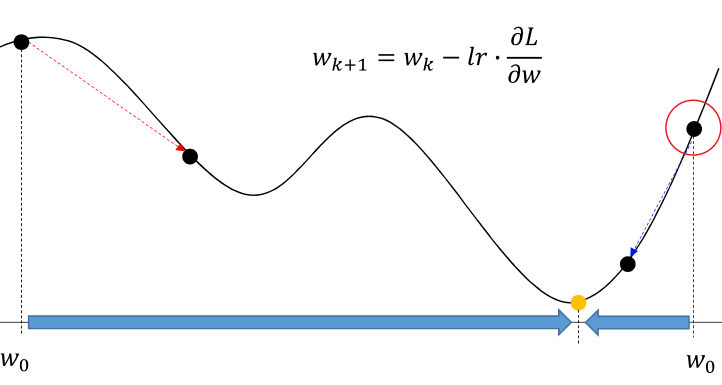
이 본문은 제가 복습하는 느낌으로 그냥 강의를 캡쳐한 것이라 실제 제가 한 것을 보고 싶다면 아래 링크로 가시면 됩니다. 2023.11.13 - [인공지능/공부] - Linear regression 1 Linear regression 1 import numpy as np import matplotlib.pyplot as plt # ==================== Part 1: Basic Function ==================== print('Running warmUpExercise ... ') print('5x5 Identity Matrix: ') def warmUpExercise(): return np.eye(5)# YOUR CODE HERE warmUpExercise( yoonscha..