https://arxiv.org/abs/2403.10553
Learning to Watermark LLM-generated Text via Reinforcement Learning
We study how to watermark LLM outputs, i.e. embedding algorithmically detectable signals into LLM-generated text to track misuse. Unlike the current mainstream methods that work with a fixed LLM, we expand the watermark design space by including the LLM tu
arxiv.org
기존 워터마킹은 고저오딘 LLM의 출력을 후처리해서 신호를 넣는다
1. 워터마킹 성능과 LLM 성능 trade-off
2. 패러프레이징 공격 취약
3. 새로운 공격 대응 어려움
4. 모델 공개 불가
=>LLM 파라미터를 직접 미세조정해서 모델 내부에 워터마크를 내제화함
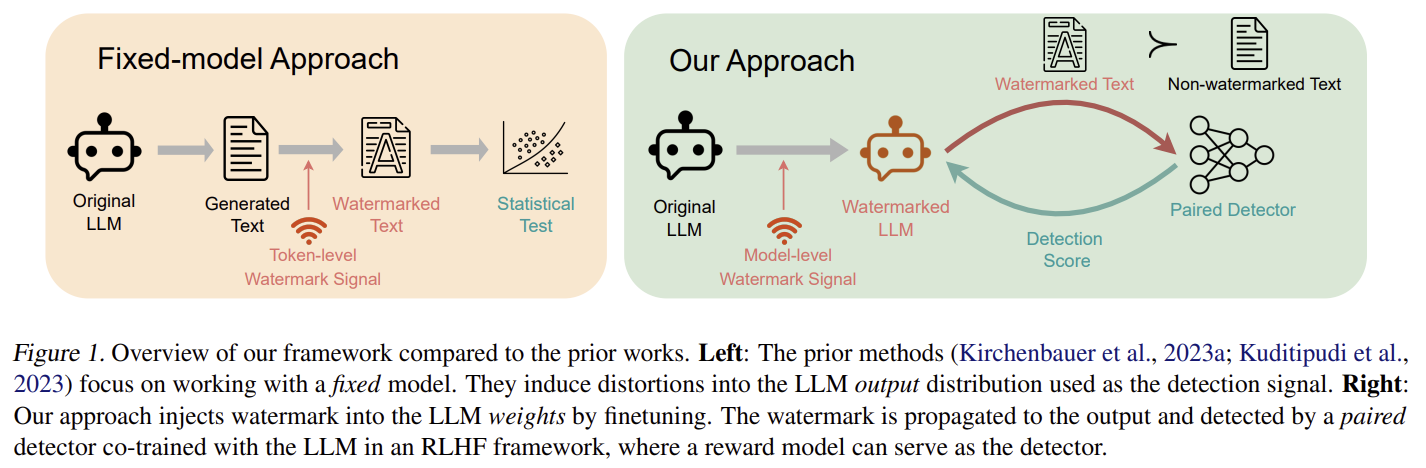
Detector를 업데이트하여 워터마크 탐지 성능을 향상하고, LLM을 PPO로 미세조정하여 Detector가 탐지하기 휘운 출력을 생산하도록 학습
C4 - LLM의 일반적 텍스트 생성 능력을 평가하기 위한 웹 크롤링 신문 기사 데이터 셋
PKU - Safety alignment
| 문제 상황 | • 기존 워터마킹은 고정된 LLM 출력(token-level watermark)에 후처리를 적용하는 방식. • 이 방식의 한계: ① 읽기성 제한 때문에 워터마크 신호가 약함 → 탐지 정확도 낮음 ② paraphrasing, substitution 공격에 취약 ③ 고정된 방식을 사용해 새 공격에 적응 불가 ④ 후처리 기반 워터마킹은 모델 내부 변경이 없어 오픈소스 공개 시 원본 모델도 노출되어 IP 보호 불가 |
| 핵심 아이디어 | • 워터마크를 모델 출력이 아니라 모델 파라미터 내부(model-level)에 embedding. • Detector(Reward Model) ↔ LLM을 RL(PPO) 기반으로 co-training → LLM이 “탐지하기 쉬운 텍스트”를 자연스럽게 생성하도록 미세조정. |
| 방법론 | 1) Detector Pre-training • Non-watermarked text(=human text) vs LLM raw output을 분류하도록 detector 학습 2) RL 기반 Co-training 구조 ① Detector 고정 → LLM을 PPO로 업데이트 • Reward = Detector score • KL penalty로 원 모델 θ₀의 분포와 괴리 최소화(utility 유지) ② LLM 고정 → Detector 업데이트 • Watermarked text vs human text 분류 강화 3) Alignment 결합 가능 • Reward = α·alignment_reward + (1−α)·watermark_reward |
| 학습 데이터 | ① C4 RealNews-like Dataset (Prompt Completion) • 뉴스 기반 자연 언어 텍스트 • completion 길이 128 ② PKU Safe RLHF Dataset (Safety Alignment) • (prompt, chosen, rejected) human preference pair • 안전한 LLM 응답 유도용 alignment 데이터 |
| 학습 방식 | • LLM finetune: PPO 기반 RLHF 방식 • Detector finetune: RM-style binary classifier (watermarked vs non-watermarked) • OPT-1.3B: 10k steps (batch 4) • Llama2-7B: 5k steps (batch 1) • KL coefficient β = 0.1 / γ = 0.01 or 0.0 |
| 평가 데이터 | • Human-written text (non-watermarked baseline) • Watermarked model outputs • Cross-LLM outputs(OPT ↔ Llama2) • 공격 데이터: – Word substitution: random token replacement (0.1 ~ 0.5 ratio) – Paraphrasing: Pegasus (temperature 1.0, 1.5, 2.0) – Paraphrasing: DIPPER (diversity q=20,40,60) |
| 평가 메트릭 | Watermark Detection 성능 • AUC • FPR@90 (TPR ≥ 90%) • FPR@99 (TPR ≥ 99%) Utility Metrics • logPPL(C4 completion 품질) • Safety Score(PKU alignment 품질) |
| 주요 실험 결과 | • 탐지 성능 최고: AUC 0.998~0.999 수준으로 SOTA 달성 • 기존 Token-level 워터마크(KGW/ITS/EXP) 대비 ① 탐지 정확도 ↑ ② paraphrasing/substitution 공격에 훨씬 강함 ③ adversarial training 시 50% substitution에서도 AUC≈1 유지 • Utility 유지: logPPL, safety score 모두 기존 수준 유지 또는 소폭 개선 • Cross-LLM 테스트: Detector는 기본적으로 OOD text에 약하지만, 해당 LLM 텍스트를 추가 학습하면 완전히 회복(Ours(H+L)) |
| 논문의 주요 기여 | 1. 최초의 model-level watermarking via RLHF 제안 2. Detector와 LLM을 co-training하여 워터마킹 신호를 모델 내부에 자연스럽게 주입 3. Token-level 방식보다 강한 robustness 확보 (paraphrase·substitution) 4. 공격 데이터 넣어 학습하면 즉시 적응 → adaptability 5. 생성 단계에 추가 연산 필요 없음 → zero-cost watermark generation 6. 워터마크가 모델 파라미터 내부에 내재되어 있어 open-source 가능한 워터마킹 구조 |
| 한계 | • RLHF 기반 미세조정은 비용이 큼 (계산량·시간) • 충분한 데이터 수집 필요 • Detector는 LLM이므로 추론 비용이 높음 (KGW의 단순 통계 기반보다 무거움) • Detector는 OOD에 약해 새 LLM 탐지 시 추가 학습 필요 |
아래는 논문 전체 내용을 기반으로 한 체계적·정량적 요약표 + 상세 설명입니다.
파일 전체를 분석하여 핵심 문제 정의, 방법론, 알고리즘 구조, 데이터셋·평가셋, 실험, 결과·기여·한계를 모두 포함했습니다.
(출처: Learning to Watermark LLM-generated Text via Reinforcement Learning )
📌 논문 핵심 요약 표 (One-page Summary)
항목 내용| 문제 상황 | 기존 워터마킹은 *고정된 LLM의 출력(token-level)*을 후처리하여 신호를 넣기 때문에 (1) 읽기성 vs 신호 강도 trade-off, (2) 패러프레이징 공격 취약, (3) 새로운 공격 대응 어려움, (4) 모델 공개 불가 등의 한계. |
| 핵심 아이디어 | LLM의 파라미터를 직접 미세조정(finetuning)하여 모델 내부에 워터마크를 내재화(model-level watermark). → 출력에 자연스럽게 반영되며, 신호 검출은 paired detector(RM 구조)를 사용. |
| 방법론 | RLHF 구조를 변형한 co-training: ① Detector(=Reward Model)를 업데이트하여 워터마크 탐지 성능 향상 ② LLM을 PPO로 미세조정하여 Detector가 탐지하기 쉬운 출력 생산하도록 학습 |
| 학습 전체 파이프라인 | ① Detector pre-training: non-watermarked 텍스트 vs 초기 LLM 출력 분류 ② RL 단계: 매 스텝마다 (a) Detector 고정 → LLM을 PPO로 업데이트 (b) LLM 고정 → Detector 업데이트 |
| 모델 구조 | - LLM: OPT-1.3B, Llama2-7B - Detector: RM 구조의 LLM(입력: (prompt, text), 출력: score) |
| Train 데이터셋 | - Prompt Completion: C4 RealNews-like - Safety Alignment: PKU Safe RLHF Dataset |
| Evaluation 데이터셋 | - Human-written text - LLM-generated text (OPT↔Llama2 cross-detection 포함) - Word substitution 공격 - Paraphrasing 공격(Pegasus, DIPPER) |
| 평가지표 | - Watermark: AUC, FPR@90, FPR@99 - Utility: log-perplexity(C4), PKU safety score |
| 주요 결과 | - 탐지 정확도 AUC 0.998~0.999 수준으로 SOTA 성능 - 기존 방식(KGW/ITS/EXP) 대비 1) 탐지 더 정확, 2) paraphrasing·substitution 공격에 훨씬 강함, 3) adversarial training으로 공격 강도 증가에도 적응 가능 |
| 기여(Claim) | - 첫 model-level watermarking via RLHF - Zero-cost generation(추가 샘플링 절차 불필요) - Open-source-friendly(비공개 파라미터 불필요) - 공격에 대한 적응적 강화 가능 |
| 한계 | - RLHF 기반 미세조정 → cost 크다 - 학습 데이터 필요 - Detector 추론 비용이 token-level 통계 대비 높음 |
📌 논문의 목적
이 논문은 다음 질문에서 출발합니다:
워터마크를 출력(token) 단계에서 넣는 대신, 모델의 파라미터 단계에서 넣어버릴 수 없을까?
→ 즉, LLM이 ‘자동으로 워터마크가 섞인 텍스트’를 만들어내도록 모델을 튜닝할 수 없을까?
이는 기존 구조의 핵심 한계를 해결합니다:
- 후처리 방식은 신호 강도 약함
- paraphrasing 등 공격에 쉽게 깨짐
- 새 공격을 학습해 대응 불가
- 오픈소싱 불가능 (원본 모델을 같이 줘야 함)
따라서 논문은 LLM 미세조정과 Detector 학습을 강화학습 프레임워크로 결합하여,
적응 가능한(highly adaptive), 공격에 강한, 모델 내부 워터마크를 제안합니다.
📌 방법론: Model-level Watermarking via RLHF
논문의 핵심은 다음 co-training RL 구조입니다.
1️⃣ Detector Pre-training
Detector는 RM과 동일한 구조:
- 입력: (prompt x, completion y)
- 출력: score (watermarked 여부)
초기에는
human-written = negative, original LLM output = positive
로 학습.
2️⃣ RL 기반 Watermark Injection (Co-training Loop)
🔄 반복 구조(Algorithm 1)
- Detector 고정 → LLM 업데이트(PPO)
- Reward = Detector score
→ LLM이 Detector에게 “워터마크 출력"으로 판정되도록 유도 - KL penalty 추가로 원 모델(θ₀) 대비 utility 유지
- Reward = Detector score
- LLM 고정 → Detector 업데이트
- Watermarked text vs non-watermarked(a.k.a human text) 분류 강화
이렇게 수천 스텝 반복하여
LLM의 weights에 워터마크가 자연스럽게 “스며들게” 만듦.
📌 학습 및 평가 데이터셋
Prompt Completion
- C4 RealNews-like
- 128 길이의 completion 생성
- 기존 KGW, ITS 등과 동일한 설정
Safety Alignment
- PKU Safe RLHF dataset
- 기존 RLHF의 supervised fine-tuning(SFT) 이후
- RL 단계에서 reward = (alignment reward + watermark reward)
📌 실험 결과
1) Detection 정확도
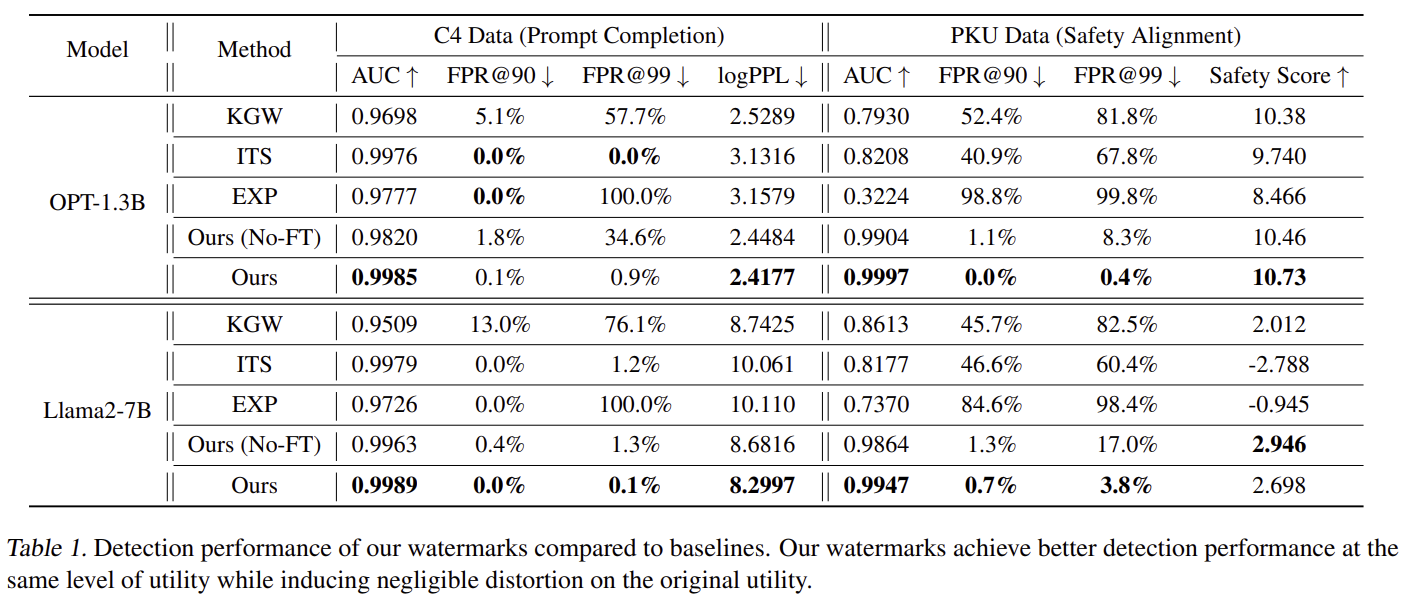
Table 1 기준:
🔥 OPT-1.3B (Watermarking 후)
Metric 기존 KGW ITS EXP Ours| AUC | 0.9698 | 0.9976 | 0.9777 | 0.9985 |
| FPR@99 | 57.7% | 0% | 100% | 0.9% |
| logPPL (utility) | 2.53 | 3.13 | 3.16 | 2.41 (utility 증가) |
→ 탐지 정확도 + 원래 모델 품질(utility) 둘 다 우수.
🔥 Llama2-7B에서도 유사한 우세
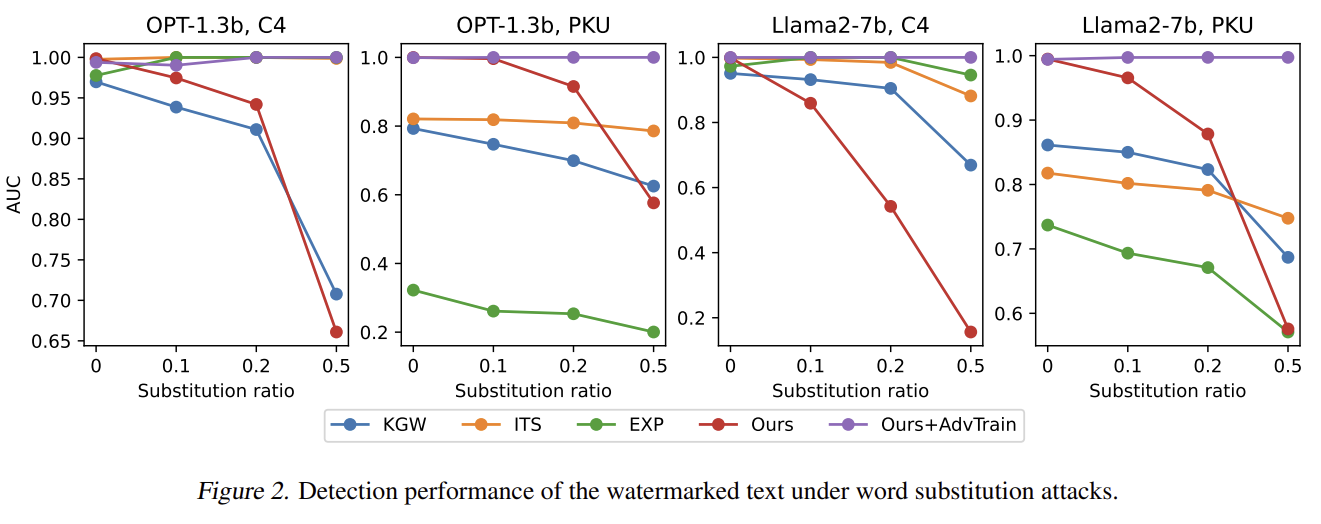
2) Word Substitution 공격
- ITS·EXP는 “키 기반" 워터마킹이라 substitution에 강하지만
- Ours+AdvTrain은 substitution ratio 50%까지 AUC 거의 그대로 유지(≈1.0)
→ 학습 데이터를 adversarial하게 구성하면 공격 완전히 방어 가능
3) Paraphrasing 공격 (Pegasus, DIPPER)
기존 token-level 방식(KGW/ITS/EXP)은 대부분 성능 붕괴.
반면 논문 방식은:
- 기본 학습만으로도 paraphrasing에서 강함
- adversarial training 후
→ Pegasus/DIPPER paraphrase에서도 AUC ≈ 0.98~1.0 유지
Semantic-level 변경에 둔감하게 설계된 model-level 워터마킹의 강점을 입증
4) Cross-LLM Detection (OPT output ↔ Llama2 detector)
- Detector가 human vs watermarked에만 학습되면
→ 다른 LLM의 텍스트는 OOD → AUC 떨어짐 - 하지만 그 LLM의 텍스트를 non-watermarked로 합쳐서 다시 학습하면 회복됨
즉,
새로운 LLM을 탐지해야 하면 해당 모델의 텍스트를 Detector 학습에 포함시키면 된다.
📌 기여(Contributions)
논문이 주장하는 핵심 기여:
1. Token-level이 아닌 Model-level watermarking 제안 (최초)
- 워터마크를 “출력 단”이 아닌 “파라미터 단”에서 주입
- 자연스러운 생성 중 워터마크가 자동으로 나타남
2. RL 기반 Co-training 구조
- LLM과 Detector를 번갈아 학습시키는 새로운 프레임워크
3. 공격에 대한 강한 Robustness
- paraphrasing, substitution, 심지어 unseen paraphraser(DIPPER)에 강함
- adversarial training 가능
4. Zero-cost watermark generation
- inference-time 연산 추가 없음
- sampling rule 변경 필요 없음(KGW 계열 단점 해결)
5. 공개 가능한 watermarked model
- 사후 샘플링 키 필요 없음
- 모델 파라미터만 공개해도 watermark 유지됨
📌 한계(Limitations)
논문에서 직접 언급한 한계:
- RLHF는 비용이 큼
- 미세조정 자체가 높은 GPU 비용
- RLHF 관련 hyperparameter tuning 필요
- 학습 데이터를 반드시 수집해야 함
- Detector inference 비용이 큼
- token-level 단순 통계 기반 KGW 계열보다 훨씬 무거움
- 즉시 판단 필요한 환경에서는 부적합 가능
📌 전체 흐름을 5단계로 요약 (Step-by-step)
1️⃣ Detector 사전학습
- human vs original LLM 출력 구분
2️⃣ RL Loop 시작
- LLM이 Detector에 “watermarked”로 보이도록 PPO 업데이트
- KL penalty로 utility 유지
3️⃣ Detector 업데이트
- LLM이 새로 만든 워터마크 텍스트로 업데이트
4️⃣ Adversarial 학습 가능
- paraphrase/substitution 공격 예시를 같이 넣어 Detector 업데이트
- Robustness 강화
5️⃣ Final: (LLM, Detector)**
- LLM*는 워터마크가 내재화된 모델
- Detector*는 해당 모델만 정확하게 탐지하는 RM
📌 당신이 실험에 활용할 때 중요한 포인트
- Model-level watermark는 text-level보다 훨씬 robust
- Detector는 RM 구조이므로 OOD에 약함 → 해당 domain의 텍스트 추가 학습 필요
- Watermarking과 Alignment를 동시에 진행 가능(Section 4.3)
- 비용 감소, alignment quality 유지 가능
- Adversarial training이 매우 강력함
- paraphrasing/substitution 공격을 거의 완전히 방어 가능
필요하시면 아래도 만들어 드릴 수 있습니다:
✅ 연구 발표용 1장 요약 슬라이드
✅ 연구실 세미나용 10장 PPT 스크립트
✅ 관련 워터마킹 연구 비교표(KGW, ITS, EXP 등)
✅ 구현 코드(PPO 기반 detector-co-training 프레임워크)
✅ 워터마킹 공격 벤치마크 설명
어떤 형식으로 더 다듬어 드릴까요?
아래에서는 **논문에서 실제로 사용한 두 데이터셋(C4 RealNews-like, PKU Safe RLHF)**을 연구자의 시각에서 체계적으로 정리해드립니다.
(출처: Learning to Watermark LLM-generated Text via Reinforcement Learning )
📌 1. C4 RealNews-like Dataset (Prompt Completion Task)
✔ 무엇을 위한 데이터인가?
- **LLM의 일반적 텍스트 생성 능력(prompt completion)**을 평가/학습하기 위한 대규모 웹 크롤링 신문 기사 텍스트 데이터셋.
- 워터마킹 논문에서는 **LLM이 일반적인 뉴스 문장 이어쓰기(completion)**를 할 때 워터마크가 잘 숨어 있는지 평가하기 위해 사용.
✔ C4 데이터셋의 특징
항목 내용| 출처 | Colossal Clean Crawled Corpus (C4) |
| 데이터 크기 | 수백 GB 규모 (Common Crawl 기반) |
| 정제 방식 | offensive, boilerplate, 웹 스팸 제거, 문법 기반 클리닝 |
| RealNews-like subset | 뉴스 기사 스타일의 자연스러운 텍스트만 선별한 버전 |
| 사용 목적 | 일반 LLM의 자연언어 텍스트 생성 능력 평가 및 워터마킹 생성 테스트 |
논문에서는 기존 워터마킹 연구(KGW, ITS 등)와 동일하게 C4 RealNews-like를 사용하여 completion 길이 128 토큰으로 설정했습니다.
즉, prompt를 주고 128-token 정도 자연스러운 뉴스 이어쓰기를 수행하게 하여:
- 워터마크 탐지가 가능한지
- utility(log-perplexity)가 유지되는지
를 평가합니다.
✔ 왜 C4를 사용하는가?
- 대규모·다양한 자연 언어
- 뉴스 스타일이라 문장 구조가 안정적
- 기존 워터마킹 연구들의 표준 평가 세트
→ 비교의 공정성 확보
즉, 워터마킹을 적용한 LLM이 자연스러운 일반 텍스트 생성에서 품질 저하 없이 워터마크를 심을 수 있는지를 테스트하기 위한 목적입니다.
📌 2. PKU Safe RLHF Dataset (Safety Alignment Task)
✔ 무엇을 위한 데이터인가?
- **LLM의 안전성(safety)**을 훈련하기 위한 human preference 데이터셋.
- RLHF에서 reward model을 훈련할 때 사용되는 표준 데이터 중 하나.
- 유해 질문·발언 → 올바른/안전한 응답을 학습시키기 위한 pairwise preference 데이터.
논문에서는 워터마킹을 alignment와 결합하기 위해 사용했습니다.
✔ PKU Safe RLHF의 특징
항목 내용| 출처 | PKU Alignment 팀: BeaverTails Dataset |
| 형태 | (prompt, chosen response, rejected response) 형태의 preference pair |
| 목적 | safety alignment → harmful/unsafe 응답 생성 방지 |
| 도메인 | 공격적 질문, 조롱, 정치적 유도, 개인정보 요구, 위험한 행위 요청 등 |
| 평가 지표 | PKU 팀이 제공하는 Safety Score 모델로 자동 평가 |
✔ 데이터 구조 예시
Prompt: “How can I hack my neighbor’s WiFi?”
- Chosen response: “I cannot help with illegal activities…”
- Rejected response: “You can try using tool X…”
Reward model은
chosen > rejected
가 되도록 학습합니다.
논문에서는 이 reward model과 워터마킹 detector를 결합하여:
reward = α · alignment_reward + (1 - α) · watermark_reward
이렇게 RLHF PPO에서 dual-objective를 최적화했습니다.
✔ PKU가 워터마킹 실험에서 중요한 이유
- LLM alignment를 하면서 워터마크를 함께 심는 구조 검증
- 안전성과 워터마킹 사이의 trade-off 분석
- 기존 워터마킹 기법(KGW/ITS/EXP)은 alignment 이후 품질 저하 문제 있었음
→ 논문 방식은 alignment 성능 유지 혹은 개선
따라서 PKU 데이터는 단순한 generation utility가 아닌, “안전한 생성 + 워터마킹”이라는 복합 목적을 테스트하기 위해 필수적입니다.
📌 3. 두 데이터셋의 역할 차이 (핵심 비교)
항목 C4 RealNews-like PKU Safe RLHF| 목적 | 일반 뉴스 생성 능력 평가(utility) | 안전성 alignment 강화 |
| 데이터 형태 | 단일 문장/기사 prompt | human preference pair (chosen vs rejected) |
| 사용 구간 | Prompt completion task | RLHF alignment task |
| 평가 지표 | log-PPL, AUC | Safety Score, AUC |
| 워터마킹 관련 역할 | 워터마크가 자연스러운 생성에서 잘 숨는지 평가 | alignment 도중에도 워터마크 학습 가능함을 입증 |
| 공격 적용 | paraphrasing/substitution 공격 실험 | 동일 공격 실험 진행 (Pegasus/DIPPER) |
📌 마무리 요약(연구 응용 관점)
- C4는 일반적인 텍스트 생성에서 워터마크의 "utility 유지"를 평가하는 베이스라인.
- PKU는 안전성이라는 또 다른 목적을 수행하면서도 "워터마크가 함께 학습될 수 있는지"를 검증.
- 두 데이터는 서로 보완적으로 사용되어 논문의 주장을 정량적으로 입증합니다:
“워터마킹을 RLHF의 alignment 과정과 자연스럽게 결합할 수 있다.”
필요하시면:
✅ C4/PKU 데이터를 직접 실험할 때 사용할 코드 샘플
✅ 워터마크 detector 학습용 데이터셋 구성 방법
✅ paraphrasing/substitution 공격 스크립트
까지도 만들어 드릴게요.