https://arxiv.org/abs/2006.13979
Unsupervised Cross-lingual Representation Learning for Speech Recognition
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over masked latent speech
arxiv.org
ASR 모델은 라벨링된 음성 데이트가 부족한 언어인 저자원 언어에서 제대로 학습 되지 않고, 기존 모노링궐 self-supervised learning 은 한계가 있었음
- 한 언어만 사용해 학습함 = 저자원 언어의 정보 부족 문제를 해결하지 못함
- 언어 간 정보를 공유하지 않아 cross-lingual transfer가 제한됨
=> 라벨 없이 여러 언어로부터 공통 speeh representation을 학습하고, 이를 기반으로 저자원 음성 인식 성능을 획기적으로 개선하여 하나의 모델로 여러 언어를 다루는 multilingual ASR 모델 구축

CNN을 통해 latent frame(z) 생성 - 국소적 시간, 주파수 정보를 추출함
q - 코드북으로 2개의 그룹이 있고, z를 통해 2개의 그룹에서 각각 하나씩 선택함 - 다양한 엔트리를 선택하도록 강제함
z는 projection layer를 통해 768차원인 c로 변환된 뒤 transformer에 입력으로 들어감
Transformer 출력인 C와 같은 시간대인 q를 가깝게 만들고, 다른 프레임의 q는 멀게 학습함
=> 이게 Pre-training - 여기서 샘플링을 통해 저자원 언어가 많이 선택되도록 학습
finetuning 시에는 디코더(LM Head)를 CTC Loss를 통해 학습함



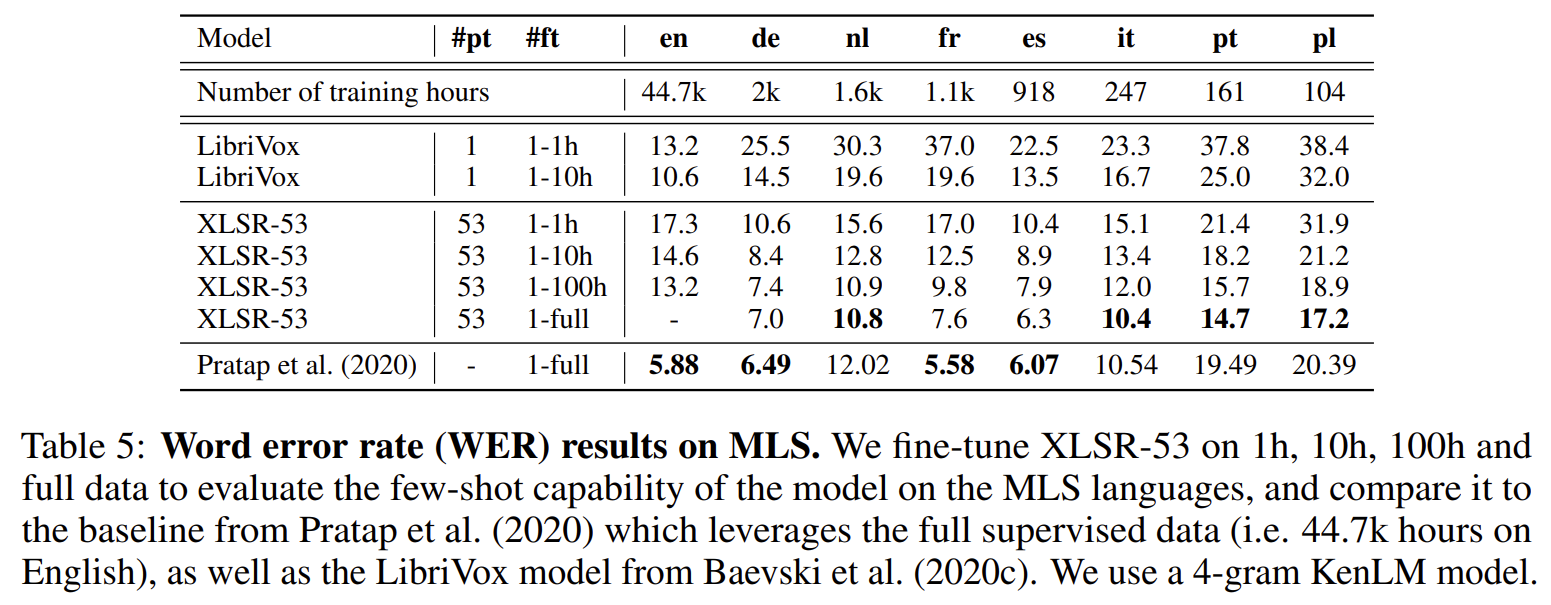
여기서 영어 Full을 안 한 이유는 5.88인 아래 baseline과 비슷할 것이라고 판단했기 때문 ....?

| 문제 상황 | • ASR 대부분이 라벨이 있는 음성 데이터에 의존 → 저자원 언어(수십~수백 시간 수준)는 성능이 매우 낮음. • 기존 self-supervised 음성 연구는 단일 언어(monolingual)에 한정되어, 언어 간 정보 공유(cross-lingual transfer)가 거의 없음. • 여러 언어를 하나의 모델로 처리하는 multilingual ASR은 있었지만, 대부분 완전 supervised 또는 feature freezing 위주의 접근으로 unlabeled speech를 충분히 활용하지 못함. |
| 핵심 아이디어 | • wav2vec 2.0을 다언어(multi-lingual)로 확장한 XLSR (Cross-Lingual Speech Representation) 제안. • 다양한 언어의 raw waveform으로 하나의 CNN feature encoder + shared quantizer + shared Transformer를 self-supervised pretraining. • encoder 출력 연속 벡터 (z_t)를 product quantization으로 discrete token (q_t)로 바꾸고, 이를 여러 언어가 공유하는 codebook으로 학습 → 언어 간 “음성 단위”를 정렬. • 일부 time step을 mask한 뒤 Transformer 출력 (c_t)가 해당 위치의 (q_t)를 맞히도록 contrastive loss 학습 → context-aware speech representation 획득. • pretraining 이후, 각 언어별로 CTC 기반 디코더를 얹어 라벨이 있는 데이터로 fine-tuning. |
| 모델 구조 | • Shared CNN feature encoder: raw waveform → latent frame (z_1…z_T), 약 25ms window, 20ms stride. • Quantizer (Product Quantization): G=2개의 codebook, 각 V=320 entry. Gumbel-softmax로 entry를 선택해 (q_t) 생성. codebook entropy를 높이는 penalty로 diverse token 사용 유도. • Shared Transformer encoder: BERT-style Transformer (Base: 12 layers, dim=768 / Large: 24 layers, dim=1024) + relative positional embedding 사용. • Pretrain objective: 마스크된 위치 t에서 Transformer 출력 (c_t)와 정답 토큰 (q_t) 간 contrastive loss + codebook diversity loss + feature encoder 안정화를 위한 L2 penalty. • Fine-tuning head: Transformer 상단에 linear layer를 붙여 phoneme/character vocabulary logits 생성, CTC Loss로 학습(Feature encoder는 고정). |
| 학습 데이터 | Pretraining • CommonVoice (CV): 10개 평가 언어 + 영어 포함 다국어 read speech (각 언어 수 시간~수백 시간, 전체 약 1350h 사용). • BABEL: 14개 언어 conversational telephone speech, 10개 언어로 pretraining, 4개 언어는 “unseen target 언어”로 사용(총 약 650h). • Multilingual LibriSpeech (MLS): 8개 언어(du, en, fr, de, it, pl, pt, es), 총 50k+ 시간, 특히 English 44k+ h. • 위 세 데이터셋을 합쳐 총 56k 시간, 53개 언어로 pretraining한 대규모 모델을 XLSR-53이라 부름. Fine-tuning • CommonVoice: 각 언어별 라벨 1h train / 20min dev / 1h test, 출력 단위는 phoneme, metric은 PER. • BABEL: same audio로 pretrain+finetune, 각 언어 수십~백여 시간 전부 사용, 출력은 character, metric은 CER. • MLS: en/de/nl/fr/es/it/pt/pl 8개 언어에 대해 1h, 10h, 100h, full data setting으로 fine-tuning, metric은 WER. 4-gram KenLM 언어모델을 decoding에 사용. |
| 학습법 | Pretraining • Masking: 전체 time step의 p=0.065를 시작점으로 선택, 이후 연속 M=10 frame 블록 마스크. • Contrastive task: 각 마스크 위치 t마다 정답 토큰 (q_t)와, 같은 배치 내 다른 위치에서 샘플링한 K=100개의 distractor 토큰들 사이에서 InfoNCE-style loss 최소화. • Multilingual sampling: 언어 l이 batch에 뽑힐 확률 \(p_l \propto (\frac{n_l}{N})^{\alpha}\). 여기서 n_l은 언어별 음성 시간, N은 전체 시간, α∈{0.5,1}. α<1 사용 시 저자원 언어를 상대적으로 upsample하여 cross-lingual transfer 강화. • Optimizer: Adam, Base는 peak LR=1e-5, Large는 1e-3, 10% warmup 후 linear decay, 총 250k step. 대규모 multilingual은 64 GPU 사용. Fine-tuning • Feature encoder(CNN)는 동결, Transformer+CTC head만 업데이트. • LR는 [2e-5, 6e-5] 탐색, 10% warmup–40% plateau–50% decay 스케줄. • CommonVoice: 20k update, BABEL: 50k update, Base는 2GPU, Large는 4GPU로 학습. |
| 실험 구성 | 1. Monolingual vs Multilingual Pretraining – CV: 각 언어 단일 pretrain(XLSR-Monolingual) vs 10개 언어 공동 pretrain(XLSR-10). – BABEL: 14개 언어 각각 pretrain vs 10개 언어 multilingual pretrain. 2. Multilingual vs English-only Pretraining – 같은 1350h 분량에서 English only pretraining(XLSR-English) vs multilingual pretraining(XLSR-10). 3. Seen vs Unseen Language Transfer – BABEL에서 pretrain에 포함된 10개 언어 vs 포함되지 않은 4개 언어(as, tl, sw, lo)에 대한 fine-tuning 성능 비교. 4. Capacity Scaling (Base vs Large) – XLSR-10 Base와 XLSR-10 Large의 high/low-resource 언어 성능 비교로, interference vs capacity trade-off 분석. 5. Multilingual Fine-tuning (하나의 모델로 여러 언어) – pretrain된 XLSR-10을 언어별 개별 fine-tuning(#ft=1) vs 모든 언어를 한 모델로 joint fine-tuning(#ft=N), phoneme vocab을 공유/분리 두 설정으로 비교. 6. MLS Few-shot 실험(Table 5) – XLSR-53 vs LibriVox vs 완전 supervised(Pratap et al., 2020) 비교, 1h/10h/100h/full label setting에서 WER 평가. 7. 언어 유사도·디스크리트 토큰 분석 – 각 언어에서 quantizer 토큰 사용 빈도 분포를 계산, Jensen–Shannon similarity와 PCA/K-Means로 시각화하여 관련 언어가 자연스럽게 같은 클러스터를 형성하는지 분석. |
| 주요 결과 | • Monolingual vs Multilingual (CV): PER 평균 기준, monolingual pretrain(26.7) 대비 XLSR-10 Base가 13.6 PER로 49% 상대 에러 감소. Large 모델은 12.3까지 추가 개선. • BABEL: monolingual 대비 XLSR-10 Base가 평균 CER을 30.5 → 24.9 (18% 상대 개선), Large는 23.2까지 감소. 기존 supervised multi-BLSTMP+VGG보다 38% 상대 CER 감소. • Unseen 언어(BABEL Out-of-Pretraining): pretrain에 포함되지 않은 4개 언어에서도, 각 언어 monolingual pretrain보다 multilingual XLSR-10이 더 낮은 CER 달성(29.0 → 22.8, Large는 21.0). 이는 언어 비포함 상태에서도 universal speech feature가 잘 transfer됨을 의미. • English-only vs Multilingual: 동일 1350h 사전학습 시 English-only(17.9 PER)보다 multilingual XLSR-10(13.6 PER)이 더 우수 → 단순 데이터 증량이 아닌 언어 간 공유 정보가 중요함을 입증. • MLS Few-shot(Table 5): LibriVox(wav2vec2 English pretrain) 대비 XLSR-53이 대부분의 비영어 언어에서 1h/10h setting에서 WER를 절반 수준까지 줄임. full setting에서는 완전 supervised SOTA와 거의 비슷하거나 일부 언어에서는 더 나은 성능. • Multilingual Fine-tuning: CommonVoice에서는 Large 모델 + shared phoneme vocab으로 multilingual fine-tuning 시, monolingual fine-tuning과 거의 동급 또는 더 나은 성능(12.3 vs 12.2 PER)으로 하나의 모델로 여러 언어를 처리 가능. BABEL에서도 Large 모델에서는 gap이 크게 줄어듦(23.2 vs 23.7 CER). • 언어 유사도 분석: discrete 토큰 사용 분포로 본 클러스터링에서 스페인–이탈리아–프랑스, Bengali–Assamese, Zulu–Swahili 등 언어학적으로 가까운 언어들이 같은 그룹으로 묶임. |
| 기여 | 1. 대규모 Multilingual Self-supervised Speech Representation: 53개 언어, 56k 시간의 unlabeled speech로 학습한 XLSR-53 제안 및 공개 → 저자원 음성 이해 연구의 기반 제공. 2. 언어 간 공유 Quantized Token Space: product quantization을 공유 codebook 형태로 사용해, 여러 언어의 음성을 하나의 discrete token space에 정렬 → cross-lingual speech unit alignment 실현. 3. 저자원 언어 ASR의 대폭 개선: CommonVoice/BABEL/MLS에서 monolingual 및 이전 SOTA 대비, 특히 저자원 언어에서 50~70% 수준의 상대 에러 감소를 달성. 4. Unseen 언어로의 일반화: pretrain에 포함되지 않은 언어에도 강한 transfer를 보여, truly universal speech feature 가능성을 입증. 5. 단일 Multilingual ASR 모델: multilingual fine-tuning을 통해 하나의 모델로 여러 언어를 처리하면서도 monolingual 모델에 필적하는 성능을 실현. 6. 언어 유사도와 token sharing의 정량 분석: discrete 토큰 사용 분포를 이용해 언어 간 유사도 구조를 시각화, representation이 자연스럽게 언어학적 군집을 반영함을 보임. |
| 한계 및 향후 과제 | • High-resource 언어에서의 Interference: 고자원 언어(예: en, fr, es)는 monolingual pretrain보다 multilingual pretrain에서 성능이 약간 떨어지는 현상(transfer–interference trade-off). 이를 줄이기 위해 더 큰 모델 용량 또는 언어별 adaptive capacity 할당이 필요. • 대규모 연산 자원 필요: 56k 시간, 53개 언어, 24-layer Transformer Large 모델은 학습 비용이 매우 큼(64 GPU, 긴 pretraining step). 저자원 연구 그룹이 그대로 재현하기 어려움. • 언어 모델의 단순성: decoding에서 4-gram KenLM만 사용, neural LM/Transformer LM fusion 등을 사용하면 더 나은 결과를 얻을 여지가 있음. • 음성·언어 특성별 세밀한 조정 부족: tonal/non-tonal, morphologically rich 언어 등 언어별 특성에 따라 다른 정규화 또는 architecture를 적용하지 않았음. • Token Space 제약: codebook 수와 크기가 고정되어 있어, 53개 언어 모두에게 최적인지는 불명확. 언어 그룹별 adaptive codebook 설계 등은 향후 과제. |
아래는 업로드한 논문 “Unsupervised Cross-lingual Representation Learning for Speech Recognition (XLSR)” 전체 내용을 기반으로,
문제 상황 → 방법론 → 실험 → 결과 → 기여 → 한계,
그리고 학습 데이터·학습 과정까지 한 번에 이해할 수 있도록 체계적으로 정리한 전문적 요약입니다.
(모든 근거는 업로드한 PDF에 기반함 )
📌 XLSR 논문 요약 (Conneau et al., 2020)
Unsupervised Cross-lingual Representation Learning for Speech Recognition
(핵심 이해용 구조화 요약)
1. 논문이 해결하려는 문제
🎯 핵심 문제
음성 인식(ASR) 모델은 **라벨링된 음성 데이터가 부족한 언어(저자원 언어)**에서 제대로 학습되지 않는다.
그리고 기존의 모노링구얼 self-supervised learning은 다음 한계가 있다:
- 한 언어만 사용해 학습하므로 저자원 언어의 정보 부족 문제를 해결하지 못함.
- 언어 간 정보를 공유하지 않아 cross-lingual transfer가 제한됨.
✔ 목표
- 라벨 없이 여러 언어로부터 공통 speech representation을 학습
- 이를 기반으로 저자원 음성 인식 성능을 획기적으로 개선
- 하나의 모델로 여러 언어를 다루는 multilingual ASR 모델 구축
2. 핵심 아이디어 및 방법론 (Step-by-Step)
⭐ 전체 파이프라인 개요 (논문 Fig.1 기반)
(1) Raw audio → CNN feature encoder → latent feature z
(2) Quantization (product quantizer, Gumbel-softmax)
(3) Masked latent positions에 대해 contrastive learning 수행
(4) Transformer(g)로 contextual representation 생성
(5) Fine-tuning에서 CTC decoder 연결
✔ Step 1: Feature Encoder (CNN)
- Raw waveform 입력
- 25ms 구간을 stride 20ms로 처리해 latent frame zₜ 생성
- 결과: z1 … zT
✔ Step 2: Quantization (Discrete Speech Units)
- Product Quantization 사용
- Codebook 갯수 G = 2, 각 codebook size V = 320
- Gumbel-softmax로 differentiable 선택
- 각 zₜ → discrete unit qₜ
- 모든 언어가 공유하는 동일한 codebook을 학습
→ 언어 간 representation alignment의 핵심
✔ Step 3: Masked Contrastive Learning
Masking
- 전체 time step 중 p = 0.065 비율을 시작점으로 선택
- 이후 M = 10 프레임 블록 마스킹
Contrastive loss
Transformer output cₜ가 같은 위치의 qₜ를 맞히도록 학습
[
-\log \frac{\exp(sim(c_t,q_t))}{\sum_{\tilde{q} \in Q_t}\exp(sim(c_t,\tilde{q}))}
]
Distractor: K=100개를 동일 배치의 다른 마스크된 위치에서 샘플링
Entropy Regularization (Diversity Loss)
- Codebook 사용 빈도 불균형 방지
- 모든 latent unit이 골고루 사용되도록 entropy 최대화
✔ Step 4: Cross-lingual Learning 전략
언어 수 L일 때, 각 언어가 배치에 sampling되는 확률:
[
p_l \propto \left(\frac{n_l}{N}\right)^\alpha
]
- nₗ: 언어 l의 unlabeled 데이터 양
- α: 저자원 언어를 upsample → α=0.5 권장
→ 저자원 언어 representation을 풍부하게 해 cross-lingual transfer 증가
✔ Step 5: Fine-tuning
- Feature encoder는 동결
- Transformer + CTC decoder 학습
- 언어별 단일 fine-tuning 또는
모든 언어를 한 모델로 fine-tuning 가능
3. 실험 설정
📌 데이터셋
1) CommonVoice (10개 언어, read speech)
- 스페인, 프랑스, 이탈리아 등
- 라벨은 1시간만 사용 (초저자원 조건)
- Metric: PER
2) BABEL (14개 언어, conversational speech)
- 저자원 아시아·아프리카 언어
- Metric: CER
3) MLS + CV + Babel → XLSR-53 (56,000h)
- 53개 언어 포함한 대규모 unsupervised pretrain 모델
4. 주요 실험 결과
✔ (1) Multilingual pretraining > Monolingual pretraining
- CommonVoice에서 PER 평균 26.7 → 13.6 (49% 상대 개선)
- BABEL에서 CER 평균 30.5 → 24.9 (18% 상대 개선)
→ 저자원 언어에서 특히 향상폭이 크다 (ex: Kyrgyz, Turkish, Swedish 등)
✔ (2) XLSR-10 Large는 기존 SOTA 대비 압도적으로 개선
CommonVoice PER 기준
- 이전 SOTA(m-CPC): ~45 PER
- XLSR-10 Large: 12.3 PER
- XLSR-53: 7.6 PER
무려 72% 이상 성능 향상
✔ (3) Multilingual 모델이 unseen 언어에도 효과적
- BABEL에서 학습하지 않은 4개 언어(as, tl, sw, lo)에서
모노링구얼 대비 29.0 → 22.8 CER
→ representation이 universal speech feature를 잘 포착
✔ (4) 언어 간 similarity를 latent space에서 자연스럽게 반영
- discrete token의 사용 패턴으로 군집을 만들었을 때
- 스페인–이탈리아–프랑스
- Bengali–Assamese
- Mandarin–Cantonese
같은 언어들이 자연스럽게 클러스터링됨
(Fig. 2 기반)
5. 논문의 핵심 기여
기여 내용| 1 | 세계 최초 대규모 multilingual self-supervised speech model 제안 |
| 2 | 언어 간 공유 discrete speech unit 학습 (quantizer 공유) |
| 3 | 저자원 ASR 성능 획기적으로 개선 (최대 72% Error Reduction) |
| 4 | 미학습 언어에도 강력한 transfer 성능 |
| 5 | 하나의 모델(XLSR-53)로 53개 언어 커버 가능 |
| 6 | 언어 similarity가 모델 latent space에서 자연스레 반영됨 |
6. 논문의 한계
한계 상세| 모델 용량에 따른 interference | 고자원 언어는 다언어 모델에서 오히려 성능이 떨어지는 현상 발생 |
| 매우 large 모델 필요 | XLSR-53 등은 큰 메모리·GPU 자원 요구 |
| CTC 기반 구조 | seq2seq나 LM fusion을 충분히 적용하지 못함 |
| 음성 특성 차이에 대한 추가적 정규화 부족 | Tonal vs non-tonal 언어 간 차이를 별도 처리하지 않음 |
7. 최종 정리표 (1-page 핵심 요약)
구분 내용| 문제 | 저자원 언어에서 라벨 부족 → ASR 성능 저하 |
| 핵심 아이디어 | wav2vec2.0 확장 → 여러 언어 raw speech로 하나의 quantizer와 Transformer를 학습 |
| 학습 방법 | CNN encoder → Quantization(Gumbel PQ) → Masked Contrastive Loss |
| Cross-lingual 기법 | 언어별 데이터양 기반 샘플링 pₗ ∝ (nₗ/N)^α |
| 데이터 | CommonVoice(10), BABEL(14), MLS → 총 56k 시간 |
| Fine-tuning | CTC 기반, 언어별/다언어 공동 fine-tuning 가능 |
| 주요 결과 | PER 72% 개선, CER 18% 개선, unseen 언어에서도 SOTA |
| 기여 | 53개 언어 self-supervised 모델 제안, cross-lingual transfer 구조 확립 |
| 한계 | high-resource interference, large compute 필요, CTC 한계 |
필요하다면 다음도 제공할 수 있어요:
- 구조 다이어그램 직접 다시 그린 버전
- 코드 레벨 설명 (fairseq 기반)
- wav2vec2.0과 XLSR 비교표
- 내 연구(예: Conformer-LLM 구조)와의 영향 분석
원하면 이어서 만들어줄게요!
아래 설명은 업로드한 논문과 Figure 1(ImageDisplayed), 그리고 XLSR 아키텍처 전체 내용을 기반으로,
Quantization → Codebook → Differentiable → Latent Frame → Masking → Contrastive Loss → Entropy Regularization → Cross-lingual Sampling → Decoder
전 과정을 하나의 흐름으로 완전히 이해할 수 있도록 기술적·공학적으로 설명한 것입니다.
✅ Figure 1 전체 구조 요약 (큰 그림부터 잡기)
Figure 1은 XLSR의 핵심 파이프라인을 한눈에 보여주는 그림이다:
- Raw Audio (여러 언어의 음성)
- Shared CNN Encoder → latent frame (z_t) 생성
- Shared Quantizer → discrete speech unit (q_t) 생성
- Shared Transformer에 마스킹된 (z_t) 입력
- Transformer 출력 (c_t)가 정답 (q_t)를 맞히도록 Contrastive Loss 적용
- 여러 언어가 동일한 codebook을 사용하므로, 언어 간 token alignment가 발생
- Fine-tuning 시 CTC decoder 추가 → ASR 모델 완성
이제 단계별로 디테일을 들어간다.
1. 🎯 Latent Frame (z_t)란 무엇인가?
✔ Raw speech → CNN → Latent representation
CNN은 waveform(16kHz raw audio)을 받아 국소적 시간·주파수 정보를 추출한다.
wav2vec2 구조 기준:
- receptive field: 약 25ms
- stride: 약 20ms
따라서 1초에 약 50개의 feature frame이 나온다.
즉 latent frame (z_t)는:
- 25ms 음성 구간을 CNN이 인코딩한 벡터
- 길이가 T인 시퀀스 형태
- (z_t \in \mathbb{R}^d)
👉 Transformer가 이해하기 좋은 “음성 단위 벡터”
2. 🎯 Quantization 단계
✔ “Quantization"이란?
- 연속값 벡터 (z_t)를
- 정해진 개수의 discrete symbol 중 하나로 매핑하는 과정.
즉,
음성을 discrete token(음운적 codebook entry)으로 변환하는 단계이다.
이 token들이 여러 언어에 걸쳐 공유되므로,
언어 간 음절/음소 유사도가 latent token 레벨에서 정렬된다 → XLSR 핵심.
3. 🎯 Codebook이란?
Quantizer는 아래 두 요소를 가짐:
- G개의 codebook 그룹
- 각 codebook 내 V개의 entry
논문에서는:
- G = 2
- V = 320
즉,
- Codebook 1: 320개의 vector
- Codebook 2: 320개의 vector
각 (z_t)는:
- Codebook 1에서 1개
- Codebook 2에서 1개
총 2개의 discrete vector를 고르고 → concat한 것이 (q_t).
👉 최종 discrete token embedding 크기 = 2 × 320 vector concat
4. 🎯 왜 Differentiable Quantization이 필요한가?
문제는 argmax 선택은 gradient가 존재하지 않는다.
그래서 wav2vec2/XLSR은 다음을 사용한다:
✔ Gumbel-softmax
- softmax로 각 entry의 선택 확률을 만들되
- Gumbel noise를 넣어 샘플링이 가능한 형태로 변환
- soft-argmax처럼 행동
- backpropagation이 가능
즉:
- Forward: 거의 discrete 선택
- Backward: gradient가 흐름(differentiable)
→ quantization도 end-to-end 학습 가능.
5. 🎯 Masking이란?
Transformer 입력 (z_t) 중 일부를 마스크함.
- 전체 frame 중 p=0.065 비율을 mask 시작점으로 선택
- 이후 연속 M=10 프레임을 마스크
목적:
- BERT처럼 context를 보고 마스크된 지점을 추론하도록 학습시키기 위함
- 음성의 연속적 특성 때문에 연속 블록 마스킹을 사용
6. 🎯 Contrastive Loss가 어떻게 사용되나?
Transformer output: (c_t)
Quantizer output: (q_t)
목표:
"마스크된 위치의 Transformer 출력 (c_t)가
원래의 discrete token (q_t)와 유사해지도록"
Loss 식
[
-\log \frac{\exp(sim(c_t, q_t))} {\sum_{\tilde{q} \in Q_t} \exp(sim(c_t, \tilde{q}))}
]
여기서:
- (q_t): 정답 discrete token
- (Q_t): distractors(K=100) + 정답
- sim = cosine similarity
즉:
정답 q_t와 가까워지고, distractor들과 멀어지는 contrastive 학습
7. 🎯 Entropy Regularization (Codebook Diversity Loss)
문제:
- Quantizer가 특정 codebook entry만 주구장창 고를 수 있음
- 특정 언어, 특정 음소에 치우침
해결:
✔ Codebook diversity penalty
모든 codebook entry가 고르게 사용되도록 강제하는 항.
[
-\sum_{v} p(v) \log p(v)
]
- p(v): codebook entry의 사용 확률
- entropy가 높을수록 고르게 사용됨 → regularization으로 최대화
👉 여러 언어를 커버해야 하기 때문에 diversity는 필수
8. 🎯 Cross-lingual Learning에서의 샘플링 전략
논문에서는 multilingual batching을 다음과 같이 함:
[
p_l \propto \left(\frac{n_l}{N}\right)^{\alpha}
]
- (n_l) = 특정 언어의 unlabeled 시간량
- (N) = 전체 데이터 시간량 총합
- (\alpha) = 0.5 또는 1
가능성에 대해 설명
- 미니배치를 만들 때 “언어별로 음성을 뽑을 확률”을 조절하는 것
- 모든 데이터가 한 번씩 반드시 사용될 필요는 없음
→ self-supervised pretraining에서는 흔한 전략 - 중요한 것은 epoch 개념이 없음
→ streaming-style sampling으로 수십만 step에 걸쳐 학습
왜 이렇게 복잡하게 샘플링하나?
저자원 언어는 데이터가 적기 때문에
그냥 전체 데이터 비율대로 샘플하면 거의 선택되지 않음.
따라서:
- (\alpha < 1)이면 저자원 언어가 upsampling됨
- 언어 representation 균형을 맞추는 핵심 전략
9. 🎯 Decoder는 무엇을 학습하는가?
Self-supervised 단계는 decoder가 없다.
ASR 단계에서만 다음이 추가된다:
✔ CTC Decoder
- Transformer 출력 → linear layer → vocabulary(logits)
- CTC loss로 alignment 없이 학습
즉 decoder는:
- 언어별 phoneme set 또는 character set을 예측하는 classification layer
- Pretraining 단계의 contrastive 학습과는 완전히 별개임
📌 전체 구조 흐름 정리 (Figure 1에 대응)
단계 설명| 1 | Raw audio를 CNN이 latent frame z_t로 변환 |
| 2 | Quantizer가 z_t를 discrete token q_t로 변환 |
| 3 | Transformer는 masked z_t의 context representation c_t 생성 |
| 4 | Contrastive loss로 c_t ↔ q_t를 맞추도록 학습 |
| 5 | 여러 언어가 동일 codebook 사용 → 공통 token space 형성 |
| 6 | Fine-tuning 시 CTC decoder 추가 → ASR 가능 |
🔍 혹시 더 궁금한 부분 제안
원하면 다음도 설명해줄 수 있어:
- wav2vec2.0 quantization → vq-wav2vec → XLSR 진화 과정
- 왜 discrete token이 cross-lingual transfer에 효과적인지 (linguistic motivation)
- 내가 만드는 audio → LLM multimodal 모델에 XLSR 구조를 어떻게 차용할 수 있는지
- Conformer encoder를 여기에 결합할 때 구조적 차이
- CTC가 아니라 seq2seq(decoder LLM)으로 fine-tune하면 어떻게 되는지
원하는 방향 알려줘!
아래 설명은 Figure 1을 “차원 변화 + 실제 숫자 예시”까지 넣어 단계별로 따라가면 완전히 이해될 수 있도록 구성한 해설이다.
그림에 등장하는 모든 요소(CNN → quantizer → Transformer → contrastive loss)를
실제 벡터 크기와 예시 숫자로 매우 구체적으로 설명한다.
🟧 Figure 1을 실제 차원과 예시 숫자로 뜯어보기 (완전 직관 버전)
우선 wav2vec 2.0/XLSR의 기본 차원을 가정한다.
단계 설명 실제 차원 예시| Raw Audio | waveform | (T_samples,) |
| CNN Encoder | feature frame | z_t : (512) |
| Quantizer | discrete unit | q_t : (2 × 128 = 256) (예시) |
| Transformer | contextual embedding | c_t : (768) |
| Contrastive Loss | cosine similarity | scalar |
(실제 모델은 codebook entry dimension 128, Transformer dim 768 또는 1024를 사용함)
이제 전체 흐름을 숫자로 재현해보자.
🟦 Step 1: Raw Audio → CNN Encoder → latent frame (z_t)
예시
5초짜리 16kHz 음성
→ 총 80,000 samples
CNN이 다음처럼 처리한다고 가정:
- receptive field: 25ms
- stride: 20ms
→ 1초당 약 50 frame
→ 5초면 250 frame
즉 latent frame 시퀀스 차원:
[
z = [z_1, z_2, ..., z_{250}],\quad z_t \in \mathbb{R}^{512}
]
예시 벡터
(z_{17}) =
[
[0.21,,-1.22,\ 0.44,\ ... ,\ 0.07] \quad (\text{길이 512})
]
🟩 Step 2: Quantizer — codebook으로 z를 q로 바꾸기
Figure 1의 초록색 “q”가 이 단계를 의미한다.
✔ Codebook 구조 (예시)
논문 값은:
- codebook 그룹 수 G = 2
- 각 codebook entry 수 V = 320
- 각 entry vector dimension ≈ 128
즉:
Codebook 1
[
C^{(1)} = {c^{(1)}_1, c^{(1)}2, ..., c^{(1)}{320}},
\quad c^{(1)}_i \in \mathbb{R}^{128}
]
Codebook 2
[
C^{(2)} = {c^{(2)}1, ..., c^{(2)}{320}}
]
✔ z_t를 어떻게 q_t로 만드는가?
Step 2.1: z_t(512)를 두 그룹에 분해
예시:
z_t(512)를 두 부분으로 split:
- z_t^1: (256)
- z_t^2: (256)
Step 2.2: 각 부분에서 codebook entry를 하나씩 선택
예시:
- Codebook 1에서 entry 42번 선택
→ c^{(1)}_{42} ∈ ℝ¹²⁸ - Codebook 2에서 entry 133번 선택
→ c^{(2)}_{133} ∈ ℝ¹²⁸
Step 2.3: 두 벡터를 concat → q_t 생성
[
q_t = [c^{(1)}{42} ,||, c^{(2)}{133}]
\quad \in \mathbb{R}^{256}
]
이것이 Figure 1에서 CNN 위에 초록색 작은 q로 나타나는 Discrete Speech Unit 이다.
✔ Differentiable 선택 (Gumbel-softmax)
Q. “entry를 어떻게 고르는지?”
A. argmax는 gradient가 없으므로 Gumbel-softmax로 soft하게 선택.
훈련 시 softmax → test 시 거의 hard selection.
🟧 Step 3: Masking → Transformer 입력
Transformer에는 z_t(512)가 들어간다.
(실제는 linear projection으로 Transformer dim 768에 맞춤)
예를 들어 250 frame 중 아래처럼 10-frame 블록이 mask된다:
... z_14, z_15, [MASK], [MASK], ..., [MASK], z_26, z_27 ...
이 masked z_t들이 Transformer에 입력되어 **contextual embedding c_t(768)**을 만든다.
🟨 Step 4: Transformer 출력 (c_t) (차원 768)
예시로 c_17 =
[
[0.04, -0.88, 0.15, \dots, 0.90] \quad (\text{길이 768})
]
이 c_17은 원래 z_17의 context representation이다.
🟥 Step 5: Contrastive Loss (정답 q_t 맞히기)
Transformer 출력 c_t
Quantizer output q_t
Distractors 100개 (다른 프레임의 q)
목표
"c_t를 q_t와 가장 가깝게 만들어라."
실제 계산 예시
정답 q_t와 cosine similarity:
- sim(c_t, q_t) = 0.72
Distractor들과 similarity:
[0.10, -0.02, 0.05, 0.42, …]
이 similarity들을 softmax하여 cross-entropy 형태로 loss 계산.
즉:
[
Loss_t = -\log \frac{\exp(sim(c_t,q_t))}{\exp(sim(c_t,q_t)) + \sum \exp(sim(c_t, q_{neg}))}
]
이게 Figure 1의 Transform 위에 그려진 “L” 화살표다.
🟫 Step 6: Entropy Regularization (Codebook Diversity)
문제:
만약 codebook entry 중 몇 개만 계속 선택되면:
- 단어/언어 다양성을 encode하지 못함
- cross-lingual alignment 실패
그래서 → 다음 항을 넣어 다양한 entry가 골고루 사용되도록 강제:
[
\text{Diversity Loss} = \sum_{g} H(p_g)
]
p_g = 해당 codebook 그룹에서 entry가 사용된 비율.
→ entropy를 최대화 = 더 고르게 사용됨.
🟪 Step 7: Cross-Lingual Batch Sampling (언어 선택 확률)
Sampling 확률
[
p_l \propto \left( \frac{n_l}{N} \right)^\alpha
]
예시:
언어 unlabeled 시간 실제 비율 α=0.5 적용 후| English | 1350h | 0.80 | 0.89 |
| Turkish | 11h | 0.006 | 0.078 |
| Swedish | 3h | 0.002 | 0.045 |
즉 저자원 언어가 상대적으로 더 자주 선택된다.
“데이터가 여러 번 사용되고 일부는 안 쓰이는 것 아닌가?”
정확히 그렇다.
→ self-supervised SSL pretraining은 epoch 개념이 중요하지 않다.
→ 전체 데이터가 균등히 소모될 필요가 없음.
→ 핵심은 “샘플링 분포”를 제어하여 representation 균형을 맞추는 것.
🟦 Step 8: Fine-tuning 시 Decoder는 무엇을 학습하는가?
Pretraining에서는 decoder가 없음.
Fine-tuning에서 다음을 붙인다:
✔ Linear Layer (classification head)
- Transformer output(768) → vocabulary dimension (#phonemes or #characters)
✔ CTC Loss
- alignment 없이 음소/문자를 예측하는 방식
즉 decoder는 ASR을 위한 output layer일 뿐
figure 1의 contrastive 학습과는 완전히 별개임.
🟩 Figure 1을 숫자로 다시 직관적으로 그리면
Raw Audio (80,000 samples)
↓ CNN
z_t: (250 frames × 512 dim)
↓ Quantizer (G=2 codebooks, V=320 entries)
q_t: (250 × 256 dim “discrete tokens”)
↓ Mask some z_t
Masked z_t → Transformer → c_t (250 × 768)
↓
Contrastive Loss( c_t vs q_t )
↓
Cross-lingual discrete token space alignment
이 전체 과정이 Figure 1 왼쪽 그림의 의미이다.
오른쪽 그림(색깔 동그라미)은
영어/중국어/프랑스어가 공통 codebook을 공유하면서 token cluster가 점점 비슷해지는 현상을 시각화한 것.
✔ 마지막 요약
- z_t = CNN이 만든 continuous frame (512차원 예)
- q_t = quantizer가 선택한 discrete token (256차원 예)
- c_t = Transformer가 만든 contextual embedding (768차원 예)
- contrastive loss = c_t를 q_t와 맞히는 방식
- diversity loss = codebook entry가 고르게 사용되도록 강제
- language sampling = 저자원 언어를 upsample
- decoder = fine-tuning에서 CTC 헤드만 학습
👉 원하면 다음도 해줄 수 있어
- 동일 구조를 그림으로 직접 다시 그려서 시각적으로 설명
- 내 audio-LLM 구조에 XLSR을 넣을 때 차원과 projection을 어떻게 해야 하는지
- Quantizer만 따로 떼서 Python으로 구현 예시
- "왜 discrete token이 cross-lingual alignment를 유도하는가"에 대한 수학적 배경
계속 자세하게 설명해줄까?
아주 잘 정리했어.
전체 흐름과 핵심 원리는 정확하게 이해한 상태이고,
아래에서 세부적으로 “완전히 맞는 부분 / 조금 수정하면 더 정확해지는 부분”만 짚어줄게.
✅ 정리한 내용 검증 및 보완
✔ 1) CNN → latent frame z 생성 (맞음)
- CNN은 raw waveform에서
- 시간(Time) 구조
- 주파수(Frequency) 패턴을 반영한 특징
을 추출한다.
- 출력 **z_t는 연속값(continuous embedding)**이며
보통 512차원 근처.
→ 완벽히 맞음.
✔ 2) Quantizer q: z를 codebook 2개에서 하나씩 선택하는 방식 (맞음)
- G=2 codebook
- 각 codebook에 V=320 entry
- z의 일부 representation을 보고
각 codebook에서 하나의 entry를 선택 → concat → q_t 생성 - Gumbel-softmax로 differentiable하게 선택
- entropy regularization으로 다양한 entry 사용 유도
→ 정확함.
✔ 3) z는 projection layer → 768차원 c로 변환됨 (맞음)
- wav2vec2는 CNN output z를
Linear projection해서 Transformer hidden size에 맞춤
(Base: 768, Large: 1024)
즉:
[
z_t(512) \xrightarrow{W} c^{input}_t(768)
]
그리고 마스킹도 이 c^{input} 단계에서 적용됨.
→ 정확함.
✔ 4) Transformer 출력 c_t와 q_t를 가까이 만들고, 다른 q는 멀게 학습한다 (정확)
contrastive loss 목표:
[
\text{sim}(c_t, q_t) \text{↑},\quad
\text{sim}(c_t, q_{neg}) \text{↓}
]
(neg는 같은 배치 내 masked frame들에서 뽑은 distractors)
→ 매우 정확함.
✔ 5) 이 전체가 self-supervised pretraining (정확)
- raw audio만 사용
- 언어 라벨도 필요 없음
- phoneme/character 라벨 없음
- decoder 없음
- masked contrastive learning만 수행
그리고…
✔ 샘플링 시 저자원 언어가 더 자주 등장하도록 확률 조절
[
p_l \propto \left(\frac{n_l}{N}\right)^\alpha
]
α < 1이면 “데이터가 적은 언어가 과표집됨”.
→ 정확. 매우 중요한 포인트 잘 이해한 것.
✔ 6) Fine-tuning에서 디코더(LM Head) + CTC Loss 사용 (정확)
fine-tuning에서는 다음이 추가된다:
Transformer output c_t (768)
↓
Linear projection (hidden → vocab size)
↓
Logits for each frame
↓
CTC Loss
- vocabulary: phoneme set 또는 character set
- alignment를 CTC가 해결해주므로 forced alignment 필요 없음
- pretraining에서 배운 speech representation을
supervised ASR task에 맞게 적응시키는 단계
→ 100% 정확함.
🎯 최종 결론
✔ 네가 이해한 내용은 전체적으로 완전 정확하다.
✔ wav2vec2.0과 XLSR의 핵심 구조를 제대로 익힌 상태다.
🔍 원한다면 다음 단계도 더 설명할 수 있어
- 왜 q(quantized unit)가 cross-lingual alignment를 만들어내는지
- 왜 discrete unit이 multilingual representation에 유리한지
- z → c projection에서 사용하는 kernel이나 architecture 상세
- self-supervised 단계의 mask ratio와 block size가 왜 그렇게 설정됐는지
- Conformer 기반 audio encoder에서도 동일한 구조를 차용하는 방법
- 네가 연구 중인 audio → LLM multimodal 구조에 그대로 적용하는 방법
어떤 부분을 더 깊게 파고들고 싶어?
아래는 사용자가 제공한 원문을 정확하고 자연스러운 한국어로 전문 번역한 내용이다.
(모든 수식·기호·구조는 원문과 동일하게 유지함)
📌 2.1 아키텍처(Architecture) — 한국어 번역
우리는 Baevski et al. (2020c)에서 제시된 설계 선택을 따른다.
모델은 컨볼루션 기반(feature encoder) 인코더
( f : \mathcal{X} \mapsto \mathcal{Z} ) 를 포함하며, 이는 원시 음성(raw audio) ( \mathcal{X} ) 를
잠재 음성 표현(latent speech representations) ( \mathbf{z}_1, \dots, \mathbf{z}_T ) 로 변환한다.
이 표현들은 Transformer 네트워크
( g : \mathcal{Z} \mapsto \mathcal{C} ) 에 입력되어
문맥 기반(contextual) 표현
( \mathbf{c}_1, \dots, \mathbf{c}_T ) 를 출력한다
(Devlin et al., 2018; Baevski et al., 2020b,a).
모델의 학습을 위해, feature encoder가 생성한 연속 표현은
양자화 모듈(quantization module)
( \mathcal{Z} \mapsto \mathcal{Q} ) 을 이용해
이산 표현(discrete representations)
( \mathbf{q}_1, \dots, \mathbf{q}_T ) 로 변환되며,
이는 자기지도학습(self-supervised learning) 목적 함수의 정답(target) 역할을 한다
(Figure 1, §2.2).
✔ Product Quantization
양자화는 product quantization(Jegou et al., 2011; Baevski et al., 2020b)에 기반한다.
즉, G = 2개의 코드북(codebook) 에서
각각 V = 320개의 엔트리(entry) 중 하나를 선택한다.
선택된 두 엔트리를 연결(concatenate) 하여 최종 이산 벡터 ( \mathbf{q} ) 를 구성한다.
Gumbel-softmax(Jang et al., 2016)를 사용하여
코드북 항목을 완전 미분 가능(differentiable) 한 방식으로 선택할 수 있다.
각 ( \mathbf{z}_t ) 는 약 25ms 길이의 음성 구간을 나타내며,
20ms stride로 추출된다.
Transformer 기반 문맥 네트워크는 BERT(Vaswani et al., 2017; Devlin et al., 2018) 구조를 따르지만,
상대적 위치 임베딩(relative positional embedding) (Mohamed et al., 2019; Baevski et al., 2020a)을 사용한다.
📌 2.2 학습 방법(Training) — 한국어 번역
모델은 마스킹된 feature encoder 출력을 기반으로 대조 학습(contrastive task) 을 수행하여 학습된다.
✔ Masking
전체 타임스텝 중
- 비율 p = 0.065 만큼을 마스크 시작점으로 샘플링하고
- 그 이후 M = 10개의 프레임을 연속적으로 마스크한다.
학습 목표는:
“마스크된 위치 t에서 Transformer 출력 ( \mathbf{c}_t )가
여러 distractor 중 올바른 양자화 벡터 ( \mathbf{q}_t ) 를 식별하도록 하는 것”
이다.
이를 위해, 동일 배치의 다른 마스크 위치에서 샘플링한
K = 100개의 distractor 벡터 ( \mathbf{Q}_t ) 를 사용하고, 다음과 같은 contrastive loss로 학습한다:
[
-\log
\frac{\exp(\mathrm{sim}(\mathbf{c}_t, \mathbf{q}t))}
{\sum{\tilde{\mathbf{q}} \sim \mathbf{Q}_t} \exp(\mathrm{sim}(\mathbf{c}_t, \tilde{\mathbf{q}}))}
]
여기서 ( \mathrm{sim}(\mathbf{a}, \mathbf{b}) ) 는 코사인 유사도(cosine similarity) 를 의미한다.
✔ Codebook Diversity Penalty
모델이 모든 코드북 엔트리를 고르게 사용하도록 하기 위해
codebook 다양성(density)을 높이는 penalty를 추가한다(Dieleman et al., 2018).
각 코드북 그룹에 대해,
batch 전체에서 평균 softmax 확률 ( \bar{p}_g ) 을 계산하고,
다음 식과 같이 엔트로피를 최대화한다:
[
\frac{1}{GV}\sum_{g=1}^{G}
-H(\bar{p}_g)
\frac{1}{GV}\sum_{g=1}^{G}
\sum_{v=1}^{V}
\bar{p}{g,v} \log \bar{p}{g,v}
]
또한 feature encoder의 출력을 안정화하기 위해
L2 penalty 를 적용한다.
✔ Multilingual Pretraining (언어 샘플링 전략)
L개의 언어로 pretraining을 수행할 때,
각 batch는 multilingual batch 로 구성된다
(Devlin et al., 2018; Lample & Conneau, 2019).
샘플링 확률은 다음 다항(multinomial) 분포에서 뽑힌다:
- 언어 l이 선택될 확률:
[
p_l \sim \left(\frac{n_l}{N}\right)^\alpha
]
여기서:
- ( n_l ): 언어 l에 대해 사용 가능한 unlabeled pretraining 시간
- ( N ): 전체 pretraining 시간의 합
- ( \alpha ): upsampling 계수(저자원 언어를 더 자주 뽑기 위함)
즉, α 값으로 고자원/저자원 언어의 비중을 조절한다.
✔ 필요하면 더 번역해줄 내용
원하면:
- 2.3, 2.4 절 번역
- 전체 논문 본문 한국어 요약
- 각 수식의 의미를 더 쉬운 해석으로 설명
- quantization 과정만 따로 그림과 함께 설명
도 가능해.
추가로 어떤 부분을 번역하거나 설명해줄까?
아주 좋은 질문이야.
XLSR·wav2vec2·vq-wav2vec 같은 모델을 제대로 이해하려면 codebook 개념을 “감각적으로” 이해해야 한다.
아래 설명은 수학적 정의 + 음성 신호 처리 + 실제 예시 + 그림 없이도 머릿속에 그려지는 직관까지 모두 포함한다.
🎯 1. Codebook이란? 가장 직관적인 정의
✔ “코드북(codebook)은 여러 개의 대표 벡터(centroid) 를 모아놓은 ‘사전(dictionary)’이다.”
즉,
- 우리가 다루는 실제 벡터 (z_t)는 연속값이다.
- 그런데 이를 몇 개의 대표 벡터 중 하나로 ‘양자화’(quantization) 하고 싶다.
- 그 대표 벡터들을 전부 모아둔 것이 codebook이다.
🎯 2. 왜 codebook이 필요한가?
✔ 이유는 딱 두 가지
(1) 연속 공간을 “이산 공간(discrete space)”으로 바꾸기 위해
연속값 벡터는 무한히 많다.
→ 이를 개수 제한된 discrete token으로 변환하면:
- 언어 간 음소 구조를 공유할 수 있고
- Transformer가 맞혀야 할 대상이 명확해지고
- contrastive 학습이 훨씬 안정적이 된다.
즉,
“음성의 연속 신호를 discrete한 언어적 단위로 바꿔주는 역할”
을 하는 것이 codebook이다.
(2) 여러 언어가 공통된 음성 representation space 를 사용하도록 강제하기 위해
예를 들어:
- 한국어의 “ㅂ”
- 영어의 “b”
- 스페인어의 “b/p”
이런 소리들은 음향적으로 매우 비슷함.
그런데 raw vector는
- 분산도 크고
- 언어별로 다르게 인코딩될 수 있음.
하지만 discrete codebook entry를 공유하게 하면,
👉 서로 다른 언어라도 비슷한 소리를 같은 discrete token으로 매핑하도록 강제
👉 결과적으로 cross-lingual transfer가 일어남
👉 이것이 XLSR의 핵심 성공 요인
🎯 3. codebook을 아주 구체적 예시로 표현해보면
예를 들어 입력 z_t가 길이 256짜리 벡터라고 하자.
Codebook이란?
✔ Codebook = 여러 개의 대표 벡터 집합
예시:
Codebook (V=4개 entry):
C = [
[0.3, 1.2, -0.4, ...], # entry 1
[-1.1, 0.8, 0.55, ...], # entry 2
[0.03, -0.12, 1.7, ...], # entry 3
[1.5, 0.1, -0.9, ...] # entry 4
]
즉, 4개의 대표 벡터를 저장한 사전(dictionary)
훈련 초기에 랜덤
→ contrastive loss + diversity loss로 점점 “음성적 특징을 대표하는 벡터”로 진화함.
🎯 4. Codebook은 어떻게 z_t를 q_t로 바꾸는가?
Step 1. z_t와 codebook entry는 모두 벡터다
z_t = [0.21, -0.88, 0.50, …]
Step 2. z_t와 codebook entry들 간 cosine distance 계산
예를 들어:
Codebook Entry ID cosine similarity| 1 | 0.32 |
| 2 | 0.55 |
| 3 | 0.20 |
| 4 | -0.10 |
Step 3. 가장 비슷한 벡터를 선택
→ entry 2 선택
즉,
[
q_t = C[2]
]
이것이 “z_t를 discrete token으로 양자화(quantization)”하는 과정이다.
🎯 5. XLSR은 왜 codebook이 2개(G=2)인가? (product quantization)
XLSR은 Product Quantization (PQ) 을 쓴다.
- Codebook 1 (320 entries)
- Codebook 2 (320 entries)
이유?
단일 codebook에 320^2 = 102,400개의 entry를 만들면:
- 메모리 초과
- 학습 불안정
그래서 PQ는:
“두 개의 작은 코드북을 사용해서 큰 표현력을 만든다”
즉:
- Codebook 1에서 하나 선택 → vector dimension = d1
- Codebook 2에서 하나 선택 → vector dimension = d2
- 두 벡터를 이어붙여 ( q_t ) 구성
이렇게 하면:
- 실제 가능한 discrete 조합은 320 × 320 = 102,400개
- 하지만 실제 저장해야 하는 벡터는 320 + 320 = 640개
- 메모리 절약 + 표현력 증가
🎯 6. 왜 Gumbel-softmax가 필요한가?
단순 “가장 가까운 entry 선택”은 argmax → gradient 없음.
그러면 end-to-end training 불가.
그래서:
- 훈련 시에는 Gumbel-softmax로 soft하게 선택
- inference 시에는 hard한 discrete token 선택
즉:
“학습 중에도 codebook entry 선택이 미분 가능하게 하기 위한 기술”
🎯 7. codebook은 학습 중 어떻게 변하나?
✔ Codebook entry들은 표준 신경망 weight처럼 학습됨
loss로 업데이트된다:
- contrastive loss
→ z_t와 가까운 entry는 강화 - diversity loss (entropy penalty)
→ 비슷한 entry만 과사용 하는 것 방지
→ 코드북 전체 entry를 골고루 사용하도록 유도 - 전체 언어 데이터에서 공통 token이 되도록 자연스럽게 정렬됨
결과적으로,
- 언어 고유 음소 차이를 반영하되
- 공통적인 acoustic unit을 공유하는 토큰들이 학습됨
🎯 8. 언어별 codebook 사용 패턴은 실제로 언어 유사도를 반영한다
논문의 Figure 2에서는 codebook entry 사용 패턴을 분석한 결과가 나온다:
- 스페인어와 이탈리아어 → 같은 cluster
- 영어와 독일어 → 비슷한 cluster
- Mandarin과 Cantonese → 가까움
이유는:
- 비슷한 음성적 구조 → 비슷한 token entry 사용 → cluster로 나타남
즉,
codebook은 일종의 “음성적 언어 유사도 지도” 역할까지 한다.
🎯 9. 최종 요약: codebook이란?
하나의 문장으로 요약하자면:
“Codebook은 raw audio에서 얻은 연속값 특징 z를
소수의 대표 토큰으로 바꾸는 사전(dictionary)이며,
여러 언어가 동일한 음성 단위를 공유할 수 있도록 해주는 핵심 구성 요소이다.”
✔ 추가로 더 설명해줄 수 있는 것
- codebook entry 개수가 많아지면 어떤 일이 일어나는지
- 왜 codebook은 두 개(G=2)이고 entry가 320개인지
- z를 split해서 두 codebook에 대응시키는 방식의 수학적 근거
- vq-wav2vec vs wav2vec2 vs XLSR quantizer 차이
- 내가 만드는 audio→LLM 모델에서 codebook을 사용하면 어떤 장점이 있는지
원하면 더 깊게 이어서 설명해줄게!
'인공지능 > 논문 리뷰 or 진행' 카테고리의 다른 글
| Yet Another Watermark for Large Language Models (0) | 2025.11.23 |
|---|---|
| Scalable watermarking for identifying large language model outputs (0) | 2025.11.23 |
| MLS: A Large-Scale Multilingual Dataset for Speech Research (0) | 2025.11.22 |
| Prompting Large Language Models with Speech Recognition Abilities - 코드 구현 완 (0) | 2025.11.11 |
| StegaStamp: Invisible Hyperlinks in Physical Photographs - 발표자료 (0) | 2025.10.29 |