728x90
728x90
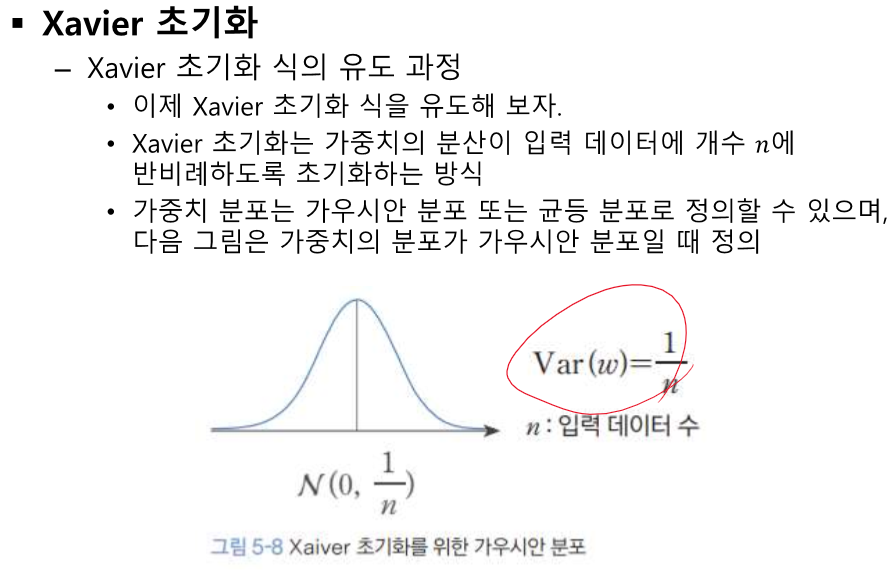
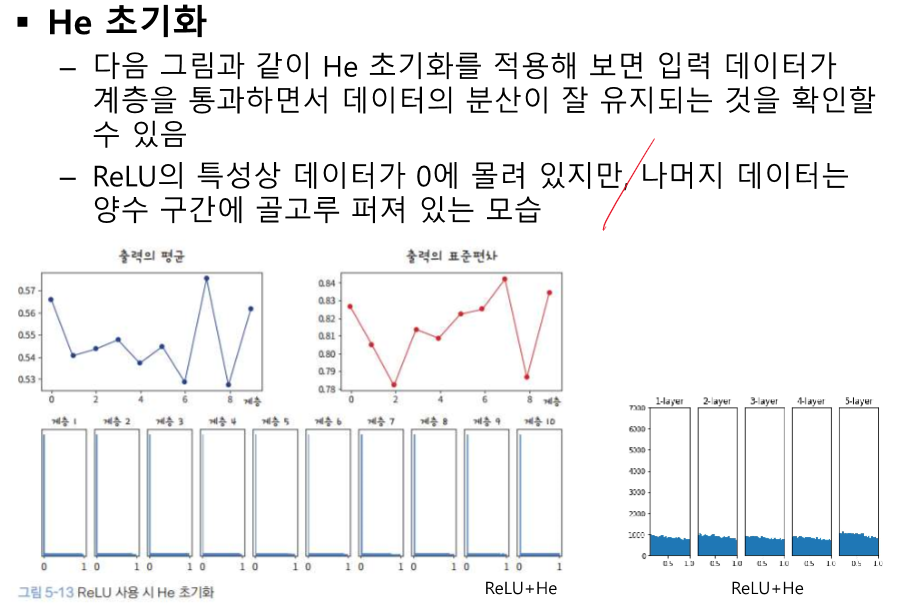
초기 값이 얼마인지에 따라 결과가 천차 만별이다.
편향성을 주게 된다.
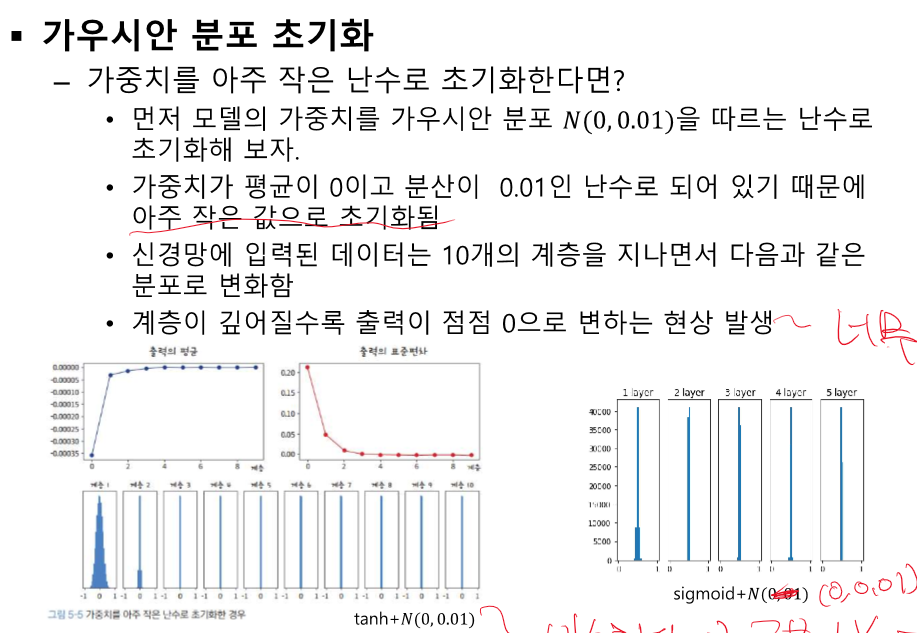
너무 작은 값으로 계속 곱하면 0에 모이게 된다.
비슷하다 -> 구분이 안간다 -> 예측에 활용될 수 없다.
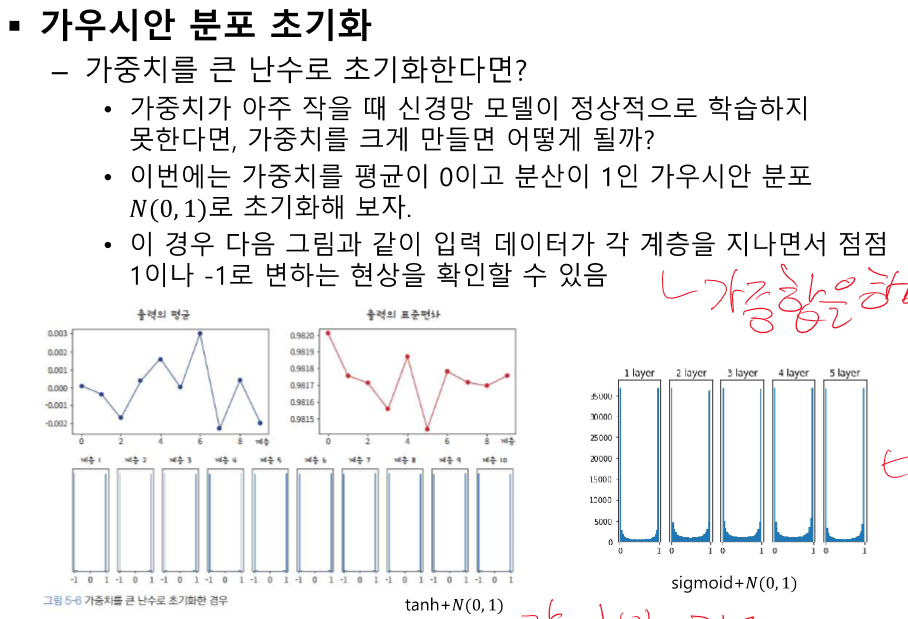
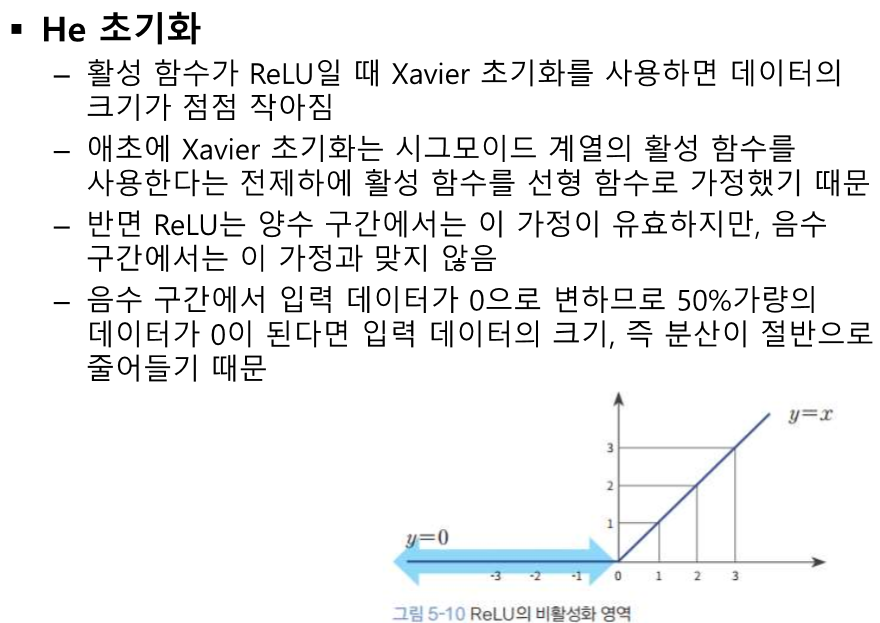
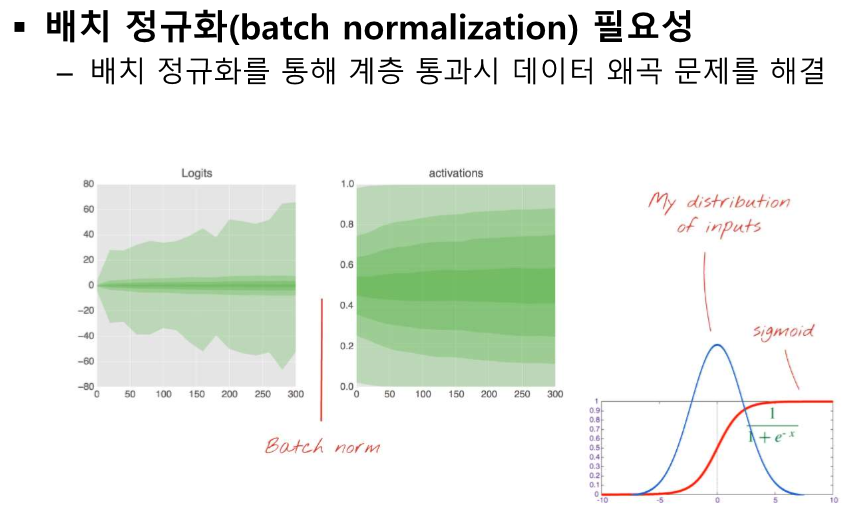
가중합을 하면서 수가 엄청 커진다.
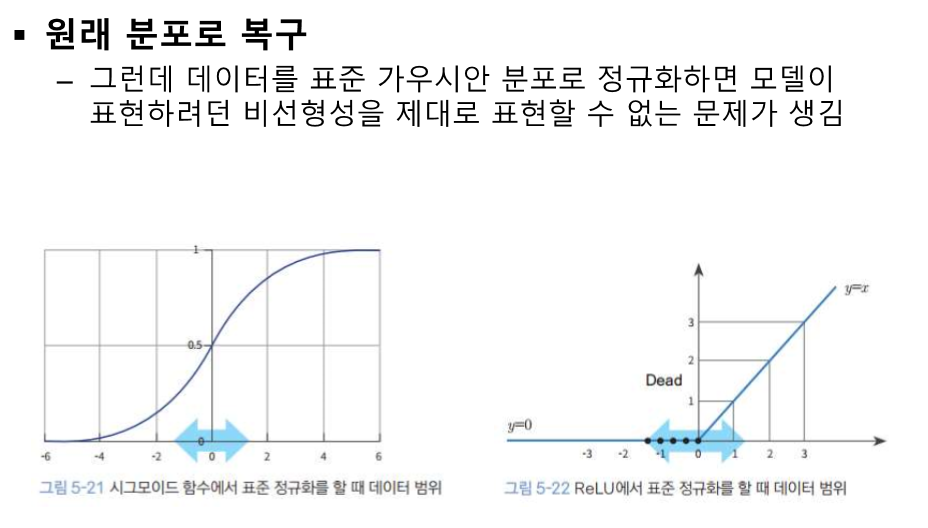
이것도 중앙으로 모여야 하는데 양 끝으로 값이 벌어진다.


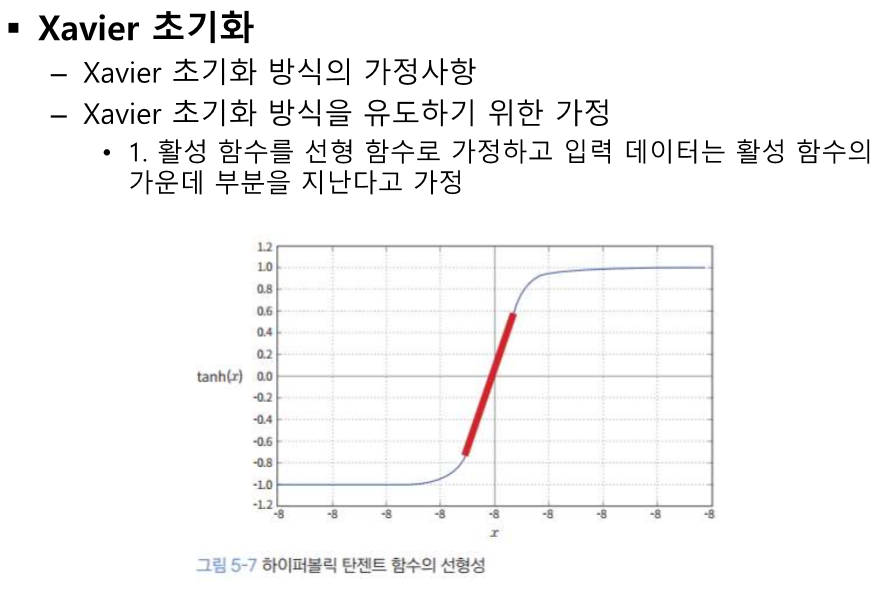

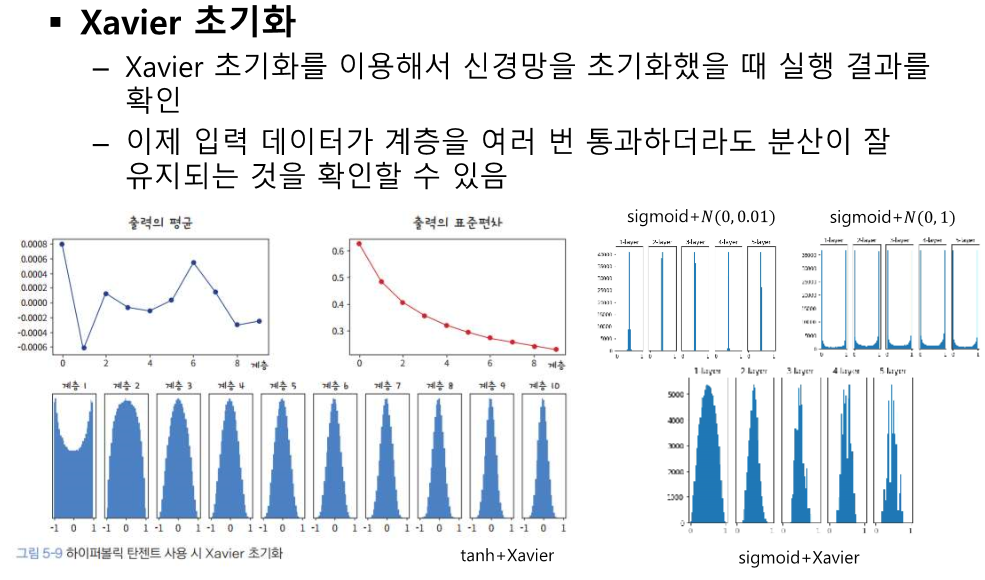
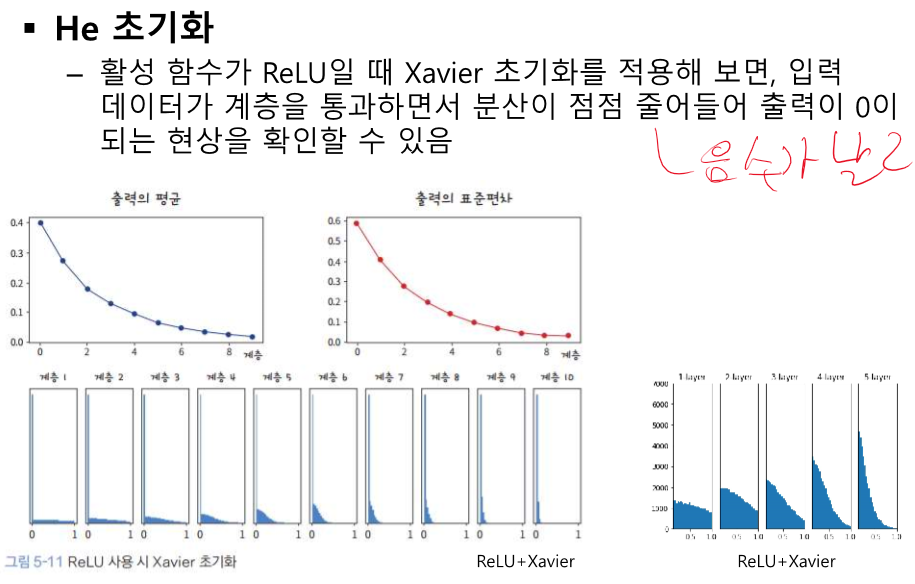
계층을 통과할 때 마다 음수가 날라간다.


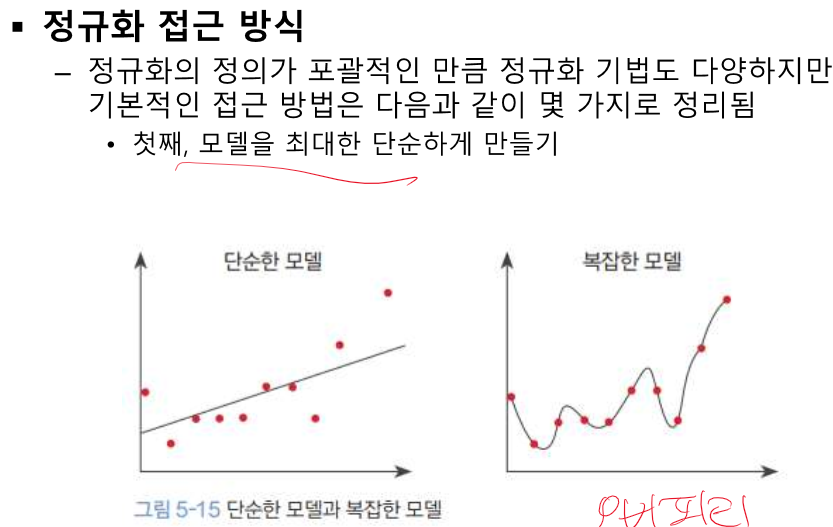
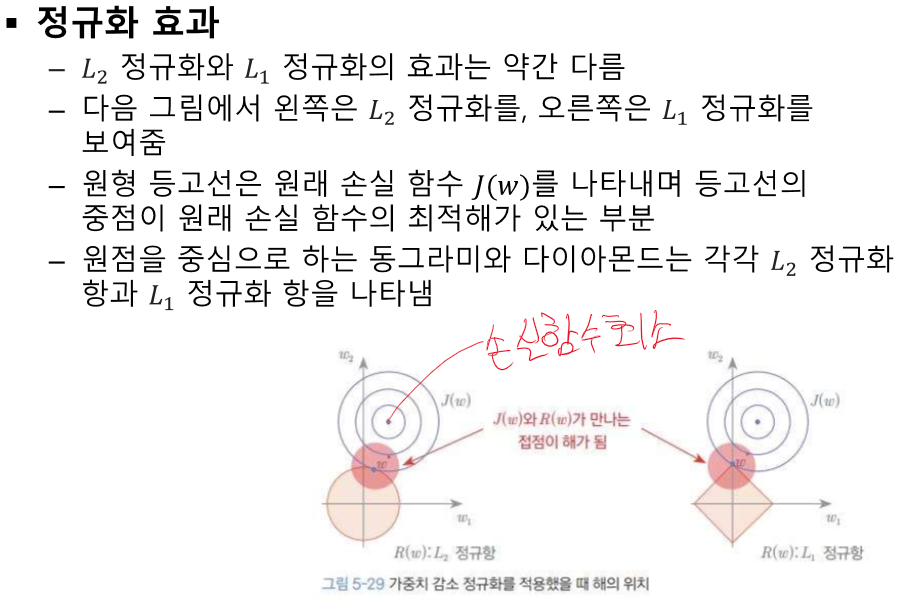
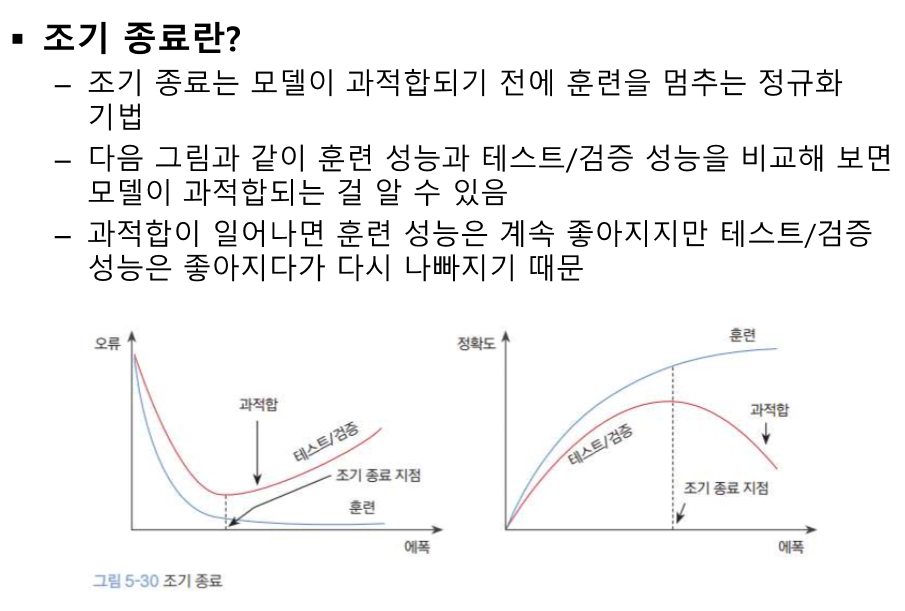
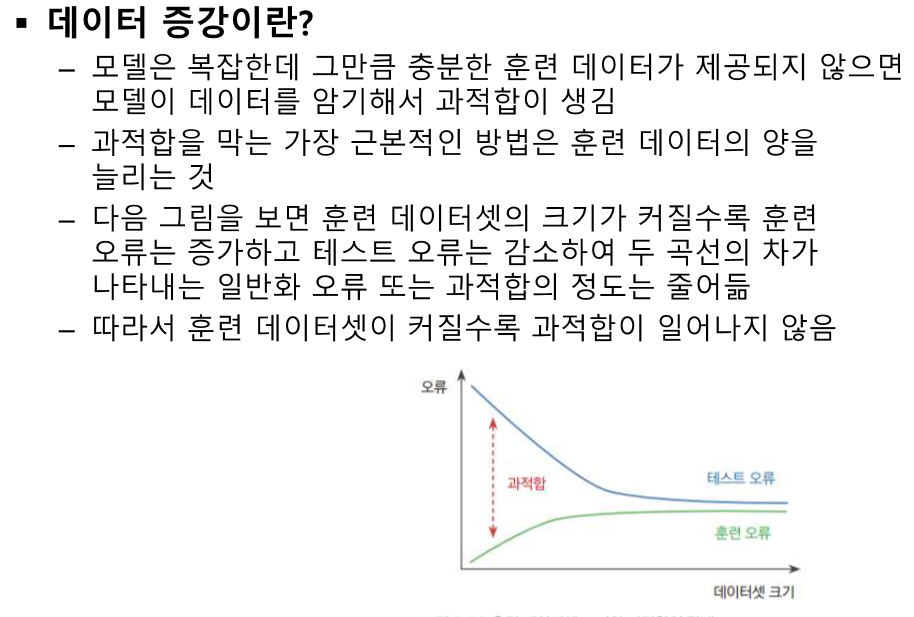
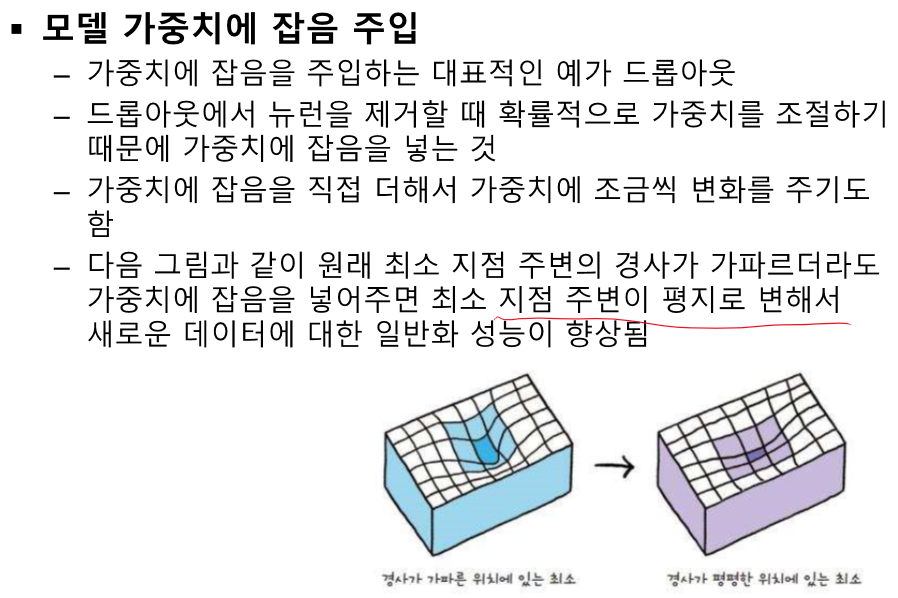
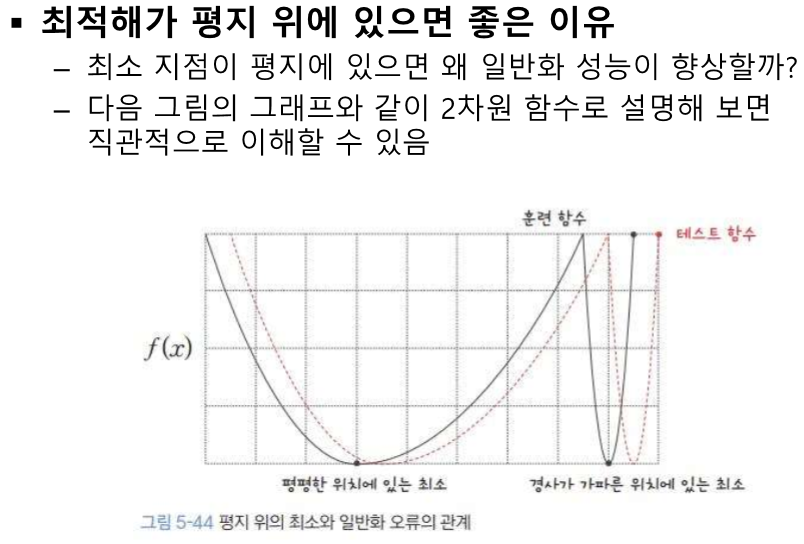
overfitting == 일반화 오류가 크다.













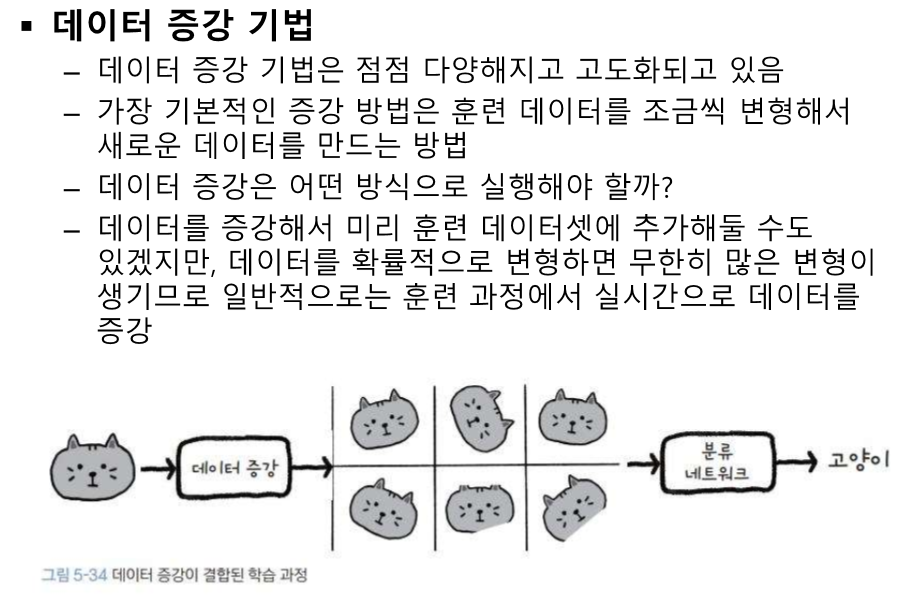

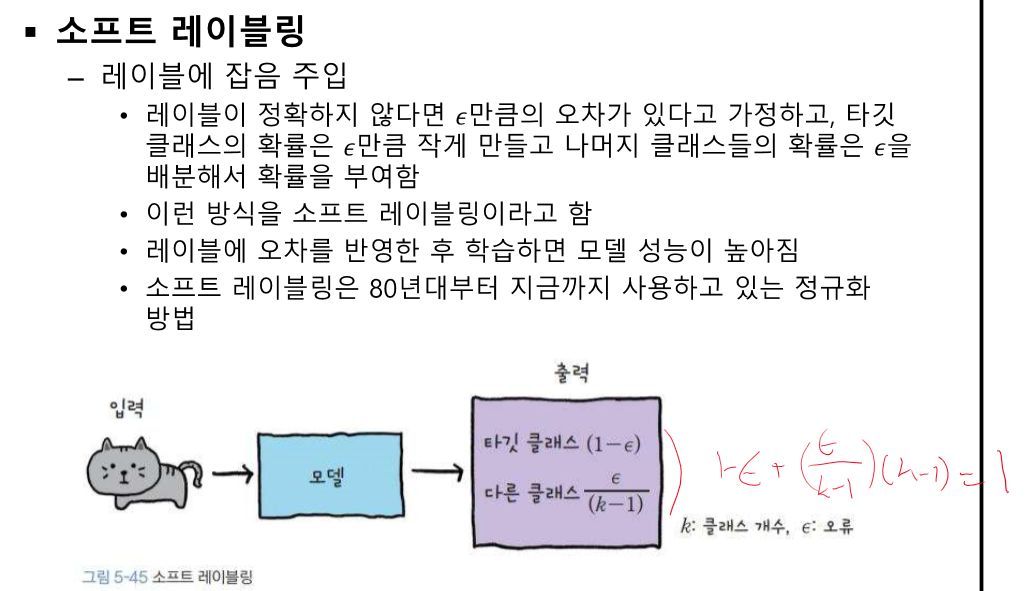
오리지널의 라벨을 가지고 가는데 6이 너무 회전하면 헷갈리니까 한계를 정해야 한다.


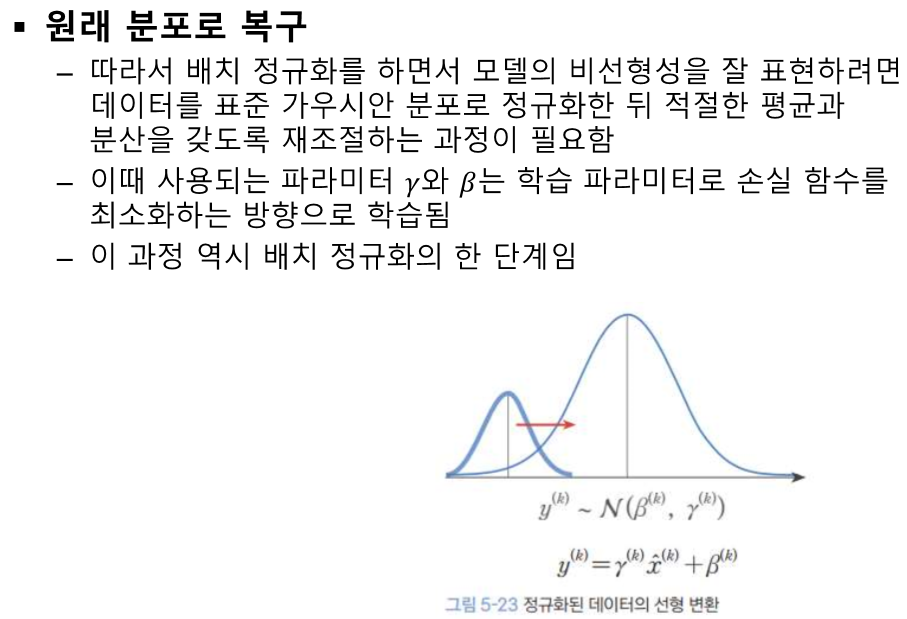
독립 -> 편향제거
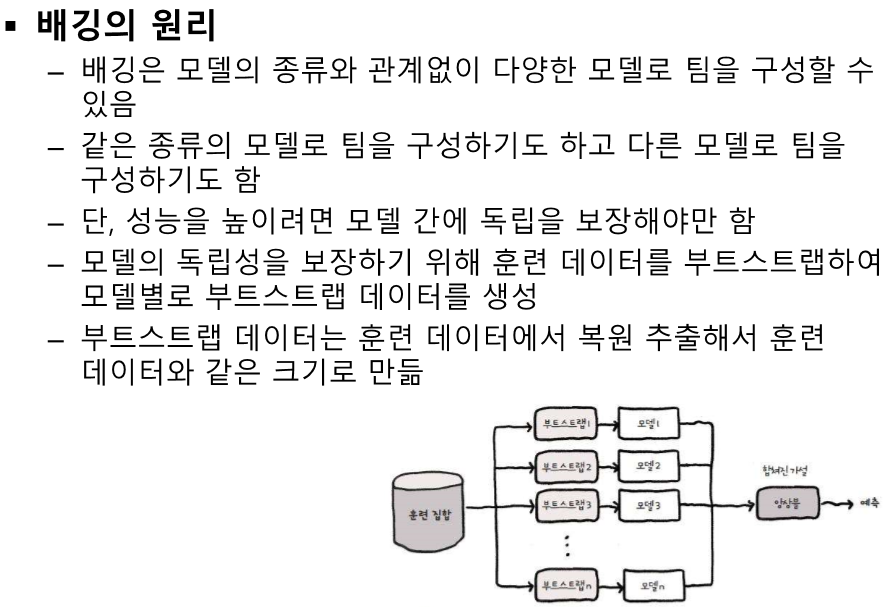
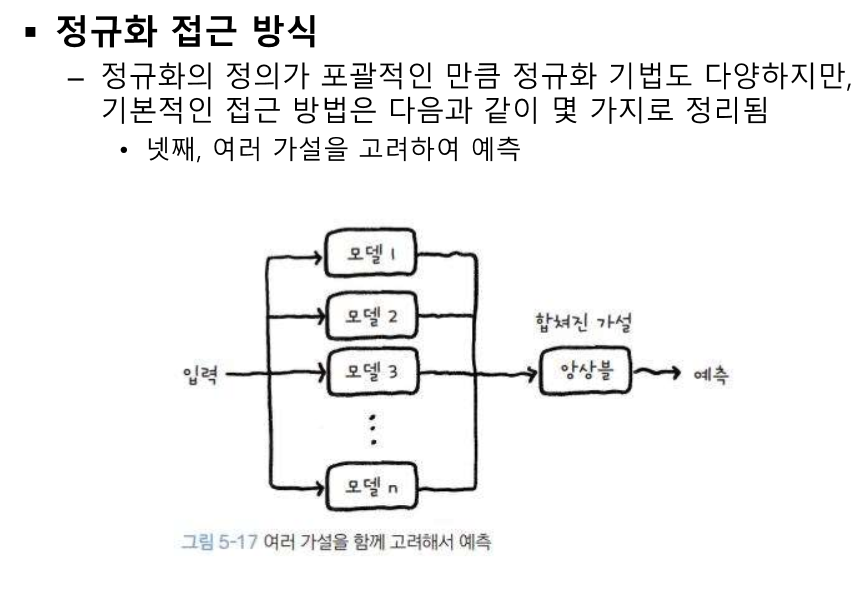
다 다른 모델을 넣어도 되고, 모양이 같은 모델을 넣어도 된다.
같은 데이터 -> 입력 데이터를 독립적으로





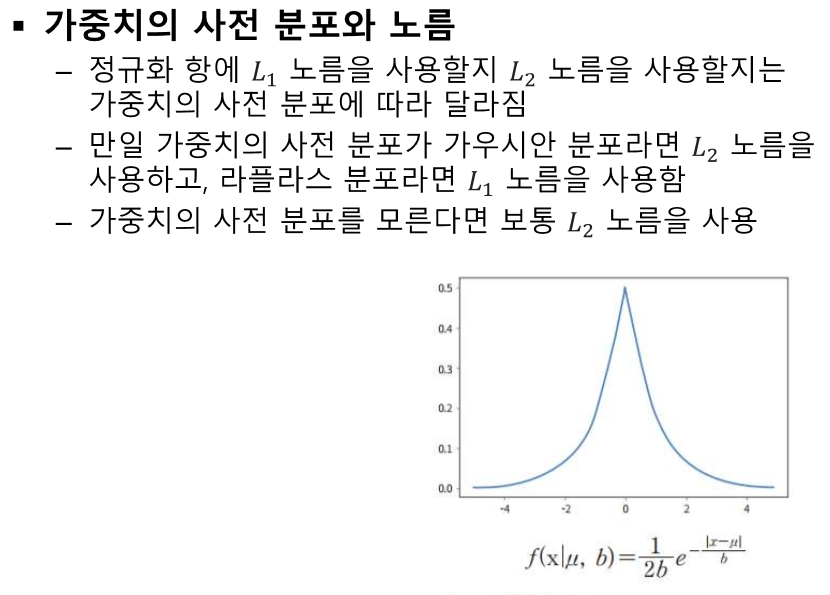
독립성이 중요하다
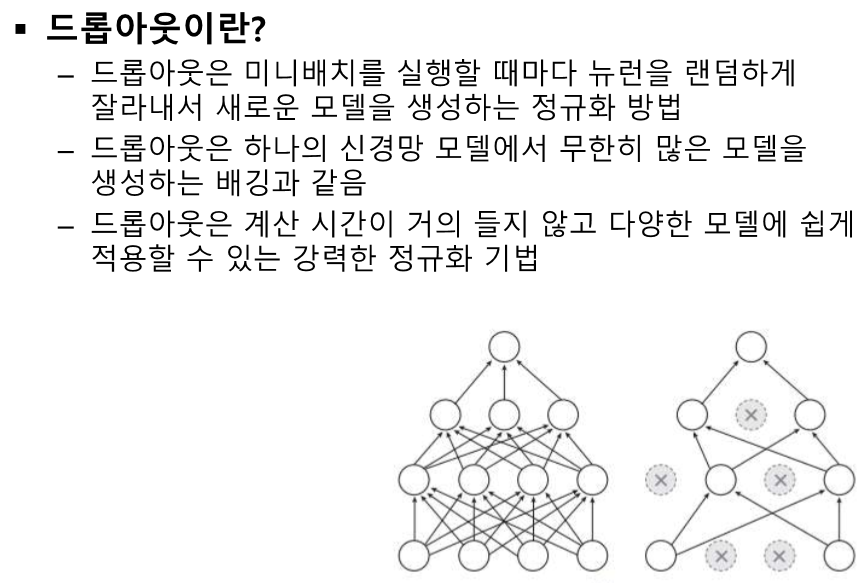


드롭아웃은 통상적으로 20퍼 사용한다.
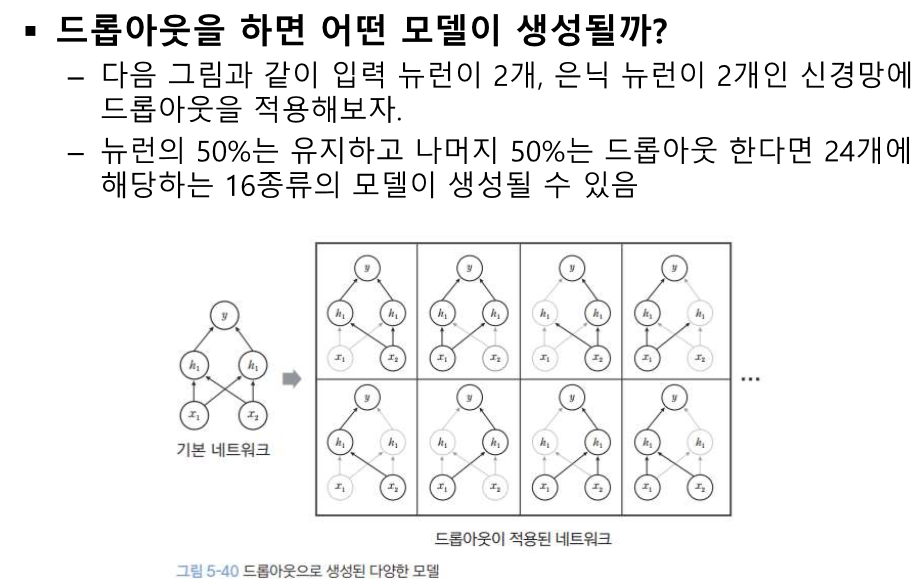





네트워크 초반 - 일반화를 위해
출력단 - 소프트 레이블링


728x90
'인공지능 > 공부' 카테고리의 다른 글
| Back propagation 손으로 하나하나 적어보기 (0) | 2024.04.17 |
|---|---|
| 딥러닝 개론 6강 - 합성곱 신경망 CNN 1 (0) | 2024.04.16 |
| 딥러닝 개론 4강 - 최적화 (0) | 2024.04.16 |
| 딥러닝 개론 3강 - 신경망(딥러닝, 머신러닝) 학습 (2) | 2024.04.16 |
| 딥러닝 개론 2강 - 순방향 신경망 forword propagation (0) | 2024.04.16 |