https://arxiv.org/abs/2409.19627
IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding
The audio watermarking technique embeds messages into audio and accurately extracts messages from the watermarked audio. Traditional methods develop algorithms based on expert experience to embed watermarks into the time-domain or transform-domain of signa
arxiv.org
신경망 기반 오디오 워터마킹은 공격을 견디도록 강건성은 좋아졌지만 여전히 용량이 낮고, 품질이 별로며, 워터마크 위치 찾기가 느리고 비효율적임
실 사용에선 동일 워터마크를 여러 구간에 중복 삽입 => 탐색비용 폭증
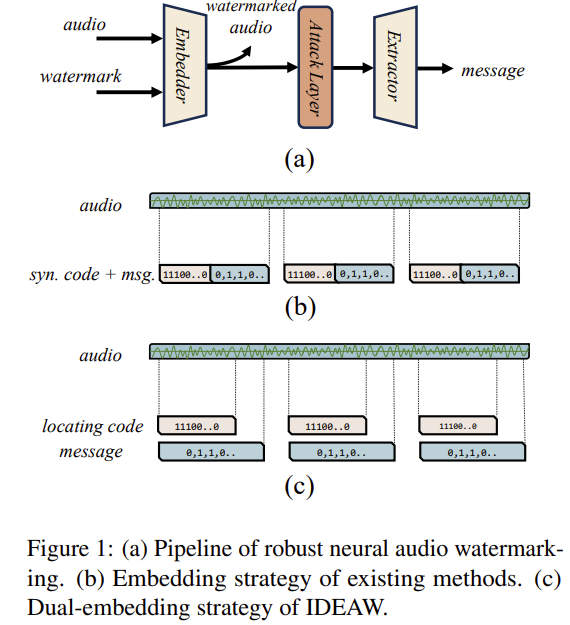
오디오에 워터마킹을 삽입하는 방법이다.

INN 1단계로 메세지를 삽입하고, INN 2단계로 위치 코드를 삽입함
추출 시에는 가벼운 INN 2단곌로 먼저 c만 빠르게 탐색 및 검증 하고 맞으면 무거운 INN 1단계를 돌려 메세지를 추출하여 탐색 시간을 절감한다.
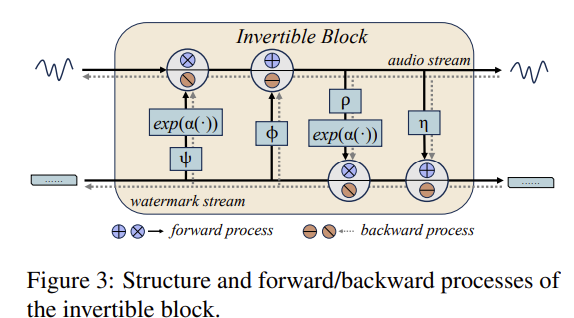
각 INN 블록은 오디오 스트림과 워터마크 스트림을 함께 변환한다.

다양한 워터마크 제거 공격에도 강건한 것을 볼 수 있다.
워터마크가 들어간 파형을 비교해도 눈으로 식별하기 어렵다.
Residual을 확대한 그래프를 봐도 임베딩은 진폭차가 작아 원음에 미치는 영향이 매우 적다.
| 문제 상황 | 신경 기반 오디오 워터마킹에서 용량↓, 지각성 미흡, 위치 탐색(locating) 고비용, INN 학습 시 공격 레이어로 대칭성 붕괴 |
| 방법론 | Dual-Embedding + INN: 1단계(INN#1)에 메시지 m, 2단계(INN#2)에 locating code c를 “수직 분리” 삽입 → 추출은 c→m 역순, Balance Block으로 공격-유발 분포 비대칭 보정 |
| 학습 설정 | VCTK(음성)+FMA(음악), 16 kHz, 1초 청크, STFT/ISTFT((n_{fft}=1000, hop=250, win=1000)) |
| 학습법 | 두 단계 학습: (1) 지각성+무결성 중심으로 INN 안정화 → (2) 공격 레이어+Balance Block 포함 공동학습. 총손실 L=λ_1L_{integ}+λ_2L_{percept}+λ_3L_{ident} |
| 공격 세트(훈련/평가) | GN(35 dB), LF(5 kHz), MP3(64 kbps), QZ(29레벨), RD(0.1%), RS(×200%), AM(0.9×), TS(90%) |
| 평가지표 | SNR(지각성), ACC(추출 정확도), Capacity(bps) |
| 결과(기본 성능) | 용량별로 SNR–ACC–Capacity 균형: 20 bps: 40.43 dB/99.64%, 32 bps: 37.72 dB/99.52%, 56 bps: 35.41 dB/99.44% |
| 결과(강건성) | 8종 공격에서 IDEAW(32/56 bps) ≈ 98–99% ACC로 WavMark/DeAR과 동급~우수 |
| 결과(탐색 효율) | Dual-Embedding으로 locating 시간 약 40–50% 절감, 특히 삽입 위치가 뒤로 갈수록 이점↑ |
| Ablation(요지) | Discriminator 제거(M1)→SNR↓, 강건성≈유지 / Balance Block 제거(M2)→강건성·ACC↓ |
| 기여 | ① Dual-Embedding으로 빠른 locating ② Balance Block으로 INN 대칭성 복원/안정화 ③ 용량 확장(최대 56 bps)에도 지각성·강건성 유지 |
| 한계/관찰 | ① c 길이(10 bit) 고정 설계(충돌≈1/2¹⁰) ② 저에너지 음성 구간에서 지각성 영향이 상대적으로 클 수 있음 |
좋아요. 업로드하신 논문 **“IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding”**를 논문 근거에 따라 체계적으로 요약·해설합니다. (핵심 인용은 원문 근거로 표기)
1) 문제 설정(Problem) — 무엇을 해결하나?
- 신경망 기반 오디오 워터마킹은 공격(압축, 리샘플링, 잡음 등)을 견디도록 학습해 강건성은 좋아졌지만, 여전히
① **용량(capacity)**이 낮고, ② **지각 불가성(품질)**이 불만족스러우며, ③ 실제 적용에서 **워터마크 위치 찾기(locating)**가 느리고 비효율적이라는 문제가 있음. - 특히 실사용에서는 동일 워터마크를 여러 구간에 중복 삽입하는데, 트리밍/스플라이싱이 일어나면 위치가 바뀌어 탐색 비용이 폭증한다는 점이 치명적.
2) 핵심 아이디어(Method) — 어떻게 풀었나? (Step-by-Step)
Step A. Dual-Embedding(이중 삽입) 전략
- **메시지 비트(m)**와 **위치 동기 코드(c; locating code)**를 서로 다른 INN 단계에 “수직적으로 분리”해 순차 삽입.
- 1단계 INN(#1): 메시지 m 삽입
- 2단계 INN(#2): 위치 코드 c 삽입
- 추출 시에는 역순: 먼저 가벼운 INN#2로 c만 빠르게 탐색·검증 → 맞으면 무거운 INN#1을 돌려 m 추출 → 탐색 시간 40~50% 절감.
Step B. Invertible Neural Network(INN) 블록 설계
- 각 INN 블록은 오디오 스트림 x와 워터마크 스트림 s(m 또는 c)을 함께 변환:
(x_{i+1}=x_i\odot e^{\alpha(\psi(s_i))}+\phi(s_i),\quad s_{i+1}=s_i\odot e^{\alpha(\rho(x_{i+1}))}+\eta(x_{i+1}))
(여기서 (\alpha)는 sigmoid, (\psi,\phi,\rho,\eta)는 dense-block 기반 서브넷) - 삽입(정방향):
(x_{\text{wmd}}=\text{INN#2}(\text{INN#1}(x,m)_a,,c)_a) - 추출(역방향):
( \hat m=\text{INN#1}^{R}!\big(\text{INN#2}^{R}(x_{\text{wmd}},x_{\text{aux2}})a,,x{\text{aux1}}\big)_{wm} )
Step C. Balance Block으로 대칭성(symmetry) 복원
- INN은 **인코더=디코더(파라미터 공유)**의 대칭성이 장점이나, 공격 레이어가 삽입되면 “인코더 출력분포 (P_W)”와 “디코더 입력분포 (P_W')”가 어긋나 학습 불안정.
- **Balance Block(추출측 보조 Dense 블록)**을 두어 (P_W' \rightarrow \hat P_W \approx P_W)로 분포 보정, 대칭성·안정성 회복.
Step D. 지각 불가성 & 강건성 학습 목표
- Perceptual loss: (L_{\text{percept}}=|x_{\text{wmd}}-x|_2^2)
- Adversarial(식별기) loss: 워터마크 유무를 판별하는 Discriminator와 적대적 학습 ( (L_{\text{ident}}), (L_{\text{discr}}) )
- 무결성(정확 추출) loss: 메시지/동기코드의 (\ell_2) 차이(중간 단계 추출 포함)로 구성 (L_{\text{integ}})
- 총합: (L_{\text{total}}=\lambda_1L_{\text{integ}}+\lambda_2L_{\text{percept}}+\lambda_3L_{\text{ident}}) (권장 (\lambda_1{=}1,\lambda_2{=}0.1,\lambda_3{=}0.1))
Step E. 2-Stage 학습
- Stage-1: 강건성(공격) 제외, 지각성+무결성에 집중해 INN 이중단을 안정화
- Stage-2: 공격 레이어 + Balance Block를 켜고 전체 공동학습(ACC 유지하며 강건성 상승)
3) 아키텍처 요약 도식(텍스트)
- Embedder (INN#1 → INN#2) → Attack Layer → Balance Block → Extractor (INN#2^R → INN#1^R) + Discriminator(병렬)
- 도메인: STFT/ISTFT 사이에서 동작(시간-주파수 변환), 각 단계에서 길이 정규화 모듈 포함
4) 학습·평가 설정(Setup)
- 데이터: VCTK(음성), FMA(음악) — 16 kHz 리샘플, 1초 청크로 분할; STFT 파라미터 ({n_fft{=}1000,) hop(=250), win(=1000)}
- 공격 세트(훈련/평가 공통): GN(35 dB), LPF(5 kHz), MP3(64 kbps), 양자화(29레벨), 랜덤드롭(0.1%), 리샘플(×2), 진폭조정(90%), 타임스트레치(90%)
- 최적화: Adam(β₁=0.9, β₂=0.99, ε=1e-8, lr=1e-5) + StepLR, 각 스테이지 100k iter; (|c|=10) bit(충돌≈1/1024)
- 지표: SNR(↑), ACC(정확도, ↑), Capacity(bps, ↑)
5) 실험 결과(Results)
5.1 기본 성능(용량별 비교)
- IDEAW(22+10=32 bps): SNR 37.72 dB, ACC 99.52% → **WavMark(32 bps, 38.55/99.35)**와 비슷한 지각성/정확도.
- IDEAW(46+10=56 bps): SNR 35.41 dB, ACC 99.44% → 더 높은 용량에서도 높은 ACC 유지.
- IDEAW(10+10=20 bps): SNR 40.43 dB, ACC 99.64% → 낮은 용량일수록 SNR/ACC가 더 좋음(일반 경향 확인).
5.2 강건성(공격별 ACC, %)
- 8종 공격(GN/LF/CP/QZ/RD/RS/AM/TS) 전반에서 **IDEAW(22+10, 46+10)**가 WavMark와 비교가능~우수한 ACC를 보임(대부분 98~99%대).
5.3 위치 탐색 효율
- 동기코드+메시지 동시 추출(단일 단계) 대비, IDEAW의 “코드-먼저” 탐색은 평균 40~50% 시간 절감. 워터마크가 오디오 뒷부분에 있을수록 이점이 커짐.
5.4 Ablation
- Discriminator 제거(M1): SNR 약화(품질 저하), 강건성은 유사.
- Balance Block 제거(M2): 강건성·ACC 하락 → 공격으로 인한 비대칭 보정의 실효성 확인.
6) 수식/목표 정리(간단 표)
구성요소 정의/역할 핵심식/목표| INN 블록 | 오디오·비밀 스트림 결합 변환 | (x_{i+1}, s_{i+1}) 갱신식(상단 Step B) |
| Dual-Embedding | (m) 후 (c) 삽입(2-stage) | (x_{\text{wmd}}=\text{INN#2}(\text{INN#1}(x,m)_a, c)_a) |
| Dual-Extraction | (c) 먼저, 그다음 (m) | (\hat m=\text{INN#1}^{R}(\text{INN#2}^{R}(\cdot))) |
| Loss(총합) | 무결성+지각+식별 | (L_{\text{total}}=\lambda_1L_{\text{integ}}+\lambda_2L_{\text{percept}}+\lambda_3L_{\text{ident}}) |
| Balance Block | 공격-유발 분포 비대칭 보정 | (P_W'!\to \hat P_W\approx P_W) |
(각 항목 근거: 본문 수식·설계 설명)
7) 기여(Contributions)
- Dual-Embedding으로 위치 탐색을 경량화(동기 코드만 신속 탐지 후 메시지 추출) → 탐색 시간 40~50% 단축.
- Balance Block으로 공격 레이어가 야기한 INN 비대칭성 완화, 학습 안정성/강건성 향상.
- **더 높은 용량(최대 56 bps)**에서도 높은 ACC와 양호한 SNR을 유지.
8) 한계(Limitations) & 향후 과제
- (한계) c와 m의 비트 길이가 모델 설계 시 고정되어 유연 조절이 어렵다. / 저에너지 음성에서 지각성이 상대적으로 취약.
- (미래일) 용량 극대화 아키텍처, 에너지 적응형 전략, 생성 모델 내 내재 워터마킹(post-hoc 아닌 in-model) 탐구.
9) 실무 적용 가이드(재현·응용 팁)
데이터/전처리
- 16 kHz, 1 s 청크로 슬라이싱 → STFT((n_fft{=}1000), hop 250, win 1000) 권장.
모델/학습 루틴
- Stage-1: INN#1·#2만 두고 (L_{\text{integ}}{+}\lambda_2L_{\text{percept}}{+}\lambda_3L_{\text{ident}})로 안정화
- Stage-2: Attack Layer(8종 랜덤 샘플) + Balance Block on → 동일 (L_{\text{total}})로 joint 학습
- (|c|{=}10)bit 기본, (|m|)은 타깃 용량(bps)에 맞춰 설계(예: 46 bit/s → 총 56 bps).
평가 체크리스트
- SNR(지각성), ACC(공격별), 탐색시간(동기 탐지→메시지 추출 경로 비교), 용량-품질 트레이드오프 곡선.
10) 비교 관점 요약 표 (한 장으로 회상용)
항목 기존 신경 워터마킹 IDEAW| 삽입/추출 | 동기+메시지 동시 처리(단일 단계) | 이중 단계(메시지→동기 분리 삽입, 추출은 역순) |
| 탐색(Locating) | 고비용(매 스텝 메시지까지 추출) | 저비용(동기만 먼저 판별 → 40~50% 절감) |
| 대칭성 | 공격 레이어로 INN 대칭 붕괴 | Balance Block으로 분포 보정·안정화 |
| 용량 | 보통 8–32 bps | 유연 확장(최대 56 bps 실증) |
| 품질/강건성 | 용량↑ 시 저하 경향 | 용량↑에서도 ACC 높게 유지, SNR 경쟁력 |
| 구현 도메인 | STFT/DWT 혼합 | STFT 일관 + 길이 정규화 모듈 |
(모든 항목은 논문 실험/설명 근거)
11) 연구 확장 아이디어(당신의 관심사에 맞춰)
- 가변 길이 동기코드: 트랜스포머형 코드 검출기로 (|c|) 동적 선택 → 탐색 지연과 오탐률을 상황별로 최적화. (논문 한계 보완)
- 에너지 인지 삽입 스케줄링: STFT-band 에너지/마스킹 모델을 이용해 프레임·대역별 삽입 강도 적응.
- 생성단 내장 워터마킹: TTS/음악 생성 모델의 스펙트럼 디코더에 INN-hook을 결합해 post-hoc 대비 용량/강건성↑.
필요하시면, **훈련 스크립트(두 단계 학습 템플릿)**와 공격 레이어 레시피, 탐색 시간 측정 코드까지 바로 만들어 드릴게요.
아래는 업로드하신 논문 IDEAW: Robust Neural Audio Watermarking with Invertible Dual-Embedding의 **방법론(Method)**을 논문 근거(본문 라인) 위주로 단계별·명확하게 풀어 쓴 설명입니다. 중요한 핵심진술마다 논문 위치를 바로 가리키는 인용을 넣었으니(라인 참조) 원문과 대조하면서 보실 수 있습니다.
개요 — 한 문장 정리
IDEAW는 (1) 메시지와 위치(동기/locating) 코드를 서로 다른 단계의 두 개의 INN에 수직적으로 나눠 삽입(dual-embedding)하여 위치 탐색 비용을 낮추고, (2) 공격(압축·잡음·리샘플 등)으로 인해 생기는 INN의 대칭성 붕괴를 보정하기 위해 Balance Block을 넣어 전체 시스템의 강건성·지각불가성·용량을 동시에 끌어올립니다.
아키텍처(구성 요소) — 핵심 블록과 흐름
- Embedder (Dual-stage INN)
- INN#1: 먼저 메시지 m을 STFT 도메인에서 입력 오디오 x에 삽입.
- INN#2: INN#1의 출력에 locating code c를 삽입(수직 분리). 최종 물음표는 ISTFT로 파형 복원.
- Attack Layer
- 학습 시 다양한 공격을 샘플-단위로 적용하여 강건성 훈련(예: Gaussian noise, MP3 64kbps, resampling 등).
- Extractor (Dual-stage 역순)
- 추출 시 먼저 INN#2로 locating code(c)를 추출, 일치 확인되면 그 위치의 오디오에 대해 INN#1 역으로 메시지(m)를 추출(비용 절감 목적).
- Discriminator (ident loss)
- 물음표의 지각불가성(사람이 원본/워터마크 구분 못함) 보장을 위해 식별기와 적대적 학습을 병행.
- Balance Block
- Attack Layer가 도입되면 인코더(임베더)의 출력분포 (P_W)와 디코더(익스트랙터)의 입력분포가 달라져 INN의 “대칭성”이 깨짐. Balance Block은 extractor 쪽에 추가 파라미터(여러 dense blocks)를 두어 공격 후 분포 (P_W')를 원래 분포에 가깝게 보정함(대칭성 유지, 안정적 추출).
수학적/연산적 세부 — INN 블록, 삽입/추출, 손실함수
1) Invertible block (한 블록의 정방향식)
논문의 INN 블록은 오디오 스트림 (x)와 워터마크 스트림 (s)를 동시에 갱신합니다(식 1):
[
x_{i+1} = x_i \odot \exp(\alpha(\psi(s_i))) + \phi(s_i)
]
[
s_{i+1} = s_i \odot \exp(\alpha(\rho(x_{i+1}))) + \eta(x_{i+1})
]
여기서 (\alpha)는 sigmoid, (\psi,\phi,\rho,\eta)는 subnet(문헌: dense block으로 구현). 이 구조 때문에 임베딩과 추출이 동일한 네트워크(파라미터 공유)로 가능하며 역방향 계산도 정확히 정의됩니다.
2) Dual-embedding(정식)
임베딩 연산(식 2):
[
x_{\text{wmd}} = \mathrm{INN#2}\big(\mathrm{INN#1}(x,m)_a,; c\big)_a
]
(서브스크립트 (a)는 audio-stream 출력, ({wm})은 watermark-stream을 의미). 즉, INN#1으로 메시지 삽입 → INN#2로 locating code 삽입 → ISTFT로 파형 복구.
3) Dual-extraction(정식)
추출(역연산, 식 3):
[
\hat m = \mathrm{INN#1}^{R}\big(\mathrm{INN#2}^{R}(x_{\text{wmd}}, x_{\text{aux2}})a,; x{\text{aux1}}\big){wm}
]
(여기서 (x{aux})는 랜덤 샘플 신호로, INN의 watermark stream 입력으로 사용).
4) 무결성(Integrity) 손실
추출된 (\hat m), (\hat c)와 원래 m,c 간 차이를 이용:
[
L_{\text{integ}} = |\hat m - m|2^2 + |\mathrm{INN#1}^R(\mathrm{INN#1}(x,m)a,x{aux1}){wm} - m|2^2 + |\mathrm{INN#2}^R(x{wmd}, x_{aux2})_{wm} - c|_2^2
]
(즉, 각 단계에서의 회수 정확도를 모두 포함).
5) 지각불가성(Perceptual) 손실
워터마크 삽입 후 파형 변화가 작도록 단순 MSE를 사용:
[
L_{\text{percept}} = |x_{wmd} - x|_2^2.
]
6) 식별(identify) 손실 + 총합
Discriminator 손실 (L_{\text{ident}})을 정의하여 원·워터marked 구분을 억제하고, 전체 손실은
[
L_{\text{total}} = \lambda_1 L_{\text{integ}} + \lambda_2 L_{\text{percept}} + \lambda_3 L_{\text{ident}}
]
실험에서는 (\lambda_1{=}1,\ \lambda_2{=}0.1,\ \lambda_3{=}0.1) 를 사용.
학습 절차(구체적 파이프라인) — 알고리즘 관점 (pseudo 참조)
논문은 학습을 두 단계로 운영합니다(A.1 알고리즘 요약):
- 길이 규제 & STFT 변환: 메시지·locating code·오디오를 길이 규제 후 STFT로 변환.
- 메시지 삽입(Emb1) → **중간 추출(Ext1)**로 (\hat m_1) 계산(중간 검증).
- locating code 삽입(Emb2) → watermarked waveform 복원(ISTFT).
- Discriminator 학습 단계(원본 vs watermarked).
- (robust=True이면) Attack Layer 적용 → Balance Block 처리로 공격후 분포 보정.
- locating code 추출(Ext2) → (\hat c) 얻고, 메시지 최종 추출(Ext1) → (\hat m).
- 손실 계산 & 역전파: (L_{\text{integ}}, L_{\text{percept}}, L_{\text{ident}}) 계산 후 가중합으로 업데이트.
(각 스테이지는 100k iterations, optimizer: Adam lr=1e-5 등 하이퍼 참조).
공격(Attack) 구성 — 훈련/평가에서 사용된 실제 공격들
학습·평가에서 샘플링되는 공격들(설정 포함): Gaussian noise(≈35 dB), lower-pass filter(5 kHz), MP3 compress(64kbps), quantization(29 levels), random dropout(0.1%), resampling(200% → back), amplitude modification(×0.9), time stretch(90%→원래 길이). 논문은 이 8종을 batch-wise로 랜덤 적용하여 강건성 훈련함.
왜 이런 설계인가? — 설계 동기(정리된 이유)
- locating(위치) 비용 문제: 기존 방식은 모든 위치에서 전부 메시지까지 추출해야 하므로 비용이 크다. INN#2(가벼움)으로 먼저 locating code만 검사하면 훨씬 빠르게 후보 위치를 걸러낼 수 있음(탐색시간 40~50% 절감).
- INN의 대칭성 유지 필요: Attack Layer가 도입되면 embedder와 extractor(파라미터 공유)의 입력/출력 분포가 어긋나 학습이 불안정해짐 → extractor 쪽에 Balance Block을 두어 그 불일치를 보정(공격에 적응)하도록 함.
- 용량 확장성: locating code를 별도로 분리하기 때문에 전체 용량(메시지+locating)을 유연히 늘려 실험상 최대 56 bps까지 높은 ACC·SNR을 얻음(논문 결과).
실용적 구현 팁(요약/권장) — 재현성 관점
- 입력: 16 kHz, 1s 세그먼트 → STFT (n_fft=1000, hop=250, win=1000).
- locating code 길이 기본값: 10 bits(충돌확률 ≈ 1/2^10).
- 학습: 두 단계(1: 무공격으로 안정화, 2: attack+balance 포함 공동학습), 각 스테이지 100k iter, Adam lr=1e-5.
- 평가: SNR(지각성), ACC(정확도), Capacity(bps), 그리고 locating 시간 측정을 함께 보고해야 IDEAW의 장점(탐색비용 절감)이 드러남.
Ablation(무엇이 중요한가) — 핵심 발견
- Discriminator 제거 → SNR(품질) 저하(식별기 도움으로 음질 유지).
- Balance Block 제거 → 강건성·정확도 하락(공격 보정의 실효성).
원하시면 다음을 바로 드리겠습니다(추가 제공 가능) — (하나만 골라서 바로 생성해 드릴게요):
- 이 방법을 PyTorch로 구현한 의사코드(Embedder/Extractor/BalanceBlock/AttackLayer 포함).
- 논문과 동일한 **학습 파이프라인(Alg.1)**을 재현하는 트레이닝 스크립트 템플릿(데이터 로더 + STFT 전처리 + 손실 계산).
- locating 효율을 비교하는 간단한 평가 코드(exhaustive vs IDEAW 방식 시간/정확도 비교).
어떤 걸 먼저 만들어 드릴까요? (원하면 바로 구현 템플릿부터 제공하겠습니다 — 요청만 해주세요.)