https://arxiv.org/abs/2410.08869
Evolution of SAE Features Across Layers in LLMs
Sparse Autoencoders for transformer-based language models are typically defined independently per layer. In this work we analyze statistical relationships between features in adjacent layers to understand how features evolve through a forward pass. We prov
arxiv.org
이 논문은 SAE의 초기 논문 같네요
모든 Layer에 SAE를 장착하고, 그 SAE를 분석하여 Feature가 다음 레이어에 그대로 전달되거나, 합쳐지고, 사라지기도 하면서 정보가 전달되는 것을 볼 수 있습니다.
그러나 라벨링을 하여 진행한 논문이 아니기 때문에 오류는 발생할 수 있고, 샘플로 인한 오류로 통계적 편향도 있을 것입니다.
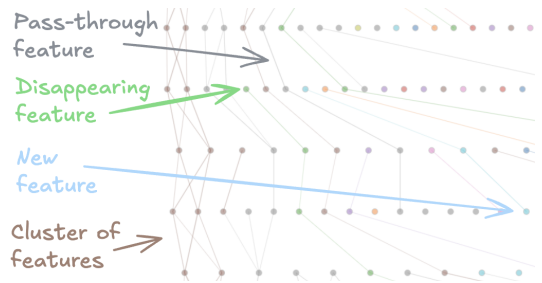
이 논문은 Sparse Autoencoder (SAE) 기능이 대형 언어 모델(LLM)의 여러 레이어를 거치면서 어떻게 변하는지를 분석하는 연구입니다. 각 단계별로 주요 내용을 체계적으로 요약하겠습니다.
1. 해결하려는 문제
이 연구는 SAE를 활용해 LLM의 각 레이어에서 활성화되는 특징(feature)들이 어떻게 변하고 연결되는지를 분석하려고 합니다. 기존의 기계 학습 모델 해석 방법론은 모델 내 개별 뉴런이 다중 기능을 동시에 수행할 수 있기 때문에 해석하기 어려운 단점이 있습니다. 이에 연구팀은 SAE를 사용해 더 높은 차원의 특성 공간에서 각 레이어의 활성화 패턴을 분리하여 이해 가능하도록 변환하고, 인접한 레이어 간에 이러한 특성의 연관성을 그래프 기반으로 시각화해 해석을 시도했습니다.
2. 연구 방법
이 논문에서는 GPT-2-small 모델을 대상으로 SAE를 적용하고, 각 레이어의 특성을 인접 레이어의 특성과 비교해 유사도를 측정하여 그래프를 생성했습니다. 이 그래프는 각 레이어의 특성들이 인접 레이어의 어떤 특성과 유사한지, 또는 새로운 특성이 생성되는지를 보여줍니다. 연구 방법에는 주로 다음과 같은 유사도 측정 방식이 포함되었습니다:
- 피어슨 상관 계수, 자카드 유사도, 충분성 및 필요성 측정치를 사용해 인접 레이어 간 특성의 유사성을 분석하고, 논리 게이트(AND/OR 게이트)와 유사한 관계도 확인했습니다.
3. 주요 결과
이 연구의 주요 발견사항은 다음과 같습니다:
- Pass-through 특성: 이전 레이어의 특성이 그대로 전달되는 경우가 많습니다. 이는 많은 특성이 LLM 내에서 레이어를 통과하면서 동일한 의미를 유지할 수 있음을 의미합니다.
- 새로운 특성: 이전 레이어에 존재하지 않지만 특정 특성들의 AND/OR 조합과 같은 형태로 새롭게 생성되는 특성이 발견되었습니다.
- 사라지는 특성: 반대로 다음 레이어에서 유사한 특성이 나타나지 않는 경우도 있어, 일부 특성은 특정 레이어에서만 유효하다는 점을 알 수 있었습니다.
- 기능적 특성 그룹화: 커뮤니티 감지 알고리즘(예: Leiden 알고리즘)을 적용해 의미상 유사한 특성들이 하나의 그룹으로 묶이기도 했으며, 이는 특정 문맥에서 특성이 더 구체적으로 분화되는 경우를 보여줍니다.
4. 한계점
이 연구는 상관관계에 기반한 분석으로, 실제 특성 간의 인과 관계를 증명하지 못한다는 한계가 있습니다. 또한, 데이터의 제한으로 인해 일부 결과는 스파스한 샘플로 인한 통계적 오류 가능성이 있으며, 사용된 유사도 측정 기준이 다르면 다른 결과가 나올 수 있습니다. 이를 해결하기 위해 더 다양한 유사도 측정 방식을 시도하거나, SAE 특성들의 기하학적 구조까지 고려한 추가 연구가 필요하다는 결론을 내렸습니다.
종합
이 연구는 LLM의 각 레이어에서 특성이 어떻게 변화하고 연결되는지에 대한 중요한 통찰을 제공합니다. SAE를 활용한 특성 해석은 LLM이 특정 문맥에서 특성을 어떻게 학습하고 적용하는지 이해하는 데 도움이 되며, 이는 더 효율적이고 해석 가능한 AI 모델을 만드는 데 기여할 수 있습니다.
뭔가 명확하게 이해가 되지 않는데 방법에 대해 좀 더 쉽게 설명해주라
이 연구의 방법을 쉽게 설명하겠습니다. 이 연구는 LLM의 각 레이어에서 특성이 어떻게 변화하는지를 파악하려는 시도입니다. 연구팀은 특히 Sparse Autoencoder(SAE)라는 기법을 사용해 각 레이어의 특성을 분석했습니다.
1. Sparse Autoencoder(SAE)란?
SAE는 뉴런처럼 복잡한 정보가 섞여 있는 모델의 활성화 신호를 보다 단순하게 풀어 보는 기법입니다. SAE를 사용하면 모델이 특정 상황에서 어떤 정보에 반응하는지, 각 레이어에서 정보가 어떻게 분리되고 변형되는지를 파악하기 쉽습니다.
2. SAE를 사용한 특성 연결 분석
LLM은 여러 레이어로 이루어져 있는데, 이 연구에서는 각 레이어에서 나타나는 특성들이 다음 레이어에서 어떻게 연결되는지를 알아보려고 합니다. 다음과 같은 방법으로 진행했습니다.
- 각 레이어의 특성 분석: 우선 LLM의 한 레이어에서 특정 단어 또는 문맥이 모델에 입력될 때, 활성화되는 특성들을 SAE로 표현합니다.
- 특성 유사도 계산: 특정 레이어의 특성과 인접한 다음 레이어의 특성이 얼마나 비슷한지를 확인합니다. 이때 사용된 유사도 계산 방법은 피어슨 상관 계수나 자카드 유사도 같은 통계적 계산법입니다. 예를 들어, 레이어 1의 특성이 레이어 2에도 비슷하게 나타난다면, 두 특성은 "비슷하다"고 평가할 수 있습니다.
- 특성 그래프 만들기: 레이어 간의 특성 유사도를 바탕으로 그래프를 만듭니다. 이 그래프는 각 레이어에서 서로 연결된 특성들을 시각화하여 보여줍니다. 즉, 한 레이어의 특성이 다음 레이어로 "그대로 전달되는지", "새로운 조합으로 나타나는지", 또는 "사라지는지"를 파악할 수 있습니다.
3. 각 특성의 변화와 해석
이렇게 만들어진 그래프를 통해, 연구팀은 특성이 레이어를 통과하면서 어떤 변화가 일어나는지를 분석할 수 있었습니다. 예를 들어:
- Pass-through 특성: 한 레이어의 특성이 다음 레이어로 그대로 전달되는 경우가 많았습니다.
- 새로운 특성: 이전 레이어의 특성들이 조합되어 새로운 방식으로 활성화되는 경우도 있었습니다(마치 논리 게이트의 AND/OR처럼).
- 사라지는 특성: 특정 레이어에만 존재하고 다음 레이어에서는 사라지는 특성도 있었습니다.
종합
이 연구는 복잡한 언어 모델 내부에서 특성이 레이어를 따라가며 어떻게 진화하는지를 시각적으로 분석하는 방법을 제시합니다. 이 과정에서 나온 특성들의 그래프는 특성이 얼마나 일관성 있게 이어지거나 분화되는지, 어떤 특성이 논리적으로 연결되는지 등을 알 수 있어 LLM을 더 깊이 이해하는 데 도움을 줄 수 있습니다.
레이어 마다 SAE도 다르고, Feature도 다른데 어떻게 통계적 방법을 통해서 유사도를 계산하는거야?
Feature가 뭘 뜻하는지를 하나 하나 라벨링하고 그 라벨링이 동일한지 보는 것이 좋은 것 아니야?
좋은 지적입니다. 이 연구에서는 통계적 방법을 통해서 각 레이어의 SAE와 Feature 간 유사도를 계산했지만, 말씀하신 대로 라벨링을 통한 일관성 평가가 더 명확한 방법일 수 있습니다. 실제로 이 연구는 모든 Feature에 대해 일일이 라벨링을 하기보다는 특성 간 유사도를 통계적으로 계산하는 방식으로 진행되었는데, 그 이유는 여러 레이어의 Feature들이 수십만 개 이상이라 일일이 라벨링하는 데 시간과 비용이 많이 들기 때문입니다.
연구팀은 피어슨 상관 계수와 같은 통계적 계산법을 사용해, 특정 레이어의 특성이 다음 레이어의 특정 특성과 얼마나 비슷하게 활성화되는지를 알아냈습니다. 이 통계적 유사도는 두 특성이 얼마나 자주 같이 활성화되는지를 반영하여, Feature들이 같은 의미를 가질 가능성을 간접적으로 추정할 수 있게 해줍니다.
하지만 말씀하신 방식대로 라벨링을 통해 각 Feature의 의미를 구체적으로 파악하고, 레이어 간 라벨의 일관성을 확인하는 방법이 실제 유사도를 더 정확히 반영할 수 있습니다. 특히, 언어 모델 내에서 특정 Feature가 특정 의미(예: 감정, 주제, 논리적 요소)를 나타낸다면, 같은 레이어 혹은 인접 레이어에서도 비슷한 의미를 유지하는지 직접적으로 확인할 수 있기 때문에 통계적 방법보다 더 해석에 용이할 수 있습니다.
그럼 피어슨 상관 계수를 어떻게 구한거야?
연구에서는 피어슨 상관 계수를 사용해 인접한 두 레이어 간 특성의 유사도를 계산했습니다. 이 과정은 다음과 같이 이루어집니다.
- SAE Feature 활성화 값 수집: LLM을 특정 데이터셋(예: 10M 토큰)으로 작동시켜 각 레이어에서 SAE 특성의 활성화 값을 수집합니다. 여기서 특성은 각 레이어의 SAE에 의해 정의된 여러 차원의 활성화 패턴입니다.
- 인접 레이어 특성 쌍 선택: 두 레이어에서 유사한 의미를 가질 것으로 예상되는 특성들을 특성 쌍으로 정의합니다. 각 쌍의 특성은 한 레이어의 특성과 그 다음 레이어의 특성으로 구성됩니다.
- 특성 간 활성화 값 상관도 계산: 한 레이어의 특정 특성의 활성화 값 벡터와 다음 레이어의 특성 활성화 값 벡터 사이의 피어슨 상관 계수를 계산합니다. 피어슨 상관 계수는 두 벡터의 변동 패턴이 얼마나 유사한지를 나타내며, 다음 수식을 사용합니다:여기서 X와 Y는 각각 인접 레이어에서 선택된 두 특성의 활성화 값 벡터이며, Xˉ와 Yˉ는 해당 벡터의 평균입니다.
- 유사성 임계값 적용: 계산된 피어슨 상관 계수가 일정 수준 이상(예: 0.95 이상)일 경우 두 특성이 의미상 유사하다고 판단합니다.

이 방법은 각 레이어의 특성이 일정한 변동 패턴을 가지면서 다음 레이어의 특정 특성과 얼마나 비슷하게 변화하는지를 나타내어, 같은 의미를 가질 가능성이 높은 특성들을 식별합니다.
그럼 이 논문에선 이렇게 실험을 한 결과 특정이 전달되는 것을 보면 레이어를 통과하며 동일한 의미를 유지할 수 있다는 것을 볼 수 있고, 새로운 특징이 이전 레이어의 feature들의 합으로 생길 수도, 사라질 수도 있다는 것이네?
맞습니다, 정확하게 이해하셨습니다! 이 논문에서는 이러한 실험을 통해 다음과 같은 결론을 도출했습니다:
- 특성이 그대로 전달되는 경우: 피어슨 상관 계수를 통해 인접한 레이어 간의 특정 특성들이 높은 유사도를 유지하는 경우가 많이 관찰되었습니다. 이는 특정 특성이 여러 레이어를 통과하면서도 동일한 의미를 유지할 수 있다는 것을 보여줍니다. 예를 들어, 레이어 1에서 감정과 관련된 특정 특성이 활성화되었다면, 레이어 2에서도 유사한 감정과 관련된 특성이 나타날 수 있다는 것입니다.
- 새로운 특성이 생성되는 경우: 이전 레이어의 여러 특성들이 결합되어 새로운 특성으로 나타나는 경우도 발견되었습니다. 연구에서는 이것을 논리 게이트(AND/OR 게이트)와 비슷한 형태로 설명합니다. 즉, 레이어 1에서 두 개의 특정 특성이 동시에 활성화되었을 때, 레이어 2에서는 이를 결합한 새로운 특성이 생성될 수 있다는 것입니다.
- 특성이 사라지는 경우: 반대로, 특정 특성들이 다음 레이어로 전달되지 않고 사라지는 경우도 관찰되었습니다. 이는 특정 레이어에서만 필요했던 특성이 이후 레이어에서는 더 이상 중요하지 않게 되어 정보 흐름에서 제외되는 경우를 의미합니다.
결과적으로, 연구팀은 LLM 내에서 특성들이 레이어를 통해 전달되거나 변형되는 방식을 분석함으로써, 모델 내부의 정보 흐름과 의미적 변화를 더 깊이 이해할 수 있었습니다. 이러한 분석은 모델이 텍스트를 처리할 때 어떻게 정보를 유지하거나 재구성하는지를 파악하는 데 큰 도움이 됩니다.