R studio 다크 모드 변환

Global Options 선택

Apperance에서 Editor theme보기

Night 중 원하는 테마로 선택하기
실행은 항상 Ctrl + Enter
# plotrix 패키지 설치 연습
install.packages("plotrix")
# 패키지 로드(불러들이기기)
library(plotrix)
# 예제 데이터 생성
# c는 벡터 형식으로 데이터를 만든다.
slices <- c(25,5,40,30,8) # 정수 벡터 5개
labels <- c("서울","부산","인천","경기","제주") # 텍스트 벡터 5개
# 3D 파이 차트를 생성
# 엔터는 , 뒤에서 치면 상관 없다.
# explode 1 ~ 0.1 표를 펼쳐준다.
# main = 제목
# col = 라벨과 매칭되는데 색을 지정해줬다.
pie3D(slices, labels = labels, explode = 0.1, main = "전국 5대 도시 인구밀도",
col = c("red", "blue", "green", "yellow", "purple"))
r은 인터프리터 언어이다 = 한 줄 한 줄 실행한다. -> 오류 나지 않은 곳 까지 실행 가능하다.
# 뒤에 주석 작성하여 가독성 높이기!
# 단어 치다가 shift누르면 완성해주거나 추천해주는데 이 기능을 애밋이라고 부른다.
# 설치한 패키지 확인
??plotrix
# 설치한 패키지 삭제
remove.packages("plotrix")
다시 ??plotrix하면 결과가 안 나온다.

새로운 파일 시작
변수-데이터할당
# Save As...를 통해서 test-01(변수-데이터할당).R 저장
# 연습을 위한 디렉토리지정하기
# 역슬레쉬 구분 잘 해주기 - 한개만 있으면 이스케이프로 알아들으니 2개씩 작성
setwd("c:\\MY_Data_Test")
# 파일 불러오기
getwd()
# 파일 내용 확인하기
# 현재 폴더 내부의 파일들이 보인다.
dir()
list.files()
# [변수란?]
# 변수란? 데이터 값을 담아놓는 그릇이라고 생각하면 됩니다.
# 변수에 데이터 값을 '할당' 할때 <- 또는 = 기호를 사용합니다.
# 데이터는 <-, 또는 = 기호를 기준으로 오른쪽에서 왼쪽으로 "할당" 됩니다.
a = 3
b = 2
# ** 제곱
c = a**b
# [변수1]
number1 <- 100
# number1은 100이라는 데이터가 저장된 곳의 주소 값을 가지고 있다.
number2 = 200
text1 <- "대한민국"
number3 <- number1
number3 = number3 + 5
# number3는 주소 값(100을 가르키는, number1과 같은)을 가지고 있었지만
# 이렇게 하게 되면 새로운 주소(105를 가르키는)를 가지게 된다.
number4 = number2 + 5
text2 = text1
# 출력 제어하기
# paste 두 개의 벡터 값을 묶어서 2개 이상 출력하게 해준다.
# print 하나만 출력해준다.
# cat
text3 = paste(text2, "~~ 만세")
# [변수2]
# 변수에 데이터 값을 할당할 때 주의점은 "" 또는 ''로
# 묶어서 사용자가 지정한 변수에 할당하게 되면
# 문자 혹은 문자열 데이터로 저장 됩니다.
# 만일 "" 또는 ''를 적용하지 않으면 오류! 발생
text5 <- 빅데이터 분석실무 2급 #오류! 발생 값을 할당하지 못한다.
text6 <- "빅데이터 분석실무 2급" #문자열로 저장
text5 <- paste(text6, "합격!")
# [변수3]
# print()함수를 통해서 출력 연습
# 앞에서는 변수에 값을 할당하고, 콘솔에서 해당 변수에
# 값이 어떻게 할당 되었는지? 변수명을 직접 타이핑
text7 <- "빅데이터 분석실무 2급" # <- (gets)할당연산자라 한다.
print(text7)
# [변수4]
# 변수에 숫자, 문자열, 벡터(c), 데이터프레임(data.frame), 리스트(list) 데이터
# 행렬 데이터 할당을 통한 print()함수 활용 출력 연습
# 1. 숫자 데이터 할당
my_number <- 77
my_number1 <- 1234
print(my_number)
print(my_number1)
# 2. 문자열열 데이터 할당
my_string <- "Hello, R!"
my_string1 <- "Hello, RRRRRRRR!"
print(my_string)
print(my_string1)
# 3. 벡터(vector) 데이터 할당
# c = combine
my_vector <- c(1, 2, 3, 4, 5)
print(my_vector)
# 결측치가 생겼다. 여기에 대한 대안이 있어야 한다.
my_vector2 <- c(1, 2, NA, 4, 5)
# 문자열 벡터
my_vector1 <- c("새우깡","짱구","바나나킥","짱구","치킨","먹고 싶다")
print(my_vector1)
# 4. 데이터프레임 할당
# 이름 나이 성별이 열이 된다.
# 유관순 윤봉길 안중근이 행이다.
my_dataframe <- data.frame(
Name = c("유관순", "윤봉길", "안중근"),
Age = c(17, 24, 30),
Gender = c('여자', "남자", "남자")
)
print(my_dataframe)
# 접근할 때는 대괄호 안에 인덱스 번호로 접근한다.
print(my_dataframe[1])
print(my_dataframe[1,1])
# 키와 벨류를 묶는다!
my_dataframe1 = data.frame(
상품명 = c("치킨","소주","맥주","콜팝","짬뽕"),
가격 = c(19000, 5000, 6000, 4000, 11000),
비고 = c("뼈, 순살 선택 가능","19세","19세","사이즈 업","해물;/차돌"),
추가금 = c(1500,0,0,1000,1000)
)
print(my_dataframe1)
# 리스트에는 문자열, 데이터 프레임, 벡터, 숫자 등 다양하게 들어갈 수 있다.
# 5. 리스트 데이터 할당
# R 프로그래밍에서 리스트는 여러 종류의 데이터를
# 하나의 객체로 묶어 저장할 수 있는 구조입니다.
# 리스트 안에는 숫자, 문자열, 벡터, 데이터프레임 등
# 다양한 형태의 데이터를 포함할 수 있습니다.
# 리스트를 생성하고 출력하면 각 요소는 $ 기호를
# 사용하여 접근할 수 있습니다.
my_list <- list(
Number = my_number,
String = my_string,
Vector = my_vector,
Dataframe = my_dataframe,
Dataframe1 = my_dataframe1
)
print(my_list)
# 리스트에서 키 값에 접근할 때 $를 사용한다.
print(my_list["Vector"])
print(my_list$"Vector")
print(my_list$Vector)
print(my_list$Vector[2])
print(my_list[3])
print(my_list[3][1])
print(my_list[3][1][2])
# 6. 행렬 데이터 할당
# nrow, ncol로 행과 열의 크기를 지정해준다.
# 하나만 지정해줘도 나머지는 알아서 나눠서 넣어준다.
my_matrix = matrix(1:9, nrow= 3, ncol = 3)
print(my_matrix)
# 빈 열은 끄집어서 재 반복하기도 한다.
my_matrix1 = matrix(1:9, nrow= 3, ncol = 5)
print(my_matrix1)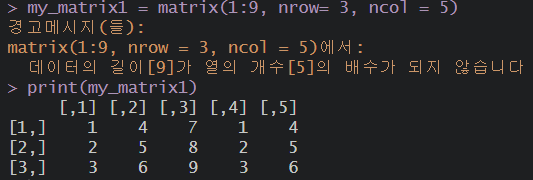
# [변수5]
# 변수에 날짜 데이터 할당 연습
# as.Data() 함수를 사용하여 변수에 날짜 데이터 적용
# class() 함수를 적용하여 변수에 할당된 유형(type) 확인하기
# R 프로그램에서 날짜 형식은 내부적으로 Data 클래스로 저장 됩니다.
# "YYYY-MM-DD" 형식으로 출력합니다.
# 1. 변수에 날짜 데이터 적용 연습
# incorrect뜻:잘못된
# correct뜻 : 옳은
incorrect_date = "2024/07/01" #(문자열 할당)
print(incorrect_date)
incorrect_date1 <- "2024-07-01" #(문자열 할당)
print(incorrect_date1)
correct <- as.Date("2024/07/01")
print(correct)
# [변수5-1 유형(type) 확인하기기]
# 변수에 적용된 데이터 유형(type) 확인하기
# 1. 변수에 날짜 데이터 적용 연습
# incorrect뜻:잘못된
# correct뜻 : 옳은
incorrect_date = "2024/07/01" #(문자열 할당)
print(incorrect_date)
class(incorrect_date)
incorrect_date1 <- "2024-07-01" #(문자열 할당)
print(incorrect_date1)
print(class(incorrect_date1))
# 날짜 데이터는 항상 as.Data 사용하기!
correct <- as.Date("2024/07/01")
print(correct)
print(class(correct))
# class는 데이터 유형을 보여준다. - 다른 언어에서는 type로 구현되어 있다.
class(3)
class(3.14)
class(my_list)
class(my_dataframe)
class(my_vector)
class(my_matrix)
이제 여기부턴 2번째 파일
# [데이터 유형/숫자형]
# 데이터 유형중에서 '숫자형'에 대해서 학습 합니다.
# 숫자형 데이터는 정수, 실수, 복소수 등이 있습니다.
# 덧셈, 뺄셈, 곱셈, 나눗셈, 나머지, 몫을 구하는 연산식 학습을 합니다.
# 1. 숫자형 데이터 할당
num1 <- 25
num2 = 4
# 2. 사칙연산 수행
sum_result <- num1 + num2 #덧셈
diff_result <- num1 - num2 #뺄셈
prod_result <- num1 * num2 #곱셈
quot_result <- num1 / num2 #나눗셈
mod_result <- num1 %% num2 #나머지
int_div_result <- num1 %/% num2 #몫
exp_result = num1 ** num2 #거듭제곱
# 3. 결과를 print()함수 이용 출력하기
print(paste("덧셈 결과:", sum_result))
print(paste("뺄셈 결과:", diff_result))
print(paste("곱셈 결과:", prod_result))
print(paste("나눗셈 결과:", quot_result))
print(paste("나머지 결과:", mod_result))
print(paste("몫의 결과:", int_div_result))
print(paste("거듭 제곱의 결과:", exp_result))
여기서 프린트에 대해 조심해야 한다.
print("거듭 제곱의 결과:", exp_result)
안된다.
#====cat() 함수를 이용하여 출력해 보겠습니다.!!!
# cat(): concatenate (연결하다) 함수는 여러 문자열을
# 결합하여 출력하는데 유용 합니다.
# \n(Enter) 안써도 된다. 가독성을 늘려준다.
# print는 ""로 묶여있어 문장으로 나오지만 cat는 백터 값의 요소로 나온다.
cat("\n", "덧셈 결과: ", sum_result, "\n",
"뺄셈 결과: ", diff_result, "\n",
"곱셈 결과: ", prod_result, "\n",
"나눗셈 결과: ", quot_result, "\n",
"나머지 결과: ", mod_result, "\n",
"몫의 결과: ", int_div_result
)
# 주의사항!
# print() 함수 사용시 두 개의 인수(인자)값을 전달하여
# 출력이 안됩니다. print("덧셈 결과: ", sum_result) 이런식으로
# 하면 출력이 안된다.
print("덧셈 결과: ", sum_result) # 오류발생!
print(cat("덧셈 결과: ", sum_result))
#cat() 함수는 자동으로 Null값을 반환
print(paste("덧셈 결과: ", sum_result))
# paste 도 출력을 해준다. data.frame에서 오류가 난다.
paste("덧셈 결과: ", sum_result)
# 이렇게도 가능 e에 저장된다.
e = paste("덧셈 결과: ", sum_result)
# [데이터 유형/숫자형]
# R 프로그래밍에서 숫자형을 나타내는 여러 가지 유형 학습
# 정수에서 0의 자리는 4자리까지 표현
# 0의 갯수가 5개부터는 지수 표현e
int_number4 <- 50000
print(paste("4자리 표현: ", int_number4))
# 5자리 부터는 지수로 표현
int_number5 <- 500000
print(paste("5자리 표현: ", int_number5))
# 6자리 부터는 지수로 표현
int_number6 <- 5000000
print(paste("6자리 표현: ", int_number6))
# 8자리 부터는 지수로 표현
int_number8 <- 500000000
print(paste("8자리 표현: ", int_number8))
# 소수점 세 째자리까지 정상 표기
exp_notation3 <- 0.001
print(paste("소숫점 세 째자리: ", exp_notation3))
# 소수점 넷째 자리까지 정상 표기
exp_notation4 <- 0.0001
print(paste("소숫점 넷 째자리: ", exp_notation4))
# 소수점 다섯 째자리까지 정상 표기
exp_notation5 <- 0.00001
print(paste("소숫점 다섯섯 째자리: ", exp_notation5))
# 데이터 분석을 할 때 0의 개수가 5개가 넘는 경우도 아주 많고
# 소수점이하 4자리가 넘어 가는 경우도 아주 많습니다.
# 예를 들어 인구수나 고객 현황, 교통 이용 승객 현황
# 이런 것들이 아주 단위가 큽니다.
# 그리고 특히 돈과 관련된 분석을 할때에도 아주 단위가
# 크기 때문에 지수로 표현하는 방법에 익숙해져야 합니다.
숫자형과 함께사용되는 함수
# [데이터 유형/round(), trunc(), ceiling(), floor() 함수]
# 숫자형 데이터와 함께 많이 사용되는 함수 이다.
# 이 함수 들은 숫자를 반올림하거나, 버리거나, 올리거나,
# 내리는 데 사용됩니다.
# [숫자형과 함께 사용되는 함수]
# 변수에 "양의 숫자 값"을 할당 합니다.
test_number <- 3.567
# round()함수 연습: 지정된 소수점 이하 자리를 반올림 한다.
# 기본값과 가장 가까운 정수로 반올림 한다.
round_value <- round(test_number) #기본 반올림(가장 가까운 정수)
round_value_2_decimals <- round(test_number, 2) #소수점 두 째자리까지 반올림
# trunc(트런크)함수 연습: 소숫점 부분을 자르고, 숫자를 정수로 잘라낸다.
trunc_value <- trunc(test_number)
# ceiling()함수 연습: 숫자를 올림하여 가장 가까운 정수로 만듭니다.
#오름차순하여 가장 가까운 값이다.
ceiling_value <- ceiling(test_number)
# floor() 함수 연습: 숫자를내림하여 가장 가까운 정수로 만듭니다.
floor_value <- floor(test_number)
# 결과를 cat() 함수를 활용하여 출력해 봅니다.
cat("원래 숫자: ", test_number, "\n")
cat("가장 가까운 정수로 반올림: ", round_value, "\n")
cat("소수점 두 째자리까지 반올림: ", round_value_2_decimals, "\n")
cat("소수 부분을 자른 값: ", trunc_value, "\n")
cat("숫자 올림한 값: ", ceiling_value, "\n")
cat("숫자 내림한 값: ", floor_value, "\n")
#====
# 변수에 "음의 숫자 값"을 할당 합니다.
neg_number <- -3.567
# round()함수 연습: 지정된 소수점 이하 자리를 반올림 한다.
# 기본값과 가장 가까운 정수로 반올림 한다.
round_neg <- round(neg_number)
# trunc(트런크)함수 연습: 소숫점 부분을 자르고, 숫자를 정수로 잘라낸다.
trunc_neg <- trunc(neg_number)
# ceiling()함수 연습: 숫자를 올림하여 가장 가까운 정수로 만듭니다.
ceiling_neg <- ceiling(neg_number)
# floor() 함수 연습: 숫자를내림하여 가장 가까운 정수로 만듭니다.
floor_neg <- floor(neg_number)
# 결과를 cat() 함수를 활용하여 출력해 봅니다.
cat("원래 숫자: ", neg_number, "\n")
cat("가장 가까운 정수로 반올림: ", round_neg, "\n")
cat("소수 부분을 자른 값: ", trunc_neg, "\n")
cat("숫자 올림한 값: ", ceiling_neg, "\n")
cat("숫자 내림한 값: ", floor_neg, "\n")
cat("\n", "원래 숫자: ", neg_number, "\n",
"가장 가까운 정수로 반올림: ", round_neg, "\n",
"소수 부분을 자른 값: ", trunc_neg, "\n",
"숫자 올림한 값: ", ceiling_neg, "\n",
"숫자 내림한 값: ", floor_neg, "\n")
데이터 유형-문자형
class(5)
class('5')
class("2024-07-01")
class('R is good~~!')
value <- 3
value1 <- 3
value2 <- '4'
value1 + value2
자료형이 다르면 더 할 수 없다.
#=====
# R 프로그래밍에서 문자열 데이터를 다루는 기본적인 학습을 위해
# 다음과 같은 함수에 사용법을 알고 있어야 합니다.
# paste(), nchar(), substr(), strsplit(), sub() 함수~
# 학습을 위해 다음과 같이 연습 합니다.
# nchar - 길이 확인인
# strsplit - 데이터 자르기
# 1. 문자열 생성하기
str1 <- "Hello"
str2 <- "World"
my_str1 = "치킨 먹고 싶다"
my_str2 = readLines("c:\\MY_Data_Test\\data\\data1.txt")
# 2. 문자열 결합
combined_str <- paste(str1, str2)
#=== 쉼표와 공백을 사이에 두고 결합
print(combined_str)
paste("맥주랑",my_str1)
combined_str_with_sep <- paste(str1, str2, sep = "/ ")
combined_str_with_sep2 <- paste(str1, str2, sep = "\n")
#=== 쉼표와 공백을 사이에 두고 결합
print(combined_str_with_sep) # "Hello/ World"
print(combined_str_with_sep2) # "Hello\nWorld"
paste(paste("ab","cd" , sep = ","),paste("ef","gh" , sep = "/") , sep = "+") #"ab,cd+ef/gh"
paste(paste("ab","cd" , sep = ""),paste("ef","gh" , sep = "") , sep = "") #"abcdefgh"
# paste 안에 여러개도 가능하다.
paste("ab","cd","ed","gh") #"ab cd ef gh"
paste("ab","cd","ed","gh",sep ="") #"abcdefgh"
# 3. 문자열의 길이 확인
str_length <- nchar(str1) # 5
paste("nchar는 길이를 알려준다 str_length:",str_length)
# 4. 특정 위치의 문자 추출
first_char <- substr(str1, 1, 1) #H
#=== 첫 번째 문자 추출
substring_example <- substr(str1, 2, 4) #ell
#=== 두 번째 문자부터 네 번째 문자까지 추출
# 5. 문자열 분할
split_str <- strsplit(str1, "")
# paste로 하게 되면 쓰레기 값이 첨가된다.
paste("결과 값은 :",split_str)
print(split_str)
# 대괄호가 두개있는 [[1]]이므로 for문에서 하나씩 꺼낼 수 있다.
print(split_str[[1]])
print(split_str[[1]][1])
split_str1 <- strsplit(str1, "t")
print(split_str1)
split_str2 <- strsplit("stetrtqtwtetrtttt", "t")
print(split_str2)
split_str3 <- strsplit("ttt", "t")
print(split_str3)
# 6. 문자열 대체
replace_str <- sub("World", "R♥", combined_str) # "Hello World" -> "Hello R♥"
#=== combined_str로 결합된 문장에서 "World"를 "R♥"로 대체
replace_str2 = sub("치킨","치킨 피자 삼겹살",my_str1)# "치킨 먹고 싶다" -> 치킨 피자 삼겹살 먹고 싶다"
print(my_str1)
print(replace_str2)
정리
#=== 작성된 코드에 대한 출력
cat("문자열 1: ", str1, "\n")
cat("문자열 1: ", str2, "\n")
cat("결합된 문자열:", combined_str, "\n")
cat("결합된 문자열(쉼표 포함)", combined_str_with_sep, "\n")
cat("문자열 1의 길이:", str_length, "다", "\n")
cat("문자열 1의 첫 문자:", first_char, "\n")
cat("문자열 1의 부분 문자열(2-4문자):", substring_example, "\n")
# 여기는 무조건 대괄호 두개를 넣어줘야 한다.
cat("문자열 1의 각 문자 분할:", split_str[[1]], "\n")
cat("대체된 문자열:", replace_str, "\n")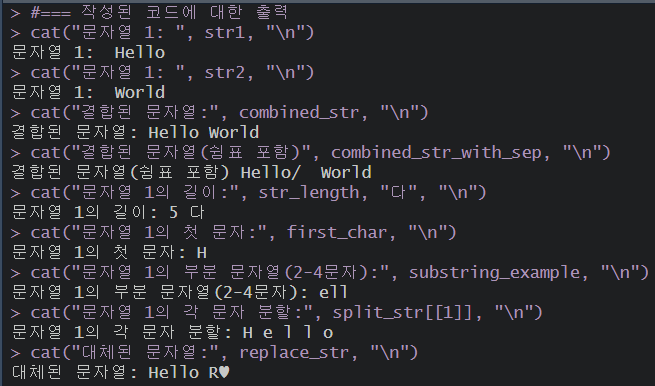
#==응용 연습
text1 <- "대한민국 대표음악 K-POP"
split_text1 <- strsplit(text1, "")
split_text2 <- strsplit(text1, ",") #, 쉼표로 구분~ 결과 오류
split_text3 <- strsplit(text1, " ") # 스페이스바 구분~ 결과 오류
split_text4 <- strsplit(text1, "")
print(split_text1)
print(split_text2)
print(split_text3)
print(split_text4[[1]])
#==
#=== strsplit() 추가설명!!
# strsplit() 함수는 데이터 전처리과정에서 사용되는 함수라는 것을
# 잘 기억해 두면 좋을 것 같습니다.
#=== 특정 문자(쉼표)를 기준으로 문자열 분할!
str3 <- "사과, 바나나, 오렌지, 딸기, 감자, 고구마"
split_str3 <- strsplit(str3, ",")
cat("공백을 기준으로 문자열 분할:\n")
cat("원본 문자열:", str3, "\n")
cat("분할된 문자열:", split_str3[[1]], "\n\n")
#=== 여러 개의 분할 기준을 사용하여 문자열 분할
str4 <- "세계;기후변화;:여러나라,유럽국가;인구밀도.기후:아시아,;"
split_str4 <- strsplit(str4, "[:;,.]+")
# +기호는 str4변수에 할당된 데이터(문장)중에서 해당 기호(:;,.)가
# 1회이상 반복되면 분류하라~
cat("여러 개의 분할 기준을 사용한 문자열 분할:\n")
cat("원본 문자열:", str4, "\n")
cat("분할된 문자열:", split_str4[[1]], "\n\n")
#==위에서 출력된 값을 데이터프레임에 넣어보겠습니다.
데이터프레임 <- data.frame(단어분류 = split_str4[[1]])
print(데이터프레임)
데이터 유형-날짜형
# [데이터 유형/날짜형 데이터]
# 날짜형 데이터 생성
date_1 <- as.Date("2024-06-19")
date_2 <- as.Date('2023-06-20')
date_3 <- "2024-07-01"
# 날짜형 데이터 출력
print(date_1)
print(class(date_1))
print(date_2)
print(class(date_2))
print(date_3)
print(class(date_3))

# 날짜 간 차이 계산
date_diff <- date_1 - date_2
print(date_diff)
# 날짜 데이터로부터 연도, 월, 일 추출
Year <- format(date_1, "%Y")
year <- format(date_1, "%y")
month <- format(date_1, "%m")
day <- format(date_1, "%d")
print(Year)
print(year)
print(month)
print(day)
date_3 <- as.Date("1756-07-19")
date_diff <- date_3 - date_2
print(date_diff)
paste("현재의 연도는",Year,"이다")
# 날짜 데이터 변환(문자열을 날짜로)
date_str <- "2024-06-19"
converted_date <- as.Date(date_str, format="%Y-%m-%d")
print(converted_date) # "2024-06-19"
class(converted_date) # date
converted_date1 <- as.Date("2024-06-19") # "2024-06-19"
converted_date2 <- as.Date("24-06-19", format="%Y-%m-%d") # "0024-06-19"
converted_date3 <- as.Date("24-06-19", format="%y-%m-%d") # "2024-06-19"
형을 잘 맞춰야 정확한 날짜 표현이 가능하다.
# 날짜 데이터 변화 as.POSIXct()함수
# as.POSIXct()함수는 R에서 날짜와 시간을 표현하는 데 사용되는
# 두 가지 주요 클래스 중 하나입니다.
# POSIXct 클래스는 날짜와 시간을 초 단위로 저장하며,
# 주로 날짜와 시간 데이터를 연산하고 조작하는 데 매우 유용합니다.
datetime_str <- "2024-06-19 15:34:22"
converted_datetime <- as.POSIXct(datetime_str, format="%Y-%m-%d %H:%M:%S", tz = "UTC")
print(datetime_str)
class(datetime_str)
print(converted_datetime)
class(converted_datetime)
# as.POSIXct() 함수를 활용한 추가 예제
# 날짜와 시간 데이터를 문자열로 생성
date_str1 <- "2024-06-29 15:30:00"
date_str2 <- "24-07-01 08:45:00"
# 문자열을 POSIXct 객체로 변환
date_1 <- as.POSIXct(date_str1, format="%Y-%m-%d %H:%M:%S", tz = "UTC")
date_2 <- as.POSIXct(date_str2, format="%y-%m-%d %H:%M:%S", tz = "UTC")
# 변환된 POSIXct 객체 출력
print(date_1)
print(date_2)
Y, y 를 잘 써서 적절하게 변환할 수 있다.
# 두 날짜 사이의 시간 차이 계산
time_diff <- difftime(date_2, date_1, units = "hours")
day_diff <- difftime(date_2, date_1, units = "days")
# unit 인수값으로
# - "secs": 초 단위로 차이를 계산합니다.
# - "mins": 분 단위로 차이를 계산합니다.
# - "hours": 시간 단위로 차이를 계산합니다.
# - "days": 일 단위로 차이를 계산합니다.
# - "weeks": 주 단위로 차이를 계산합니다.
# - "auto": 자동으로 적절한 단위를 선택합니다.
# 시간 차이 출력
print(paste("시간 차이:", time_diff, "시간"))
print(paste("날짜 차이:", day_diff, "일"))
# 현재 시간 가져오기
current_time <- Sys.time()
print(paste("현재 시각: ", current_time))
# 현재 시간과 특정 시간 사이의 차이 계산
current_diff <- difftime(current_time, date_1, units = "hours")
print(paste("현재 시간과", date_str1, "사이의 시간 차이:",
current_diff, "시간"))
# 특정 시간에 1일 추가하기
new_date <- date_1 + 24*60*60 # 24시간 60분 60초
print(paste("1일 추가된 날짜와 시간:", new_date))
날짜형 추가
# [데이터 유형/날짜형 데이터 추가 학습]
# lubridate() 함수에 대해서 알아보겠습니다.
# lubridate 패키지를 사용하려면 패키지를 설치하고 로드해야 합니다
# RStudio에서 이를 위해 install.packages() 함수와 library() 함수 사용
# lubridate 패키지는 날짜와 시간을 더 쉽게 다룰 수 있도록 도와주는
# 다양한 함수들을 제공합니다.
# 패키지 설치(한 번만 실행합니다.)'
install.packages("lubridate")
중복 설치하진 말기! - 처음엔 Yes
# 패키지 로드(매 세션마다 적용합니다)
library(lubridate)패키지 로드 해줍니다.
# 패키지가 로드 되었기에 학습을 합니다.
# 날짜와 시간 데이터 생성
date_str1 <- "2024-06-30"
date_str2 <- "2024/06/30"
date_time <- "2024-06-30 15:34:22"
# lubridate 패키지에 as_date() 함수를 사용 문자열을
# 날짜형 데이터로 변환
date_1 <- as_date(date_str1)
date_2 <- as_date(date_str2)
print(date_1)
class(date_1)
print(date_2)
class(date_2)
# lubridate 패키지에 ymd()함수를 사용 문자열을 날짜형
# 데이터로 변환
date_ymd <- ymd(date_str1)
print(date_ymd)
class(date_ymd)
더 유하고, 자유로운 사용이 가능하다. 띄어쓰기가 있어도 잘 바꿔준다. y Y도 알아서 구분한다.
# lubridate 패키지에 ymd_hms()함수를 사용 문자열을
# UTC표준 날짜-시간형 데이터로 변환
datetime_hms <- ymd_hms(date_time)
print(datetime_hms)
# 날짜 데이터로부터 연도, 월, 일 추출하기
연 <- year(date_1)
월 <- month(date_1)
일 <- day(date_1)
print(연)
print(월)
print(일)
정리 안해줘도 되는게 너무 편하긴 하네요
date_time <- "2025-07-28 15:34:22"
datetime_hms <- ymd_hms(date_time)
연 <- year(datetime_hms)
월 <- month(datetime_hms)
일 <- day(datetime_hms)
시 <- hour(datetime_hms)
분 <- minute(datetime_hms)
초 <- second(datetime_hms)
print(연)
print(월)
print(일)
print(시)
print(분)
print(초)
다되네 ㄷㄷ
# 날짜 간 차이 계산
date_3 <- ymd("2024-06-19")
date_4 <- ymd("2023-06-20")
날짜차이 <- date_3 - date_4
print(날짜차이)
# 날짜 데이터에 "시간" 추가하기
new_datetime_1 <- date_3 + hours(9) + minutes(35) + seconds(34)
print(new_datetime_1)
new_datetime_2 <- date_4 + hours(25) + minutes(35) + seconds(34)
print(new_datetime_2)
# hours(??) 소괄호안에 시간을 26으로 하면 새벽2시
# hours(??) 소괄호안에 시간을 25으로 하면 새벽1시
데이터 유형-NA 형 학습
# [데이터 유형/NA 형 학습]
# NA란(Not Available “해당없음”)의 약자로 사용할 수 없는
# 데이터를 말합니다.(결측치 값이라고 합니다.)
# 따라서 NA 값으로 연산을 하게되면 결과값은 NA가 됩니다.
# [NA 연산을 학습합니다]
# NA(결측치) 형 데이터 생성
x <- c(1, 2, NA, 4, 5)
print(x)
# NA를 포함한 벡터의 평균 계산
mean_x <- mean(x, na.rm = TRUE)
print(mean_x)
# na.rm = TRUE라는 속성은 결측치 값을 무시하고 평균을
# 구하라는 부분이기에 위 계산값은 12 / 4(개수) 하기에 3이다.
# NA(결측치)를 다른 값으로 대체
x[is.na(x)] <- 0
# is.na(x) 함수는 벡터 x의 각 요소가 NA인지를 확인하여
# 논리형 벡터를 반환합니다.
# 결측치값이 있는 자리는 TRUE, 없는 자리는 FALSE를 반환하여
# TRUE 자리값을 숫자 0으로 대체
# R 프로그래밍에서는 대괄호[]는 리스트, 벡터 등 데이터에 접근
# 할 수 있는 선택 방법이다.
print(x)
is.na는 결측치를 찾아서 결측치인 부분을 True로 준다.
# NA(결측치 값)을(를) 포함한 데이터 프레임 생성 후 연산1
df <- data.frame(
col1 = c(1, 2, NA, 4),
col2 = c(NA, 5, 6, NA)
)
print(df)
print(is.na(df))
# 결측값을 포함한 열의 평균 계산 및 대체
df$col1[is.na(df$col1)] <- mean(df$col1, na.rm = TRUE)
df$col2[is.na(df$col2)] <- mean(df$col2, na.rm = TRUE)
print(df)

이렇게 나옵니다
이젠 대체하지 말고 빼버리기!
# NA(결측치 값)을 포함한 데이터 프레임 생성 후 연산2
df <- data.frame(
col1 = c(1, 2, 3, 4),
col2 = c(5, NA, NA, NA),
col3 = c(7, 8, 9, 10)
)
print(df)
# 결측값이 포함된 행을 제거하고 출력
df_no_na_rows <- df[complete.cases(df), ]
print(df_no_na_rows)
# 결측값이 포함된 열 제거하고 출력
df_no_cols <- df[, colSums(is.na(df)) == 0]
print(df_no_cols)

이러한 결과로 행과 열들이 빠지게 됩니다.

평균값으로 채우기
데이터 유형-NULL 형 학습
# [데이터 유형/NULL 형 학습]
# NULL 형 학습을 하기위해서 우선 NA 형과 차이점을 확인 합니다.
# NA(결측치 값) 연산!!
Na_num <- sum(10, NA, 20)
print(Na_num)
#====
#NULL 연산!!
Null_num4 <- sum(10, NULL, 20)
print(Null_num4)
NA는 연산이 안되지만 NULL은 연산이 됩니다! 왜?
R에서 NA와 NULL은 서로 다른 의미와 용도를 가진 값으로, 연산에서 차이가 나타납니다. 이 둘의 차이점을 설명하겠습니다.
NA (Not Available)
- NA는 결측값(missing value)을 나타내며, 데이터의 값이 없거나 알 수 없음을 의미합니다.
- 연산에서 NA가 포함되면, 그 결과도 NA가 됩니다. 이는 결측값이 포함된 연산의 결과가 불확실하기 때문입니다.
- 예를 들어:
위 코드에서 sum(x)의 결과는 NA입니다. 결측값이 포함된 데이터에 대해 합을 구할 수 없기 때문입니다.x <- c(1, 2, NA, 4) sum(x)
NULL
- NULL은 객체가 존재하지 않음을 의미하며, 주로 리스트, 데이터 프레임 등의 요소를 제거할 때 사용됩니다.
- 연산에서 NULL은 아무 영향을 미치지 않습니다. NULL과의 연산은 무시되며, 마치 해당 요소가 존재하지 않는 것처럼 처리됩니다.
- 예를 들어:
위 코드에서 sum(unlist(y))의 결과는 7입니다. NULL은 무시되고 나머지 값들의 합이 계산됩니다.y <- list(1, 2, NULL, 4) sum(unlist(y))
정리
- NA: 데이터의 결측값을 의미하며, 연산에서 결측값을 포함하면 결과도 결측값이 됩니다.
- NULL: 객체가 존재하지 않음을 의미하며, 연산에서 무시됩니다.
이 차이로 인해 NA와 NULL은 각각의 상황에 맞게 적절히 사용해야 합니다. NA는 데이터 분석에서 결측값 처리를 위해 자주 사용되며, NULL은 리스트나 데이터 프레임 등에서 요소를 제거하거나 초기화할 때 주로 사용됩니다.
이렇게 하면 연산이 됩니다.

# NULL과의 산술 연산
num1 <- 10
num2 <- NULL
# NULL 값이 있는 경우 0으로 간주하여 연산
sum_result <- num1 + ifelse(is.null(num2), 0, num2)
print(sum_result)
# ifelse()함수에 의해서 (조건식, 참, 거짓) 으로 구성된
# 내용에 따라, num2에 값이 NULL이기이 참 이라서 숫자 0을
# 반환하여 10 + 0은 10이 되는겁니다.
# NULL을 사용한 리스트 원소 제거
my_list <- list(a = 1, b = 2, c = 3)
# b라는 값을 지워버린다.
my_list$b <- NULL
print(my_list)
키 자체가 사라져 버렸다.
# NULL을 포함한 벡터 생성
# NULL을 포함한 벡터 생성을 하였지만, 벡터 출력시 NULL은
# 무시되고 출력 된다.
# NULL은 빈 공간이다!!!
vec <- c(1, 2, NULL, 4)
print(vec)

NA는 출력한다.!!
# NULL을 사용한 함수 반환 값
# 함수 선언
my_function <- function(x){
if(x < 0){
return(NULL)
}
else if(x == 0){
return("x값은 0")
}
else if(x > 1){
return(paste("x값은 양의 값:", x))
}
else{
return(x)
}
}
# 함수 실행
result1 <- my_function(0)
result2 <- my_function(5)
result3 <- my_function(-3)
result4 <- my_function(0.7)
print(result1)
print(result2)
print(result3)
print(result4)
#====
# 지금까지 많이 사용되는 일반적인 데이터
# 유형들을 살펴보았습니다.
# 다음 시간부터 여러 건의 데이터를 묶어서 변수에 할당
# 하는 방법에 대해서 알아보겠습니다.
'언어 > R' 카테고리의 다른 글
| 빅 데이터 분석 실무 필기 준비 (1) | 2024.07.10 |
|---|---|
| 빅데이터 분석 실무 3일차 (0) | 2024.07.10 |
| 빅데이터 분석 실무 1일 차 (0) | 2024.07.08 |