많이 봐왔던 타이타닉 데이터로 사용한다.
데이터의 70퍼센트가 비어있다면 탈락시키는 방법이다.

80프로는 채워져있고, 비어있는 값은 중앙 값으로 채워줄 수 있다.

대다수의 값으로 채우는 방법도 있다!
전처리를 재활용할 수 있도록 함수로 만드는 방법이 효과적이다.

Exploratory Data Analysis

카테고리별로 데이터를 묶는다.

시각화를 보고 데이터를 파악한다.


nun을 전부 28을 넣었기 때문에 28이 엄청 많아졌다.


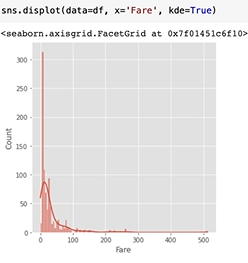


다양하게 데이터들끼리 묶어서 확인해 볼 수 있다.
Feature Engineering

sex_to_id에선 male = 0, female =1로 가져서 위와 같은 과정을 거치면 010101로 바꿀 수 있게 된다.

함수를 만들어서 관리한다!

실행하면 지금은 성별에 대한 정보만 남는다.

여긴 3개 이상이므로 원 핫 인코딩이 필요하다.
0 : S, 1 : C, 2 : Q로 되어있다.



근데 이렇게 되면 독립이 아니게 되는데 하나 지워줘야 하는거 아닌가...?



이거 하나로 5단위로 끊어서 묶게 된다.


최종 정리 본이다.
Normalization
min-max



global을 안써도 사용하긴 하나 명시적으로 표기



정답이랑 나눈 것이다. survived만 따로 있다.

Logisitic regression 모델링 학습

여기선 클레스로 만드네요. 9개의 파라미터(feature도 9개다.)를 만들어서 곱해주고, 바이어스 하나 더해줘서 전진하는 것 만들었습니다. 그리고 sigmoid도 한번 적용해줍니다.
텐서 구조로 자료도 변환해주면 됩니다.

이렇게 하면 모델 정의는 끝!
COST Function

경사하강법을 진행하면서 학습을 진행한다!
backward 후 step에서 미분, 파라미터 업데이트를 진행하게 된다.
Evaluation

평가!

각각의 feature에 따른 그래프가 점점 바뀐다.
'인공지능 > 자연어 처리' 카테고리의 다른 글
| 자연어 처리 - 비용 함수 이해하기 (2) | 2024.01.09 |
|---|---|
| 자연어 처리 - Linear Regression 선형 회귀, Cost function 비용함수 실습 (1) | 2024.01.09 |
| 자연어 처리 - 머신러닝 기초, 나이브, k알고리즘, 앙상블, (1) | 2024.01.04 |
| 자연어 처리 - 모델 평가 (1) | 2024.01.03 |
| 딥러닝 기초 , rogistic regression, 파라미터, 비용 함수, 학 (1) | 2024.01.03 |