https://arxiv.org/abs/2302.03162
Protecting Language Generation Models via Invisible Watermarking
Language generation models have been an increasingly powerful enabler for many applications. Many such models offer free or affordable API access, which makes them potentially vulnerable to model extraction attacks through distillation. To protect intellec
arxiv.org
기존 방법들은 동의어로만 바꿔줘도 파훼가능!
=> 출력 텍스트를 수정하지 말고 토큰 확률 분포 자체에 숨겨진 신호를 삽입하여 워터마크 뽑기
여기선 토큰을 두 개의 그룹으로 나눠서 토큰 선택할 때 주기가 있게 됨(coosine을 통해 두 그룹이 번갈아가면서 뽑히도록)
=> 이러면 학습을 하기 위해 API를 통해 text를 얻는 공격자는 워터마킹 된 텍스트를 얻고 이를 통해 모델을 학습하게 된다.
probing dataset을 통해 모델이 우리 모델 데이터를 통해 학습됨을 입증

품질 저하 없이 기존 방법보다 안정적인 워터마킹을 할 수 있고, 워터마킹 텍스트가 지워져도 모델에 남아있다.

📌 학습 데이터셋 (Victim Model Training)
실험은 두 가지 generative task에서 진행됨.
🔵 (1) Machine Translation
IWSLT14 De→En
- 약 160k 문장
- 7k BPE vocab
- 실험에서는 standard fairseq preprocessing 사용
WMT14 De→En
- 약 4.5M 문장
- 32k BPE vocab
- 더 큰 데이터셋으로 robustness 확인
🔵 (2) Story Generation
ROCStories
- 각 샘플은 5개 문장
- 1~4번째 문장을 입력으로 사용
- 5번째 문장을 생성
- 약 90,000개의 학습 샘플
- vocab: 25k BPE
📌 평가 데이터셋 및 평가 메트릭
🔵 (1) Generation Quality Metrics
Machine Translation:
- BLEU: n-gram exact overlap 기반 번역 품질
- BERTScore: contextual semantic similarity 측정
Story Generation:
- ROUGE-L: longest common subsequence 기반 recall F1
- BERTScore: semantic similarity
👉 GINSEW는 품질 저하가 매우 적음(BLEU/ROUGE 감소 ≤ 0.4)
🔵 (2) Watermark Detection Metrics
mean Average Precision (mAP)
- Positive extracted 모델(20개) vs Negative 모델(30개)을
detection score(Psnr 기반)로 sorting하여 계산 - 높을수록 stolen 모델과 정상 모델 구분이 잘됨
Psnr (Peak Signal-to-Noise Ratio)
- Lomb–Scargle frequency domain에서
fw 근처 energy / noise energy 비율 - Psnr ↑ = watermark 존재 ↑
👉 논문의 핵심 지표.
GINSEW는 평소 mAP=100, 공격 상황에서도 86~93 유지.
| 문제 상황 | - LLM이 API로 제공되면서 model extraction attack(=distillation) 위험 증가 - 공격자는 대량 querying → pseudo-label 생성 → 모델 복제 가능 - 기존 watermark(lexical, synonym replacement)는 synonym randomization 등 단순 post-processing으로 쉽게 제거되어 IP 보호 실패 |
| 핵심 아이디어 | Invisible probability-based watermarking ① Vocabulary를 두 그룹(G1/G2)으로 랜덤 분할 ② 입력 x를 hash하여 scalar t=g(x,v,M) 생성 ③ 주파수 fw를 갖는 sinusoidal 신호 z₁,z₂ 생성 ④ 각 decoding step마다 group probability(Q_G1/Q_G2)에 ε 수준의 미세 perturbation 삽입 ⑤ 확률벡터 전체를 재스케일링하여 자연스러운 분포 유지 → 텍스트 내용은 바뀌지 않지만, 확률 패턴이 distillation에 의해 전파되는 구조 |
| 워터마크 검출 방식 | Algorithm 2 기반 ① suspect model에 probing input D 입력 ② 각 step에서 Q̂_G1 수집하여 (t, Q̂_G1) 시계열 생성 ③ Lomb–Scargle periodogram으로 fw 주파수의 peak 탐지 ④ Signal-to-noise ratio(Psnr) 계산 → threshold(Psnr>5 등)로 stolen 여부 판단 ※ 확률벡터 없이 텍스트만으로도 FFT 기반 검출 가능 |
| 학습 데이터 | Machine Translation - IWSLT14 De→En (7k BPE), WMT14 De→En (32k BPE) Story Generation - ROCStories (첫 4문장 입력, 마지막 문장 예측, 25k vocab) |
| Victim Model & 학습법 | - Transformer-base (fairseq) - Optimizer: Adam(β=(0.9,0.98)) - LR: 5e-4, warmup 4000 steps, inverse-sqrt decay - Beam search(5) decoding (기본) |
| Extraction 실험 구성 | - Positive extracted models: 20개 (watermarked API 출력으로 학습) - Negative models: 30개 (raw data로 from-scratch 학습) - 다양한 adversary 구조 실험: mBART, Transformer 6-6/4-4/2-2, ConvS2S |
| 평가 데이터 & 지표 | Generation quality - MT: BLEU, BERTScore - Story: ROUGE-L, BERTScore Watermark detection 지표 - Psnr (peak SNR), mAP(mean Average Precision) |
| 주요 결과 (Main Results) | - GINSEW는 generation quality 거의 유지 (BLEU/ROUGE 감소 ≤0.4) - Normal 경우 mAP = 100으로 IP 침해 완벽 검출 - Synonym randomization 공격 시 → 기존 방법(mAP 59~68) 붕괴 → GINSEW는 mAP 86~93 유지 (압도적 강인성) - distillation epoch이 증가할수록 watermark signal(Psnr) 증가 (Fig. 8) |
| 추가 실험 인사이트 (Ablations) | - 작은 모델(Transformer 2-2 등)은 watermark 학습이 약함 (mAP↓) - Text-only detection도 가능 (Psnr≈8 이상) - ε 증가 → detection↑ / quality↓ → 최적 ε=0.2 - adversary가 raw+WM mixed data 사용해도, WM 비율 ≥0.5면 검출 가능 |
| 기여(Contributions) | 1) LLM text generation을 대상으로 한 최초의 확률 공간 기반 invisible watermarking 2) distillation-resistant – 모델이 잘 distill될수록 오히려 watermark 강화 3) synonym/randomization 등 text-surface 공격 완전 회피 4) text-only detection 가능성 제시 5) 기존 watermarking 대비 mAP 19~29 point 개선 |
| 한계(Limitations) | - watermark level ε이 너무 낮으면 peak 검출 어려움 - large probing dataset 필요 (Lomb–Scargle 안정적 peak 위해) - adversary 모델이 지나치게 작으면 신호가 충분히 학습되지 않음 - 공격자가 여러 단계 재학습/정규화하면 신호 약화 가능성 존재 - 논문 가정: API는 한 번만 distillation됨 |
아래는 업로드한 논문 「Protecting Language Generation Models via Invisible Watermarking」 전체 내용을 기반으로,
문제 상황 → 방법론(GINSEW) → 실험 구성 → 결과 → 기여 → 한계 를 한눈에 파악할 수 있도록 연구자가 바로 실험에 적용할 수 있는 수준으로 체계적으로 정리한 표 및 상세 설명이다.
(근거: 논문 전체 본문 및 Table 1, Figure 1–8 등 시각 요소 포함)
📌 논문 핵심 요약 표 (Researcher-Friendly Summary)
구분 내용| 문제 상황 | LLM은 API로 제공되지만, 사용자가 대량 질의 후 sequence-level knowledge distillation으로 복제하는 model extraction attack이 증가. 기존 텍스트 워터마킹(lexical, synonym) 방식은 synonym randomization 등 간단한 공격으로 쉽게 제거됨. |
| 핵심 아이디어 (GINSEW) | 출력 텍스트를 수정하지 않고, 토큰 확률분포(probability vector) 자체에 숨겨진 주기 신호(sinusoidal signal) 삽입. 두 토큰 그룹(G1/G2)를 만들고 각 그룹의 **group probability(QG1/QG2)**를 미세 조정하여 워터마크 삽입 → 겉으로 보이지 않음 → distillation으로 확률 패턴이 그대로 전파됨. |
| 워터마킹 방식 | - 입력 x에 대해 hash g(x,v,M) 계산- 주파수 fw를 갖는 cosine 신호 적용- group prob을 ε 수준으로 미세 조정: (\tilde Q_{G1} = \frac{Q_{G1}+\varepsilon(1+z_1)}{1+2\varepsilon})- 확률 벡터 전체를 재스케일링하여 정상 분포 유지 |
| 워터마크 검출 | - suspect model에 probing input D 입력- 각 decoding step에서 Q̂_G1 수집- (t, Q̂_G1) 쌍으로 시간–신호 시계열 구성- Lomb–Scargle periodogram을 활용해 fw 주파수에서의 peak 여부 확인- peak의 SNR(Psnr)을 detection score로 사용 |
| 데이터셋 | MT: IWSLT14(7k BPE), WMT14(32k BPE)Story: ROCStories(25k BPE) |
| 평가 지표 | ※ Generation quality: BLEU, ROUGE-L, BERTScore※ Watermark detection: mAP, Psnr |
| 비교 baseline | - He et al. (2021): 단순 synonym replacement- CATER (2022): 조건부 synonym watermarking |
| 주요 결과 | - Generation quality 거의 영향 없음(표 1)- Synonym randomization 공격 시 기존 기법은 mAP 60대까지 급락하지만, GINSEW는 mAP 86–93 유지- distillation이 진행될수록 watermark 신호가 강화됨(Fig. 8) |
| 장점 | - 텍스트 표면 깨끗함 → 완전 invisible- distillation 과정에서 watermark가 더 강화됨- synonym 공격, spelling 교란이 무력화됨 |
| 한계 | - watermark level ε이 너무 작으면 검출 불가- probing dataset이 충분히 커야(Lomb–Scargle) peak가 안정적- adversary가 매우 작은 모델(2-2 Transformer 등) 사용하면 신호 학습이 제한됨 |
| 기여도 | - NLP에서 최초의 확률 벡터 기반 invisible watermarking- distillation-resistant protection을 수학적으로/실험적으로 검증- text-only detection 가능성도 제안(Fig. 5.2) |
🔍 1. 문제 상황 (Problem Setting)
논문은 LLM API를 이용한 model extraction 문제가 심각하다고 지적한다.
✔ Distillation이 API 모델을 손쉽게 복제할 수 있는 이유
- API 출력은 사실상 “학습 라벨”로 취급 가능
- KD(sample complexity O(1/ϵ))가 raw data 학습(O(1/ϵ²))보다 훨씬 효율적
- Stanford Alpaca 사례: 단 $600로 ChatGPT 수준의 모델을 복제했다고 보고
→ API 제공 기업·공공기관의 모델 지적재산권(IP) 보호가 위협받음
🔍 2. 기존 워터마킹 접근의 한계
기존 텍스트 워터마킹은 전부 겉으로 보이는(token-level) 방식이다.
✔ He et al. (2021), CATER (2022)
- 특정 단어를 동의어로 바꾸는 방식(표면 수정)
- simple synonym randomization 공격으로 즉시 무력화됨
- 표면 텍스트가 변형되면 워터마크 신호가 깨짐
🔍 3. GINSEW 방법론 상세 (step-by-step)
아래는 논문 Figure 1–2, Algorithm 1–2의 전체 내용을 기반으로 구성.
(1) 두 그룹으로 vocabulary split
모든 토큰을 절반씩 나누어 G1, G2 두 그룹으로 배정
(논문은 random assignment 사용)
(2) 입력 x를 해시하여 pseudo-random scalar 생성
[ t = g(x, v, M) \sim U(0,1) ]
- v: random phase vector
- M: random token matrix
- tok(x): 두 번째 토큰을 선택 (실험 상 일관된 선택)
- probability integral transform을 통해 uniform scalar 생성
→ 이 값이 watermark의 “위상(phase)” 역할
(3) sinusoidal signal 생성
[ z_1 = \cos(f_w \cdot g(x)) ]
[ z_2 = \cos(f_w \cdot g(x) + \pi) = -z_1 ]
- 그룹1은 +cos, 그룹2는 -cos 효과 적용 (완벽한 대칭)
- fw는 비밀키 역할을 하는 주파수
(4) group prob(QG1, QG2)에 ε 수준의 미세 조작
[ \tilde Q_{G1} = \frac{Q_{G1} + \varepsilon (1+z_1)}{1 + 2\varepsilon} ]
→ 확률합이 1이 되는 valid distribution임을 Lemma A.2로 증명함.
(5) 확률벡터 전체를 재스케일링
각 토큰 i에 대해:
- i ∈ G1 → pᵢ ← pᵢ · (˜QG1 / QG1)
- i ∈ G2 → pᵢ ← pᵢ · (˜QG2 / QG2)
→ 문장 자체는 변형되지 않지만, 모델이 학습할 확률 패턴은 변함
→ distillation 시 이 패턴이 그대로 누적·전파됨
(6) suspect model 검증
Algorithm 2 과정:
- probing input x 투입
- suspect model의 Q̂_G1을 step 별로 수집
- (t, Q̂_G1) 시계열 생성
- Lomb–Scargle periodogram 적용
- fw 주파수에서 peak 찾기 → Psnr 계산
Psnr > 5 같은 threshold로 stolen model 판정
🔍 4. 실험 구성
데이터셋
- MT: IWSLT14 De→En (7k BPE), WMT14 De→En (32k BPE)
- Story generation: ROCStories (25k BPE)
Victim model
- Transformer-base (fairseq)
Extraction setting
- 20개의 positive extracted model
- 30개의 negative model (raw data로 학습)
Decoding
- Beam search(5) 기본
- Beam4, Top-k sampling(k=5)도 실험
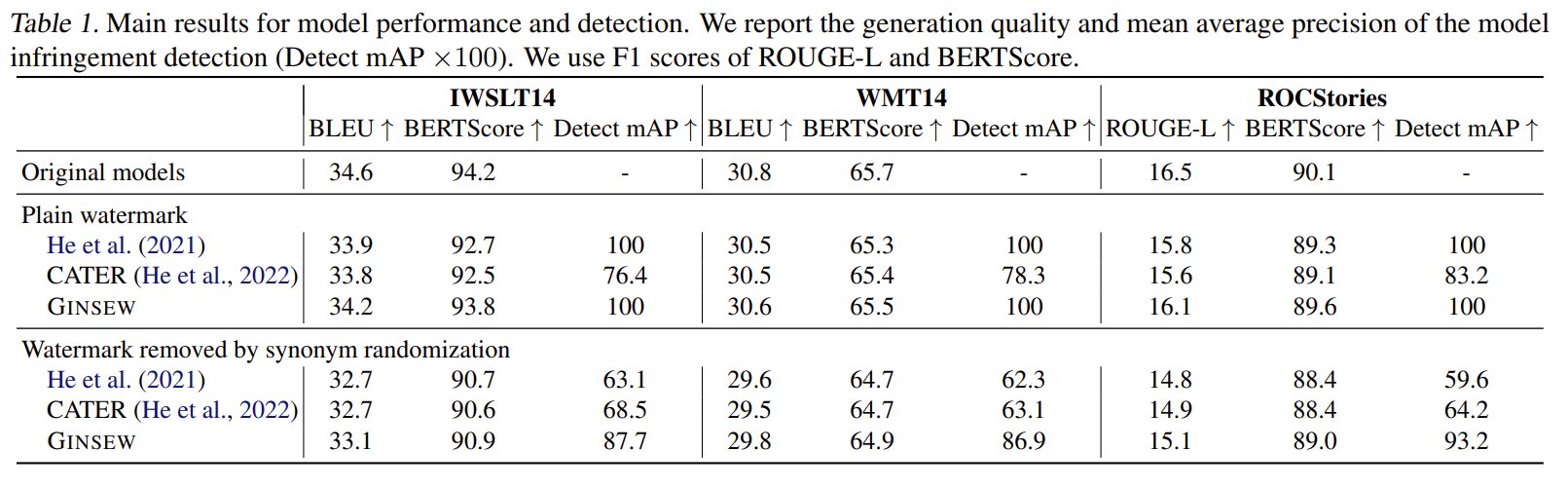
🔍 5. 주요 결과 요약 (Table 1 기반)
✔ Generation quality 영향 거의 없음
Dataset Non-WM GINSEW 감소폭| IWSLT BLEU | 34.6 | 34.2 | -0.4 |
| WMT BLEU | 30.8 | 30.6 | -0.2 |
| ROC ROUGE-L | 16.5 | 16.1 | -0.4 |
ε=0.2 수준에서는 품질 하락이 매우 미미함.
✔ Detection 성능 (mAP 100%)
- He et al. (2021): 100
- CATER: 76~83
- GINSEW: 100
그러나 공격 상황에서 차이가 크게 난다
✔ Synonym randomization 공격 (watermark removal attack)
Method IWSLT mAP WMT mAP ROC mAP| He et al. | 63% | 62% | 59% |
| CATER | 68% | 63% | 64% |
| GINSEW | 87% | 86% | 93% |
GINSEW는 token surface가 아닌 확률 공간에서 watermark를 전파하기 때문에 공격에 매우 강함.
✔ Distillation이 진행될수록 watermark 강화 (Fig. 8)
- epoch 증가
→ BLEU 증가
→ Psnr도 증가
즉, stolen model이 성능을 높일수록 watermark 신호가 더 뚜렷해짐.
이것은 watermark robustness 관점에서 매우 이상적.
🔍 6. Ablation에서 발견된 핵심 인사이트
✔ (1) 모델 구조가 달라도 signal 학습됨 (Table 2)
- mBART, Transformer 6–6, 4–4 → mAP 100
- 작은 모델(2–2), ConvS2S → mAP 저하
→ 파라미터 수가 너무 적으면 워터마크 신호를 충분히 학습하지 못함
✔ (2) Text-only detection도 가능 (Sec 5.2)
- 확률벡터 없이, 생성 텍스트의 token이 G1인지 여부만 보고도
- FFT로 fw peak 검출 가능 (Psnr=8.35)
✔ (3) watermark level ε의 trade-off (Fig. 6)
- ε ↑ → 검출 성능↑, 품질↓
- 최적값으로 ε=0.2 선택
✔ (4) mixture 공격 시 ratio ≥ 0.5이면 detection 가능 (Fig. 7)
🔍 7. 기여·의의
- LLM text generation 최초의 invisible probability watermarking 기법
- surface-level이 아닌 확률 공간 watermark → synonym/randomization 공격 완전 방어
- distillation 과정에서 watermark가 오히려 강화되는 구조
- 백색박스/확률 정보 없이도 text-only detection 가능
- mAP 기준 기존 기법 대비 19~29 포인트 향상
🔍 8. 한계점
- watermark level ε 낮으면 peak 검출 어려움
- probing dataset 크게 필요
- adversary 모델이 너무 작으면 워터마크 학습이 약함
- 공격자가 여러 단계로 재학습하면 신호 약화 가능성 존재
- 논문 가정: 공격자는 victim을 한 번만 distill함
✔ 요약 한 줄
GINSEW은 텍스트가 아닌 ‘확률 공간’에 주기 신호를 삽입함으로써 distillation으로도 사라지지 않는 invisible watermark를 구현하고, synonym 공격에도 견고한 LLM 보호 기법이다.
필요하다면 다음도 제공해 줄 수 있어:
- 📌 그림(Figure 1–8) 중심 해설
- 📌 GINSEW 구현용 파이토치 코드 템플릿
- 📌 다른 watermark 기법(CosWM, CATER)과 기술적 차별점 비교표
- 📌 너의 watermark 연구 실험 설계안 제작
원하는 형식으로 다시 정리해줄까?
아래 설명은 Figure 1 전체 흐름을 논문의 **GINSEW 방법론(워터마킹 + 추적/검출 단계)**과 함께 연구자 관점에서 구조적으로 정리한 것이다.
이미지를 기반으로 한 설명이며, 논문 본문 내용도 함께 통합했다.
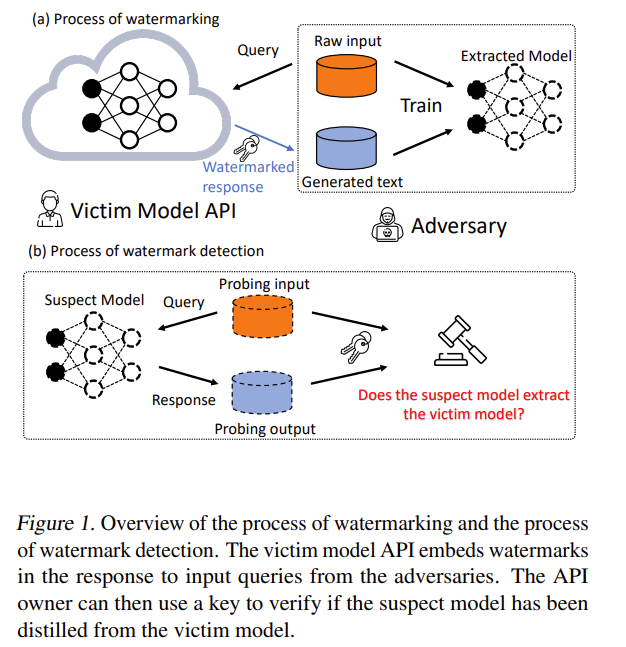
📌 Figure 1: GINSEW의 전체 파이프라인 개념도
“워터마킹이 어떻게 삽입되고, 어떻게 검출되는가”를 직관적으로 보여주는 핵심 그림
🔵 (a) Process of Watermarking — 워터마크 삽입 단계
1) Victim Model API가 질의를 받으면, 출력 확률 분포에 ‘숨겨진 신호’를 삽입한다
그림에서 **파란색 ‘Watermarked response’**가 이를 의미함.
- 사용자가 API에 Query를 보냄
- 모델은 원래의 토큰 확률 분포 p 를 계산함
- GINSEW는 여기서 텍스트 자체를 바꾸지 않고
→ p의 확률값만 미세하게 조정하여 워터마크를 삽입한다
🔍 GINSEW가 삽입하는 것은 ‘텍스트’가 아니라 확률 공간의 패턴
논문의 핵심:
- Vocabulary를 두 그룹(G1/G2)으로 나눔
- 입력 x를 해시하여 t=g(x,v,M) 생성
- 주파수 fw를 갖는 cosine 신호 z₁,z₂를 계산
- group probability Q_G1, Q_G2에 ε만큼 변조를 가해
[
\tilde Q_{G1} = \frac{Q_{G1} + \varepsilon(1+z_1)}{1+2\varepsilon}
] - 확률 벡터 전체를 재스케일링
→ 출력되는 단어는 자연스럽지만, 내부 확률 패턴에는 은밀한 주기 신호가 심어져 있음
2) 공격자(Adversary)는 이를 이용해 모델을 학습한다 (Extracted Model)
그림 오른쪽 상단 박스:
- 공격자는 raw input dataset을 준비
- Victim API에게 질의하여 watermarked generated text를 얻음
- 이를 pseudo-label로 사용해 Extracted Model을 distill함
중요 포인트:
- 공격자가 텍스트만 보더라도,
모델에 그대로 전파되는 것은 텍스트 표면이 아니라 확률 패턴 - 즉, 공격자도 눈치채지 못하게 stealth하게 워터마킹이 가해짐
🔵 (b) Process of Watermark Detection — 워터마크 검출 단계
이 단계는 모델이 탈취되었는지 IP 분쟁 상황에서 활용되는 구조이다.
1) Suspect Model에 Probing input을 넣는다
그림의 왼쪽:
- Suspect Model은 공격자가 만든 모델(혹은 제3자가 제출한 모델)
- API 소유자 혹은 제3의 중재기관이 probing dataset D 를 준비함
2) 출력에서 group probability(Q̂_G1)를 수집
논문 Algorithm 2 단계:
- probing input x를 suspect model에 넣음
- 모델이 decoding하는 각 step에서 p̂ (확률벡터) 를 수집
- p̂에서 G1에 속한 단어 확률합 Q̂_G1 계산
- (t = g(x), Q̂_G1) 쌍을 시계열로 모음
그림의 Probing output 블록이 이를 나타냄.
3) 이 시계열이 GINSEW의 ‘비밀 주파수 fw’를 포함하는지 분석
그림 오른쪽:
‘Does the suspect model extract the victim model?’
이 문장이 바로 다음 절차를 의미한다.
- 수집한 (t, Q̂_G1) 값에 대해
Lomb–Scargle periodogram을 적용 - 프리퀀시 도메인에서 fw 위치에 peak 존재 여부를 확인
- Signal-to-noise ratio(Psnr)가 높은 경우
→ 해당 모델은 Victim 모델을 distill한 것이 거의 확실
즉, 확률 기반 watermark가 distillation 과정을 통해 그대로 전파되었음을 확인하는 과정이다.
🔵 Figure 전체가 전달하는 핵심 메시지
1) 워터마크는 API의 출력 확률에 은밀히 삽입된다 (사용자는 모름)
- 텍스트는 자연스럽고 품질도 거의 동일
- 공격자도 알아채기 어렵다
2) Distillation 기반 모델 탈취는 확률 패턴까지 복제함
- 그래서 숨겨진 신호가 그대로 공격자 모델에 복제된다
3) 사후 검증 단계에서 비밀키(fw, v, M)로 신호를 읽어낼 수 있다
- 확률벡터 or 텍스트만으로도 검출 가능
- 법적 분쟁, API 보호, IP 주장을 위한 강력한 증거 제공
📌 요약(한 문장)
Figure 1은 GINSEW가 API 출력 확률에 삽입한 ‘보이지 않는 주기 신호’가 distillation을 통해 공격자 모델로 전달되며, 사후에 비밀키를 이용해 신호를 추출해 IP 침해 여부를 판단하는 전체 워크플로우를 나타낸다.
원하면 이 Figure를
- 실험 파이프라인 관점,
- gradient-flow 관점,
- security threat model 관점
에서도 해석해줄게.