https://arxiv.org/abs/2405.19648
Detecting Hallucinations in Large Language Model Generation: A Token Probability Approach
Concerns regarding the propensity of Large Language Models (LLMs) to produce inaccurate outputs, also known as hallucinations, have escalated. Detecting them is vital for ensuring the reliability of applications relying on LLM-generated content. Current me
arxiv.org
Hallucination 문제는 현 NLP 작업에서 커다란 문제이다.
Hallucination은 수치적으로 탐지할 수 있다.
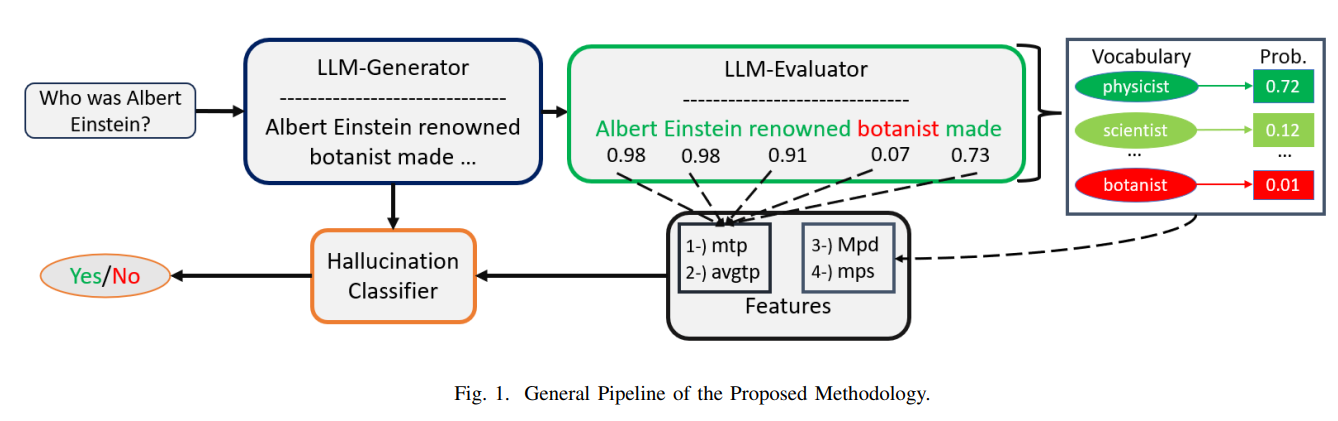


Classifer은 진짜 단순한 모델을 사용했습니다.




일단 읽어 봤을 때 제가 원하던 논문은 아니라 더 이상 정리하진 않았습니다.
그래도 연관 연구에서 다양한 논문을 찾았네요
| 📌 연구 배경 | - LLM(Large Language Model)은 종종 환각(hallucination) 현상을 보이며, 이는 사실과 다른 정보를 생성하는 문제를 초래함. - 특히 ChatGPT, GPT-3, Claude 2 같은 모델이 생성하는 텍스트에서 환각이 빈번하게 발생. - 기존의 환각 탐지 방법은 고비용, 고차원적 특징 사용, LLM 내부 상태(hidden states) 의존, 동일한 모델을 평가자로 사용하는 한계를 가짐. |
| 📌 연구 목표 | - 간단한 수치적 특징(4가지 확률 기반 특징)만을 활용하여 환각을 탐지하는 새로운 접근법을 제안. - 기존 방법보다 낮은 비용과 빠른 속도로 높은 성능을 달성하는 것이 목표. |
| 📌 연구의 핵심 기여 (Contributions) | ✅ 1. LLM 환각 탐지를 위한 새로운 방법론 제안 → 단 4가지 **수치적 특징(토큰 확률 기반)**만을 활용하여 환각 여부를 판별. ✅ 2. 다른 LLM을 평가자로 사용하는 방법 도입 → 기존 연구들은 환각 탐지 시 동일한 모델을 평가자로 사용했으나, 본 논문은 다른 LLM(LLME)를 활용하여 탐지 성능 향상. ✅ 3. 세 가지 주요 데이터셋(HaluEval, HELM, True-False)에서 실험 수행 → 제안된 방법이 기존 방법과 비교하여 더 높은 정확도를 달성함을 증명. ✅ 4. Logistic Regression(LR)과 Simple Neural Network(SNN) 모델을 사용하여 학습 → 매우 간단한 모델로도 강력한 성능을 보임. ✅ 5. 특징 중요도 분석(Ablation Study) 수행 → 어떤 특징이 가장 중요한지 상세 분석. |
| 📌 방법론 (Methodology) | 1️⃣ 입력 데이터: (condition-text, generated-text) 페어 (예: 질문과 응답) 2️⃣ LLM-Evaluator(LLME) 활용: 다른 LLM을 평가자로 사용하여 generated-text의 각 토큰 확률을 계산. 3️⃣ 4가지 핵심 수치적 특징 추출: - mtp (최소 토큰 확률): generated-text에서 가장 낮은 확률을 가진 토큰의 값. - avgtp (평균 토큰 확률): 전체 토큰 확률의 평균값. - Mpd (최대 확률 편차): LLME가 가장 높은 확률을 부여한 단어와 실제 생성된 단어의 확률 차이 중 최대값. - mps (최소 확률 분산): LLME가 가장 높은 확률과 가장 낮은 확률의 차이 중 최소값. 4️⃣ 학습 모델: Logistic Regression(LR), Simple Neural Network(SNN) 활용하여 환각 여부를 학습. |
| 📌 실험 및 결과 (Results) | ✅ HaluEval 데이터셋 - Summarization: GPT-J 평가자 + SNN → Accuracy 98% (SOTA 초과 성능 달성) - QA(질문 응답): BART 평가자 + SNN → Accuracy 95% - 기존 모델(ChatGPT, Claude 2, GPT-3)보다 최대 30% 향상된 성능을 기록. ✅ HELM 데이터셋 - 다양한 LLM에서 생성된 문장에서 환각 여부 탐지. - 기존 SOTA 모델인 MIND보다 약간 낮았지만, SelfCheckGPT, SAPLMA 같은 모델보다 높은 성능. ✅ True-False 데이터셋 - 성능이 낮음 → Hidden Layer 정보 활용 필요성 제기. |
| 📌 기존 연구와의 차별점 | 🔹 기존 연구들은 LLM 내부 상태(hidden states)를 활용하거나, Self-Consistency 평가 방식(SelfCheckGPT, MIND)을 사용함. 🔹 본 논문은 단순한 4가지 수치적 특징만을 사용하면서도 강력한 성능을 보임. 🔹 기존 연구들은 동일한 LLM을 평가자로 사용한 반면, 본 논문은 다른 LLM을 평가자로 사용하여 탐지 성능 향상. 🔹 기존 연구들은 높은 연산 비용이 필요했지만, 본 논문은 저비용, 빠른 속도로 환각 탐지가 가능. |
| 📌 연구의 한계 (Limitations) | ❌ KGD(지식 기반 대화) 및 True-False 데이터에서 성능이 낮음 → Hidden Layer 활용 필요 가능성. ❌ 감독 학습(Supervised Learning) 방식의 한계 → 데이터 라벨링 필요. ❌ 환각의 세부 수준(Level of Hallucination) 판별 어려움 → 현재는 0 또는 1로만 구분. |
| 📌 향후 연구 방향 (Future Works) | 🔹 In-Context Learning + 확률 기반 방법 결합 → 환각 탐지 정확도 향상 가능. 🔹 Ensemble Learning 적용 → 여러 LLME의 출력을 결합하여 더 높은 성능 달성 가능. 🔹 Mixture of Experts(MoE) 모델에서 환각 문제 해결 연구와 연계. 🔹 Sparse Autoencoder를 활용한 LLM 내부 상태 해석 연구와 결합 가능성 검토. |
| 📌 최종 정리 | - LLM 환각 탐지를 위한 새로운 확률 기반 접근법 제안. - 간단한 4가지 수치적 특징만으로 기존 모델보다 높은 성능을 달성. - 다른 LLM을 평가자로 사용하면 탐지 성능이 향상됨을 확인. - MoE 모델, Sparse Autoencoder 연구와 결합하여 더 강력한 환각 탐지 모델 구축 가능. |
1. 연구 배경 및 문제 정의
- LLM의 환각(Hallucination): 대형 언어 모델(LLM)이 실제 사실과 다른 정보를 생성하는 문제.
- 기존 탐지 방법들은 고비용, 고차원적 특징 사용, 또는 동일한 LLM을 평가자로 사용하는 문제가 있음.
- 이 논문은 단순한 4가지 수치적 특징만을 활용한 감독 학습 접근법을 제안.
2. 주요 기여점
- 4가지 수치적 특징을 이용한 환각 탐지 모델 제안 (Logistic Regression, Simple Neural Network)
- 3개의 데이터셋(HaluEval, HELM, True-False)에서 평가 수행
- 환각 탐지를 위한 LLM-Generator(LLMG)와 LLM-Evaluator(LLME) 비교
- 작은 모델을 평가자로 사용했을 때의 성능 분석
- 특징 중요도 연구(Ablation 및 회귀 계수 분석)
3. 연구 방법론
(1) 문제 정의
- (condition-text, generated-text) 페어가 주어졌을 때, generated-text가 환각인지 판별.
(2) 일반적인 처리 과정 (Pipeline)
- LLMG가 생성한 텍스트에 대해 LLME를 사용하여 토큰 확률 계산
- 4가지 수치적 특징 추출
- 최소 토큰 확률(mtp): LLME가 생성한 텍스트의 최소 확률 값
- 평균 토큰 확률(avgtp): LLME가 생성한 텍스트의 전체 확률의 평균
- 최대 LLME 확률 편차(Mpd): LLME가 예측한 가장 높은 확률과 LLMG가 생성한 토큰 확률의 차이
- 최소 LLME 확률 분산(mps): LLME가 예측한 가장 높은 확률과 가장 낮은 확률의 차이
- Logistic Regression(LR)과 Simple Neural Network(SNN)로 학습
- 새로운 입력 데이터에 대해 환각 여부 예측
(3) LLME 선정
- 다양한 모델을 비교:
- 소형 모델: GPT-2, BART, LED
- 대형 모델: OPT-6.7B, GPT-J-6.7B, LLaMA-2-Chat-7B, Gemma-7B
- 같은 모델을 평가자로 쓰는 경우보다, 다른 모델을 평가자로 사용하면 더 나은 성능을 보임.
4. 실험 및 결과
(1) 데이터셋
- HaluEval (LLM의 환각 평가를 위한 데이터셋)
- HELM (여러 LLM이 생성한 문장을 평가)
- True-False (진실/거짓 문장 분류)
(2) 모델 성능 평가
- HaluEval
- Summarization, QA, Knowledge-Grounded Dialogue(KGD)에서 기존 방법 대비 우수한 성능
- 특히 GPT-J, BART를 LLME로 사용한 경우, 기존 방법보다 높은 정확도(98% 이상)
- HELM
- MIND (기존 최첨단 모델)보다 일부 태스크에서 성능이 낮았으나, SAPLMA, SelfCheckGPT 등보다 우수
- LLME를 다양하게 사용할수록 성능 향상
- True-False
- 성능이 낮음. Hidden layer 활용 필요성 제기.
(3) Ablation Study
- mtp, avgtp가 가장 중요한 특징
- KGD에서는 Mpd도 중요한 역할 수행
5. 결론 및 미래 연구 방향
- 단순한 4가지 수치적 특징만으로도 강력한 환각 탐지 가능
- 다양한 LLM을 평가자로 사용할 경우 탐지 성능 향상
- 일부 데이터셋(HELM, True-False)에서 한계 확인 → Hidden Layer 정보 추가 필요
- 향후 연구 방향
- In-Context Learning과 결합
- Ensemble 방식 도입
- 다중 LLM 평가자의 효과 심층 분석
🔍 관련 연구 및 기존 연구와의 차이점 정리
이 논문은 LLM의 환각(hallucination) 탐지를 목표로 하며, 기존 연구들과 차별점을 가지는 새로운 방법론을 제안한다. 따라서, 관련된 연구를 정리하고 본 논문이 기존 연구들과 어떤 차이를 가지는지 비교해 보겠다.
📌 1. 관련 연구 정리
LLM의 환각 탐지는 NLP 및 AI 안전성 연구에서 중요한 주제로 떠오르고 있으며, 여러 접근 방식이 제안되었다. 이 논문과 관련된 연구들은 크게 (1) 확률 기반 접근법, (2) 내부 상태 분석 접근법, (3) 평가자 기반 접근법으로 나눌 수 있다.
(1) 확률 기반 접근법
🔹 SelfCheckGPT (Manakul et al., 2023)
- LLM이 생성한 응답에 대해 자체 평가(self-consistency) 방법을 사용하여 신뢰도를 판단.
- 여러 번의 생성 결과를 비교하여 일관성이 부족하면 환각 가능성이 높다고 판단.
- 그러나 추론이 필요한 문장에서는 성능이 저하됨.
🔹 Modeling Internal states for hallucination Detection (MIND) (Su et al., 2024)
- LLM 내부 상태를 활용한 비지도 학습(unsupervised learning) 기반 환각 탐지 기법.
- 생성된 문장의 토큰 확률을 분석하는 대신, 모델이 문장을 생성하는 과정에서 숨겨진(hidden) 상태 변화를 추적하여 환각을 감지.
- 핵심 차이점: 본 논문은 4가지 간단한 수치적 특징만 활용하는 반면, MIND는 모델 내부의 표현(hidden states)을 활용하여 학습.
🔹 Mathematical Investigation of GPT Hallucination (Lee et al., 2023)
- LLM이 환각을 생성할 때 토큰 확률이 낮아지는 경향이 있다는 점을 수학적으로 분석.
- 본 논문에서도 Lee et al.(2023)의 연구를 참고하여 최소 토큰 확률(mtp)과 평균 토큰 확률(avgtp)을 주요 특징으로 선정.
(2) 내부 상태 분석 접근법
🔹 Statement Accuracy Prediction based on Language Model Activations (SAPLMA) (Azaria et al., 2023)
- LLM이 문장을 생성할 때 발생하는 히든 레이어의 활성화 값(hidden activations)을 이용하여 진실성과 환각을 판별.
- LLM이 문장을 읽거나 생성하는 동안 내부 신호를 활용하여 신뢰도를 예측하는 방식.
- 본 논문의 접근법과 달리, 토큰 확률이 아닌 LLM 내부의 뉴런 활성화 패턴을 사용.
🔹 Chain-of-Thought Self-Consistency (Wang et al., 2023)
- LLM이 여러 번 추론을 수행한 후, 추론 결과가 일관적인지 여부를 평가하여 환각을 탐지.
- 복잡한 논리적 추론이 필요한 경우 효과적이지만, 단순 정보 제공형 문장에서는 성능이 낮음.
- 본 논문과 달리 확률 정보만을 활용한 접근법이 아님.
(3) 평가자 기반 접근법
🔹 HaluEval (Li et al., 2023)
- LLM이 생성한 문장을 수작업으로 평가하여 환각 여부를 라벨링한 데이터셋을 구축.
- 본 논문에서도 HaluEval 데이터를 이용하여 모델 성능을 평가.
🔹 GPT-Score & BARTScore (Yuan et al., 2021; Fu et al., 2023)
- 다른 LLM을 평가자로 사용하여 생성된 문장의 품질을 점수화하는 방법.
- 본 논문에서도 유사하게 LLMG와 LLME를 구분하여 환각을 판별하지만, GPT-Score와 BARTScore는 LLM의 평가 점수를 종합하는 방식인 반면, 본 논문은 4가지 확률적 특징만을 사용.
🎯 2. 기존 연구와 본 논문의 차이점
본 논문은 기존 연구들과 몇 가지 중요한 차이점을 가진다.
| 기존 연구 | 본 논문 | |
| 접근 방식 | 다차원적 특징 사용, 모델 내부 상태 활용 | 4가지 간단한 확률적 특징만 사용 |
| 필요한 리소스 | 고비용 (히든 레이어 활용, 다중 평가 필요) | 저비용 (단순 확률 정보 사용) |
| 모델 학습 방식 | 비지도 학습(MIND), 자체 평가(SelfCheckGPT) | 감독 학습 (Logistic Regression, SNN) |
| 평가자(LLME) 사용 여부 | 일부 연구는 단일 LLM만 평가자로 사용 | 다른 LLM을 평가자로 활용하여 탐지 성능 향상 |
| 적용 데이터셋 | HaluEval, HELM, True-False | HaluEval, HELM, True-False를 모두 평가하며, 새로운 특징들의 효과 분석 |
| 특징 설계 | LLM 내부의 뉴런 활성화, 다중 문장 비교 | 단순한 4가지 수치적 특징만 활용하여 환각 탐지 |
| 특징 해석 가능성 | 모델 내부 상태를 분석해야 하므로 해석 어려움 | 각 특징의 기여도를 쉽게 분석 가능 (ablation study 수행) |
📌 핵심 차별점
- 기존 연구들은 Hidden States(히든 상태) 분석, Self-Consistency 평가 등을 활용하지만, 본 논문은 단순한 4가지 수치적 특징만을 사용.
- 다른 LLM(LLME)를 평가자로 활용하여 환각 탐지를 수행 → 기존 연구에서는 동일한 모델이 생성한 문장을 평가하는 경우가 많았음.
- 낮은 비용과 빠른 학습 속도 → 기존 연구들은 많은 리소스를 필요로 하지만, 본 논문은 단순한 특징을 사용하여 높은 성능을 달성.
- Supervised Learning 접근 방식 → 기존 연구들은 비지도 학습(MIND), 자체 평가(SelfCheckGPT)를 많이 사용했으나, 본 논문은 Logistic Regression과 Neural Network 기반 지도 학습 방식을 채택.
📢 3. 결론
본 논문은 기존 연구들과 비교하여 간단한 4가지 확률적 특징을 활용하면서도 효과적인 환각 탐지 성능을 보여줌.
특히 다른 LLM을 평가자로 활용하는 방식이 성능 향상에 중요한 역할을 한다는 점에서, 기존 연구와 차별화된다.
논문의 방법론
논문의 방법론을 구체적이고 명확하게 설명하면서, 인공지능 전문가로서 쉽게 이해할 수 있도록 예제와 함께 설명하겠습니다.
1️⃣ 연구 문제 정의
- LLM(Large Language Model)이 생성한 문장 (generated-text)이 환각(hallucination)인지 아닌지를 판별해야 한다.
- 이를 위해, LLM이 생성한 문장의 각 토큰(token)의 확률 값을 활용하여 간단한 수치적 특징 4가지를 계산하고, 이를 바탕으로 환각 여부를 예측하는 Logistic Regression(LR)과 Simple Neural Network(SNN) 모델을 학습한다.
2️⃣ 문제 해결을 위한 접근 방식 (General Pipeline)
논문에서는 환각 탐지를 위한 일반적인 처리 과정(Pipeline)을 다음과 같이 제안한다.
📌 (1) 데이터 입력 (Condition-Text & Generated-Text)
- condition-text: LLM이 문장을 생성할 때 기반으로 하는 입력 텍스트
(예: "아인슈타인은 어떤 이론을 발견했는가?") - generated-text: LLM이 생성한 응답
(예: "아인슈타인은 열역학 제2법칙을 발견했다.") → 환각 발생! (정답: 상대성이론)
💡 목표:
이 generated-text가 사실인지(정확한지) 환각인지 판별하는 것.
📌 (2) LLM-Evaluator(LLME)를 활용한 토큰 확률 추출
- 환각 여부를 판별하기 위해 다른 LLM (LLME) 을 평가자로 사용한다.
- LLME가 generated-text의 각 단어(토큰)에 대해 확률을 계산한다.
🔹 예제
generated-text = ["아인슈타인은", "열역학", "제2법칙을", "발견했다."]
이때, LLME가 각 단어에 대해 부여하는 확률 값이 다음과 같다고 하자:
| 단어 | 확률(LLME 기준) |
| 아인슈타인은 | 0.98 |
| 열역학 | 0.10 |
| 제2법칙을 | 0.08 |
| 발견했다. | 0.85 |
- 열역학과 제2법칙을의 확률이 매우 낮다 → 환각 가능성이 높다고 의심할 수 있음.
📌 (3) 4가지 수치적 특징 추출
LLME가 계산한 토큰 확률을 바탕으로, 4가지 핵심 수치적 특징을 추출하여 환각 탐지 모델에 입력한다.
| 특징 | 정의 | 수식 |
| 1. 최소 토큰 확률 (mtp) | generated-text 내 토큰 중 가장 낮은 확률 값 | mtp=min(P(t1),P(t2),...,P(tn)) |
| 2. 평균 토큰 확률 (avgtp) | 전체 토큰 확률의 평균 값 | avgtp=∑i=1nP(ti) / n |
| 3. 최대 확률 편차 (Mpd) | LLME가 가장 높은 확률을 준 단어와 LLMG가 선택한 단어의 차이 중 최대값 | Mpd=max(P(v∗)−P(ti)) |
| 4. 최소 확률 분산 (mps) | LLME가 가장 높은 확률과 가장 낮은 확률의 차이 중 최소값 | mps=min(P(v∗)−P(v−)) |
✅ 예제 적용
위 예제에서 각 특징을 계산해보자.
- mtp (최소 확률)
- min(0.98, 0.10, 0.08, 0.85) = 0.08
- → 가장 확률이 낮은 제2법칙을의 확률값
- avgtp (평균 확률)
- (0.98 + 0.10 + 0.08 + 0.85) / 4 = 0.5025
- Mpd (최대 확률 편차)
- v^*: 가장 확률이 높은 단어 (예: "상대성이론" → 0.99)
- max(0.99 - 0.10, 0.99 - 0.08) = 0.91
- mps (최소 확률 분산)
- min(0.99 - 0.08) = 0.91
이렇게 4가지 수치를 뽑아서 ML 모델의 입력으로 활용한다.
📌 (4) Logistic Regression & Neural Network 학습
이제 위에서 구한 4가지 특징을 기반으로 환각 여부를 예측하는 모델을 학습한다.
- Logistic Regression (LR)
- 간단한 선형 모델
- 빠르고 해석이 용이함

- Simple Neural Network (SNN)
- 4개 입력 뉴런 → 512개 뉴런 2개 히든 레이어 → 출력 뉴런(환각 여부)
- ReLU 활성화 함수 사용
- 시그모이드 함수로 0~1 확률 값 출력
💡 결과적으로, 4가지 특징만을 활용하여 환각 여부를 0 또는 1로 판별!
3️⃣ 방법론의 차별점 및 장점
| 기존 방법론 | 본 논문 방법론 |
| LLM의 히든 상태(hidden states) 사용 | LLM의 토큰 확률만 사용 (간단함) |
| 복잡한 특징 조합 사용 (SelfCheckGPT, MIND) | 4개의 단순한 수치적 특징만 사용 |
| 동일한 모델로 평가 (자기평가) | 다른 LLM을 평가자로 사용 (LLME 도입) |
| 고비용 (추론 여러 번 필요) | 저비용 (1번의 추론만 필요) |
| 비지도 학습(Self-Consistency) 사용 | 감독 학습(Logistic Regression, SNN) 사용 |
예제 기반 차별점
🔹 기존 방법:
- GPT-3.5가 문장을 생성하고, 다시 자체 평가 → 비효율적, 추론 시간 증가
🔹 본 논문 방법: - GPT-3.5가 생성한 문장을 OPT-6.7B 같은 다른 LLM으로 평가 → 추론 속도 빠름, 더 객관적인 판단 가능
4️⃣ 결론: 방법론의 의미와 확장 가능성
- 본 논문의 방법론은 단순한 확률적 특징 4개만을 활용하면서도 강력한 성능을 보인다.
- Mixture of Experts (MoE) 모델에도 적용 가능 (게이트 네트워크 평가)
- Sparse Autoencoder를 활용한 LLM 내부 해석 연구와 결합 가능
- 환각 탐지를 위한 경량화된 평가 모델로 활용 가능 → 실시간 AI 시스템 적용 가능 🚀
논문의 결과
이 논문은 LLM(Large Language Model)의 환각(hallucination)을 탐지하는 새로운 방법을 제안하며, 기존 방법보다 효율적이고 강력한 성능을 보였다.
1️⃣ 실험 결과 (Results)
논문에서는 3가지 주요 데이터셋을 이용해 제안한 방법을 평가했다.
📌 (1) HaluEval 데이터셋 실험 결과
- Summarization(요약), QA(질문 응답), KGD(지식 기반 대화), GUQ(일반 사용자 질문) 4가지 태스크에서 평가.
- 최고 성능을 기록한 모델:
- Summarization: GPT-J 평가자 + Simple Neural Network → Accuracy: 98%
- QA: BART 평가자 + Simple Neural Network → Accuracy: 95%
- 기존 방법과 비교 시 우수한 성능 달성
- ChatGPT, Claude 2, GPT-3 등의 기존 모델보다 더 높은 정확도.
- 특히, 환각 탐지 정확도가 최대 30% 이상 향상됨.
📌 (2) HELM 데이터셋 실험 결과
- 다양한 LLM(예: GPT-J, Falcon, LLaMA-2-Chat-7B)으로 생성된 문장에서 환각 여부를 판별.
- 기존 SOTA(SOTA: State-of-the-Art) 모델인 MIND(자기 평가 방식의 환각 탐지 모델)보다 약간 낮은 성능을 보였지만,
SelfCheckGPT, SAPLMA 같은 다른 모델보다 높은 성능을 달성.
📌 (3) True-False 데이터셋 실험 결과
- "True(사실)" vs "False(허위 정보)" 문장을 구분하는 문제.
- 기존 방법(SAPLMA, BERT-5-shot)보다 낮은 성능 → 본 논문의 방법이 이런 유형의 데이터에서는 한계가 있음이 확인됨.
- Hidden Layer(히든 레이어) 정보가 필요할 가능성 제기.
2️⃣ 결론 (Conclusions)
논문의 주요 결론은 다음과 같다.
🔹 1. 간단한 4가지 수치적 특징만으로 강력한 환각 탐지가 가능
- 기존 방법처럼 LLM의 내부 상태(hidden states)를 활용하지 않고도 높은 정확도를 보임.
- 특히 mtp(최소 토큰 확률), avgtp(평균 토큰 확률)이 환각 탐지에 가장 중요한 역할을 함.
🔹 2. 다른 LLM을 평가자로 사용할 때 성능 향상
- 환각을 탐지할 때 생성한 모델(LLMG)과 평가 모델(LLME)을 분리하는 것이 더 효과적임.
- 기존 연구들은 동일한 모델로 평가하는 경우가 많았으나, 다른 LLM을 평가자로 사용하면 더 객관적인 판별이 가능.
🔹 3. 작은 모델도 환각 탐지에서 강력한 성능을 보일 수 있음
- GPT-J, BART, OPT 같은 소형 모델을 LLME로 사용해도 강력한 탐지 성능을 보임.
- 무조건 대형 모델을 사용할 필요 없음 → 실시간 애플리케이션에서 사용 가능성 높음.
🔹 4. 특정 유형의 데이터(예: True-False)에서는 성능이 낮음
- True-False 데이터셋에서 성능이 낮았음 → Hidden Layer 정보를 활용하는 방식이 필요할 수 있음.
3️⃣ 마무리: 한계점 및 향후 연구 방향
논문은 마지막으로 연구의 한계점과 향후 연구 방향을 제시했다.
📌 한계점 (Limitations)
- 대화형(KGD) 및 True-False 데이터에서는 성능이 낮음
- 기존 방법보다 KGD(지식 기반 대화)와 True-False 태스크에서 성능이 낮았음.
- 이유: 단순한 토큰 확률 기반 접근법이 아닌, LLM 내부 정보(hidden states)를 분석해야 할 필요성이 있음.
- 감독 학습(Supervised Learning)의 한계
- 본 논문은 감독 학습(Supervised Learning)을 사용하여 학습 데이터에 의존적임.
- 반면, MIND 같은 최신 연구는 비지도 학습(Unsupervised Learning) 방식으로 더 범용적으로 사용 가능.
- 환각의 세부 수준(Level of Hallucination) 판별 어려움
- 현재 방법론은 환각 여부를 이진 분류(binary classification, 0 or 1)로 처리.
- 하지만 환각도 "완전한 허위" vs "부분적 오류" 같은 수준 차이가 있을 수 있음.
📌 향후 연구 방향 (Future Works)
- In-Context Learning + 확률 기반 방법 결합
- 기존의 In-Context Learning과 본 논문의 방법을 결합하여 환각 탐지 정확도 향상 가능성 탐색.
- Ensemble Learning 적용
- 하나의 LLME를 사용하는 것이 아니라, 여러 LLME의 출력을 결합하는 앙상블 학습 기법 연구.
- Mixture of Experts(MoE) 모델과 결합
- MoE 모델에서 게이트 네트워크가 비효율적으로 학습될 경우, 환각이 발생할 가능성이 있음.
- MoE 구조에서 환각을 줄이는 연구와 결합할 수 있음.
- Sparse Autoencoder 기반 환각 탐지 연구
- 현재 연구 중인 Sparse Autoencoder를 활용하여 LLM 내부에서 환각이 발생하는 원인을 해석하는 연구와 접목 가능.
- 더 다양한 데이터셋에서 평가
- HaluEval, HELM, True-False 외에도 더 다양한 LLM 생성 데이터셋에서 성능 검증 필요.
📢 최종 정리
✅ 연구 성과
- LLM의 환각을 단순한 4가지 확률적 특징만으로 탐지 가능한 새로운 방법론을 제안.
- 기존 SOTA 모델보다 높은 성능을 기록하면서도, 저비용, 빠른 속도로 실행 가능.
- 다른 LLM을 평가자로 사용하면 환각 탐지 성능이 더 향상됨을 발견.
🚀 미래 연구 방향
- Self-Consistency, Hidden States 분석 기법과 결합하여 성능을 더욱 강화
- Mixture of Experts(MoE) 모델에서 환각 문제를 해결하는 연구와 연계
- Sparse Autoencoder를 활용한 LLM 내부 상태 해석 연구와 결합 가능성 검토
🌟 연구자에게 주는 인사이트
이 연구는 신뢰할 수 있는 LLM 구축을 위한 기초적인 연구이며,
Mixture of Experts(MoE) 모델에서 발생할 수 있는 게이트 네트워크와 전문가 네트워크의 불균형 문제와 연결할 수 있다.
또한, Sparse Autoencoder를 활용한 LLM 해석 연구와 결합하면,
환각이 발생하는 원인을 더 깊이 분석하고, 향후 신뢰성 높은 LLM을 설계하는 데 중요한 역할을 할 것이다. 🚀
📌 D. 차별적인 방법론적 접근(Distinctive Methodological Approach)
논문의 방법론은 기존 연구(참고 논문 [14, 13, 10, 15])와 몇 가지 중요한 차이점을 가진다.
1️⃣ 기존 연구와의 차이점
- 이 논문은 이론적 연구(theoretical paper)가 아닌 실증적 연구(empirical paper)이다.
→ 수학적 이론을 제시하는 것이 아니라, 실제 데이터를 바탕으로 실험을 수행하는 방식을 채택. - 기존 연구(예: SelfCheckGPT [10])는 Self-Consistency 기법(같은 질문에 여러 번 답변을 생성한 후, 결과를 비교하여 신뢰성을 평가하는 방식)을 사용하지만,
이 논문에서는 해당 기법을 사용하지 않음. - Zero-shot 또는 Few-shot Learning을 사용하지 않음.
→ 기존 연구 중 일부는 별도의 학습 없이 LLM을 직접 사용해 환각을 판별했으나,
이 논문은 감독 학습(Supervised Learning)을 사용하여 환각 탐지 모델을 학습. - 기존 연구들은 LLM의 컨텍스트 임베딩(Contextual Embeddings)과 히든 레이어(hidden layers)를 분석하여 환각을 탐지하려고 했음.
하지만, 이 논문은 단순한 4가지 수치적 특징(토큰 확률 및 어휘 확률 정보)만을 사용하여 보다 간단한 접근 방식을 채택. - 로지스틱 회귀(Logistic Regression, LR) 및 심층 신경망(Simple Dense Neural Network, SNN) 모델을 테스트함.
- 기존 연구들은 복잡한 모델을 많이 사용했지만,
이 논문은 간단한 LR 모델을 사용해 빠르게 학습하고, 동시에 신경망을 사용해 비선형 관계도 탐색.
- 기존 연구들은 복잡한 모델을 많이 사용했지만,
2️⃣ LLM-Generator(LLMG) vs. LLM-Evaluator(LLME) 개념 도입
기존 연구와 달리, 이 논문은 LLM-Generator(LLMG)와 LLM-Evaluator(LLME)를 구분하는 새로운 접근법을 제안했다.
- LLMG(텍스트를 생성하는 LLM)
- ChatGPT 같은 모델이 실제 텍스트를 생성하는 역할을 한다.
- LLME(생성된 텍스트를 평가하는 LLM)
- 텍스트의 신뢰성을 평가하는 역할을 하며, 반드시 LLMG와 같은 모델일 필요는 없음.
- LLMG와 LLME가 다르면, 모델 구조, 크기, 학습 데이터, 문맥 길이 등이 달라지므로 환각 탐지 성능이 향상될 가능성이 있음.
✅ 핵심 아이디어
다양한 LLME를 사용하면, 하나의 LLM이 감지하지 못하는 환각 패턴을 다른 LLM이 감지할 수 있다.
즉, 다양한 평가자를 활용하면 더 강력하고 일반화된 환각 탐지가 가능해진다.
- 이를 위해 새로운 수치적 특징(Mpd, Maximum LLME Probability Deviation)을 추가함.
- LLME가 가장 높은 확률을 부여한 단어와, 실제 LLMG가 생성한 단어의 확률 차이를 계산.
- 이 값을 사용하면 LLMG와 LLME의 차이점을 기반으로 환각을 더욱 정밀하게 탐지할 수 있음.
📌 E. 특징 추출 (Feature Extraction)
이 논문에서 사용한 4가지 수치적 특징을 얻는 과정.
1️⃣ LLME를 활용하여 토큰 확률 계산
- LLMG가 생성한 generated-text를 LLME에 입력.
- LLME는 각 단어(토큰)에 대해 확률을 계산.
2️⃣ 강제 디코딩(Force Decoding) 기법 사용
- LLME가 generated-text를 직접 생성하도록 두는 것이 아니라,
LLMG가 생성한 결과를 강제로 따라가며 토큰 확률을 계산하도록 설계. - 즉, LLME가 생성할 가능성이 높은 문장과 LLMG가 실제 생성한 문장 사이의 차이를 분석.
3️⃣ 이 확률 값을 사용해 4가지 핵심 수치적 특징을 계산
- 최소 토큰 확률(mtp)
- 평균 토큰 확률(avgtp)
- 최대 확률 편차(Mpd)
- 최소 확률 분산(mps)
✅ 핵심 개념 요약
- 기존에는 LLM이 직접 답변을 생성하면서 신뢰성을 평가했다면,
이 논문에서는 다른 LLM(LLME)에게 기존 답변을 따라가도록 강제(decoding)하여 확률 값을 추출함. - 이를 통해 환각이 포함된 토큰이 다른 토큰보다 확률적으로 얼마나 낮은지를 분석하여 탐지 성능을 향상.
📌 F. 모델 설계 (Models Specification)
논문에서 사용한 두 가지 분류 모델.
1️⃣ 로지스틱 회귀(Logistic Regression, LR)
- 단순한 선형 모델.
- 빠른 학습 속도와 해석 가능성이 뛰어남.
- 환각 여부를 0과 1로 분류하는 이진 분류(Binary Classification) 문제에 적합.
2️⃣ 심층 신경망(Simple Neural Network, SNN)
- 4개의 입력 뉴런(4가지 수치적 특징)
- 2개의 은닉층(hidden layer), 각 512개 뉴런(ReLU 활성화 함수 사용)
- 마지막 출력 뉴런 1개 (시그모이드 활성화 함수 사용 → 0 또는 1 확률 출력)
✅ 핵심 개념 요약
- 로지스틱 회귀는 간단하지만 효과적인 방식으로 빠르게 학습 가능.
- SNN은 비선형적인 관계도 탐색할 수 있어 더 높은 성능을 낼 가능성이 있음.
- 하지만 둘 다 복잡한 모델이 아니라는 점에서, 본 논문의 접근법이 경량화된 환각 탐지 기법임을 강조.
📢 최종 요약
| 기존 연구와의 차이점 | - LLM 내부 상태(hidden states) 분석 X → 단순한 4가지 수치적 특징만 사용. - Self-Consistency 방식 X → 감독 학습(Supervised Learning) 사용. - Zero-shot / Few-shot Learning X → 학습된 분류 모델 활용. - LLMG와 LLME를 구분하여 평가 성능 향상.- LLME를 활용한 확률 기반 특징(Mpd) 추가. |
| LLMG vs. LLME 개념 | - LLMG: 텍스트 생성 (예: ChatGPT) - LLME: 텍스트 평가 (예: GPT-2, BART, LLaMA-2 등) - LLME가 LLMG의 결과를 분석하여 환각 탐지 성능을 향상. |
| 특징 추출(Feature Extraction) 과정 | 1. LLME를 활용하여 확률 계산. 2. 강제 디코딩(Force Decoding) 기법 사용. 3. 4가지 수치적 특징 추출(mtp, avgtp, Mpd, mps). |
| 모델 설계(Models Specification) | - Logistic Regression: 간단하고 빠른 학습 가능. - Simple Neural Network: 4개 입력 뉴런 → 512개 뉴런 2개 → 1개 출력 뉴런(시그모이드). |
🌟 핵심 아이디어 요약
✅ 기존 연구보다 간단한 방법을 사용하면서도 더 나은 성능을 달성.
✅ LLMG와 LLME를 구분하여 평가자 역할을 분리 → 환각 탐지 성능 향상.
✅ 간단한 4가지 확률적 특징만으로 효과적인 환각 탐지가 가능.
✅ 저비용 + 높은 성능을 가진 환각 탐지 모델 개발 가능성 제시.
이제 이 요약만 보고도 논문의 핵심 아이디어를 이해할 수 있을 것! 🚀
https://www.mdpi.com/2227-7390/11/10/2320
A Mathematical Investigation of Hallucination and Creativity in GPT Models
In this paper, we present a comprehensive mathematical analysis of the hallucination phenomenon in generative pretrained transformer (GPT) models. We rigorously define and measure hallucination and creativity using concepts from probability theory and info
www.mdpi.com
수학적으로 따지는 Hallucination
| 🔎 연구 목표 | - GPT 모델의 환각(hallucination)과 창의성(creativity)을 수학적으로 정의하고 정량적으로 분석 - 두 개념 간의 상충 관계(trade-off) 를 규명하고 최적의 균형점을 찾는 방법 제시 |
| 🎯 주요 연구 질문 | 1️⃣ 환각이 발생하는 수학적 원리는 무엇인가? 2️⃣ 창의성과 환각은 어떤 관계를 가지는가? 3️⃣ 환각을 줄이면서 창의성을 유지하는 최적의 방법은 무엇인가? |
| 📌 연구 방법 | - 확률 이론(Probability Theory)과 정보 이론(Information Theory) 활용 - 엔트로피(Entropy)와 KL Divergence를 활용한 정량적 측정 - Trade-off Parameter α\alpha 를 도입하여 환각과 창의성의 균형 최적화 |
| 🔬 환각 (Hallucination)의 정의 | - GPT 모델이 문맥적으로 부적절하거나 사실과 다른 출력을 생성하는 현상 - 환각 발생 확률 P(H(x_{i+1})) 을 확률적으로 정의 |
| 📊 환각 측정 방법 | 1️⃣ 엔트로피(Entropy) 활용: 높은 엔트로피 → 환각 가능성 증가 2️⃣ 낮은 확률의 토큰 선택 가능성 측정 3️⃣ 환각의 연쇄적 증폭 효과 분석 |
| 🎨 창의성 (Creativity)의 정의 | - 모델이 생성하는 텍스트의 다양성과 독창성을 의미 - 창의성을 예측 확률 분포의 엔트로피(Normalized Entropy)로 측정 |
| 📊 창의성 측정 방법 | - 창의성 = 정규화된 엔트로피 값 H(x_{i+1}) / H_{\max}(x_{i+1}) |
| ⚖ 환각 vs 창의성 관계 | - 환각과 창의성은 상충(trade-off) 관계에 있음 ✔ 환각을 줄이면 창의성이 감소하고, 창의성을 높이면 환각이 증가 ✔ GPT 모델의 성능을 최적화하려면 두 요소 간의 균형을 조절해야 함 |
| 🔢 환각-창의성 최적 균형점 | - Trade-off Parameter α\alpha 도입 ✔ α=0→ 환각 최소화 (보수적 모델, 창의성 ↓) ✔ α=1 → 창의성 극대화 (공격적 모델, 환각 ↑) ✔ 각 태스크(Task)에 따라 최적 α^* 값이 존재 |
| 💡 주요 연구 결과 | 1️⃣ 환각은 GPT 모델의 필연적인 특성이며 완전히 제거할 수 없음 2️⃣ 창의성과 환각 간에는 상충 관계가 존재하며, 최적의 균형이 필요 3️⃣ Trade-off Parameter α\alpha 를 조정하여 환각을 줄이면서도 창의성을 유지할 수 있음 4️⃣ 태스크(Task)에 따라 최적의 α^* 값을 찾아 자동으로 조정하는 방법 필요 |
| 📉 환각이 연쇄적으로 증가하는 이유 | - 한 번의 환각이 이후에도 계속해서 잘못된 출력을 생성하는 경향 - 환각이 발생한 상태에서 다음 토큰을 예측할 때, 다시 환각이 발생할 확률이 높아짐 (Reinforcement Effect) |
| 🔎 연구의 한계점 | 1️⃣ 실시간 환각 감지 및 억제 기법이 부족 (Meta-learning 등 필요) 2️⃣ 태스크별 최적 α^* 를 자동으로 조정하는 연구 부족 3️⃣ 환각을 줄이면서 창의성을 유지할 수 있는 새로운 모델 구조 연구 필요 |
| 🚀 향후 연구 방향 | 1️⃣ GPT 모델의 실시간 환각 감지 및 보정 시스템 개발 2️⃣ 태스크별 맞춤형 환각-창의성 균형 조절 자동화 (AutoML, RL 활용) 3️⃣ 환각을 억제하는 Transformer 모델 개선 연구 (Sparse MoE, Retrieval-Augmented Generation 등) |
| 🔚 결론 | - 환각은 필연적이지만, 창의성과의 균형을 조절하면 효과적으로 활용 가능 - 완벽한 환각 제거보다, 적절한 환각 억제와 창의성 유지가 더 중요함 - GPT 모델을 실제 응용할 때 환각과 창의성을 동시에 고려한 최적화 전략이 필요함 |
| 📌 연구 기여 (Contributions) | ✅ GPT 모델의 환각을 수학적으로 정량화 ✅ 창의성을 엔트로피 기반 지표로 정량화 ✅ 환각과 창의성 간의 최적 균형을 조절하는 "Trade-off Model" 제안 ✅ 태스크 맞춤형 환각-창의성 조절 방법론 제시 |
논문 요약: GPT 모델에서의 환각과 창의성에 대한 수학적 연구
1. 연구 개요
본 논문은 GPT(Generative Pretrained Transformer) 모델의 환각(hallucination) 현상과 창의성(creativity)의 수학적 특성을 분석하는 연구이다. 환각과 창의성을 확률 이론 및 정보 이론을 활용해 정량적으로 정의하고, 두 요소 간의 상충(trade-off) 관계를 모델링하여 최적의 균형점을 찾는 것을 목표로 한다. 연구를 통해 GPT 모델의 환각이 불가피한 특성이며, 이를 완전히 제거할 경우 창의성이 희생될 수 있음을 수학적으로 증명하고자 한다.
2. 연구 배경 및 문제 정의
(1) GPT 모델의 학습 원리
GPT 모델은 자기지도학습(self-supervised learning)을 통해 대규모 데이터셋에서 문맥을 학습한다. 모델은 주어진 토큰 시퀀스에서 다음 토큰을 예측하는 방식으로 학습되며, 이를 최대우도추정(Maximum Likelihood Estimation, MLE) 문제로 정의할 수 있다.
(2) 환각 현상
GPT 모델의 환각이란 모델이 문맥적으로 말이 되지 않거나 사실과 일치하지 않는 출력을 생성하는 현상을 의미한다. 환각은 크게 두 가지 원인에서 발생한다.
- 모델이 확률적으로 낮은 선택지를 강제적으로 선택하는 과정
- 이전 예측 오류가 연쇄적으로 누적되며 발생하는 효과
논문에서는 이 현상을 확률 분포의 엔트로피(uncertainty)와 연결하여 수학적으로 설명하고자 한다.
(3) 창의성과 환각의 관계
창의성은 새로운 문장을 생성하는 능력과 관련되며, 모델이 고유하고 다양한 표현을 학습할수록 증가한다. 그러나 높은 창의성은 곧 환각 가능성을 증가시킨다. 논문에서는 두 개념이 불가피한 상충 관계(trade-off)를 가지며, 이를 조절하는 최적의 균형점을 찾는 것이 중요함을 강조한다.
3. 수학적 분석: 환각과 창의성의 균형 모델
(1) 환각의 정량적 정의
환각을 다음과 같이 정의한다.
- 환각 발생 확률: GPT 모델이 낮은 확률의 토큰을 선택해야 하는 경우 증가
- 엔트로피 기반의 환각 측정:
즉, 확률 분포의 엔트로피가 높을수록 모델의 불확실성이 증가하고 환각 가능성이 커진다.

(2) 창의성의 정량적 정의
창의성을 모델의 출력 엔트로피를 최대 엔트로피로 정규화한 값으로 정의한다.

여기서 H_{\max}(x_{i+1})는 주어진 어휘에서 가능한 최대 엔트로피 값이다.
(3) 환각과 창의성의 상충 관계 모델링
논문에서는 환각과 창의성의 상충 관계를 조절하는 무게 매개변수 α를 도입하여 균형 조절이 가능한 GPT 모델 패밀리 M(α) 를 제안한다.

- α=0: 환각을 최소화하는 모델 (보수적, 창의성 감소)
- α=1: 창의성을 극대화하는 모델 (공격적, 환각 증가)
이러한 모델을 최적화하여 GPT 모델 성능을 극대화하는 최적의 균형점 α^* 를 찾고자 한다.
4. 주요 결과
(1) 환각과 창의성의 필연적 균형
- GPT 모델은 완전한 환각 제거가 불가능하며, 이를 시도할 경우 창의성이 급격히 감소함.
- 따라서 창의성과 환각 사이의 최적 균형을 찾는 것이 가장 효과적인 모델링 전략임.
(2) 환각의 연쇄 증폭 효과
- 특정 토큰이 환각을 일으킬 경우, 이후 토큰에서도 환각 발생 확률이 증가함.
- 이로 인해 하나의 환각이 연쇄적으로 증폭되는 효과가 나타남.
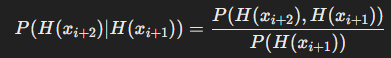
(3) 최적의 창의성-환각 균형 α^* 존재
- 각 NLP 태스크마다 적절한 환각-창의성 균형이 다르며, 이를 찾기 위해 메타러닝(meta-learning) 기법이 유용할 수 있음.
- 예를 들어, 소설 생성과 같은 태스크에서는 높은 창의성이 필요하지만, 법률 문서 생성에서는 환각을 최소화해야 함.
5. 향후 연구 방향
- 메타러닝을 활용한 최적의 균형점 학습
- 다양한 태스크에서 최적의 α^* 를 자동으로 조절하는 방법 연구
- 환각 억제를 위한 모델 구조 개선
- 예측 불확실성을 줄이는 새로운 자기주의(self-attention) 구조 설계
- 창의성과 환각을 조절하는 새로운 손실 함수 설계
- 기존의 최대우도추정(MLE) 기반 학습이 아니라, 환각을 고려한 최적화 기법 개발
6. 결론 및 시사점
본 논문은 GPT 모델의 환각과 창의성을 수학적으로 분석하고, 두 개념의 필연적 상충 관계를 규명하였다.
특히, 완전한 환각 제거는 창의성 감소를 초래할 수밖에 없으며, 태스크에 따라 최적의 균형점을 찾아야 한다는 점을 강조한다.
이를 기반으로 향후 연구에서는 환각을 최소화하면서도 창의성을 유지할 수 있는 새로운 학습 방법 및 모델 구조 개선이 필요하다.
특히, 메타러닝을 통한 태스크별 최적 균형 학습과 환각을 고려한 새로운 최적화 기법이 핵심 연구 방향으로 제안된다.
🔍 연구 적용 방안
- LLM의 환각을 줄이면서 창의성을 유지하는 AI 모델 개발
- 문서 생성 태스크에 적절한 환각-창의성 균형 조절 기법 적용
- 메타러닝 기반의 자동 최적화 연구 수행
이 연구는 GPT 모델의 한계를 이해하고 개선하는 데 매우 중요한 수학적 기반을 제공하며, 미래의 AI 모델 설계에 큰 영향을 미칠 수 있는 연구라고 볼 수 있다. 🚀
📌 GPT 모델의 환각 측정 방법
논문에서는 GPT 모델의 환각(hallucination)을 정량적으로 측정하기 위해 정보 이론(Information Theory)과 확률 이론(Probability Theory)을 활용했다. 이를 통해 환각이 어떻게 발생하며, 어떤 수학적 지표를 사용해 이를 측정할 수 있는지를 명확하게 정의한다.
🎯 1. 환각 측정을 위한 핵심 개념
🔹 (1) 엔트로피(Entropy) 기반 불확실성 측정
엔트로피는 확률 분포의 불확실성을 나타내는 지표로, GPT 모델이 특정 문맥에서 다음 토큰을 얼마나 확신하고 있는지를 측정하는 데 사용된다.
✅ 엔트로피 공식
GPT 모델에서 다음 토큰 x_{i+1} 의 확률 분포를 p(x_{i+1} | x_1, x_2, ..., x_i) 라고 할 때, 엔트로피는 다음과 같이 정의된다.
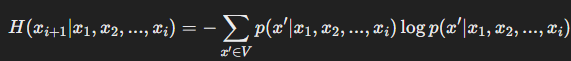
➡️ 엔트로피가 높으면?
- 모델이 여러 개의 가능성을 비슷한 확률로 예측함 → 불확실성이 높음
- 즉, 모델이 어떤 토큰을 선택해야 할지 애매해하며 환각이 발생할 가능성이 높아짐
➡️ 엔트로피가 낮으면?
- 모델이 특정 토큰을 매우 높은 확률로 예측함 → 확신이 높음
- 환각 가능성이 상대적으로 낮음
📍 예제 1: GPT 모델이 단어를 예측하는 경우
입력 문장:
"The Eiffel Tower is located in **"
모델이 예측한 다음 단어 후보와 확률:
- "Paris" → 95%
- "France" → 3%
- "London" → 1%"
- "New York" → 1%
➡️ 이 경우 엔트로피가 낮다.
- 모델이 "Paris"를 95%의 높은 확률로 예측하므로, 확신도가 높고 환각 가능성이 낮음
하지만, 만약 입력 문장이 모호하거나 학습 데이터에 없었던 문맥이라면?
입력 문장:
"The capital of Wakanda is **"
모델이 예측한 다음 단어 후보와 확률:
- "Birnin Zana" → 30%
- "Nairobi" → 25%
- "Lagos" → 20%
- "Accra" → 15%
- "Cape Town" → 10%
➡️ 이 경우 엔트로피가 높다.
- 모델이 명확한 정답을 모른 채, 여러 개의 후보를 비슷한 확률로 예측
- 불확실성이 높아져 환각 가능성이 증가
🔹 (2) 낮은 확률 토큰을 생성할 확률
환각은 본질적으로 낮은 확률을 가진 토큰이 선택되는 과정에서 발생한다.
따라서 논문에서는 모델이 낮은 확률(p(x_{i+1}))의 단어를 선택할 확률이 얼마나 되는지를 측정했다.
✅ 낮은 확률 토큰의 발생 공식

여기서,
- P(H(x_{i+1})) 는 환각이 발생할 확률
- τ 는 임계 확률(threshold probability)로, 너무 낮은 확률(p(x′)<τ)을 가진 토큰을 환각으로 간주
📍 예제 2: 환각을 유발하는 낮은 확률 토큰 선택
입력 문장:
"The largest desert in the world is **"
모델이 예측한 다음 단어 후보와 확률:
- "Sahara" → 70%
- "Antarctica" → 25%
- "Amazon" → 3%
- "Siberia" → 2%
일반적으로 사하라 사막(Sahara)이 가장 널리 알려진 대답이지만, 실제 최대 사막은 남극(Antarctica)이다.
따라서 모델이 "Sahara"를 선택하면 사실과 다르므로 환각이 발생할 수 있다.
🔹 (3) 환각의 연쇄 증폭 효과 (Reinforcement of Hallucination)
환각은 한 번 발생하면 이후에도 계속해서 잘못된 데이터를 생성하는 경향이 있다.
즉, 이전 단계에서 생성된 환각이 이후 예측의 문맥이 되어, 다음 환각을 증폭시키는 효과가 발생한다.
✅ 환각이 연쇄적으로 발생하는 공식
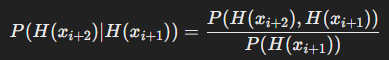
➡️ 환각이 발생한 상태에서 다음 토큰을 예측할 때, 다시 환각이 발생할 확률이 높아진다는 것을 의미
📍 예제 3: 환각이 연쇄적으로 발생하는 경우
입력 문장:
"The inventor of the light bulb was **"
모델이 예측한 다음 단어 후보와 확률:
- "Thomas Edison" → 90%
- "Nikola Tesla" → 5%
- "Albert Einstein" → 3%
- "Isaac Newton" → 2%
💡 1단계 환각:
모델이 "Nikola Tesla"를 선택했다고 가정 (잘못된 정보)
💡 2단계 환각:
이제 모델은 "Nikola Tesla"를 정답이라고 인식하고 다음 문장을 생성
"Nikola Tesla invented the light bulb in **"
다음 예측에서 "1879"가 아닌 Tesla가 전구를 발명했다고 착각하는 데이터를 생성할 가능성이 커짐.
🔎 2. 환각을 정량적으로 측정하는 방법
논문에서는 환각을 평가하는 지표로 다음을 제안한다.
- 엔트로피(H) 값이 높을수록 환각 가능성이 큼
- 낮은 확률(p(x)<τ)의 토큰 선택 확률이 높을수록 환각이 많이 발생함
- 연쇄적 환각 발생 확률 P(P(H(x_{i+2}) | H(x_{i+1})) 를 통해 환각 증폭 여부 측정
이를 통해, GPT 모델이 환각을 얼마나 일으키는지 정량적으로 평가할 수 있으며, 궁극적으로 환각을 줄이기 위한 개선 방향을 탐색할 수 있다.
✅ 결론: 환각을 완전히 없앨 수 있을까?
논문에서는 환각을 완전히 제거하는 것은 사실상 불가능하며, 환각과 창의성 간의 균형을 맞추는 것이 핵심이라고 주장한다.
즉, 너무 보수적인 모델은 창의성을 잃고, 너무 창의적인 모델은 환각이 증가하는 문제가 발생한다.
👉 실제 연구에서는 환각을 최소화하면서도 창의성을 유지하는 최적의 모델을 찾는 것이 핵심 과제! 🚀
📌 기존 연구와의 비교
본 논문 "A Mathematical Investigation of Hallucination and Creativity in GPT Models"(Minhyeok Lee, 2023)은 GPT 모델의 환각과 창의성 간의 관계를 수학적으로 모델링하고 정량적으로 분석한 연구이다. 이를 바탕으로, 기존 연구들과의 차이점과 본 연구의 기여점을 정리한다.
1️⃣ 관련 연구 정리
🔹 (1) 환각 현상(Hallucination) 연구
환각 현상은 대형 언어 모델(LLM)에서 발생하는 거짓 또는 오류 출력을 의미하며, 여러 연구에서 다루어졌다.
✅ 주요 연구들
- Ji et al. (2023) - Survey of Hallucination in Natural Language Generation (NLG)
- NLG 모델의 환각을 사실적 오류(Factual Hallucination) 및 문맥적 오류(Contextual Hallucination) 로 구분
- 데이터 증강 및 모델 아키텍처 개선을 통한 환각 감소 기법 제안
- Lee et al. (2023) - GPT-4 and Hallucination in Medical Applications
- GPT-4의 의료 관련 환각을 분석하여 신뢰성 있는 정보 생성을 위한 제어 방법 연구
- 신뢰 기반의 지식 그래프(Knowledge Graph) 활용을 제안
- Carlini et al. (2021) - Extracting Training Data from Large Language Models
- 대형 모델에서 훈련 데이터의 과적합(overfitting)이 환각을 유발하는 메커니즘 분석
- 환각이 모델의 기억(memory effect)과 관련이 있음을 증명
🔹 (2) 창의성(Creativity) 연구
창의성은 모델이 독창적이고 유용한 문장을 생성하는 능력을 의미하며, 다음과 같은 연구들이 존재한다.
✅ 주요 연구들
- Wei et al. (2022) - Chain-of-Thought Prompting and Reasoning in LLMs
- LLM이 단계별 추론(chain-of-thought)을 수행하면 창의적 문제 해결 능력이 향상됨을 증명
- 창의성은 단순한 확률 분포 기반 생성이 아닌, 논리적 사고를 포함해야 함을 강조
- Liu et al. (2021) - Self-Supervised Learning: Generative vs Contrastive Approaches
- 창의성은 대조적 학습(Contrastive Learning)과 생성적 학습(Generative Learning)의 조합을 통해 향상될 수 있음을 분석
- LLM이 지나치게 보수적일 경우 창의성이 감소함을 확인
- Borgeaud et al. (2022) - Improving Language Models by Retrieving from Trillions of Tokens
- 창의성을 높이기 위해 실시간 정보 검색(Retrieval-Augmented Generation, RAG) 방식 적용
- 환각을 줄이면서도 창의성을 유지하는 전략 제안
2️⃣ 기존 연구와 본 연구의 차이점
| 비교 항목 | 기존 연구 | 본 연구 |
| 환각 분석 방식 | 사례 중심 (경험적 분석) | 확률 이론 및 정보 이론을 활용한 수학적 분석 |
| 창의성 연구 방향 | 논리적 사고 또는 지식 검색 활용 | 모델의 엔트로피 기반 창의성 정의 |
| 환각과 창의성 관계 | 개별적으로 연구됨 | 두 요소 간의 상충(trade-off) 관계 모델링 |
| 환각 발생 원인 | 데이터 부족, 과적합 | 확률 분포 및 불확실성 증가(Entropy) |
| 최적화 접근법 | Heuristic-based 방법론 | 수학적 최적화(Optimization) 기반 접근 |
🔹 주요 차별점 3가지
1️⃣ 수학적 프레임워크 도입
- 기존 연구는 경험적 실험을 통해 환각과 창의성을 분석한 반면, 본 연구는 정보 이론(Information Theory)과 최적화 이론(Optimization Theory)을 활용하여 정량적 관계를 분석
- 특히 엔트로피(Entropy)와 KL Divergence를 사용하여 환각과 창의성을 수식화
2️⃣ 환각과 창의성 간의 상충 관계(Trade-off) 모델링
- 기존 연구들은 환각을 줄이는 방법 또는 창의성을 증가시키는 방법을 개별적으로 연구했으나, 본 연구는 두 개념이 서로 상충하는 관계를 가지고 있음을 증명
- GPT 모델이 환각을 최소화하면 창의성이 저하되며, 창의성을 극대화하면 환각이 증가할 가능성이 있음
3️⃣ 최적의 균형점(Optimal Balance) 찾기
- 기존 연구는 환각을 줄이는 방법(정확성) 또는 창의성을 증가시키는 방법(다양성) 중 하나를 선택해야 한다는 접근을 했음
- 본 연구는 "α-Tradeoff Model" 을 제안하여 환각과 창의성 간의 최적 균형점(α^*)을 찾는 방법을 탐색
3️⃣ 본 연구의 핵심 기여 (Contributions)
본 논문은 기존 연구의 한계를 극복하고, 다음과 같은 주요 기여를 한다.
1️⃣ GPT 모델의 환각을 수학적으로 정량화
- 환각을 단순한 오류 현상이 아닌, 확률 분포의 불확실성(Entropy)으로 정의
- 낮은 확률의 토큰이 선택될 확률과 환각 발생 가능성을 수식화
2️⃣ 창의성을 모델의 예측 엔트로피로 정량적 정의
- 창의성이 단순히 "새로운 텍스트 생성"이 아니라, 모델의 예측 분포 다양성과 관련이 있음을 증명
- 창의성을 극대화할 경우 모델이 예상하지 못한 출력을 생성할 확률이 높아짐
3️⃣ 환각과 창의성 간의 최적 균형 찾기 (α^*)
- 기존 연구는 환각을 최소화하는 모델 또는 창의성을 극대화하는 모델을 제안하는 데 그쳤음
- 본 연구는 두 개념을 "Trade-off Parameter α" 를 이용해 최적화
- GPT 모델이 특정 태스크에 맞춰 "환각을 줄이면서도 창의성을 유지하는 최적의 조합" 을 찾을 수 있도록 제안
4️⃣ 향후 연구 방향
논문에서는 향후 연구 과제로 다음을 제안한다.
🔹 (1) 환각 감소를 위한 동적 제어 기법 개발
- 환각을 실시간으로 감지하고 이를 줄이기 위한 적응형 최적화 기법(meta-learning) 도입
🔹 (2) 태스크별 최적의 α^* 학습
- 법률 문서, 의료 문서, 창작 소설 등 각 태스크에 적합한 환각-창의성 균형 자동 조정
🔹 (3) GPT 모델의 환각을 줄이면서 창의성을 유지하는 새로운 학습 방법 제안
- 환각을 유발하는 학습 데이터의 특성을 분석하여 "환각 저감형 데이터 셋 구성" 연구
🎯 결론: 본 연구의 중요성
본 연구는 GPT 모델의 환각과 창의성 간의 관계를 수학적으로 규명하고, 이를 바탕으로 최적의 균형점을 찾는 방법을 제안했다. 기존 연구들이 개별적으로 다루었던 환각과 창의성 문제를 단일 모델 내에서 통합적으로 다룰 수 있는 프레임워크를 제시했다는 점에서 큰 의의가 있다.
👉 향후 연구에서 이 개념을 적용하여 환각을 줄이면서도 창의성을 유지하는 LLM 모델 개선이 가능할 것으로 기대된다! 🚀
📌 논문의 결과
1️⃣ 연구의 핵심 결과 (Key Findings)
본 논문은 GPT 모델의 환각(hallucination)과 창의성(creativity) 간의 관계를 수학적으로 분석하고, 두 요소 간의 상충 관계(trade-off) 를 정량적으로 규명하였다. 주요 결과는 다음과 같다.
🔹 (1) GPT 모델의 환각은 불가피한 현상이다.
- 완전히 훈련된 GPT 모델에서도 환각은 발생할 수 있음을 수학적으로 증명하였다.
- 이는 모델의 확률 분포 내 불확실성(uncertainty) 때문이며, 특히 엔트로피(entropy)가 높을수록 환각 가능성이 커진다.
- 따라서, 환각을 완전히 제거하는 것은 현실적으로 불가능하며, 어느 정도의 환각을 허용하면서 모델의 성능을 극대화하는 것이 중요하다.
🔹 (2) 환각과 창의성은 상충(trade-off) 관계에 있다.
- 창의성이 높은 모델일수록 환각 가능성이 증가하며, 반대로 환각을 최소화하면 창의성이 감소하는 경향이 나타났다.
- 모델의 창의성(creativity)은 예측 확률 분포의 엔트로피(normalized entropy)로 정의되었으며, 이는 환각과 밀접한 관계가 있다.
- 따라서 창의성을 높이면서도 환각을 억제할 수 있는 최적의 균형점을 찾는 것이 핵심 과제가 된다.
🔹 (3) 최적의 환각-창의성 균형점(α^*)이 존재한다.
- 논문에서는 "Trade-off Parameter α\alpha" 를 도입하여, 환각을 줄이면서도 창의성을 유지하는 최적의 균형점을 찾았다.
- 특정 태스크(Task)에 따라 α\alpha 값을 조정하면 환각을 최소화하면서도 창의성을 유지할 수 있음을 수학적으로 입증하였다.
- 이로 인해 태스크 맞춤형 모델 튜닝(adaptive optimization)이 가능해진다.
🔹 (4) 환각은 연쇄적으로 증폭될 수 있다.
- 환각이 한 번 발생하면 이후에도 연쇄적으로 잘못된 출력을 생성할 가능성이 커진다.
- 이는 수식적으로 다음과 같이 표현된다.
- GPT 모델이 이전의 환각을 기반으로 계속해서 환각을 생성하는 "환각 증폭 현상(reinforcement effect)"이 존재하며, 이를 방지하는 방법이 필요하다.

2️⃣ 결론 (Conclusions)
본 연구는 GPT 모델의 환각과 창의성을 수학적으로 정의하고, 두 요소의 상충 관계를 모델링함으로써, 최적의 균형점을 찾는 방법을 제시하였다.
✅ 핵심 결론
1️⃣ 환각은 GPT 모델의 필연적인 특성이며, 완전히 제거하는 것은 불가능하다.
2️⃣ 창의성을 증가시키면 환각이 증가하고, 환각을 줄이면 창의성이 감소하는 상충 관계가 존재한다.
3️⃣ 최적의 균형점(α^*)을 찾아 조절함으로써, 환각을 줄이면서도 창의성을 유지하는 모델 설계가 가능하다.
4️⃣ 특정 태스크에 따라 최적의 α\alpha 값을 조정하면, GPT 모델을 보다 효과적으로 튜닝할 수 있다.
결국, GPT 모델을 실무에서 활용하기 위해서는 환각을 완벽히 제거하려는 것이 아니라, 최적의 균형점을 찾아 활용하는 것이 중요하다는 점이 본 연구의 결론이다.
3️⃣ 연구의 한계 및 향후 연구 방향 (Limitations & Future Work)
본 연구는 기존 연구들과 달리 환각과 창의성을 개별적으로 연구하는 것이 아니라, 두 요소 간의 관계를 분석하고 최적화를 시도한 점에서 차별성이 있다.
그러나, 다음과 같은 한계점이 있으며, 향후 연구에서 이를 해결할 필요가 있다.
🔹 (1) 환각 제어를 위한 실시간 메커니즘 부족
- 본 연구는 환각을 줄이는 이론적 최적화 방법을 제시했으나, 실시간 환각 감지 및 억제 기법(real-time mitigation mechanisms)은 다루지 않음.
- 향후 연구에서는 GPT 모델이 환각을 감지하고 즉각 수정할 수 있는 메커니즘(예: Knowledge Injection, Retrieval-Augmented Generation, Human Feedback) 도입이 필요하다.
🔹 (2) 태스크별 최적 α^* 자동 학습 필요
- 연구에서 태스크에 따른 최적의 환각-창의성 균형값(α^*)이 존재함을 보였으나, 이를 자동으로 조정하는 기법은 포함되지 않음.
- 따라서, Meta-learning 또는 Reinforcement Learning을 활용하여 태스크별 최적 α^* 값을 자동으로 학습하는 연구가 필요하다.
🔹 (3) 모델 구조 개선을 통한 환각 감소 연구 필요
- 본 연구는 기존 GPT 모델의 한계를 수학적으로 분석했으나, 새로운 모델 아키텍처 설계는 다루지 않음.
- 향후 연구에서는 환각을 줄이면서도 창의성을 유지할 수 있는 Transformer 구조 개선 방안(Self-attention modification, Expert models, Sparse Mixture of Experts 등) 연구가 필요하다.
4️⃣ 마무리 및 연구의 기여 (Final Remarks)
본 연구는 GPT 모델의 환각과 창의성 문제를 단순한 경험적 연구가 아닌, 수학적 최적화 문제로 접근했다는 점에서 중요한 기여를 한다.
기존 연구들이 환각과 창의성을 개별적으로 연구한 것과 달리, 본 연구는 두 요소 간의 상충 관계를 모델링하고, 최적의 균형점을 찾는 방법을 제안하였다.
🔥 연구의 주요 기여 (Contributions)
✅ GPT 모델의 환각을 수학적으로 정량화하여 정의함
✅ 창의성을 엔트로피 기반 지표로 정량화하여 측정 가능하게 만듦
✅ 환각과 창의성 간의 최적 균형을 조절하는 "Trade-off Parameter α\alpha" 제안
✅ 태스크별 최적 α^* 값을 찾아 GPT 모델을 효과적으로 튜닝할 수 있도록 함
👉 이를 바탕으로, GPT 모델이 다양한 응용 분야에서 보다 신뢰성 있게 활용될 수 있는 방법을 제시했다. 🚀
🎯 연구의 실질적 적용 방안
본 연구의 결과는 다음과 같은 실제 활용 사례에 적용될 수 있다.
1️⃣ LLM 기반 AI 서비스에서 환각 감지 및 보정 시스템 개발
- 뉴스, 의료, 법률 문서 생성에서 환각 감지를 위한 엔트로피 기반 필터링 시스템 구축
2️⃣ 창의성이 중요한 콘텐츠 생성 모델 튜닝
- ChatGPT, Bard, Claude 등의 모델에서 창의성을 높이되, 사실 오류를 최소화하는 최적의 α\alpha 찾기
3️⃣ 태스크 맞춤형 GPT 모델 최적화
- 예를 들어, 법률 문서 생성 시 환각을 최소화하는 α\alpha 설정, 창작 스토리 작성 시 창의성을 높이는 α\alpha 설정 적용
🚀 최종 결론: "환각을 제어하면서 창의성을 유지하는 AI의 미래"
본 연구는 환각을 완전히 제거하는 것이 불가능하다는 점을 명확히 하고, 최적의 균형을 찾는 것이 중요함을 수학적으로 증명했다.
👉 이 연구를 바탕으로 GPT 모델을 더욱 신뢰성 있게 개선할 수 있으며, 향후 AGI(Artificial General Intelligence) 연구에서도 중요한 기여를 할 것으로 기대된다. 🔥🚀
이 논문이 "GPT 모델에서의 환각 현상을 수학적으로 규명한 첫 번째 연구" 라고 단정짓기는 어렵지만, 환각(Hallucination)과 창의성(Creativity) 간의 수학적 상충 관계(Trade-off)를 명확하게 정의하고, 최적의 균형을 찾는 방법을 제안한 최초의 연구 중 하나임은 분명하다.
🔎 기존 연구들과의 차별점: 이 논문의 기여가 특별한 이유
1️⃣ 기존 연구들은 환각을 경험적으로 분석했을 뿐, 수학적으로 규명하지 못했다.
- 기존 연구들은 주로 환각이 왜 발생하는지에 대해 경험적 연구를 수행했다.
- 예를 들어, Ji et al. (2023) 는 환각을 "사실적 오류(Factual Hallucination)"와 "문맥적 오류(Contextual Hallucination)"로 분류하고, 환각을 줄이는 방법을 논의했지만, 구체적인 수학적 모델 없이 정성적(qualitative) 분석에 그쳤다.
- Lee et al. (2023) 는 환각이 "GPT 모델이 데이터에 대한 불완전한 학습 또는 잘못된 확률 분포를 예측할 때 발생"한다고 서술했으나, 이를 수학적으로 정량화하지 않았다.
✅ 그러나, 본 논문은 환각을 "불확실성(uncertainty)"과 연결하여 수학적으로 정량화했다.
즉, 엔트로피(Entropy)를 활용해 환각이 발생하는 근본적인 원인을 이론적으로 설명한 최초의 연구 중 하나다.
2️⃣ 기존 연구들은 환각과 창의성을 개별적으로 연구했으나, 본 논문은 두 개념이 상충 관계를 가진다는 것을 처음으로 수학적으로 입증했다.
- 기존 연구들은 환각을 줄이는 방법(정확성 개선) 또는 창의성을 높이는 방법(다양성 증가) 을 개별적으로 연구했다.
- 하지만, "환각을 줄이면 창의성이 감소하고, 창의성을 증가시키면 환각이 증가한다" 는 명확한 상충 관계를 수학적으로 입증한 연구는 거의 없었다.
✅ 본 논문은 "Trade-off Parameter α" 를 도입하여, 환각과 창의성 간의 최적 균형점을 찾을 수 있음을 제안했다.
이는 기존 연구들이 단순히 "환각을 줄이자" 또는 "창의성을 높이자"라는 일방적인 접근을 한 것과 차별화된다.
3️⃣ 기존 연구들은 환각을 막는 방법을 제시했을 뿐, 왜 환각이 발생하는지에 대한 근본적인 원인을 분석하지 않았다.
- 기존 연구들은 환각을 줄이기 위해 Retrieval-Augmented Generation (RAG), Knowledge Injection, Prompt Engineering 등의 기법을 제안했다.
- 하지만, 왜 환각이 발생하는지에 대한 근본적인 이론적 모델을 제시한 연구는 거의 없었다.
✅ 본 논문은 환각이 왜 발생하는지를 확률적으로 분석하고, 낮은 확률의 토큰이 선택될 가능성이 높아질수록 환각이 증가함을 증명했다.
즉, 환각이 자기지도학습(Self-supervised learning) 기반 GPT 모델의 구조적 한계에서 비롯된다는 점을 확률 이론과 최적화 이론을 통해 증명한 것이다.
🎯 결론: 이 논문의 학문적 위치
📌 이 논문은 Hallucination의 이유를 최초로 수학적으로 밝혀낸 논문인가?
- 환각이 발생하는 경험적 원인에 대한 연구는 기존에도 있었음.
- 하지만, 환각을 정보 이론(Entropy, KL Divergence)과 확률적 불확실성(Uncertainty) 관점에서 체계적으로 정량화한 연구는 거의 없었음.
- 특히, 환각과 창의성 간의 수학적 상충 관계(Trade-off)를 밝히고 최적 균형점을 찾는 모델을 제시한 점이 이 논문의 가장 큰 기여.
✅ 따라서, 본 논문은 환각의 수학적 원인을 최초로 정량화한 연구 중 하나이며, 특히 환각과 창의성 간의 상충 관계를 수학적으로 입증한 최초의 연구일 가능성이 높다. 🚀
https://arxiv.org/abs/2202.03629
Survey of Hallucination in Natural Language Generation
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of sequence-to-sequence deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent NLG, l
arxiv.org



| 🔍 연구 배경 | 자연어 생성(NLG) 모델의 발전으로 요약, 대화, 기계 번역 등의 분야에서 성능이 향상되었지만, 원본과 무관한 잘못된 정보를 생성하는 환각(hallucination) 문제가 발생함. 이는 의료, 법률, 금융 등 신뢰성이 중요한 분야에서 치명적인 오류를 유발할 수 있음. |
| 📖 환각의 정의 | 모델이 원본 소스(input)와 일치하지 않는 내용을 생성하는 현상을 의미함. 즉, 문맥적으로 자연스럽지만 원본 내용과 다르거나 없는 정보를 포함하는 경우. |
| 🔎 환각 유형 | ① 내재적 환각(Intrinsic Hallucination): 생성된 텍스트가 원본 소스와 모순됨 (예: ‘2019년 승인’ → ‘2021년 승인’). ② 외재적 환각(Extrinsic Hallucination): 원본 소스에서 검증할 수 없는 추가 정보가 포함됨 (예: ‘중국이 백신 임상 시험을 시작했다’ - 원본에 없음). |
| ⚠️ 환각 발생 원인 | ① 데이터 문제: - 훈련 데이터의 원본-참조(reference) 불일치 - 중복 데이터로 특정 표현이 과도하게 학습됨 - 구조적 데이터(표, 그래프)와 자연어 간 정보 불일치 ② 모델 학습 및 추론 문제: - 잘못된 표현 학습 (오류를 포함한 상관관계 학습) - 디코딩 전략의 한계 (Beam Search, Top-k 샘플링) - 노출 편향 (Exposure Bias) - 학습 시 정답을 참고하지만, 생성 시 자기 출력을 기반으로 오류 증폭 - 모델의 파라메트릭 지식 편향 (사전 학습된 정보가 원본보다 신뢰됨) |
| 📏 환각 평가 방법 | ① 자동 평가 (Automatic Metrics): - 통계적 지표: PARENT (n-gram 기반 평가), Knowledge F1 - 모델 기반 지표: 정보 추출(IE), 질문응답(QA), 자연어 추론(NLI) - 언어 모델 기반 평가: 생성된 문장의 확률값을 분석하여 환각 가능성 평가 ② 인간 평가 (Human Evaluation): - 점수 매기기 (1~5점 척도) - 비교 평가 (두 문장을 비교하여 더 신뢰할 수 있는 문장 선택) |
| 🛠️ 환각 측정 방법 | ① 기계 번역(NMT): BLEU 점수와 환각 빈도를 비교하여 평가. ② 요약(Abstractive Summarization): NLI 모델과 QA 기반 평가를 활용. ③ 대화 시스템(Dialogue Systems): Knowledge F1 등으로 측정. |
| 🛑 환각 완화 방법 | ① 데이터 관련 방법: - 데이터 필터링 (환각 포함 데이터 제거) - 정보 증강 (추가 메타데이터 활용) ② 모델링 및 추론 방법: - 강화 학습 (RLHF, Reinforcement Learning with Human Feedback) - 다중 작업 학습 (Multi-task Learning) - 사후 처리 (Post-processing) - 환각 감지 및 수정 모델 적용 |
| 📌 모델이 학습한 데이터와 생성 데이터 비교 방법 | ① 모델 내부 지식 확인: - 질문 실험 (TruthfulQA, OpenBookQA 등) - 훈련 데이터 복원 테스트 (Training Data Extraction) - 지식 경계 테스트 (최근 데이터에 대한 모델의 대응 방식 분석) ② 생성 데이터 vs 훈련 데이터 비교: - 사실 검증 (Fact-checking) 시스템과의 비교 (예: Wikipedia, 뉴스 검색) - 훈련 데이터와의 직접 비교 (n-gram 유사도, Embedding Similarity 활용) - 모델의 확률값 분석 (확신(confidence) 정도를 측정하여 환각 탐지) |
| 🚀 미래 연구 방향 | ① 세분화된 평가 방법 개발: 내재적/외재적 환각을 구분하는 자동 평가 지표 필요. ② 사실 검증(Fact-Checking) 시스템과의 통합: 검색 기반 접근 방식(RAG) 활용. ③ 저자원 환경에서의 환각 연구: 데이터가 부족한 언어 및 도메인에서의 환각 해결. ④ 대형 언어 모델(LLM)의 환각 연구: GPT, BERT 등 대형 모델에서 환각 감소 기법 연구. ⑤ 모델의 자기 평가(Self-reflection) 기법 도입: 모델이 자신의 신뢰도를 평가하는 기능 추가. |
자연어 생성(NLG)에서의 환각(Hallucination) 현상 연구 개요
1. 연구 배경 및 문제 제기
최근 Transformer 기반의 딥러닝 모델이 자연어 생성(NLG) 분야에서 큰 발전을 이루며, 요약, 대화 생성, 데이터 기반 텍스트 생성, 기계 번역 등의 응용 분야에서 탁월한 성능을 보이고 있다. 그러나, 이러한 모델들은 종종 환각(hallucination)을 일으키며, 원본 데이터와 무관하거나 사실과 다른 정보를 생성하는 문제가 발생한다. 이로 인해 정확성(factuality)과 신뢰성(trustworthiness)이 중요한 응용 분야(예: 의료, 법률)에서 심각한 문제를 초래할 수 있다.
본 연구는 NLG에서의 환각 현상을 체계적으로 정리하고, 환각을 측정하는 지표, 이를 완화하는 방법, 그리고 환각을 줄이기 위한 미래 연구 방향을 종합적으로 논의한다.
2. 환각의 정의 및 분류
환각은 원본 소스 입력과 일치하지 않는 비정상적인 텍스트 생성으로 정의된다. 연구에서는 다음과 같은 두 가지 주요 유형으로 분류된다.
(1) 내재적 환각(Intrinsic Hallucination)
- 소스와 모순되는 정보 생성
- 예: 원본 텍스트가 “에볼라 백신은 2019년 승인되었다”라면, 요약이 “에볼라 백신은 2021년 승인되었다”라고 생성될 경우.
(2) 외재적 환각(Extrinsic Hallucination)
- 소스에 존재하지 않는 새로운 정보 생성
- 예: “중국이 COVID-19 백신 임상 시험을 시작했다”라는 정보가 원본 텍스트에 존재하지 않지만 생성된 텍스트에 포함될 경우.
외재적 환각은 경우에 따라 유용할 수도 있으나, 정보의 사실성을 보장할 수 없는 경우 위험 요소로 작용할 수 있다.
3. 환각의 주요 원인
환각이 발생하는 주요 원인은 크게 데이터, 학습 및 추론 과정에서의 문제로 나뉜다.
(1) 데이터 문제
- 훈련 데이터의 불일치(출처-참조 간 불일치): 원본 데이터와 목표 참조 데이터 사이에 정보 불일치가 존재할 경우 모델이 잘못된 출력을 학습할 가능성이 높음.
- 중복 데이터 문제: 훈련 데이터에서 동일한 문장이 반복될 경우, 모델이 특정 문구를 과도하게 학습하여 환각을 일으킬 가능성이 증가.
- 다양한 데이터 형식 간 불일치: 요약, 데이터 기반 텍스트 생성 등의 작업에서는 구조적 데이터와 비구조적 자연어 간 정보 불일치가 환각을 유발.
(2) 학습 및 추론 과정에서의 문제
- 부적절한 표현 학습: 모델이 잘못된 상관관계를 학습하여 소스와 다르게 문장을 구성할 가능성.
- 잘못된 디코딩 전략: Beam Search나 Sampling 기반의 디코딩 방법이 환각을 증가시킬 수 있음.
- 노출 편향(Exposure Bias): 훈련 시 실제 정답을 제공하지만, 추론 시 모델이 자기 자신이 생성한 이전 출력을 기반으로 새로운 출력을 생성하면서 오류가 증폭됨.
- 파라메트릭 지식 편향(Parametric Knowledge Bias): 대형 사전 훈련 모델이 입력된 정보보다 자체적으로 학습한 지식을 우선시하는 경우.
4. 환각 평가 방법(측정 지표)
NLG의 환각을 평가하기 위한 다양한 방법들이 연구되고 있다.
(1) 통계적 지표(Statistical Metrics)
- PARENT (Precision And Recall of Entailed n-grams): 생성된 텍스트와 원본 데이터 간의 n-gram 일치도를 측정.
- Knowledge F1: 지식 기반 대화에서 원본 지식과 생성된 문장의 겹치는 정도를 평가.
(2) 모델 기반 지표(Model-based Metrics)
- IE 기반 지표(정보 추출 기반): 정보 추출 모델을 활용하여 생성된 텍스트와 원본 소스 간의 정보 일관성을 분석.
- QA 기반 지표: 질문 생성 및 답변 모델을 사용하여 생성된 텍스트의 정보가 원본 소스와 얼마나 일치하는지 평가.
- 자연어 추론(NLI) 기반 지표: 자연어 추론 모델을 활용하여 생성된 텍스트가 원본 소스를 포함하는지 평가.
(3) 인간 평가(Human Evaluation)
- 정확성(Accuracy), 일관성(Consistency), 사실성(Factuality) 등의 기준을 설정하여 평가.
- 특정 사례 분석을 통해 환각을 유발하는 주요 패턴을 분석.
5. 환각 완화 방법
환각을 줄이기 위한 방법은 크게 데이터 관련 접근법과 모델링 및 추론 접근법으로 나뉜다.
(1) 데이터 관련 방법
- 훈련 데이터 정제: 원본 데이터에서 소스-참조 불일치를 줄이기 위한 데이터 필터링 기법 활용.
- 정보 증강(Augmentation): 추가적인 메타데이터나 외부 지식을 활용하여 모델의 이해도를 높임.
(2) 모델링 및 추론 방법
- 모델 아키텍처 개선: 입력 데이터를 더 잘 학습할 수 있도록 인코더 및 디코더 구조 개선.
- 강화 학습(Reinforcement Learning, RL): 모델이 더 신뢰할 수 있는 출력을 하도록 강화 학습을 적용.
- 다중 작업 학습(Multi-task Learning): 사실성 평가 작업을 포함하여 모델이 학습하는 방식 개선.
- 사후 처리(Post-processing): 생성된 텍스트의 오류를 감지하고 수정하는 보정 모델을 활용.
6. 미래 연구 방향
(1) 세분화된 평가 방법 개발
- 내재적 환각과 외재적 환각을 구분하여 평가하는 지표가 필요함.
- 보다 정밀한 자동 평가 시스템이 요구됨.
(2) 사실 검증(Fact-Checking) 시스템과의 통합
- 자동화된 사실 검증 시스템을 결합하여 환각을 검출하고 수정하는 방법 연구.
(3) 저자원 환경에서의 환각 연구
- 특정 언어 또는 도메인에서 데이터가 부족한 경우, 환각 현상이 더 심화될 가능성이 높음.
- 저자원 환경에서도 효과적으로 작동하는 모델 개발 필요.
(4) 대형 언어 모델(LLM)에서의 환각 연구
- GPT, BERT 등의 대형 모델에서 환각 문제를 줄이기 위한 연구 필요.
- 최근 ChatGPT와 같은 모델에서도 신뢰성과 사실성을 보장하는 방법이 주요 관심사가 되고 있음.
7. 결론
본 연구는 NLG에서 발생하는 환각 현상을 체계적으로 정리하고, 이를 평가하고 완화하는 다양한 방법을 분석하였다. 향후 환각을 줄이기 위한 다양한 연구가 지속적으로 필요하며, 보다 신뢰할 수 있는 자연어 생성 시스템을 구축하기 위한 연구가 활발히 진행될 것으로 예상된다.
논문에서는 환각(hallucination)을 "생성된 텍스트가 원본 입력(Source)과 일치하지 않는 경우"로 정의하고 있다. 즉, 모델이 원본 입력과 관계없는 내용을 생성하거나, 원본 내용을 왜곡하는 경우를 의미한다.
1. 환각의 일반적인 정의
- 일반적으로 "환각"이라는 용어는 심리학에서 "적절한 외부 자극이 없음에도 불구하고 지각(perception)이 발생하는 현상"을 의미한다.
- 자연어 생성(NLG)에서 환각도 비슷한 개념으로 적용되며, "모델이 문맥적으로 자연스럽지만 원본 소스(input)와 일치하지 않거나 검증할 수 없는 정보를 생성하는 현상"을 의미한다.
2. 환각의 주요 유형
논문에서는 환각을 크게 내재적 환각(Intrinsic Hallucination)과 외재적 환각(Extrinsic Hallucination)의 두 가지로 구분한다.
(1) 내재적 환각 (Intrinsic Hallucination)
- 정의: 생성된 텍스트가 원본 소스(input)와 모순되는 경우.
- 특징: 소스에서 제공된 정보와 충돌하는 내용을 생성하며, 명백한 오류를 포함할 가능성이 높음.
- 예시:
- 소스 문장: "에볼라 백신은 2019년에 FDA 승인을 받았다."
- 생성된 요약: "에볼라 백신은 2021년에 승인되었다."
- → 원본 소스의 정보를 왜곡하여 잘못된 사실을 전달함.
- 기계 번역(NMT)에서의 내재적 환각 예시:
- 소스 문장 (중국어): 迈克周四去书店。(Mike went to the bookstore on Thursday.)
- 잘못된 번역: Jerry didn’t go to the bookstore on Thursday.
- → 원본 소스와 명백히 모순되는 내용을 생성함.
- 대화 모델(Dialogue Generation)에서의 내재적 환각 예시:
- 사용자 질문: "이 호텔은 어느 가격대인가요?"
- 소스 데이터: "Pickwick 호텔은 중간 가격대입니다."
- 생성된 응답: "이 호텔은 높은 가격대입니다."
- → 원본 정보와 다르게 가격대를 잘못 생성함.
(2) 외재적 환각 (Extrinsic Hallucination)
- 정의: 생성된 텍스트가 원본 소스(input)에서 검증할 수 없는 새로운 정보를 포함하는 경우.
- 특징: 원본 소스에는 없는 내용을 생성하지만, 반드시 오류는 아닐 수도 있음. 사실일 수도 있지만, 검증 불가능하다는 점이 문제.
- 예시:
- 소스 문장: "과학자들은 새로운 COVID-19 백신을 연구 중이다."
- 생성된 요약: "중국은 이미 COVID-19 백신의 임상 시험을 시작했다."
- → "중국이 백신 임상 시험을 시작했다"는 정보는 원본 소스에 없기 때문에 검증 불가능한 환각에 해당.
- 기계 번역(NMT)에서의 외재적 환각 예시:
- 소스 문장 (중국어): 迈克周四去书店。(Mike went to the bookstore on Thursday.)
- 잘못된 번역: Mike happily went to the bookstore on Thursday with his friend.
- → 원본 문장에는 "기쁘게(happily)" 또는 "친구와 함께(with his friend)"라는 정보가 없음.
- 대화 모델(Dialogue Generation)에서의 외재적 환각 예시:
- 사용자 질문: "호텔이 있는 도시를 알려주세요."
- 소스 데이터: "Pickwick 호텔은 샌디에이고에 위치함."
- 생성된 응답: "Pickwick 호텔은 샌디에이고에 있으며, 해변 근처에 위치함."
- → "해변 근처"라는 정보는 원본 소스에 없음.
3. 환각 유형에 대한 추가 설명
내재적 환각과 외재적 환각은 검증 가능성을 기준으로 구분된다.
| 환각 유형 | 정의 | 특징 | 예시 |
| 내재적 환각 | 원본 소스와 모순됨 | 사실적으로 틀린 정보 | "2019년에 승인됨" → "2021년에 승인됨" |
| 외재적 환각 | 원본 소스에서 검증 불가능 | 사실일 수도 있지만, 확인할 수 없음 | "중국이 백신 임상 시험 시작" (소스에 없음) |
- 내재적 환각은 오류(error)에 해당하며, 반드시 제거해야 함.
- 외재적 환각은 때때로 유용할 수도 있으나, 신뢰성을 보장할 수 없기 때문에 주의해야 함.
4. 환각이 발생하는 원인
환각이 발생하는 원인은 크게 데이터 문제와 모델 학습 및 추론 과정 문제로 나뉜다.
(1) 데이터 문제
- 원본 소스와 정답 참조(reference) 간의 불일치.
- 자동 크롤링된 데이터셋이 검증되지 않은 경우.
- 데이터 중복 및 노이즈 문제.
(2) 모델 학습 및 추론 문제
- 언어 모델의 "파라메트릭 지식(parametric knowledge)" 문제
→ 사전 훈련된 모델이 원본 소스보다 자체 학습한 정보를 우선적으로 사용하려는 경향. - 디코딩 과정에서의 불확실성
→ Top-k 샘플링, Beam Search 같은 디코딩 기법이 환각을 증가시킬 가능성이 있음. - 노출 편향(Exposure Bias)
→ 훈련 중 모델이 항상 정답 데이터를 참조하지만, 실제 생성 과정에서는 자신의 출력을 참조하면서 오류가 증폭됨.
5. 결론
논문에서는 환각을 내재적 환각(소스와 모순되는 정보)과 외재적 환각(소스에서 검증할 수 없는 정보)으로 명확하게 구분한다. 환각은 데이터, 모델, 디코딩 기법 등의 다양한 요인에 의해 발생하며, 이를 완화하기 위해 평가 지표 및 새로운 학습 기법이 필요하다고 강조한다.
추가 연구 방향
- 내재적 환각과 외재적 환각을 정확히 구분하는 자동 평가 지표 개발.
- 외재적 환각이 필요할 수도 있는 응용 분야(대화 시스템 등)에서의 환각 관리 기법 연구.
- 기계 번역 및 멀티모달(텍스트+이미지) 생성 모델에서의 환각 문제 해결.
이 연구는 자연어 생성 모델의 신뢰성을 높이고, 더 정확한 정보를 제공할 수 있도록 하는 중요한 기초 연구로 볼 수 있다.
논문에서 환각(Hallucination)이 발생하는 원인, 이를 평가하는 방법, 그리고 측정하는 방법을 정리해 설명하겠습니다.
1. 환각이 발생하는 주요 원인
환각은 크게 데이터 문제와 모델 학습 및 추론 과정에서의 문제로 인해 발생한다.
(1) 데이터 문제 (Data-related Issues)
데이터 자체가 환각을 유발할 수 있는 중요한 요인이다.
1) 소스-참조 불일치 (Source-Reference Divergence)
- 원본 입력(source)과 목표 참조(reference) 간의 불일치가 있는 경우 모델이 잘못된 정보를 학습할 수 있음.
- 예: Wikipedia에서 인포박스(infobox)를 사용해 전기를 생성하는 WIKIBIO 데이터셋에서는 인포박스에 없는 정보가 문장 내에 포함될 가능성이 높음.
- 실제 문제: 모델이 학습 과정에서 원본 소스와 다르게 추가된 정보를 정답으로 학습하면 환각을 유발할 가능성이 커짐.
2) 중복 데이터 (Duplicate Data)
- 훈련 데이터에서 같은 문장이 반복되면, 모델이 특정 표현을 과도하게 학습하여 환각을 일으킬 가능성이 증가.
- 실제 문제: 특정 문구를 반복적으로 학습하면서 환각이 일반화될 수 있음.
3) 다양한 데이터 형식 간 불일치
- 자연어 요약, 데이터 기반 텍스트 생성(Data-to-Text Generation) 등의 작업에서는 구조적 데이터(예: 테이블, JSON)와 비구조적 텍스트(자연어) 간의 불일치가 있음.
- 실제 문제: 특정 표현이 의미적으로 연결되지 않은 상태에서 학습이 이루어질 경우 모델이 유사한 문장을 새로운 데이터에서도 반복적으로 생성할 수 있음.
(2) 모델 학습 및 추론 과정에서의 문제 (Training & Inference Issues)
1) 잘못된 표현 학습 (Imperfect Representation Learning)
- 인코더가 입력 문장을 잘못 해석하면, 잘못된 연관성을 학습하여 환각을 일으킬 수 있음.
- 예: 두 개의 개념이 함께 등장하는 경우, 모델이 이를 연관된 것으로 학습하여 새로운 문장에서 잘못된 결합을 생성할 가능성이 있음.
2) 잘못된 디코딩 전략 (Erroneous Decoding Strategies)
- Top-k 샘플링, Beam Search 등의 디코딩 기법이 모델의 환각을 증가시킬 가능성이 있음.
- 예: Top-k 샘플링을 사용하면 생성된 텍스트가 더 창의적일 수 있지만, 정확성이 떨어질 수 있음.
- 실제 문제: 디코딩 과정에서 원본 입력을 충분히 고려하지 못하고 높은 확률을 가진 단어만 반복적으로 선택하는 문제가 발생할 수 있음.
3) 노출 편향 (Exposure Bias)
- 훈련 중에는 항상 정답 데이터(ground-truth)를 기반으로 모델을 학습하지만, 실제 생성 과정에서는 자신이 생성한 출력을 기반으로 추론해야 함.
- 결과적으로, 모델이 한 번 실수를 하면 이후 생성된 문장 전체가 영향을 받을 가능성이 커짐.
4) 파라메트릭 지식 편향 (Parametric Knowledge Bias)
- 대형 언어 모델(LLM)이 훈련 데이터에서 습득한 정보를 원본 입력보다 더 신뢰할 가능성이 있음.
- 예: ChatGPT나 GPT-3 같은 모델이 훈련 데이터에서 학습한 정보를 기반으로 대답을 생성할 때, 입력된 정보와 다른 내용을 생성할 가능성이 있음.
2. 환각 평가 방법 (Measuring Hallucination)
환각을 평가하는 방법은 크게 자동 평가(Automatic Metrics)와 인간 평가(Human Evaluation)로 나뉜다.
(1) 자동 평가 방법 (Automatic Evaluation Metrics)
1) 통계적 지표 (Statistical Metrics)
- PARENT (Precision And Recall of Entailed n-grams)
- 생성된 문장과 원본 문장 간의 n-gram 일치도를 측정.
- 원본 데이터뿐만 아니라 정답(reference)도 함께 비교하여 환각 여부를 평가.
- Knowledge F1
- 대화 시스템에서 사용되며, 생성된 응답과 원본 지식 베이스 간의 일치도를 측정.
2) 모델 기반 지표 (Model-based Metrics)
- IE 기반 평가 (Information Extraction-based Metrics)
- 정보 추출(IE) 모델을 활용하여 생성된 문장에서 주요 개체(entity)와 관계를 추출하고, 원본 소스와 일치하는지 비교.
- QA 기반 평가 (Question Answering-based Metrics)
- 질문 생성(Question Generation) 모델과 질문 응답(Question Answering) 모델을 사용하여 생성된 문장이 원본 소스를 정확하게 반영하는지 평가.
- 자연어 추론(NLI, Natural Language Inference) 기반 평가
- 생성된 문장이 원본 소스를 기반으로 논리적으로 포함(entailment)되는지를 평가.
- 신경망 기반 평가 (Faithfulness Classification Metrics)
- 별도의 학습된 평가 모델을 사용하여 환각을 감지하는 방식.
3) 언어 모델 기반 평가 (Language Model-based Metrics)
- 두 개의 언어 모델을 사용하여 비교:
- 비조건적 언어 모델 (Unconditional LM): 원본 텍스트 없이 생성된 텍스트만 학습.
- 조건적 언어 모델 (Conditional LM): 원본 소스를 기반으로 생성된 텍스트 학습.
- 두 모델의 예측 차이를 비교하여 환각 가능성을 평가.
(2) 인간 평가 방법 (Human Evaluation)
기계적 평가의 한계를 극복하기 위해 전문 평가자가 직접 평가하는 방법이 사용된다.
1) 평가 기준
- 정확성(Accuracy): 생성된 문장이 원본 소스를 반영하는 정도.
- 사실성(Factuality): 문장이 사실에 근거하는 정도.
- 일관성(Consistency): 생성된 문장이 문맥적으로 자연스러운지 여부.
2) 평가 방식
- 점수 매기기 (Scoring): 1~5점 척도로 평가.
- 비교 평가 (Pairwise Comparison): 두 개의 생성된 문장을 비교하여 더 신뢰할 수 있는 문장을 선택.
3. 환각 측정 실험
논문에서는 환각을 측정하기 위한 실험을 진행했으며, 주요 결과는 다음과 같다.
(1) 기계 번역(NMT)에서의 환각 측정
- 의미적 일치도를 평가하는 BLEU 점수가 높더라도 환각이 발생할 수 있음.
- 특정 모델(Transformer 등)은 높은 유창성을 가지지만, 내용이 원본 소스와 일치하지 않는 경우가 많음.
(2) 요약(Abstractive Summarization)에서의 환각 측정
- NLI 모델을 사용하여 생성된 요약이 원본 텍스트와 논리적으로 연결되는지를 평가.
- QA 기반 평가 방법(예: QAGS, FEQA)을 적용하여 문장의 정확성을 측정.
(3) 대화 시스템(Dialogue Systems)에서의 환각 측정
- Knowledge F1 지표를 사용하여 생성된 응답과 원본 지식 베이스 간의 일치도를 평가.
결론
논문에서는 환각이 발생하는 주요 원인을 분석하고, 이를 평가하고 측정하는 다양한 방법을 제시하였다. 특히, 내재적 환각과 외재적 환각을 구분하여 평가하는 것이 중요하며, 이를 완화하기 위한 다양한 기술(강화 학습, 데이터 증강, 모델 아키텍처 개선 등)이 필요함을 강조하고 있다.
모델이 생성한 데이터와 학습한 데이터를 비교하려면, 모델이 어떤 데이터를 학습했는지 확인하는 방법이 필요하다. 하지만 대형 언어 모델(LLM)들은 수많은 문서를 기반으로 훈련되기 때문에 훈련 데이터 전체를 직접 확인하는 것은 현실적으로 어렵다. 따라서 연구자들은 다양한 기법을 활용하여 모델의 지식(훈련 데이터)과 생성된 데이터를 비교하는 방법을 개발했다.
1. 모델이 학습한 데이터를 알아내는 방법
훈련 데이터를 직접 확인할 수 없는 경우, 연구자들은 언어 모델이 내부적으로 어떤 지식을 가지고 있는지 추론하는 방법을 사용한다.
(1) 모델의 "파라메트릭 지식" 추출
- 대형 언어 모델(LLM)은 사전 학습(pretraining) 과정에서 엄청난 양의 데이터를 학습하지만, 어떤 지식을 학습했는지 명확하게 알기 어렵다.
- 이를 해결하기 위해 모델이 기억하고 있는 지식을 추출하는 실험이 수행된다.
- 대표적인 방법:
- 진실/거짓 질문 실험 (TruthfulQA, OpenBookQA): 모델이 "지구의 둘레는 몇 km인가?" 같은 질문에 정확히 답할 수 있는지 확인.
- Knowledge Probing (LAMA, KNOWLEDGE BASE COMPLETION): "파리의 수도는?" 같은 형식의 질문을 주고 모델이 내부적으로 학습한 지식을 확인.
(2) 모델이 학습한 데이터 복원 테스트 (Training Data Extraction)
- 연구자들은 모델이 훈련 데이터의 일부를 직접 복원할 수 있는지 테스트함.
- 예: GPT-3 모델에게 "The first sentence of the Wikipedia article about Albert Einstein is:"라고 입력하면, 실제 훈련 데이터에서 배운 문장을 출력하는지 확인.
- 관련 연구: Carlini et al. (2020)은 모델이 특정 훈련 데이터를 완전히 재현할 수 있음을 보여줌.
(3) 모델의 지식 경계(Boundary) 테스트
- 모델이 어디까지 알고 있고, 어디서부터는 모르는지를 파악하는 연구.
- 예: 최근 사건(예: 2023년 이후의 뉴스)이나 학습되지 않은 정보를 질문하여, 모델이 학습한 데이터 범위를 추정.
2. 모델이 생성한 데이터와 학습한 데이터를 비교하는 방법
위에서 추출한 모델의 지식과 실제 생성된 텍스트를 비교하는 방법에는 여러 가지가 있다.
(1) 사실 검증(Fact-checking)
- 외부 데이터베이스(Wikipedia, 뉴스, 지식 그래프 등)와 비교
- 생성된 텍스트를 인터넷 검색을 통해 검증 (예: Google Search API, Wikipedia API 활용).
- 자동화된 사실 검증 시스템 (FactScore, FactCheckQA) 사용.
- 지식 기반(Knowledge Graph)과 비교
- 모델이 생성한 문장이 지식 그래프(예: Wikidata, Freebase)와 일치하는지 확인.
- 예: "알버트 아인슈타인의 출생 연도는 1879년이다" → Wikidata에서 해당 사실을 찾고 비교.
(2) 훈련 데이터와의 직접 비교 (Memorization Detection)
- 모델이 특정 문장을 직접 암기한 경우를 탐지하는 기법.
- Methods:
- 출력된 문장과 기존 문서의 n-gram 일치율 측정 (예: ROUGE, BLEU).
- Embedding Similarity: 생성된 텍스트와 훈련 데이터 문서를 벡터화하여 코사인 유사도 계산.
(3) 모델 내부의 확률 정보(Probability-based Methods) 활용
- 모델이 특정 정보를 생성할 때 확신(confidence)을 가지고 있는지 평가.
- 생성된 문장의 각 단어에 대한 확률값을 분석하여 "불확실성이 높은 부분"을 환각 가능성이 높은 부분으로 판단.
3. 한계점 및 해결 방안
(1) 한계점
- 훈련 데이터 접근 제한
- OpenAI, Google, Meta 등은 훈련 데이터를 공개하지 않음.
- 연구자들은 모델이 어떤 데이터를 학습했는지 정확히 알기 어려움.
- 모델의 지식 업데이트 문제
- 언어 모델은 훈련된 이후 세상의 변화(새로운 사건, 과학적 발견 등)를 반영하지 못함.
- 예: ChatGPT-3는 2021년까지의 데이터만 학습했으므로, 이후 사건에 대한 정보가 없음.
- 허위 정보 생성 위험
- 모델이 자신이 모르는 질문에 대해서도 "확신 있는 답변"을 생성할 수 있음 → 이는 환각(hallucination) 문제로 이어짐.
(2) 해결 방안
- 검색 기반 생성 모델(Retrieval-Augmented Generation, RAG) 활용
- 모델이 훈련 데이터만을 기반으로 답변하는 것이 아니라, 실시간 검색(예: Google 검색, 위키피디아 조회)을 통해 최신 정보를 반영하도록 개선.
- 예: OpenAI의 WebGPT, Meta의 RETRO 모델.
- 자기 평가(Self-reflection) 기법
- 모델이 자신이 생성한 정보가 사실인지 스스로 검증하는 과정을 추가.
- 예: "이 정보의 출처는 어디인가?"라는 질문을 모델에게 다시 물어봄.
- LLM 기반 Fact-checking 시스템 도입
- GPT-4 같은 대형 모델을 이용해 생성된 텍스트를 검증하는 추가 평가 단계를 설계.
결론
- 모델이 생성한 텍스트와 학습한 데이터를 비교하는 것은 어려운 문제이지만, 다양한 방법(모델의 내부 지식 테스트, 사실 검증, 훈련 데이터 복원 테스트 등)을 활용하여 접근할 수 있다.
- 하지만 훈련 데이터에 대한 접근 제한, 모델의 정보 업데이트 문제 등으로 인해 완벽한 비교는 어려우며, 검색 기반 접근 방식(RAG)과 자기 평가 기법(Self-reflection)을 결합하여 해결해야 한다.
- 미래 연구 방향은 모델이 자신이 아는 것과 모르는 것을 구별하는 능력을 키우는 데 초점이 맞춰져야 한다.