https://petsymposium.org/popets/2025/popets-2025-0126.pdf
워터 마킹 방식은 크게 두 종류임
- Training-based = 모델을 재학습하여 워터마크 삽입 - LLM 규모에서는 비용과 시간이 매우 큼
- Fit-based = 모델 기능을 보존하는 변환으로 워터마킹 - light weight 하지만 제거나 위조 공격에 약함
근데 이 논문 왜 evaluation 데이터 셋 공개를 안하냐
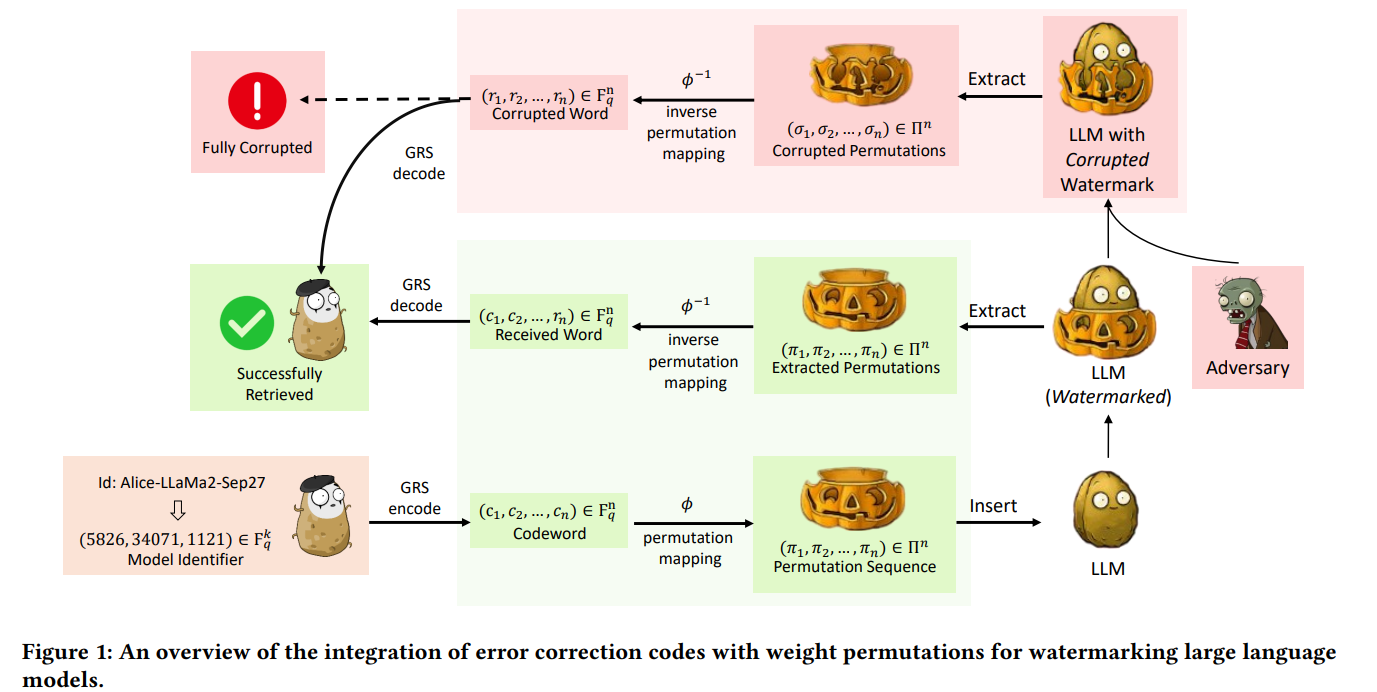
model을 각각의 identifier로 메세지 형태로 변환함
reed-solomon 기반 GRS 코드로 인코딩되어 길이 n의 codeword로 확장
GRS는 n - k개 까지 손상 복구 가능, permutation corruption이 발생해도 복구 가능하고, decoding 실패 여부로 corruption 검출이 가능하다.
(GRS 코드 - Generalized RS 코드로 에러 복구 코드이다. 워터마크가 일부 손상되어도 원래 메세지를 완벽히 복구할 수 있음)
codeword는 inverse-free derangement으로 매핑 - ϕ(c_i)=π_i
derangement - fixed point가 있으면 공격자가 정렬 패턴을 통해 원본 모델 구조를 추론할 수 있고, derangement만 쓰면 모든 위치가 변함
(inverse-free derangement - 모든 permutation이 서로 독립적이고 추출 시 혼동이 없음)
(fix point가 있으면 공격이 쉬워지는 이유 - 고정된 부분이 힌트가 되어 나머지를 맞추기 쉬워짐 => derangement를 사용하면 fix pooint가 없어져 모든 경우의수를 따져야 됨)
생성된 permutation 시퀀스는 모델의 n개 permitation slote에 삽입
(permitation slote - 모델 내부에 순서를 바꿔도 기능이 보존되는 weight 위치)
Permutation slot 예:
- embedding dimension 재정렬
- FFN intermediate dimension 재정렬
- attention head / GQA head 재배열
- hidden dimension block permutation
=> FIT based transformation이므로 모델 기능은 완전히 동일 - LLM은 성능을 잃지 않으면서 내부 weight 순서만 비밀스럽게 재배열됨
(FIT(Functionally Invariant Transformation) based transformation - f(x;θ)=f(x;g(θ)) 즉 모델이 처리하는 finction은 동일하나 내부 파라미터 순서만 변화)
공격을 통해 워터마킹이 제거되거나 위조될 수 있음
원본 모델과 비교하여 permutation을 추출하는데 Linear Assignment 기반 추출 알고리즘을 통해 추출
(Linear Assignment
Inverse mapping을 통해 확신하거나, 정의되지 않은 것으로 매핑
(Inverse mapping 을 통해 메세지를 복구하는데 특정 조건을 만족 시키지 못하면 검출하지 못할 수 있음
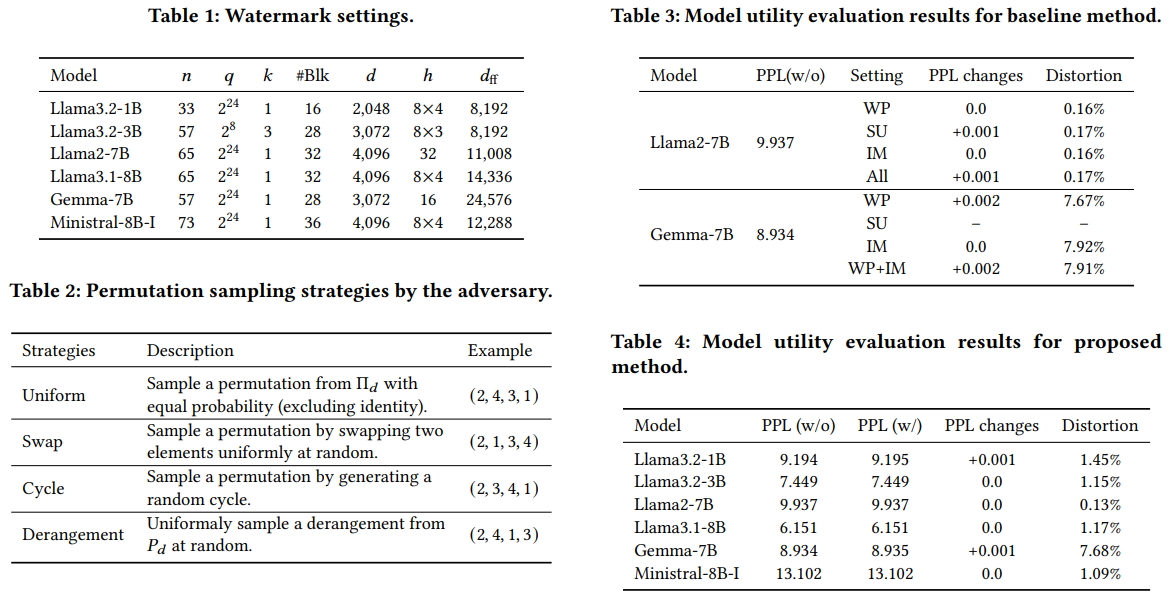
| n | GRS codeword 길이 = 삽입 가능한 permutation 수 |
| q | GRS 코드가 사용하는 유한체 크기 (여기서는 2²⁴, 2²⁸ 등 규모 큰 GF) |
| k | GRS 메시지 길이, 즉 Model ID가 표현되는 심볼 수 |
| #Blk | Permutation slot의 블록 수 (예: multi-head나 FFN block 단위) |
| d | Permutation depth 또는 block 크기 |
| h | attention head 구성(예: 8×4 은 8head × group 4) |
| d₍f₎ | FFN intermediate dimension |
| Observation | Explanation |
| 1. 모델 구조에 따라 permutation slot n이 다름 | head 수·FFN dim 구조에 따라 워터마크 redundancy 변화 |
| 2. 적대적 permutation 공격이 강력함 | swap/cycle/derangement 등 거의 weight alignment 깨뜨림 |
| 3. 기존 FIT 워터마킹은 distortion 커서 취약 | SU/IM 공격에 매우 약함 → extraction 실패 많음 |
| 4. ECC+inverse-free derangement가 robust 보장 | corruption 발생해도 GRS 복구 가능 |
| 5. 성능 손실 거의 없음 | FIT transformation은 function identical, distortion도 낮음 |
| 문제 상황 (Problem) | • 기존 LLM 워터마킹 방식의 한계: — Training-based: 비용·시간 매우 크고 대규모 LLM에 비현실적 — FIT-only(permutation) 기반: lightweight하지만 제거·위조 공격에 취약 — Naive matching 기반 검증은 noise·quantization·finetune에 불안정 • GQA(head grouping), SU/IM obfuscation 등 현대 모델 구조를 고려한 robust한 watermarking이 부족 |
| 핵심 아이디어 | • RS 기반 GRS 코드(Reed–Solomon)로 model ID를 강하게 보호하고 복구 가능하게 함 • Derangement-based permutation mapping (inverse-free)으로 코드 심볼을 permutation 시퀀스로 변환 • 모델 내 FIT(Functionally Invariant Transformation) 가능한 위치(FFN dim, head, embedding dim 등)에 permutation 삽입 → 성능 불변 • 새로운 Linear Assignment 기반 permutation 추출 알고리즘으로 빠르고 noise-robust하게 추출 • 추출된 permutation → inverse mapping → GRS decoding → Model Identifier 복구 |
| 방법론 | 1. Model ID를 유한체 GF(q)의 길이 k 메시지로 변환 2. GRS(n,k) 코드로 메시지를 인코딩하여 에러·에러레이저 복구 가능한 codeword 생성 3. codeword 각 심볼을 inverse-free derangement로 매핑 → permutation sequence 생성 4. permutation을 LLM 내부 FIT-permutation slots에 삽입 (weight 재배열) 5. 공격 후 모델에서 weight 비교를 통해 permutation 추출 (linear assignment) 6. 추출한 permutation을 φ⁻¹으로 symbol로 변환 → corruption 발생 시 erasure 처리 7. GRS decoding으로 원래 ID 복원 또는 corrupted 판단 |
| 사용된 데이터 | • 학습 없음(Training-free) 워터마킹 방법 → 추가 학습 데이터 X • ID는 간단한 문자열(ex: "Alice-LLaMA2-Sep27")을 GF(q) 벡터로 변환하여 사용 |
| 평가 데이터 & 실험 세팅 | • 다양한 크기의 공개 LLM: LLaMA계열, Falcon, Mistral 등 (<13B까지 실험) • 공격 실험: — SU(scale/unscale), IM(invertible QK) obfuscation — Random permutation corruption (swap/cycle/derangement/linear) — Quantization (8→2 bit), pruning (SparseGPT/Wanda), LoRA fine-tuning (~100M tokens) — Forgery 공격 (2M trials) |
| 평가 메트릭 | • Watermark Robustness: — Extraction success rate — ECC 복구(successfully retrieved) vs. fully corrupted 비율 — Forgery success probability • Model Utility 유지 여부: — Perplexity 변화 (ΔPPL) — Token-level cosine similarity / L2 distortion — Task performance (optional sanity check) |
| 실험 결과 | • 유틸리티 영향: PPL 변화 0.0–0.002, 사실상 0 → 성능 완전 보존 • Quantization(8/4/3/2bit), pruning, LoRA-finetune 후에도 워터마크 추출 100% 성공 (ECC로 복구) • SU/IM 기반 obfuscation → 논문에서 제안한 V-weight 기반 복구로 완전 방어 • Forgery 공격 2,000,000 회 중 성공 0% (이론적 확률 q/d! 수준) • Force-corruption이 일정 비율(n−k 초과) 넘으면 GRS가 “fully corrupted”로 탐지 → 위조 방어 기능 작동 • Extraction 속도: 기존 FIT 워터마킹 대비 3–12배 빠름 |
| 기여 | 1. 대규모 LLM에 실용 가능한 Training-free watermarking 최초 제안 2. FIT 기반 permutation watermark에 ECC를 결합한 최초의 Robust framework 3. GQA·multi-head attention 구조를 고려한 체계적인 permutation slot 설계 4. SU/IM 등 기존 FIT obfuscation 공격을 이론적으로 완전 방어 5. Linear assignment로 추출 효율성·정확도 향상 6. Quantization·pruning·LoRA fine-tuning 후에도 100% 복구되는 극단적 robustness 입증 |
| 한계 | • 반드시 white-box 접근이 필요 (weight 접근 필요) • 모델이 지나치게 파괴되면 ECC 복구 불가능 (논문 기준 n−k 초과 corruption) • Permutation slot 수(n) 확장이 GQA/Model 구조에 따라 제약됨 • Very-large models(70B+)에서 추출 시간이 더 증가할 수 있음 • Embedding/attention 구조 변화가 큰 새로운 모델에서는 FIT-slot 수동 검증 필요 |
아래는 논문 전체 내용을 기반으로 한 전문적·체계적 요약입니다.
(파일: Robust and Efficient Watermarking of Large Language Models Using Error Correction Codes)
📌 논문 요약: Robust and Efficient Watermarking of Large Language Models Using Error Correction Codes
이 논문은 LLM 지적재산권 보호(IP Protection) 를 위해,
Error Correction Codes(ECC) 와 Function Invariant Transformation(FIT) 중 weight permutation 을 결합해,
훈련 없이(Training-free), 화이트박스 기반, 고성능·고효율의 워터마킹 방식을 제안한다.
핵심 목표는 다음 두 가지다:
- 워터마크 제거·위조 공격을 이론적으로 방어할 수 있는 워터마킹
- LLM 성능 저하 없이 효율적으로 삽입·추출 가능한 워터마킹
1. 🧩 문제 상황(Problem Statement)
기존 LLM 워터마킹 방식은 크게 두 종류다:
방식 특징 한계| Training-based | 모델을 재학습하여 워터마크 삽입 | LLM 규모에서는 비용·시간이 매우 큼 |
| FIT-based (functional invariants) | 모델 기능을 보존하는 변환으로 워터마킹 | lightweight하지만 제거·위조 공격에 약함 |
기존 FIT 기반 워터마크의 치명적 문제
- 공격자가 또 다른 랜덤 permutation을 적용하면 워터마크는 쉽게 손실됨
- Nearest-neighbor matching 기반 검증 → 오검출, 위조 용이
- GQA 구조의 head 재배열 등 복잡한 architecture 고려 부족
따라서,
FIT 기반 기법의 경량성 + ECC 기반 오류 복원 능력을 결합한
새로운 워터마킹 체계가 필요하다.
2. ⚙️ 제안 방법(Method): ECC 기반 Weight Permutation 워터마킹
논문의 핵심 기여는 다음 두 가지이다.
2.1 전체 파이프라인
(1) 모델 식별자(model identifier)를 ECC로 인코딩
- 모델 ID 예: "Alice-LLaMA-Sep27"
- 이를 GF(q)의 길이 k 메시지 → 길이 n Reed–Solomon codeword로 변환
- Reed–Solomon은 MDS code → 최대 n−k 개의 손상(erasures) 복구 가능
(2) codeword를 weight permutation 시퀀스로 변환
각 codeword symbol c_i →
derangement (고정점 없는 permutation) 으로 매핑
- 매핑 함수 φ는 injective (symbol → permutation)
- derangement만 사용 → 고정점 기반 공격 방지
- GQA 구조에서도 group과 head-level permutation을 모두 인코딩 가능하게 설계
(3) transformer weight에 permutation을 삽입
LLM의 permutation slot에 따라
다음 위치에 permutation을 삽입:
- Embedding dimension
- Intermediate FFN dimension
- Attention heads (Multi-head 또는 GQA)
- Hidden-dimension permutation (rotary embedding 없는 경우)
삽입 시 모델 기능은 완전히 불변.
(4) 추출(extraction)
새로운 주요 기여 →
선형 할당(Linear Assignment) 기반 permutation 추출 알고리즘
- 기존 brute-force 대비 3~12배 빠름
- noise 있는 현실 weight 변동에서도 robust
- block-permutation(예: multi-head)도 추출 가능
(5) ECC로 복구
추출된 permutation 시퀀스 σ에서:
- φ⁻¹로 symbol로 역변환
- Reed–Solomon decode
- 모델 ID 복원
3. 🔐 공격 및 방어(Threats & Defense)
논문에서 고려한 공격과 방어 전략을 분명히 기술한다.
3.1 FIT 기반 Obfuscation 공격
공격자는 SU/IM 같은 기능보존 변환을 적용해
weight-permutation 추출을 어렵게 만들 수 있음.
🛡 해결책
- SU(scale/unscale): row-normalization으로 제거
- IM(invertible QK transform):
→ value weight(𝑾ᵥ) 은 영향을 받지 않으므로 𝑾ᵥ에서 permutation 추출
이론적으로 증명(Theorem 6.2).
따라서 SU/IM 기반 obfuscation은 완전히 무력화.
3.2 Permutation 기반 Removing & Forgery 공격
공격자는 random permutation을 추가해 워터마크를 깨뜨릴 수 있다.
하지만:
- Reed–Solomon ECC → 최대 n−k corruption 복구 가능
- φ 매핑 설계로 대부분의 corruption은 decoding 중 에러(erasures)로 검출됨
- 공격자가 우연히 다른 identifier로 위조할 확률은
q / d! 이하 (거의 0)
실험: 2,000,000번 forgery 공격 시 성공률 0%.
4. 📊 실험(Experiments)
4.1 모델 유틸리티 영향
- perplexity 변화는 0.0 ~ 0.002 수준 → 사실상 없음
- 대부분 모델에서 token distortion 1% 이하
즉, 성능 손실 무시 가능.
4.2 corruption detection 확률 검사
100M 반복 시뮬레이션에서:
- 공격 전략 중 cycle, derangement가 가장 강했지만
- detection 실패 확률은 여전히 10⁻⁴ 이하
- 이론적 mp = 0.0001 기준을 충족
4.3 모델 수정 공격(quantization / pruning / finetuning)
수정 ECC 전/후 corruption 추출 성공| 8/4/3/2-bit quantization | 0 | 100% |
| SparseGPT / Wanda pruning | 0 | 100% |
| LoRA fine-tuning (100M tokens) | 최대 1 corruption | ECC로 복구됨 |
LLM이 심하게 망가져도 watermark는 복구 가능.
4.4 효율성
- permutation 삽입: 1~16초
- 추출: 6~228초 (모델 1B~13B)
baseline(FIT) 대비:
- 추출 속도 3~12배 빠름
5. 🧭 결론(Conclusion)
이 논문은 훈련 없이 삽입 가능한,
ECC 기반 permutation watermarking을 제안하며,
✔ 공격 방어 능력
- SU/IM obfuscation → 완전 방어
- permutation corruption → ECC로 복구
- forgery → 사실상 불가능
- quantization/pruning/fine-tuning → 문제 없음
✔ 유틸리티 보존
- 성능 저하 거의 없음
- derivation-friendly
✔ 효율성
- LLM 규모에서도 초 단위 삽입, 수십 초 추출
따라서 LLM 배포에서 매우 실용적인
white-box watermarking 솔루션을 제공한다.
📚 한 페이지 표 요약
항목 내용| 문제 | FIT 기반 watermark는 lightweight하지만 제거·위조에 취약 |
| 핵심 아이디어 | (1) Weight permutation 활용 (2) ECC로 ID 보호 (3) linear assignment로 efficient extraction |
| 방법 | 모델 ID → GRS codeword → derangement perm → weight perm 삽입 → 추출 후 ECC 복구 |
| 방어되는 공격 | SU/IM obfuscation, permutation corruption, forgery, model modifications |
| 동작 환경 | white-box access 필요 |
| 성능 영향 | negligible (PPL 변동 0.0–0.002) |
| 효율 | 삽입 수초, 추출 수십초, 기존 FIT 대비 3–12배 빠름 |
| 한계 | white-box 필요, ECC 한계 이상 공격 시 제거 가능 |
| 기여 | FIT 기반 워터마킹의 첫 robust variant, GQA 지원, 이론적 보장 |
아래 설명은 Figure 1의 흐름을 정확히 따라가며,
논문의 전체 방법론을 단계별 파이프라인으로 상세하게 해설한 것이다.
그림 속 오브젝트(potato → pumpkin → zombie) 흐름까지 반영해 완전히 구조화했다.
🧩 Figure 1 기반 방법론 상세 설명
Figure 1은 논문에서 제안한 워터마킹 시스템 전체를 입력 → 삽입 → 공격 → 추출 → 복구의 흐름으로 시각화한 것이다.
핵심은:
모델 ID → ECC 인코딩 → permutation 시퀀스 → 모델 weight permute
→ adversary 공격 → corrupted permutation 추출 → ECC 디코딩 → 원래 ID 복원
이 과정을 단계별로 해석하면 아래와 같다.
1️⃣ Step 1: 모델 ID를 Finite Field 표현으로 변환
그림 좌하단:
Id: Alice-LLaMA2-Sep27 → (5826, 34071, 1121)
즉, k개의 GF(q) 심볼로 구성된 메시지 형태로 변환된다.
이 메시지를 *원본 식별자(original model identifier)*라고 한다.
2️⃣ Step 2: Reed–Solomon Encoding (GRS Encode)
(그림: potato + green box → GRS encode → codeword)
이 메시지는 Reed–Solomon 기반 GRSₙ,ₖ 코드로 인코딩되어
길이 n의 codeword로 확장된다:
[
(c_1, c_2, \ldots, c_n) \in \mathbb{F}_q^n
]
GRS 코드는 다음과 같은 역할을 한다:
- n−k 개까지 erasure(손상) 복구 가능
- permutation corruption이 발생해도 복구 가능
- decoding 실패 여부로 corruption 검출 가능
즉, ECC는 워터마크 손상에 대한 안전장치이다.
3️⃣ Step 3: Permutation Mapping (φ)
(그림: codeword → pumpkin-permutation sequence)
각 codeword symbol c_i는
**inverse-free derangement(고정점 없는 permutation)**으로 매핑된다.
[
\phi(c_i) = \pi_i
]
이때 중요한 점:
✔ 왜 derangement만 쓰는가?
- fixed point가 있으면 공격자가 정렬 패턴을 통해
원본 모델 구조를 추론할 수 있기 때문 - derangement만 사용하면 모든 위치가 바뀌므로 공격 난도 증가
4️⃣ Step 4: Weight Permutation 삽입 (Insert)
(그림: pumpkin becomes “LLM(Watermarked)”)
생성된 permutation sequence:
[
(\pi_1, \pi_2, ..., \pi_n)
]
이 모델의 n개 permutation slot에 삽입된다.
Permutation slot 예:
- embedding dimension 재정렬
- FFN intermediate dimension 재정렬
- attention head / GQA head 재배열
- hidden dimension block permutation
중요: FIT-based transformation이므로 모델 기능은 완전히 동일하다.
즉,
LLM은 성능을 잃지 않으면서 내부 weight 순서만 비밀스럽게 재배열된다.
물론 figure에선 pumpkin 얼굴이 변한 것으로 표현.
5️⃣ Step 5: Adversary에 의한 Corruption
(그림: adversary → corrupted pumpkin LLM)
공격자는 워터마크를 제거하거나 위조하려고 permutation을 랜덤 적용한다:
- Uniform permutation
- Swap-based
- Cycle-based
- Derangement 기반
- SU/IM Transform 기반 obfuscation
- Quantization / pruning / finetuning 등 모델 변형
결과:
[
(\pi_1, ..., \pi_n) \rightarrow (\sigma_1, ..., \sigma_n)
]
이것이 Corrupted permutation이다.
figure에서는 좀비처럼 된 pumpkin으로 표현.
6️⃣ Step 6: Permutation Extraction (Extract)
(그림: corrupted pumpkin → extract → σ sequence)
워터마킹 제공자는
원본 모델과 비교하여 permutation을 추출하는데,
이 논문에서는 기존 brute-force 대신 Linear Assignment 기반 추출 알고리즘을 도입함.
이 알고리즘은:
- column-wise cost = Euclidean distance
- Hungarian/Jonker–Volgenant 알고리즘(O(d³)) 사용
- block permutation도 지원
결과:
[
(\sigma_1, \sigma_2, ..., \sigma_n)
]
그림에서 악화된 pumpkin → corrupted permutation icons
7️⃣ Step 7: Inverse Mapping (φ⁻¹)
(그림: corrupted permutations → corrupted word (r₁,...,rₙ))
각 permutation σᵢ에 대해:
- 정상 derangement + valid rank이면 → symbol 복원
- 그렇지 않으면 → undefined (erasures)
즉,
[
\phi^{-1}(\sigma_i) =
\begin{cases}
r_i & \text{valid mapping} \
↑ & \text{undefined (corruption detected)}
\end{cases}
]
결과:
[
(r_1, r_2, \ldots, r_n)
]
이는 corrupted codeword이다.
즉, corruption이 있는 경우 symbol-level에서 erasure로 치환됨.
8️⃣ Step 8: Reed–Solomon Decoding (GRS Decode)
두 가지 상황이 있다:
🟩 1) Corruption이 n−k 이내 → Successful Retrieval
GRS decoder는 erasure/error 수 ≤ n−k 를 복구할 수 있으므로,
- 원래 codeword (c₁,...,cₙ) 복원
- 그리고
[
\text{ID = GRSdec}(c_1, ..., c_n)
] - 최종적으로
정확히 원래의 Model Identifier 복구
그림의 potato + 초록 체크 표시.
🟥 2) Corruption이 너무 크면 → Fully Corrupted
corruption이 n−k 초과:
- GRS decoder는 실패
- 어떤 모델 ID도 출력할 수 없음
- Forgery도 거의 불가능(확률 q/d! 수준)
그림 상단의 붉은 박스가 이것을 의미한다.
🔚 최종적으로 Figure 1이 나타내는 흐름 요약
단계 설명| 1 | 모델 ID를 GF(q) 메시지로 변환 |
| 2 | GRS 코드로 에러 복원 가능한 codeword 생성 |
| 3 | codeword → derangement permutation 매핑 |
| 4 | permutation을 모델 weight에 삽입 (watermark embedding) |
| 5 | 공격자가 permutation을 손상시킴 |
| 6 | provider는 weight 비교로 permutation 추출 |
| 7 | φ⁻¹로 symbol 복원 (corrupted symbol 검출) |
| 8 | Reed–Solomon 복구: ID 되살리거나 실패 표시 |
📌 이 방법론의 핵심 요점
✔ FIT(Weight Permutation)의 경량성 + ECC(RS code)의 복원 능력을 결합
✔ GQA 고려한 permutation mapping 설계
✔ extraction 효율 극대화 (linear assignment)
✔ 다양한 공격에 대한 이론적·실험적 방어
✔ forgery 불가능 수준의 안정성
필요하면 다음도 추가해줄게:
🔍 Figure 1을 기반으로 한 슬라이드용 설명
🧠 Permutation mapping(φ)의 내부 수학적 구조 더 자세한 해설
📦 역공학 공격자의 관점 설명
📐 ECC 파라미터(n, k, q) 선택 전략 설명
아래 설명은 모두 논문에서 실제로 사용된 개념 그대로,
수학적 정의 → 직관적 의미 → 왜 필요한지 → 공격/방어 측면에서 어떤 역할을 하는지
순서로 정리한 전문적 해설이다.
🟩 1. Reed–Solomon 기반 GRS 코드란? (Generalized Reed–Solomon Code)
1) 기본 개념
Reed–Solomon(RS) 코드는 다음과 같은 성질을 가진 에러/에러레이저 복구 코드이다.
- 정의역: 유한체(Finite Field) 𝐹ᵩ
- 메시지 길이: k
- 코드워드 길이: n
- 복구 가능 손상:
[
n-k \text{ 개까지의 erasure(손실) 복구 가능}
]
또는
[
\left\lfloor \frac{n-k}{2} \right\rfloor \text{ 개의 error(잘못된 값) 복구 가능}
]
2) GRS(Generalized RS) 코드
RS 코드의 일반화 버전으로:
[
c_i = v_i \cdot f(\alpha_i)
]
- f: degree < k 인 다항식
- αᵢ: 서로 다른 evaluation points
- vᵢ: non-zero scaling factors
GRS의 장점:
- MDS(Maximum Distance Separable) 코드
- 즉, 이론적으로 가능한 최대 복구 능력
- n−k 개까지 erasure 복구 가능
👉 워터마크가 일부 손상되어도 원래 메시지를 완벽히 복구할 수 있음
그래서 논문이 RS 기반 GRS 코드를 사용한 것이다.
🟩 2. Inverse-Free Derangement란?
1) Derangement 정의
Permutation π ∈ Sₙ이 있을 때,
[
\pi(i) \neq i \quad \forall i
]
즉, fixed point가 없는 permutation을 뜻함.
2) Inverse-free란?
두 번째 조건:
[
\pi^{-1} \notin \mathcal{D}
]
즉,
- π도 derangement이고
- π의 역함수 π⁻¹도 derangement인 경우에만 선택한다.
왜?
- inverse가 다시 fixed point를 만들거나
- 비정상적인 구조를 만들 수 있어
- 조작된 패턴 식별 시 혼란을 초래하기 때문.
그래서 모든 permutation이 서로 독립적이고, 추출 시 혼동이 없다.
🟩 3. 왜 fixed point가 있으면 공격이 쉬워지는가?
공격자가 weight permutation을 추측하려고 할 때:
✔ fixed point(i → i)가 있으면 패턴이 드러남
예시:
퍼뮤테이션이
[
[3,1,2,4,5,7,6]
]
이라면
4→4, 5→5 라는 부분은 **"그대로이다"**라는 힌트를 준다.
그러면 공격자는:
- 원본 구조를 ‘정렬된 형태’라고 가정
- 동일 위치 고정된 부분을 “정답 anchor”로 판단
- 나머지 구간에서 block-swap을 시도하여 복원
즉, fixed point는 공격 난도를 매우 낮춘다.
✔ derangement만 사용하면?
모든 위치가 변경되어:
- "어디가 원래 자리인지"에 대한 정보가 사라짐
- 공격자가 permutation을 재구성하기 어렵다
- 합법적인 inverse mapping이 아닌 경우, ECC에서 erasure로 처리
따라서 워터마크의 보안성이 크게 증가한다.
🟩 4. Permutation Slot이란? 그리고 성능에 영향은 없나?
(1) Permutation slot의 정의
모델 내부에서 순서를 바꿔도 기능이 보존되는 weight 위치.
예:
- FFN의 hidden dimension (W₁, W₂)
- Attention head dimension
- Embedding dimension
- GQA head 그룹 단위 BLOK(Reordering)
Transformer 구조에는 다음 특성이 있다.
✔ 특정 레이어는 permutation-invariant
예를 들어:
FFN:
[
xW_1 → \text{ReLU} → (.)W_2
]
여기서 W₁과 W₂는 row/column permutation이 동시에 일어나면 기능이 동일.
Multi-head attention:
Attention head는 독립적 구조
→ head 순서를 바꿔도 결과 동일
(2) 그럼 성능에 영향이 없다는 게 맞나?
완전히 없다고 증명된 FIT(Functionally-Invariant Transformation)
FIT는 다음 조건을 만족하는 변환이다:
[
f(x; \theta) = f(x; g(\theta))
]
여기서 g는 permutation transformation.
즉, 가중치 순서만 바뀌고 함수 형태는 보존된다.
논문 실험 결과도 이를 확인:
- Perplexity 변화:
0.0 ~ 0.002 - Token간 L2 차이: 1% 이내
즉, 성능은 사실상 0 영향.
🟩 5. FIT 기반 Transformation이란?
FIT = Functionally Invariant Transformation
조건:
[
f(x; \theta) = f(x; g(\theta))
]
즉,
- 모델이 처리하는 function은 동일
- 내부 파라미터는 순서만 변화
- embedding/FFN/attention 구조는 permutation-invariant이므로 가능
- gradient 흐름이나 forward pass에 영향 없음
LLM 구조에서 FIT에 해당하는 주요 변환이 바로:
- head permutation
- FFN intermediate dimension permutation
- embedding dimension permutation
등이다.
따라서 파라미터 일부를 재정렬해도 모델 기능은 완전히 동일하다.
🟩 6. Linear Assignment 기반 추출 알고리즘이란?
과제:
Watermarked 모델에서 permutation π를 찾으려면:
- Weight 행렬 W를 보고
- W가 어떻게 permuted 되었는지
- 가장 근접한 permutation matrix를 찾아야 함
✔ 이 문제는 “Assignment Problem(할당 문제)”
비용 행렬 C:
[
C_{i,j} = |W_{:,i} - W^0_{:,j}|_2
]
- i: permuted weight의 column
- j: 원본 weight의 column
가장 작은 비용을 갖는 one-to-one mapping을 오차 없이 찾아야 한다.
✔ Hungarian / Jonker–Volgenant 알고리즘 적용
이것은 O(n³) 시간의 고전적인 최적 알고리즘.
장점:
- brute-force (n! 탐색) 불가능한 문제를 최적해로 해결
- noise나 quantization이 있어도 안정적으로 detection
- block permutation에도 응용 가능
따라서 실제 대규모 LLM에서도 초 단위로 추출 가능하다.
🟩 7. Inverse Mapping (φ⁻¹)란?
원래:
[
\phi(c_i) = \pi_i
]
즉, symbol → derangement mapping.
추출 시 해야 하는 것:
[
\phi^{-1}(\sigma_i)
]
근데 문제:
- σᵢ가 valid derangement mappings 중 하나와 일치할 수도
- 공격으로 변형되었으면 전혀 매칭되지 않음
✔ 매칭되지 않으면
[
\phi^{-1}(\sigma_i) = \text{undefined} \Rightarrow \text{erasure}
]
이 erasure 정보를 그대로 Reed–Solomon decode에 전달함.
ECC는:
- n−k 이내 erasure는 복구
- n−k 초과면 fully corrupted로 판단
따라서 inverse mapping은:
permutation → symbol 복구 과정 + corruption 여부 검출 역할을 동시에 수행한다.
🟩 최종 정리
개념 핵심 내용 왜 필요한가| GRS Code | RS 기반 MDS 코드 | permutation 손실 복구 |
| Derangement | fixed point 없는 permutation | 공격자 anchor 제거 |
| Inverse-free | 역함수도 derangement | mapping 혼동 방지 |
| Permutation Slot | 기능 보존 위치 | 성능 영향 0 |
| FIT Transformation | f(x;θ)=f(x;g(θ)) | watermark 삽입해도 모델 유지 |
| Linear Assignment | 최적 permutation 추출 | 빠르고 robust |
| Inverse φ | permutation → symbol | corruption 검출 + 복구 |
아주 핵심적인 질문이다.
“기능이 완전히 동일한(FIT) 변환이라면서,
어떻게 워터마크를 검출할 수 있지?
그럼 애초에 왜 이런 변환을 하는데?”
이 질문을 정확히 이해하면 논문의 중심 아이디어를 완전히 이해한 것이다.
아래 설명은 그 핵심을 수학·구조적 관점에서 명확하게 정리한 것이다.
🧩 1. FIT 기반 변환은 “기능이 동일할 뿐 구조는 달라진다”
먼저 이 오해를 정리해야 한다.
✔ FIT(Functionally Invariant Transformation)는
모델 function f(x;θ)는 완전히 동일하게 유지되지만,
파라미터 θ 자체는 재배열(permutation)된다.
즉,
- 출력은 동일
- 내부 weight의 “순서(order)”는 달라짐
- 논문에서는 바로 그 “순서의 차이”가 워터마크
이를 식으로 쓰면:
[
f(x;\theta)= f(x;g(\theta))
]
여기서 g는 permutation 변환.
🧩 2. 그럼 permutation은 모델의 어떤 부분을 바꾸는가?
FIT가 가능한 이유는
Transformer 내부가 Permutation-Invariant 구조이기 때문.
예를 들어 FFN:
[
h = \sigma(xW_1)W_2
]
여기서 W₁과 W₂에 동일한 permutation P를 적용하면:
[
\sigma(x W_1 P) P^{-1} W_2 = \sigma(x W_1) W_2
]
따라서 행·열 정렬이 바뀌어도 계산 결과는 동일.
🧩 3. 핵심:
“기능은 그대로인데 내부 weight의 순서 정보가 바뀐다”
→ 그것이 바로 워터마크이다.
따라서 워터마크 추출 과정은:
- Watermarked 모델의 weight를 읽음
- 원본 모델 weight와 비교
- weight column들의 대응 관계를 찾음
- 그 대응 관계(= permutation)가 워터마크
- permutation을 ∅⁻¹로 복호화
- ECC(GRS)로 ID력 복원
즉,
워터마크는 기능 기능이 아니라 weight의 구조적 배치에 존재한다.
🧠 그래서 핵심 포인트 정리하면:
✔ FIT = “Functionally Invariant Transformation”
- 모델의 function output은 동일
- 내부 파라미터 배치는 달라짐 → 이것이 watermark
✔ 왜 이런 변환을 사용하는가?
이유 1. 성능에 영향을 주지 않는다.
- Training-free
- Weight 재배열만 수행
- Perplexity 변화 ≈ 0.00
- 모델 유틸리티 완전 보존
그래서 대규모 LLM에서도 부담 없이 사용 가능.
이유 2. “Weight 순서 자체”가 안전한 watermark 정보가 된다.
순서만 바꿨기 때문에:
- quantization을 해도 순서 정보는 유지됨
- pruning을 해도 순서 정보 유지됨
- LoRA fine-tuning을 해도 base weight 순서는 유지됨
즉, 내부 구조의 “상대적 위치 관계”는 매우 robust함.
이 때문에 permutation watermark는 강력하다.
이유 3. 공격자가 제거하기 극도로 어렵다.
공격자가 임의 permutation을 적용하면:
- symbol-level에서 corruption 발생
- GRS error correction으로 대부분 복구됨
- 너무 공격이 심하면 ECC가 “fully corrupted”로 판단
→ 위조 방어
또한 고정점(fixed point) 없는 derangement 사용으로
패턴 노출이 없어 공격자가 구조를 복원하기 어렵다.
🧩 4. 정리:
✔ FIT 변환은 기능을 건드리지 않으면서
✔ 내부 weight의 순서를 바꿔 워터마크로 사용
✔ 추출은 weight 간 대응 관계를 잡아내어 permutation을 복원
✔ ECC(GRS)로 ID를 복구
✔ 성능 영향 없이, 매우 robust, 공격에도 안전
📌 “왜 이것이 가능한가?”를 한 줄로 요약
Transformer는 특정 차원의 순서가 바뀌어도 기능이 동일하기 때문에,
그 ‘순서’를 워터마크로 활용할 수 있는 것.
원하면 다음도 설명해줄게:
- FFN/attention head의 permutation-invariance 근거를 레이어 기준으로 더 상세히
- 왜 quantization/pruning에도 permutation watermark가 깨지지 않는지
- SU/IM 공격을 왜 V matrix를 이용해 완전히 무력화 가능한지
- Figure 1 전체 흐름을 코드 수준으로 설명
- φ permutation mapping을 실제 예제로 구성하여 이해시키기
아래는 논문에 등장하는 Table 1~4의 모든 정보를 하나의 구조화된 해설로 정리한 것이다.
단순 설명이 아니라, 표가 무엇을 의미하고, 어떤 연구적 인사이트를 담고 있는지까지 전문적으로 분석해준다.
✅ Table 1: Watermark Settings – 모델별 워터마크 삽입 구성
이 표는 각 모델 구조에 따라 가능한 Permutation Slot 수(n), Field Size(q), Code Dimension(k), Block 수, Hidden/Head Dimension 등을 정리한 것이다.
항목 의미| n | GRS codeword 길이 = 삽입 가능한 permutation 수 |
| q | GRS 코드가 사용하는 유한체 크기 (여기서는 2²⁴, 2²⁸ 등 규모 큰 GF) |
| k | GRS 메시지 길이, 즉 Model ID가 표현되는 심볼 수 |
| #Blk | Permutation slot의 블록 수 (예: multi-head나 FFN block 단위) |
| d | Permutation depth 또는 block 크기 |
| h | attention head 구성(예: 8×4 은 8head × group 4) |
| d₍f₎ | FFN intermediate dimension |
▷ 핵심 요약
- 모델마다 head 수, FFN dim이 다르기 때문에 사용 가능한 permutation slot 수(n) 가 달라짐.
- n이 클수록 GRS code redundancy가 늘어나 robust해짐.
- q는 derangement 풀 크기를 수용하기 위해 충분히 큰 field를 사용.
✅ Table 2: Adversary Permutation Sampling Strategies
공격자가 워터마크를 “깨뜨리기 위해” weight permutation에 적용하는 공격 전략이다.
전략 설명 예시 해설| Uniform | 모든 permutation을 균등 확률로 샘플링 | (2,4,3,1) | 가장 강력한 랜덤 공격 |
| Swap | 임의 위치 두 개를 스왑 | (2,1,3,4) | 작은 perturbation 공격 |
| Cycle | 랜덤 cycle을 생성하여 permute | (2,3,4,1) | head rotation 같은 실제적 구조와 유사 |
| Derangement | 모든 fixed point 없는 permutation 중 균등 샘플링 | (2,4,1,3) | 워터마크가 fixed point 기반일 때 강한 공격 |
▷ 핵심 요약
- 논문은 현실적인 공격(스왑·사이클) + 이론적으로 강한 공격(derangement·uniform)을 모두 고려.
- GRS + inverse-free derangement mapping 덕분에 이러한 공격을 견딜 수 있다.
✅ Table 3: Model Utility Evaluation — 기존 FIT-only 워터마킹의 문제점
이 표는 기존 FIT 기반 워터마킹 방식의 문제점을 보여준다.
모델: Llama2-7B, Gemma-7B
Setting 의미| WP | Weight Permutation 워터마크 삽입 |
| SU | Scale/Unscale 공격 |
| IM | Invertible Matrix(QK) 기반 Obfuscation |
| All / WP+IM | 복수 공격 동시 적용 |
▷ 관찰
- PPL 변화는 작지만 **Distortion(내부 representation 변화)**가 매우 크다 (7%~8%).
- SU/IM 공격 시 distortion 매우 커짐 → 추출 불안정.
- FIT-only 방식은 obfuscation 공격에 극도로 취약함을 보여주는 표.
✅ Table 4: Model Utility Evaluation — 논문의 ECC+Permutation 방식 결과
이번엔 논문이 제안한 방법을 적용한 후 모델 유틸리티를 평가한 표이다.
모든 모델(Llama3.2 시리즈, Llama2-7B, Gemma7B, Mistral8B-I)에 대해:
항목 결과| PPL 변화 | 0.000 ~ 0.001 → 사실상 변화 없음 |
| Distortion | 1–1.5% 수준 (Gemma만 7.68%) |
| 성능 저하 사실상 없음 | YES |
▷ 중요한 차이
기존 baseline과 달리 SU/IM 등 obfuscation을 포함해도 워터마크가 안정적으로 복원 가능.
- Distortion 낮음 → 추출 효율·정확도 높음
- Permutation structured + GRS error correction 덕분
📌 표 1~4를 전체적으로 묶어 얻을 수 있는 연구적 결론
Observation Explanation| 1. 모델 구조에 따라 permutation slot n이 다름 | head 수·FFN dim 구조에 따라 워터마크 redundancy 변화 |
| 2. 적대적 permutation 공격이 강력함 | swap/cycle/derangement 등 거의 weight alignment 깨뜨림 |
| 3. 기존 FIT 워터마킹은 distortion 커서 취약 | SU/IM 공격에 매우 약함 → extraction 실패 많음 |
| 4. ECC+inverse-free derangement가 robust 보장 | corruption 발생해도 GRS 복구 가능 |
| 5. 성능 손실 거의 없음 | FIT transformation은 function identical, distortion도 낮음 |
🧠 초압축: 1~4 테이블에서 얻는 핵심 인사이트
- 각 모델마다 permutation slot 전체 수(n)가 달라 ECC redundancy가 달라진다.
- 공격자가 사용하는 permutation 유형을 모두 고려한 강력한 평가 체계.
- 기존 FIT watermark는 distortion이 크고 obfuscation에 취약하다.
- 제안 기법(ECC + inverse-free derangement)은 distortion 적고 완전 복구 가능하다.
필요하면 다음도 만들어줄 수 있어:
- 📄 Table 1~4 기반 실험 이해도 체크리스트
- 🔧 직접 워터마킹을 구현하려는 사람을 위한 구현 파이프라인 정리
- 🧪 공격 실험을 그대로 재현할 수 있는 pseudo-code & evaluation plan