https://arxiv.org/abs/2310.12362
REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models
We present REMARK-LLM, a novel efficient, and robust watermarking framework designed for texts generated by large language models (LLMs). Synthesizing human-like content using LLMs necessitates vast computational resources and extensive datasets, encapsula
arxiv.org
기존 워터마킹은 rule-based에 쉽게 제거, inference time에 제약이 크며 의미를 왜곡할 수 있음
-> 의미, 유창성 손상 없이 더 많은 bit를 삽입하자. 공격에 강하고, LLM 종류나 도메인 변화에도 잘 작동하게 해보자
여기선 생성된 문서에 2차적인 모델을 써서 출력을 진행하네요

워터마킹의 작동 시나리오
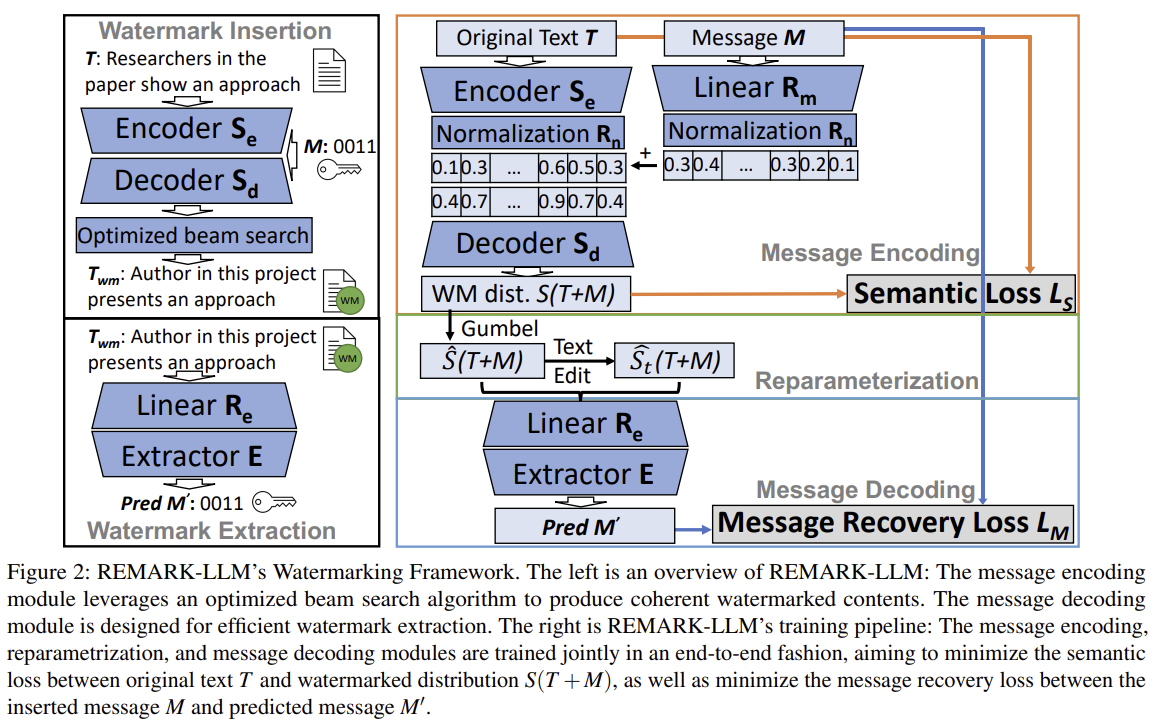
T5 Seq2Seq 로 텍스트 T와 워터마크 키M을 Latent space에서 결합하여 voca 확률 분포 생성
Gumbel softmax로 근사 분포 생성
디코더로 분포에서 메세지 M' 추출
HC3 - GPT가 생성한 QA 응답
ChatGPT Abstract - 논문의 Abstract를 GPT가 재작성
Human Abstract - 사람이 작성한 Abstract

WER - 워터마킹 추출률
WER이 높지만 BERT가 낮으면 의미를 보존하지 못한다는 것


| 문제 상황 | • LLM이 생성하는 텍스트는 고가치 IP이지만 스팸·표절·가짜뉴스 등 악용 위험 존재 • 문자열은 희소·취약하여 watermark 삽입이 어려움(토큰 수 제한, 작은 변화에도 의미 붕괴) • 기존 기법 한계: Rule-based(쉽게 제거), Inference-time(KGW: 의미 붕괴), Neural-based(AWT: 용량 낮음) |
| 연구 목표 | • 문장 의미를 유지하며 더 많은 비트를 삽입하고, 다양한 공격에 강건하며, LLM 종류와 도메인이 달라도 잘 동작하는 watermarking 프레임워크 개발 |
| 방법론 | 1) Message Encoding: T5 Seq2Seq 기반. 텍스트 T와 비트열 M을 latent space에서 결합해 vocab 확률 분포 S(T+M) 생성 2) Reparameterization: Gumbel-Softmax로 S(T+M)을 one-hot에 가까운 Ŝ로 변환 3) Message Decoding: Transformer decoder가 Ŝ에서 watermark M′을 복원 4) Optimized Beam Search: 단순 argmax 대신 의미·유창성·복원률 균형화하여 최종 문장 생성 |
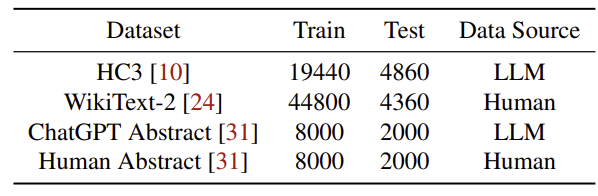
| 학습 데이터 | HC3 (LLM-generated): 19,440 train / 4,860 test (ChatGPT 응답) WikiText-2 (Human-written): 44,800 train / 4,360 test ChatGPT Abstract: 8,000 train / 2,000 test Human Abstract: 8,000 train / 2,000 test |
| 학습 방식 | • End-to-end joint training • Semantic Loss Lₛ: 원문 T와 S(T+M)의 cross-entropy • Message Recovery Loss Lₘ: M ↔ M′, M ↔ M′ₜ(LM), 공격 변형 포함 • 공격 변형 추가: deletion / insertion / replacement noise 주입 • 하이퍼파라미터: masking 50%, Gumbel τ=0.3, AdamW, LR=3e−5, epoch 300 |
| 평가 방식 | Effectiveness: WER (Watermark Extraction Rate) Fidelity: BERTScore(semantic), BLEU-4(coherence) Strength: z-score (<4 미만 실패, ≥4 강한 워터마크) Robustness: 공격 후 AUC (text deletion/addition/replace/rephrase/re-watermark) Efficiency: 시간·메모리 측정(삽입 overhead) Undetectability: ML classifier 검사(F1=0이면 탐지 불가) |
| 평가 데이터셋 | • In-distribution: HC3 test, WikiText-2 test • Cross-distribution: ChatGPT Abstract, Human Abstract • LLM-agnostic 평가: LLaMA-2, OPT, OpenOrca 생성 텍스트 (64bit 삽입 실험) |
| 주요 실험 결과 | 1) Segment-level (80 tokens) • 8-bit 삽입: REMARK-LLM WER 95%, AWT 74% • 16-bit 삽입: REMARK-LLM WER 73%, AWT는 실패 (50%) • KGW는 WER 높지만 의미 붕괴(BERT-S ≈ 0.6) 2) Long sequence (640 tokens) • 64bit 삽입: REMARK-LLM WER ≈95%, AWT는 68%로 하락 • KGW는 BLEU≈0, 의미 붕괴 심각 3) Watermark Strength • 평균 z-score = 7.12 (p=5.4×10⁻¹³) — 매우 강한 통계적 증거 • GPT-4 최대 길이(8k tokens) 기준 → z=25 이상 4) Robustness (ChatGPT Abstract 기준 AUC) • Deletion: 0.90• Addition: 0.90 • Replacement: 0.88 • Rephrase(T5): 0.85 (AWT=0.68로 크게 손실) • Re-watermarking: 0.74 (세 모델 중 가장 강함) 5) Undetectability • Transformer/BERT classifier 모두 Accuracy=50%, F1=0 → 탐지 불가 |
| 기여 | • 최초로 Seq2Seq latent-space watermarking 사용 • 의미·유창성 보존하면서 기존 AWT 대비 2× 많은 bit 삽입 능력 확보 • 공격 내재화 학습으로 deletion/replace/rephrase 등 강건성 향상 • Inference-time overhead가 작고 GPU 메모리 요구량 낮음 • LLM architecture-agnostic: OPT / LLaMA2 / OpenOrca 등 모두에서 높은 성능 유지 |
| 한계 | • BLEU 관점에서 원문과 완전히 동일한 문장 형태는 보장하지 않음(마스킹 기반 변화) • 도메인 특화 텍스트(법률/의학)에서 의미 보존 문제 가능성 존재 • 하이퍼파라미터(마스킹 비율, τ)에 민감 • 텍스트 외 modal(코드, 이미지)에는 아직 적용 불가 |
아래는 **REMARK-LLM 논문 전체를 체계적으로 정리한 ‘연구자용 전문 요약’**입니다.
문제 상황 → 방법론 → 학습 구조 → 실험 설정 → 결과 → 기여 → 한계까지,
논문을 다시 펼치지 않고도 실험에 바로 적용할 수 있도록 표 + 구조적 설명으로 정리했습니다.
(전체 내용은 업로드된 PDF 기반이며 반드시 참고문헌 없이 재구성했습니다.)
📌 REMARK-LLM: Robust & Efficient Watermarking Framework 요약
1. 논문 핵심 요약 (표)
아래 표 하나만 보면 논문 전체 흐름을 복기할 수 있도록 구성했습니다.
구분 내용| 문제 상황 | LLM이 생성하는 대규모 텍스트는 지식재산(IP) 가치가 크지만, 악용(스팸·표절·가짜뉴스) 위험이 큼. 기존 워터마킹은 ① rule-based: 쉽게 제거됨, ② inference-time: 의미 왜곡/강한 제약, ③ neural-based(AWT): capacity 낮음. |
| 목표 | 의미·유창성 손상 없이 더 많은 bit 삽입, 공격(삭제·치환·재워터마킹 등)에 강함, LLM 종류/도메인 변화에도 잘 동작하는 watermarking 생성 및 검증 모델 개발 |
| 전체 구조 | (1) Message Encoding Module – T5 Seq2Seq로 텍스트 T와 워터마크 M을 latent 공간에서 결합 → voca 확률 분포 S(T+M) 생성 (2) Reparameterization – Gumbel-Softmax로 one-hot 근사 분포 Ŝ 생성 (3) Message Decoding Module – Transformer 기반 decoder로 Ŝ에서 메시지 M′ 추출 |
| 학습 목표 | Semantic Loss: 원본 T와 watermark 분포 S(T+M)의 의미를 유지 Message Recovery Loss: 삽입 메시지 M과 추출 메시지 M′의 차이를 최소화 Malicious Transform Loss: 삭제·삽입·치환의 공격 입력 Ŝₜ에서도 M 복원 |
| 삽입 방식(추론) | 단순 argmax가 아닌 Optimized Beam Search로 ① 문장 일관성 유지 ② 메시지 추출률 최대화 |
| 평가 데이터 | HC3 (ChatGPT), WikiText-2 (Human), ChatGPT Abstract, Human Abstract 등 |
| 평가 지표 | WER(Extraction Rate), BERTScore, BLEU-4, z-score(워터마크 강도), 시간/메모리 효율, 공격 강건성(AUC), 탐지 불가성(F1≈0) |
| 주요 결과 | - 동일 길이 텍스트에서 AWT 대비 2× 긴 비트 삽입 가능 - 640 tokens에서 64bit 삽입 시도 → 평균 z-score = 7.12( 매우 강함 ) - 의미 보존(BERTScore ≈ 0.9 유지) 안정적 - 공격(삭제, 치환, 재워터마킹) 후에도 AUC 0.85 유지 - KGW보다 의미 보존이 월등하고, AWT보다 bit capacity 2배 높음 |
| 기여 | - 최초로 Seq2Seq 기반 latent watermarking 적용 - 최적화된 beam search로 유창성+추출률 동시 확보 - 공격을 학습 과정에서 포함하여 강건성 강화 - 다른 LLM(OpenOrca, LLaMA2 등)에서도 완전 이식 |
| 한계 | - 텍스트 삽입/치환이 눈에 뜨일 수 있음(경미하지만 스타일 변화 존재) - 매우 높은 BLEU(=원문과 거의 동일한 문장)를 요구하는 도메인에서는 부적합 가능 - Gumbel-Softmax 기반이므로 온도·마스킹 비율 등 하이퍼파라미터에 예민 |
2. 문제 상황 (세부 설명)
왜 워터마킹이 어려운가?
텍스트는 이미지·음성과 달리:
- Embedding 공간이 매우 희소(Sparse)
- GPT-4 최대 토큰 8.2k → 삽입 위치가 매우 제한적
- 미세한 변형도 의미를 훼손
- 단어 한 개만 바뀌어도 의미/문장 구조 망가짐
- 공격에 취약
- rephrase, synonym 교체, word deletion 등 NLP 공격으로 쉽게 제거 가능
기존 KGW(녹/적 토큰 제약 방식)는 강하지만 의미 왜곡이 심각,
반면 AWT는 의미는 잘 지키지만 capacity가 매우 낮아서 실용성이 떨어짐.
3. 방법론 (Step-by-Step 구조)
전체 그림은 **Figure 2 (p.5)**를 기반으로 한다.
STEP 1: Message Encoding Module
입력:
- LLM 생성 텍스트 T = {T₁, …, Tₙ}
- 워터마크 bit열 M
방식:
- T를 T5 Encoder(Se)로 latent vector Se(T)로 변환
- M을 Linear → Normalization을 거쳐 같은 공간으로 매핑
- T의 모든 token latent에 M을 더함
→ Se(T + M) 라는 watermarked latent representation - T5 Decoder(Sd)가 voca 확률 분포 S(T+M) 생성
- 이는 아직 실제 단어가 아니라 soft distribution
STEP 2: Reparameterization Module
문제:
- Encoding은 확률 분포 S
- Decoding은 one-hot token을 필요로 함
해결:
Gumbel-Softmax로 one-hot 근사 Ŝ 생성 (Equation 1)
- temperature τ ↓ → 더 one-hot에 가까움
- τ ↑ → diversity 증가
STEP 3: Message Decoding Module
- Ŝ → Linear(Re) → embedding H(T+M)
- Transformer decoder E가 watermark M′ 추출
- 공격 상황에서도 동일 M′를 추출하도록 학습
- 삭제(add), 삽입(drop), 치환(replace) noise를 Ŝ에 주입
4. 학습 Objective
(1) Semantic Loss Lₛ
원문 T와 watermarked distribution S(T+M)의 cross-entropy
→ 의미 변형 최소화
(2) Message Recovery Loss Lₘ
- M ↔ M′
- M ↔ M′ₜ(공격 버전)
(3) 최종 Loss
[
L = w_1 L_s + w_2 L_m
]
5. 추론(Inference) 시 워터마크 삽입 방식
단순 argmax로 단어를 뽑으면 문장이 깨짐 → 의미 유지 불가.
따라서 Algorithm 1: Optimized Beam Search (p.6) 사용:
- 다양한 temperature로 noisy 분포 생성
- beam size B로 여러 후보 문장 생성
- 각 후보에서 watermark extraction 정확도 a(E(Tᵢ), M)을 계산
- 의미/유창성/추출률을 균형화하여 가장 좋은 후보 선택
결과적으로:
- 문장 구조와 자연스러움을 유지하면서도
- 워터마크 복원률이 매우 높아짐
6. 실험 설정
데이터셋 (Table 2)
- HC3 (ChatGPT)
- ChatGPT Abstract
- WikiText-2 (Human)
- Human Abstract
평가지표
- WER: watermark extraction rate
- BERTScore: 의미 유사도
- BLEU-4: 문장 일관성
- z-score: 삽입 워터마크의 통계적 강도
- AUC: 공격 후 복원 강도
- 시간/메모리 효율
7. 주요 실험 결과
7.1 Segment-level (80 tokens)
(Table 3)
- 8-bit 삽입 시
REMARK-LLM WER ≈ 95%, AWT는 74% - 16-bit 삽입 시
REMARK-LLM WER ≈ 73%, AWT는 실패 (50%) - KGW는 99% WER이지만 BERTScore=0.62 → 의미 붕괴
7.2 Long sequence (640 tokens)
(Table 4)
- 64-bit 삽입 시
- REMARK-LLM WER 95%
- KGW는 의미 붕괴
- AWT WER는 68%로 크게 하락
- 전반적으로 REMARK-LLM이 가장 높은 fidelity + capacity 조합 달성
7.3 Watermark Strength (z-score)
(Figure 3)
- 평균 z-score = 7.12
→ p-value = 5.4×10⁻¹³ (매우 강한 증거) - GPT-4 최대 길이(8k tokens) 기준
→ z-score 25.2 (압도적으로 강함)
7.4 공격 강건성
(Figure 4)
공격 유형 REMARK-LLM AUC 특징| 삭제(Delete) | 0.90 | 의미 유지 & 높은 복원률 |
| 삽입(Add) | 0.90 | AWT 대비 +20%p 이상 유지 |
| 치환(Replace) | 0.88 | synonym 치환에도 견고 |
| Rephrase (T5-large) | 0.85 | AWT는 0.68까지 폭락 |
| Re-watermarking | 0.74 | 세 모델 중 가장 강함 |
7.5 탐지 불가성
(표 13)
- Transformer/BERT-large로 분류 시
→ Accuracy = 50%
→ F1 = 0
즉, 탐지 모델이 워터마크 여부를 전혀 구분 못함.
8. 기여 정리
- Seq2Seq latent 공간 결합 방식의 워터마크 삽입
- 최적화 beam search로 유창성 + 복원률 동시 확보
- 공격 내재화 학습으로 강력한 robust 특성
- LLM architecture agnostic (OPT, LLaMA2 등 모두 동작)
- capacity 2× 증가, AWT 대비 장기 텍스트에서 압도적 우위
- 탐지 어렵고(z-score↑, F1=0), 의미 보존(BERT-S≈0.9)
9. 한계 및 향후 연구
한계 이유| BLEU는 기존 AWT보다 낮아 문장 형태가 일정 부분 바뀜 | 마스킹 기반 학습으로 다양성은 높지만 문장 형태 보존은 상대적으로 떨어짐 |
| 도메인 특화 텍스트(법률/의학 등)에서는 의미 왜곡 위험 | 고유 용어 변경 시 semantic fidelity 문제 발생 가능 |
| 하이퍼파라미터 민감 | masking %, Gumbel τ가 성능에 직결 |
| 이미지·코드 등 multimodal에는 아직 적용 X | 텍스트 중심 방식 |
10. 요약 문장
"REMARK-LLM은 기존 AWT를 완전히 대체할 수 있을 만큼 높은 bit capacity·강한 robustness·우수한 의미 보존을 동시에 달성한 최초의 실용적 neural watermarking 프레임워크이다."
필요하시면 아래도 추가로 만들어드립니다:
✅ Figure 기반 시각적 해설
✅ 실험 재현용 코드 구조 가이드
✅ 당신의 워터마킹 연구(예: SynthID, RED-WM, EXP 등)와 비교 분석
✅ 한국어 발표 슬라이드용 요약자료
원하시는 방향이 있을까?
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Learning to Watermark LLM-generated Text via Reinforcement Learning (0) | 2025.11.23 |
|---|---|
| Watermarking Language Models through Language Models (0) | 2025.11.23 |
| Yet Another Watermark for Large Language Models (0) | 2025.11.23 |
| Scalable watermarking for identifying large language model outputs (0) | 2025.11.23 |
| Unsupervised Cross-lingual Representation Learning for Speech Recognition (0) | 2025.11.22 |