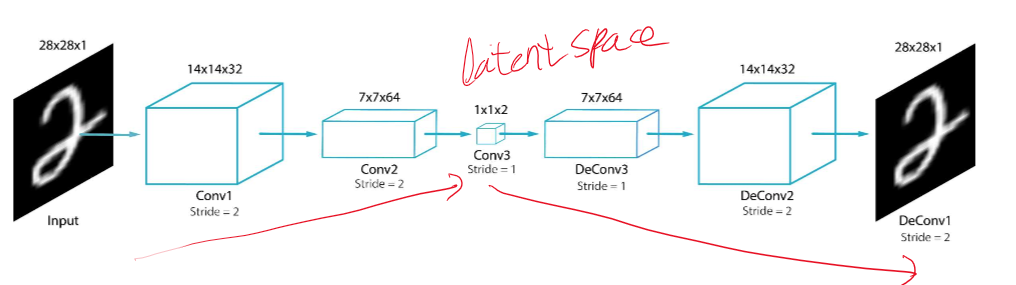
여태까지 FCN, CNN, CAM 모두 supervised learning였다. 즉 지도학습으로 input(data)와 정답(label)이 주어지는 학습이었다. 그러나 오늘 다룰 Autoencoder는 label이 없는 즉 정답이 input인 unsupervised learning이다. 나중에 나오겠지만 차원을 축소시켜 피쳐의 개수를 줄이고, 정보의 loss는 최대한 줄인다. 우린 encoder(z = f(x))와 decoder(x = g(z))로 나눌 수 있따. ( x = g(f(x))) 로스는 결과와 입력값의 차이를 제곱하는 mse와 비슷한 성격을 가지고 있다. latent space를 그래프로 표시하면 위와 같다. 여기서 점이 없는 부분을 decoder로 돌리면 없는 data를 생산할 수 있다. 그..