니다."
- GeAR → "자동차 엔진은 연료를 연소시켜 피스톤을 움직이며 동력을 생성하는 방식으로 작동합니다."
📌 1.4 GeAR의 전체적인 동작 방식
- 쿼리를 벡터로 변환 → Bi-Encoder에서 유사도가 높은 문서 검색.
- 문서 내 특정 부분을 식별 → Fusion Encoder로 쿼리와 문서의 관계 학습.
- 답변 또는 요약 생성 → Text Decoder가 관련 정보를 생성.
📝 비유
GeAR는 기존 검색 모델이 단순히 "관련 문서를 찾아주는 도서관 사서"라면,
"책에서 필요한 내용을 찾아 직접 요약해주는 AI 도우미"라고 볼 수 있다.
2. 데이터셋 구성 (Dataset Construction)
GeAR는 두 가지 검색 시나리오를 고려하여 학습 데이터를 구성했다:
📌 2.1 Question Answer Retrieval (QAR, 질문-응답 검색)
- 쿼리: 질문 형태 ("자동차 엔진의 원리는?")
- 문서: 질문에 답변할 수 있는 문서
- 세부 정보: 질문에 대한 정답이 포함된 문장
🔹 사용된 데이터셋:
- PAQ (Lewis et al., 2021)에서 3천만 개(30M)의 데이터 샘플링
- 추가적으로 SQuAD, NQ, TriviaQA 데이터셋 사용
📌 2.2 Relevant Information Retrieval (RIR, 관련 정보 검색)
- 쿼리: 특정 키워드 기반 검색 ("전기차, 배터리 수명, 충전 방식")
- 문서: 키워드와 연관된 문서
- 세부 정보: 문서 내에서 해당 키워드와 가장 연관성이 높은 문장
🔹 데이터 생성 방법:
- 대형 언어 모델(LLM)을 활용하여 자동 생성
- 위키피디아 문서에서 5.8M 개의 데이터 생성
📝 예시
- 위키피디아에서 "전기차 배터리는 어떻게 충전되는가?" 문장을 선택.
- LLM을 사용해 "전기차 충전 방식, 배터리 수명, 충전소" 등의 쿼리 생성.
- 이를 학습 데이터로 사용하여 검색 모델 최적화.
3. 학습 방식 (Training Methodology)
GeAR는 검색 성능(문서 검색)과 정보 생성(세밀한 정보 생성) 두 가지 목표를 학습하도록 설계되었다.
📌 3.1 학습 목표
- Contrastive Learning (대조 학습)
- Bi-Encoder에서 쿼리와 문서 간 유사도를 최적화.
- MoCo(He et al., 2020) 및 BLIP(Li et al., 2022) 방식 활용.
- Language Modeling (언어 모델링)
- Fusion Encoder와 Text Decoder가 문서 내에서 중요한 정보를 학습하고 생성할 수 있도록 훈련.
- LLM Loss를 도입하여 문서와 쿼리를 결합한 후 적절한 정보 생성.
📝 예시
- GeAR는 "내연기관 엔진과 전기차 모터의 차이점은?"이라는 질문을 입력하면,
- "전기차 모터는 배터리 전력을 사용하여 회전하며, 내연기관 엔진은 연료 연소를 통해 동력을 생성합니다."와 같은 문장을 자동으로 생성할 수 있도록 학습됨.
📌 3.2 학습 데이터 크기 및 모델 훈련 환경
- 학습 데이터 크기:
- QAR: 30M 데이터 샘플링
- RIR: 5.8M 개의 데이터 생성
- 훈련 환경:
- 16 AMD MI200-64GB GPUs 사용
- AdamW 옵티마이저 사용 (학습률 1e-5, Weight Decay 0.05)
- 10 Epochs 동안 훈련 진행
4. GeAR의 학습 과정 예시 (Step-by-Step 예제)
📌 예제: "내연기관 vs 전기차 모터의 차이점" 검색
- 입력 쿼리: "내연기관 vs 전기차 모터 차이점?"
- 문서 검색 (Bi-Encoder)
- 관련 문서 3개 검색:
- 문서1: "내연기관 엔진의 작동 원리"
- 문서2: "전기차 모터의 작동 방식"
- 문서3: "전기차와 하이브리드 자동차의 차이점"
- 관련 문서 3개 검색:
- 세부 정보 추출 (Fusion Encoder)
- 문서2 내 "전기차 모터는 배터리를 통해 회전 운동을 수행한다." 문장을 강조.
- 답변 생성 (Text Decoder)
- 최종 출력:"전기차 모터는 배터리를 통해 회전 운동을 수행하며, 내연기관 엔진은 연료 연소를 통해 동력을 생성합니다."
5. 결론
- GeAR는 검색과 생성의 결합을 통해 기존 검색 모델의 한계를 극복.
- 단순히 검색 결과를 반환하는 것이 아니라, 문서 내에서 중요한 정보를 자동으로 찾아내고 생성 가능.
- 웹 검색, 법률 문서 분석, 논문 검색 등 다양한 응용 가능성이 있음.
📌 GeAR는 검색과 AI 기반 생성 모델의 결합을 통해 "더 똑똑한 검색 시스템"을 가능하게 하는 혁신적인 접근법이다! 🚀
1. 실험 결과 분석
GeAR 모델의 성능을 검증하기 위해 문서 검색(Document Retrieval), 세밀한 정보 탐색(Units Localization), 정보 생성(Information Generation) 세 가지 실험을 수행하였다.
각 실험에서 기존 검색 모델 대비 우수한 성능을 보였으며, 특히 검색된 문서 내 세부 정보를 더 정확히 식별하고, 관련 내용을 효과적으로 생성하는 능력을 입증하였다.
📌 1.1 문서 검색 성능 (Documents Retrieval)
비교 대상 모델:
- 기존의 검색 모델: SBERT, E5, BGE, GTE
- 재학습된 검색 모델: SBERT (재학습), BGE (재학습)
🔹 주요 성능 지표
- Recall@5 (R@5): 상위 5개의 검색 결과 중 실제 관련 문서가 포함될 확률
- MAP@5 (M@5): 검색된 문서의 순위별 가중치를 고려한 평균 정밀도
🔹 결과 요약
| 모델 | SQuAD (R@5) | NQ (R@5) | TriviaQA (R@5) | PAQ (R@5) | RIR (R@5) |
| SBERT | 0.812 | 0.754 | 0.677 | 0.808 | 0.376 |
| E5 | 0.803 | 0.760 | 0.645 | 0.816 | 0.484 |
| BGE | 0.829 | 0.674 | 0.690 | 0.752 | 0.451 |
| GTE | 0.866 | 0.767 | 0.726 | 0.836 | 0.528 |
| GeAR | 0.883 | 0.747 | 0.660 | 0.940 | 0.961 |
✅ GeAR는 모든 데이터셋에서 기존 모델보다 우수한 검색 성능을 보임
✅ 특히 PAQ 및 RIR 데이터셋에서 큰 성능 향상을 달성 (기존 모델 대비 +5~10% 향상)
📌 1.2 세밀한 정보 탐색 성능 (Units Localization)
- 기존 검색 모델은 문서를 하나의 단위로만 평가하여 내부 문장 정보까지 고려하지 못함.
- GeAR는 문서 내에서 중요한 문장을 자동으로 탐색하여 기존 검색 모델보다 더 정확한 정보 추출이 가능.
🔹 평가 지표
- Recall@1 (R@1): 정답 문장이 검색된 문서에서 1순위로 선택될 확률
- MAP@1 (M@1): 검색된 문장 순위별 가중치를 고려한 정밀도
🔹 결과 요약
| 모델 | SQuAD (R@1) | NQ (R@1) | TriviaQA (R@1) | PAQ (R@1) | RIR (R@3) |
| SBERT | 0.739 | 0.558 | 0.359 | 0.498 | 0.891 |
| E5 | 0.783 | 0.590 | 0.379 | 0.573 | 0.891 |
| BGE | 0.768 | 0.570 | 0.362 | 0.565 | 0.894 |
| GTE | 0.758 | 0.548 | 0.352 | 0.525 | 0.895 |
| GeAR | 0.810 | 0.765 | 0.515 | 0.885 | 0.954 |
✅ GeAR는 문서 내에서 정확한 정답 문장을 찾아내는 능력이 뛰어남
✅ 특히 NQ 및 PAQ 데이터셋에서 기존 모델 대비 +20% 이상 향상
✅ 세밀한 정보까지 추출 가능하여 검색 결과의 해석 가능성 증가
📌 1.3 정보 생성 성능 (Information Generation)
- GeAR는 단순 검색을 넘어 검색된 문서에서 관련 내용을 자동으로 생성할 수 있음.
- 기존 검색 모델이 단순한 검색 결과를 반환하는 반면, GeAR는 검색된 문서 내용을 요약하거나 질문에 대한 답변을 생성 가능.
🔹 평가 지표
- Exact Match (EM): 생성된 문장이 정답과 완전히 일치할 확률
- F1 Score: 생성된 문장이 정답과 얼마나 유사한지를 평가
🔹 결과 요약
| SQuAD (EM) | NQ (EM) | TriviaQA (EM) | PAQ (EM) | RIR (Rouge-L) | |
| GeAR | 61.2 | 66.1 | 47.4 | 88.1 | 87.1 |
✅ GeAR는 문서에서 질문에 대한 답변을 직접 생성할 수 있음
✅ PAQ 및 RIR 데이터셋에서 높은 정확도를 보이며, 검색 결과의 해석 가능성을 극대화
✅ 기존 검색 모델이 제공하지 못하는 "생성 능력"을 추가적으로 제공
2. 결론 (Conclusion)
🔹 GeAR의 주요 기여
- ✅ 검색과 생성의 결합 (Retrieval + Generation)
- 기존 검색 모델은 단순히 문서를 찾는 역할을 했지만,
GeAR는 검색된 문서에서 관련 정보를 직접 생성할 수 있음.
- 기존 검색 모델은 단순히 문서를 찾는 역할을 했지만,
- ✅ 세밀한 정보 검색 능력 향상
- 기존 검색 모델은 문서 전체의 유사도만 평가했지만,
GeAR는 문서 내에서 가장 중요한 문장을 찾아 정확성을 극대화.
- 기존 검색 모델은 문서 전체의 유사도만 평가했지만,
- ✅ 연산 효율성 유지
- Bi-Encoder 기반 검색 모델과 동일한 연산량을 유지하면서도 추가적인 정보 생성 가능.
- 기존 대비 검색 성능이 향상되었으며, 추가적인 연산 부담이 크지 않음.
3. 향후 연구 방향 (Future Work)
GeAR의 가능성을 더욱 확장하기 위해 다음과 같은 연구 방향이 제안됨.
📌 3.1 긴 문서 검색 (Long Context Retrieval)
- 현재 GeAR는 512 토큰 이하의 문서 검색을 지원.
- 더 긴 문서(1000~5000 토큰)를 처리할 수 있도록 확장 연구 필요.
📌 3.2 멀티모달 검색 (Multi-Modal Retrieval)
- 현재는 텍스트 기반 검색이지만,
이미지, 비디오, 음성 데이터까지 확장 가능한 검색 모델 연구 가능.
📌 3.3 검색과 생성 성능 최적화 (Retrieval-Generation Trade-off)
- 검색 성능과 생성 성능을 최적화하기 위해 Multi-Task Learning 기법 도입 가능.
- 검색 성능을 유지하면서 생성된 정보의 품질을 높이는 방향으로 연구 필요.
4. 마무리
GeAR는 단순한 검색을 넘어, 검색된 정보의 해석 가능성을 극대화하는 혁신적인 검색 모델이다.
기존 검색 모델이 단순한 문서 리스트를 반환하는 것과 달리,
GeAR는 문서 내에서 중요한 정보를 추출하고, 추가적인 생성 기능을 제공하여 더 유용한 검색 시스템을 구축할 수 있는 가능성을 제시하였다.
📌 GeAR는 "더 똑똑한 검색 시스템"을 가능하게 하는 핵심 기술이며, 미래의 검색 및 AI 기반 연구에서 중요한 역할을 할 것으로 기대됨! 🚀