728x90
728x90




희소 벡터의 문제를 해결!


기본적인 분포 가설이다.

CBOW - 주변 단어를 보고 학습 단어를 배우겠다.
skip -gram - 중심 단어를 보고 주변 단어를 배우겠다.


토큰화를 잘 하기 위해 강아지가 -> 강아지

학습데이터도 늘리고, 관계도 만들 수 있다.

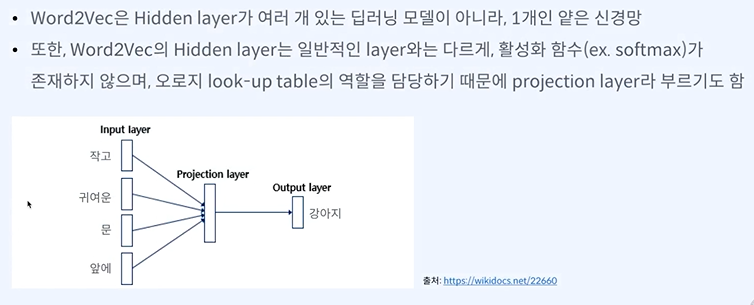
딥러닝이 아니라 하나의 앝은 레이어를 가진 머신러닝이라고 볼 수 있다.
단순한 원 핫 벡터를 사용한다.
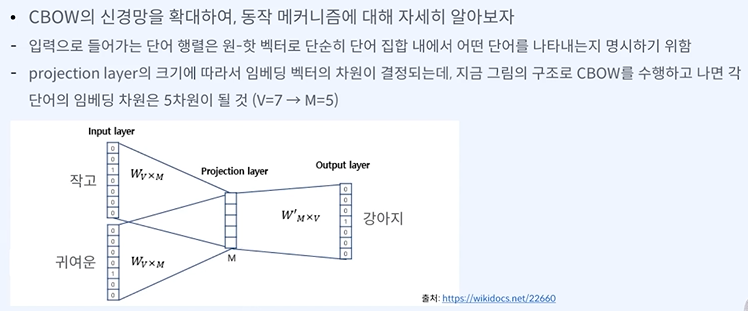
인풋 레이어에서 프로젝션 레이어로 어떻게 메핑할까가 중요하다.










여기선 강아지를 보고 작고, 귀여운, 문, 앞에가 나와야 한다.


학습기회가 많아짐으로써 조정, 오차 잡는 것을 따라잡을 수 없다.

중의성, 모호성을 많이 녹여내진 못했다.
학습데이터에 없다면 학습하기 어렵다.
새로운 단어가 생기면 재 학습해야 한다.


빈도가 적으면 단어를 확실하게 학습하고, 빈도수가 높으면 학습에서 제외하거나 횟수를 제한할 수 있다.

은, 는 것이다.



뽑기만 하면 되니까 효율적이다.


728x90
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 python - 워드 임베딩 만들기 - GloVe (0) | 2024.03.17 |
|---|---|
| 자연어 처리 python - 워드 임베딩 만들기 - Fast Text (0) | 2024.03.16 |
| 자연어 처리 - 워드 임베딩 만들기 - 워드 임베딩이란? (0) | 2024.03.13 |
| 자연어 처리 python 실습 - BERT 모델의 임베딩 간 유사도 측정 (0) | 2024.03.13 |
| 임베딩이란 ? - 임베딩 간 유사도 계산 (0) | 2024.03.07 |