https://arxiv.org/abs/2307.11795
Prompting Large Language Models with Speech Recognition Abilities
Large language models have proven themselves highly flexible, able to solve a wide range of generative tasks, such as abstractive summarization and open-ended question answering. In this paper we extend the capabilities of LLMs by directly attaching a smal
arxiv.org
LLM의 발전으로 다양한 Task에서 두각을 보이고 있음 -> 오디오 인코더를 통해 LLM이 음성 인식을 수행하도록 기능 확장
코드 구현
Prompting Large Language Models with Speech Recognition Abilities - Code 구현
https://github.com/MyoungJinKim/AAA737_TermProject GitHub - MyoungJinKim/AAA737_TermProject: Prompting Large Language Models with Speech Recognition Abilities 논문 코드 재현Prompting Large Language Models with Speech Recognition Abilities 논문 코
yoonschallenge.tistory.com
intro
기존 LLM은 텍스트만 받기에 텍스트로 포착하기 어려운 정보를 받을 수 없음
최근 연구는 LLM에 다른 양식(오디오, 사진)을 처리할 수 있는 기능을 통해 LLM 확장
ex) PaLM-E : 비전 인코더
비전 인코더 + LLM 조합이 많이 생김
LTU - 오디오 인코더를 통해 LLaMA에 입력을 줘서 소리를 추론 및 이해할 수 있으나 음성 이해 및 인식 능력이 제한적
다양한 방법 중에 LLM 전체를 학습하는 방법도 있는데 Cost가 너무 많이 든다.
어뎁터도 추가하지만 이 것도 inference cost가 증가함
=> LoRA를 통해 이런 문제를 해결
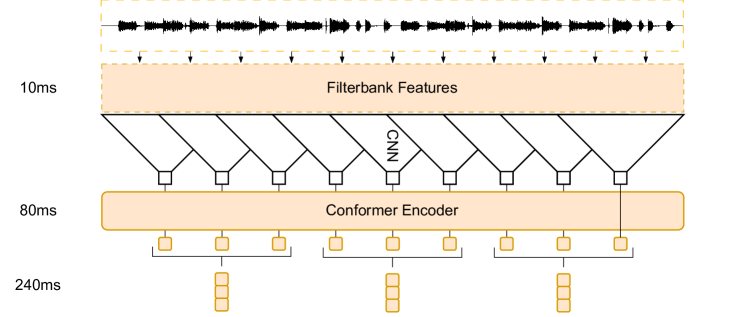
Figure 1 - 청각적인 Feature 추출
처음엔 CTC 학습을 통해 오디오가 유용한 인코더를 추출할 수 있도록 학습
출력 시퀸스가 길어질 수 있으므로 연속적인 임베딩을 쌓아 길이를 줄 일 수 있음
저 뒤에 스택은 최대 960ms까지 쌓아서 인코딩 임베딩을 줄일 수 있음
| 단계 | 시간 단위 | 주요 역할 |
| Raw Audio | 10ms | 파형 입력 |
| Filterbank | 10ms | 주파수 특성 추출 |
| CNN | 80ms | 로컬(음소) 특징 압축 |
| Conformer | 80ms | 장기 문맥 모델링 (Transformer + Conv) |
| Frame Stack | 240ms | 긴 문맥 윈도우로 결합 |
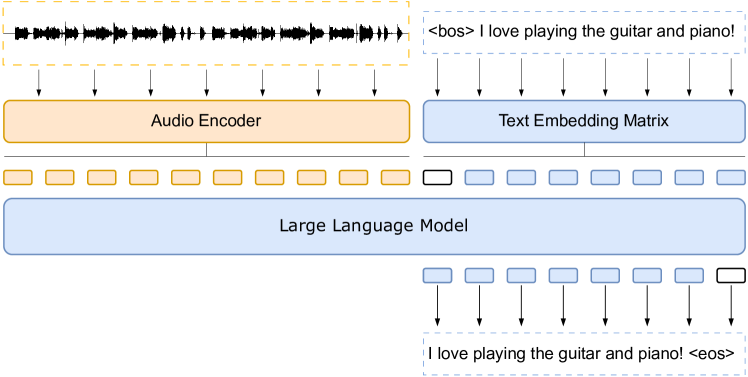
Figure 2
LLM의 다른 파라미터를 고정하고, LoRA만 학습하거나, 학습 X
실험
오디오 북 읽은 데이터인 MLS ARS 코퍼스 활용 - 각 발화는 최대 20초 길이
오디오 = 10ms 프레임을 8개의 stride를 가지는 CNN으로 512차원으로 추출 및 conformer 블록으로 연산
각 블록은 512차원, 피드포워드는 2048차원
CTC 학습할 땐 1547의 Vocab 사이즈를 가짐
이 conformer는 7200만개 (72M)의 파라미터를 가지고, 지도 학습을 통해 모델 훈련하여 Representation을 가짐
이를 쌓아서 512 * n 차원을 가지고 이를 Projection 하여 4096차원의 임베딩으로 만들어 LLM에 입력

80ms에서 가장 좋은 성능을 보이고, 스택을 많이 쌓아도 강한 성능을 보이는 것을 볼 수 있다.
여기선 Rank = 8과 알파 16이 사용됨
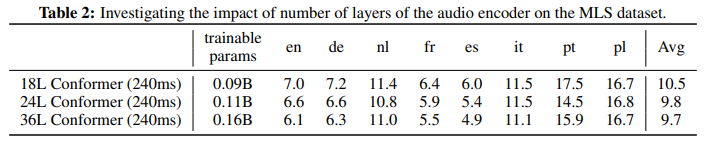
Ablation 연구로 Layer가 깊어질수록 높은 성능을 보이는 것을 알 수 있지만 학습 파라미터와 inference 시간이 조금 증가한다.
오디오 인코더의 중요성을 보여준다.

Lora Lank의 차원을 늘려가며 학습할 수 있는 파라미터를 늘렸을 때 더 좋은 성능을 보이는 것을 알 수 있다. BUT 학습 비용이 커진다.

여기선 노이즈 토큰을 통해 적젏한 수주느이 노이즈가 성능 개선에 도움이 될 수 있음을 보여줌
언어 데이터가 부족한 폴란드나 포루투갈 언어에 부적절한 영향을 줌 -> 추후 연구가 필요함
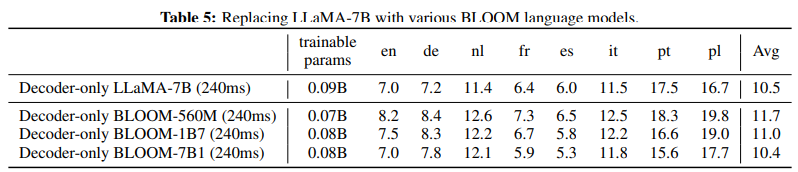
다양한 언어 모델에도 동일하게 학습을 진행해봄
7B 사이즈인 라마(주로 영어로만 학습 됨)와 블룸이 비슷한 것을 보고 다국어로 학습된 블룸의 영향이 크지 않은 것을 볼 수 있음
=> 오디오 인코더가 이미 각 언어의 정보를 충분히 공급해주기 때문에 LLM 내부의 언어 분포 차이는 상쇄된다.
모델 사이즈가 커지면 성능도 늘어나긴 함
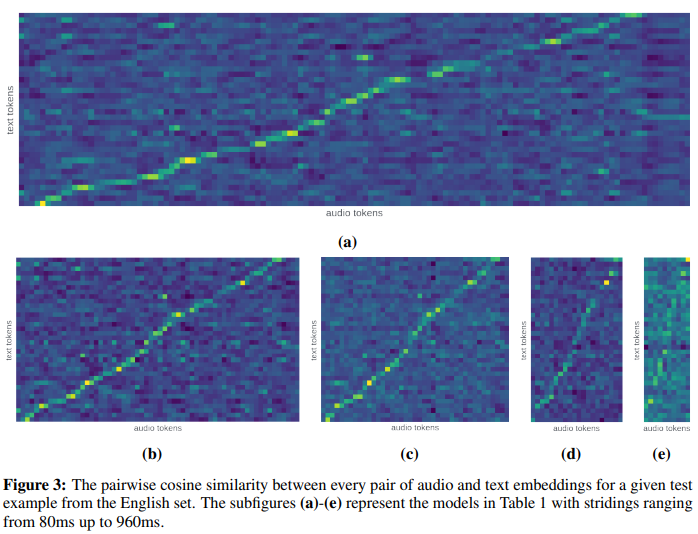
생성된 text 토큰의 임베딩과 embedding 된 audio 임베딩이 유사도가 높다
=> 오디오 임베딩과 생성된 텍스트 임베딩이 정렬되어 있음
그런데 오디오 토큰의 Stride가 점 차 늘어나서 임베딩 토큰 하나의 정보가 늘어날 수록 정렬이 어려워져 선이 흐릿해짐을 알 수 있음
= 큰 스트라이드 일 수록 한 벡터에 여러 단어가 섞여있어 정확한 매칭이 어려움
Conformer 인코더는 텍스트와 유사한 의미 공간으로 임베딩을 만들고, LLM은 그 위에 오디오 시퀸스를 순차적으로 복기하듯 텍스트로 바꾸고 있음
| 문제 상황 | 기존 ASR(Automatic Speech Recognition)은 전용 구조(CTC, Transducer, seq2seq)에 의존하여, LLM이 가진 강력한 언어 이해·생성 능력을 직접 활용하지 못함. → LLM이 오디오 입력을 직접 받아 텍스트를 생성하도록 할 수 있을까? → 오디오+LLM 융합 시, 전체 파라미터를 학습하지 않고도 동작할 수 있는가? |
| 핵심 아이디어 / 방법론 | ① Conformer 오디오 인코더로 오디오를 시계열 임베딩(80ms 단위, 512-d)으로 변환 ② CTC 손실로 사전학습(pretraining) 하여 음성과 텍스트 간 정렬 구조 학습 ③ CTC 분류기(Linear+Softmax) 제거 후 중간 Representation만 사용 ④ 여러 프레임을 stack(예: 3×80ms=240ms) 하여 시퀀스 길이 단축 + 풍부한 문맥 포함 ⑤ LLM(LLaMA-7B 등)에 오디오 임베딩 시퀀스를 텍스트 임베딩 앞에 그대로 붙여(prepend) 입력 ⑥ LLM은 NTP(Next Token Prediction) 으로 다음 텍스트를 예측 (즉, “음성→텍스트 번역”) ⑦ LLM은 동결(frozen) 또는 LoRA(Q,K,V,O)로만 조정 (파라미터 효율적 튜닝) ⑧텍스트 입력의 25%를 <unk>로 마스킹하여 모델이 오디오 정보에 더 의존하도록 학습 |
| 모델 구조 | Conformer(18~36L, hidden=512) + Linear proj. → LLaMA-7B decoder-only LLM LoRA rank R ∈ {0, 8, 16, 32} 적용 (attention Q,K,V,O에 한정) |
| 학습 데이터 | MLS (Multilingual LibriSpeech) — 50k 시간, 8개 언어 (en, de, nl, fr, es, it, pt, pl) 영어 44.5k h, 폴란드어·포르투갈어 저자원(≈100~160h) 발화 길이 ≤ 20초, 저자원 언어는 oversampling |
| 학습 설정 | - Conformer Pretraining: CTC loss, SentencePiece vocab=1547, Adam(β1=0.9, β2=0.98), peak lr=1e−3, warmup 20k, exp decay 16×A100 40GB, batch≈500초 오디오 - Joint LLM Training: peak lr=5e−4 → 5e−6, warmup 5k, 약 100k step 내 조기종료 64×A100 40GB, batch≈80초 오디오 - Loss: NTP(Next Token Prediction) only, no auxiliary loss - Decoding: Greedy decoding (beam/LM 없음) |
| 실험 | - 프레임율(Stride): 80,160,240,480,960ms 비교 - Conformer 깊이: 18L,24L,36L 비교 - LoRA rank: 0(동결),8,16,32 비교 - 텍스트 마스킹 비율 F: 0~0.5 비교 - LLM 종류: LLaMA-7B vs BLOOM-7B |
| 주요 결과 | - 80ms stride: 평균 WER 9.7%, monolingual CTC보다 18% 상대 향상 - 240ms stride + 36L: 9.7% (80ms 성능과 동일, 더 효율적) - LoRA rank 효과: R=0(10.9%) → R=32(9.5%) - LLM 동결만으로도 합리적 성능, LoRA로 추가 개선 - Mask F=0.25 → 약 5~6% 상대 개선, F>0.4는 저자원 언어에 악영향 - 고 stride(480/960ms)도 monolingual 모델에 근접 → 롱폼 오디오 가능성 |
| 기여 | ✅ LLM을 ASR로 확장할 수 있음을 실험적으로 입증 — “오디오 임베딩을 텍스트 앞에 붙이는 것만으로” 동작 ✅ Parameter-efficient multimodal adaptation: LoRA만으로도 다국어 ASR 달성 ✅ 브리지 모듈 제거: 단순한 임베딩 정합으로 LLM 멀티모달화 실현 ✅ 롱폼 오디오 처리 가능성 제시 (큰 stride에서도 안정적) ✅ 정렬 성질(오디오↔텍스트) 분석 → 단조 정렬(monotonic alignment) 확인 |
| 한계 | ⚠️ 도메인 일반화 한계: MLS(오디오북) 중심, 대화체·잡음 환경 미검증 ⚠️ 정렬 손실 미사용: explicit alignment loss 없이 implicit 정렬만 학습 ⚠️ 외부 LM/beam search 미활용: 실제 응용 대비 성능 최적화 여지 ⚠️ 단일 과업 한정: 음성→텍스트 외 다중과업(감정/화자/LID)은 미포함 |
| 핵심 결론 | - LLM은 오디오 임베딩을 프롬프트처럼 해석할 수 있으며, 별도 브리지 없이 다국어 ASR 수행 가능 - CTC로 정렬 사전학습된 Conformer가 핵심: 이 representation이 LLM의 언어 공간과 자연스레 연결됨 - LoRA(Q,K,V,O)만으로도 LLM의 attention 구조를 적응시켜 성능 향상 - 단순하지만 강력한 구조로, ASR→멀티모달 LLM으로의 확장 가능성을 제시 |
다음 논문을 업로드한 것으로 보고, 핵심만 빠르게 파악·적용할 수 있도록 요점을 정리했습니다.
개요 (한 줄 요약)
Conformer 오디오 인코더가 만든 가변 길이 오디오 임베딩을 LLM의 텍스트 임베딩 앞에 그대로 붙여(prepending) 디코더-온리 LLM(주로 LLaMA-7B)으로 다국어 ASR을 수행하며, 소수 파라미터(LoRA)만 조정해도 MLS에서 단일 언어 CTC 베이스라인을 평균 18% WER로 능가한다는 실증 연구.
방법
- 오디오 인코더: 18~36L Conformer(≈72–160M)로 10 ms Fbank→유효 stride 8, CTC 사전학습. 출력(80 ms 프레임, 512-d)을 n개 스택(예: n=1,2,3,6,12 → 80~960 ms)하여 512n-d → **LLM hidden(4096-d)**로 선형 사상.
- LLM 결합: “오디오 임베딩 시퀀스 ⊕ 텍스트 임베딩 시퀀스”를 그대로 LLM 입력으로 투입, 다음 토큰 예측으로 학습. LLM은 동결하거나 **LoRA(Q,K,V,O)**만 학습(R∈{0,8,16,32}).
- 마스킹: 텍스트 토큰의 일부(F∈[0,0.5])를 <unk>로 치환해 오디오 조건부 복원 압력을 높임(최적 F≈0.25).
주요 결과 (MLS, 그리디 디코딩, 외부 LM 미사용)
- 프레임율(스트라이드): 80 ms가 최고(Avg WER 9.7%). 160/240/480/960 ms로 늘려도 경쟁력 유지(긴 오디오 처리 잠재력).
- LoRA 랭크: R=0(LLM 완전 동결)도 **10.9%**로 준수. R을 8→16→32로 늘리면 **최대 9.5%**까지 하락(개선).
- 오디오 인코더 크기: 18L(240 ms)→24L→36L로 키우면 10.5%→9.8%→9.7%(성능 ↑). 큰 인코더 + 느린 프레임율이 작은 인코더 + 빠른 프레임율에 근접.
- LLM 종류: LLaMA-7B vs BLOOM-7B1 유사. 다국어 코퍼스 사전학습 이점은, 음성 다국어 학습을 거치면 상쇄되는 경향.
- 텍스트 마스킹: F=0.25에서 ~5–6% 상대 개선(저자 평균 기준). 과도하면 저자원 언어(pt/pl) 악화.
- 정렬 분석: 오디오-텍스트 코사인 유사도 히트맵이 단조 정렬 경향을 보임(스트라이드 커질수록 정렬 난이도 ↑).
기여와 포인트
- 최소 침습 멀티모달화: 복잡한 브리지 모듈 없이 임베딩 전처리(스택+프로젝션)만으로 LLM을 ASR로 전환.
- 파라미터 효율: LLM 동결 또는 LoRA로 원래 텍스트 능력 보존 가능성과 학습 비용 절감을 함께 제시.
- 롱폼 오디오 경로: 960 ms 등 거친 시계열 샘플링에서도 합리적 성능 → 긴 컨텍스트 음성 적용 여지.
- 정렬 성질 증거: LLM이 “번역/복기(regurgitation)” 과업으로 오디오-텍스트 매핑을 학습한다는 실험적 시사점.
한계 및 개선 아이디어
- 외부 LM/빔서치 부재: 단순 그리디 디코딩만 보고 → 실제 제품 수준 최적화(lexicon/LM) 미포함.
- 감정/화행 정보 미활용: ASR 중심. 패러랠 태스크(화자/감정/언어 식별) 다중목표 학습 여지.
- 정렬 감독 부재: 정렬은 간접 학습. CTC/OT/Monotonic Alignment Loss로 직접 감독하면 스트라이드↑에서도 견고성↑ 가능.
- 데이터 구성: MLS(오디오북) 편향. 대화체/소음/실사용 도메인 일반화는 후속 과제.
실전 적용 체크리스트 (연구/엔지니어링)
- 파이프라인 스켈레톤
- Conformer-CTC 사전학습 → 최종 선형층 제거.
- 80 ms 프레임 시퀀스 n-스택(권장: 2~6) → 512n→4096 프로젝션.
- [AUDIO_EMBS] ⊕ [<bos> text tokens]를 LLM 디코더에 투입, NTP 손실.
- **LoRA(Q,K,V,O)**만 활성(초기 R=16 권장), 텍스트 마스킹 F≈0.25.
- 디코딩: 우선 그리디로 재현, 이후 빔/외부 LM 추가 실험.
- 권장 하이퍼파라미터(시작점)
- LLM: LLaMA-7B 동결 + LoRA R=16(α=16).
- 인코더: 24L 이상, 커널 11, d_model=512, 8 heads.
- 스택: 240 ms(3-스택) 또는 160 ms(2-스택)부터 탐색.
- LR 스케줄: 인코더 1e-3 peak(워밍업 20k), 합동학습 5e-4→5e-6(워밍업 5k, 100k 이내 조기종료).
- 마스킹: F=0.25, 저자원 언어엔 F↓.
- 평가/분석
- 언어별 WER와 스트라이드×R 그리드를 표준화.
- 정렬 히트맵(오디오-텍스트 코사인)으로 실패 케이스 파악 → 정렬 손실 도입 여부 결정.
후속 연구 제안 (사용자 연구 맥락에 맞춤)
- Alignment-aware 학습: NTP + CTC/CTC-alignment/Monotonic Chunkwise 보조 손실을 인코더 투출에 부여.
- 멀티태스크: ASR + 언어 식별(LID) / 화자 임베딩 공동 학습으로 도메인 강건성↑.
- 롱컨텍스트: 480–960 ms 스트라이드 + Chunked-Attention/Sliding KV-Cache로 1h급 오디오 실험.
- Instruction-ASR: 프롬프트에 스타일·구두점·요약 지시를 넣어 “ASR→정규화/요약”까지 원-패스.
- 안전·가드 통합: Code/Guard 연구 경험을 살려 스트리밍 가드-스코어러를 디코딩 루프에 삽입(토큰 단위 필터링).
필요하면 위 파이프라인을 실험 스크립트/컨피그 형태로 바로 뽑아드리겠습니다(데이터 경로·GPU 수에 맞춰).
좋은 질문입니다. 이 세 가지는 음성-언어 모델 연구의 핵심 구성요소이므로, 각각을 직관적 예시와 함께 정리하겠습니다.
🎧 1. Conformer란?
**Conformer(Convolution-augmented Transformer)**는
**음성 신호를 인식(ASR)**하기 위한 Transformer + CNN 하이브리드 인코더입니다.
| Self-Attention (Transformer) | 장기 의존 관계(긴 문장, 문맥) 학습 |
| Convolution Block (CNN) | 지역적 패턴(음소, 발음 등 짧은 특징) 학습 |
즉, 음성의 시간적 연속성과 국소 패턴을 동시에 잡기 위해
Transformer의 글로벌 문맥 이해력 + CNN의 로컬 감도를 결합한 구조입니다.
- 대표식 구조:
- Input Mel-Spectrogram → Conformer Layers → Hidden sequence (feature frames)
- Whisper, SpeechT5, Google’s Universal Speech Model 등도 Conformer 계열을 사용합니다.
🗣️ 2. ASR (Automatic Speech Recognition)
ASR = 음성을 자동으로 텍스트로 변환하는 기술입니다.
예를 들어, 사람이 “안녕하세요”라고 말하면 ASR 시스템은 ["안녕하세요"]라는 텍스트를 출력합니다.
일반 파이프라인은 다음과 같습니다:
Audio waveform → Acoustic Encoder (Conformer) → Text Decoder (CTC / LLM)
이 논문에서는 마지막 디코더를 **CTC가 아니라 LLM(LLaMA)**으로 대체하여
“음성→언어 모델로 직접 텍스트 생성”하도록 학습합니다.
즉, Conformer + LLM = 음성 입력을 직접 텍스트로 디코딩하는 end-to-end ASR이 됩니다.
⚙️ 3. LoRA(Q,K,V,O)란?
LoRA(Low-Rank Adaptation)는
기존 모델의 가중치를 거의 건드리지 않고 추가 모듈만 학습하는 파인튜닝 기법입니다.
LLM에서는 주로 Attention 레이어 내부의 선형 변환에 적용됩니다.
(1) Attention의 기본 구조
Self-Attention은 다음 네 가지 선형 변환으로 구성됩니다:
- Q (Query)
- K (Key)
- V (Value)
- O (Output projection)
각각은 Wq, Wk, Wv, Wo 라는 거대한 행렬로 표현됩니다.
(2) LoRA(Q,K,V,O)의 의미
LoRA를 이 네 개 모두에 적용한다는 뜻입니다.
즉, LoRA가 Q,K,V,O 각각에 대해 작은 저랭크 보조행렬을 추가해 미세조정합니다.
수식적으로는 이렇게 됩니다:
[
W_q' = W_q + \Delta W_q,\quad \Delta W_q = A_q B_q^T, \quad \text{(rank } r \ll d)
]
마찬가지로 ( W_k, W_v, W_o )에도 각각 LoRA 모듈을 붙입니다.
- 장점:
- 전체 파라미터의 1~2%만 학습 → GPU 메모리 절감
- LLM 본체는 동결 → 원래 언어능력 유지
- 오디오 입력에 맞는 “attention 조정력”만 학습 가능
- 예시:
- “LoRA(Q,K)”만 쓰면, 입력 패턴을 인식하는 부분만 조정
- “LoRA(Q,K,V,O)”는 입력→출력까지 전 Attention 전체를 적응화
🔍 요약 비교표
개념 역할 핵심 포인트| Conformer | 음성 특성 추출용 인코더 | Transformer + CNN → 장단기 의존 결합 |
| ASR | 음성을 텍스트로 변환 | Conformer + (CTC 또는 LLM) |
| LoRA(Q,K,V,O) | LLM 파라미터 효율 파인튜닝 | Attention 4요소(Q,K,V,O)에 LoRA 적용 |
원하신다면, 이 구조를 기반으로
“Conformer + LLaMA(LoRA Q,K,V,O)”를 실제로 결합하는 PyTorch 코드 골격도 만들어드릴 수 있습니다.
그걸 원하시나요?
정확히 이해하셨습니다 ✅
이 그림이 바로 Conformer 기반 음성 인코더 구조를 시각적으로 보여주는 것입니다.
조금 더 체계적으로 설명드리면 다음과 같습니다.
🧠 전체 구조의 단계적 해석
(1) Raw Audio (Waveform, 10ms window)
- 입력은 시간 도메인의 파형(signal)입니다.
- 이를 10ms 단위로 쪼개어 짧은 구간(feature frame)을 만듭니다.
즉, “10ms마다 한 번씩 특징을 계산”.
(2) Filterbank Features (Spectrogram)
- 각 10ms 프레임에서 주파수 스펙트럼(=Mel-filterbank feature)을 추출합니다.
→ 사람의 청각 특성을 반영한 80차원 정도의 벡터가 됩니다. - 결과적으로 시간 × 주파수의 2D feature map이 생성됩니다.
(이게 음성의 “이미지” 역할을 합니다.)
(3) CNN (Convolution Block)
- Conformer 내부의 첫 모듈로,
짧은 구간(음소, 발음 단위)의 지역 패턴을 학습합니다. - 음성 신호는 연속적이고 지역 상관성이 강하므로,
CNN이 로컬한 구조(예: 자음·모음 조합, 발성 패턴)를 잘 포착합니다. - 여러 층의 CNN이 적용되면서 **stride(간격)**가 커집니다.
예를 들어 그림처럼 10ms → 80ms로 압축됩니다.
⇒ 즉, “8개 프레임을 합쳐서 하나의 더 풍부한 특징”을 만듭니다.
(4) Conformer Encoder
- CNN이 만든 80ms 단위의 feature sequence를 입력받아,
Transformer의 Self-Attention으로 더 긴 문맥을 모델링합니다. - 이 Conformer 블록은 다음을 동시에 수행합니다:
- Convolution module: 지역 정보(음절·단어 내부의 구조)
- Self-Attention module: 장기 의존 관계(문장 전체 흐름)
- 결과적으로, 짧은 시간 구조 + 긴 문맥 정보를 모두 포함한 feature를 생성합니다.
(5) Frame Stacking (240ms 등)
- 마지막 단계에서 여러 개의 Conformer 출력을 **concat(결합)**하여
더 긴 시간 단위(예: 3개의 80ms → 240ms context)를 하나의 벡터로 묶습니다.
이렇게 하면 LLM이 처리해야 할 토큰 수를 줄이면서도
충분히 긴 오디오 정보를 한 벡터에 담을 수 있습니다.[80ms vec_1, vec_2, vec_3] → concat → [240ms vec] - 예를 들어:
🔍 정리
단계 시간 단위 주요 역할| Raw Audio | 10ms | 파형 입력 |
| Filterbank | 10ms | 주파수 특성 추출 |
| CNN | 80ms | 로컬(음소) 특징 압축 |
| Conformer | 80ms | 장기 문맥 모델링 (Transformer + Conv) |
| Frame Stack | 240ms | 긴 문맥 윈도우로 결합 |
즉, 당신의 설명은 완전히 정확합니다 👏
“시간 단위로 들어오는 오디오 특성상 CNN을 통해 국소적 특징을 잡아내고, Transformer를 통해 구간을 잡아서 전체적인 특성을 잘 잡은 feature를 뽑아내는 것”
맞습니다.
그리고 “그 뒤에 concat을 진행하는 것”도 바로 Frame Stacking (Temporal Concatenation) 단계입니다.
원하신다면,
이 구조를 PyTorch로 표현한 Conformer-based Audio Encoder → Embedding Stack → LLM 입력 연결 코드 골격도 바로 보여드릴 수 있습니다.
그걸 보시겠습니까?
정확합니다 ✅
ASR (Automatic Speech Recognition) = 우리가 흔히 말하는 STT (Speech-to-Text) 와 같은 개념입니다.
💬 차이점 정리하자면:
용어 풀네임 의미 쓰임새| ASR | Automatic Speech Recognition | 음성 신호를 자동으로 인식해 텍스트로 변환하는 기술 전반 | 연구·논문, 시스템 구조 설명에 사용 |
| STT | Speech-to-Text | "음성 → 문자" 변환이라는 기능적 표현 | 제품·서비스 이름에서 주로 사용 (예: Google STT API) |
즉,
- “STT는 기능 이름”이고
- “ASR은 기술 이름”입니다.
둘 다 본질적으로 **같은 과정(음성 → 텍스트 변환)**을 말합니다.
예시로 보면 다음과 같습니다:
입력 처리 출력| 🎤 “오늘 날씨 어때?” | ASR/STT 모델 (Conformer + LLM) | “오늘 날씨 어때?” |
요약하자면
ASR = STT (Speech-to-Text)
다만, ASR은 연구 용어, STT는 서비스 용어로 더 자주 쓰입니다.
좋습니다. 업로드하신 논문이 제안한 ASR-LLM 결합 방법론을 핵심만, 단계별로 정확하게 정리합니다.
방법론 한눈에 보기
아이디어: 오디오 인코더가 만든 오디오 임베딩 시퀀스를 텍스트 임베딩 앞에 그대로 이어 붙여(prepend) 디코더-온리 LLM에 넣고, **다음 토큰 예측(NTP)**만으로 음성→텍스트 생성을 학습한다. LLM은 동결하거나 LoRA로 주의(attention) 가중치(Q,K,V,O)를 저랭크로만 조정한다.
1) 오디오 인코더(Conformer) → 프레임 스택 → LLM 차원 정합
- 입력: 10 ms 간격의 80-차 Mel filterbank. 초기에 CNN 특성 추출부로 유효 stride 8(10 ms→80 ms)로 압축. 이후 선형층으로 512-차로 정규화, 뒤이어 **Conformer 블록(예: 18L)**을 통과해 80 ms 간격의 임베딩 시퀀스를 생성.
- CTC로 선학습(오디오 전사 감독) 후, LLM 결합 단계에서는 CTC 헤드를 제거하고 출력 프레임을 여러 개 묶어(concat) 더 긴 맥락(예: 3×80 ms=240 ms)으로 스택한다. 마지막에 LLM 히든 차원으로 프로젝션하여 입력 호환성을 맞춘다(그림 1).
요약 수식
[
\mathbf{H}^{(80\text{ms})}\in\mathbb{R}^{T\times 512}\ \xrightarrow{\text{stack}}\
\mathbf{H}^{(240\text{ms})}\in\mathbb{R}^{\lfloor T/3\rfloor \times (3\cdot512)}
\xrightarrow{\text{Proj}}\
\tilde{\mathbf{H}}\in\mathbb{R}^{\lfloor T/3\rfloor \times d_\text{LLM}}
]
(스택 팩터 3의 예)
2) 오디오+텍스트 시퀀스 결합과 목표함수
- 결합: ([ \tilde{\mathbf{H}}_{\text{audio}} ] \oplus [\text{text embeddings}]) 를 만들어 디코더-온리 LLM에 그대로 투입한다(그림 2). 별도의 복잡한 브리지 모듈이 없다.
- 학습 목표: 표준 다음 토큰 예측(NTP). 즉, LLM이 오디오로부터 조건부로 텍스트를 “복기(regurgitation)”하듯 생성하도록 학습한다. 저자들은 이 과업을 **복사/번역(copying/translation)**으로 해석할 수 있다고 본다.
3) LLM 파라미터화: 동결 vs LoRA(Q,K,V,O)
- 기본 설정은 LLM 동결, 혹은 **주의(Attention) 선형변환(Q,K,V,O)**에만 LoRA를 적용해 파라미터 효율적으로 적응시킨다. 저랭크 랭크 (R\in{0,8,16,32}) 를 조사.
- 결과적으로 **R=0(완전 동결)**도 평균 **WER 10.9%**로 합리적이며, **R을 늘릴수록 개선(R=32 → 9.5%)**됨을 보였다(240 ms 조건). 이는 전체 미세조정보다 저비용으로 충분한 적응이 가능함을 시사.
4) 텍스트 마스킹(입력 증강)
- 학습 시 입력 텍스트의 일정 비율 (F\in[0,0.5])을 <unk> 로 무작위 치환해, 모델이 오디오 신호에 더 의존하게 만든다.
- F=0.25에서 평균 WER ~5.7% 상대 개선을 달성했으나, 과도한 마스킹은 저자원 언어(pt, pl)에 불리했다.
5) 스트라이드·인코더 크기·LLM 종류에 대한 설계 선택(및 근거)
- 프레임율(스트라이드): 80 ms가 최선이지만, 480/960 ms처럼 매우 거친 샘플링도 단일언어 CTC 베이스라인과 경쟁할 만큼 유지되어 롱폼 오디오에 유리한 경로를 제시.
- 인코더 크기: 36L Conformer(240 ms)가 **평균 9.7%**로 성능↑. 큰 인코더+느린 프레임율이 작은 인코더+빠른 프레임율을 상당 부분 대체.
- LLM 종류/튜닝: LLaMA를 동결하고 오디오 인코더만 학습해도 10.9%. LoRA 랭크를 키우면 추가 개선. LLM 전체 튜닝은 더 나은 성능 여지가 있으나 비용 대비 효용 고려 필요.
6) 정렬(Alignment) 분석: 왜 이게 작동하는가?
- 오디오 임베딩과 정답 텍스트 임베딩 간 코사인 유사도 히트맵을 보면 단조(monotonic) 정렬 경향이 나타난다. 스트라이드가 커질수록 정렬이 어려워지며, 정렬 손실을 직접 부여하는 미래 연구의 필요성을 제기.
7) 데이터·학습·디코딩 세부
- 데이터: MLS 50k h(8개 언어, 영어 다수·저자원 언어 포함). n-gram LM 미사용. 저자원 언어는 오버샘플링. 각 발화 ≤20 s.
- 학습: 오디오 인코더는 80-d FBANK@10 ms, CNN stride 8→512-차로 투영, 18L Conformer(hidden 512, FFN 2048, conv kernel size 등) 세부 구성을 명시. 이후 LLM과 합동학습(동결/LoRA)으로 NTP.
- 디코딩: 보고된 수치는 그리디(외부 LM·빔서치 없음).
8) 메커니즘 관점 요약(설계 합리성)
- CTC 선학습 인코더로 발화의 음운·단어 단서가 압축된 의미공간 임베딩을 만든다.
- 이를 텍스트 임베딩 앞에 그대로 붙이면, LLM은 “이미 절반 정답이 들어온” 조건 하에 NTP로 복기-번역을 수행한다.
- **LoRA(Q,K,V,O)**로 주의 모듈만 소규모 적응 → 메모리/비용 절감과 원래 LLM 능력 보존 사이의 균형.
9) 실전 재현 체크리스트(요약)
- 오디오 인코더: FBANK@10 ms → CNN stride 8 → 512-d → Conformer L(≥18) → 프레임 스택(예:×3=240 ms) → LLM 차원 프로젝션.
- LLM 입력: ([ \text{audio} ] \oplus [ \text{text} ]), NTP 학습. LLM 동결 또는 LoRA(Q,K,V,O; R∈{8,16,32}).
- 증강: 텍스트 마스킹 (F≈0.25) 권장(저자원 언어는 완만하게).
- 디코딩: 우선 그리디로 재현, 필요 시 빔/외부 LM 추가.
필요하시면 위 절차를 그대로 실행하는 **PyTorch 템플릿(Conformer 인코더→스택→프로젝션→LLaMA+LoRA 학습 루프)**을 만들어 드리겠습니다.
좋은 이해입니다 — 논문에서도 바로 그 과정을 다루고 있습니다. 정리하면 다음과 같습니다.
🔹 1. Conformer를 CTC로 선학습(pretrain) 하는 이유
- 논문에서는 오디오 인코더(Conformer)를 처음부터 LLM과 함께 학습하지 않고, 먼저 단독으로 CTC(Connectionist Temporal Classification) 손실로 학습시킵니다.
- 이유는 단순합니다: LLM에 넣기 전에 Conformer가 음성과 텍스트 간의 기본적인 정렬(alignment) 을 먼저 익히도록 하는 것입니다.
즉,
"이 소리 구간은 'hello'의 'he'에 해당한다"
"이 다음 구간은 'llo'다"
이런 식의 프레임-토큰 정렬 구조를 CTC로 미리 학습시켜 두는 것입니다.
이 과정을 통해 Conformer는 이미 각 오디오 프레임이 문자열 토큰과 시간적으로 어느 정도 일치하는 특징 공간을 형성하게 됩니다.
🔹 2. “CTC 헤드를 제거한다”는 의미
CTC 학습에는 마지막에 선형 분류기(Linear layer) 가 붙어 있습니다.
이 층은 각 시간 프레임마다 "이건 어떤 글자(혹은 단어)일까?"를 직접 예측합니다.
논문에서는 이렇게 명시합니다:
“A final linear layer is used to pretrain the audio encoder using a CTC loss with a SentencePiece vocabulary … The final linear layer is discarded after pretraining.”
즉,
- CTC 학습 시:
- Conformer → Linear(512→vocab_size) → Softmax → CTC Loss
- LLM 결합 시:
- Conformer → (CTC head 제거) → Hidden representation (512-d)
이 CTC head(선형 + softmax) 를 제거하면 이제 오디오는 단어 분류 결과가 아니라,
그 중간의 연속적 표현(feature embedding) 만 남습니다.
이 임베딩 시퀀스가 “오디오 의미 표현(semantic acoustic representation)” 역할을 하며,
LLM이 그걸 받아서 다음 토큰을 예측할 수 있게 됩니다.
🔹 3. 요약하면 이런 흐름입니다
단계 구성 설명| ① Conformer 선학습 | Conformer + Linear(CTC) | 오디오→글자 정렬 학습 |
| ② CTC head 제거 | Linear 제거 | “글자 분류기” 대신 중간 표현만 남김 |
| ③ Feature 전달 | Conformer hidden(512-d) | 시간 축 따라 feature 시퀀스 추출 |
| ④ Frame stacking + projection | n개 프레임 concat 후 LLM hidden 차원(4096)으로 투영 | LLM 입력 차원 정합 |
| ⑤ LLM 입력 | [오디오 임베딩] ⊕ [텍스트 임베딩] | LLM이 NTP로 텍스트 생성 학습 |
🔹 4. 직관적 비유
- CTC 단계: Conformer가 "이 소리는 ‘가’ 소리, 이건 ‘나’ 소리" 정도를 배우는 단계
- CTC head 제거 후: "소리를 의미 공간에서 표현할 줄 아는 귀"만 남음
- LLM 연결: 이제 그 “귀”가 들은 임베딩을 LLM이 해석해서 문장으로 말하는 것
즉, CTC는 Conformer가 들을 줄 알게 만드는 훈련용 임시 학습기이고,
그걸 끝내면 “말귀를 알아듣는 청각 피질”만 남겨서 LLM에 연결한다고 보면 됩니다.
좋은 이해입니다 — 논문에서도 바로 그 과정을 다루고 있습니다. 정리하면 다음과 같습니다.
🔹 1. Conformer를 CTC로 선학습(pretrain) 하는 이유
- 논문에서는 오디오 인코더(Conformer)를 처음부터 LLM과 함께 학습하지 않고, 먼저 단독으로 CTC(Connectionist Temporal Classification) 손실로 학습시킵니다.
- 이유는 단순합니다: LLM에 넣기 전에 Conformer가 음성과 텍스트 간의 기본적인 정렬(alignment) 을 먼저 익히도록 하는 것입니다.
즉,
"이 소리 구간은 'hello'의 'he'에 해당한다"
"이 다음 구간은 'llo'다"
이런 식의 프레임-토큰 정렬 구조를 CTC로 미리 학습시켜 두는 것입니다.
이 과정을 통해 Conformer는 이미 각 오디오 프레임이 문자열 토큰과 시간적으로 어느 정도 일치하는 특징 공간을 형성하게 됩니다.
🔹 2. “CTC 헤드를 제거한다”는 의미
CTC 학습에는 마지막에 선형 분류기(Linear layer) 가 붙어 있습니다.
이 층은 각 시간 프레임마다 "이건 어떤 글자(혹은 단어)일까?"를 직접 예측합니다.
논문에서는 이렇게 명시합니다:
“A final linear layer is used to pretrain the audio encoder using a CTC loss with a SentencePiece vocabulary … The final linear layer is discarded after pretraining.”
즉,
- CTC 학습 시:
- Conformer → Linear(512→vocab_size) → Softmax → CTC Loss
- LLM 결합 시:
- Conformer → (CTC head 제거) → Hidden representation (512-d)
이 CTC head(선형 + softmax) 를 제거하면 이제 오디오는 단어 분류 결과가 아니라,
그 중간의 연속적 표현(feature embedding) 만 남습니다.
이 임베딩 시퀀스가 “오디오 의미 표현(semantic acoustic representation)” 역할을 하며,
LLM이 그걸 받아서 다음 토큰을 예측할 수 있게 됩니다.
🔹 3. 요약하면 이런 흐름입니다
단계 구성 설명| ① Conformer 선학습 | Conformer + Linear(CTC) | 오디오→글자 정렬 학습 |
| ② CTC head 제거 | Linear 제거 | “글자 분류기” 대신 중간 표현만 남김 |
| ③ Feature 전달 | Conformer hidden(512-d) | 시간 축 따라 feature 시퀀스 추출 |
| ④ Frame stacking + projection | n개 프레임 concat 후 LLM hidden 차원(4096)으로 투영 | LLM 입력 차원 정합 |
| ⑤ LLM 입력 | [오디오 임베딩] ⊕ [텍스트 임베딩] | LLM이 NTP로 텍스트 생성 학습 |
🔹 4. 직관적 비유
- CTC 단계: Conformer가 "이 소리는 ‘가’ 소리, 이건 ‘나’ 소리" 정도를 배우는 단계
- CTC head 제거 후: "소리를 의미 공간에서 표현할 줄 아는 귀"만 남음
- LLM 연결: 이제 그 “귀”가 들은 임베딩을 LLM이 해석해서 문장으로 말하는 것
즉, CTC는 Conformer가 들을 줄 알게 만드는 훈련용 임시 학습기이고,
그걸 끝내면 “말귀를 알아듣는 청각 피질”만 남겨서 LLM에 연결한다고 보면 됩니다.
아주 정확한 질문입니다 — 핵심을 정확히 짚으셨습니다 ✅
결론부터 말하면,
네, 맞습니다.
Conformer의 출력(512차원 × n개 프레임 스택)을 하나의 4096차원 벡터로 프로젝션(Projection) 해서 LLM의 입력 차원과 맞춥니다.
아래에 그 과정을 단계별로, 왜 이렇게 설계했는지도 함께 정리해드리겠습니다.
🔹 1. 차원 불일치 문제
- Conformer 출력:
각 타임 프레임마다 512차원의 feature vector를 냅니다.
(즉, shape ≈ [T, 512]) - Stacking (Frame stacking):
여러 프레임을 하나로 묶어(예: n=3이면 240ms),
[512] × 3 = 1536차원, [512] × 12 = 6144차원 등으로 차원이 가변적이 됩니다.
이 스택은 시간 길이를 줄이는 대신, 한 벡터에 더 긴 오디오 정보를 포함하게 됩니다. - 문제:
LLM(LLaMA-7B 등)은 고정 입력 차원, 즉 hidden size = 4096을 요구합니다.
따라서 Conformer 출력의 차원이 4096보다 작거나 크면 그대로는 입력할 수 없습니다.
🔹 2. 해결: Linear Projection Layer
논문 본문에 명시되어 있습니다:
“The stacked embeddings are then projected to the hidden dimension of the large language model to ensure they can be prepended to the text embeddings.”
즉,
“512×n차원 → 4096차원” 으로 선형 변환(Projection)을 수행합니다.
수식으로 표현하면
[
\mathbf{h}_t^{\text{conf}} \in \mathbb{R}^{512n}
\quad \xrightarrow{\text{Linear Projection }W\in\mathbb{R}^{512n\times 4096}}
\quad \mathbf{z}_t^{\text{proj}} \in \mathbb{R}^{4096}
]
- 여기서 ( n ) 은 스택 프레임 수 (1,2,3,6,12 등)
- ( \mathbf{z}_t^{\text{proj}} ) 가 바로 LLM에 입력되는 오디오 임베딩입니다.
🔹 3. 프로젝션의 역할
역할 설명| 차원 정합 (Dimensional Matching) | Conformer 출력과 LLM 입력 hidden size(4096)를 동일하게 만들어줌 |
| 정보 압축 (Information Compression) | 여러 프레임의 지역 정보(짧은 시간 구간)를 하나의 고차원 벡터에 요약 |
| 모달리티 정렬 (Modality Alignment) | 오디오 특징 공간을 LLM의 언어 임베딩 공간으로 정렬시킴 (embedding bridge 역할) |
이 덕분에 LLM은 “이 벡터는 오디오 기반 토큰 시퀀스의 일부”라는 것을 동일한 차원 공간에서 자연스럽게 처리할 수 있습니다.
🔹 4. 예시 (n에 따른 입력 흐름)
n (스택 수) Conformer 출력 차원 Projection 후 차원 LLM 입력 길이 감소율| 1 | 512 | 4096 | 1x |
| 3 | 1536 | 4096 | 3x fewer frames |
| 6 | 3072 | 4096 | 6x fewer frames |
| 12 | 6144 | 4096 | 12x fewer frames |
즉, n이 커질수록 시간 해상도는 낮아지지만, LLM 입력 길이가 줄어 긴 오디오도 처리 가능하게 됩니다.
Projection layer는 이 차원의 “다리” 역할을 합니다.
🔹 5. 직관적 이해
비유로 말하자면:
- Conformer가 오디오의 짧은 조각(음소) 을 각각 512차원으로 인코딩하고,
- 여러 조각을 “하나의 긴 문장 조각”으로 묶은 뒤,
- Linear projection이 그것을 LLM의 문장 단위 언어 벡터(4096차원) 로 번역해주는 겁니다.
즉, “청각적 문맥을 언어공간으로 투사하는 변환층” 역할을 합니다.
🔹 정리
항목 설명| 입력 | Conformer 출력 (T × 512) |
| Stacking | n개 프레임 묶음 → (T/n × 512n) |
| Projection | Linear(512n → 4096) |
| 출력 | (T/n × 4096) 오디오 임베딩 시퀀스 |
| 사용 목적 | LLM 입력 차원 통일 + 오디오-언어 임베딩 정렬 |
결론적으로
Conformer의 512×n 차원 representation은 항상 Linear Projection Layer를 거쳐 4096차원으로 변환되고,
이게 LLM의 입력 시퀀스 앞부분(prepend) 으로 들어갑니다.
즉, Projection은 “차원 맞춤 + 의미적 브릿지” 두 역할을 동시에 수행합니다.
좋습니다. 이 문단은 LLM 종류(언어 범위, 규모)에 따른 ASR 성능 영향을 분석한 부분으로, 논문의 LLM 선택 실험(ablation) 결과를 요약하고 있습니다.
하나씩 뜯어서 설명드리면 다음과 같습니다.
🧩 1. 실험 목적
연구팀은 처음에는 LLaMA-7B 모델을 사용했습니다.
그런데 다음과 같은 의문이 생겼습니다:
“LLaMA는 주로 영어 데이터로 학습된 모델인데,
만약 다국어 데이터로 학습된 LLM을 사용하면
다국어 음성 인식(ASR) 성능이 더 좋아질까?”
그래서 LLaMA 대신 BLOOM 시리즈(다국어 LLM)를 사용해 비교 실험을 진행했습니다.
🧠 2. 배경 차이 — LLaMA vs BLOOM
모델 학습 데이터 특성 언어 범위 규모| LLaMA-7B | 주로 영어 중심 (다른 언어는 소수) | 약 수십 개 언어지만 영어 편향 | 7B 파라미터 |
| BLOOM-560M / 1B7 / 7B1 | 다국어(Multilingual) 전용 설계 | 46개 언어 이상 | 0.56B / 1.7B / 7.1B |
즉, BLOOM은 구조적으로 다국어 언어 분포를 많이 본 모델이고,
LLaMA는 사실상 영어 모델에 가깝습니다.
⚗️ 3. 실험 설정
- Conformer 오디오 인코더는 고정 (동일한 오디오 피처 제공).
- LLM만 교체:
- LLaMA-7B
- BLOOM-560M
- BLOOM-1B7
- BLOOM-7B1
- 목표: LLM의 언어 커버리지 및 모델 크기(scale) 가 ASR 성능(WER)에 어떤 영향을 미치는가를 평가.
📊 4. 결과 해석
(1) LLaMA-7B vs BLOOM-7B1 (같은 크기)
“we observe no significant difference in average WER.”
👉 즉, 두 모델의 평균 단어 오류율(WER) 은 거의 동일했습니다.
- BLOOM은 다국어 학습,
- LLaMA는 영어 중심인데도,
결과적으로 둘 다 비슷한 수준의 성능을 보였습니다.
➡️ 이유:
한번 “다국어 음성 데이터(MLS)”로 훈련을 거치면,
기존 LLM의 언어 편향이 크게 영향을 미치지 않습니다.
즉, 오디오 인코더가 이미 각 언어의 정보를 충분히 공급해주기 때문에
LLM 내부의 언어 분포 차이는 상쇄된다는 뜻입니다.
(2) LLM 규모 효과 (BLOOM-560M → 1B7 → 7B1)
“there is a clear trend showing significantly better performance from scaling an LLM while keeping the conformer audio encoder fixed.”
👉 즉, LLM의 크기가 커질수록 WER이 지속적으로 낮아짐을 관찰했습니다.
- 같은 인코더(Conformer)를 사용할 때,
LLM이 커지면 더 복잡한 문맥적 언어 패턴을 잘 복원하고
다국어 문장 구조를 더 정확히 예측합니다.
➡️ 결론적으로:
- 언어 다양성(BLOOM의 다국어 학습)은 큰 영향을 주지 않았지만,
- LLM의 용량(파라미터 수) 은 명확히 성능을 향상시켰습니다.
🔍 5. 요약 정리표
비교 항목 LLaMA-7B BLOOM-7B1 결과 요약| 학습 언어 | 영어 중심 | 다국어 | 평균 WER 차이 거의 없음 |
| 모델 크기 | 7B | 7B | 유사 크기, 유사 성능 |
| 결론 | LLM의 언어 커버리지는 ASR 성능에 영향 미미 (다국어 오디오 학습 시) | ||
| 추가 실험 | BLOOM 560M → 1B7 → 7B1 | 모델이 커질수록 WER ↓ | 모델 스케일이 가장 중요 요인 |
💬 한 줄 결론
“LLM의 언어 다양성보다 모델 크기(Scale)가 ASR 성능 향상에 더 중요하다.”
즉,
Conformer가 음성으로부터 충분히 언어 정보를 추출하면,
LLM은 영어든 다국어든 상관없이 ‘문맥 복원기’ 로 작동하며,
결국 LLM의 용량이 클수록 더 정확히 텍스트를 생성하게 됩니다.