https://arxiv.org/abs/2305.14763
Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models
The escalating debate on AI's capabilities warrants developing reliable metrics to assess machine "intelligence". Recently, many anecdotal examples were used to suggest that newer large language models (LLMs) like ChatGPT and GPT-4 exhibit Neural Theory-of
arxiv.org
- 이 논문은 대규모 언어 모델(LLM)의 Neural Theory of Mind(N-ToM) 능력을 다양한 데이터셋으로 평가하며, 일부 ToM 능력을 보여주지만 이는 취약하고 일관되지 않다고 결론짓습니다.
- LLM이 특정 과제에서 높은 성능을 보였으나, 이는 실제 추론보다는 표면적 패턴 학습과 휴리스틱에 의존한 결과로 나타났습니다.
- 모델은 질문 형식의 변화나 대립적 데이터에서 성능이 크게 저하되며, 인간과 같은 정서적 추론 능력을 가지지 못함이 드러났습니다.
- "Emergent Abilities" 주장은 근거가 부족하며, LLM의 훈련 데이터 공개 없이 모델의 실제 ToM 능력을 평가하기는 어렵습니다.
- 연구는 LLM이 인간 수준의 ToM을 가지려면 단순한 모델 크기 증가 대신 새로운 설계와 평가 방법이 필요하다고 강조합니다.
만약 모델이 4o나 o1이 있었다면 어떤 결과가 나왔을지 궁금하긴 하네요

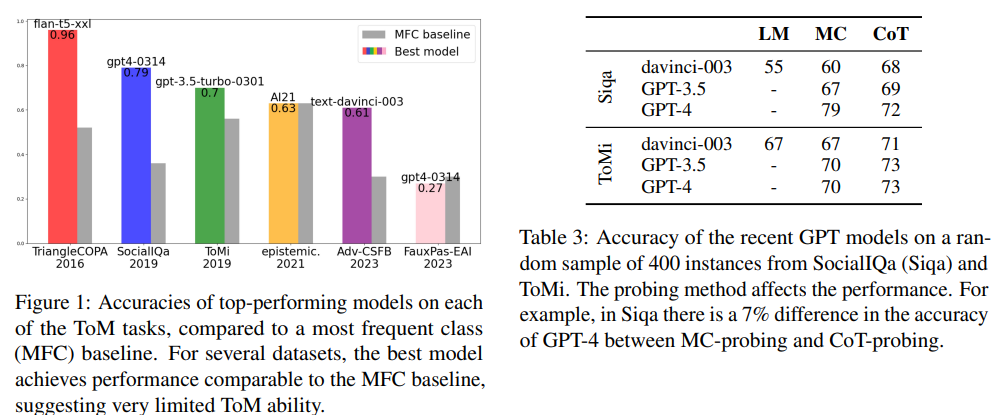

논문 요약: "Clever Hans or Neural Theory of Mind? Stress Testing Social Reasoning in Large Language Models"
1. 연구 문제: LLM의 "Neural Theory of Mind (N-ToM)" 능력 평가
- 문제 정의: 인간의 "Theory of Mind(ToM)"는 타인의 신념, 감정, 의도를 이해하는 능력입니다. 최근 LLMs (GPT-4 등)가 이러한 능력을 모방할 수 있다는 주장이 나왔으나, 일화적 증거와 실험적 결과가 상충합니다.
- 목표: LLM이 N-ToM 능력을 가진다고 주장하기 위해 일화적 증거와 제한된 벤치마크를 넘어, 더 체계적이고 심층적인 평가를 수행.
2. 연구 방법: 다양한 N-ToM 관련 데이터셋과 평가 방법 사용
- 6개 주요 데이터셋: FauxPas-EAI, Triangle COPA, SocialIQa 등, 다양한 ToM 과제를 포함.
- 실험 세부사항:
- 질문 형식 변화: 답변 형식(선다형, 생성형) 및 Chain-of-Thought(CoT) 방식을 적용해 모델의 성능을 비교.
- 대립적 데이터셋(Adversarial Examples): 단순 ToM 과제에서 약간의 변형(예: 투명한 용기)으로 모델의 취약점을 드러냄.
- 모델: GPT-3, GPT-3.5, GPT-4 등 15개 대규모 언어 모델.
3. 결과
- 성공적인 사례:
- 일부 오래된 데이터셋(Triangle COPA)에서 96% 정확도 달성.
- 최신 모델(GPT-4)은 일부 ToM 과제에서 높은 성능을 보임.
- 실패 및 취약점:
- FauxPas-EAI와 같은 최신 데이터셋에서는 성능이 저조(27% 정확도).
- 대립적 사례에 취약하며, 이는 모델이 표면적 패턴과 얕은 휴리스틱에 의존함을 나타냄.
- 질문 형식(CoT 등)에 따라 성능 편차가 심함.
4. 한계
- 데이터셋 범위 제한: ToM은 인간 상호작용의 광범위한 영역에 걸쳐 있으며, 연구에서 사용된 데이터셋은 제한적.
- 심리학적 테스트의 적용 한계: 인간을 위해 설계된 심리학 테스트가 LLM의 ToM 능력을 정확히 평가하지 못할 수 있음.
- 훈련 데이터 비공개: LLM의 훈련 데이터가 공개되지 않아 데이터 유출 여부 판단 불가.
5. 타당성과 아쉬운 점
- 타당성:
- 다양한 데이터셋과 평가 방식을 활용해 더 체계적인 N-ToM 평가 수행.
- 기존의 단순한 ToM 테스트(예: Sally-Anne Test)의 한계를 보완.
- 아쉬운 점:
- 인간 중심의 심리 테스트를 기계에 적용하는 방식의 한계.
- 대립적 데이터셋에서 낮은 성능은 모델의 일반화 부족을 시사.
- "Emergent Ability(출현 능력)" 주장의 검증 부족. LLM이 ToM을 훈련 과정에서 자연스럽게 획득했는지에 대한 명확한 증거가 부족.
6. 추후 연구를 위한 제언
- AI Agent 연구 방향:
- 인간의 ToM을 모방하려는 접근법보다 "신뢰성 있는 사회적 추론" 메커니즘에 초점.
- 대립적 데이터셋을 활용한 모델의 일반화 능력 강화.
- 멀티모달 학습(언어 + 시각적 정보)을 통해 ToM과 같은 복잡한 능력을 탐구.
- 실용적 개선안:
- CoT를 활용해 더 신뢰할 수 있는 추론 능력을 증진.
- 훈련 데이터 및 모델 아키텍처의 투명성을 강화.
이 연구는 AI Agent 설계 시, 인간의 복잡한 추론 능력을 기계가 어떻게 효과적으로 모방할 수 있을지를 탐구하는 데 중요한 시사점을 제공합니다.
TOM이 뭔지 좀 더 자세하게 설명하고, 무엇인지 말해줘
Theory of Mind(ToM): 개념 및 중요성
1. Theory of Mind(ToM)란?
- 정의: ToM은 타인의 마음을 이해하는 능력으로, 다른 사람의 믿음, 감정, 의도, 욕구가 자신의 것과 다를 수 있음을 이해하는 능력입니다.
- 예: 누군가가 잘못된 정보를 기반으로 행동한다고 이해하는 능력.
- 인간의 사회적 상호작용에서 중요한 역할을 하며, 감정적 공감, 의사소통, 협력 등에서 필수적입니다.
- 기본 예제:
- False Belief Task(잘못된 믿음 과제): 한 사람이 특정 사물의 위치에 대해 잘못된 정보를 가지고 있다고 가정하고, 이 사람이 어떤 행동을 할 것인지 예측.
- 예: Sally-Anne Test에서 Sally는 자신의 바구니에 구슬이 있다고 믿지만, Anne이 구슬을 다른 상자에 옮긴 경우, Sally는 여전히 바구니를 확인할 것으로 예측.
- False Belief Task(잘못된 믿음 과제): 한 사람이 특정 사물의 위치에 대해 잘못된 정보를 가지고 있다고 가정하고, 이 사람이 어떤 행동을 할 것인지 예측.
2. ToM의 심리학적 배경
- 발달 심리학:
- ToM은 인간이 생후 약 4~5세가 되면 발달하는 인지 능력으로 간주됩니다.
- 어린 아이들은 초기에는 자신의 관점에서만 세상을 보지만, ToM이 발달하면서 타인의 관점과 의도를 고려하기 시작합니다.
- 임상적 테스트:
- ToM은 자폐 스펙트럼 장애(ASD)와 같은 신경발달 장애를 평가하는 데 사용됩니다.
- 예:
- False Belief Test: 타인이 잘못된 믿음을 가지고 있다는 것을 이해하는 능력을 테스트.
- Faux Pas Test(실례 테스트): 사회적 문맥에서 잘못된 행동을 탐지하고, 그 행동이 왜 부적절했는지 설명하는 과제.
3. ToM의 구성 요소
- First-order Belief (1차 신념):
- 타인이 특정 믿음을 가지고 있다고 이해하는 능력.
- 예: "Sally는 구슬이 여전히 바구니에 있다고 믿는다."
- Second-order Belief (2차 신념):
- 타인이 다른 사람의 생각을 어떻게 이해할지를 추론.
- 예: "Anne은 Sally가 구슬을 바구니에 있다고 생각할 것이라고 믿는다."
- Emotional Perspective-taking (감정적 관점 이해):
- 타인의 감정을 추론하거나 공감하는 능력.
- 예: "그 사람이 슬프다는 것을 알고 위로한다."
4. ToM의 인공지능에서의 활용 (Neural-ToM, N-ToM)
- N-ToM의 개념:
- LLM(GPT-4 등)이나 AI가 사람처럼 타인의 신념이나 의도를 추론하고 이해할 수 있는 능력을 가질 수 있는지 평가.
- 예: AI가 "Sally는 구슬이 바구니에 있다고 생각할 것이다"라는 답을 내릴 수 있는지 확인.
- AI에서의 도전 과제:
- 얕은 휴리스틱(Heuristics):
- AI가 단순히 데이터에서 패턴을 암기하고 답변하는지, 실제로 추론 능력을 가진 것인지 구별이 어려움.
- 대립적 데이터(Adversarial Data):
- 간단한 문제(예: False Belief Task)에서 약간의 변형만 있어도 AI의 성능이 크게 저하.
- 얕은 휴리스틱(Heuristics):
- ToM과 AI의 사회적 역할:
- 인간과 상호작용하는 AI(챗봇, 소셜 로봇) 설계에 중요.
- 인공지능 윤리 및 책임 있는 AI 구현에서도 필수적 개념.
ToM의 핵심은 무엇인가?
- ToM은 인간의 인지적, 정서적 추론 능력을 기계가 모방하려는 시도를 포함합니다.
- 이 개념은 AI Agent 설계 시, 인간처럼 복잡한 상황에서 타인의 행동과 의도를 이해하고 반응하는 시스템을 개발하는 데 필수적인 지표로 작용합니다.
그럼 이 ToM은 AI가 인간의 인지적, 정서적 추론 능력을 얼마나 따라왔는지 확인하는 데이터 셋이네?
그렇습니다! Theory of Mind(ToM) 평가 데이터셋은 AI가 인간의 인지적 및 정서적 추론 능력을 어느 정도 따라왔는지 확인하기 위한 도구로 사용됩니다. 이를 통해 AI의 사회적 추론 능력을 체계적으로 테스트하고 평가할 수 있습니다.
ToM 데이터셋의 주요 특징
- 목적:
- 인간의 사회적 상호작용에서 중요한 ToM 능력을 AI가 얼마나 잘 모방할 수 있는지 평가.
- LLM(GPT-4 등)이 단순히 데이터를 암기하거나 패턴을 인식하는 것이 아니라, 실제로 타인의 믿음이나 의도를 추론할 수 있는지 확인.
- 다양한 문제 유형:
- ToM 데이터셋은 인간의 다양한 ToM 능력을 평가하는 문제를 포함합니다.
- False Belief Task: 타인이 잘못된 믿음을 가지고 있는 상황을 이해할 수 있는지 테스트.
- Faux Pas Test: 사회적 맥락에서 부적절한 발언이나 행동을 탐지하고 그 이유를 추론.
- Epistemic Reasoning: 타인의 지식과 믿음을 논리적으로 추론하는 문제.
- ToM 데이터셋은 인간의 다양한 ToM 능력을 평가하는 문제를 포함합니다.
- 특징적인 데이터셋:
- SocialIQa: 사람들의 동기, 감정, 사회적 상호작용을 이해하는 문제.
- ToMi: Sally-Anne Test에서 영감을 받은 기억과 신념 관련 문제.
- Adv-CSFB: 대립적 데이터(Adversarial Examples)를 포함하여 단순 패턴에 의존하는 AI의 취약성을 드러냄.
AI 평가를 위한 ToM 데이터셋의 의의
- AI의 한계 탐구:
- AI가 얼마나 일반화된 추론 능력을 가지고 있는지, 또는 단순히 패턴 암기에 의존하는지 구별.
- 예: 새로운 정보나 예외적 상황에서 AI의 성능이 저하되면, 이는 진정한 추론 능력이 없다는 증거가 됨.
- 사회적 상호작용의 척도:
- AI가 사람과 더 자연스러운 상호작용을 할 수 있도록, 인간 수준의 ToM 능력에 근접했는지 평가.
- 예: 챗봇이 사용자 감정을 이해하고 적절한 공감을 표현하는 능력.
- AI 윤리와 책임성:
- AI가 사회적 맥락에서 적절히 작동할지를 검증하는 데 필수적.
- 예: 잘못된 추론으로 인해 부적절하거나 유해한 결과를 초래하지 않도록 보장.
ToM 데이터셋을 통해 얻을 수 있는 통찰
ToM 데이터셋은 AI Agent가 단순히 데이터를 바탕으로 응답하는 시스템을 넘어, 인간과 유사한 방식으로 추론하고 적응할 수 있는지를 검증하는 핵심 지표입니다.
결론적으로:
- ToM 데이터셋은 AI의 사회적 지능(Social Intelligence) 수준을 측정하는 필수 도구로, AI 시스템이 인간의 인지적·정서적 추론 능력을 모방하려는 진화 단계에서 중요한 평가 방법입니다.
- 이를 통해 AI가 실질적으로 인간 수준의 추론 능력을 달성했는지 또는 단순히 통계적 패턴에 의존하는지를 판단할 수 있습니다.
그럼 이 논문은 언어 모델이 커질수록 인간을 정서적으로 모방한다는 것이 끝이야?
이 논문은 단순히 언어 모델(LLM)이 커질수록 인간의 정서적 모방 능력이 증가한다는 결론에서 멈추지 않습니다. 오히려, 이러한 주장에 대해 신중하고 비판적인 시각을 제시하며, LLM이 정말로 인간의 정서적 추론 능력을 모방한다고 주장하기에 충분하지 않음을 강조합니다.
논문의 주요 메시지와 결론
1. LLM의 정서적 모방 능력: 제한적이고 비일관적
- 언어 모델이 Neural Theory of Mind(N-ToM) 능력을 일부 보여주지만, 이는 인간 수준의 ToM이라고 보기에는 매우 취약합니다.
- 성공 사례: 일부 데이터셋에서 높은 성능을 기록(GPT-4가 특정 ToM 테스트에서 97% 정확도 달성).
- 실패 사례: 대립적 데이터(adversarial examples)나 새로운 유형의 질문에서는 성능이 급격히 저하.
- 이는 LLM이 깊이 있는 추론 능력이 아닌, 데이터 내 표면적 패턴(휴리스틱)에 의존함을 나타냅니다.
2. "모방"은 착각일 수 있음
- 모델이 보이는 "정서적 모방"은 실제 인간과 같은 인지 능력이 아니라 ELIZA 효과에서 비롯될 가능성이 높습니다.
- ELIZA 효과: 사람들은 컴퓨터가 단순히 언어적으로 적절하게 응답했을 때, 그것이 실제로 "생각"한다고 착각.
- LLM의 정교한 텍스트 생성 능력은 인간의 정서적 추론을 모방하는 것처럼 보이지만, 이는 단순히 훈련된 데이터를 기반으로 적절한 응답을 생성하는 것일 뿐.
3. 모델 크기 증가 ≠ 정서적 추론 능력 향상
- 모델 크기가 커질수록 일부 성능이 향상되지만, 이는 진정한 추론 능력이 아니라 더 많은 데이터와 계산 리소스를 통해 더 많은 패턴을 학습한 결과일 수 있습니다.
- 예: GPT-4는 특정 ToM 과제를 잘 수행했지만, 새로운 질문 형식이나 대립적 문제에서는 여전히 실패.
- 이는 "Emergent Abilities(출현 능력)" 주장에 대한 회의론을 뒷받침합니다. 단순히 모델 크기가 커진다고 해서 인간과 같은 정서적 추론이 자연스럽게 나타나는 것은 아님.
4. LLM의 한계: 인간 수준 ToM에 도달하지 못함
- 이 논문은 다음과 같은 이유로 현재의 LLM이 인간 수준의 ToM에 도달하지 못했다고 주장합니다:
- 표면적 학습: LLM은 데이터 내 패턴(문장 구조, 단어 빈도 등)에 의존하며, 실제로 타인의 신념이나 의도를 이해하지 못함.
- 취약성: 질문 형식이나 맥락의 작은 변화만으로도 성능이 크게 저하.
- 검증 부족: 모델 훈련 데이터가 공개되지 않아, ToM 테스트를 위한 데이터에 과도하게 노출되었을 가능성을 배제하기 어려움.
- 실제 ToM의 복잡성: 인간의 ToM은 언어 외에도 경험, 감정, 상호작용을 기반으로 하며, 현재의 텍스트 기반 모델로 이를 완전히 모방하기는 불가능.
결론: LLM의 ToM 연구가 제시하는 의미
이 논문은 "언어 모델이 커질수록 인간을 정서적으로 모방한다"는 단순 결론 대신, 다음과 같은 심층적인 통찰을 제공합니다:
- LLM은 아직 인간 수준의 정서적 추론 능력을 가지지 못함:
- 모델의 성능이 높아 보이더라도, 이는 진정한 추론보다는 데이터 패턴 암기에 가까움.
- AI가 인간 수준의 정서적, 사회적 지능을 가지려면 새로운 설계와 접근법이 필요.
- N-ToM 연구의 중요성:
- 인간처럼 타인의 감정과 신념을 이해하는 AI 시스템을 설계하려면, 기존의 심리학적 테스트를 넘어서는 맞춤형 평가 도구가 필요.
- 미래 연구 방향:
- LLM의 ToM 능력을 강화하려면 단순히 모델 크기를 키우는 대신, 대립적 데이터셋, 멀티모달 학습(텍스트 + 이미지/음성), 그리고 새로운 추론 알고리즘을 개발해야 함.
- AI의 윤리적 설계에도 ToM 연구가 중요한 기초를 제공.
결론적으로, 이 논문은 LLM의 성능을 과대평가하지 않으며, AI가 인간처럼 정서적으로 모방하려면 여전히 많은 연구와 발전이 필요함을 강조합니다. 따라서, 이 논문은 "끝"이라기보다는 AI의 인간 모방 능력을 평가하는 새로운 연구의 시작점으로 볼 수 있습니다.
최신 모델은 결과가 다를까?
최신 대규모 언어 모델(LLM)들은 이전 모델에 비해 '마음 이론'(Theory of Mind, ToM) 능력에서 향상된 성능을 보이고 있습니다. 예를 들어, GPT-4는 일부 ToM 과제에서 75%의 정확도를 기록하여 6세 아동 수준의 성능을 나타냈습니다.
또한, 챗GPT와 LLaMA2는 다른 사람의 정신 상태를 추적하는 능력 테스트에서 인간과 유사하거나 능가하는 성능을 보였다는 연구 결과도 있습니다.
그러나 이러한 성과에도 불구하고, 최신 모델들이 인간 수준의 ToM 능력을 완전히 갖추었다고 보기는 어렵습니다. 특히, 대립적 데이터나 새로운 유형의 질문에서는 성능이 저하되는 경향이 있으며, 이는 모델이 여전히 표면적 패턴 학습에 의존하고 있음을 시사합니다.
따라서 최신 모델들이 ToM 능력에서 진전을 이루고 있지만, 인간과 동일한 수준의 정서적 추론 능력을 완전히 달성하기 위해서는 추가적인 연구와 개선이 필요합니다.