728x90
728x90
목표 - 대표적인 단어 임베딩 방법론인 FastText의 작동 원리를 이해할 수 있다.



여기서 n-gram은 단어단위 이다.
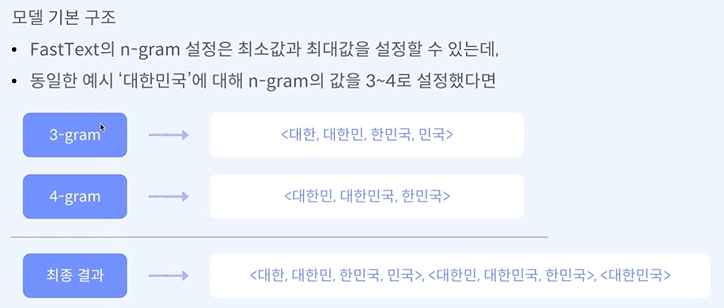


학습을 이전의 방식(skip gram)보다 훨씬 많이 할 수 있다.

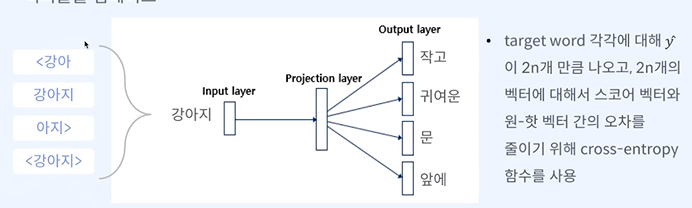

C = 주변 단어
유사도 = 코사인유사도 -> 단어에 대한 여러 벡터와 주변 단어 모든 벡터를 내적

여기선 분자를 최대화 해야 한다. -> 내적을 최소화 한다.







728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 python 실습 - 한국어 Word2Vec 임베딩 만들기 (0) | 2024.03.17 |
|---|---|
| 자연어 처리 python - 워드 임베딩 만들기 - GloVe (0) | 2024.03.17 |
| 자연어 처리 python - 워드 임베딩 만들기 - Word2Vec(CBOW, Skip-gram) (0) | 2024.03.13 |
| 자연어 처리 - 워드 임베딩 만들기 - 워드 임베딩이란? (0) | 2024.03.13 |
| 자연어 처리 python 실습 - BERT 모델의 임베딩 간 유사도 측정 (0) | 2024.03.13 |