https://arxiv.org/abs/2404.01037
ARAGOG: Advanced RAG Output Grading
Retrieval-Augmented Generation (RAG) is essential for integrating external knowledge into Large Language Model (LLM) outputs. While the literature on RAG is growing, it primarily focuses on systematic reviews and comparisons of new state-of-the-art (SoTA)
arxiv.org
이 논문은 RAG 기술을 체계적으로 비교하며, 검색 정확도와 답변 유사성이라는 명확한 지표를 통해 RAG 시스템의 성능을 정량적으로 평가
특히, HyDE와 Sentence Window Retrieval의 조합이 높은 검색 정확도를 기록하며, 기존 Naive RAG 시스템 대비 명확한 성능 개선을 입증
Multi-query와 MMR처럼 기대 이하의 성능을 보인 기술들도 분석하며, 연구의 한계를 정직하게 드러낸 점은 신뢰 업
또한, GPT-4를 활용한 QA 데이터 생성과 사람 검토를 병행해 평가 데이터의 신뢰도를 높인 점이 참신
이 연구는 단순히 기술을 비교하는 데 그치지 않고, RAG 시스템의 실질적인 개선 가능성과 방향성을 제시하려는 문제 해결 중심의 접근이 돋보임
다만, 데이터셋과 모델의 제약으로 인해 결과의 일반화 가능성에 한계가 있음을 보완하기 위한 후속 연구가 필요
| 연구 목적 | 다양한 Retrieval-Augmented Generation (RAG) 기술 간 성능 비교를 통해 검색 정확도(Retrieval Precision)와 답변 유사성(Answer Similarity) 개선 방안을 탐구. |
| 데이터 | - 423개 논문(AI ArXiv 데이터셋) 사용. - 13개 핵심 논문과 410개 노이즈 데이터로 구성. - 질문-답변(QA) 데이터: 107개 쌍 (GPT-4 생성 후 검토). |
| 주요 RAG 기술 | - Sentence-window Retrieval: 검색 정확도는 높지만 답변 유사성에서 약점. - HyDE (Hypothetical Document Embedding): 검색 정밀도 향상. - LLM Rerank: 검색 재정렬 성능 우수. |
| 평가 기준 | - Retrieval Precision: 검색된 청크의 관련성 (0~1 점수). - Answer Similarity: 생성된 답변과 기준 답변의 유사성 (0~5 점수). |
| 결과 요약 | - HyDE + LLM Rerank 조합: 최고 성능 기록 (검색 정확도). - Sentence-window Retrieval: 검색 단계에서 우수하지만 답변 생성 단계에서 부족. - MMR과 Cohere Rerank: 기대 이하 성능. |
| 한계 | - 단일 데이터셋과 제한된 질문-답변 세트. - GPT-3.5-turbo 사용으로 평가 모델의 한계. - 서로 다른 청크 전략으로 직접 비교의 어려움. |
| 미래 연구 방향 | - 지식 그래프 통합: 검색 정밀도 개선. - Unfrozen RAG 시스템: 특정 데이터셋에 최적화. - Auto-RAG: RAG 구성 요소 자동 최적화. - 다양한 데이터셋에서의 검증. |
| 연구 기여 | - RAG 기술의 정량적 평가 및 성능 비교 데이터 제공. - 연구 재현성을 위한 실험 코드 공개(GitHub: ARAGOG). |
| 결론 | - HyDE와 LLM Rerank는 검색 성능을 효과적으로 개선하지만, 처리 지연과 비용 증가. - Sentence-window Retrieval은 검색에서 강점, 답변 생성 단계는 추가 개선 필요. |

이 Figure는 Retrieval-Augmented Generation (RAG) 시스템의 전반적인 워크플로우를 시각적으로 나타냅니다. 각 단계는 사용자 입력에서 시작하여 최종 응답 생성까지 이어지는 과정을 설명합니다.
워크플로우 설명
- User (사용자):
- Input query: 사용자가 시스템에 입력하는 질문이나 요청.
예: "What are the benefits of using RoBERTa over BERT?"
- Input query: 사용자가 시스템에 입력하는 질문이나 요청.
- System (시스템):
- Retrieve relevant documents:
입력된 질문(query)에 따라 관련 문서를 데이터베이스에서 검색.
예: 질문에 적합한 문서 청크를 벡터화 후 검색. - Return documents:
검색된 문서가 시스템으로 반환됨.
예: "RoBERTa 논문에서 Next Sentence Prediction 제거 관련 내용."
- Retrieve relevant documents:
- Database (데이터베이스):
- 시스템이 필요한 문서를 보유한 데이터 저장소.
- RAG 시스템은 데이터베이스에서 벡터 검색과 같은 기술을 활용하여 적합한 정보를 찾음.
예: 벡터 기반 유사도 검색 수행.
- Generator (응답 생성기):
- Generate response based on documents and query:
검색된 문서와 입력 질문을 결합하여 답변 생성.
예: GPT-3.5 또는 GPT-4를 사용해 질문에 대한 적절한 응답 생성. - Return generated response:
생성된 답변이 사용자에게 반환됨.
예: "RoBERTa removes Next Sentence Prediction for better efficiency."
- Generate response based on documents and query:
이 Figure가 의미하는 주요 RAG 시스템 특징
- Retrieval Precision과 Answer Similarity를 높이기 위한 각 단계가 분명히 정의됨.
- 검색 단계 (Retrieval)와 생성 단계 (Generation)의 분리:
이는 검색과 생성이 각각 최적화될 수 있도록 구조를 설계한 결과. - 데이터베이스와 시스템 간 상호작용:
시스템이 효율적으로 정보를 검색하고, 생성기(generator)가 문맥과 질문을 결합하여 응답 생성.
이 Figure는 RAG 기술의 핵심 구조를 시각적으로 간단히 설명하며, 검색과 생성의 분리, 데이터 흐름, 그리고 최종 응답 생성 과정을 명확히 보여줍니다. 추가적인 세부 사항이 필요하다면 말씀해주세요!
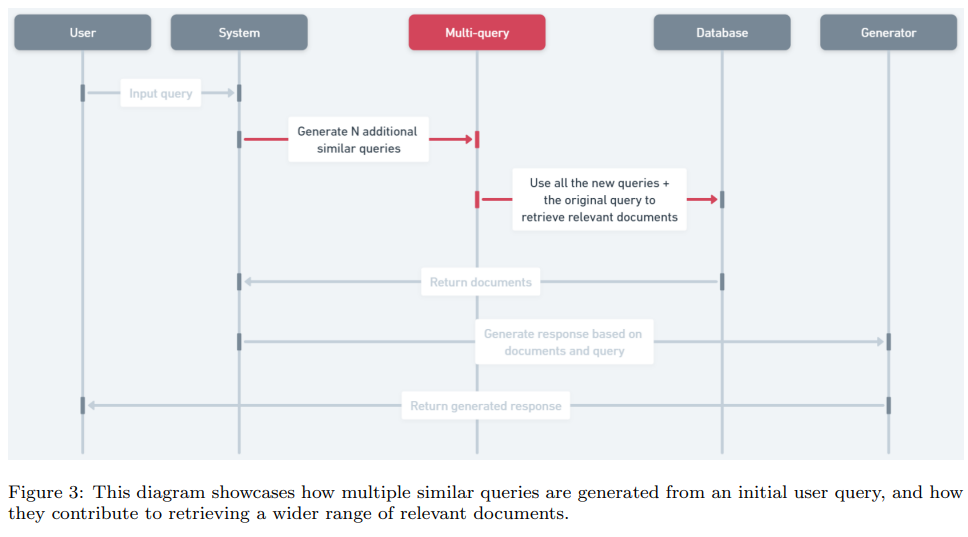
이 Figure는 Multi-query Retrieval 기법의 전체적인 과정을 시각적으로 보여줍니다. Multi-query Retrieval은 사용자의 단일 입력 질문(query)을 여러 유사한 질문들로 확장하여 더 넓고 포괄적인 검색을 가능하게 하는 RAG 기술 중 하나입니다. 아래는 각 단계에 대한 설명입니다.
워크플로우 단계
- User (사용자):
- Input query: 사용자가 시스템에 입력하는 원본 질문.
예: "What improvements does RoBERTa make over BERT?"
- Input query: 사용자가 시스템에 입력하는 원본 질문.
- System (시스템):
- Generate N additional similar queries:
- 입력된 질문에 대해 N개의 유사 질문을 생성. 이 과정은 LLM을 활용하여 다양한 관점에서 질문을 확장.
예:- 원본 질문: "What improvements does RoBERTa make over BERT?"
- 확장된 질문:
- "How is RoBERTa different from BERT?"
- "What are the main changes introduced in RoBERTa?"
- "How does RoBERTa optimize pretraining compared to BERT?"
- 입력된 질문에 대해 N개의 유사 질문을 생성. 이 과정은 LLM을 활용하여 다양한 관점에서 질문을 확장.
- Use all the new queries + the original query to retrieve relevant documents:
- 생성된 모든 질문(N개의 유사 질문 + 원본 질문)을 사용하여 데이터베이스에서 관련 문서를 검색.
- 이는 단일 질문으로 수행한 검색보다 더 광범위하고 다양한 관련 문서를 포함하도록 설계.
- Generate N additional similar queries:
- Database (데이터베이스):
- 입력된 여러 질문(query)을 기반으로 관련 문서들을 검색하고, 해당 문서를 시스템으로 반환.
- Generator (응답 생성기):
- Generate response based on documents and query:
검색된 문서와 원본 질문을 기반으로 답변을 생성.
예: "RoBERTa removes the next sentence prediction task and adopts dynamic masking for pretraining." - Return generated response:
생성된 답변이 사용자에게 반환.
- Generate response based on documents and query:
Multi-query Retrieval의 특징
- 검색 다각화: 하나의 질문이 아닌 여러 유사 질문을 통해 더 넓은 범위의 문서를 검색.
이는 단일 질문이 놓칠 수 있는 중요한 정보를 포괄적으로 포함할 가능성을 높임. - LLM의 역할: LLM이 입력 질문의 의도를 다양한 방식으로 재구성하여 보다 정교한 검색을 가능하게 함.
- 효율성과 비용 문제: 질문이 여러 개로 확장되므로, 검색 비용과 처리 시간이 증가할 수 있음.
Figure의 의미
이 Figure는 Multi-query Retrieval이 단일 질문 기반 검색과 비교해 어떻게 더 다양한 관련 문서를 검색하고, 이를 통해 최적의 응답을 생성할 수 있는지를 명확히 보여줍니다. 그러나 추가적인 LLM 호출과 데이터 처리로 인해 효율성 문제를 고려해야 함을 시사합니다.
궁금한 점이 더 있거나 다른 기술과 비교가 필요하다면 말씀해주세요!

이 Figure는 Retrieval-Augmented Generation (RAG) 시스템에서 재정렬(reranking) 프로세스를 시각적으로 보여줍니다. 재정렬 단계는 검색된 문서들 중 가장 관련성이 높은 문서를 선별하여 응답 생성의 품질을 향상시키는 데 중점을 둡니다. 아래는 각 단계에 대한 설명입니다.
워크플로우 단계
- User (사용자):
- Input query: 사용자가 입력하는 질문.
예: "What are the main improvements introduced in RoBERTa?"
- Input query: 사용자가 입력하는 질문.
- System (시스템):
- Retrieve k documents:
데이터베이스에서 k개의 관련 문서를 검색.
예: 질문과 가장 관련성이 높은 상위 10개의 문서를 검색. - 검색된 문서는 전문적으로 정렬되지 않은 상태로 반환됨.
- Retrieve k documents:
- Reranker (재정렬 단계):
- Send k documents for reranking:
검색된 문서(k개)를 재정렬 알고리즘에 입력.- 재정렬 과정에서는 ML 모델(예: cross-encoder 기반 reranker 또는 LLM 기반 reranker)을 사용하여 문서의 관련성을 재평가.
- Return n best documents:
가장 관련성이 높은 상위 n개의 문서를 반환(일반적으로 n ≤ k).
예: 질문에 가장 적합한 상위 5개 문서를 선정.
- Send k documents for reranking:
- Generator (응답 생성기):
- Generate response based on documents and query:
재정렬된 문서와 질문을 기반으로 최종 응답 생성.
예: "RoBERTa improves over BERT by removing next sentence prediction and adopting dynamic masking." - Return generated response:
생성된 응답이 사용자에게 반환.
- Generate response based on documents and query:
재정렬(Reranking)의 역할
- 검색 품질 향상:
- 단순 검색 결과는 노이즈 데이터나 덜 관련된 문서를 포함할 수 있음.
- 재정렬을 통해 문서의 관련성을 재평가하고, 최적의 문서를 선별함으로써 응답 품질을 높임.
- 효율성 보장:
- n개의 최적 문서만 최종 응답 생성에 활용함으로써, 생성 단계의 연산 비용을 줄임.
Reranking 기술의 예
- Cohere Re-ranker:
- 문서와 질문을 교차 인코더(Cross-encoder)로 처리하여 재정렬.
- 문서와 질문을 함께 분석해 더 정교한 문맥 평가를 수행.
- LLM-based Re-ranker:
- 대형 언어 모델(예: GPT-3.5 또는 GPT-4)을 활용하여 검색된 문서의 관련성을 평가.
- 고비용이지만 높은 정확도를 보임.
Figure의 주요 의미
- 이 Figure는 RAG 시스템에서 단순 검색 결과를 재정렬하여 관련성이 가장 높은 문서를 선택하는 과정을 보여줍니다.
- 재정렬 단계는 응답 생성의 품질을 크게 개선하며, 검색과 생성의 중간 단계로 문서 선택의 정밀도를 높이는 핵심 기술임을 강조합니다.
궁금한 점이 더 있으시면 알려주세요!

이 Figure는 AI ArXiv 데이터셋 준비 과정을 시각적으로 나타냅니다. 논문에서 사용된 데이터셋 구성, 질문-답변(QA) 생성 및 검토 과정, 그리고 문서 청크(chunking) 전략을 포함한 데이터 준비 단계들을 체계적으로 보여줍니다. 아래는 각 세부 요소에 대한 설명입니다.
AI ArXiv 데이터셋 준비 과정
- Full Dataset (전체 데이터셋):
- 총 423개 논문으로 구성된 데이터셋.
- 주제: 대형 언어 모델(LLM)과 인공지능(AI).
- 출처: Hugging Face를 통해 공개된 데이터셋 사용.
- 이 데이터셋은 노이즈 데이터로 활용되어 검색의 복잡성을 증가시키고, RAG 시스템의 성능을 더 현실적으로 평가.
- 총 423개 논문으로 구성된 데이터셋.
- Question-Answer Pairs (질문-답변 쌍 생성):
- 13개 핵심 논문(원본 데이터셋에서 선택) 기반으로 QA 데이터 생성.
- 핵심 논문 예: "RoBERTa: A Robustly Optimized BERT Pretraining Approach."
- 질문-답변 생성 과정:
- GPT-4를 사용해 고품질 질문-답변 쌍을 자동 생성.
- 생성된 QA 데이터는 사람 검토를 거쳐 정확성과 관련성을 확인.
예: "What is the main improvement in RoBERTa?" → "RoBERTa removes next sentence prediction and adopts dynamic masking."
- 13개 핵심 논문(원본 데이터셋에서 선택) 기반으로 QA 데이터 생성.
- Chunking Approach (문서 분할 전략):
- 검색과 문서 처리 효율성을 높이기 위해 다양한 청크 생성 전략을 적용.
- TokenTextSplitter:
- 벡터 데이터베이스용으로 512 토큰 크기로 분할, 50 토큰 중첩.
예: "RoBERTa improves over BERT by removing next sentence prediction."
- 벡터 데이터베이스용으로 512 토큰 크기로 분할, 50 토큰 중첩.
- SentenceWindowNodeParser:
- 문장 기반으로 윈도우 크기 3으로 청크 생성.
예: "Dynamic masking is applied. This optimizes pretraining. Larger mini-batches are used."
- 문장 기반으로 윈도우 크기 3으로 청크 생성.
- TokenTextSplitter with larger chunks:
- 문서 요약 인덱스 생성을 위해 3072 토큰 크기로 더 큰 청크를 생성.
- TokenTextSplitter:
- 검색과 문서 처리 효율성을 높이기 위해 다양한 청크 생성 전략을 적용.
Figure의 주요 메시지
- 전체 데이터 구성과 핵심 논문 활용:
- 423개의 전체 논문 중 일부(13개)는 핵심 QA 생성을 위한 고품질 데이터로 활용, 나머지는 검색 노이즈로 포함.
- 이 과정은 현실적인 RAG 시스템 평가를 위한 데이터 준비의 중요성을 강조.
- 질문-답변 쌍의 품질 관리:
- 질문-답변 쌍은 자동화된 GPT-4 생성과 사람 검토를 통해 고품질 QA 세트를 보장.
- 문서 분할의 유연성:
- 다양한 청크 전략을 사용하여 RAG 기술에 맞춘 최적의 검색 및 처리 방식을 설계.
이 Figure는 RAG 시스템 연구에서 데이터 준비의 중요성과 전략적 접근 방식을 강조하며, 실험 환경의 현실성을 높이기 위한 세부적인 절차를 시각적으로 명확히 나타냅니다. 추가 질문이 있으시면 언제든 말씀해주세요!

이 Figure는 Retrieval-Augmented Generation (RAG) 시스템에서 평가 프로세스를 나타냅니다. 각 청크(chunk)의 관련성을 평가하여 전체 검색 정확도(Retrieval Precision)를 계산하는 방법을 단계별로 보여줍니다. 아래는 Figure에 대한 상세 설명입니다.
워크플로우 단계
- Send evaluation question to system (평가 질문 입력):
- 시스템에 평가 질문이 입력됩니다.
예: "What are the improvements in RoBERTa over BERT?"
- 시스템에 평가 질문이 입력됩니다.
- System returns k chunks (시스템이 k개의 청크 반환):
- RAG 시스템은 데이터베이스에서 검색된 k개의 청크를 반환합니다.
예: 3개의 청크가 반환될 경우:- 청크 1: "RoBERTa removes the next sentence prediction task."
- 청크 2: "Dynamic masking is applied to improve pretraining efficiency."
- 청크 3: "Larger mini-batches are used during training."
- RAG 시스템은 데이터베이스에서 검색된 k개의 청크를 반환합니다.
- Each chunk evaluated for relevancy (청크별 관련성 평가):
- 반환된 각 청크가 질문과 얼마나 관련성이 있는지 평가됩니다.
- 관련성 점수: 0 (무관함) 또는 1 (관련 있음)로 부여.
- 청크 1: 관련성 점수 1
- 청크 2: 관련성 점수 1
- 청크 3: 관련성 점수 0
- Calculate retrieval precision (검색 정확도 계산):
- 검색 정확도 = 관련 청크 수 / 총 청크 수로 계산됩니다.
예: 관련 청크 2개 / 반환된 총 청크 3개 → 검색 정확도 = 0.67.
- 검색 정확도 = 관련 청크 수 / 총 청크 수로 계산됩니다.
- Repeat for all questions in dataset (데이터셋의 모든 질문에 대해 반복):
- 동일한 평가 프로세스를 데이터셋의 모든 질문에 대해 반복합니다. 예: 107개의 질문-답변(QA) 쌍에 대해 각 질문의 검색 정확도를 개별적으로 계산.
- Calculate mean of retrieval precision scores (평균 검색 정확도 계산):
- 모든 질문의 검색 정확도를 평균하여 최종 검색 정확도를 산출. 예:
- 질문 1의 검색 정확도: 0.67
- 질문 2의 검색 정확도: 0.80
- 질문 3의 검색 정확도: 0.75
→ 최종 검색 정확도 = (0.67 + 0.80 + 0.75) / 3 = 0.74
- 모든 질문의 검색 정확도를 평균하여 최종 검색 정확도를 산출. 예:
평가 프로세스의 주요 특징
- 관련성 점수 기반 평가:
- 각 청크가 질문과 직접적으로 연관이 있는지 평가.
- 간단한 점수 체계(0 또는 1)를 통해 명확성과 효율성을 보장.
- 검색 정확도 산출:
- 검색된 청크 중 실제로 유용한 청크의 비율을 정량적으로 측정.
- 시스템의 검색 성능을 명확히 이해하는 데 유용.
- 전체 데이터셋에 대한 반복:
- 특정 질문에 국한되지 않고, 데이터셋 전반에 걸쳐 평가하여 RAG 시스템의 전반적인 성능을 측정.
Figure의 의미
- 이 Figure는 RAG 시스템의 검색 능력을 평가하기 위한 구조적이고 체계적인 프로세스를 시각적으로 명확히 보여줍니다.
- 평가 결과는 RAG 기술 간 비교나 검색 알고리즘 개선의 기준이 됩니다.
- 단순하지만 효과적인 평가 방식으로, 검색 정확도를 정량적으로 분석하는 데 중점을 둡니다.
궁금한 점이나 추가 설명이 필요하면 말씀해주세요!

이 Figure는 실험별 검색 정확도(Retrieval Precision)의 분포를 보여주는 Boxplot입니다. 각 실험에서 사용된 다양한 RAG 기술의 검색 정확도 성능을 비교하기 위해 작성되었습니다. 이 그래프는 중앙값(median), 분산(range), 그리고 상자 크기(사분위수 범위, IQR)를 통해 RAG 기술의 성능 및 일관성을 평가합니다.
Figure의 주요 구성 요소
- Y축 (Experiment):
- 다양한 RAG 기술과 조합을 나타냅니다.
- 기술 조합 예:
- Classic VDB + Naive RAG: 가장 기본적인 검색 방법.
- Sentence Window Retrieval + LLM Rerank: 문장 기반 검색과 LLM 기반 재정렬 조합.
- Document Summary Index + Cohere Rerank: 문서 요약 인덱스를 사용한 검색과 Cohere 재정렬.
- X축 (Retrieval Precision):
- 검색 정확도 점수(0~1)로, 값이 클수록 검색된 컨텍스트가 질문과 더 높은 관련성을 가짐.
- Boxplot의 구성:
- 중앙값(Median): 상자의 가운데 선으로, 해당 실험의 검색 정확도의 중간값.
- 사분위수 범위(IQR): 상자의 위아래 경계로, 데이터의 1사분위수(Q1)와 3사분위수(Q3) 범위.
- Whisker(수염): 중앙값에서 벗어난 데이터 분포를 나타냄.
- Outliers(이상값): 수염 범위 밖의 값으로, 비정상적으로 높거나 낮은 검색 정확도를 의미.
Figure 분석
- Classic VDB 기반 기술:
- Naive RAG: 검색 정확도가 가장 낮은 수준 (~0.65).
이는 가장 기본적인 RAG 접근 방식으로, 추가적인 기술이 적용되지 않음. - HyDE, Cohere Rerank, LLM Rerank와의 조합:
- 검색 정확도가 눈에 띄게 향상(~0.75).
- 특히 LLM Rerank와 HyDE 조합이 Naive RAG 대비 우수한 성능을 보임.
- Naive RAG: 검색 정확도가 가장 낮은 수준 (~0.65).
- Sentence Window Retrieval 기반 기술:
- Sentence Window Retrieval 자체:
- 기본적으로 높은 검색 정확도 (~0.85).
- 문장 기반 검색은 높은 관련성을 가진 컨텍스트를 선택하는 데 강점을 가짐.
- LLM Rerank, HyDE와의 조합:
- 검색 정확도가 더욱 증가(~0.90).
- 상자 크기가 작아 일관된 성능을 보여줌.
- Sentence Window Retrieval 자체:
- Document Summary Index 기반 기술:
- Cohere Rerank와 조합하여 ~0.85의 검색 정확도를 보임.
- 하지만 Sentence Window Retrieval 조합보다는 약간 낮은 성능.
- Multi-query와 MMR:
- Multi-query + Reciprocal:
- 검색 정확도가 Naive RAG보다 낮거나 유사 (~0.70).
- 다중 쿼리를 사용하는 방식의 효과가 기대보다 미흡.
- Maximal Marginal Relevance (MMR):
- 유사하게 Naive RAG 대비 큰 성능 개선이 보이지 않음.
- Multi-query + Reciprocal:
주요 관찰
- 최고 성능 조합:
- Sentence Window Retrieval + LLM Rerank 및 Sentence Window Retrieval + HyDE는 검색 정확도와 성능 일관성에서 가장 우수.
- 기본 기술(Naive RAG):
- 검색 정확도가 가장 낮으며, 추가 기술 적용의 필요성을 강조.
- 기술 조합 효과:
- HyDE와 LLM Rerank는 여러 조합에서 검색 정확도를 크게 개선.
- Multi-query와 MMR은 기대 이하의 성능을 보여 추가 개선 필요.
Figure의 의미
이 그래프는 다양한 RAG 기술의 검색 정확도 성능을 체계적으로 비교하며, 성능 개선을 위한 유망한 기술 조합(Sentence Window Retrieval, HyDE, LLM Rerank 등)을 제안합니다. 또한, Multi-query와 MMR과 같은 기술은 효율성을 높이기 위해 추가 연구와 개선이 필요하다는 점을 시사합니다.
추가 설명이 필요하거나 특정 기술에 대해 더 알고 싶으시면 말씀해주세요!
1. 연구 문제 정의
RAG (Retrieval-Augmented Generation)는 대형 언어 모델(LLM)이 외부 지식을 통합하여 더 나은 응답을 생성하도록 돕는 기술입니다. 기존 연구는 새로운 RAG 기술의 도입과 이전 모델과의 비교에 초점이 맞춰져 있었으나, 다양한 RAG 기술 간의 실험적 비교는 부족한 상황입니다. 본 연구는 이를 해결하기 위해 여러 RAG 기술과 조합의 성능을 정량적으로 평가하며, 특정 RAG 기술의 장단점을 분석합니다.
2. 연구 목적
- 다양한 RAG 기술의 Retrieval Precision(검색 정확도)과 Answer Similarity(답변 유사성)를 비교.
- 각 기술의 조합 효과를 확인하고, 실제 응용에 적합한 기술을 제안.
- 기존 Naive RAG 시스템 대비 개선 방안을 제시.
3. 주요 RAG 기술
- Sentence-window Retrieval: 단일 문장을 중심으로 검색 정확도를 높이고, 생성 시에는 문맥을 확장.
- Document Summary Index: 문서 요약을 통해 검색 효율성을 향상시키는 방식.
- HyDE (Hypothetical Document Embedding): 질문에 대한 가상의 답변을 생성하여 검색 결과를 정제.
- Multi-query: 질문을 다양한 각도로 변형해 검색 범위를 확장.
- Maximal Marginal Relevance (MMR): 검색 결과의 다양성과 관련성 간 균형 유지.
- Cohere Rerank 및 LLM Rerank: ML 모델과 LLM을 활용하여 검색 결과를 재정렬.
4. 실험 방법
- 데이터셋: AI 관련 논문(423개)에서 13개의 핵심 논문을 중심으로 데이터베이스 구성.
- 평가 기준:
- Retrieval Precision: 검색된 컨텍스트의 정확도를 0~1 사이 점수로 평가.
- Answer Similarity: 생성된 답변과 기준 답변 간 유사성을 0~5 점수로 평가.
- LLM 선택: OpenAI의 GPT-3.5-turbo 사용(비용 효율성을 고려).
- 평가 반복성: 실험은 기술별로 10회 반복 실행하여 변동성을 최소화.
- 통계 분석: ANOVA와 Tukey의 HSD 테스트를 통해 성능 차이를 검증.
5. 주요 결과
- Retrieval Precision:
- Sentence-window Retrieval는 높은 검색 정확도를 기록했지만, 답변 유사성은 낮음.
- HyDE와 LLM Rerank 조합이 가장 우수한 검색 성능을 보임.
- MMR과 Cohere Rerank는 Naive RAG와 비교해 유의미한 개선을 보이지 않음.
- Multi-query는 예상 외로 Naive RAG보다 낮은 성능을 기록.
- Answer Similarity:
- 검색 정확도가 높아도 생성된 답변이 기준 답변과 항상 일치하지 않음.
- Sentence-window Retrieval는 정확한 정보를 검색했지만, 이를 답변 생성에 효과적으로 활용하지 못하는 한계를 보임.
6. 한계
- 데이터셋과 질문 범위가 제한적이므로 결과의 일반화에 한계가 있음.
- GPT-3.5-turbo 대신 더 고급 모델(GPT-4)을 사용할 경우 더 나은 결과를 도출할 가능성.
- 각 기술의 성능이 문서 분할 방식에 크게 의존하여 직접적인 비교에 어려움 존재.
7. 결론 및 미래 연구 방향
- 결론:
- HyDE와 LLM Rerank는 검색 성능 향상에 기여하지만, 비용과 처리 시간이 증가.
- Sentence-window Retrieval는 검색 정확도가 높으나, 답변 생성 단계에서 약점 존재.
- Document Summary Index는 Naive RAG보다 우수했으나 추가 개선 필요.
- 미래 연구 방향:
- 지식 그래프(Knowledge Graph) 통합: 검색 정확도와 문맥성을 높이는 데 잠재력 확인.
- Unfrozen RAG 시스템: 데이터셋에 맞춰 RAG 구성요소를 세부적으로 튜닝.
- 자동 최적화(Auto-RAG): RAG 구성 요소(분할 전략, 윈도 크기 등)를 자동으로 최적화하는 시스템 탐구.
8. 연구 기여
본 연구는 RAG 기술의 성능을 정량적으로 평가하고, 향후 연구 및 실용적인 RAG 시스템 개발의 기반을 제공
방법론
1. 데이터셋 준비
1.1 데이터 구성
- 논문에서 사용된 데이터는 AI ArXiv 데이터셋으로, Hugging Face에서 제공하는 423개 논문으로 이루어져 있습니다.
- 실험을 위해 데이터베이스를 13개 핵심 논문(예: RoBERTa, BERT)으로 축소하였으며, 나머지 410개 논문은 노이즈 데이터로 포함하였습니다. 이를 통해 실제 환경에서 흔히 발생하는 검색 복잡성과 정확도 저하 문제를 시뮬레이션했습니다.
예시:
"RoBERTa: A Robustly Optimized BERT Pretraining Approach" 논문이 데이터베이스에 포함되었으며, 사용자가 "What are the improvements in RoBERTa over BERT?"라는 질문을 했을 때 적절한 답변을 생성하는 것을 목표로 설정.
1.2 데이터 분할 (Chunking Approach)
- 검색 효율성을 높이고 문맥을 유지하기 위해 다양한 문서 분할 전략을 활용.
- 클래식 분할: 512 토큰 크기로 문서를 분할, 50 토큰의 중첩을 추가.
- 문장 윈도우(Sentence Window): 3개의 연속된 문장을 하나의 청크로 설정.
- 문서 요약(Document Summary Index): 3072 토큰 크기로 큰 청크를 생성하고 요약본을 생성.
예시:
"RoBERTa 논문"이 다음과 같이 분할됩니다.
- 클래식 분할:
청크 1: "RoBERTa improves BERT by removing the next sentence prediction objective."
청크 2: "It uses larger mini-batches for training and dynamic masking."
(각 청크는 512 토큰 내외로 설정) - 문장 윈도우:
청크 1: "RoBERTa improves BERT by removing the next sentence prediction objective. It uses larger mini-batches for training."
청크 2: "Dynamic masking and other optimization techniques are applied."
(각 청크는 3개의 문장 포함) - 문서 요약:
청크: "RoBERTa removes next sentence prediction, uses dynamic masking, and larger mini-batches for robust pretraining."
2. 평가 데이터 준비
2.1 질문-답변(QA) 세트 생성
- 평가를 위해 총 107개의 질문-답변 쌍이 생성되었습니다.
- GPT-4를 이용해 질문을 자동 생성하고, 이후 사람 검토를 통해 적합성을 확인.
예시 질문:
- 질문: "What is the main improvement in RoBERTa over BERT?"
- 기준 답변: "RoBERTa eliminates the next sentence prediction task and adopts dynamic masking."
3. RAG 시스템의 평가 방법
3.1 실험 반복성과 LLM 변동성 완화
- LLM의 출력 변동성을 줄이기 위해 각 RAG 기술을 10회 반복 실행하여 평균 성능을 평가했습니다.
- 이를 통해 통계적 신뢰성을 확보.
3.2 평가 지표
- Retrieval Precision (검색 정확도): 검색된 청크 중 질문과 관련된 내용의 비율을 평가.
- 점수 범위: 0~1 (1에 가까울수록 높은 정확도).
- 청크별로 관련성을 점수화한 뒤, 평균값으로 계산.
- Answer Similarity (답변 유사성): 생성된 답변이 기준 답변과 얼마나 유사한지 평가.
- 점수 범위: 0~5 (5에 가까울수록 높은 유사성).
- LLM 기반 평가자가 생성된 답변과 기준 답변을 비교.
예시:
- 질문: "What improvements does RoBERTa make over BERT?"
- 검색 정확도: "Dynamic masking and no next sentence prediction" 포함 시 0.9.
- 답변 유사성: "RoBERTa eliminates next sentence prediction and adopts larger mini-batches" 생성 시 점수 4.5.
4. 사용된 LLM
- GPT-3.5-turbo를 사용하여 답변 생성 및 검색 정확도 평가.
- 선택 이유: 비용 효율성과 OpenAI의 Tonic Validate 플랫폼 요구사항 준수.
- GPT-4 사용 시 평가 품질이 더 높아질 수 있으나, 실험 비용 제약으로 인해 사용하지 않음.
5. 통계적 분석
5.1 분산 분석 (ANOVA)
- 여러 RAG 기술 간의 평균 검색 정확도 차이를 확인하기 위해 ANOVA 테스트 실시.
5.2 Tukey HSD 테스트
- 특정 기술 간의 유의미한 차이를 평가하기 위해 Tukey HSD 테스트 적용.
예시 결과:
- HyDE와 LLM Rerank 조합은 Naive RAG 대비 검색 정확도가 유의미하게 높음 (p-value < 0.05).
- Multi-query 기술은 Naive RAG보다 낮은 검색 정확도를 보여 추가 개선이 필요.
결과
1. 결과 (Results)
1.1 Retrieval Precision (검색 정확도)
- Sentence-window Retrieval:
- 검색 정확도가 가장 높았으며, Naive RAG 대비 현저한 성능 향상을 보임.
- 그러나, 높은 검색 정확도가 Answer Similarity와 반드시 연결되지는 않음.
- HyDE와 LLM Rerank:
- 개별적으로도 우수한 성능을 보였으나, 조합했을 때 가장 높은 검색 정확도를 기록.
- 이 조합은 Naive RAG 대비 통계적으로 유의미한 성능 향상을 보임.
- MMR과 Cohere Rerank:
- Naive RAG 대비 성능이 개선되지 않음.
- Multi-query:
- Naive RAG보다 낮은 검색 정확도를 보이며, 성능 저하 원인 분석이 필요.
1.2 Answer Similarity (답변 유사성)
- 검색 정확도와 답변 유사성 간의 불일치가 관찰됨.
- 예: Sentence-window Retrieval는 검색 정확도는 높았지만, 생성된 답변의 유사성은 낮음.
- Classic Vector Database와 Document Summary Index에서는 검색 정확도와 답변 유사성이 양의 상관관계를 보임.
1.3 통계 검증
- ANOVA와 Tukey의 HSD 테스트를 통해 각 RAG 기술 간의 차이가 통계적으로 유의미함을 확인.
- Sentence-window Retrieval + LLM Rerank와 같은 조합은 다른 기술 대비 우수한 성능을 보임.
2. 결론 (Conclusion)
- HyDE와 LLM Rerank:
- RAG 시스템의 검색 정확도를 크게 향상시키는 데 성공.
- 그러나, 추가적인 LLM 호출이 필요하여 처리 지연과 비용 증가라는 한계 존재.
- Sentence-window Retrieval:
- 검색 정확도는 가장 높았으나, 생성된 답변이 기준 답변과 일치하지 않는 문제가 발견됨.
- 이 기술은 검색 단계 최적화에는 유용하지만, 생성 단계 개선이 필요.
- Document Summary Index:
- Naive RAG 대비 성능이 개선되었으며, 효율성과 정확성을 모두 향상시킬 가능성이 있음.
- Multi-query와 MMR:
- Naive RAG보다 성능이 낮거나 비슷하여, 기술적 개선이 필요.
3. 마무리 및 한계 (Limitations)
3.1 한계
- 모델 선택:
- GPT-3.5-turbo를 사용하였으나, GPT-4와 같은 고성능 모델을 사용했다면 결과가 달라질 가능성.
- 데이터셋:
- 단일 데이터셋과 107개의 질문-답변 쌍에 기반한 실험으로, 결과의 일반화 한계가 존재.
- 청크 분할 전략:
- 각 RAG 기술이 서로 다른 청크 분할 방식을 사용하여 직접 비교의 어려움 발생.
- 평가 지표:
- Retrieval Precision과 Answer Similarity를 사용하였으나, 보다 정교한 평가 기준이 필요.
3.2 연구 기여
- RAG 기술 간의 비교를 통해 HyDE와 Sentence-window Retrieval 등 유망한 기술을 확인.
- RAG 시스템 설계 시 비용-성능 균형을 고려할 수 있는 실용적 정보를 제공.
4. 미래 연구 방향 (Future Work)
- 지식 그래프 통합:
- RAG 시스템에 지식 그래프(Knowledge Graph)를 추가하여 검색 정밀도와 문맥성을 개선.
- Unfrozen RAG 시스템:
- 데이터셋 특화된 RAG 구성 요소를 세부적으로 튜닝하여 시스템 적응력 강화.
- Auto-RAG:
- RAG 시스템의 구성 요소(예: 청크 크기, 윈도우 크기 등)를 자동으로 최적화하는 방법론 개발.
- 다양한 데이터셋에서의 실험:
- 실험을 여러 데이터셋에서 반복하여 연구 결과의 일반성을 높이고, 새로운 통찰 제공.
- RAG와 AutoML 융합:
- RAG 구성 요소 자동 탐색을 통해 최적의 시스템 설계를 가능하게 함.
5. 연구 요약
본 연구는 Retrieval-Augmented Generation (RAG) 기술의 성능을 비교 분석하며, 각각의 장단점을 구체적으로 제시했습니다. 이를 통해 RAG 기술 발전에 필요한 방향성을 제시하며, RAG 시스템 설계의 기초 자료로 활용될 수 있습니다.