728x90
728x90

SVM이 왜 최대 마진 분류기라고 불리는지 ?
좀 더 안전한 마진이 생기도록 변환한 것이다!
빨간색 영역에 대해서는 고려하지 않는다.
cost 함수의 값을 0으로 하여 전체 비용 함수를 다시 표현하면 간단하게 표현할 수 있다.
그럼 정규화 항을 통해서만 학습하나....?
마진이 뭘까? - 오차?
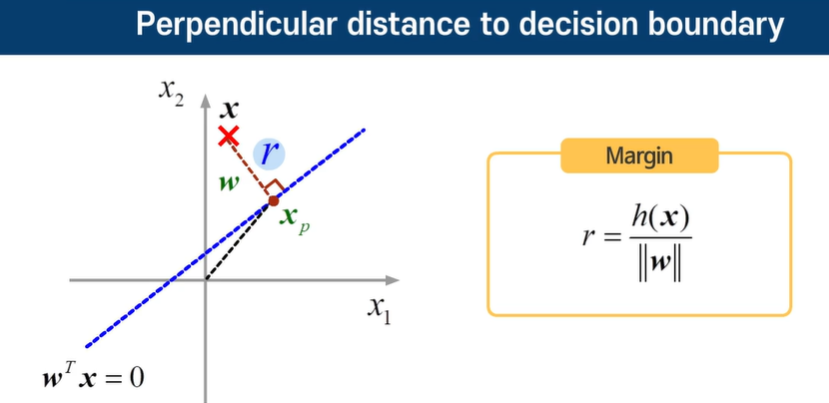

두 데이터 간의 거리이다.


w 값을 극대화 해야 한다.
이진 분류 문제에서 생각해보자



이론적으로 많은 경계를 구할 수 있지만 최대 마진은 하나만 존재한다!
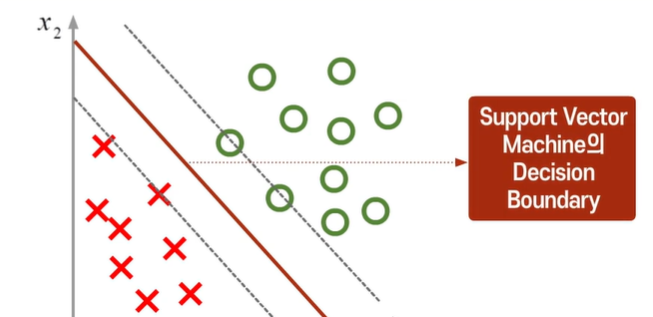
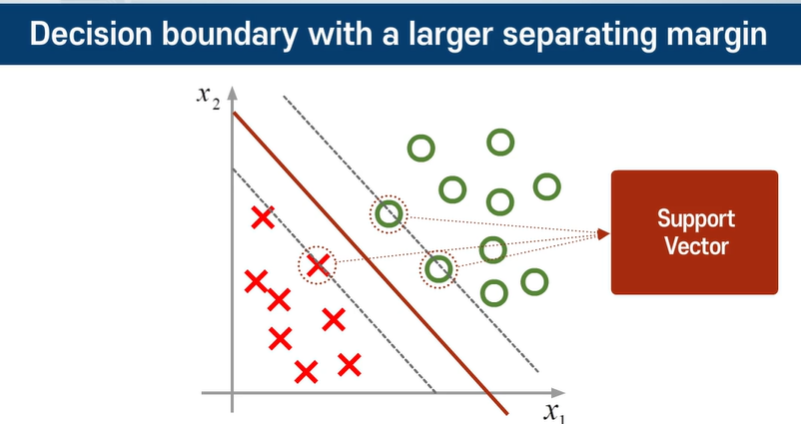
마진 위의 데이터를 서포터 백터라고 한다.

이상치가 존재하는 경우 어떻게 될까?

여기서 매우 특이한 데이터가 추가된다.

C가 매우큰 경우 잘못된 데이터에 매우 민감하다.

C가 매우 큰 경우 잘못된 데이터에 민감하다.

C가 작은 경우 이상치에 민감하지 않다.
C 값이 너무 크지 않으면 이상치가 존재해도 분류 경계선이 민감하게 반응하지 않는다.

728x90
'인공지능 > 공부' 카테고리의 다른 글
| 모두를 위한 머신러닝 11주차 4차시 - 커널의 개념 (0) | 2024.05.18 |
|---|---|
| 모두를 위한 머신러닝 11주차 3차시 - 최대 마진 분류의 수학적 개념 (0) | 2024.05.18 |
| 모두를 위한 머신러닝 11주차 1차시 - SVM의 최적화 목적 함수 (0) | 2024.05.17 |
| 인공지능과 빅데이터 15주차 - 딥러닝, 정형데이터 다중 분류 (0) | 2024.05.14 |
| 인공지능과 빅데이터 14주차 - 다층 퍼셉트론, 이진 분류 (0) | 2024.05.14 |