# N-gram Language Modeling
작은 샘플들을 활용해 N-gram language modeling을 구현해보고, 구현한 N-gram language model로 자동 완성 기능을 이해해보자data
corpus = ["오늘 날씨 어때",
"오늘 날씨 어때",
"오늘 날씨 어때",
"오늘 축구 경기",
"오늘 경기 결과",
"오늘 경기 결과",
"내일 날씨",
"내일 축구 경기",
"내일 축구 경기",
"축구 일정",
]문장의 빈도를 통한 확률 제대로 확인!
# tokenization
vocabs = set()
for sample in corpus:
for token in sample.split():
vocabs.add(token)vocabs = list(vocabs)
vocabs출력
idx_to_token = vocabs
token_to_idx = {token: idx for idx, token in enumerate(idx_to_token)}
token_to_idx{'날씨': 0, '축구': 1, '결과': 2, '경기': 3, '일정': 4, '내일': 5, '어때': 6, '오늘': 7}
토큰화!
# Bi-gram language modeling
# bi-gram language modeling은 P(next_token|previsous_token)을 사용하는 모델
# 우리는 P(previous token, next_token)의 joint probability distribution을 알 수 있으면
# 위의 P(next_token|previsous_token)를 계산하기 쉬움
# 그럼 먼저 P(previous token, next_token)는 어떻게 구할까?
# 먼저 카운팅! prvious_token -> next_token에 대한 테이블을 만들어서 카운팅을 수행한다.이전 토큰이 주어졌을 때 다음 토큰을 구하기!
카운팅 수행하기
prev_token_to_next_token_cnt_table = {}
total_cnt = 0
for sample in corpus:
tokens = sample.split()
for prev_token, next_token in zip(tokens[:-1], tokens[1:]):
if prev_token not in prev_token_to_next_token_cnt_table:
prev_token_to_next_token_cnt_table[prev_token] = {}
if next_token not in prev_token_to_next_token_cnt_table[prev_token]:
prev_token_to_next_token_cnt_table[prev_token][next_token] = 0
prev_token_to_next_token_cnt_table[prev_token][next_token] += 1
total_cnt += 1
prev_token_to_next_token_cnt_table{'오늘': {'날씨': 3, '축구': 1, '경기': 2},
'날씨': {'어때': 3},
'축구': {'경기': 3, '일정': 1},
'경기': {'결과': 2},
'내일': {'날씨': 1, '축구': 2}}
카운트 테이블!
오늘 -> 날씨 는 카운트가 3번
오늘 -> 축구 는 카운트 1번 이렇게 카운팅 된다.
이전에 나온 단어를 통해 다음 단어를 카운팅 한다.
import pandas as pd
prev_token_to_next_token_table_df = pd.DataFrame(prev_token_to_next_token_cnt_table).transpose()
prev_token_to_next_token_table_df.fillna(0,inplace=True)
# 맨 왼쪽 컬럼이 prev_token, 첫번째 열이 next_token
prev_token_to_next_token_table_df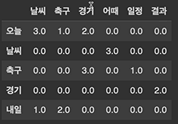
세로축이 이전 토큰, 가로축이 다음 토큰
data중에 0인 것들이 엄청 많다. spase matrix
# count(prev token=날씨, next_token=어때)
prev_token_to_next_token_table_df.loc['날씨', '어때']3
## P(prev_token, next_token) joint prob distribution!
prev_token_to_next_token_join_prob_table_df = prev_token_to_next_token_table_df / total_cnt
# 나누는 것만으로 구할 수 있다.
sum(prev_token_to_next_token_join_prob_table_df.sum()) # 1이 나온다.
prev_token_to_next_token_join_prob_table_df
확률 구하기!
## P(next_token|prev_token) Conditional prob distribution!
marginal_prob = prev_token_to_next_token_join_prob_table_df.sum(axis=1)
marginal_prob # marginal probabilty -> P(prev_token)오늘 0.333333
날씨 0.166667
축구 0.222222
경기 0.111111
내일 0.166667
dtype: float64
# P(next_token|prev_token) = P(prev_token, next_token) / P(prev_token)prev_token_to_next_token_cond_prob_table_df = prev_token_to_next_token_join_prob_table_df.copy()
for row_name, row in prev_token_to_next_token_join_prob_table_df.iterrows():
for col_name, val in row.iteritems():
prev_token_to_next_token_cond_prob_table_df.loc[row_name, col_name] /= marginal_prob[row_name]
prev_token_to_next_token_cond_prob_table_df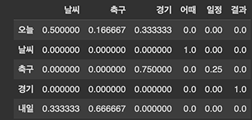
# P(next_token=날씨|prev_token=오늘)
prev_token_to_next_token_cond_prob_table_df.loc["오늘", "날씨"]0.5
# P(next_token=경기|prev_token=결과)
prev_token_to_next_token_cond_prob_table_df.loc["경기", "결과"]1
## Bi-gram을 이용한 Naive한 자동 완성 기능
x = "오늘" # 오늘이 주어졌을 때 다음 토큰들의 확률!
# split input
input_tokens = x.split()
if input_tokens:
last_token = input_tokens[-1]
# lookup cond prob distribution
prev_token_to_next_token_cond_prob_table_df.loc[last_token]날씨 0.500000
축구 0.166667
경기 0.333333
어때 0.000000
일정 0.000000
결과 0.000000
Name: 오늘, dtype: float64
오늘 경기라고 입력하더라도 '경기'에 대해서만 확인한다!
이전 토큰 하나만 본다.
# get top candidates
top_k = 2
next_token_candidates = prev_token_to_next_token_cond_prob_table_df.loc[last_token].sort_values(ascending=False)[:top_k]
next_token_candidates = next_token_candidates.keys().tolist()
next_token_candidates['날씨', '경기']
# 이 찾아진 next_token_candidates를 이용해 다시 그 다음에 나올 token들을 찾을 수도 있음
def suggest(query, depth=2, top_k=2):
# split input
input_tokens = query.split()
if input_tokens: # 인풋이 존재하면
last_token = input_tokens[-1] # 가장 마지막 토큰만을 사용한다.
else:
last_token = marginal_prob.sort_values(ascending=False).index[0] # 비어있다면 아무 토큰도 없을 때로 예측
suggested_list = [] # 제안하는 토큰들의 리스트
def dfs(last_token, prev_token_list, depth):
# terminal
if depth <= 0:
return
# recursion
next_token_candidates = prev_token_to_next_token_cond_prob_table_df.loc[last_token].sort_values(ascending=False)# 라스트 토큰이 주어졌을 때 가장 높은 확률을 sort
next_token_candidates = next_token_candidates[next_token_candidates > 0] # 확률이 0 이상인 것만
last_token_list = next_token_candidates.keys().tolist()[:top_k]# 높은 확률 몇개만 가져오기
for last_token in last_token_list:
new_suggest = prev_token_list + [last_token]
suggested_list.append(new_suggest)
if last_token in prev_token_to_next_token_cond_prob_table_df.index:
dfs(last_token, prev_token_list=new_suggest, depth=depth-1) # 문장을 좀 더 길게 만들어 준다.
dfs(last_token, [last_token], depth)
# concate tokens
suggested_list = [ " ".join(tokens) for tokens in suggested_list]
return suggested_list
suggest("축구", depth=2)['축구 경기', '축구 경기 결과', '축구 일정']
suggest("날씨", depth=2)['날씨 어때']
suggest("경기", depth=2)['경기 결과']
suggest("", depth=2)['오늘 날씨', '오늘 날씨 어때', '오늘 경기', '오늘 경기 결과']
가장 높은 확률을 가져온다!
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 살펴보기 - 개요 (0) | 2024.03.02 |
|---|---|
| 자연어 처리 python 실습 - Neural Language model 구현 (3) | 2024.03.01 |
| 자연어 처리 python - 최신 Language model들과 활용법 (0) | 2024.03.01 |
| 자연어 처리 python - skip thought vector (0) | 2024.03.01 |
| 자연어 처리 - Neural language modeling 2 (0) | 2024.02.21 |