머신러닝 3주차 2차시 - 특징 값 스케일링 내가 아는 스케일 - 값의 차이를 적당한 범위로 맞춰준다. 큰 값이 영향을 크게 주게 된다! 경사 하강법이 잘 적용되지 않을 수 있다. 그럼 최솟값이 안맞지 않나? Feature Scaling 밸런스를 가지도록 스케일링 한다! 평균 값을 빼주는 이유 : 특징 값이 좌우 균등하게 분포하도록! 스케일링 시 - 경사하강법이 빨라 질 수 있다. 분류 문제에서도 경사 하강법에 도움을 준다. 범위가 너무 다른 경우 적용한다! 인공지능/공부 2024.03.18
머신러닝 3주차 1차시 - 다 변수 선형 회귀 이전에는 엔진 파어만을 통해 자동차 가격을 예측했다. 비용함수를 최소화하는 값을 찾으면 그 값을 가설에 대입하면 끝이었다. 데이터는 205개가 주어졌다. cost function은 비슷하다. 그저 하나가 늘은 것 뿐이다. 변수가 여러가지라면 벡터로 표현하면 편하다. w*는 최적 값이다. 경사 하강법 변수가 한개일 경우 변수가 2개 이상일 경우 특징의 개수 - n 학습 데이터 개수 - m 데이터의 총 개수는 205개이다. w0는 바이어스 파라미터이다. -> x에 1을 하나 추가해준다. 이 것도 벡터화 시킬 수 있다. 우리 x0 = 1로 만들어서 굳이 안나눠도 되지 않나...? 인공지능/공부 2024.03.18
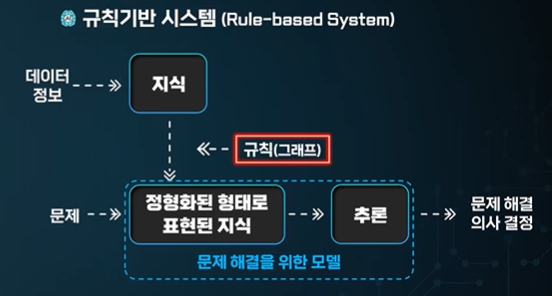
인공지능과 빅 데이터 3주차 3차시 - 규칙기반 시스템, 전문가 시스템 규칙 기반 시스템 - 특정 문제 해에 대한 전문가적인 답변을 준다. 정형화에는 규칙이 들어간다. 지식 베이스 - 사전에 알게된 정보 추론 규칙 - 지식 베이스를 기반으로 모르는 정보에 대한 정보를 알려준다. 추론 과정을 볼 수 있다. 추론을 통한 탐색 순방향 추론 = 방향성이 순 방향이다. 조건부 - 주어진 상황의 매칭 (많아지면 연산에 무리가 간다.) 역방향 추론 결론부부터 확인한다. 가설 - 사실을 가정한다. 순방향 추론 시작! 왼쪽은 조건부가 된다. 이번엔 역방향 추론으로 간다. 이 것을 보고 치타라는 가설을 세울 수 있다. 여기서 확인도 치타이다 부터 확인하기 시작한다. 전문가 시스템 Expert System - 전문가의 추론 과정을 시스템으로 옮긴 것이다. 질병 진단 전문가 시스템을 활용 -> .. 인공지능/공부 2024.03.18
인공지능과 빅 데이터 3주차 2차시 - 지식 표현과 추론, 지식 표현의 불확실성 논리를 이용한 지식 표현과 추론 명제 논리 - 참 거짓을 분명하게 판정할 수 있는 문장 논리 합, 곱, 부정 나오네요 술어 - 대상의 속성이나 대상 간의 관계를 함수 형태로 나타낸다. 인공지능은 논리를 바탕으로 추론해야 한다. 규칙을 이용한 지식 표현과 추론 규칙의 나열 - 조합하여 그래프로 표현할 수 있다. 그래프 표현이 직관적이고 쉽다. 의미망을 이용한 지식 표현과 추론 직접적인 연결은 없어도 상위 개념을 통해 연결되어 있다면 가능하다고 볼 수 있다. 팽귄이면 조류다. 조류는 알을 낳는다. 지식이 풍부해질 수록 연결이 더욱 많아진다. 지식을 그대로 글로 표현한 것은 활용하기에 굉장히 어렵다. 지식 표현의 불확실성 오리너구리가 예시가 될 수도 있겠네요 복잡한 대상, 지식 표현은 불확실한 것이 분명히 있.. 인공지능/공부 2024.03.18
인공지능과 빅 데이터 3주차 1 - 규칙 기반 시스템, 지식 기반 시스템 마이신 - 혈액 감염 진단과 치료를 위한 처방을 목적으로 하는 의학 전문가 시스템 의사 없이도 진단 및 판단을 한다. 규칙 기반 시스템의 대표적인 예시이다. 머신러닝 = 많은 데이터에서 규칙을 찾는다. 사람이 디자인 한다! -> 그럼 그게 인공지능인가? 주입하지 않은, 학습하지 않은 상황에 대해서도 대처를 한다. 스스로 추론을 통해 알아낸 것이다. 머신러닝은 데이터를 먼저 접근한다. 우유를 많이 먹었다면 그렇다라고 하겠죠 아주 단순한 기술엔 단순 프로그래밍 구현으로도 충분하다. 고차원 기능, 판단이 필요한 문제엔 AI가 활용된다. 딥페이크, 수많은 데이터 수집을 하기엔 Rule based AI를 활용하기엔 무리가 있다. 지식 - Rule based AI를 구축하는데 기반이 된다. 이것도 강화학습처럼 경험.. 인공지능/공부 2024.03.18
자연어 처리 python 실습 - 워드 임베딩 시각화 워드 임베딩 시각화 Introduction Chapter 4. 단어 임베딩 만들기 강의의 워드 임베딩 시각화 실습 강의입니다. 이전 실습에서처럼 (1) 단어 임베딩의 대표적인 방법인 Word2Vec을 활용하여 워드 임베딩을 직접 구축해보고, (2) 이번 실습에서는 구축한 워드 임베딩을 2차원으로 시각화하여 임베딩의 품질을 보다 정교하게 측정해보겠습니다. 이후 실습의 용이성을 위해 한국어 글꼴을 설치합니다! !sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf 1. 한국어 워드 임베딩 구축 워드 임베딩 구축 과정은 지난 실습에서 다뤘으므로, 이번 실습에서는 빠르게 구축을 진행해볼게요! 오늘 사용할 학습 데이터셋.. 인공지능/자연어 처리 2024.03.17
자연어 처리 python 실습 - 한국어 Word2Vec 임베딩 만들기 한국어 워드 임베딩 구축 Introduction Chapter 4. 단어 임베딩 만들기 강의의 첫 번째 실습 강의인 한국어 워드 임베딩 구축 강의입니다. 강의에서 배웠던 단어 임베딩의 대표적인 방법인 Word2Vec을 활용하여 영어와 한국어 워드 임베딩을 직접 구축해보고 임베딩의 품질을 평가합니다. 1. 영어 워드 임베딩 구축 한국어 워드 임베딩을 만들기 전에 영어 워드 임베딩을 구축하며 임베딩 구축에 대한 감을 익혀봅시다. 간단한 실습을 위해, scikit-learn 패키지에서 제공하는 20 newsgroup를 활용합니다. import pandas as pd import numpy as np from sklearn.datasets import fetch_20newsgroups dataset = fetc.. 인공지능/자연어 처리 2024.03.17
자연어 처리 python - 워드 임베딩 만들기 - GloVe 빈도기반 - 유의미한 단어의 변환이 있어도 유사도가 비슷하게 나온다. word2vec는 n을 설정하기 때문에 전체를 반영하지 못한다. 이럼 행렬이 엄청 커질거 같은데.... (중심)like 전체 등장 횟수중 (주변)deep과 등장한 횟수으로 1/3으로 봐서 동시 등장한 확률을 볼 수 있다. 결국 어떤 단어가 등장했을 때 어떤 단어가 등장할 확률을 구할 수 있다. 인공지능/자연어 처리 2024.03.17
자연어 처리 python - 워드 임베딩 만들기 - Fast Text 목표 - 대표적인 단어 임베딩 방법론인 FastText의 작동 원리를 이해할 수 있다. 여기서 n-gram은 단어단위 이다. 학습을 이전의 방식(skip gram)보다 훨씬 많이 할 수 있다. C = 주변 단어 유사도 = 코사인유사도 -> 단어에 대한 여러 벡터와 주변 단어 모든 벡터를 내적 여기선 분자를 최대화 해야 한다. -> 내적을 최소화 한다. 인공지능/자연어 처리 2024.03.16
딥러닝 개론 복습 1 딥러닝은 깊은 신경망이 있다는게 특징입니다. 이렇게 봐도 너무 애매한데 이럴때 GPT죠 여우와 토끼 사진을 구분한다고 할 때 머신러닝은 인간이 사진을 보고 사진에서 토끼의 귀 길이, 여우의 귀 길이, 색, 크기 등을 컴퓨터에 입력해줘야 하는거고 딥 러닝은 사진만 던져주면 알아서 하는거야? 네, 맞습니다! 머신러닝과 딥러닝을 여우와 토끼의 사진을 구분하는 상황으로 비교하면, 다음과 같이 설명할 수 있습니다: 머신러닝에서는 사람이 특징(feature)을 직접 정의하고 추출해야 합니다. 예를 들어, 여우와 토끼를 구분하기 위해 사람이 귀의 길이, 색, 크기 등을 사전에 정의한 특징으로 결정하고, 이 데이터를 기반으로 컴퓨터가 학습하여 여우와 토끼를 구분하게 됩니다. 이 과정에서 중요한 것은 얼마나 유의미하고 .. 인공지능/공부 2024.03.14