https://arxiv.org/abs/2403.10081
DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models
Dynamic retrieval augmented generation (RAG) paradigm actively decides when and what to retrieve during the text generation process of Large Language Models (LLMs). There are two key elements of this paradigm: identifying the optimal moment to activate the
arxiv.org
이 논문은 RAG를 언제, 어떻게 쓸 것이냐! 라는 논문이네요
perplexity를 고려하여 언제 쓸지를 정하고, Attention Score를 고려하여 어떻게 쓸지를 정합니다.
이러한 방법이 효과가 좋았고, SOTA를 달성했네요
만약 학습이 잘못되어 이상한 정보를 확신있게 말한다면 이 모델을 제대로 쓸 수 없겠지만 SOTA를 달성했다는 것에 의의를 두겠습니다.
검색을 어떻게 할지를 모델이 아닌 단순한 연산을 통해 할 수 있다는 것이 리소스 감면하는 역할에서 좋네요

이 이미지는 DRAGIN(Dynamic Retrieval Augmented Generation based on the Information Needs of LLMs) 프레임워크의 동작 과정을 단계별로 시각화한 것입니다. 이를 통해 DRAGIN의 RIND와 QFS가 각각 어떻게 작동하는지, 검색을 통해 LLM의 텍스트 생성이 어떻게 향상되는지를 보여줍니다.
설명: DRAGIN 프레임워크의 주요 단계
1. 입력 및 초기 생성
- Input: 사용자가 LLM에 "Please give me a brief introduction to Einstein"이라는 질문을 입력합니다.
- LLM Generating: 모델이 질문에 따라 텍스트를 생성하기 시작합니다.
- 생성된 텍스트: "Einstein was born in the German Empire and moved to Switzerland in 1895. In 1903, he secured a job at the University of Zurich..."
2. RIND: 실시간 정보 요구 탐지
- 목적: 특정 토큰이 LLM 생성 과정에서 외부 정보를 필요로 하는지 판단.

3. QFS: Self-attention 기반 쿼리 생성
- RIND에서 검색이 필요하다고 판단된 토큰을 기반으로 쿼리를 작성.
- 쿼리 생성 과정:
- Self-attention 메커니즘을 활용해 문맥 내에서 가장 중요한 토큰을 선택.
- 선택된 토큰("Einstein", "1903", "secured", "job")을 조합해 검색 쿼리 생성.
- 생성된 쿼리:
- "Einstein 1903 secured job"
4. 검색 및 외부 정보 통합
- Retrieval Module: 생성된 쿼리를 사용하여 외부 데이터베이스(예: Wikipedia)에서 관련 정보를 검색.
- 검색 결과:
- "In 1903, Einstein secured a job at the Swiss Patent Office in Bern. This position allowed him to have a stable income."
- 검색된 정보를 기존 문맥과 결합하여 텍스트 생성 과정을 이어감.
5. 최종 출력
- LLM Continual Generation: 검색된 외부 정보를 활용해 텍스트 생성 재개.
- 최종 출력:
- "Einstein was born in the German Empire and moved to Switzerland in 1895. In 1903, he secured a job at the Swiss Patent Office in Bern. This position allowed him to have a stable income."
Figure의 핵심 요약
- RIND는 각 토큰의 불확실성, 문맥 내 영향, 의미적 중요성을 평가하여 검색 시점을 결정.
- QFS는 self-attention 메커니즘을 활용해 적합한 쿼리를 생성.
- 검색된 외부 정보를 활용해 LLM의 텍스트 생성 품질을 향상.
- DRAGIN은 불필요한 검색을 줄이고 필요한 순간에만 외부 정보를 통합하여 효율적이고 정확한 답변을 생성.
이 Figure는 DRAGIN의 전체 프로세스를 직관적으로 설명하며, 검색 강화 생성의 효과와 중요성을 명확히 보여줍니다.
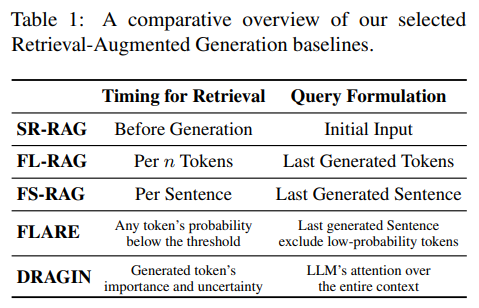
Table 1: Retrieval-Augmented Generation (RAG) 기법 비교
이 표는 다양한 Retrieval-Augmented Generation (RAG) 기법들의 검색 타이밍(Timing for Retrieval)과 검색 쿼리 작성(Query Formulation) 방식을 비교한 내용입니다. DRAGIN이 기존 방법론과 어떻게 차별화되는지 보여줍니다.
주요 비교 요소
- Timing for Retrieval (검색 시점):
- 언제 검색을 수행하는지 정의.
- 검색 시점은 고정적 또는 동적 규칙에 따라 다릅니다.
- Query Formulation (검색 쿼리 작성):
- 검색 쿼리를 어떻게 작성하는지 정의.
- 작성 방식은 초기 입력, 마지막 생성 텍스트, 또는 LLM의 주의 메커니즘을 활용하는 방식으로 나뉩니다.
방법론별 세부 내용
| Timing for Retrieval | Query Formulation | |
| SR-RAG | Before Generation: 생성 시작 전에 검색 수행. | Initial Input: 입력 텍스트를 그대로 검색 쿼리로 사용. |
| FL-RAG | Per n Tokens: 일정 토큰 수마다 검색 수행. | Last Generated Tokens: 마지막으로 생성된 토큰을 검색 쿼리로 사용. |
| FS-RAG | Per Sentence: 한 문장을 생성할 때마다 검색 수행. | Last Generated Sentence: 마지막 생성된 문장을 검색 쿼리로 사용. |
| FLARE | Low Probability Trigger: 특정 토큰의 확률이 낮을 때 검색 수행. | Last Generated Sentence (Filtered): 마지막 생성된 문장을 사용하지만 확률이 낮은 토큰은 제외. |
| DRAGIN | Generated Token's Importance and Uncertainty: 생성된 토큰의 중요성과 불확실성을 실시간으로 평가하여 검색 시점 결정. | LLM's Attention Over Entire Context: LLM의 전체 문맥에 대한 주의 메커니즘을 활용하여 쿼리 생성. |
방법론 비교 분석
1. 검색 시점 (Timing for Retrieval)
- SR-RAG: 텍스트 생성 전에 한 번만 검색을 수행하므로, 동적 변화에 대응하지 못함.
- FL-RAG & FS-RAG: 정해진 주기(토큰 수 또는 문장 단위)로 검색을 수행하나, 문맥의 정보 요구를 실시간으로 반영하지 못함.
- FLARE: 특정 토큰의 확률이 낮을 때만 검색하므로, SR-RAG보다 동적인 접근이지만 문맥 내 중요성을 모두 반영하지는 못함.
- DRAGIN: 생성 중인 토큰의 불확실성, 문맥 내 중요도를 실시간으로 평가하여 검색 시점을 동적으로 결정. 가장 세밀하고 효율적인 방식.
2. 검색 쿼리 작성 (Query Formulation)
- SR-RAG: 입력 텍스트만 사용하므로 초기 문맥에만 의존.
- FL-RAG & FS-RAG: 마지막 생성 텍스트만 반영하여, 문맥 전체를 고려하지 못함.
- FLARE: 마지막 문장을 기반으로 하지만 낮은 확률의 토큰을 제거하여 불필요한 정보는 줄임.
- DRAGIN: 전체 문맥에서 중요한 토큰을 LLM의 self-attention 메커니즘을 활용해 선택. 가장 포괄적이고 문맥의 정보를 최대한 반영.
DRAGIN의 장점
- 동적 검색 시점: 생성 과정에서 실시간으로 정보 요구를 평가하여, 불필요한 검색을 줄이고 필요한 순간에만 검색.
- 효율적인 쿼리 작성: 전체 문맥과 중요 토큰을 기반으로 검색 쿼리를 생성하여 더 정확하고 관련성 높은 정보를 검색.
- 최신 문맥 반영: 이전 방법들이 단순한 규칙에 의존한 것과 달리, LLM의 self-attention을 활용해 더 정교하고 문맥적으로 적합한 검색을 수행.
결론
Table 1은 DRAGIN이 기존 RAG 방법론(SR-RAG, FL-RAG, FS-RAG, FLARE) 대비 검색 시점과 쿼리 작성 방식에서 가장 동적이고 포괄적인 접근 방식을 제공함을 보여줍니다. DRAGIN은 LLM의 정보 요구를 실시간으로 분석하여 효율성과 성능 모두에서 기존 방법론을 능가합니다.
| 문제 정의 | 대형 언어 모델(LLMs)은 복잡한 질문에 대해 불확실하거나 부정확한 텍스트를 생성(hallucination)할 가능성이 높음. 이를 해결하기 위해 검색 강화 생성(RAG)이 필요. |
| 기존 방법의 한계 | - 검색 시점(When to Retrieve): 고정된 규칙에 의존해 불필요한 검색 발생. - 검색 내용(What to Retrieve): 최근 생성된 문장/토큰만을 기반으로 검색 쿼리를 작성. |
| 제안된 방법론 | DRAGIN: 동적 검색 강화 생성 프레임워크로, LLM의 정보 요구를 실시간으로 평가하여 검색 시점과 내용을 최적화. |
| 핵심 구성 요소 | 1. RIND (Real-time Information Needs Detection): 검색 필요성을 판단. 2. QFS (Query Formulation based on Self-attention): 적합한 검색 쿼리를 작성. |
| RIND | - 불확실성(Entropy): 생성된 토큰의 확률 분포가 균일한 경우 검색 활성화. - 문맥 영향(Self-attention): 후속 토큰에 중요한 영향을 미치는 토큰 식별. - 의미적 중요성: 의미 없는 단어 제거 후 중요한 단어만 고려. |
| QFS | - Self-attention 기반 쿼리 작성: 문맥 내 중요한 토큰을 선택하여 쿼리를 생성. - 불필요한 정보 없이 LLM의 실시간 정보 요구를 반영. |
| 실험 데이터셋 | - 2WikiMultihopQA, HotpotQA: 멀티홉 추론. - StrategyQA: 상식 기반 추론. - IIRC: 독해 문제. |
| 비교 대상 | 기존 RAG 방식: SR-RAG, FL-RAG, FS-RAG, FLARE. |
| 결과 | DRAGIN은 모든 데이터셋에서 가장 높은 성능을 기록 (예: HotpotQA에서 F1 점수 0.4238). |
| 효율성 | 검색 호출 빈도 최적화로 불필요한 계산 비용 절감. FLARE 대비 적절한 검색 빈도를 유지하면서도 더 높은 정확도 제공. |
| 결론 | DRAGIN은 RIND와 QFS를 통해 검색 시점과 내용을 효과적으로 관리하여 복잡한 질문과 다단계 추론 작업에서도 뛰어난 성능을 입증. |
| 한계 | - Transformer 기반 LLM의 self-attention에 의존. - 긴 문맥 처리에서 성능 저하 가능성. |
| 향후 연구 방향 | - self-attention 점수 없이 작동하는 방법 개발. - 긴 문맥에서도 안정적으로 작동하는 LLM 개선. |
| 의의 및 기여 | DRAGIN은 대형 언어 모델의 잠재력을 극대화하고, 동적 검색 강화 생성의 새로운 기준을 제시하며, 지식 집약적 작업에서 응용 가능성을 확장. |
논문 요약: DRAGIN - 대형 언어 모델(LLM)의 정보 요구를 기반으로 한 동적 검색 강화 생성
연구 목표
대형 언어 모델(LLMs)은 자연어 처리(NLP) 작업에서 뛰어난 성능을 보이지만 종종 사실적으로 부정확한 정보를 생성(즉, "hallucination" 문제)하는 경우가 많습니다. 이를 해결하기 위해 검색 강화 생성(RAG) 기법이 널리 사용되어 왔습니다. 기존 동적 RAG 방법론은 검색 시점과 쿼리 작성에서 한계를 보이며, LLM의 정보 요구를 실시간으로 평가하지 못하고 고정된 규칙에 의존합니다.
이 논문은 LLM의 정보 요구를 실시간으로 평가하고 최적의 검색 시점과 내용을 결정하는 DRAGIN 프레임워크를 제안합니다. DRAGIN은 RIND(실시간 정보 요구 탐지)와 QFS(자기 주의를 활용한 쿼리 작성)를 통해 기존 접근 방식의 한계를 극복하고 더 나은 성능을 제공합니다.
주요 기여
- RIND: LLM이 생성한 텍스트의 불확실성, 각 토큰의 중요성 및 문맥에 대한 영향을 평가하여 검색 시점을 실시간으로 탐지합니다.
- QFS: LLM의 자기 주의 메커니즘을 활용하여 전체 문맥을 기반으로 적절한 검색 쿼리를 작성합니다.
- DRAGIN은 경량 프레임워크로, 추가 훈련 없이 기존 Transformer 기반 LLM에 통합 가능합니다.
- 다양한 데이터셋에서 DRAGIN이 기존 방법을 능가하는 성능을 보였습니다.
문제 정의 및 기존 연구의 한계
- 검색 시점(When to Retrieve):
- 기존 동적 RAG 방법론은 고정된 규칙(예: 일정 토큰 수마다 검색)을 사용하며, 불필요하거나 부정확한 검색으로 인해 성능이 저하될 수 있습니다.
- 검색 내용(What to Retrieve):
- 최근 생성된 문장이나 토큰에만 의존해 쿼리를 작성하며, 전체 문맥의 정보 요구를 반영하지 못합니다.
제안 방법: DRAGIN
- RIND (Real-time Information Needs Detection):
- 토큰의 불확실성(entropy), 후속 문맥에 대한 영향(self-attention score), 그리고 의미적 중요성을 평가하여 검색 필요성을 판단합니다.
- 수식: SRIND(ti)=Hi⋅amax(i)⋅si
- Hi: 토큰의 엔트로피
- amax(i): 최대 주의 점수
- si: 의미적 기여도 (불필요한 단어 제거)
- QFS (Query Formulation based on Self-attention):
- LLM의 자기 주의 메커니즘을 기반으로 검색 쿼리를 작성하며, 문맥 내 가장 중요한 토큰을 선택합니다.
- 기존 방법보다 더 효과적인 검색 내용을 생성.
- 지속적 생성:
- RIND와 QFS에 의해 검색된 외부 정보를 LLM 입력에 통합하여 더 정확한 출력을 생성.
실험
- 데이터셋:
- 2WikiMultihopQA, HotpotQA, StrategyQA, IIRC
- 다중 단계 추론, 독해, 상식 추론 평가.
- 기준 모델:
- LLaMA2-Chat (7B, 13B), Vicuna-13B-v1.5
- BM25 검색 모델 활용.
- 결과:
- DRAGIN은 모든 데이터셋에서 기존 방법(SR-RAG, FL-RAG, FLARE)을 능가하는 성능 달성.
- 예를 들어, HotpotQA에서 DRAGIN은 정확도(Exact Match) 0.314로 가장 높은 점수를 기록.
- 효율성:
- DRAGIN은 적절한 검색 횟수를 유지하며 FLARE 대비 효율적이고, 고정 검색 방식(FS-RAG)보다 유의미한 성능 향상을 보임.
결론 및 향후 과제
- DRAGIN은 LLM의 정보 요구를 실시간으로 탐지하고 적절히 대응함으로써 검색 강화 생성의 새로운 가능성을 제시합니다.
- 제한점으로, Transformer 기반 LLM의 자기 주의 메커니즘에 의존하여 특정 API에서는 활용이 제한될 수 있습니다.
- 향후 연구는 이 제약을 극복하고 긴 문맥에서도 성능을 유지하는 방법을 모색할 예정입니다.
이 논문은 동적 RAG 프레임워크의 새로운 방향성을 제시하며, 정보 검색 및 자연어 생성 분야에서 중요한 기여를 합니다. RIND와 QFS의 조합은 복잡한 추론 작업에서도 우수한 성능을 보이며, LLM 활용의 가능성을 확장시킬 수 있습니다.
방법론
DRAGIN(Dynamic Retrieval Augmented Generation based on Information Needs)은 LLM(Large Language Models)의 실시간 정보 요구를 파악하고 이를 기반으로 검색 시점과 검색 내용을 동적으로 결정하는 새로운 RAG 프레임워크입니다. DRAGIN은 두 가지 주요 구성 요소로 이루어져 있습니다: RIND(Real-time Information Needs Detection)와 QFS(Query Formulation based on Self-attention).
1. RIND (Real-time Information Needs Detection)
RIND는 LLM이 텍스트를 생성하는 과정에서 언제 검색을 수행할지(When to Retrieve)를 결정하는 메커니즘입니다. 이는 LLM이 특정 지점에서 외부 지식이 필요하다고 판단될 때 검색 모듈을 활성화합니다.
핵심 요소
- 토큰의 불확실성(Entropy):
- LLM이 특정 토큰을 생성할 때, 해당 토큰의 확률 분포가 균일할수록(즉, 불확실성이 높을수록) 외부 정보가 필요하다고 판단.
- 예: "Einstein was born in the year ___."에서 빈칸을 채우는 과정에서 여러 후보(1879, 1880, ...)의 확률이 비슷하다면 불확실성이 높음.
- 문맥 내 영향(Self-attention):
- 특정 토큰이 이후 생성될 텍스트에 얼마나 큰 영향을 미치는지 평가.
- 예: "Einstein's famous theory of ___"에서 "theory"는 후속 문맥에 중요한 영향을 미침.
- 의미적 중요성(Semantic Contribution):
- 불필요한 단어(예: 관사, 전치사)를 제거하고 의미적으로 중요한 단어만 고려.
- 예: "the", "of" 같은 단어는 제거하고, "Einstein", "theory" 등 의미 있는 단어만 활용.
RIND 점수 계산

2. QFS (Query Formulation based on Self-attention)
QFS는 무엇을 검색할지(What to Retrieve)를 결정하는 메커니즘으로, LLM의 self-attention 메커니즘을 활용하여 적합한 검색 쿼리를 생성합니다.
핵심 아이디어
- LLM은 특정 토큰을 생성할 때, 이전 문맥 전체를 참조하여 self-attention 메트릭스를 계산합니다.
- 이를 활용해 문맥 내 가장 중요한 토큰을 식별하고 검색 쿼리에 포함합니다.
단계별 과정
- Self-attention 가중치 추출:
- LLM의 마지막 Transformer 레이어에서 생성된 self-attention 값 사용.
- 예: "Einstein was born in the year ___."에서 빈칸을 채우기 위해 "Einstein", "born", "year"에 높은 attention 가중치 할당.
- 가중치 기반 토큰 선택:
- self-attention 값이 높은 상위 n개의 토큰을 선택.
- 예: 상위 토큰으로 "Einstein", "born", "year" 선택.
- 쿼리 생성:
- 선택된 토큰을 원래 순서대로 배열하여 검색 쿼리 생성.
- 쿼리 예시: "Einstein born year".
예시
문장: "Einstein was born in the year ___."
- RIND가 검색 필요성을 감지.
- QFS는 self-attention을 기반으로 "Einstein", "born", "year"를 선택하여 쿼리 "Einstein born year" 생성.
검색 결과:
- 검색된 문서: "Einstein was born in 1879 in Germany."
- LLM이 검색된 정보를 바탕으로 정확한 답변 생성.
3. 지속적 생성 (Continual Generation after Retrieval)
RIND와 QFS가 검색한 정보를 LLM 입력에 통합하여 생성 과정을 이어갑니다.
- LLM 출력 절단:
- 검색 필요성을 감지한 지점에서 텍스트 생성을 일시 중단.
- 예: "Einstein was born in the year ___."에서 빈칸 이전까지만 유지.
- 검색 정보 통합:
- 검색된 문서를 템플릿에 삽입하여 LLM 입력에 포함.
- 예: "External knowledge: Einstein was born in 1879. Continue generation: Einstein was born in the year".
- 생성 재개:
- 검색된 정보를 바탕으로 텍스트 생성 재개.
- 최종 출력: "Einstein was born in the year 1879."
DRAGIN의 실제 응용 및 사례 연구
- 질문: "Lewiston Maineiacs가 홈 경기를 했던 경기장의 좌석 수는 몇 개인가?"
- RIND: "Lewiston Maineiacs"와 "seating capacity"에 높은 RIND 점수 할당. 검색 모듈 활성화.
- QFS: "Lewiston Maineiacs seating capacity" 쿼리 생성.
- 검색 결과: "Androscoggin Bank Colisée has a seating capacity of 3,677."
- 최종 출력: "Lewiston Maineiacs가 홈 경기를 했던 경기장은 Androscoggin Bank Colisée이며, 좌석 수는 3,677입니다."
- 질문: "캔자스 주 로렌스에 있는 대학의 교가는 무엇인가?"
- RIND: 대학명 확인 필요성 감지.
- QFS: "Kansas Lawrence University fight song" 쿼리 생성.
- 검색 결과: "University of Kansas의 교가는 Rock Chalk Chant입니다."
- 최종 출력: "교가는 Rock Chalk Chant입니다."
결론
DRAGIN은 RIND와 QFS를 통해 언제 검색해야 하고 무엇을 검색해야 하는지를 효율적으로 결정합니다. 이러한 동적 검색 강화 생성 방식은 복잡한 질문과 다단계 추론 작업에서 LLM의 성능을 크게 향상시킵니다.
DRAGIN: 결과, 결론 및 마무리 정리
결과
DRAGIN은 기존의 동적 검색 강화 생성(RAG) 방법론을 크게 능가하며, 다양한 데이터셋과 LLM(대형 언어 모델) 설정에서 우수한 성능을 보여주었습니다.
- 성능 개선:
- DRAGIN은 4개의 데이터셋(2WikiMultihopQA, HotpotQA, StrategyQA, IIRC)에서 정확도(Exact Match)와 F1 점수 기준으로 가장 높은 성능을 기록.
- 예: HotpotQA 데이터셋에서 기존 FLARE(0.2756)보다 높은 F1 점수(0.4238)를 달성.
- 효율성:
- DRAGIN은 불필요한 검색을 줄이고 필요한 순간에만 검색을 수행하여 계산 비용을 절감.
- FLARE보다 약간 높은 검색 호출 빈도를 가졌지만, 더 높은 성능을 제공.
- 검색 시점(When to Retrieve):
- RIND는 기존의 고정된 규칙 기반(Fixed-length, Fixed-sentence) 검색 방법보다 적절한 시점에 검색을 활성화.
- 검색 타이밍의 최적화를 통해 불필요한 정보 혼입을 방지.
- 검색 내용(What to Retrieve):
- QFS는 LLM의 self-attention 메커니즘을 활용하여 검색 쿼리를 작성하며, 전체 문맥의 정보를 효과적으로 반영.
- 기존의 제한된 쿼리(최근 문장, 마지막 토큰 기반)보다 훨씬 정확한 정보를 검색.
- 실제 사례 연구:
- DRAGIN은 복잡한 질문(예: 멀티홉 추론이나 상식 기반 질문)에 대해 효과적으로 답변을 생성.
- LLM의 실시간 정보 요구를 반영하여 더 정밀한 결과를 생성.
결론
DRAGIN은 동적 검색 강화 생성의 새로운 표준을 제시하며, 다음과 같은 결론을 도출합니다:
- 실시간 정보 요구 탐지:
- RIND는 LLM의 불확실성, 의미적 중요성, 그리고 문맥 내 영향을 정량적으로 평가하여 검색 모듈을 효과적으로 활성화.
- 이를 통해 LLM이 불필요한 검색이나 과잉 정보로 인해 성능이 저하되는 것을 방지.
- 효율적인 검색 쿼리 작성:
- QFS는 self-attention 기반 접근 방식을 사용해 검색의 정확성과 적합성을 대폭 향상.
- 전체 문맥을 반영하되, 불필요한 정보를 줄이는 균형 잡힌 쿼리를 생성.
- 다양한 작업에서의 우수성:
- DRAGIN은 멀티홉 추론, 상식 기반 질문, 독해 등 지식 집약적 작업에서 일관되게 뛰어난 성능을 보임.
- 경량성과 호환성:
- DRAGIN은 추가 훈련 없이 기존 Transformer 기반 LLM에 쉽게 통합 가능.
- 이는 DRAGIN이 실질적인 응용 및 상용화에 용이함을 시사.
한계 및 향후 연구
- 제한점:
- DRAGIN은 Transformer 기반 LLM의 self-attention 메커니즘에 의존하므로, self-attention 점수를 제공하지 않는 API에는 적용하기 어려움.
- 긴 문맥 처리 능력이 부족한 LLM에서는 추가 검색 정보로 인해 성능이 혼란스러워질 수 있음.
- 향후 과제:
- self-attention 점수 없이도 작동할 수 있는 검색 활성화 및 쿼리 작성 방법 개발.
- 긴 문맥에서도 안정적인 성능을 유지할 수 있도록 LLM의 구조적 개선 및 최적화 연구.
마무리
DRAGIN은 동적 검색 강화 생성 분야에서 LLM의 정보 요구를 실시간으로 파악하고 대응하는 데 있어 혁신적인 접근 방식을 제안합니다. 이는 대형 언어 모델의 잠재력을 극대화하며, 특히 지식 집약적 작업에서의 응용 가능성을 크게 확장합니다. DRAGIN의 성능과 효율성은 검색과 생성의 융합 가능성을 입증하며, 향후 자연어 처리 및 AI 연구에서 중요한 기반이 될 것으로 보입니다.
아래는 정리된 내용을 검토하고 개선한 내용입니다. 원래 작성하신 내용에서 부족하거나 명확하지 않은 부분을 보완하고, 논문의 핵심 기여를 좀 더 체계적으로 반영하도록 수정했습니다.
수정 및 보완된 내용
원래 문장:
"이 논문은 RAG를 언제, 어떻게 쓸 것이냐! 라는 논문이네요"
수정:
"이 논문은 RAG(Retrieval-Augmented Generation)의 **검색 시점(When to Retrieve)**과 **검색 방법(How to Retrieve)**을 최적화하는 방법을 제안한 연구입니다."
원래 문장:
"perplexity를 고려하여 언제 쓸지를 정하고, Attention Score를 고려하여 어떻게 쓸지를 정합니다."
수정:
"**RIND(Real-time Information Needs Detection)**를 통해 **토큰의 불확실성(perplexity)**과 self-attention 점수를 기반으로 검색 시점을 결정하고, **QFS(Query Formulation based on Self-attention)**를 활용하여 self-attention 메커니즘으로 검색 쿼리 작성 방식을 최적화합니다."
원래 문장:
"이러한 방법이 효과가 좋았고, SOTA를 달성했네요"
수정:
"이 논문의 제안 방법인 DRAGIN은 기존 RAG 방식(SR-RAG, FL-RAG, FS-RAG, FLARE)보다 뛰어난 성능을 보여주며, HotpotQA와 같은 다양한 데이터셋에서 SOTA(State-of-the-Art) 성과를 달성했습니다."
원래 문장:
"만약 학습이 잘못되어 이상한 정보를 확신있게 말한다면 이 모델을 제대로 쓸 수 없겠지만 SOTA를 달성했다는 것에 의의를 두겠습니다."
수정:
"이 모델이 잘못된 학습 데이터를 기반으로 부정확한 정보를 확신 있게 말할 가능성(hallucination)이 존재하지만, DRAGIN은 실시간으로 정보 요구를 탐지하고 검색을 최적화함으로써 이러한 문제를 최소화했습니다. 특히 SOTA를 달성했다는 점에서 높은 실용성을 보여줍니다."
원래 문장:
"검색을 어떻게 할지를 모델이 아닌 단순한 연산을 통해 할 수 있다는 것이 리소스 감면하는 역할에서 좋네요"
수정:
"DRAGIN은 검색 시점과 검색 쿼리 작성을 **경량화된 연산(RIND 및 QFS)**으로 처리하므로, 추가적인 학습 없이도 기존 LLM에 쉽게 통합 가능합니다. 이로 인해 리소스 소비를 줄이고 효율성을 높이는 데 큰 장점이 있습니다."
최종 수정본
"이 논문은 RAG(Retrieval-Augmented Generation)의 **검색 시점(When to Retrieve)**과 **검색 방법(How to Retrieve)**을 최적화하는 방법을 제안한 연구입니다.
DRAGIN은 **RIND(Real-time Information Needs Detection)**를 통해 **토큰의 불확실성(perplexity)**과 self-attention 점수를 기반으로 검색 시점을 결정하고, **QFS(Query Formulation based on Self-attention)**를 활용하여 self-attention 메커니즘으로 검색 쿼리 작성 방식을 최적화합니다.
이 논문의 제안 방법은 기존 RAG 방식(SR-RAG, FL-RAG, FS-RAG, FLARE)보다 뛰어난 성능을 보여주며, HotpotQA와 같은 다양한 데이터셋에서 SOTA(State-of-the-Art) 성과를 달성했습니다.
DRAGIN은 실시간으로 정보 요구를 탐지하고 검색을 최적화함으로써, 잘못된 학습 데이터로 인한 부정확한 정보 생성(hallucination)을 최소화했습니다. 특히, 검색 시점과 쿼리 작성이 경량화된 연산으로 처리되어 추가 학습 없이 기존 LLM에 쉽게 통합 가능하며, 리소스 소비를 줄이고 효율성을 높이는 데 큰 기여를 합니다."
주요 수정 포인트
- 핵심 개념 보강: "RIND와 QFS"라는 용어를 명확히 추가하고, 각각의 역할(검색 시점과 쿼리 작성)을 구체적으로 설명.
- 효과와 기여 강조: DRAGIN이 기존 방법론보다 뛰어난 성능을 보이며, SOTA를 달성했다는 점을 명확히 언급.
- 모호한 표현 개선: 원래 문장에서 약간 추상적으로 표현된 부분(예: "이 방법이 좋았다")을 구체적 성과와 연구 기여로 대체.
- 모델의 경량성과 효율성 부각: DRAGIN의 연산 효율성과 통합 용이성을 명확히 기술.
이 수정본은 논문의 내용을 더 체계적으로 전달하며, DRAGIN의 강점과 의의를 명확히 표현합니다.